基于 AutoDL 云算力使用 LLaMA Factory 微调大模型及 API 服务搭建完整记录
目录
前言
大模型微调是让通用大模型适应特定任务或领域的重要手段。LLaMA Factory 是目前最流行的开源微调框架之一,提供了 WebUI 可视化界面和命令行两种使用方式,大大降低了大模型微调的门槛。本文详细介绍在 AutoDL 云服务器上使用 LLaMA Factory 进行大模型微调的完整操作流程,包括环境安装、WebUI 使用、模型训练、微调后对话、模型导出以及 API 部署等环节。通过本文,您将掌握使用 LLaMA Factory 对 Qwen 等系列模型进行 LoRA 微调的核心方法,并能够独立完成从训练到部署的全流程操作。
1 环境准备
1.1 申请 AutoDL GPU 实例
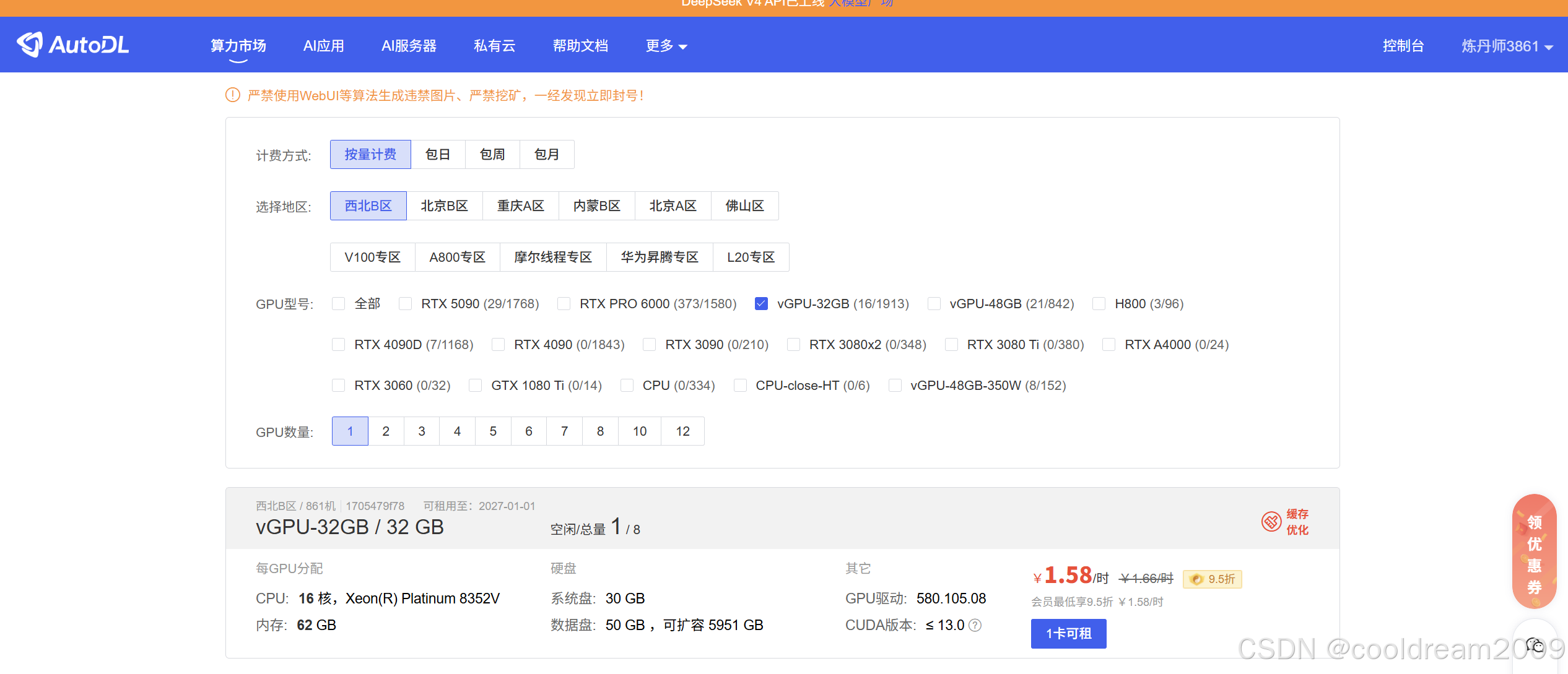
在 AutoDL 控制台申请 GPU 实例,配置建议如下:
| 配置项 | 推荐选择 |
|---|---|
| 显卡型号 | RTX 4090 或 A100 |
| 显存 | 24GB 及以上 |
| 镜像 | 选择支持 Python 3.10+ 的 PyTorch 镜像 |
| 数据盘 | 至少 100GB 用于存储模型和数据集 |
实例创建完成后,通过 JupyterLab 进入操作页面。JupyterLab 是一个基于 Web 的交互式开发环境,支持在浏览器中编写和运行代码,非常适合进行机器学习实验。
1.2 配置网络加速
为了加快 GitHub 访问和依赖下载速度,先配置网络代理环境:
source /etc/network_turbo
这条命令会加载网络加速配置,解决海外资源访问速度慢的问题。如果没有配置网络加速,Git 克隆和 pip 安装可能会非常缓慢甚至超时失败。
1.3 克隆 LLaMA Factory 仓库
cd autodl-tmp
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
使用 git clone --depth 1 可以只克隆最新的提交记录,大幅减少克隆时间和磁盘占用。LLaMA Factory 仓库包含完整的微调框架代码、WebUI 界面、预置数据集以及训练脚本。
1.4 创建 Python 环境并安装依赖
conda init
关闭当前终端并打开一个新终端,使 conda 环境生效。然后创建独立的 Python 环境并激活:
conda create -n lf python=3.12
conda activate lf
cd ~/autodl-tmp/LLaMA-Factory
pip install -e ".[torch,metrics]"
这里创建了名为 lf 的 conda 环境,Python 版本为 3.12。pip install -e ".[torch,metrics]" 是以可编辑模式安装 LLaMA Factory 及其 torch 和 metrics 相关依赖。安装的依赖包约 10GB 左右,网络状况较差时需要 30-40 分钟,网络良好时约 10 分钟左右,请耐心等待安装完成。
2 LLaMA Factory 配置与启动
2.1 修改 WebUI 端口配置
LLaMA Factory 默认使用 7860 端口,为避免与其他服务冲突,修改为 6006。使用 vim 编辑器打开端口配置文件:
vim ~/autodl-tmp/LLaMA-Factory/src/llamafactory/webui/interface.py
找到以下内容:
demo.launch(server_name="0.0.0.0", server_port=7860, share=share, max_threads=200)
修改为:
demo.launch(server_name="0.0.0.0", server_port=6006, share=share, max_threads=200)
将端口号从 7860 改为 6006,这样可以避免与其他服务端口冲突,也便于记忆和访问。
2.2 验证安装
安装完成后,运行以下命令验证 LLaMA Factory 是否正确安装:
llamafactory-cli version

如果安装成功,会显示版本号信息。如果提示命令未找到,请检查环境是否正确激活以及安装是否完成。
2.3 启动 WebUI 服务
GRADIO_SERVER_PORT=6006 llamafactory-cli webui --server-name 0.0.0.0
启动成功后会显示类似以下信息:
Visit http://ip:port for Web UI, e.g., http://127.0.0.1:6006
* Running on local URL: http://0.0.0.0:6006
* To create a public link, set `share=True` in `launch()`.
此时在浏览器访问 http://<您的服务器IP>:6006 即可打开 LLaMA Factory 的 WebUI 界面。使用 --server-name 0.0.0.0 参数可以确保服务可以从外部访问。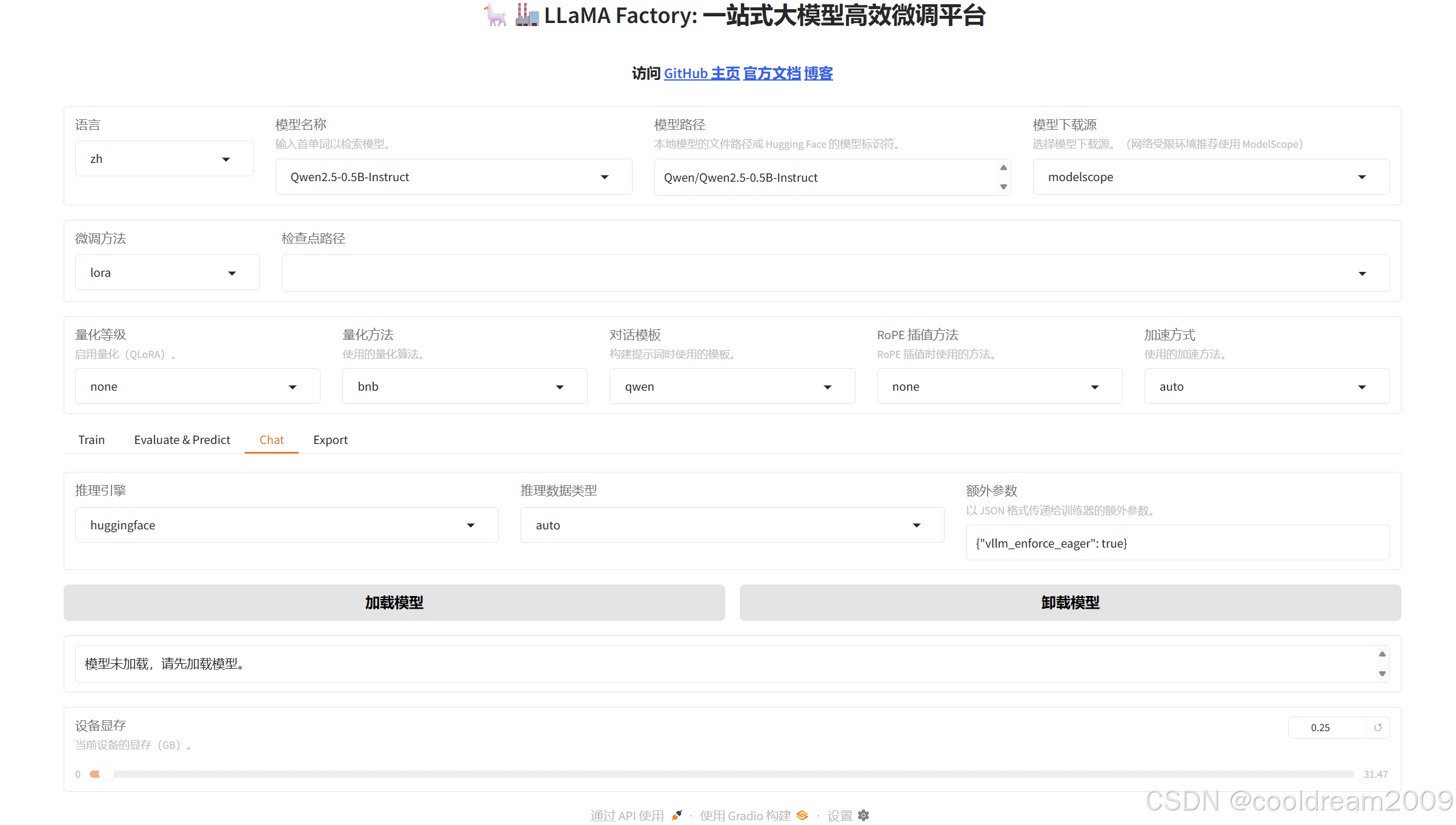
3 WebUI 界面介绍
LLaMA Factory 的 WebUI 界面功能丰富,分为以下五个主要功能模块:
| 功能模块 | 说明 |
|---|---|
| 通用设置 | 模型选择、数据集配置、日志设置等基础参数 |
| 微调训练 | 选择数据集、设置训练参数、启动训练任务 |
| 模型评估 | 对训练好的模型进行性能评估 |
| 在线推理 | 在 WebUI 中直接测试模型效果 |
| 模型导出 | 将训练好的模型导出到指定目录 |
通用设置区域主要用于配置模型来源、加载方式以及日志记录策略。微调训练是核心模块,在这里选择数据集、配置训练超参数并启动训练任务。模型评估模块集成了多种评估指标,可以对微调后的模型进行量化评估。在线推理模块允许用户直接在界面上与模型对话,实时体验模型效果。模型导出模块则将训练成果持久化,导出为标准格式便于后续部署使用。
对于初学者,建议先熟悉界面布局,了解各模块的功能位置,再进行实际操作。WebUI 的优势在于所有操作都有可视化反馈,降低了操作失误的风险。
4 加载基座模型进行对话
4.1 选择模型
在模型选择区域,填写模型名称:
Qwen/Qwen2.5-0.5B-Instruct
Qwen2.5-0.5B-Instruct 是阿里云通义千问系列的小型指令微调模型,拥有 5 亿参数,对硬件要求相对较低,适合在消费级 GPU 上进行微调实验。Instruct 后缀表示该模型已经过指令微调,具备更好的对话和问答能力。
4.2 测试基座模型对话
切换到在线推理模块,加载模型后,输入以下测试问题:
比较以下两位著名人物,使用特征列表并以句子形式提供输出。人物1:阿尔伯特·爱因斯坦\n人物2:斯蒂芬·霍金\n特征:智力、教育、对世界的影响
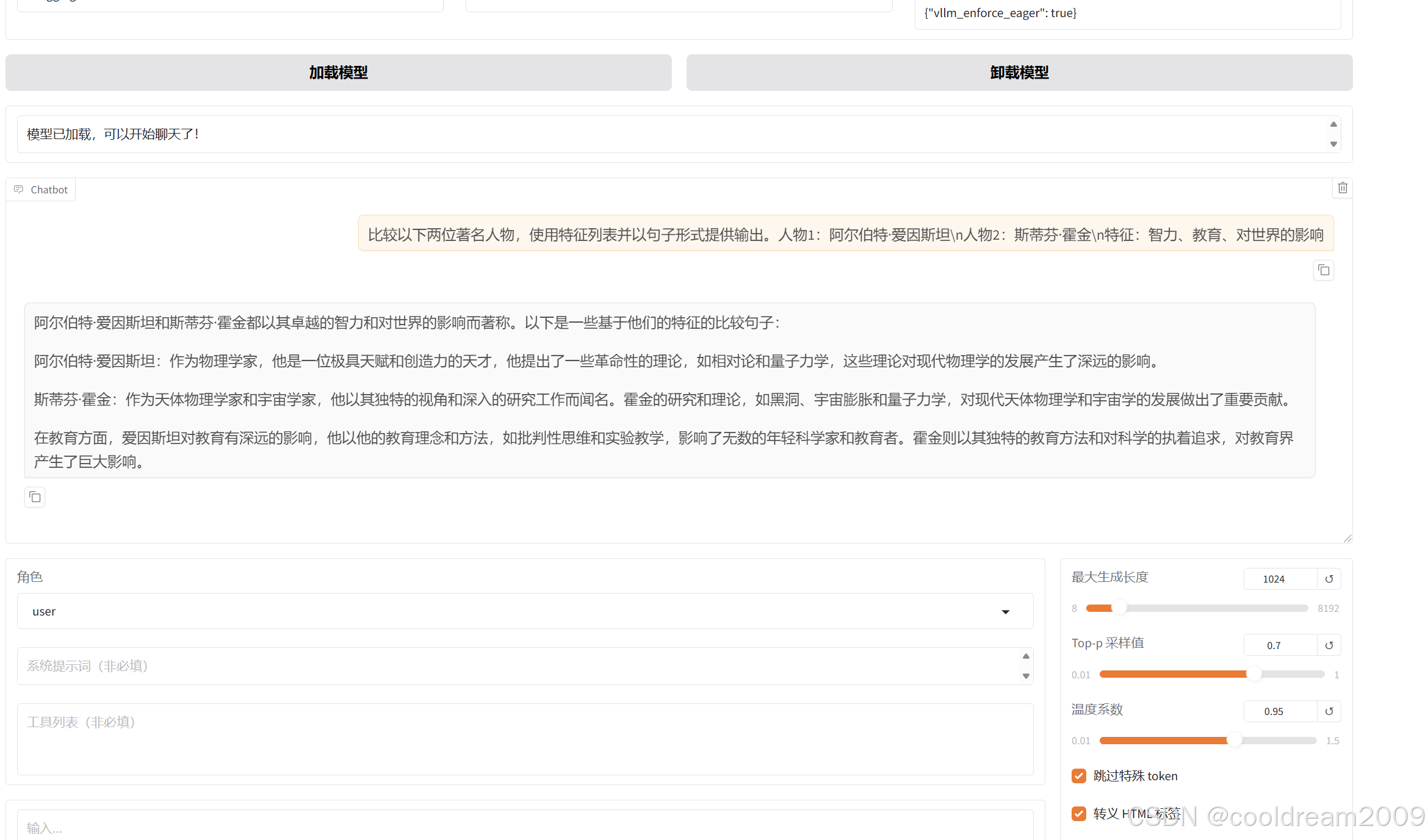
模型将基于基座模型的能力进行回答。此时模型尚未经过微调,回答基于预训练知识,可能存在泛化性一般、专业程度有限等问题。这个测试主要用于后续对比微调效果。
5 模型微调
5.1 准备数据集
LLaMA Factory 内置了多个常用数据集,在数据集选择区域选择:
alpaca_zh_demo.json
该数据集是中文 alpaca 格式,包含 instruction、input、output 三个字段。instruction 字段描述任务指令,input 字段提供额外的上下文信息,output 字段是期望的模型回答。alpaca_zh_demo 是一个精简的数据集,适用于快速验证微调流程完整性和熟悉操作界面。
5.2 配置训练参数
在训练参数设置区域,配置以下关键参数:
| 参数名称 | 推荐值 | 说明 |
|---|---|---|
| 学习率 | 2e-4 | LoRA 微调常用学习率,数值越大训练越快但可能不稳定 |
| 训练轮数 | 3-5 | 根据数据集大小调整,大数据集可适当减少 |
| 批次大小 | 4-8 | 根据显存大小调整,24GB 显存建议设为 4-8 |
| LoRA 秩 | 16 | 越大可训练参数越多、效果越好但占用更高显存 |
| LoRA Alpha | 16 | 通常设为 LoRA 秩的 1-2 倍,用于调整 LoRA 层的输出 scale |
此外还有梯度累积步数、预热步数、正则化系数等参数可以使用默认值或根据需要调整。对于初学者,建议先使用默认参数或推荐值跑通流程,再逐步尝试调优。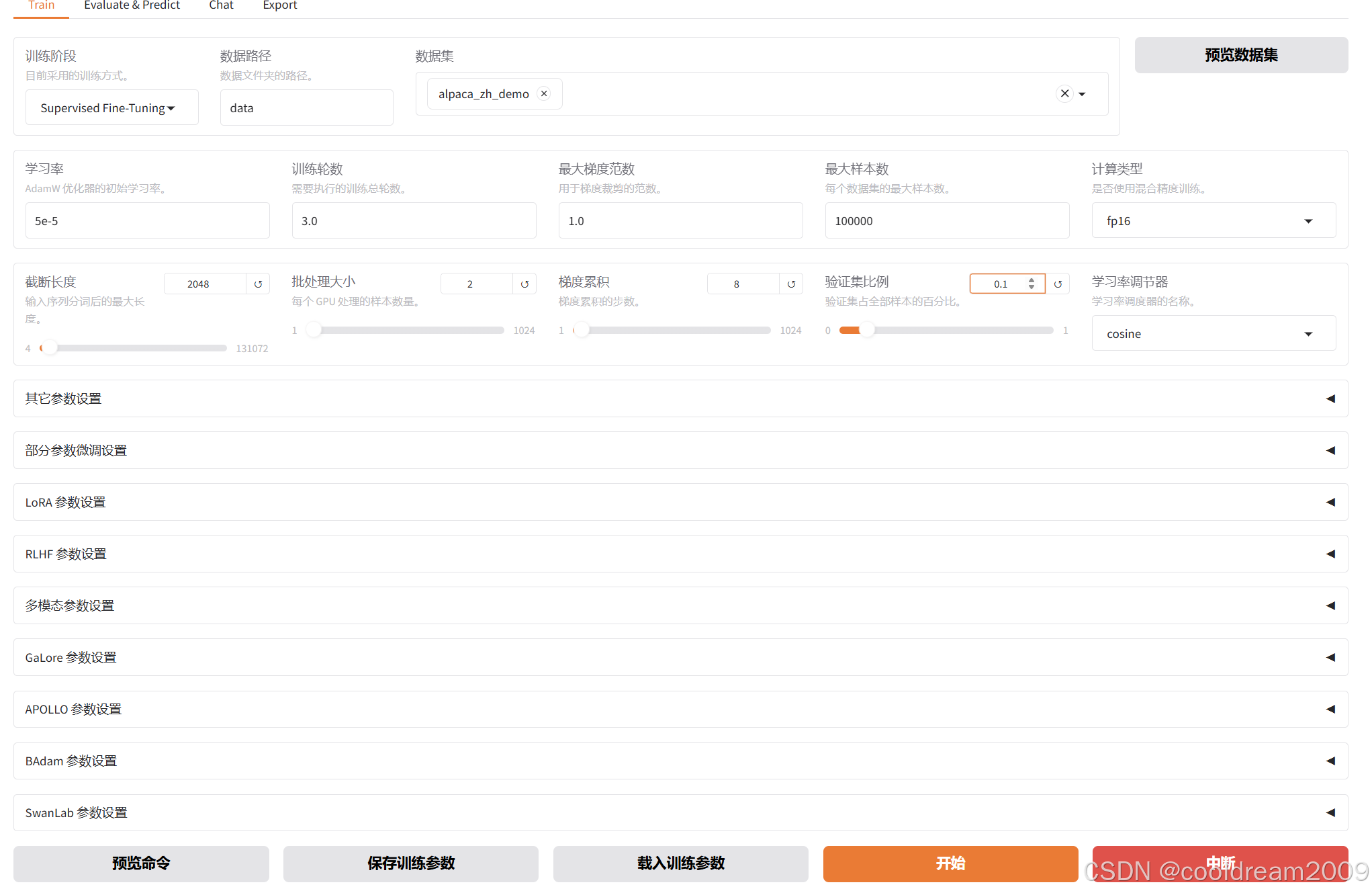
5.3 启动训练
确认参数配置无误后,点击开始训练按钮。训练过程中可在终端查看实时日志,包括 loss 下降曲线、GPU 显存使用情况、训练速度等指标。训练完成后会在设定的输出目录生成检查点文件,包含 LoRA 适配器权重和训练元信息。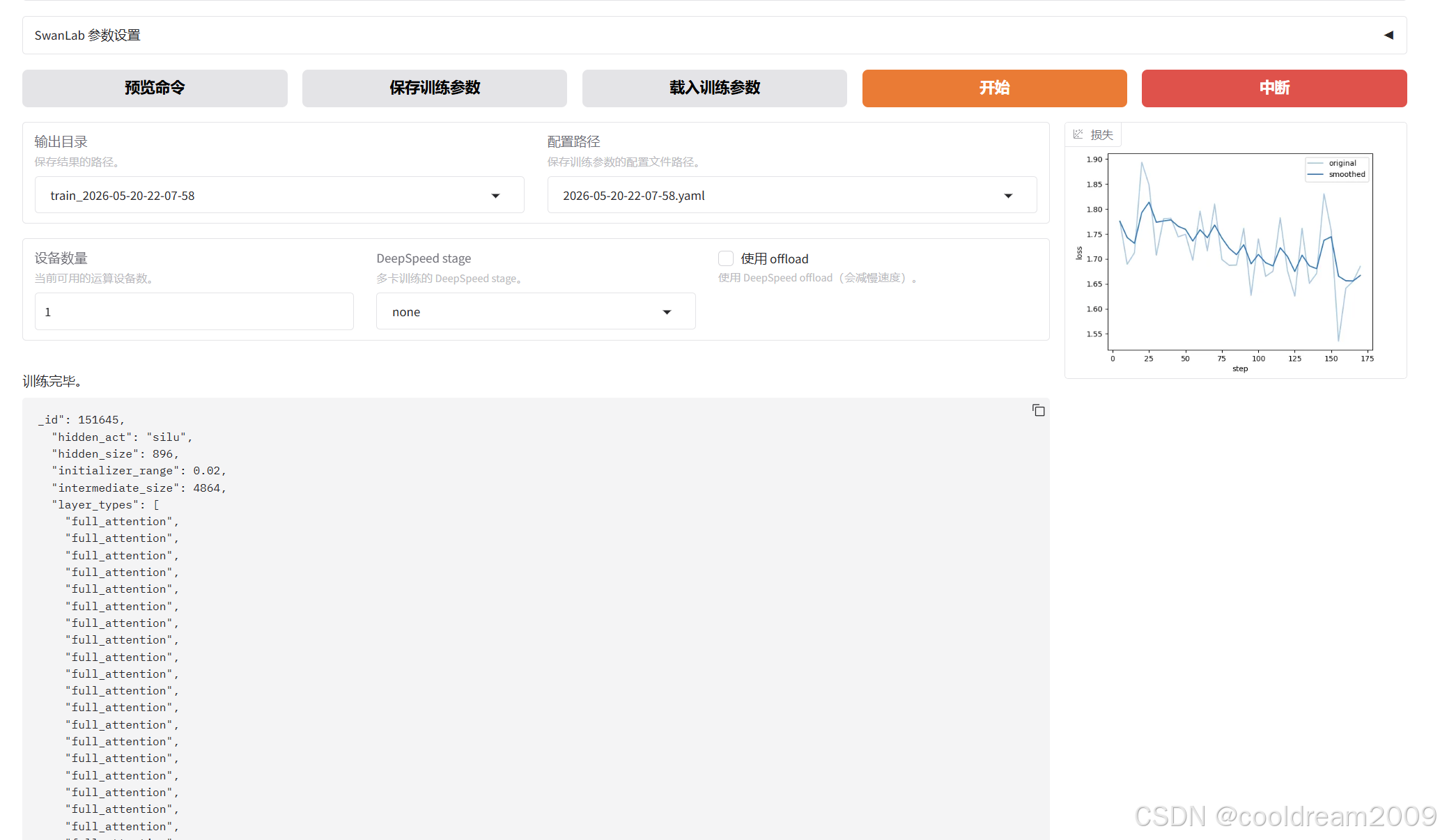
6 微调后模型对话
6.1 加载微调后的模型
在模型选择区域,点击检查点目录选择训练产生的模型文件夹。LLaMA Factory 会在指定输出目录中保存训练检查点,默认路径为 saves/模型名称/lora/训练时间-output。
6.2 测试微调效果
切换到在线推理模块,加载微调后的模型,再次输入相同的测试问题:
比较以下两位著名人物,使用特征列表并以句子形式提供输出。人物1:阿尔伯特·爱因斯坦\n人物2:斯蒂芬·霍金\n特征:智力、教育、对世界的影响
对比微调前后的回答差异。微调后的模型应该在理解问题格式、保持回答一致性方面有所提升,如果使用特定领域的数据集微调,回答的专业性也会显著增强。
7 模型导出
7.1 导出配置
在模型导出模块,配置导出路径,将训练好的模型导出到指定目录。导出时会将 LoRA 适配器权重与基座模型合并,生成完整的模型文件。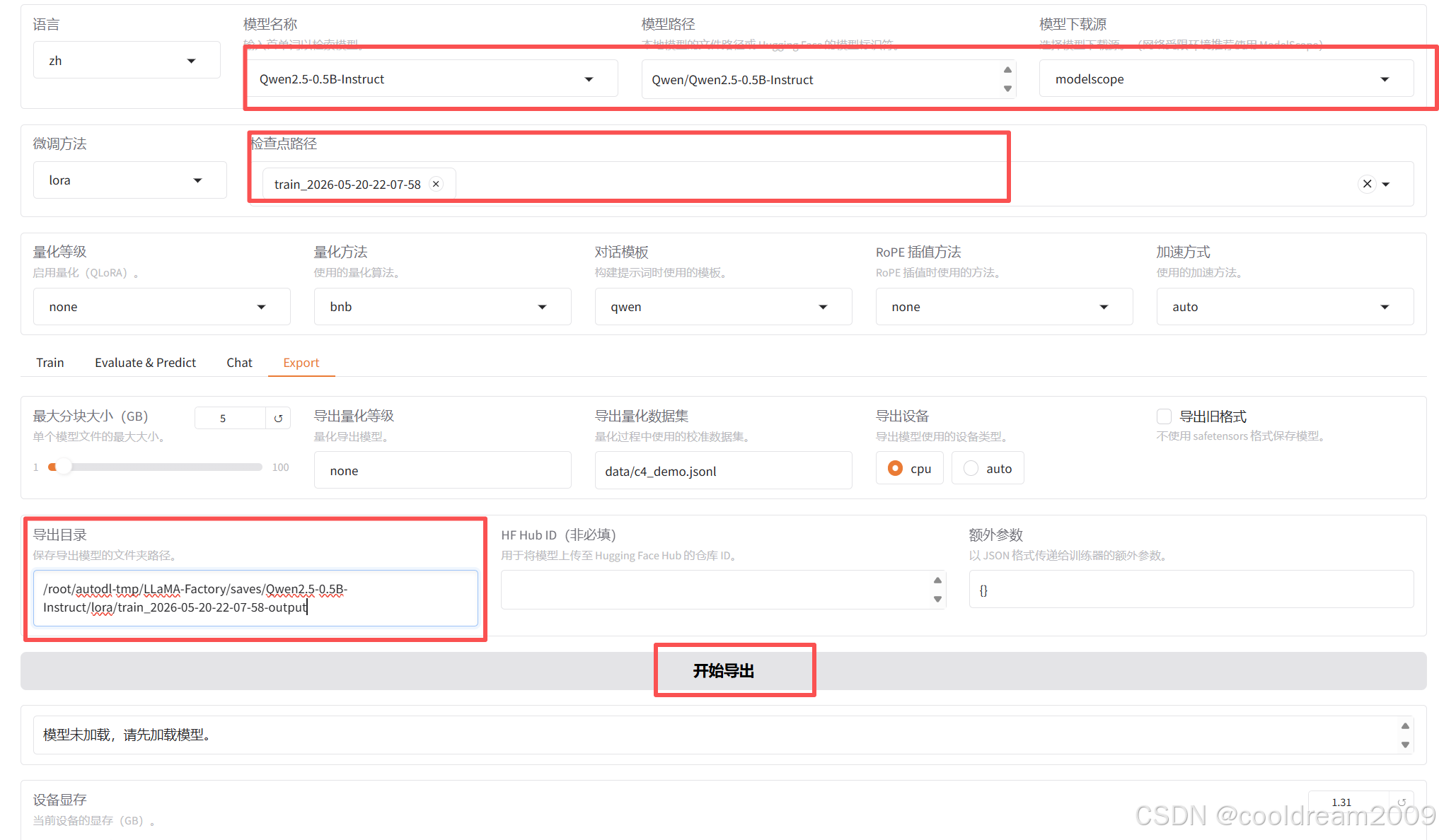
7.2 导出命令说明
导出后的模型包含完整的模型权重、配置文件和分词器,可用于后续的部署或进一步转换格式。导出的模型遵循 HuggingFace Transformers 规范,可以直接用 transformers 库加载使用。
8 模型部署
8.1 使用 HuggingFace 后端启动 API 服务
训练完成后,使用以下命令启动 API 服务:
API_PORT=6008 API_MODEL_NAME=qwen-lora llamafactory-cli api \
--model_name_or_path /root/autodl-tmp/LLaMA-Factory/saves/Qwen2.5-0.5B-Instruct/lora/train_2026-05-20-22-07-58-output \
--template qwen \
--infer_backend huggingface
参数说明:
API_PORT=6008:设置 API 服务端口为 6008API_MODEL_NAME=qwen-lora:设置模型在 API 中的名称--model_name_or_path:指定微调后的模型路径--template qwen:指定模型对应的对话模板类型--infer_backend huggingface:指定推理后端为 HuggingFace
服务启动后会显示监听地址和端口,此时可以通过 API 调用来使用微调后的模型。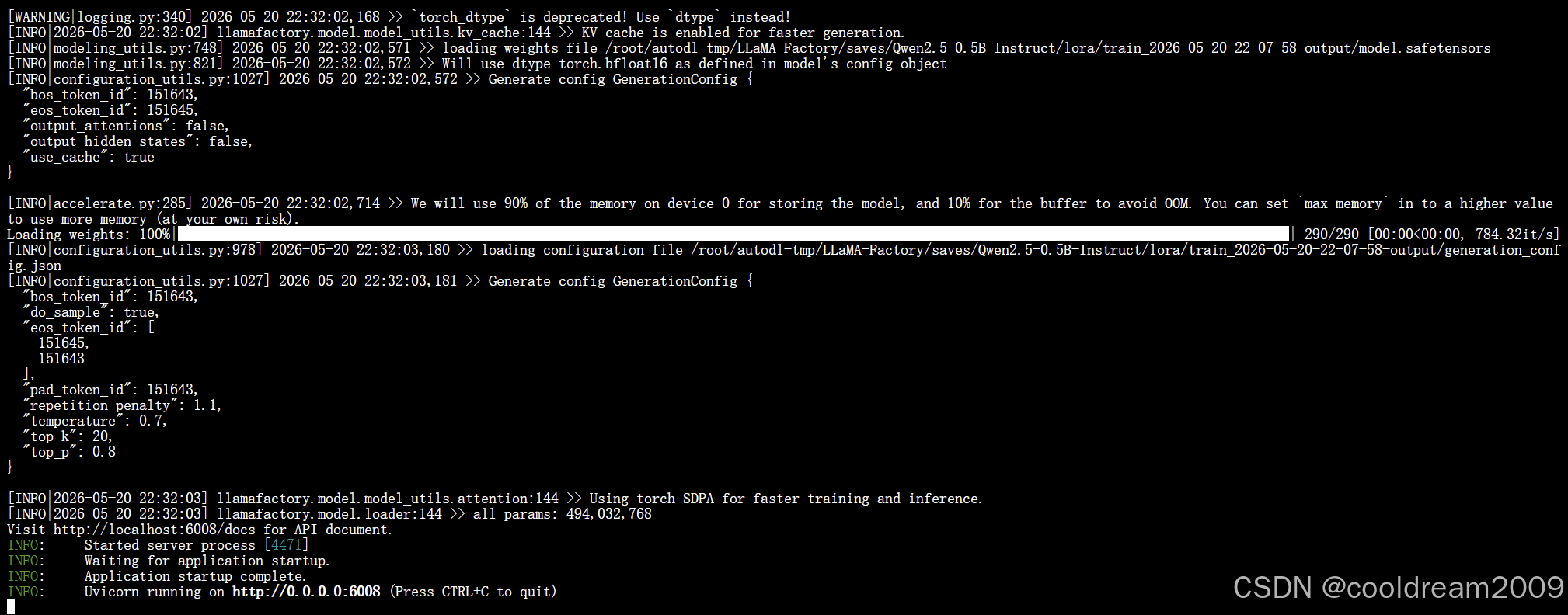
9 API 调用
9.1 Python 调用示例
创建调用脚本 llama_factory_demo.py,内容如下:
import requests
# vLLM 接口地址(默认)
url = "https://uu1013314-9bc9-cab7f12a.westb.seetacloud.com:8443/v1/chat/completions"
# 请求体
data = {
"model": "qwen-lora",
"messages": [
{"role": "user", "content": "乘坐公共交通时,请列出五个安全提示。"}
],
"temperature": 0.1,
"max_tokens": 2048
}
# 发送请求
response = requests.post(url, json=data)
result = response.json()
# 输出回答
print("模型回答:")
print(result["choices"][0]["message"]["content"])
LLaMA Factory 的 API 接口设计与 OpenAI API 兼容,因此可以直接使用 openai Python 库的接口进行调用。通过 base_url 参数指定 LLaMA Factory 服务的地址,model 参数指定要使用的模型名称。
9.2 运行调用脚本
python llama_factory_demo.py
脚本运行后会向 API 服务发送请求,并打印模型返回的回答。如果服务未启动或地址配置错误,会收到连接失败的错误提示。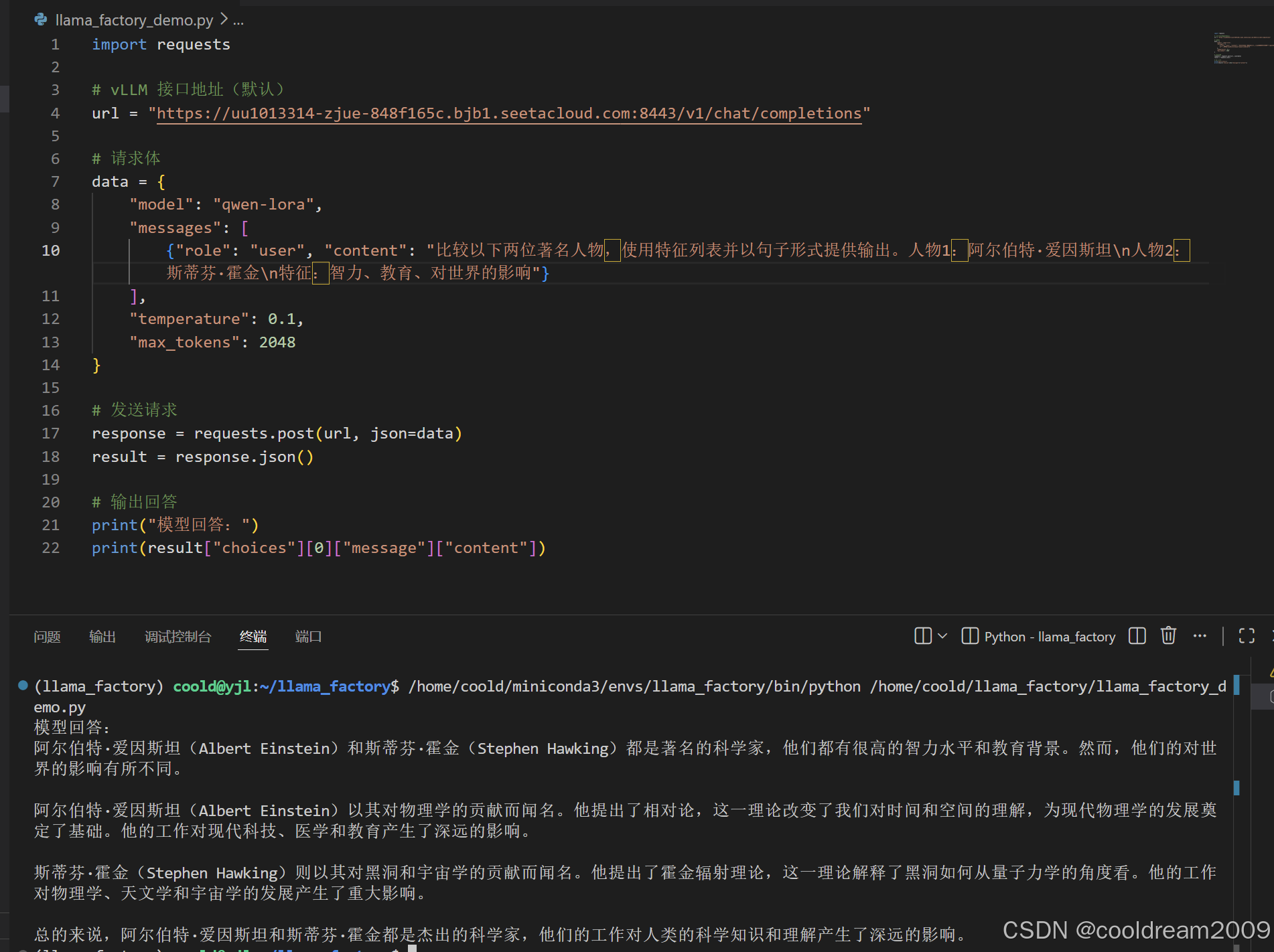
结语
本文详细介绍了在 AutoDL 上使用 LLaMA Factory 进行大模型微调的完整流程。从环境搭建、框架配置、WebUI 使用,到模型训练、效果验证、API 部署,涵盖了 LoRA 微调的各个环节。
LLaMA Factory 的优势在于提供了开箱即用的 WebUI 界面,大幅降低了使用门槛,同时支持 Qwen、LLaMA、ChatGLM 等多种大模型和 LoRA、QLoRA 等多种微调方法。通过本文的方法,您可以在消费级显存条件下完成模型微调,适合教学演示和科研实验。
在实际应用中,可以进一步探索以下方向:更换更大规模的基座模型以获得更好的效果、使用领域特定数据集进行垂直场景微调、尝试不同的量化方法以平衡效果与资源消耗、以及将微调后的模型部署为生产级别 API 服务。LLaMA Factory 还支持多模态模型微调和强化学习微调,有兴趣的读者可以进一步研究。
参考资料
| 资源 | 链接 |
|---|---|
| LLaMA Factory 官方仓库 | https://github.com/hiyouga/LLaMA-Factory |
| Qwen2.5 模型系列 | https://huggingface.co/Qwen/Qwen2.5-0.5B-Instruct |
| AutoDL 云服务器 | https://www.autodl.com |
| HuggingFace Transformers | https://huggingface.co/docs/transformers |

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐
 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)