服务器内存排查之free、vmstat、sar命令实战教程
在Linux服务器的运维场景中,程序突然卡顿且无日志报错、CPU未跑满的情况时有发生,此时内存问题往往是潜在的“罪魁祸首”。对于开发运维人员而言,掌握free、vmstat、sar这三个命令,就如同为服务器配备了专业的“体检工具”,能够在短短几分钟内精准定位内存相关的故障根源,为高效解决问题提供有力支持。
一、内存排查的必要性
当内存容量充足时,程序能够顺畅运行;然而,一旦内存不足,便会引发一系列问题。一方面,程序可能因无法获取足够的内存空间而崩溃;另一方面,系统不得不借助磁盘的“备用仓库”(即swap分区)来存储和读取数据。但磁盘的读写速度相较于内存而言,慢了100倍以上,这种速度差异必然导致程序出现明显的卡顿现象,严重影响服务器的性能和用户体验。
二、free命令:内存排查的“入门利器”
free命令堪称内存排查领域的“入门款”工具,它能够快速提供关于内存使用情况的基本信息,让用户迅速了解服务器的内存状态。
(一)简单操作与灵活参数
在Linux终端中,只需输入“free”命令,即可查看内存的初始状态。若希望结果以更人性化的GB/MB为单位显示,避免记忆KB数值的繁琐,可添加“-h”参数;若想实现每隔一定时间(如3秒)自动刷新内存信息,可添加“-s 3”参数。具体命令如下:
|
1 |
|
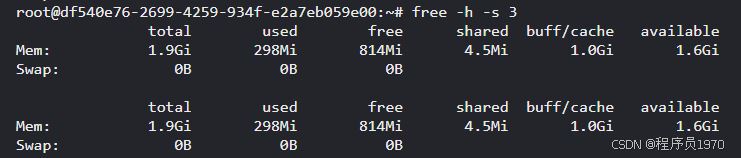
(二)结果解读:洞察内存“收支”
free命令输出的结果包含多个核心字段,每个字段都如同仓库的“收支数据”,反映了内存的不同使用情况:

- Mem(物理内存主仓库):这是程序最常用的内存空间,类似于实际工作中的主要工作区域。
- total:表示主仓库的总容量,例如1.9GB,反映了服务器物理内存的总量。
- used:显示已使用的内存容量,如298MB,体现了当前正在被程序占用的内存大小。
- free:代表完全未被使用的“空仓库”容量,例如814MB。但需要注意的是,这个值并非真正可用的内存,因为还需要考虑缓冲和缓存所占用的空间。
- buff/cache(临时存储区):这部分内存类似于仓库的“暂存架”,用于临时存储数据。
- buff(缓冲区):刚从磁盘接收的数据会先存放在这里进行整理,类似于快递站的“待分拣区”。例如,刚下载的文件碎片会暂时存储在缓冲区,等待进一步处理。
- cache(缓存区):频繁访问的文件或数据会被存放在这里,以便快速调用,类似于家里的“常用物品柜”。例如,常用的程序代码会被缓存在此,提高程序运行效率。
- available(真正可用内存):这是最为关键的指标,其值大约等于free + buff/cache,例如1.6GB。当这个值低于total的10%时,就表明内存已经接近耗尽,需要及时采取措施。
- Swap(内存备用仓库):这是磁盘上划分的专门空间,作为内存的备用区域。只有当主仓库(物理内存)满载时,系统才会使用Swap分区。但由于磁盘速度远慢于内存,使用Swap分区会导致性能下降。
(三)实际场景应用:快速判断内存状况
通过free命令,运维人员可以在10秒内快速判断内存是否充足。例如,当使用“free -h”命令查看结果时,如果发现available值只有100MB(而总内存为1.9GB),这就表明内存已经非常紧张,可能需要清理缓存或考虑升级内存。另外,如果Swap的used值大于0,并且持续增加,这说明主仓库的内存已经不够用,系统开始频繁使用备用仓库,此时必须尽快排查原因,避免问题进一步恶化。
三、vmstat命令:内存+CPU+IO的“全面体检专家”
vmstat命令犹如服务器的“全面体检报告”,它不仅能够提供内存的使用情况,还能同时监测CPU和IO的状态,是Linux运维领域中备受推崇的“明星命令”。
(一)使用方法:定期统计,精准把握
在终端中输入“vmstat”命令,默认会统计一次当前的系统状态。若希望实现定期统计,例如每隔5秒统计一次,共统计3次,可使用以下命令:
|
1 |
|
其中,第一个数字“5”表示统计间隔(秒),第二个数字“3”表示统计次数。通过定期统计,可以更准确地观察系统性能的变化趋势。
(二)结果解读:按模块剖析性能维度
vmstat的输出字段较多,但按照不同的性能维度进行模块划分后,理解起来就变得相对简单。

- procs(进程排队情况)
- r:表示正在运行以及等待CPU的进程数。如果这个数值长期大于服务器的CPU核心数(例如,服务器为4核CPU,而r长期大于4),则说明CPU资源不足,进程需要排队等待处理。
- b:代表等待资源的进程数,这些资源可能包括内存、磁盘IO等。如果这个数值大于0,说明有进程因为资源不足而“卡壳”,无法正常执行。
- memory(内存主仓库+备用仓库)
- swpd:显示备用仓库(Swap)已经使用的空间大小(单位:KB)。如果这个数值大于0,说明主仓库的内存已经不够用,系统开始使用备用仓库。如果swpd长期大于0且持续增加,就需要考虑升级内存或者终止一些无用的进程。
- free:表示主仓库的空闲内存容量。
- buff:缓冲区容量,类似于数据整理的“待分拣区”。
- cache:缓存区容量,类似于存放常用物品的“常用物品柜”。如果cache的值非常大,而io中的bi值比较小,说明文件系统的缓存效率较高,能够有效地减少磁盘IO操作。
- swap(备用仓库存取速度)
- si:每秒从备用仓库(磁盘)读入内存的数据量(单位:KB),即从备用仓库往主仓库运输数据。
- so:每秒从内存写入备用仓库的数据量(单位:KB),即主仓库放不下数据时,往备用仓库运输数据。正常情况下,si和so的值都应该为0。如果这两个值长期大于0(例如持续5分钟都有数值),说明主仓库的内存严重不足,必须采取措施解决,如升级内存或检查是否存在内存泄漏问题。
- io(磁盘读写速度)
- bi:每秒从磁盘读入的数据量(单位:KB)。
- bo:每秒写入磁盘的数据量(单位:KB)。如果bi + bo的值很大,并且后面的wa(IO等待CPU时间)大于20%,说明磁盘IO成为了系统的瓶颈,即使内存容量足够,也会导致系统出现卡顿现象。
- system(系统内核消耗的CPU)
- in:表示某一时间间隔内观测到的每秒设备终端数。
- cs:表示每秒产生的上下文切换次数。这个值越小越好,如果值过大,说明CPU大部分时间浪费在上下文切换上,没有得到充分利用。此时,需要考虑调低线程或者进程的数目,以提高CPU的使用效率。需要注意的是,in和cs的值越大,由内核消耗的CPU就越多。
- CPU(CPU干活情况)
- us:用户程序使用的CPU时间占比,例如订单系统、网页服务等业务程序。如果这个值长期大于50%,说明用户程序对CPU的占用过高,可能需要优化程序或算法。
- sy:系统内核使用的CPU时间占比,例如内存管理、磁盘IO等系统操作。us + sy的值最好小于80%,否则说明CPU资源不足,无法满足系统运行的需求。
- id:表示CPU处于空闲状态的时间百分比。
- wa:表示IO等待所占用的CPU时间百分比。如果wa大于20%,说明IO操作过慢,拖慢了整个系统的速度。引起I/O等待的原因可能是磁盘大量随机读写造成的,也可能是磁盘或者监控器的带宽瓶颈(主要是块操作)导致的。

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐

 0
0 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)