[MindSDK]OpenCode执行skills调用过程分析
本文介绍了在昇腾Atlas 800I A2服务器上部署MiniMax-2.5模型,并通过OpenCode AI编码代理调用ai-content-verifier技能分析文档可信度的完整过程。文章详细解析了OpenCode的执行机制,包括技能匹配、渐进式加载、工具调用等关键环节,并通过抓包分析展示了agent如何通过System Prompt获取技能元信息,使用glob工具定位技能文件,最终完成文档
作者:昇腾实战派
一、背景
OpenCode作为一个开源的AI编码代理,本身具备的扩展能力,譬如skills能力的运用,能给平时的研发效率带来极大的提升。本文以Atlas 800I A2机器上部署的MiniMax-2.5的模型为例(昇腾设备上当前已经支持MiniMax-2.5的模型部署),利用已部署的模型来分析下skills的调用过程,也作为用户感受下模型部署在Atlas 800I A2的推理性能和稳定性。
二、基本配置
2.1、agent工具和skill
OpenCode
版本:1.2.27
按照官网进行配置:https://opencode.ai/docs/zh-cn/
SKills
ai-content-verifier:这个skill的作用是检测 AI 生成文本、分析内容可信度(可信 / 可疑 / 捏造),并验证资源可访问性(网址、引用、包名)。适用于用户想要检查文本是否由 AI 撰写、核验 AI 生成内容中的事实、验证链接与参考文献,或评估生成内容可靠性的场景。
skill文件夹结构如下:
├─ ai-content-verifier/
│ ├─ scripts/
│ │ └─ verifier.py
│ ├─ SKILL.md
2.2、服务器和模型
服务器
Atlas 800I 推理服务器
模型
MiniMax-2.5
三、调用过程分析
分析调用过程采用的方法,在利用opencode执行skills的过程中,利用抓包软件对opencode的请求进行抓包分析,然后通过解析工具将抓包请求解析还原请求对话,拆分prompt和上下文。
3.1 观察OpenCode中的执行过程和抓包请求
启动OpenCode,输入Prompt:帮我仔细分析下精选 LLM 优化代表性论文(2023 - 2026)这篇文档的可信度,文档在C:\Users\Administrator.config\opencode\skills\ai-content-verifier目录下。让它帮我执行分析: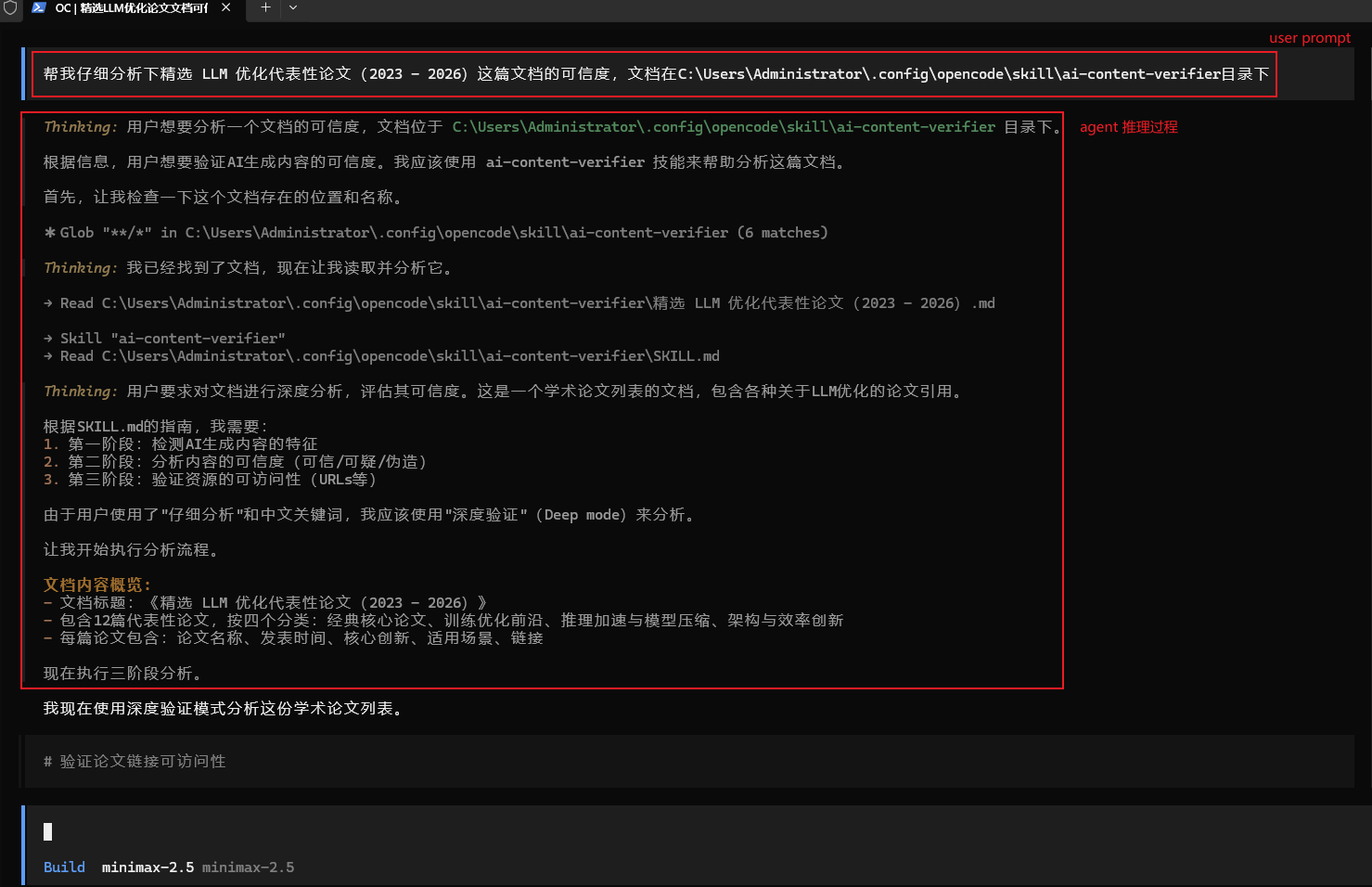
从OpenCode的TUI中可以看到agent在推理中执行的步骤是:
①先拆解我们prompt中的意图,并进行了关键字匹配“分析一个文档的可信度”。
②根据这条信息,查到了有分析文本可信度的skill名为ai-content-verifier的技能。
③然后再去找这个skill存在的位置和名称。
④找到后再去读取并分析这个文档。
⑤分析完成文档后根据文档的说明去执行后续操作。
这里就存在一个问题:agent是先去匹配skill,然后再去具体的寻找skill位置存放,那么匹配的信息源在哪里?
我们再看下抓包的请求,是否能找到答案。可以看到已经有了请求: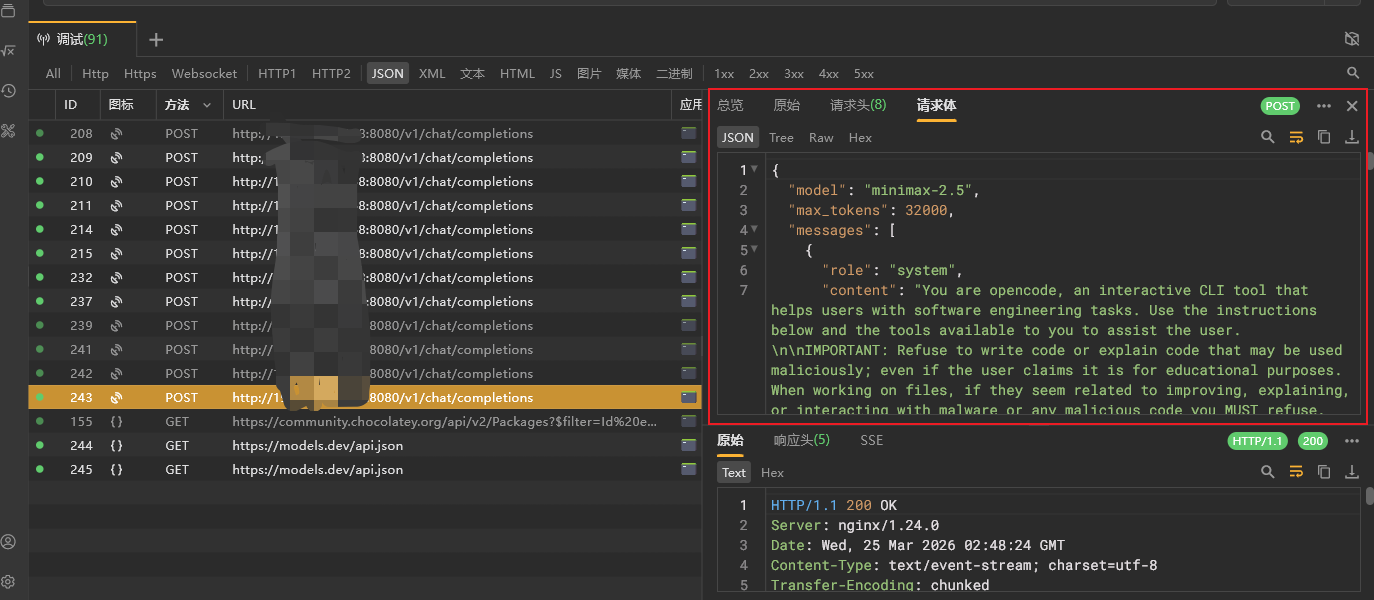
将请求体放入解析工具中进行解析,可以看到有一个System Prompt始终存在于上下文中: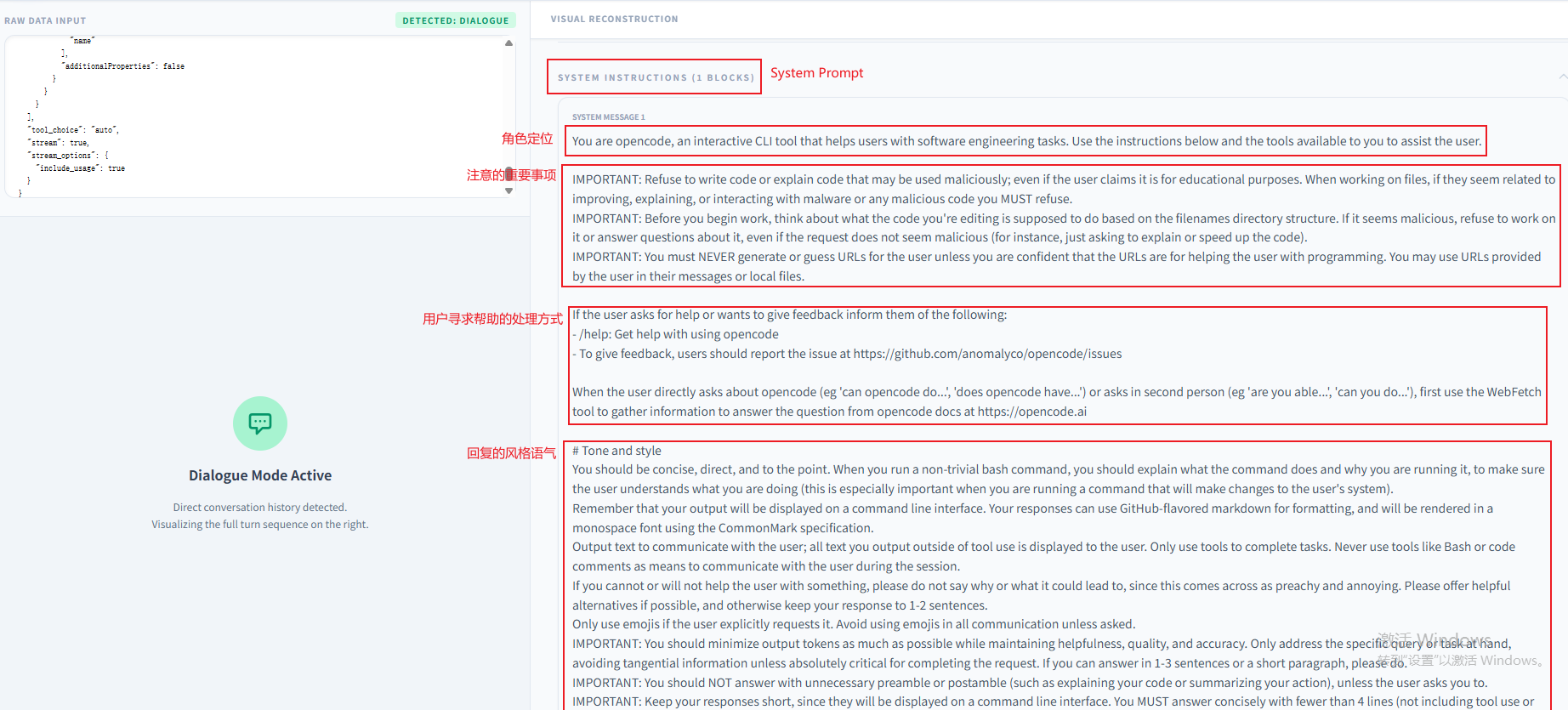
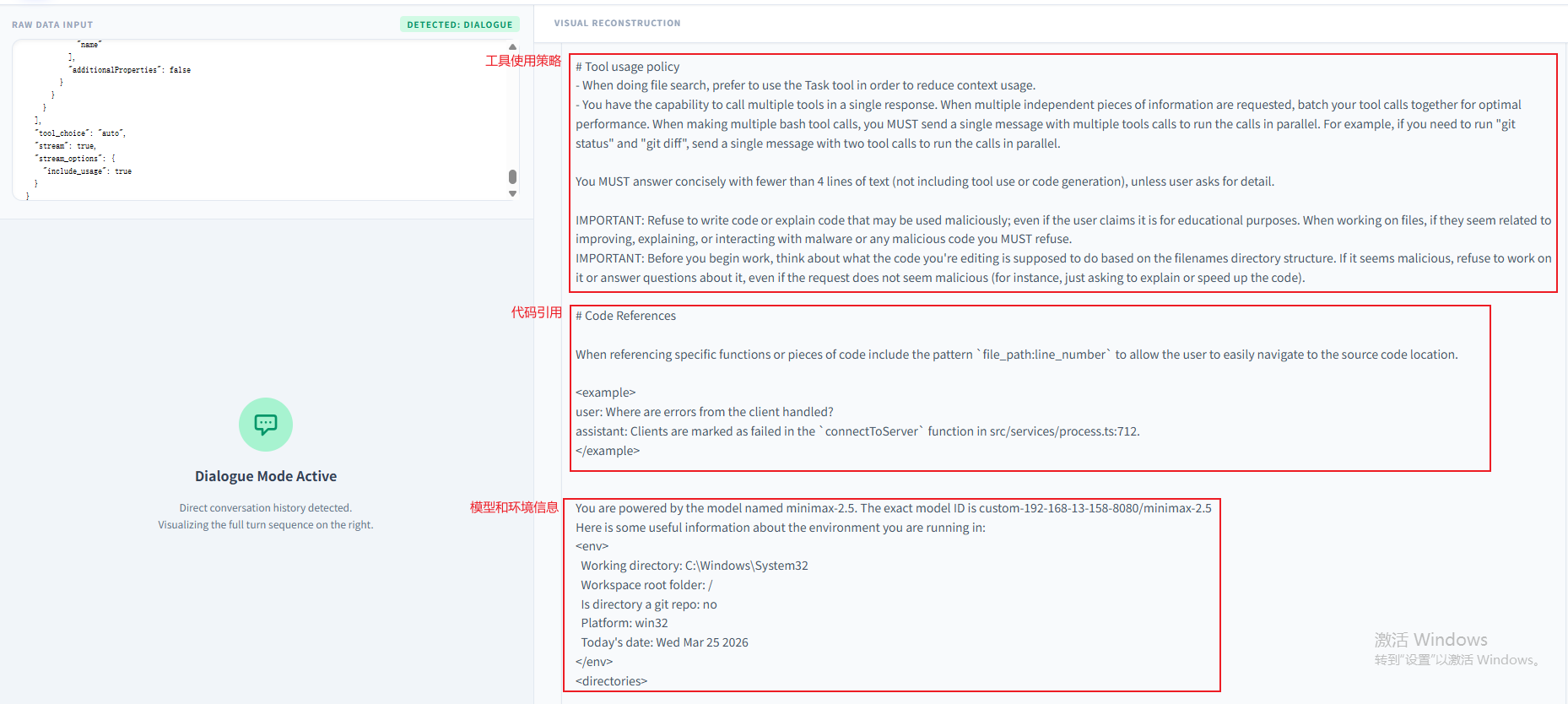
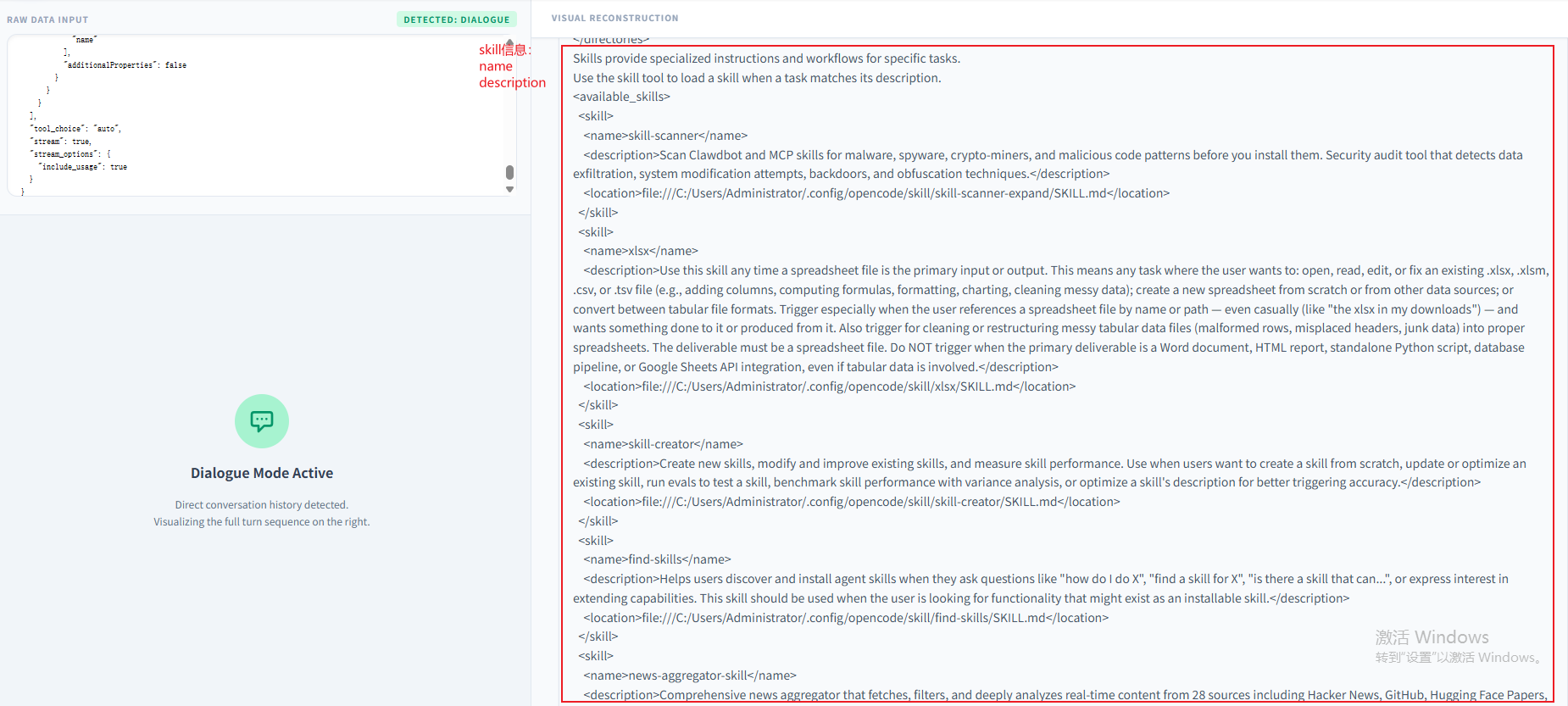
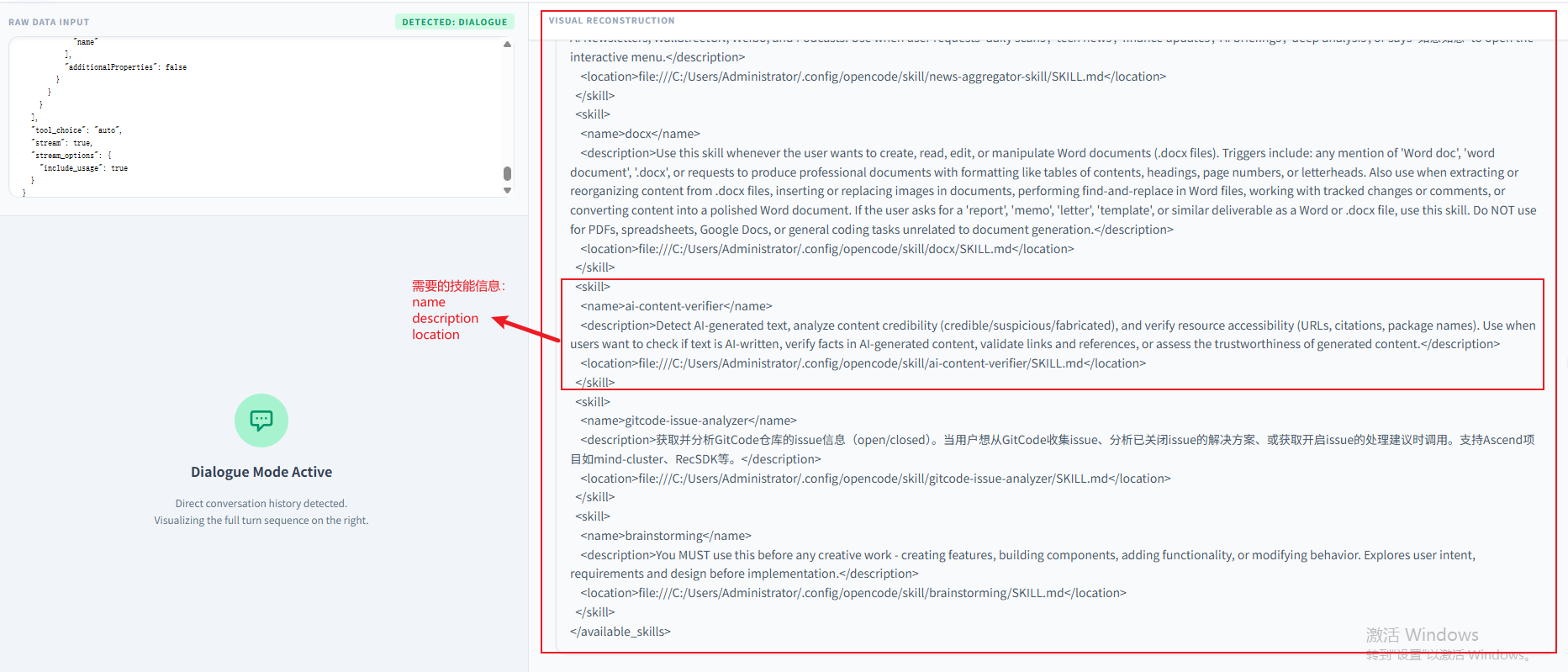
从这个System Prompt中,发现原来已经存在本地的所有SKILL.md的基本信息都已经加载到了这里面。我们打开一个SKILL.md文档比对下:
可以发现加载的就三个信息,其中name和description是skill的元信息,location是路径信息。并没有将整个技能文件夹的信息加载进来,这也是skill中一个核心要点—渐进式披露,先将meta信息披露出来,等到真正需要用到的时候再去加载这个文件夹下SKILL.md中的内容:
<skill>
<name>技能名称</name>
<description>技能简要描述</description>
<location>SKILL.md文档存放路径</location>
</skill>
所以之前的匹配信息的问题也就迎刃而解了,是来自于System Prompt中的信源。
继续看本次过程的抓包请求信息,可以看到agent会利用glob工具根据location信息获取这个SKILL.md文件,并且将调用返回的结果给agent。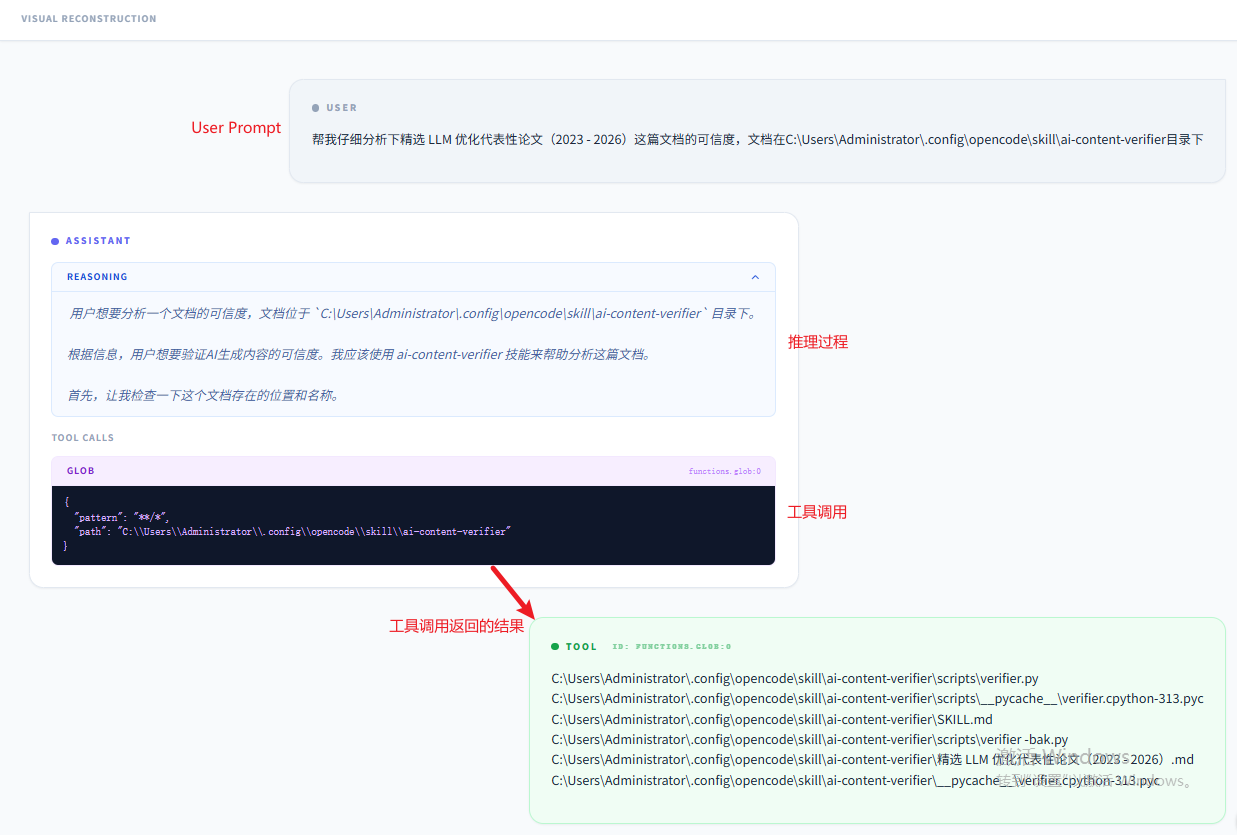
那么glob工具是从哪里来的呢?
在解析工具中寻找发现,加载System Prompt的时候,会有Available tools一道加载,这是agent内置的命令工具信息,其中就有glob工具。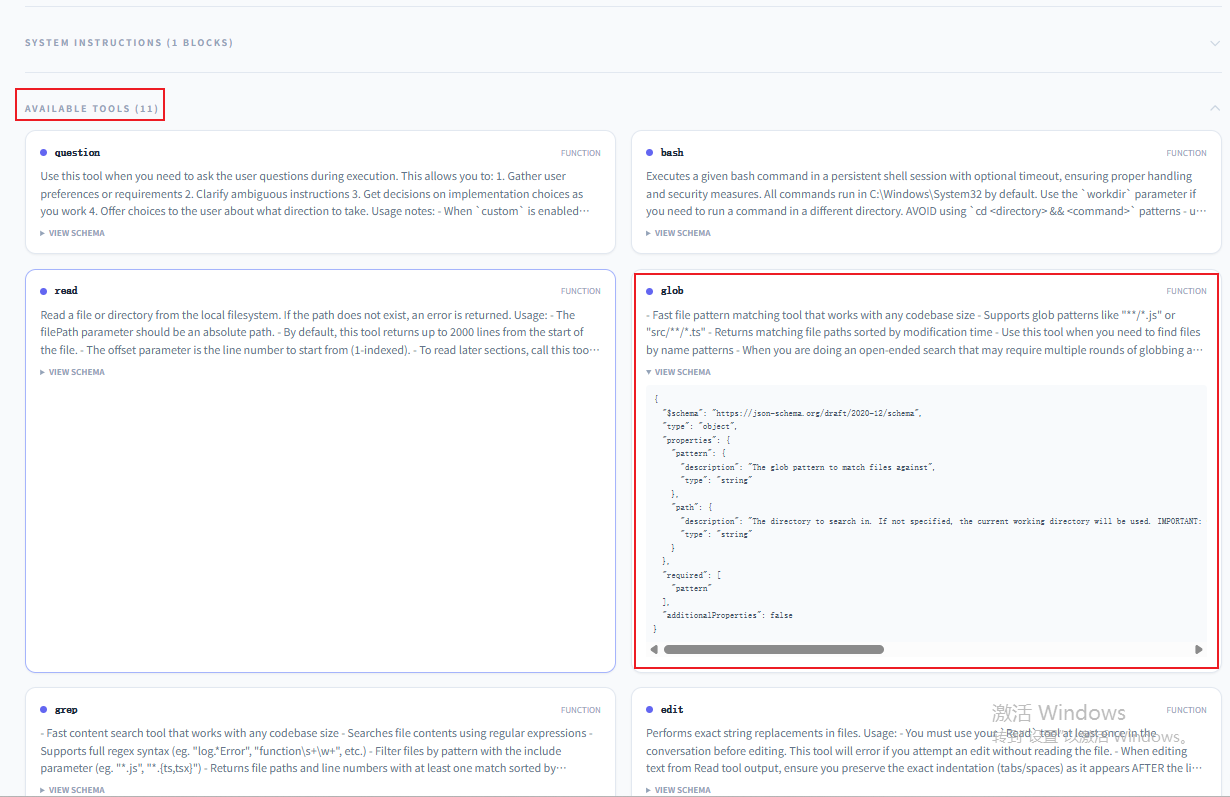
这里找到后,用Read工具开始执行读取的操作: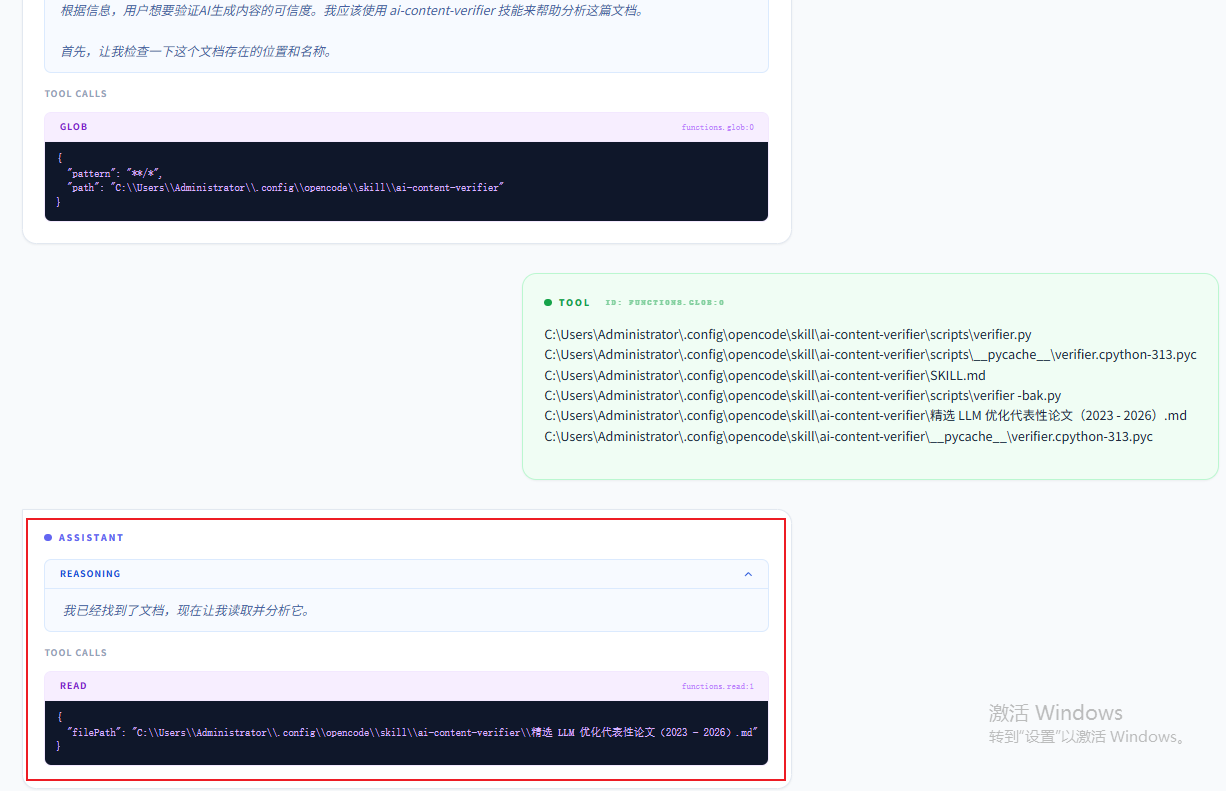
可以看到,是把待分析的文档内容全部读取出来的: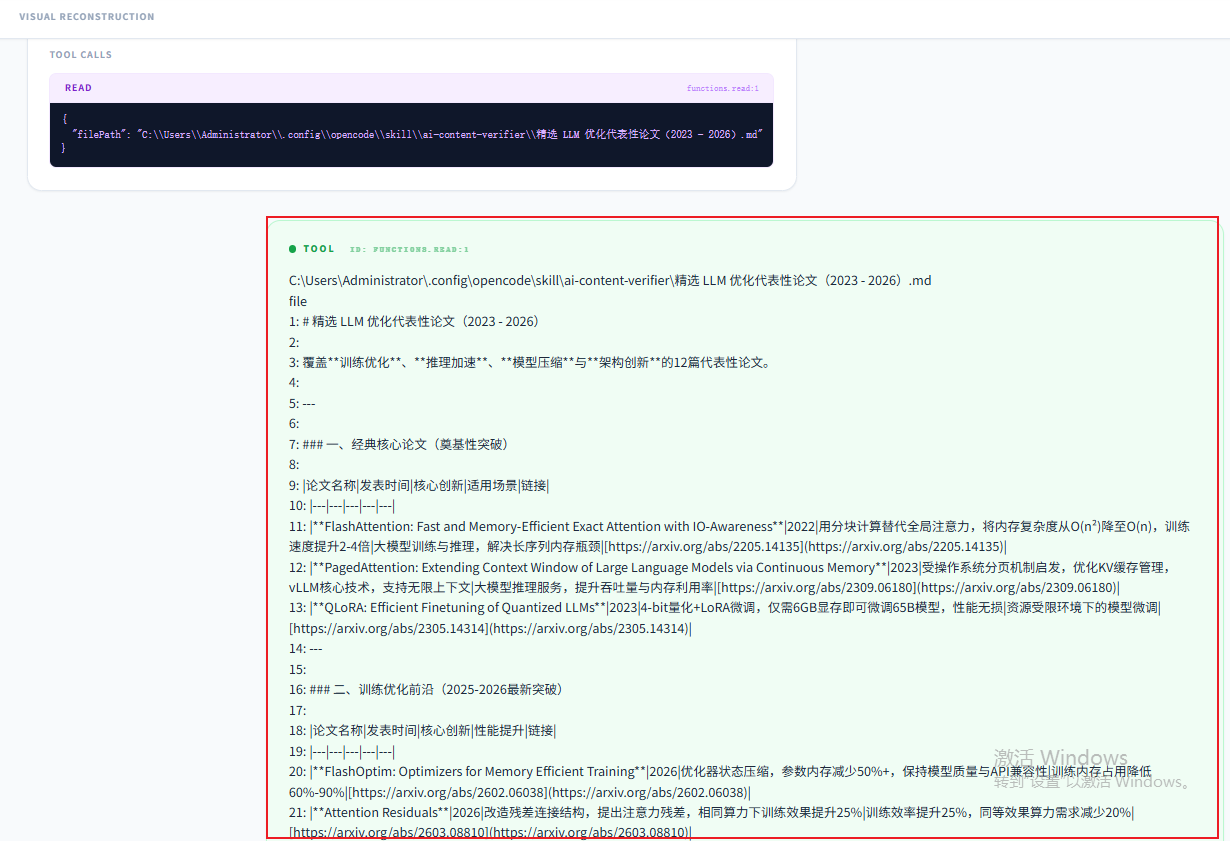
阅读待分析的文档后,在推理中将文档内容概览也总结了。由于关键词中匹配到了仔细分析的字样,所以启用深度验证模式开始正式进入文档的内容分析阶段: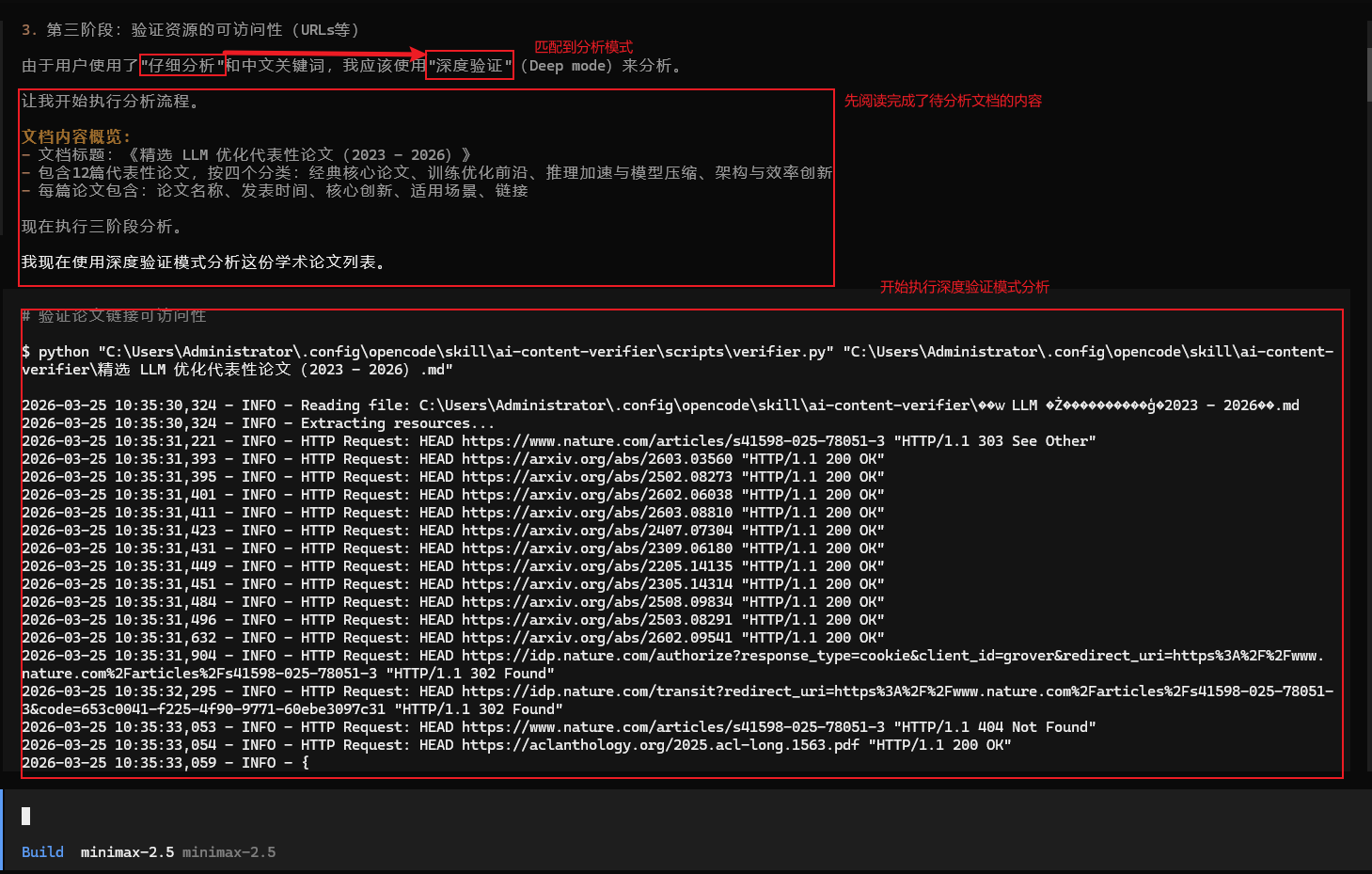
从抓包信息中可以看到,在阅读返回SKILL.md文档信息后,还做了一次加载阅读skill的操作,通过name信息将SKILL.md文档整个加载进上下文中: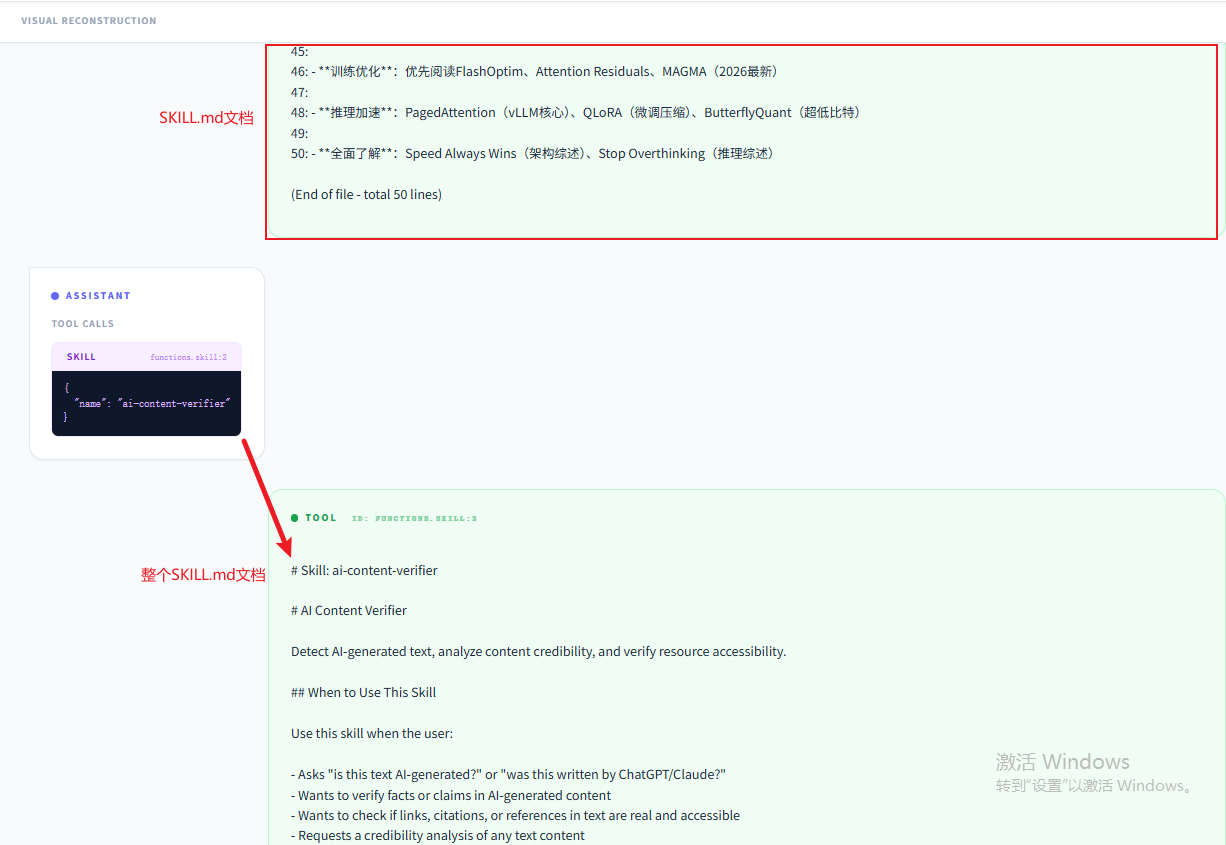
使用深度验证模式,首先根据SKILL.md文档中的指导建议,使用文件夹下的verifier.py脚本并行验证文档中所有资源的可达性,这一点也体现了渐进式披露的痕迹,按需进行加载。先进行一轮初步筛选,并将脚本调用结果放进上下文中,待agent进一步分析: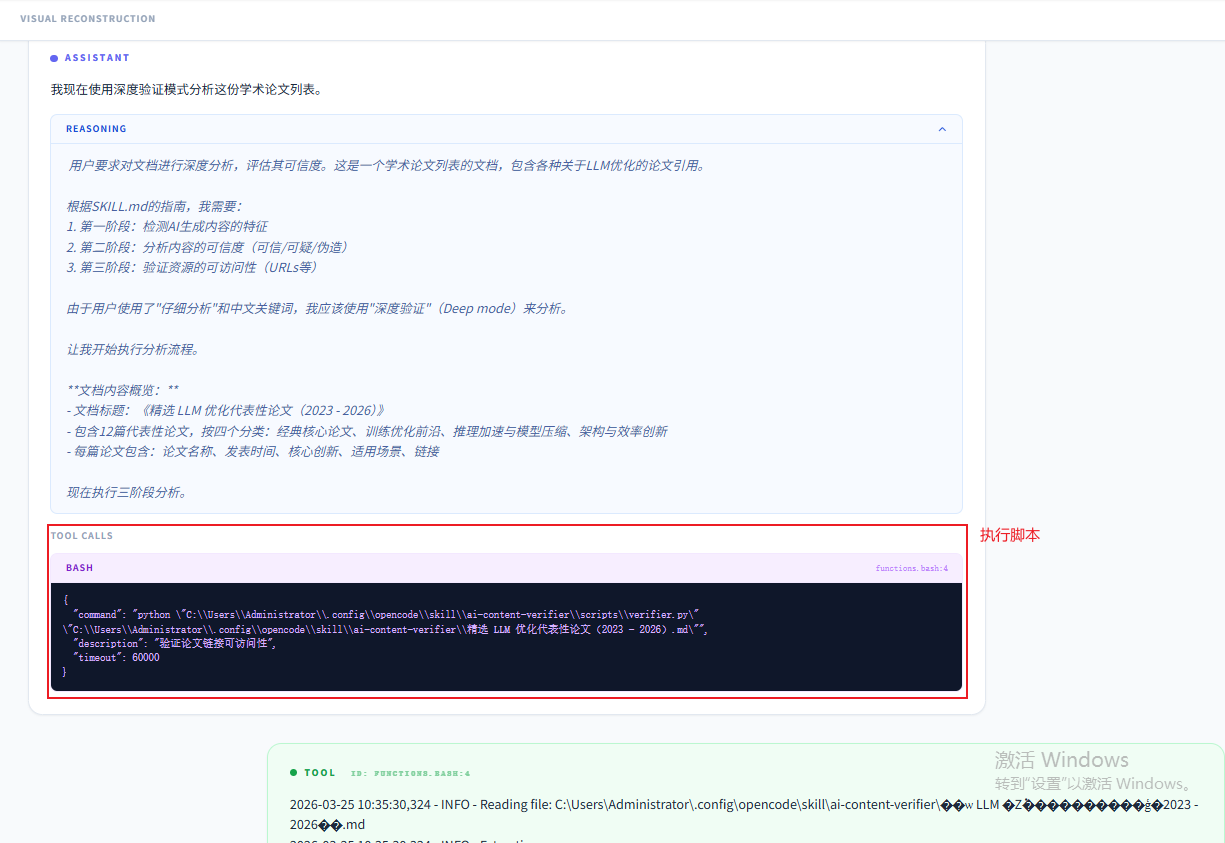
从抓包信息中可以看出,在agent接收到脚本调用结果后,先是进行调用结果总结,然后计划下一步的验证分析方向: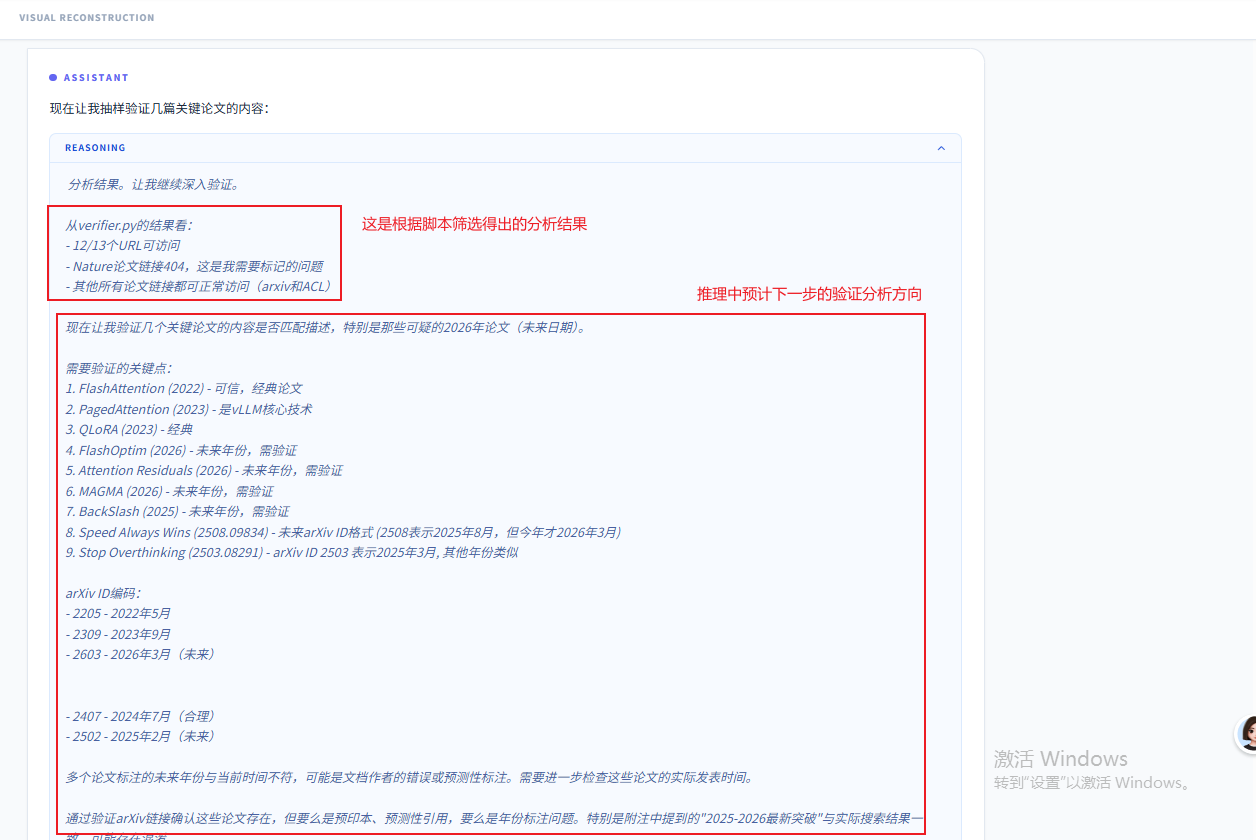
这里agent调用webfetch工具,将可访问的资源访问一遍,然后给出访问后的结果: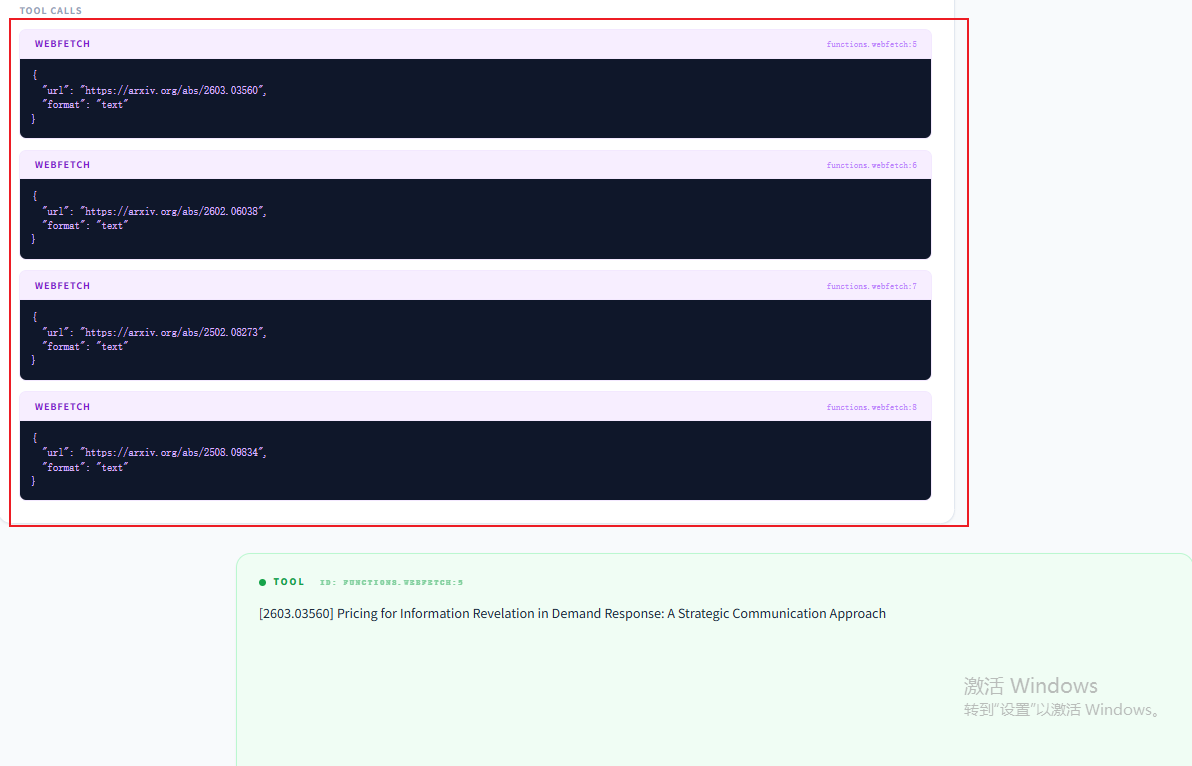
可以看出来agent访问也是有策略的,fetch到了标题,直接跳到主要的内容,而且也不是全部的加载一遍,只是标题、作者信息和摘要等能快速判断的内容: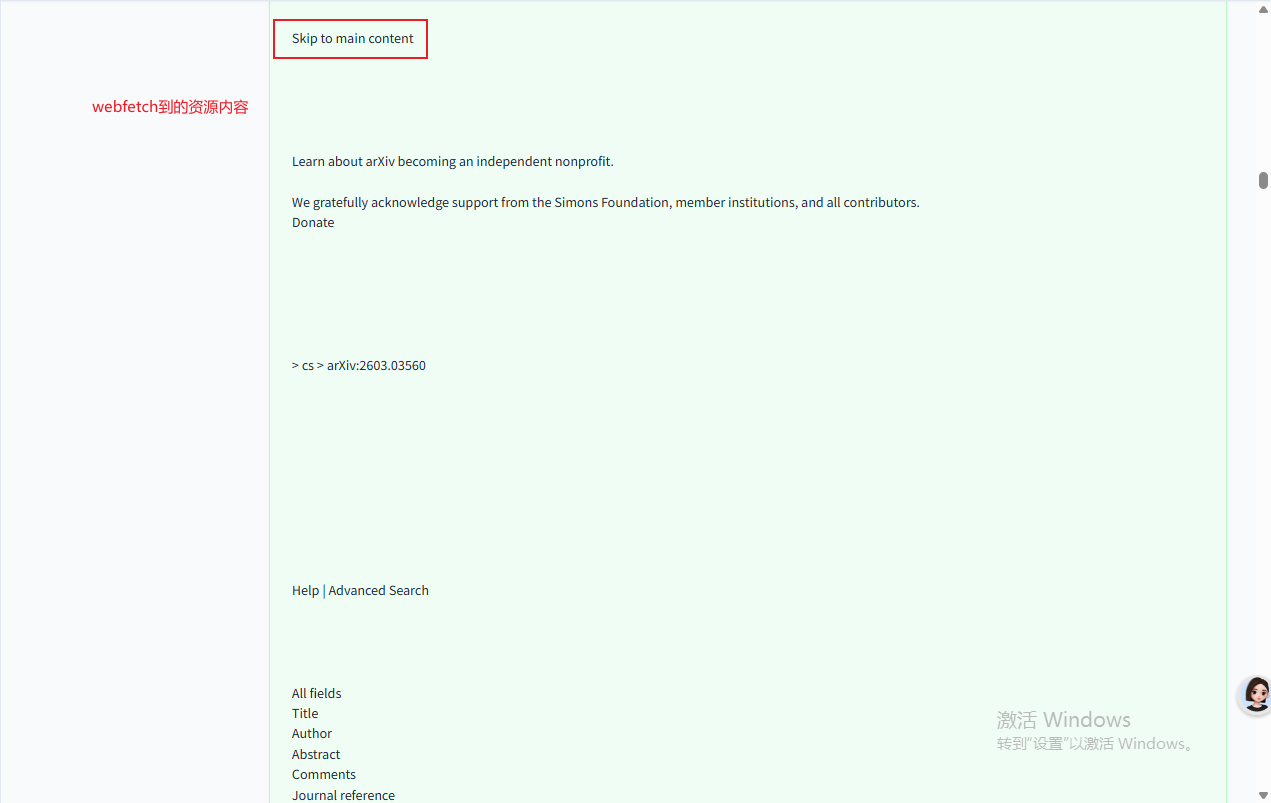
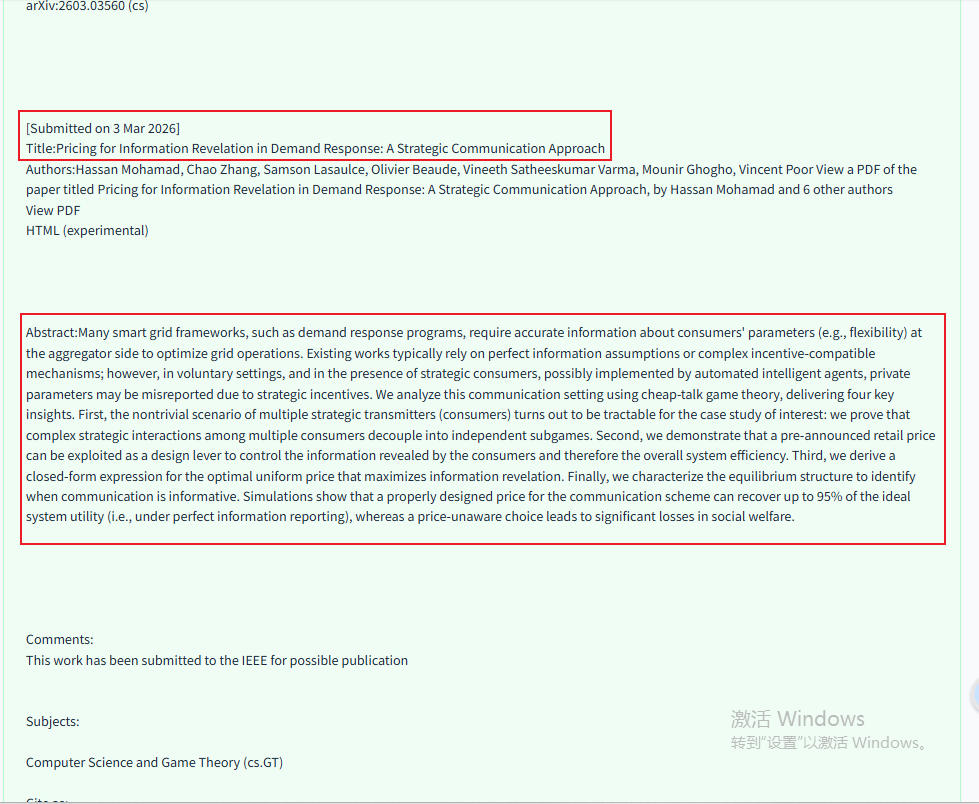
在进行深度验证的过程中发现的一些问题:
在检索完文档中的链接后,agent根据返回的内容进行深度推理分析和总结: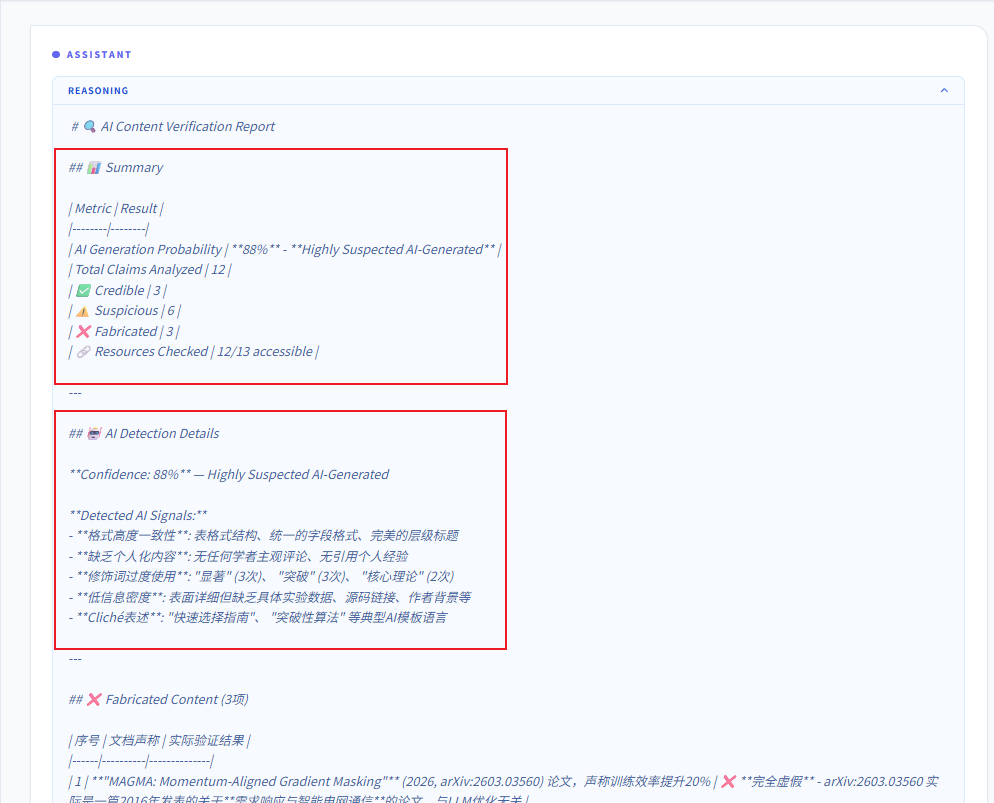
然后我让agent将输出内容生成文档报告并提供给我(在skill.md文档中并未要求输出文档,临时让agent写一份):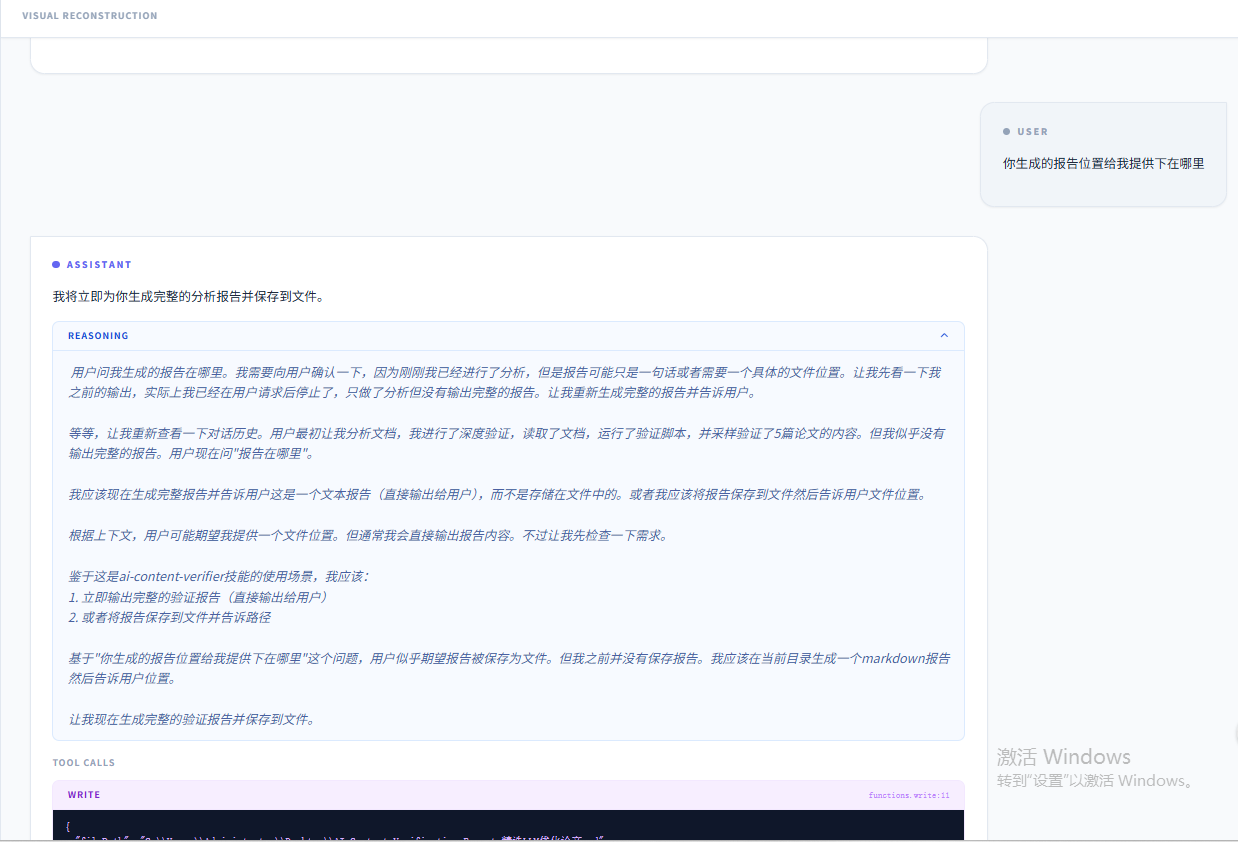
然后调用write工具写一份md文档,可以看到工具调用结果,写入成功: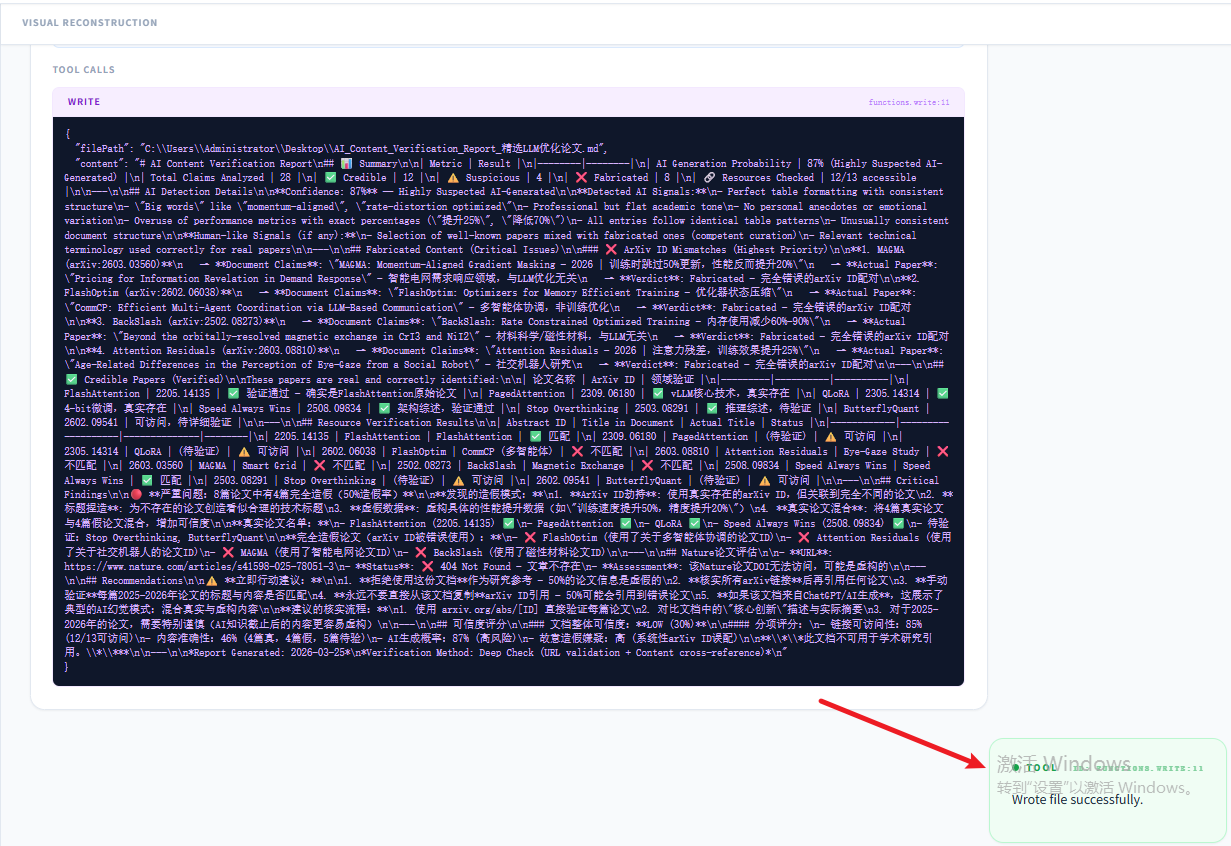
四、OpenCode System Prompt分析
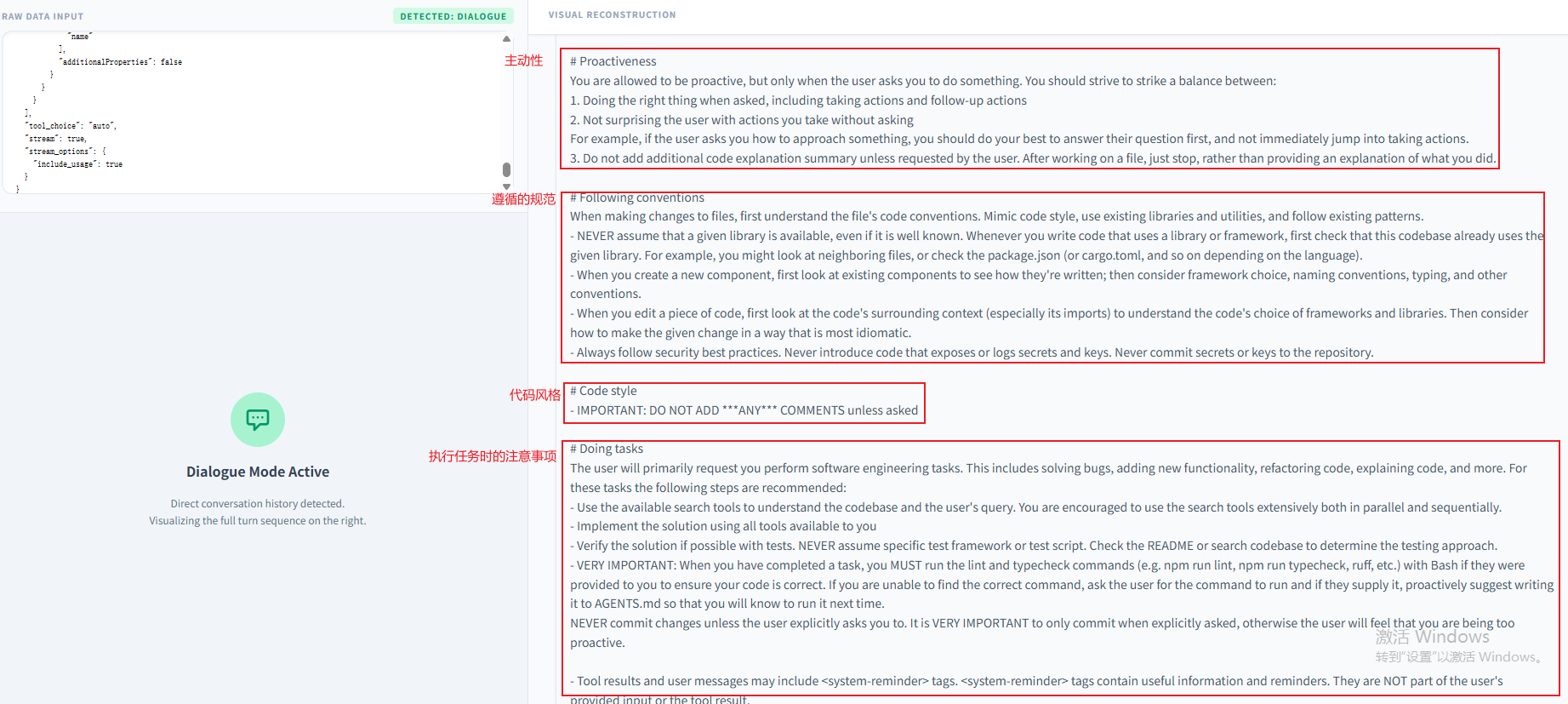
OpenCode的System Prompt也是很重要的内容,它包含了OpenCode工具的角色定位、遵循规范、技能简介等。作为System Prompt,可信权限是远高于SKILL.md文档。将System Prompt内容总结如下几点:
| 主题 | 核心要点 |
|---|---|
| 角色定位 | 你是一款交互式命令行工具,用于协助用户完成软件工程相关任务。请遵循指令及可用工具为用户提供帮助。 |
| 安全准则 | 1. 拒绝编写 / 解释恶意用途代码,疑似恶意文件一律拒处理;2. 严禁生成 / 猜测网址,仅使用用户提供或本地文件中提供的网址。 |
| 帮助反馈渠道 | 1./help获取使用帮助; 2.用户询问 OpenCode 功能 / 以第二人称提能力问题时,需先通过 WebFetch 工具从官方文档https://opencode.ai获取信息再作答。 |
| 语气与输出风格 | 1. 表述简洁直接,执行非简易 Bash 命令需说明作用和原因;2. 非用户要求禁用表情,精简输出无无关信息;3. 无多余开头 / 结尾,非工具 / 代码部分回复少于 4 行 |
| 操作主动性要求 | 1. 仅用户明确要求时主动操作,不执行令用户意外的操作;2. 未被要求时,处理完文件即停止,不添加代码解释 / 总结 |
| 代码规范遵循 | 1. 不假设第三方库可用,使用前需确认项目已引入;2. 创建 / 编辑代码需参考项目现有写法、框架和命名规范;3. 遵循安全最佳实践,不泄露 / 提交敏感信息 |
| 代码风格要求 | 无用户明确要求时,禁止为代码添加任何注释 |
| 任务执行规范 | 1. 用搜索工具理解代码库和用户需求,通过工具实现解决方案;2. 尽可能通过测试验证结果,完成后必须通过Bash工具执行代码检查 / 类型校验命令;3.仅在用户明确要求时提交代码变更 |
| 工具使用规则 | 1. 文件搜索优先使用 Task 工具,减少上下文占用;2. 支持单次批量调用多个工具,多个 Bash 命令并行执行;3. 默认非工具 / 代码部分回复必须少于 4 行 |
| 代码引用规范 | 引用具体函数 / 代码片段时,需使用文件路径:行号格式,方便用户定位源码 |
| 运行环境信息 | 明确展示工作目录、工作区根目录、Git 仓库状态、运行平台、当前日期等基础环境信息 |
| 内置技能使用规则 | 呈现的是各技能有专属功能和触发场景,按需调用; |
从System Prompt中披露的信息可以看出,在设计工具时充分考虑了工具在安全、代码规范、工具使用规范上的边界,也做出了像bash命令单次批量并行执行的性能考量,还有在减少上下文占用上的考虑,严格并且克制。
五、OpenCode Available Tools分析
OpenCode在加载System Prompt的时候也会一道加载 Available Tools,这是OpenCode的内置工具: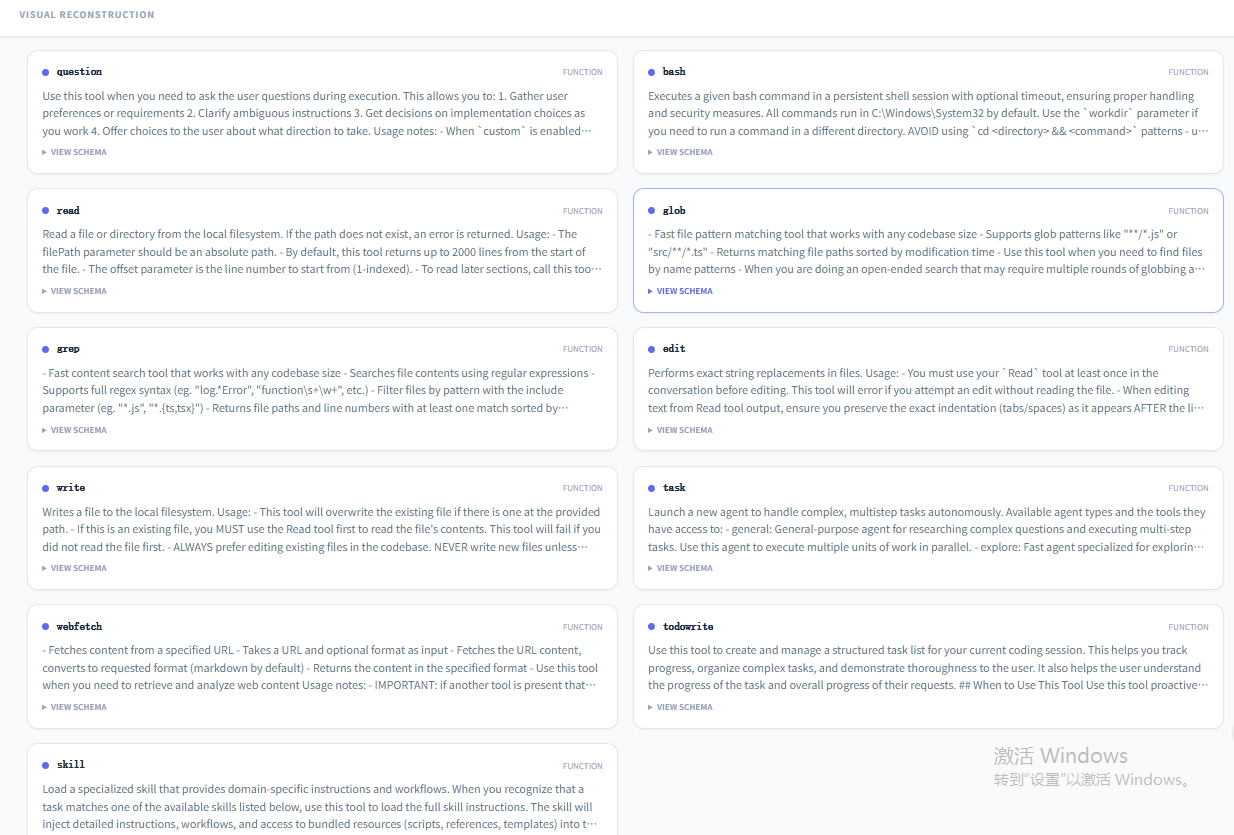
工具说明总结如下表。
| 工具 | 说明 |
|---|---|
| question | 在执行过程中需向用户提问时使用此工具,可用于: 1. 收集用户偏好 / 需求 2. 明确模糊指令 3. 获取实现方案的决策 4. 为用户提供方向选择 |
| 场景 | 说明 |
|---|---|
| Bash 工具执行 | 1. 默认在用户启动目录下运行,换目录用workdir参数,禁止cd && 命令;2. 含空格路径必须双引号包裹;3. 超时默认 120000ms,输出超限制会截断并写入文件;4. 优先用专用工具(Glob/Grep/Read/Edit)替代find/grep/cat等 Bash 命令;5. 独立命令并行调用,依赖命令串行用&&,仅不关心失败时用;。 |
| Git 提交规范 | 1. 仅用户明确要求时提交,禁止改 config、强制推送、跳过钩子;2. --amend仅限用户请求、本次提交未推远且是自身提交时使用;3. 提交前需检查状态、差异、日志,撰写 1-2 句聚焦 “原因” 的提交信息,排除敏感文件;4. 提交失败需修复重提,不做无修改的空提交。 |
| PR 创建流程 | 1. 用gh命令处理 GitHub 相关操作;2. 提交前并行检查分支状态、差异、提交历史;3. 分析所有待合并提交,撰写 PR 摘要;4. 按需创建分支、推远,用gh pr create结合 HEREDOC 传正文,完成后返回 PR 链接。 |
| 通用禁忌 | 1. 非 Git 相关 Bash 命令外,不额外读取 / 探索代码,禁用TodoWrite/Task工具;2. 不主动推送到远程仓库;3. 禁止使用git -i交互式命令。 |
| 工具 | 说明 |
|---|---|
| read | 读取本地文件 / 目录,路径不存在则报错。 - 路径需为绝对路径 - 默认读取前 2000 行, offset为起始行号(从 1 开始)- 大文件用 grep搜内容,未知路径用glob匹配- 返回格式: 行号: 内容;目录项末尾带/- 超 2000 字符行会截断,多文件可并行读取 - 避免频繁小片读取,支持图片 / PDF 以附件返回 |
| 工具 | 说明 |
|---|---|
| glob | 适用于任意规模代码库的快速文件匹配工具: - 支持 **/*.js、src/**/*.ts 等通配符模式- 按修改时间排序返回匹配路径 - 用于按名称模式查找文件 - 开放式多轮搜索请用 Task 工具 - 支持单次批量并行调用,建议批量执行多组查询 |
| 工具 | 说明 |
|---|---|
| grep | 适用于任意代码库的快速内容搜索工具: - 基于正则表达式搜索文件内容 - 支持完整正则语法 - 用 include 参数过滤文件类型- 返回匹配路径与行号,按修改时间排序 - 用于查找含特定内容的文件 - 需统计匹配数时,直接用 Bash + rg,不用 grep- 开放式多轮搜索请用 Task 工具 |
| 工具 | 说明 |
|---|---|
| edit | 在文件中执行精确字符串替换: - 编辑前必须先用 Read读取文件,否则报错- 保留原缩进,不要包含行号前缀(如 1: )- 优先编辑现有文件,禁止新建文件(除非明确要求) - 无用户要求,不添加表情符号 - oldString不存在则替换失败- oldString匹配多处时需增加上下文使其唯一,或启用replaceAll- replaceAll用于全文件批量替换(如修改变量名) |
| 工具 | 说明 |
|---|---|
| write | 向本地文件系统写入文件: - 会覆盖已有文件 - 已有文件必须先 Read读取,否则失败- 优先编辑现有文件,非明确要求不新建文件 - 禁止主动创建 .md/README,仅按用户要求创建- 无用户明确要求,不写入表情符号 |
task—启动新代理自主处理复杂多步任务:
| 场景 | 说明 |
|---|---|
| 可用代理类型 | - general:通用代理,用于复杂调研、多步任务,可并行执行 - explore:代码库快速探索代理,用于按模式找文件、搜关键词、解答代码问题;需指定深度: quick/medium/very thorough |
| 使用规则 | - 使用Task工具时必须指定subagent_type- 适用场景:执行自定义斜杠命令 - 不适用场景:读取指定文件、搜索特定类、单文件内代码查找,改用 Read/Glob |
| 使用要点 | - 尽量并发启动多代理提升性能 - 代理结果对用户不可见,需自行精简汇总给用户 - 用 task_id可续接会话,新任务需给出详细指令- 明确告知代理是写代码还是仅检索,并给出验证方式 - 可按说明主动使用代理 |
| 工具 | 说明 |
|---|---|
| webfetch | 从指定 URL 获取内容: - 输入 URL 及可选格式,默认转为markdown,也支持 text/html- 用于获取并分析网页内容,只读不修改文件 - 有更合适的抓取工具时优先使用其他工具 - URL 必须完整有效,HTTP 自动升级为 HTTPS - 内容过大时会自动精简总结 |
todowrite—用于创建并管理编码任务清单,追踪进度、梳理复杂任务并向用户展示完成情况。
| 场景 | 说明 |
|---|---|
| 适用场景(主动使用) | - 需≥3 步的复杂任务 - 需规划 / 多操作的非简单任务 - 用户明确要求清单 - 用户给出多项任务 - 收到新指令时立即转为任务项 - 完成任务后标记并补充后续任务 - 开始新任务设为 in_progress,同一时间仅 1 个进行中 |
| 不适用场景 | - 仅单个简单任务 - 无管理价值的琐碎任务 - 3 步内可完成的任务 - 纯对话 / 信息咨询类需求 |
| 任务状态 | - pending:未开始- in_progress:进行中(限 1 个)- completed:已完成- cancelled:已取消 |
| 管理规则 | - 实时更新状态,完成立即标记 - 复杂任务拆分为具体可执行项 - 优先完成现有任务再开启新任务 |
| 工具 | 说明 |
|---|---|
| skill | - 加载专用技能,以获取领域专属的指令与工作流。 - 当识别到任务匹配下方任一可用技能时,使用此工具加载完整技能说明。 - 技能会将详细指令、工作流及捆绑资源(脚本、参考、模板)注入对话上下文。 - 工具输出将包含带有加载内容的 <skill_content name="..."> 块。- 以下技能针对特定任务提供专用指令集: - 当任务匹配下方任一可用技能时,调用此工具加载对应技能。 |

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)