利用网络算力使用 Unsloth 实现llama大模型的微调部署调用
大模型微调是让通用大模型适应特定任务或领域的重要技术。传统全参数微调需要昂贵的 GPU 资源,而 Unsloth 通过 QLoRA 4bit 量化技术,将微调的显存需求降低 50% 以上,同时保持训练速度提升 2-5 倍。本文详细介绍在 AutoDL 云服务器上使用 Unsloth 进行大模型微调的完整操作流程,包括环境配置、模型下载、微调训练、权重合并以及 API 部署。
目录
前言
大模型微调是让通用大模型适应特定任务或领域的重要技术。传统全参数微调需要昂贵的 GPU 资源,而 Unsloth 通过 QLoRA 4bit 量化技术,将微调的显存需求降低 50% 以上,同时保持训练速度提升 2-5 倍。本文详细介绍在 AutoDL 云服务器上使用 Unsloth 进行大模型微调的完整操作流程,包括环境配置、模型下载、微调训练、权重合并以及 API 部署。
1 创建 GPU 实例
本步骤说明如何在 AutoDL 平台创建用于深度学习的 GPU 服务器。

在 AutoDL 控制台创建实例,配置 vGPU 32G,通过 JupyterLab 进入操作页面。选择合适的 GPU 型号和内存配置,确保能够支持后续的模型加载和微调训练操作。
2 安装 Unsloth
本步骤说明如何在服务器上安装 Unsloth 微调框架及其依赖。打开JupyterLab,然后打开一个终端,通过命令安装unsloth。

2.1 初始化 conda 环境
conda init
conda init 命令用于初始化 conda 环境,使其在终端中可用。执行后需要关闭当前终端并重新打开,才能进入 conda 的 base 环境。
2.2 安装 Unsloth 及依赖
pip install unsloth
pip install addict
pip install unsloth 用于安装 Unsloth 核心库,这是进行高效微调的基础。pip install addict 用于安装 addict 依赖库,Unsloth 内部需要用到。
3 下载基座大模型
本步骤说明如何下载用于微调的基础大模型文件。
3.1 创建目录并安装 ModelScope
cd autodl-tmp/
mkdir unsloth
cd unsloth/
pip install modelscope
这组命令用于创建工作目录并安装 ModelScope 下载工具。cd autodl-tmp/ 进入存储目录,mkdir unsloth 创建项目文件夹,pip install modelscope 安装 ModelScope 库以支持模型下载。
3.2 下载 Llama-3.2-1B-Instruct 模型
python -c "from modelscope import snapshot_download; snapshot_download( 'unsloth/Llama-3.2-1B-Instruct', local_dir='./llama-3.2-1b-Instruct', revision='master')"
这条命令使用 ModelScope 的 snapshot_download 函数下载 Llama-3.2-1B-Instruct 模型到本地目录 ./llama-3.2-1b-Instruct。这是 Meta 公司的开源指令遵循模型,适合进行微调实验。
3.3 安装 libcurl 依赖
apt install libcurl4-openssl-dev -y
安装 libcurl 开发库,为后续 llama.cpp 编译提供必要的依赖。-y 参数表示自动确认安装提示。
4 模型加载
本步骤说明如何在 Jupyter 笔记本环境中正确加载 Unsloth 和模型。
4.1 配置 Jupyter 内核(可选)
python -m ipykernel install --user --name base --display-name "Python (base)"
如果 Jupyter 无法识别 unsloth,在终端运行此命令。python -m ipykernel install 用于将当前 Python 环境注册为 Jupyter 可用的内核,--name base 指定内核名称,--display-name 设置在 Jupyter 中显示的名称。
4.2 打开JupyterLab
打开JupyterLab后,在笔记本窗口,进行大模型的微调训练。
5 执行微调训练
本步骤说明如何执行完整的模型微调流程,包括环境配置、模型加载、LoRA 设置、数据处理、训练执行和权重保存。这是整个流程的核心部分。
5.1 环境变量配置
import os
os.environ.pop('HF_HUB_LOCAL_ADDR', None)
os.environ.pop('HUGGINGFACE_HUB_LOCAL_ADDR', None)
os.environ['HF_HUB_DISABLE_IPV6'] = '1'
os.environ['TRANSFORMERS_OFFLINE'] = '1'
os.environ['UNSLOTH_DISABLE_STATS'] = '1'
这组环境变量配置用于优化 Unsloth 的网络和存储行为。HF_HUB_DISABLE_IPV6='1' 禁用 IPv6 避免连接问题,TRANSFORMERS_OFFLINE='1' 开启离线模式,UNSLOTH_DISABLE_STATS='1' 禁用联网统计避免超时。
5.2 加载模型和分词器
from unsloth import FastLanguageModel
import torch
max_seq_length = 2048
dtype = None
load_in_4bit = True
model_name = "/root/autodl-tmp/unsloth/llama-3.2-1b-Instruct"
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = model_name,
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
)
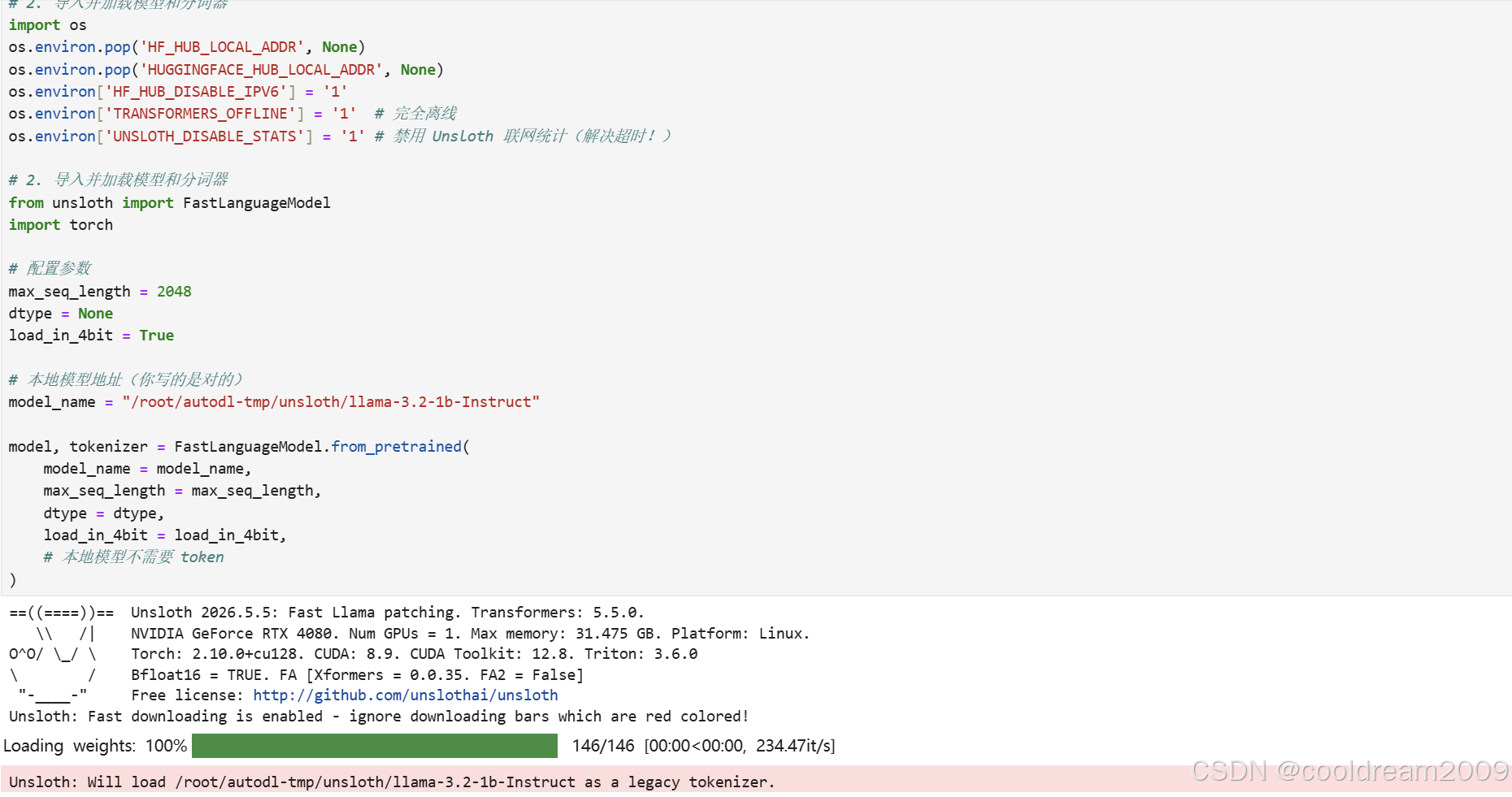
此代码使用 FastLanguageModel 加载本地模型。max_seq_length=2048 设置最大序列长度,load_in_4bit=True 启用 QLoRA 4bit 量化,大幅降低显存占用。FastLanguageModel 是 Unsloth 提供的优化模型加载类。
5.3 添加 LoRA 适配器
model = FastLanguageModel.get_peft_model(
model,
r = 16,
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",],
lora_alpha = 16,
lora_dropout = 0,
bias = "none",
use_gradient_checkpointing = "unsloth",
random_state = 3407,
use_rslora = False,
loftq_config = None,
)
此代码为模型添加 LoRA 适配器。r=16 设置 LoRA 秩,target_modules 指定应用 LoRA 的层(包括注意力层和 FFN 层),use_gradient_checkpointing="unsloth" 启用 Unsloth 优化的梯度检查点以节省显存。
5.4 准备数据(Alpaca 格式)
alpaca_prompt = """Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
{}
### Input:
{}
### Response:
{}"""
def formatting_prompts_func(examples):
instructions = examples["instruction"]
inputs = examples["input"]
outputs = examples["output"]
texts = []
for instruction, input, output in zip(instructions, inputs, outputs):
text = alpaca_prompt.format(instruction, input, output)
texts.append(text)
return { "text" : texts, }
此代码定义了 Alpaca 格式的数据处理函数。alpaca_prompt 是经典的指令微调 prompt 模板,包含 Instruction(指令)、Input(输入)、Response(回答)三部分。formatting_prompts_func 函数将数据集的每个样本格式化为统一的文本格式。
5.5 加载数据集
import os
os.environ["HF_HUB_OFFLINE"] = "1"
os.environ["HF_DATASETS_OFFLINE"] = "1"
from modelscope import MsDataset
dataset = MsDataset.load('AI-ModelScope/alpaca-cleaned', split='train')
dataset = dataset.map(formatting_prompts_func, batched=True)
print(dataset[0]["text"])

此代码从 ModelScope 加载 alpaca-cleaned 数据集。MsDataset.load 使用 ModelScope 而非 HuggingFace 加载数据,dataset.map 批量应用前面定义的格式化函数,将数据转换为模型可训练的格式。
5.6 配置并启动训练
from trl import SFTTrainer
from transformers import TrainingArguments
trainer = SFTTrainer(
model = model,
tokenizer = tokenizer,
train_dataset = dataset,
dataset_text_field = "text",
max_seq_length = max_seq_length,
args = TrainingArguments(
per_device_train_batch_size = 4,
gradient_accumulation_steps = 4,
warmup_steps = 10,
max_steps = 120,
learning_rate = 2e-4,
fp16 = not torch.cuda.is_bf16_supported(),
bf16 = torch.cuda.is_bf16_supported(),
logging_steps = 1,
optim = "adamw_8bit",
weight_decay = 0.01,
lr_scheduler_type = "linear",
seed = 3407,
output_dir = "outputs",
report_to = "none",
),
)
trainer.train()
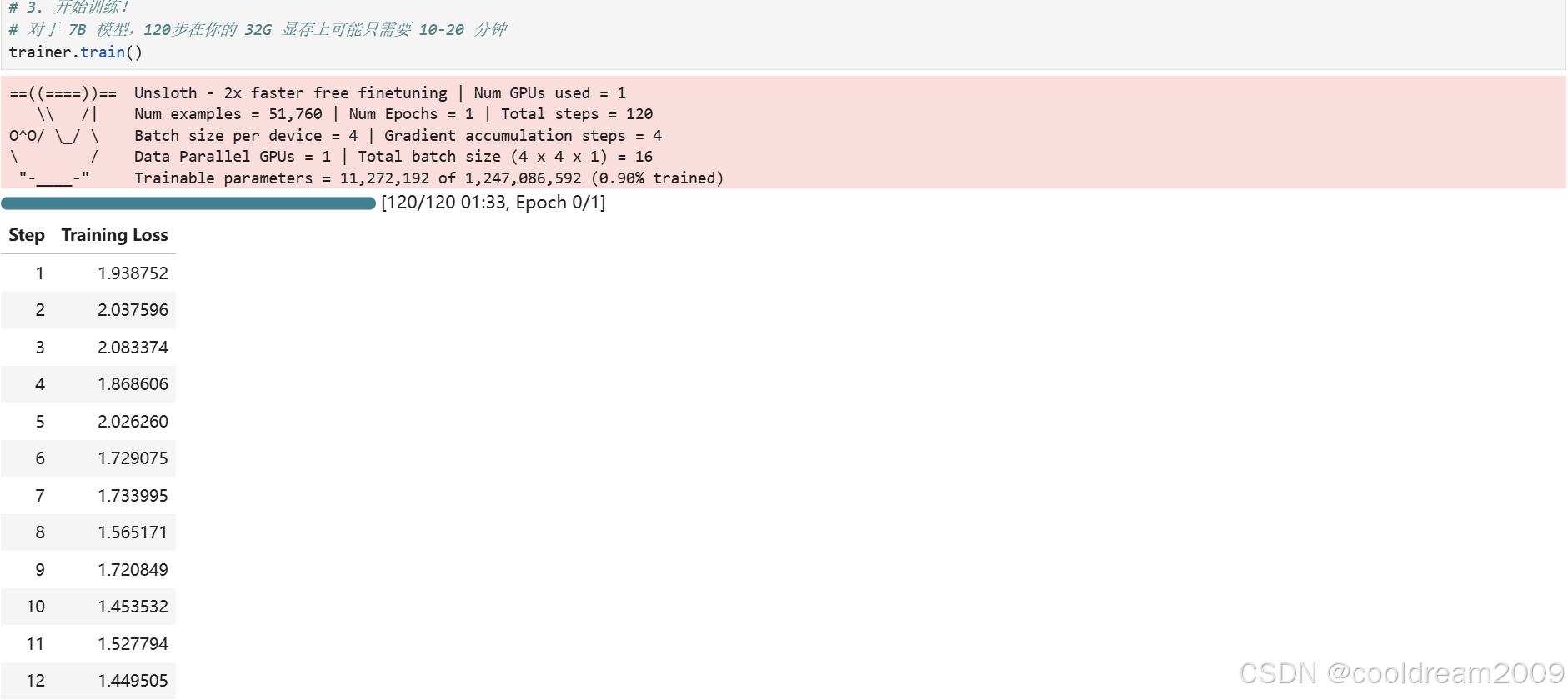
此代码配置并启动模型训练。SFTTrainer 是 HuggingFace TRL 库提供的监督微调训练器。关键参数:per_device_train_batch_size=4 每 GPU 批次大小,gradient_accumulation_steps=4 梯度累积,max_steps=120 训练步数,optim="adamw_8bit" 使用 8bit AdamW 优化器节省显存,fp16/bf16 根据 GPU 支持情况自动选择精度。
5.7 测试微调效果(可选)
from transformers import TextStreamer
instruction = "Tell me about Unsloth's key features for fine-tuning."
input_text = ""
text_to_generate = alpaca_prompt.format(instruction, input_text, "")
inputs = tokenizer([text_to_generate], return_tensors="pt").to("cuda")
streamer = TextStreamer(tokenizer)
_ = model.generate(**inputs, streamer=streamer, max_new_tokens=256, temperature=0.7)
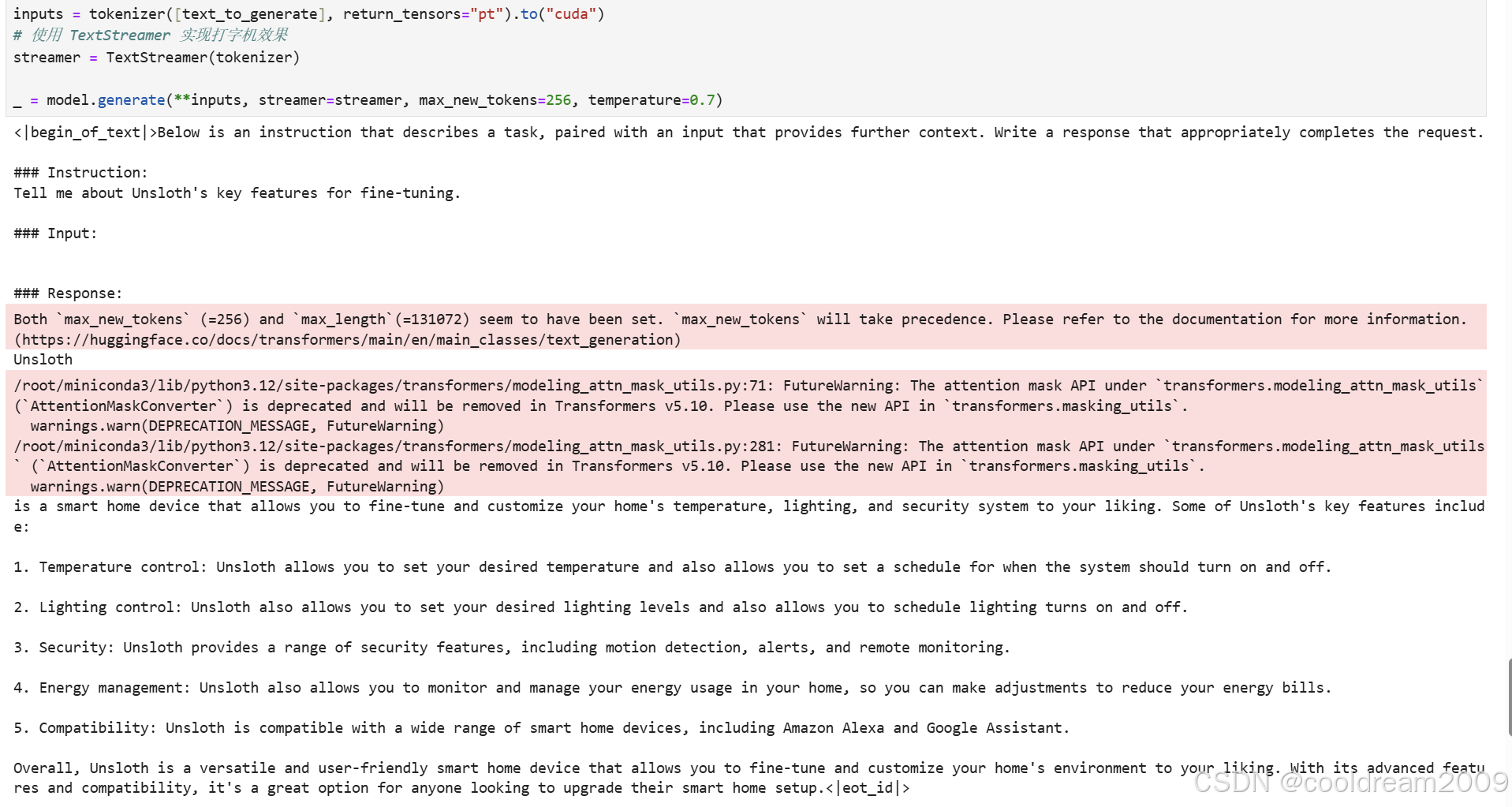
此代码用于测试微调后模型的生成效果。使用与训练时相同的 prompt 模板格式化输入,TextStreamer 实现流式输出显示,model.generate 调用模型生成回复,temperature=0.7 控制随机性。
5.8 保存 LoRA 适配器
import os
os.chdir("/root/autodl-tmp/unsloth")
print(os.getcwd())
model.save_pretrained("lora_model")
tokenizer.save_pretrained("lora_model")
此代码保存微调得到的 LoRA 适配器权重。os.chdir 切换到工作目录,model.save_pretrained 保存 LoRA 权重,tokenizer.save_pretrained 保存分词器配置。LoRA 权重文件很小,便于存储和分享。
5.9 合并 LoRA 到基础模型
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import PeftModel
import torch
BASE_MODEL = "./llama-3.2-1b-Instruct"
LORA_DIR = "./lora_model"
SAVE_DIR = "./merged_model_final"
print("加载基座模型...")
base_model = AutoModelForCausalLM.from_pretrained(
BASE_MODEL,
torch_dtype=torch.bfloat16,
device_map="auto",
trust_remote_code=True,
)
tokenizer = AutoTokenizer.from_pretrained(BASE_MODEL, trust_remote_code=True)
print(f"加载 LoRA 适配器: {LORA_DIR}")
peft_model = PeftModel.from_pretrained(base_model, LORA_DIR)
print("合并权重...")
merged_model = peft_model.merge_and_unload()
print(f"保存完整模型到: {SAVE_DIR}")
os.makedirs(SAVE_DIR, exist_ok=True)
merged_model.save_pretrained(SAVE_DIR)
tokenizer.save_pretrained(SAVE_DIR)
print("✅ 合并完成!")
print("\n保存的文件:")
for file in os.listdir(SAVE_DIR):
size = os.path.getsize(os.path.join(SAVE_DIR, file)) / (1024**2)
if size > 1:
print(f" ✓ {file:30} {size:.2f} MB")
else:
print(f" ✓ {file:30} {size:.2f} KB")

此代码将 LoRA 适配器合并到基础模型中,生成完整的微调模型。PeftModel.from_pretrained 加载 LoRA 权重,merge_and_unload() 执行权重合并,save_pretrained 保存为标准 HuggingFace 格式模型。
6 利用 llama.cpp 从合并后的模型生成 GGUF 文件
6.1 编译 llama.cpp 工具
# 克隆仓库(浅克隆节省时间和空间)
git clone --depth 1 https://github.com/ggml-org/llama.cpp
# 编译 quantize 工具(禁用 CUDA 和 CURL 等不需要的功能)
cmake -B build -DBUILD_SHARED_LIBS=OFF -DGGML_CUDA=OFF -DLLAMA_CURL=OFF
cmake --build build --config Release -j --target llama-quantize
6.2 转换微调后的模型为 GGUF
第一步:转换 HuggingFace 格式 → F16 GGUF
python ~/.unsloth/llama.cpp/convert_hf_to_gguf.py \
./merged_model_final \
--outfile ./my_model_F16.gguf \
--outtype f16
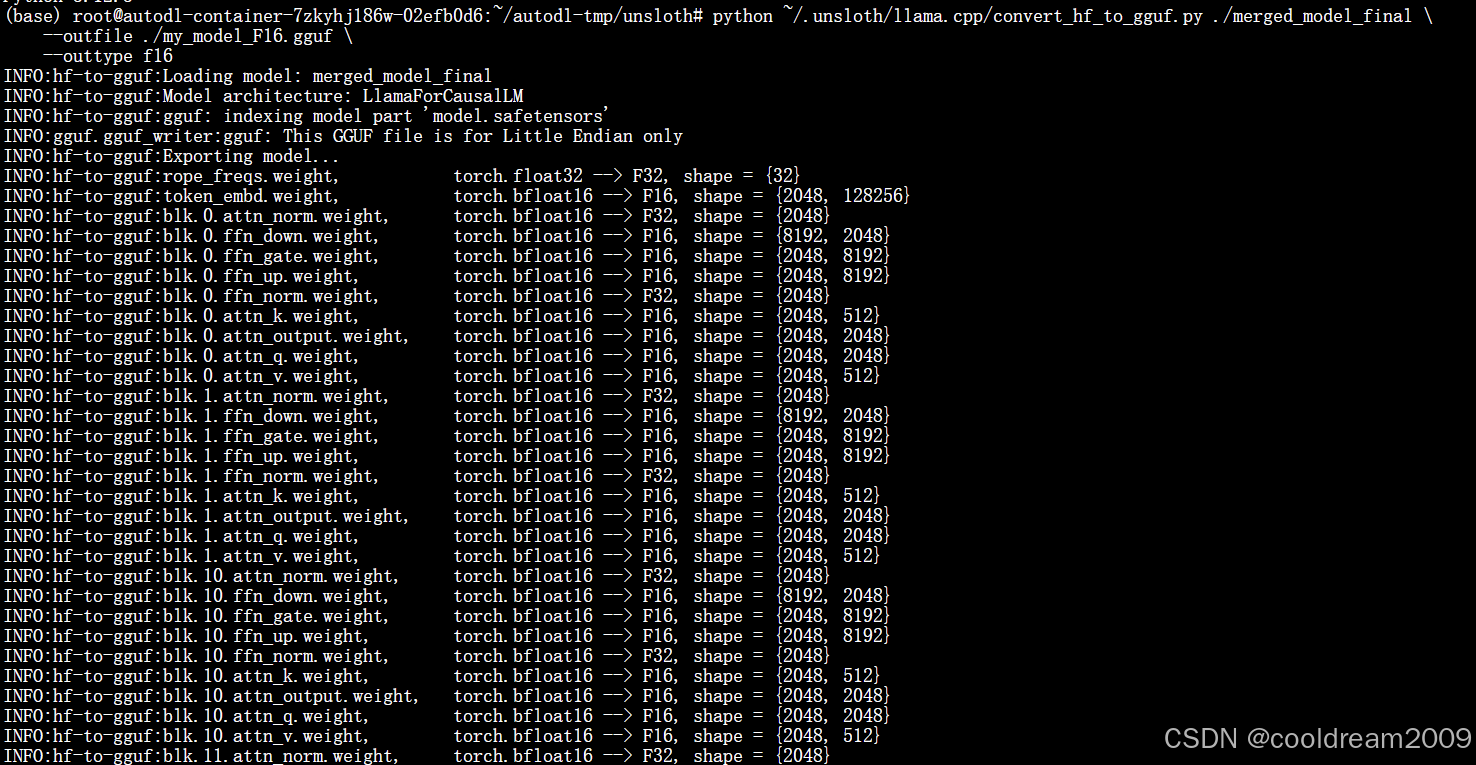
- 输入:微调后的 HF 格式模型(
./merged_model_final) - 输出:FP16 精度的 GGUF 文件(
my_model_F16.gguf)
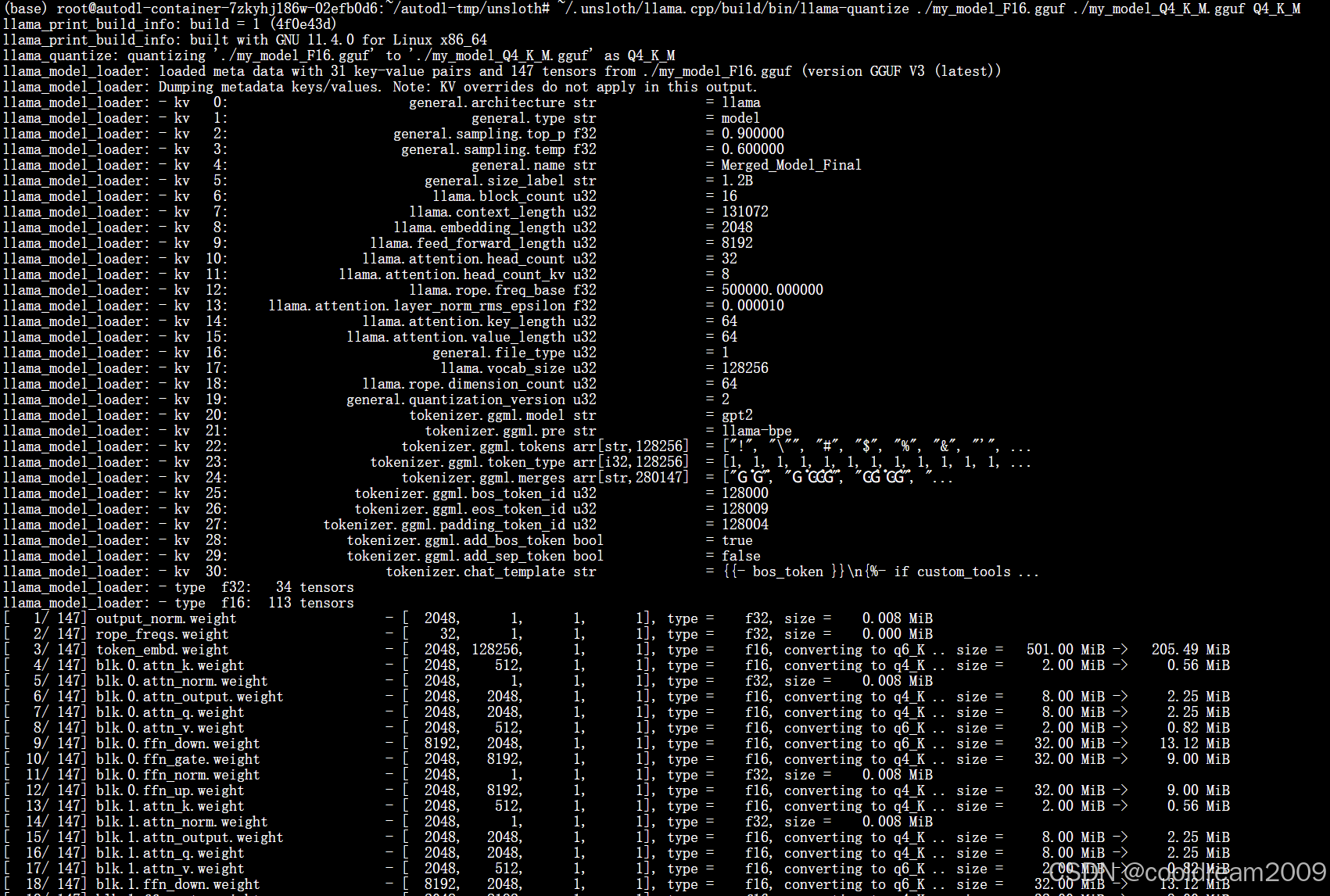
第二步:量化 F16 → Q4_K_M
~/.unsloth/llama.cpp/build/bin/llama-quantize \
./my_model_F16.gguf \
./my_model_Q4_K_M.gguf \
Q4_K_M
-
量化类型
Q4_K_M:4-bit 量化(K-quant 方法,M 表示中等大小) -
将模型从 16-bit 压缩到 ~4-bit,显著减小文件大小
-
F16:保留原始精度,文件较大
-
Q4_K_M:平衡质量和大小,通常性能下降很小但体积减少约 75%
-
最终得到可直接用
llama.cpp/llama-cli加载的量化模型
7 部署启动 API 服务器
本步骤说明如何将微调后的模型部署为 API 服务,使其可以通过网络接口调用。
启动 llama-server
# 如果你是导出了 GGUF 文件
~/.unsloth/llama.cpp/build/bin/llama-server \
--model ./my_model_Q4_K_M.gguf \
--port 6006 \
--ctx-size 4096
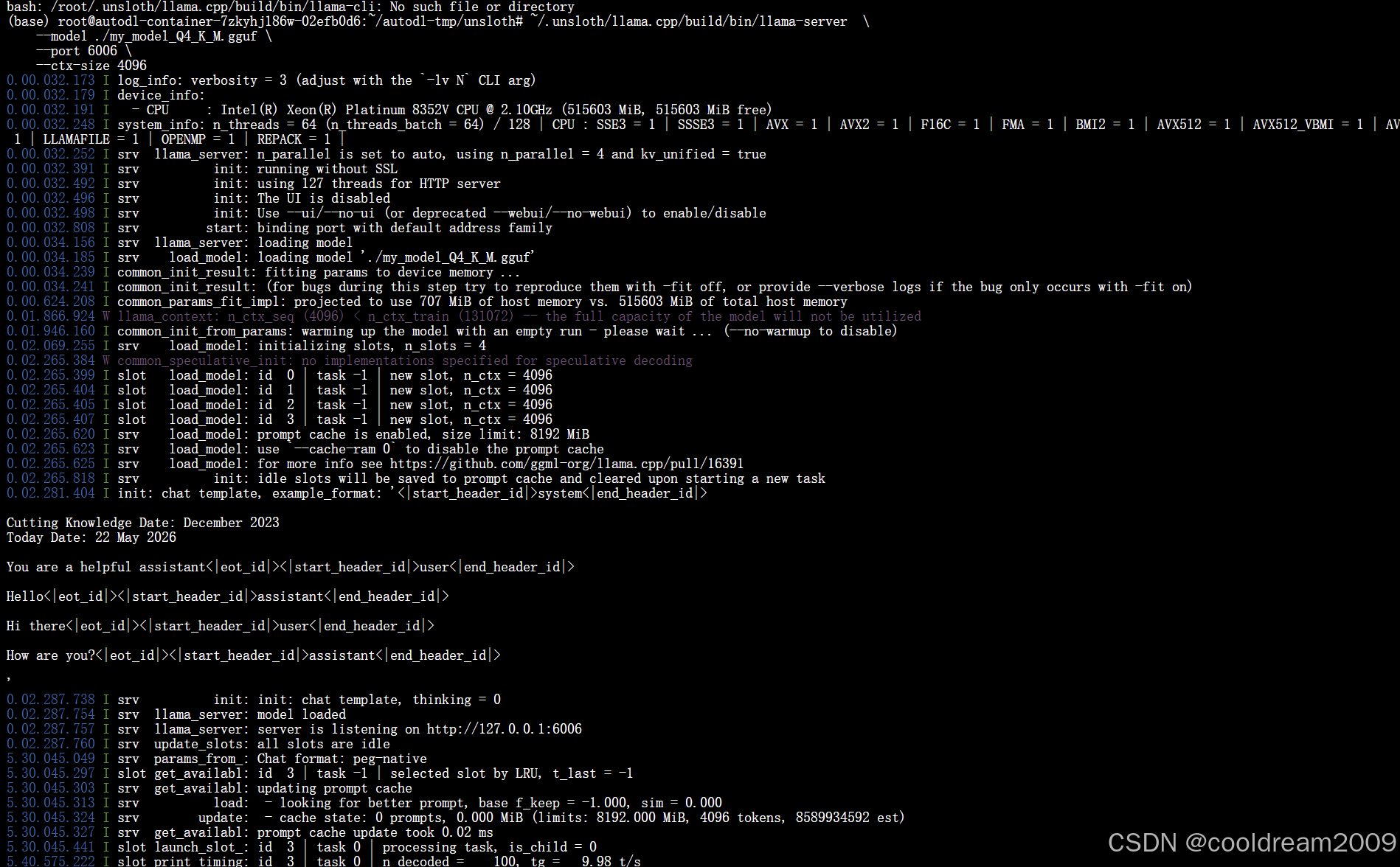
此命令启动 llama-server API 服务。--model 指定模型文件路径,--port 6006 设置服务端口,--ctx-size 4096 设置上下文窗口大小。启动后服务会监听指定端口,提供与 OpenAI API 兼容的接口。
8 调用 API
本步骤说明如何使用 Python 代码通过 OpenAI SDK 调用部署的模型 API。使用 Python 代码调用
from openai import OpenAI
# 1. 配置客户端
client = OpenAI(
base_url="https://u1013314-186w-02efb0d6.westd.seetacloud.com:8443",
api_key="sk-no-key-required",
)
# 2. 发送请求
response = client.chat.completions.create(
model="default",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{
"role": "user",
"content": "What are the benefits of fine-tuning a small language model?",
},
],
temperature=0.7,
stream=False,
)
# 3. 打印回复
print(response.choices[0].message.content)
此代码使用 OpenAI SDK 调用本地部署的模型 API。OpenAI 客户端配置 base_url 为服务地址,chat.completions.create 发送对话请求,messages 包含系统提示和用户问题,temperature 控制生成随机性,stream=False 表示不使用流式输出。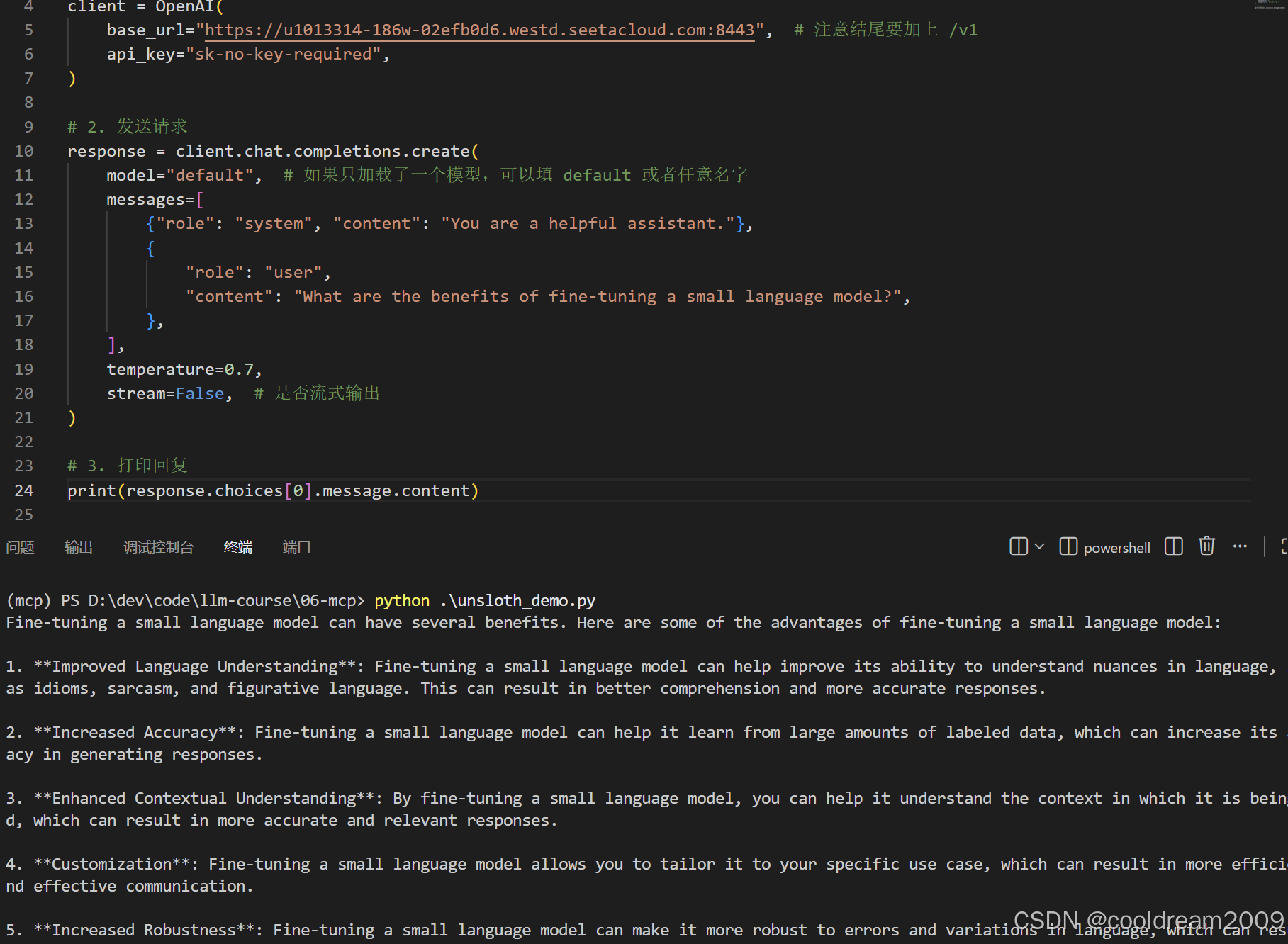
结语
本文档完整介绍了在 AutoDL 上使用 Unsloth 进行大模型微调的整个流程。通过 QLoRA 4bit 量化技术,即使使用消费级 GPU 也能完成大模型的微调训练。关键步骤包括:创建 GPU 实例、安装 Unsloth、下载基座模型、执行微调训练、保存合并权重,最后通过 llama-server 部署为 API 服务。微调后的模型可以更好地适应特定任务或领域需求,相比全参数微调大幅降低了资源门槛。

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐

 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)