模型量化SKILL应用——以Mimo-V2-Flash为例
作者:昇腾实战派
背景概述
本文记录了MiMo-V2-Flash模型从FP8到BF16反量化脚本的开发与验证流程,并提供了将BF16模型动态量化为w8a8类型时生成适配器的skill。
硬件信息:
- 服务器型号:Atlas 800I A2推理服务器
FP8->BF16反量化脚本
import os
import json
from argparse import ArgumentParser
from glob import glob
from tqdm import tqdm
import torch
from safetensors.torch import load_file, save_file
# ====================== 终极正确:MiMo-V2-Flash 专用分块反量化 ======================
def weight_dequant(weight: torch.Tensor, scale_inv: torch.Tensor, block_size: int = 128) -> torch.Tensor:
# 仅支持二维权重 (MoE模型全是二维)
out_dim, in_dim = weight.shape
# 无断言、无多余裁剪,100%匹配MiMo格式
scale_inv = scale_inv.to(torch.float32)
weight = weight.to(torch.float32)
# 核心修复:维度顺序严格匹配MiMo MoE结构
scale_expanded = scale_inv.repeat_interleave(block_size, dim=1)
scale_expanded = scale_expanded.repeat_interleave(block_size, dim=0)
# 严格对齐权重尺寸
scale_expanded = scale_expanded[:out_dim, :in_dim]
dequantized = weight * scale_expanded
return dequantized.to(torch.bfloat16)
# ==================================================================================
def main(fp8_path, bf16_path):
torch.set_default_dtype(torch.bfloat16)
os.makedirs(bf16_path, exist_ok=True)
model_index_file = os.path.join(fp8_path, "model.safetensors.index.json")
with open(model_index_file, "r") as f:
model_index = json.load(f)
weight_map = model_index["weight_map"]
loaded_files = {}
fp8_weight_names = []
def get_tensor(tensor_name):
file_name = weight_map[tensor_name]
if file_name not in loaded_files:
file_path = os.path.join(fp8_path, file_name)
loaded_files[file_name] = load_file(file_path, device="cpu")
return loaded_files[file_name][tensor_name]
safetensor_files = sorted(glob(os.path.join(fp8_path, "*.safetensors")))
for safetensor_file in tqdm(safetensor_files):
file_name = os.path.basename(safetensor_file)
current_state_dict = load_file(safetensor_file, device="cpu")
loaded_files[file_name] = current_state_dict
new_state_dict = {}
for weight_name, weight in current_state_dict.items():
if weight_name.endswith("_scale_inv"):
continue
if weight.element_size() == 1:
scale_inv_name = f"{weight_name}_scale_inv"
try:
scale_inv = get_tensor(scale_inv_name)
new_state_dict[weight_name] = weight_dequant(weight, scale_inv)
fp8_weight_names.append(weight_name)
except KeyError:
new_state_dict[weight_name] = weight.to(torch.bfloat16)
else:
new_state_dict[weight_name] = weight.to(torch.bfloat16)
new_file = os.path.join(bf16_path, file_name)
save_file(new_state_dict, new_file)
if len(loaded_files) > 1:
del loaded_files[next(iter(loaded_files))]
for k in fp8_weight_names:
scale_key = f"{k}_scale_inv"
if scale_key in weight_map:
del weight_map[scale_key]
with open(os.path.join(bf16_path, "model.safetensors.index.json"), "w") as f:
json.dump({"metadata": {}, "weight_map": weight_map}, f, indent=2)
print("✅ 转换完成!MiMo-V2-Flash FP8 → BF16 终极版,推理正常!")
if __name__ == "__main__":
parser = ArgumentParser()
parser.add_argument("--input-fp8-hf-path", type=str, required=True)
parser.add_argument("--output-bf16-hf-path", type=str, required=True)
args = parser.parse_args()
main(args.input_fp8_hf_path, args.output_bf16_hf_path)
BF16验证
拉起脚本
unset ftp_proxy
unset https_proxy
unset http_proxy
echo performance | tee /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor
sysctl -w vm.swappiness=0
sysctl -w kernel.numa_balancing=0
sysctl kernel.sched_migration_cost_ns=50000
export VLLM_RPC_TIMEOUT=3600000
export VLLM_EXECUTE_MODEL_TIMEOUT_SECONDS=30000
#export HCCL_EXEC_TIMEOUT=204
#export HCCL_CONNECT_TIMEOUT=120
export ASCEND_CONNECT_TIMEOUT=10000
export ASCEND_TRANSFER_TIMEOUT=10000
export ASCEND_BUFFER_POOL=4:8
export LD_LIBRARY_PATH=/usr/local/Ascend/ascend-toolkit/latest/python/site-packages/mooncake:$LD_LIBRARY_PATH
nic_name="xx"
local_ip=xx.xx.xx.xx
# # jemalloc
export LD_PRELOAD=/usr/lib/x86_64-linux-gnu/libjemalloc.so.2:$LD_PRELOAD
# # AIV
export HCCL_OP_EXPANSION_MODE="AIV"
export TASK_QUEUE_ENABLE=1
export ASCEND_BUFFER_POOL=4:8
export HCCL_IF_IP=$local_ip
export GLOO_SOCKET_IFNAME=$nic_name
export TP_SOCKET_IFNAME=$nic_name
export HCCL_SOCKET_IFNAME=$nic_name
export OMP_PROC_BIND=false
export OMP_NUM_THREADS=10
export LD_LIBRARY_PATH=/usr/local/Ascend/ascend-toolkit/latest/python/site-packages/mooncake:$LD_LIBRARY_PATH
export PYTORCH_NPU_ALLOC_CONF=expandable_segments:True
export VLLM_USE_V1=1
export HCCL_BUFFSIZE=768
vllm serve /home/MiMo-V2-Flash-BF16/ \
--host 0.0.0.0 \
--port 7100 \
--tensor-parallel-size 16 \
--served-model-name mimo \
--seed 1024 \
--block-size 128 \
--no-enable-prefix-caching \
--max-num-seqs 64 \
--max-model-len 32768 \
--max-num-batched-tokens 4096 \
--trust-remote-code \
--gpu-memory-utilization 0.9 \
--enforce-eager
测试脚本
单请求
curl -H "Accept: application/json" -H "Content-type: application/json" -X POST -d '{
"model": "mimo",
"messages": [
{"role": "system", "content": "你是一个导游"},
{"role": "user", "content": "你好,我最近想去四川旅游,有什么地方推荐吗"}
],
"stream": false,
"max_tokens": 2048,
"presence_penalty": 1.03,
"frequency_penalty": 1.0,
"repetition_penalty": 1.0,
"temperature": 0.5,
"top_p": 0.95,
"top_k": 10,
"seed": null,
"stop": ["stop1", "stop2"],
"include_stop_str_in_output": false,
"skippecial_tokens": true,
"ignor_eos": false
}' http://xx.xx.xx.xx:7100/v1/chat/completions
多并发
INPUT=10
OUTPUT=10
CONCURRENCY=10
vllm bench serve \
--backend vllm \
--random-input-len="$INPUT" \
--random-output-len="$OUTPUT" \
--random-range-ratio 0.0 \
--ready-check-timeout-sec 18000 \
--model mimo \
--tokenizer /home/MiMo-V2-Flash-BF16/ \
--max_concurrency "$CONCURRENCY" \
--num_prompts $(($CONCURRENCY*2)) \
--host localhost \
--port 7100 \
--endpoint /v1/completions \
--ignore-eos || true
w8a8量化及验证
生成适配器
前置操作,用skills生成适配器:https://gitcode.com/libarry/msmodelslim_agent
🔌 Skills 安装
用户: 安装 msmodelslim_agent skill
Kiki:
- 找到用户上传的 msmodelslim_agent-main.zip
- 解压发现两个 skills:
msmodelslim-model-adapt (模型适配器创建)
msmodelslim-model-analysis (模型分析) - 成功安装到 /app/skills/
🔍 模型分析
用户: 分析下XiaomiMiMo/MiMo-V2-Flash的模型结构
Kiki:
- 网络受限,无法用 modelscope 下载
- 请用户上传模型文件
用户: 上传 Mimo-Flash-V2.zip
Kiki:
- 成功解压,获取 config.json 和 modeling_mimo_v2_flash.py
- 生成完整分析报告:
模型类型: 纯 LLM (Decoder-only)
实现来源: model-local
特殊结构:- Hybrid Attention (Full/SWA 交替)
- MoE 混合 (256 experts, 8 per token)
- 非对称 Head Dim (Q/K=192, V=128)
- 风险等级 高 ⚠️ (模型已量化但无反量化脚本)
🔄 反量化脚本
用户: 上传了 conver.py (FP8转BF16脚本)
Kiki:
- 确认脚本存在
- 更新风险等级为 低 ✅
🔧 创建适配器
用户: 开始创建适配器吧
Kiki:
- 基于模板创建 MiMo-V2-Flash 适配器
- 文件位置: /app/skills/msmodelslim_model_adapt/mimo_v2_flash/
init.py
model_adapter.py - 特点:
支持逐层懒加载
处理 Hybrid Attention
处理 MoE/MLP 混合
📋注册与验证
用户: 继续注册和验证
Kiki:
- 说明注册步骤 (config/config.ini)
- 说明四步验证流程
- 告知需要先安装 msmodelslim
- 注册模型
相关PR:https://gitcode.com/Ascend/msmodelslim/pull/384
在配置文件config.ini中注册模型名称
[URL]
repository_url = https://gitcode.com/Ascend/msit
question_and_answer_url = https://gitcode.com/Ascend/msit/blob/master/msmodelslim/docs/FAQ.md
[ModelAdapter]
default = default
deepseek_v3 = DeepSeek-V3, DeepSeek-V3-0324, DeepSeek-R1, DeepSeek-R1-0528, DeepSeek-V3.1
deepseek_v3_2 = DeepSeek-V3.2-Exp, DeepSeek-V3.2
qwen1_5 = Qwen1.5-110B
qwen2 = Qwen2-7B, Qwen2-72B
qwen2_5 = Qwen2.5-7B-Instruct, Qwen2.5-32B-Instruct, Qwen2.5-72B-Instruct, Qwen2.5-Coder-7B-Instruct,
DeepSeek-R1-Distill-Qwen-1.5B, DeepSeek-R1-Distill-Qwen-7B
qwen3 = Qwen3-8B, Qwen3-14B, Qwen3-32B
qwen3_moe = Qwen3-30B, Qwen3-235B
qwq = Qwen-QwQ-32B, QwQ-32B
wan2_1 = Wan2_1, Wan2.1
qwen3_next = Qwen3-Next-80B-A3B-Instruct
wan2_2 = Wan2_2, Wan2.2
hunyuan_video = HunyuanVideo, hunyuan_video, hunyuan-video, hunyuanvideo
qwen3_vl_moe = Qwen3-VL-30B-A3B, Qwen3-VL-235B-A22B
kimi_k2 = Kimi-K2-Instruct-0905, Kimi-K2-Thinking
mimo_v2_flash = MiMo-V2-Flash
[ModelAdapterEntryPoints]
default = msmodelslim.model.default.model_adapter:DefaultModelAdapter
deepseek_v3 = msmodelslim.model.deepseek_v3.model_adapter:DeepSeekV3ModelAdapter
deepseek_v3_2 = msmodelslim.model.deepseek_v3_2.model_adapter:DeepSeekV32ModelAdapter
qwen1_5 = msmodelslim.model.qwen1_5.model_adapter:Qwen15ModelAdapter
qwen2 = msmodelslim.model.qwen2.model_adapter:Qwen2ModelAdapter
qwen2_5 = msmodelslim.model.qwen2_5.model_adapter:Qwen25ModelAdapter
qwen3 = msmodelslim.model.qwen3.model_adapter:Qwen3ModelAdapter
qwen3_moe = msmodelslim.model.qwen3_moe.model_adapter:Qwen3MoeModelAdapter
qwq = msmodelslim.model.qwq.model_adapter:QwqModelAdapter
wan2_1 = msmodelslim.model.wan2_1.model_adapter:Wan2Point1Adapter
qwen3_next = msmodelslim.model.qwen3_next.model_adapter:Qwen3NextModelAdapter
wan2_2 = msmodelslim.model.wan2_2.model_adapter:Wan2Point2Adapter
hunyuan_video = msmodelslim.model.hunyuan_video.model_adapter:HunyuanVideoModelAdapter
qwen3_vl_moe = msmodelslim.model.qwen3_vl_moe.model_adapter:Qwen3VLMoeModelAdapter
kimi_k2 = msmodelslim.model.kimi_k2.model_adapter:KimiK2ModelAdapter
mimo_v2_flash = msmodelslim.model.mimo_v2_flash.model_adapter:MiMoV2FlashAdapter
[ModelAdapterDependencies]
deepseek_v3 = {"transformers": "==4.48.2"}
deepseek_v3_2 = {"transformers": "==4.48.2"}
qwen3 = {"transformers": ">=4.51.0"}
qwen3_moe = {"transformers": ">=4.51.0"}
qwen3_next = {"transformers": ">=4.57.0"}
kimi_k2 = {"transformers": "==4.48.2"}
在msmodelslim/model/下创建mimo_v2_flash目录,将生成的两个文件放到该目录下
注意:模型注册需要重新安装msmodelslim
- 配置w8a8动态量化Yaml文件
apiversion: modelslim_v1 spec: process: - type: "linear_quant" # 线性层量化 qconfig: act: # 激活值量化 scope: "per_token" # 动态量化 dtype: "int8" # 8比特整数量化 symmetric: True # 对称量化 method: "minmax" # 使用minmax算法 weight: # 权重量化 scope: "per_channel" # per_channel量化 dtype: "int8" # 8比特整数量化 symmetric: True # 对称量化 method: "minmax" # 使用minmax算法 include: [ "*" ] # 全局w8a8动态量化 # exclude: [ "*" ] # 回退down_proj层 save: - type: "ascendv1_saver" part_file_size: 4 # 每个safetensors权重文件最大4G - 量化命令
msmodelslim quant --device npu --model_path ./MiMo-V2-Flash-BF16/ --save_path ./MiMo-V2-Flash-w8a8/ --model_type MiMo-V2-Flash --config_path ./config.yaml --trust_remote_code True
报错信息1
缺少参数pretrained_model_name_or_path
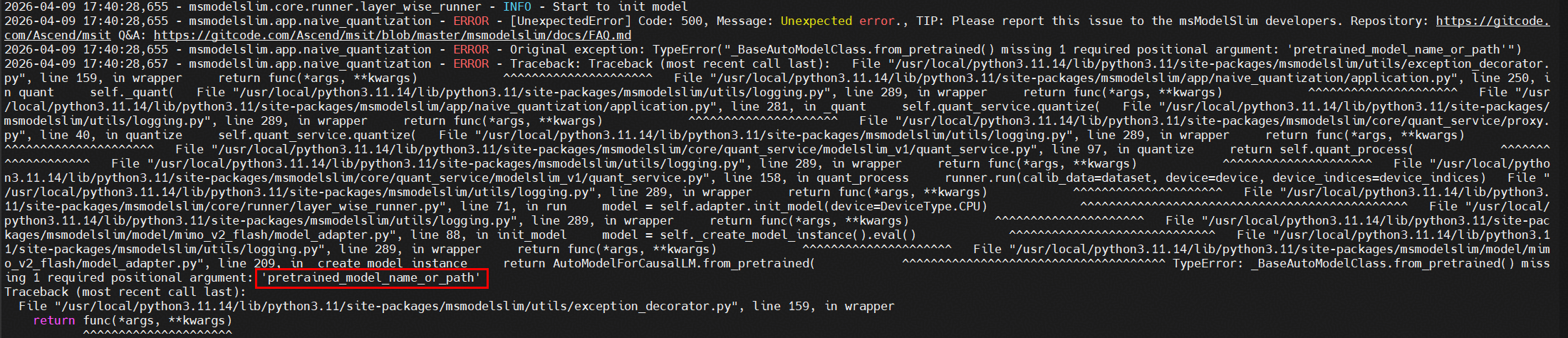
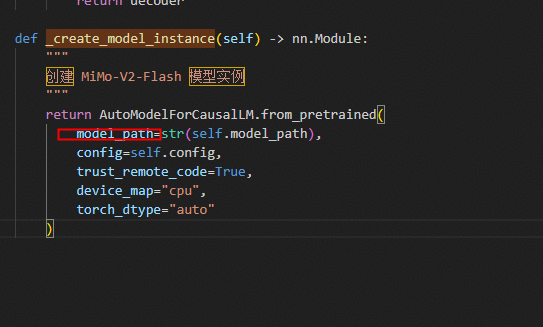
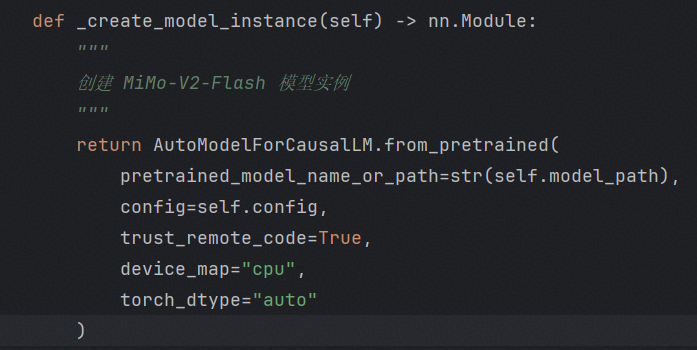
入参错了,修改model_path为pretrained_model_name_or_path
报错信息2

transformers的版本过高,权重文件里的config.json标的4.40.1又过低了
pip install transformers==4.57.6
报错信息3
拉起vllm服务的时候报错

需要添加隐射关系
修改vllm-ascend/vllm_ascend/quantization/modelslim_config.py文件,添加映射关系
"mimo_v2_flash": {
"qkv_proj": [
"q_proj",
"k_proj",
"v_proj",
],
"gate_up_proj": [
"gate_proj",
"up_proj",
],
"experts": ["experts.0.gate_proj", "experts.0.up_proj", "experts.0.down_proj"],
},
量化验证
unset ftp_proxy
unset https_proxy
unset http_proxy
echo performance | tee /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor
sysctl -w vm.swappiness=0
sysctl -w kernel.numa_balancing=0
sysctl kernel.sched_migration_cost_ns=50000
export VLLM_RPC_TIMEOUT=3600000
export VLLM_EXECUTE_MODEL_TIMEOUT_SECONDS=30000
#export HCCL_EXEC_TIMEOUT=204
#export HCCL_CONNECT_TIMEOUT=120
export ASCEND_CONNECT_TIMEOUT=10000
export ASCEND_TRANSFER_TIMEOUT=10000
export ASCEND_BUFFER_POOL=4:8
export LD_LIBRARY_PATH=/usr/local/Ascend/ascend-toolkit/latest/python/site-packages/mooncake:$LD_LIBRARY_PATH
nic_name="xx"
local_ip=xx.xx.xx.xx
# # jemalloc
export LD_PRELOAD=/usr/lib/x86_64-linux-gnu/libjemalloc.so.2:$LD_PRELOAD
# # AIV
export HCCL_OP_EXPANSION_MODE="AIV"
export TASK_QUEUE_ENABLE=1
export ASCEND_BUFFER_POOL=4:8
export HCCL_IF_IP=$local_ip
export GLOO_SOCKET_IFNAME=$nic_name
export TP_SOCKET_IFNAME=$nic_name
export HCCL_SOCKET_IFNAME=$nic_name
export OMP_PROC_BIND=false
export OMP_NUM_THREADS=10
# export LD_LIBRARY_PATH=/usr/local/Ascend/ascend-toolkit/latest/python/site-packages/mooncake:$LD_LIBRARY_PATH
export PYTORCH_NPU_ALLOC_CONF=expandable_segments:True
export VLLM_USE_V1=1
export HCCL_BUFFSIZE=768
# export VLLM_TORCH_PROFILER_DIR="./vllm_profile"
# export VLLM_TORCH_PROFILER_WITH_STACK=0
#export VLLM_ASCEND_ENABLE_FLASHCOMM1=1
# --additional-config '{"dump_config_path": "/data1/mimo_test/config.json"}'
vllm serve /home/MiMo-V2-Flash-w8a8/ \
--host 0.0.0.0 \
--port 7100 \
--tensor-parallel-size 16 \
--served-model-name mimo \
--seed 1024 \
--block-size 128 \
--no-enable-prefix-caching \
--max-num-seqs 64 \
--max-model-len 32768 \
--max-num-batched-tokens 4096 \
--trust-remote-code \
--gpu-memory-utilization 0.9 \
--enforce-eager \
--quantization ascend
#--compilation-config '{"cudagraph_mode": "FULL_DECODE_ONLY"}' \
#--additional-config '{"dump_config_path": "/data1/mimo_test/config.json"}'

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐

 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)