【Linux系统编程】Linux系统指令(3)———一文带你了解Linux的基础指令
在上一篇文章中,我们学习了Linux一些新的指令,同时也明白了,在Linux环境下,一切接文件,这就让我们在理解操作系统和硬件方面有了更加深刻的认识,今天,我们就再继续学习Linux指令,本篇文章将会对Linux指令进行收尾。在文章的开头,也要做个小小的铺垫:Linux中,一切皆文件!!!

🎈主页传送门:良木生香
🔥个人专栏:《C语言》 《数据结构-初阶》 《程序设计》《鼠鼠的C++学习之路》《Linux系统编程》
🌟人为善,福随未至,祸已远行;人为恶,祸虽未至,福已远离

前言:在上一篇文章中,我们学习了Linux一些新的指令,同时也明白了,在Linux环境下,一切接文件,这就让我们在理解操作系统和硬件方面有了更加深刻的认识,今天,我们就再继续学习Linux指令,本篇文章将会对Linux指令进行收尾。
在文章的开头,也要做个小小的铺垫:Linux中,一切皆文件!!!
一、nano记事本
在Linux系统下有一个东西的功能与我们windows记事本的功能相同,那就是nano,简单的使用方法如下:假设我现在有一个名为test2.txt的文本文件,那么,只用输入这个指令:
nano test2.txt就能进入nano编辑器了,效果如下:
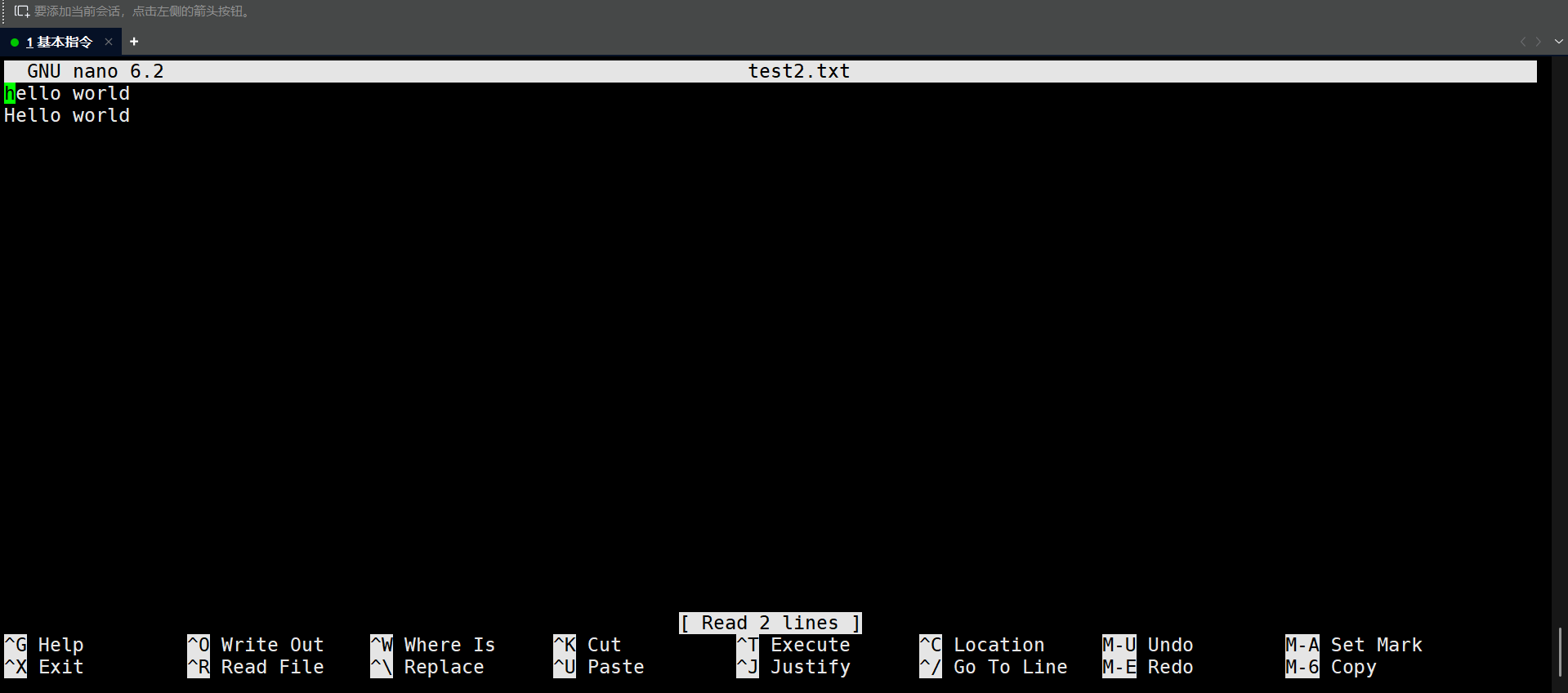
下面的指令都是CRTL+对应的字母进行操作。
当我对文章进行修改之后,只用按下CRTL+X,就会弹出这样的提示:
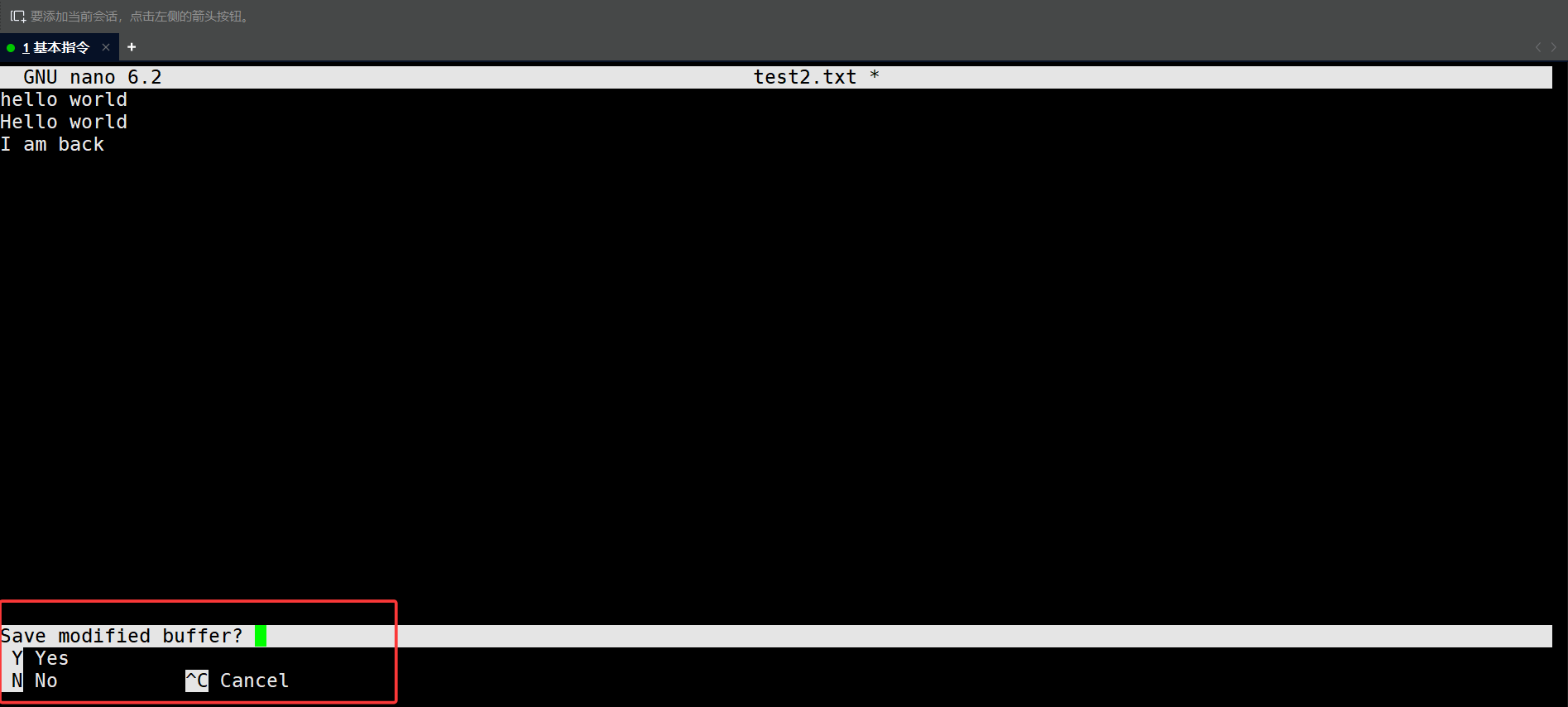
这时候只用按下y再按下回车即可自动保存退出。
二、cat指令
语法:cat 【选项】【文件】
功能:查看目标文件的内容
常用选项:
- -b 对非空输出行进行编号
- -n 对输出的所有行进行编号
- -s 不输出多行空行
首先,我们可以通过这个指令对文档进行快速编辑:
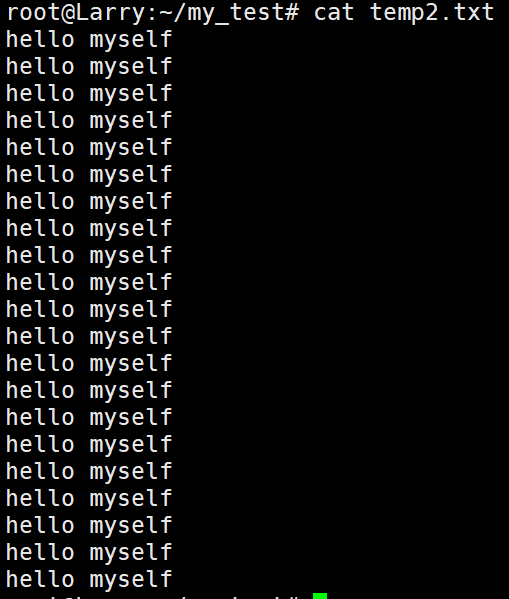
cnt=0; while [ $cnt -le 20 ]; do echo "hello myself"; let cnt++; done > temp2.txt这样子就能直接再temp.txt文档中创建20行"hello myself"的内容了。
直接输出的话是这样子的:
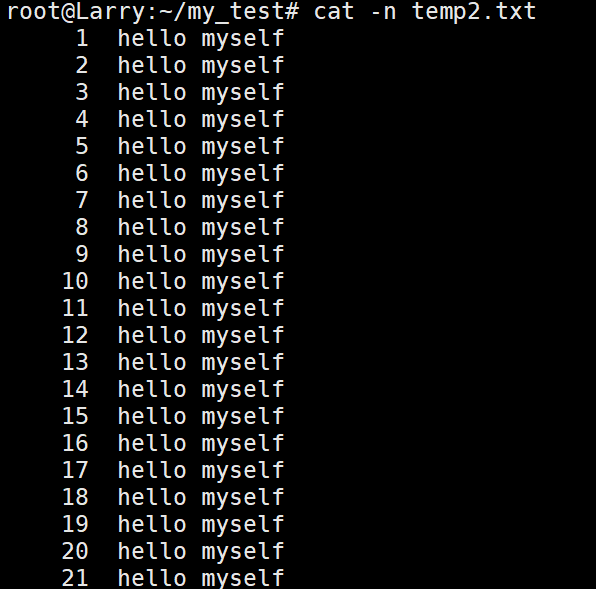
但是如果我们加上cat指令特有的选项的话,就会变成这样:
-n:
-b:(这里为了突出非空行编号的作用,就删掉了一些作为空行)
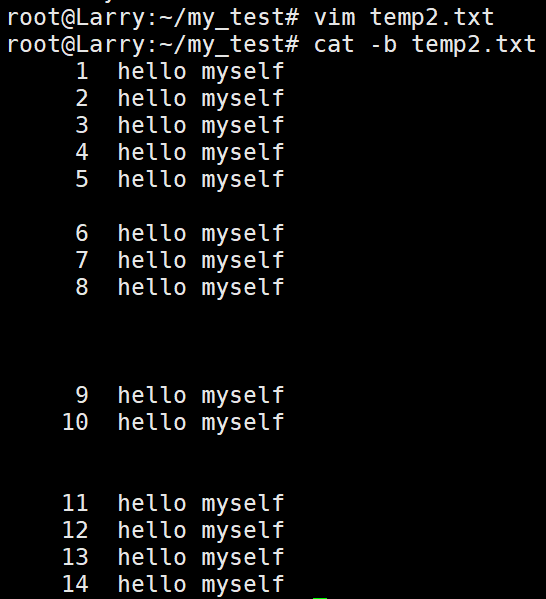
-s:当空行是多行连续时,不会多行同时输出:
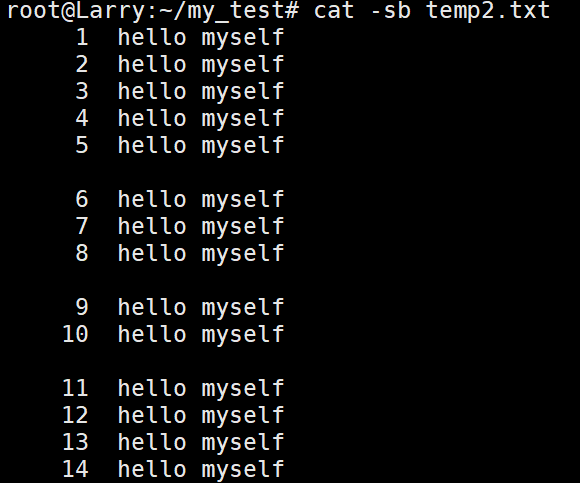
当组合使用时,就能达到不输出多行连续空行,也能标出行号。
如果我想将文档倒着输出呢?我又该怎么做?很简单!使用tac命令。
顾名思义:cat是正着输出,tac就是倒着输出,因为tac是由cat反转而来。
使用tac结果如下:
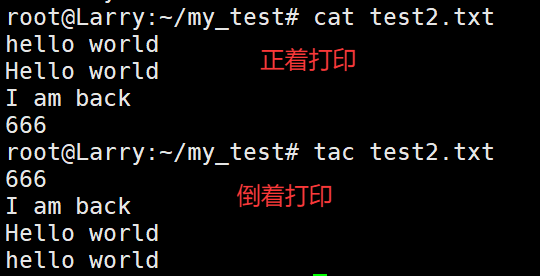
当然,cat使用的场景仅限于查看小文件,小代码,并不适合查看几千行的文档。
想要查看大文档时,就要使用到下面这两个指令了。
三、more && less指令
more和less这两个指令都是用来查看大文档或者代码的,因为他们的功能相比于cat再大文档中会更加强大。
我们先通过这个指令创建一个比较大的文档,差不多有2000行左右的文档。
cnt=0; while [ $cnt -le 2000 ]; do echo "hello $cnt"; let cnt++; done > temp.txt在文档中同时将每一行的数字都标注了,通过这个temp文档,我们就能非常清楚的明白more和less的用法差别了~~
3.1、more
语法:more 【选项】
功能:more命令,功能类似cat
常用选项:
- -n指定输出行数
- q退出more
在temp文档中,使用more是这样的:
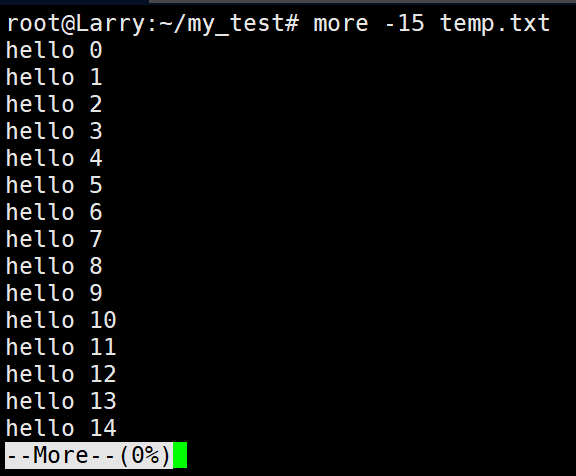
这就是more指令的结果,more是不能向前翻懂内容进行查看的,只能向后查看。但是为什么现在我们使用键盘上的PGUPh和PGDN也能让more实现向前翻查看内容?这是因为现在的终端和Linux都支持more向前翻的功能,但实际上不是more指令本身的作用,而是终端在做优化。
3.2、less
语法:less 【参数】文件
功能:less的功能与more类似,但是功能比more更加好用,可以向前向后翻文档查找内容
选项:
- -i 忽略搜索时的大小写
- -N 显示每行的行号
- /字符串 :向下搜索"字符串"的功能
- ?字符串:向上搜索"字符串"的功能
- n:重复前一个搜索(与 / 或 ?有关)
- N:反向重复前一个搜索。(与 / 或者 ?有关)
- q:退出
less在temp.txtx中的效果是这样的:
也可以向前翻:
查看行数就加上-N :
以上就是less和more的基本用法了,下面我们来看看另一组指令:
四、head && tail 指令
这两个指令一看到名字大概就应该知道是怎么作用的吧,下面我们一个一个来分析:
4.1、head
语法:head 【参数】 【文件】
功能:head用来显示档案的开头到标准输出中,默认的head命令是输出相应文件的开头10行。
选项:-n<行数> :显示的行数
使用示例如下:
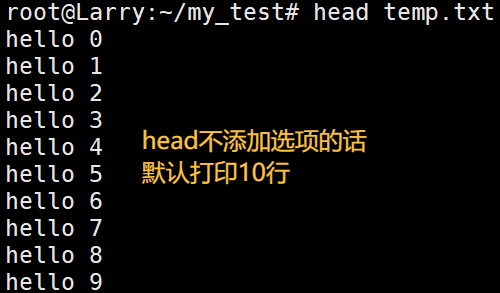
显示特定行数:
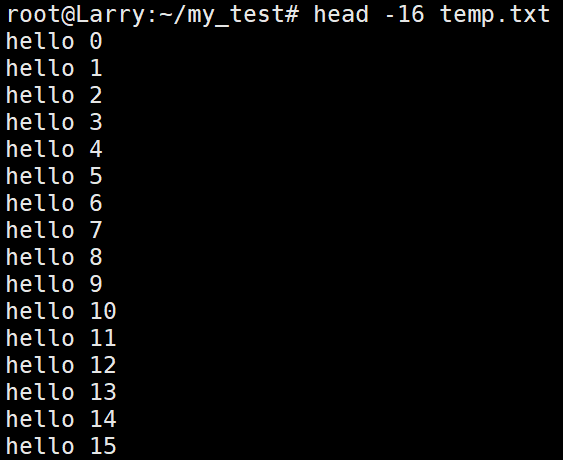
4.2、tail
与head 相反,tail指令是将档案的结尾输出到标准输出中,默认也是显示10行。
使用实例如下:
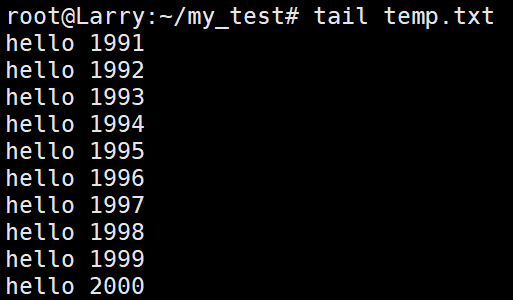
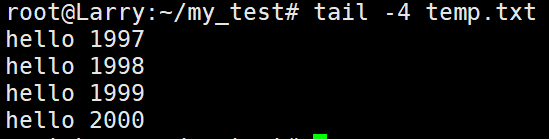
加上选项之后:
那么截至目前,在Linux中有关查看文档的指令我们学习了cat、more、less以及head、tail.
假设我现在只想查看文件的中间特定行数的内容呢?我该怎么做?根据之前所学习的知识,我们知道,可以发挥重定向的作用(假设查看701-710行的数据):
head -711 temp.txt > temp3.txt先将temp.txt中前700行的数据输出重定向到temp3.txt.再使用tail查看temp3.txt的结尾内容:
tail temp3.txt那么,这样一来,两条指令的运行结果如下图所示:
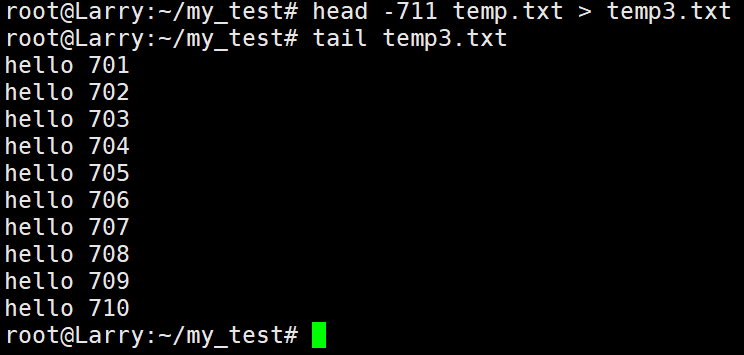
这样做确实能够达成目的,但是过程有些过于繁琐了,并且在文档内容量比较大的情况下,使用输出重定向会随时不少性能,这里就要介绍一种新的方法了:
五、管道
管道,顾名思义,就是用来传输东西的。不论是生活中的下水管道,燃油管道,天然气管道,这些管道都具有一些共同的特性:1.都有入口和出口 2.其中运输的都是有价值的东西。
那管道和我们现在要处理的问题有什么关系呢?,请看下面的指令:
head -711 temp.txt | tail指令的运行结果如下:
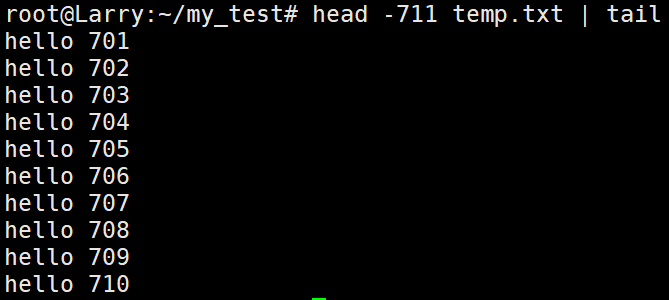
为什么这个指令就能实现刚才要两条指令才能实现的功能?就是因为这个指令用了管道的功能,原理如下:head -711 temp.txt这前半条指令将temp.txt中的前711行提取了出来,再通过 “ | ” 这个符号使得这711行数据进入了内存中,此时就调用了管道的特性,可以理解为暂存,然后才通过tail指令将这711行的末尾输出出来。
具体示意图如下:

这样就就可以不用再额外创建文件了。
管道可以级联,像这样:
head -801 temp.txt | tail -20 | tac | less这一段指令的作用如下;将temp.txt中的第781-800行数据倒序输出同时用less查看,运行结果如下:
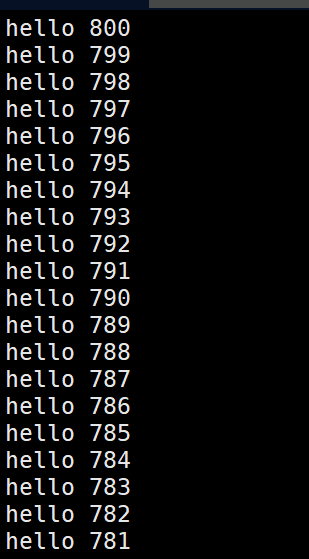
因为行数比较少,所以less的功能不能完全的发挥出来。在管道级联时,所产生的文件为管道文件,且为匿名文件。但只这里我么你可以跟通过自己创建一个命名管道文件来查看文件类型:
mkfifo fifo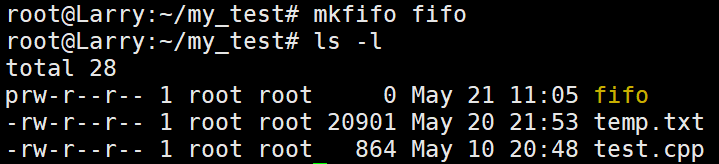
可以看到,文件fifo的文件属性开头是p开头,对用的是pipe这个英文单词,意为管道。在上一篇文章中我们演示了双终端的通信效果,那么管道也同样可以放在双终端上:

在一个终端中将字符串写入fifo文件,再在另一个终端中将fifo读出来,这样就完成了管道应用与重定向相结合的功能了。
小贴士:cat fifo 与 cat < fifo是不相同的,具体为何不相同的会在进程中讲解~~~
六、date指令
功能:格式化输出时间
想要输出现在的时间,具体到时分秒,指令如下:
date +%Y/%m/%d_%H:%M:%S在显示时分秒时,单词首字母全部大写,年月日只有年大写。
其中的格式,每个占位符之间的符号自己定,不一定是/。
6.1、时间戳
时间戳指的是从1970年1月1日零点零分零秒开始计时到现在的时间。
在上面那个查看时间的指令后面再加上 -d @时间戳,就能得到某个时间戳的显示时间:
date +%Y/%m/%d_%H:%M:%S -d @1779363749像这样,就能可视化出这个时间戳的时间,运行结果为:

如果是这个指令的话:
date +%Y/%m/%d_%H:%M:%S -d @0
也就是说,这里应该是显示出1970年1月1日零点零分零秒的时间,但是为什么这个结果显示的是早上八点呢?这是因为,这里显示的时间与时区有关,我们中国所在的是东八区,所以在时间戳为0时,我们中国处于早上八点。
时间戳有社么作用?作用可多了,什么银行啊,铁路调度啊,金融交易啊等场景都会用到时间戳。这时候就有人要问了,时间不是以整形的形式存放的吗,如果时间戳真到了那一天溢出整形了,该怎么办?不用慌,到时候自会出现修正它的人。
为什么时间戳在计算机中非常重要?一方面主要是程序的日志。当某公司的大型程序运行到一半的时候出现了某个BUG需要及时修复,那么这时候就要调用带有时间戳的日志程序,看看到底是那个时间点出现了错误,是什么错误,方便后续的工作处理;另一方面就是截止恶意访问。放某个服务器在某次用户访问中挂掉了,就可以通过查询访问的ip和时间戳,从而对恶意访问的用户进行拦截。
Linux的程序日志一般存放在/var/log/下。
七、cal指令
cal命令可以⽤来显⽰公历(阳历)⽇历。公历是现在国际通⽤的历法,⼜称格列历,通称阳历。“阳历”⼜名“太阳历”,系以地球绕⾏太阳⼀周为⼀年,为西⽅各国所通⽤,故⼜名“西历”。
语法:cal 【参数】【年份】
功能:用于查了看日历等信息,如果只有一个参数,则表示年份(1-9999),如果有两个参数,则表示月份和年份。
常用选项:
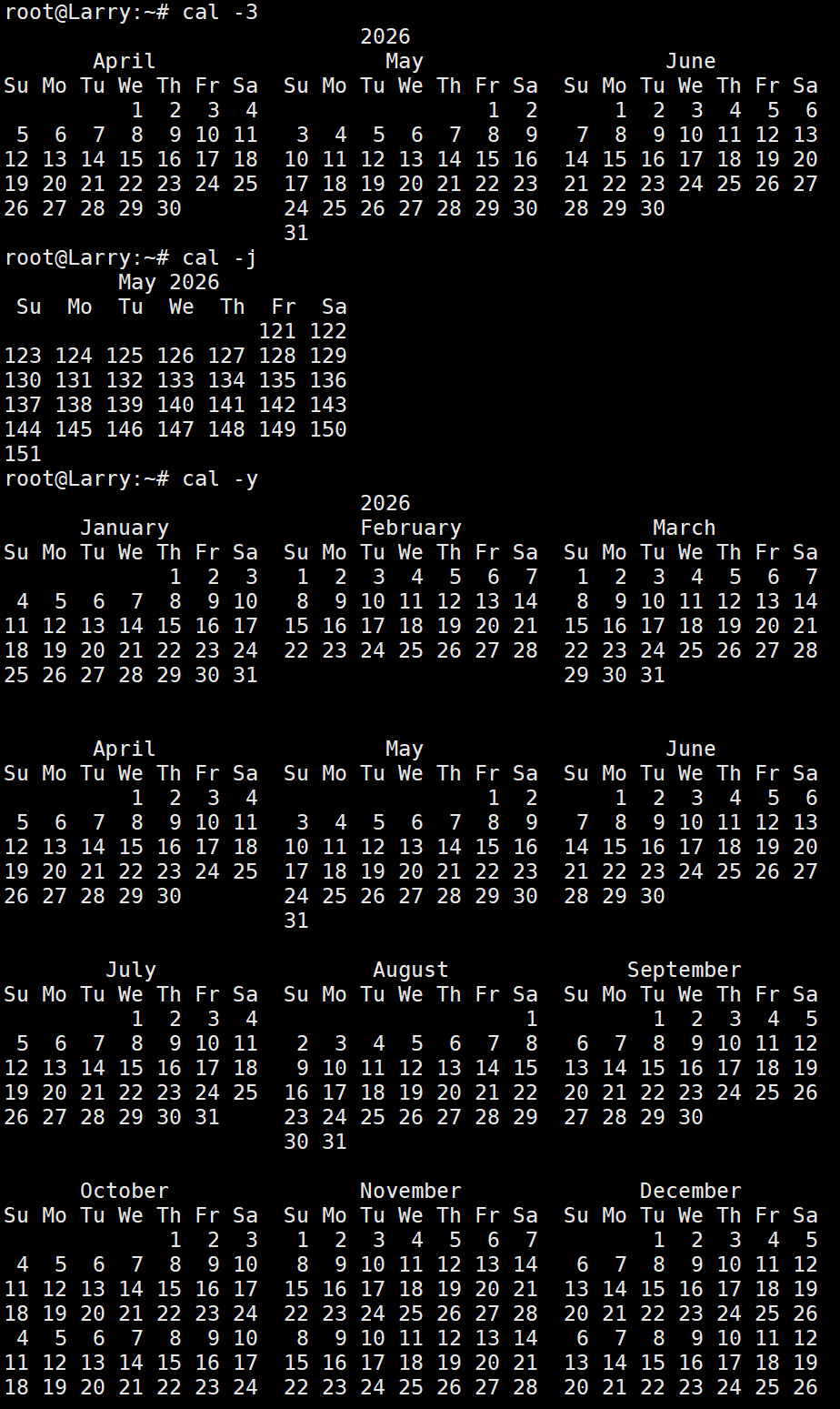
- -3:显示系统的前一个月,当前月以及下一个月的日历。
- -j:显示在当年中的第几天。
- -y:显示当前年份的日历。
具体使用如下:
八、find指令
语法:find pathname -options
功能:用于在文件树中查找文案金,并且做出相应的处理。
常用选项:
- -name 按照文件名查找文件
- 其他选项需要再查,本命令比较复杂
那么现阶段我们只用掌握在根目录下查找文件即可,像这样:
总结:现阶段关于查找我们学习了find(全局查找),which(特定指令的路径),whereis(找到二进制文件或者安装包等),以及alias(重命名)。
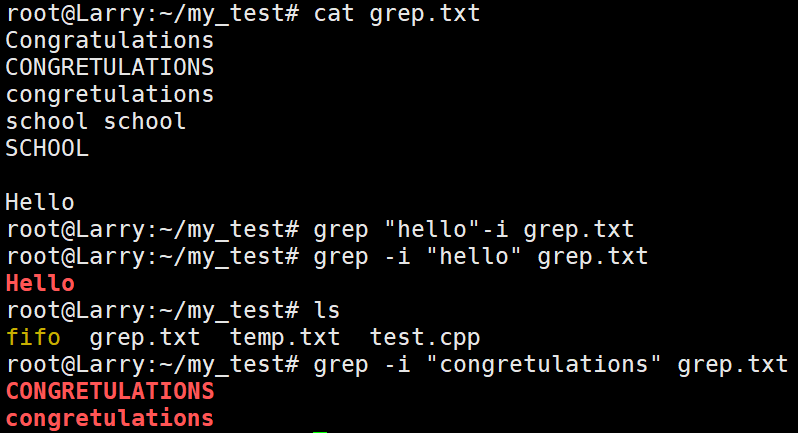
九、grep指令
语法:grep 【选项】 想要搜索的字符串 在哪个文件搜索
功能:在文件中搜索字符串,将找到的行打印出来。
常用选项:
- -i:忽略大小写的不同,所有大小写是为相同。
- -n:顺便输出行号
- -v:反向选择,即显示出没有 “想要搜索的字符串” 内容的那一行。
具体使用方法如下:
十、top指令
top指令就像任务管理器,我们windows也有任务管理器:
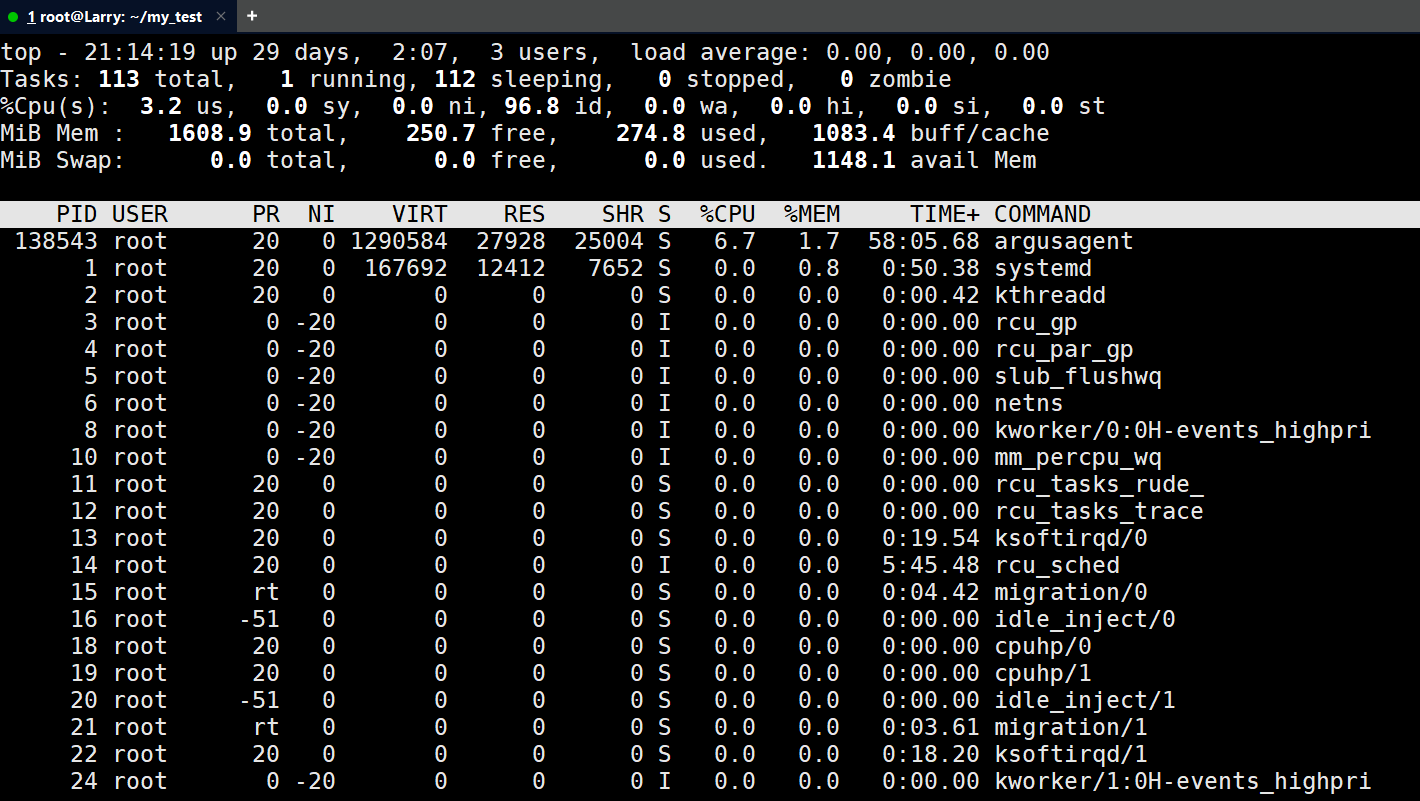
top指令常用的选项如下:
-d:刷新时间的间隔
-n:刷新的次数
像这样:
top -n 3 -d 3
意思就是,每隔三秒书刷新一次资源管理器的数据,刷新三次。如果直接使用top就会直接显示资源管理器,需要手动退出:
十一、zip && unzip指令
在平时发送文件时候,我们会发现以文件的形式是无法发送的,需要以压缩包的格式发送才行,这是为什么?平时说的打包和压缩又是什么一回事?
打包是将多个文件变成一个文件,是多变一,而压缩则是将文件的大小变小,是大变小。
为何要打包和压缩?因为在网络领域中,因网络传输的某些因素,导致丢失文件,效率低下的问题时常发生,假设我要发送十个文件,但是对方可能只收到了8个文件,这就很尴尬了。所以我们都要求用压缩包的方式发送。
压缩算法有很多种,用什么算法取决于压缩格式。
zip:
zip 压缩文件.zip 压缩文件/目录
unzip:
unzip 压缩文件.zip -d /指定路径
将压缩包解压至指定路径。
想要直观的看到压缩指令的使用,我们就要吸纳创建大批文件,可以使用下面的命令:
touch test{1..100}.txt意思是创建100个test.txt文件,并且在每个文件上都标注编号。
进入_zip路径后就能看到有100个test.txt文件了。现在使用这个命令对他们进行打包压缩,单独压缩文件不用递归,但是压缩文件夹就要使用递归了。
zip -r _zip.zip _zip这时候回退上一级,就能看到_zip.zip压缩包了:
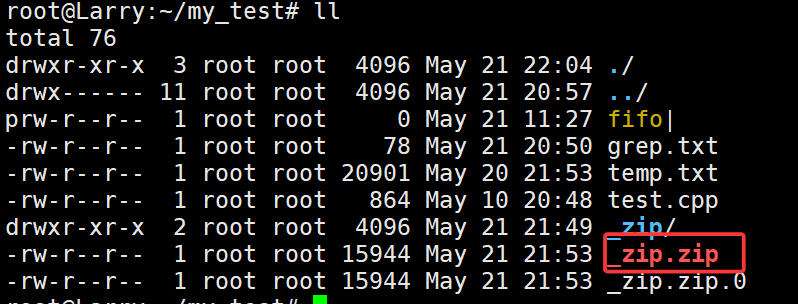
我们可以通过sz指令将_zip.zip压缩包发送到我们的windows系统上:
sz _zip.zip
当然,想从windows上发送文件到Linux下也是可以的,可以给直接拖拽,或者是 rz -E,就会将文件发送到Linux当前的路径下了。
安装sz和rz的命令如下:
ubentu:apt install lrzsz
CentOS: yum install lrzsz
那么以上就是本次所有的内容了
文章是自己写的哈,有什么描述不对的、不恰当的地方,恳请大佬指正,看到后会第一时间修改,感谢您的阅读~~~~
博主笔记:







openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐

 16
16 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)