进一步了解进程---第四章 进程管理
在前面的几个章节中我们初步的了解了什么是进程,进程的状态,操作系统管理进程的方法,并且我们详细的知道了进程的切换调度的原理,今天我们再来深入的了解一些进程的管理方面的知识这篇文章首先在进程创建部分,重点讲解了fork系统调用的使用,包括如何通过返回值区分父子进程,以及写时拷贝(COW)机制在资源管理中的高效应用。其次是进程终止,详细阐述了子进程结束的多种方式(exit_exitreturn),并强

个人主页:小则又沐风
个人专栏:<数据结构>
<竞赛专栏>
<Linux>
座右铭
路虽远,行则将至;事虽难,做则必成
目录
前言
在前面的几个章节中我们初步的了解了什么是进程,进程的状态,操作系统管理进程的方法,并且我们详细的知道了进程的切换调度的原理,今天我们再来深入的了解一些进程的管理方面的知识
进程创建
首先我们先来学习一下进程的创建,在之前的讲解中我们已经尝试的创建过进程了,但是我们当时只是随口一提而已,并没有进行详细的讲解,今天我们来详细的讲解一下进程的创建.
并且解决一下我们当时遗漏的问题
首先我们创建一个进程是需要进行系统调用的,我们的函数的接口就是fork
我们知道这个函数就可以创建出一个子进程了,我们现在来看看创建出的子进程的特点
创建进程
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>
int main( void )
{
pid_t pid;
printf("Before: pid is %d\n", getpid());
if ( (pid=fork()) == -1 )perror("fork()"),exit(1);
printf("After:pid is %d, fork return %d\n", getpid(), pid);
sleep(1);
return 0;
} 我们来看看这个代码的运行结果会是什么
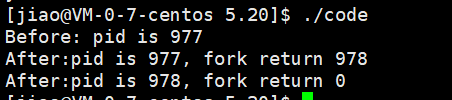
我们可以看到的是这个before的语句是只执行了一次,但是这个after的语句是执行了两次的,
这是为什么
这就是因为我们在第二个语句的执行之前我们创建出了一个新的进程,然后这个进程的代码和数据是和父进程一样的,所以我们的子进程执行了一次after语句父进程也执行了一遍
在这里子父进程的结束的前后是和cpu的调度有关的
fork的返回值
在之前我们就知道了这个函数的返回值返回给子父进程的值是不相同的,
如果成功创建出进程的话对父进程的返回值是创建出子进程的pid,对子进程的返回值是0
如果创建失败的话就是-1
那么在之前我们就已经试图的讲解一下为什么这个函数会有这么多的返回值现在我们来更详细的讲解一下
首先我们需要知道的是父进程是可以创建出很多的子进程的,那么这个父进程和子进程的比例就是1:n那么如果父进程拿到的不是创建成功的子进程的pid的话,他怎么才能找到他的孩子??
最后我们要知道的是父进程是需要拿到子进程的退出的信息的.所以这里的返回值是有说法的.
现在我们知道了为什么父进程的返回值是一个子进程的pid那么我们在来了解一下为什么会有两个返回值
我们需要知道的是我们这个fork是一个函数,调用这个函数就需要就进入到这个函数的体内的,那么这个函数一定是在return的语句之前就创建出了一个子进程,那么之后的代码和数据就会父进程和子进程一人一份,所以会有两份返回值.
但是在同一个变量中为什么它可以同时满足两个条件,也就是为什么我们感觉这个变量是由两个数据
这就需要我们了解一下写时拷贝了
写时拷⻉
通常,⽗⼦代码共享,⽗⼦再不写⼊时,数据也是共享的,当任意⼀⽅试图写⼊,便以写时拷⻉的⽅ 式各⾃⼀份副本。具体⻅下图
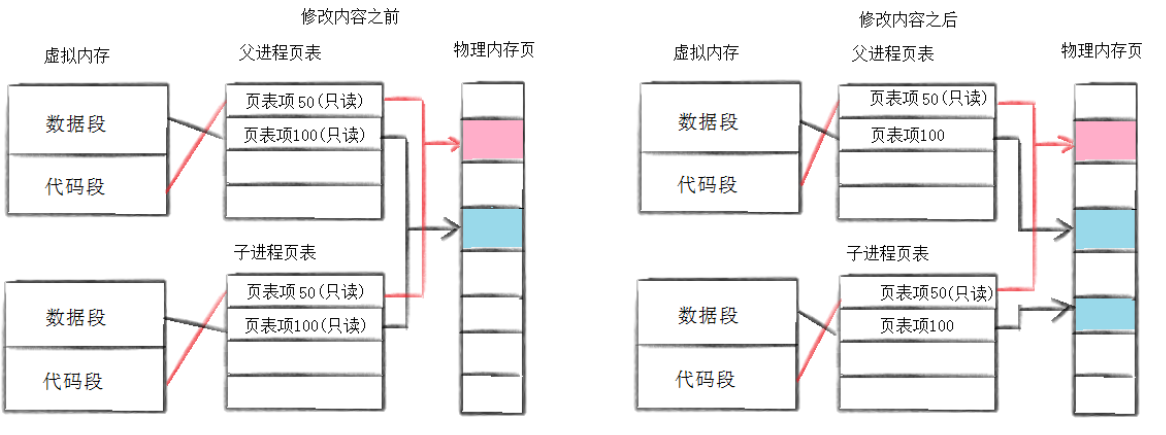
我们知道的是我们在内存中由两张表一个是虚拟地址空间表和一个物理空间地址表,一开始我们的子父进程的虚拟地址指向的物理地址是相同的,但是如果有一个进程需要对数据进行修改的话,我们可以看到在进行写时拷贝之前我们的数据和代码都是只读的,但是我们知道的是代码段是只读的不错,但是这个数据段是可以修改的,这时候就会出现矛盾,系统就会处理这个矛盾,在这里就会对进程需要修改的数据进行写时拷贝然后把他的那一份指向新的物理内存,但是虚拟地址是没有改变的,这样我们看起来是一个变量有了两个数据,但是其实是指向了两个不同的物理内存而已
在写时拷贝过后对应的数据的权限就会从只读变成了可以读也可以写
这时候就有人问了:
为什么一开始在创建出子进程的时候就对数据进行了全部的写时拷贝???
这是因为拷贝就需要物理内存的空间,但是不是所有的数据会遭到修改,所以没有必要,这样会节省空间
进程终⽌
进程的终止的情况于三种:
- 代码运行完毕,结果正确
- 代码运行完毕,结果错误
- 代码运行异常终止
进程退出的方法
- 从main函数退出
- 调用exit
- 调用_exit
上面的都算是正常的退出.而异常终止是
CTRL+C
退出码
我们在运行我们的进程的时候我们只能得到的是这个进程已经退出了,但是我们怎么才能知道这个进程的执行的结果是什么,是怎么退出的
那么这时候我们的进程在退出的时候就会有一个退出码,这个退出码就是来描述自己的退出的信息的
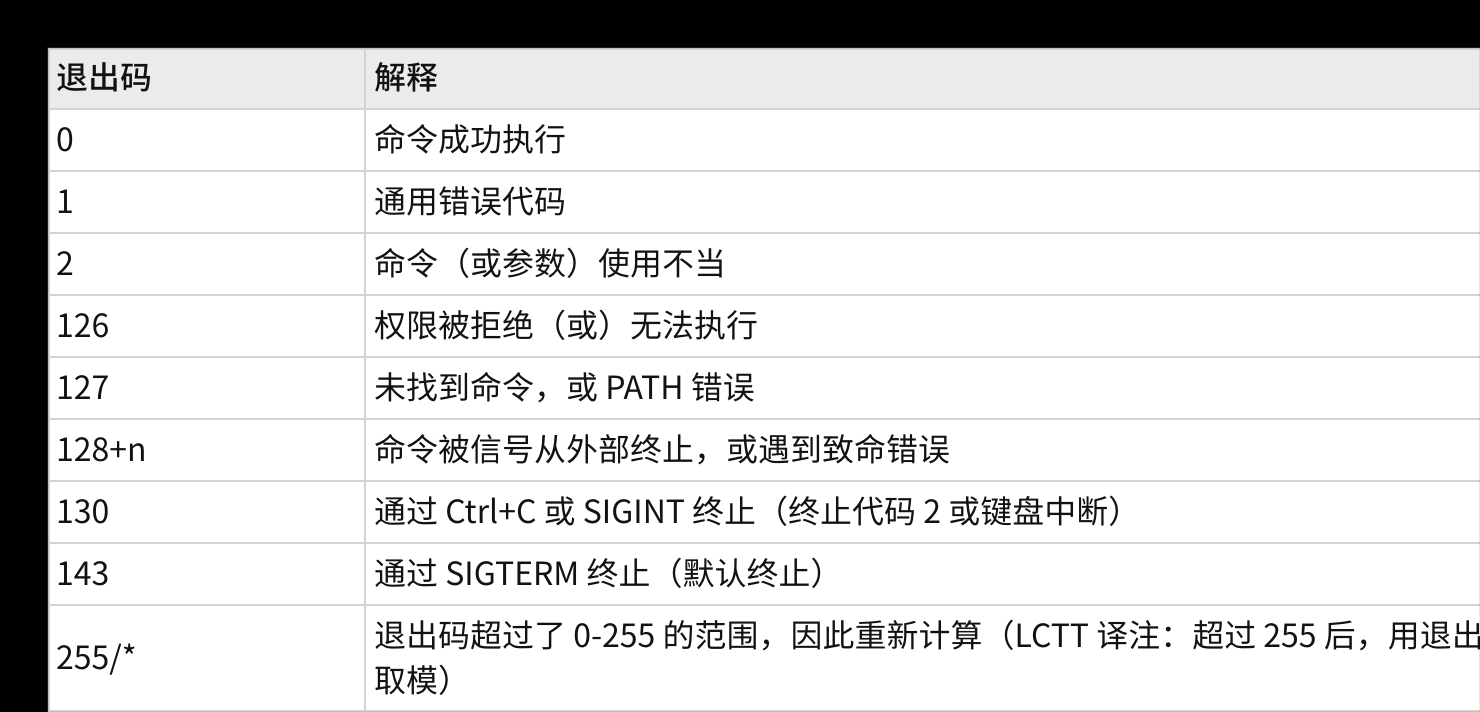
其基本思想是,程序返回退出代码 0 时表⽰执⾏成功,没有问题。 代码 1 或 0 以外的任何代码都被视为不成功。
这时候就和我们的进程状态联系在一起了,我们知道在通常的情况下,是父进程负责接收子进程的退出的信息的,如果是子进程先结束的话,子进程就会进入僵尸状态等到信息被接受,如果父进程先结束的话,子进程就会被领养.但是我们一般不会让子进程变成孤儿进程,之后我将会讲解做法
现在我们知道了进程成功结束的话退出码是一个0.这就是我们的main函数最终我们写的总是return 0;了
但是进程执行失败的话,执行错误的情况有很多种,所以退出码不可能只有几种,所以我们来看一下Linux下的退出码
exit/_exit函数
这个函数的都是用来终止进程,但是这个函数有不同的地方,这个函数的参数是传递终止的信息的,
之后这个信息将会被父进程获得
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
void Myexit()
{
printf("hello exit");
exit(1);
}
void My_exit()
{
printf("hello _exit");
_exit(1);
}
int main()
{
Myexit();
return 0;
}现在我们先调用exit来看看是什么情况
![]()
成功打印信息,并且退出
那么_exit呢?
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
void Myexit()
{
printf("hello exit");
exit(1);
}
void My_exit()
{
printf("hello _exit");
_exit(1);
}
int main()
{
//Myexit();
My_exit();
return 0;
}![]()
我们发现这个_exit并没有打印信息,但是退出了,这是什么情况???
下面我们来简单的了解一下
我们知道的是我们在Linux下其实一切的东西都是文件,我们向显示器中写入信息都是从这个文件中写入的,但是我们如果写入一条信息的话就向文件中写入的话,我们就会频繁的打开这个文件,就相当于你妈妈让你扔垃圾你一件件扔,所以你需要频繁的下楼,所以你会选择把垃圾打包一起扔,所以这个写入文件也是这样的,我们写入的时候我们并不是直接写入到了文件中,而是写在了文件的缓存区,这个缓存区达到了刷新了条件了,才会调用系统的write函数写入文件,
如果缓存区不刷新我们的信息就会在这里呆着,不会在文件中出现,所以这个_exit函数和exit函数的区别就是_exit不会刷新文件的缓存区.所以我们之前发现不加/n的代码执行起来会不一样,这就是因为在linux的规定中写入显示器文件的刷新条件是行刷新
在这里我们只做简单了解之后会在文件管理中详细的讲解
return退出
这个就是我们最常用的退出的方式了,return n就相当于exit(n);
进程等待
我们刚才讲子进程是有变成孤儿进程的风险的,所以我们怎么才能解决这个问题呢??
我们只需要让父进程结束的时候我们让父进程等待子进程结束就好了.
那么下面我们来了解一下进程等待的函数
wait
这个函数就是用来等待进程的函数接口,下面我们仔细地看看这个函数
pid_t wait(int* status);
这个函数地返回值是pid_t的值,如果这个函数的返回值是一个-1的话就说明我们等待失败了.
如果等待成功的话这个函数的返回值就是被等待进程的pid
我们来看看这个函数的使用
#include<stdio.h>
#include<sys/types.h>
#include<sys/wait.h>
int main()
{
printf("我要开始创建进程了\n");
int id=fork();
if(id==-1)
{
perror("创建进程失败\n");
exit(1);
}else if(id==0)
{
//child
int cout=3;
while(cout)
{
cout--;
sleep(1);
}
exit(1);
}else
{
//father
int x=wait(NULL);
if(x==-1)
{
perror("等待失败\n");
}else{
printf("我等待的进程的pid是:%d",x);
}
}
return 0;
}在这里的函数的参数是用来接收进程退出码的,但是我们在这里不关心函数的退出码的话我们就输入空指针就好了

现在看来我们的使用是对的
那么我们再来看看另一个更常用等待进程的函数
waitpid
这个函数相对于上一个函数是更加的常用的,下面我们来看看这个函数的相关的信息
pid_ t waitpid(pid_t pid, int *status, int options);
pid_ t waitpid(pid_t pid, int *status, int options);
返回值:
当正常返回的时候 waitpid 返回收集到的⼦进程的进程 ID ;
如果设置了选项 WNOHANG, ⽽调⽤中 waitpid 发现没有已退出的⼦进程可收集 , 则返回 0; 如果调⽤中出错 , 则返回-1, 这时 errno 会被设置成相应的值以指⽰错误所在;
参数:
pid :Pid=-1, 等待任⼀个⼦进程。与 wait 等效。
Pid>0. 等待其进程 ID 与 pid 相等的⼦进程。
status:
输出型参数 WIFEXITED(status): 若为正常终⽌⼦进程返回的状态,则为真。(查看进程 是否是正常退出) WEXITSTATUS(status): 若 WIFEXITED ⾮零,提取⼦进程退出码。(查看进程 的退出码)
options: 默认为 0 ,表⽰阻塞等待
上面的说的似乎这个函数的使用十分的复杂,没关系我们来详细的讲解一下这个函数的使用
首先我们来说一下第一个函数的参数
第一个参数:pid_t pid
这个参数是指明我们需要等待进程的参数,如果这个参数我们填写的是-1的话这个就会像wait一样等待所有的进程.
如果我们传入的是一个进程的pid的话那么他就会专门等待这个进程的
第二个参数:int *status
这个参数我们在上面的使用中是把他设置成空指针的,我们只知道的是这个变量是用来接收被等待进程的退出码的,那么我们来看看这个是怎么用的
#include<stdio.h>
#include<stdlib.h>
#include<sys/types.h>
#include<sys/wait.h>
int main()
{
int id=fork();
if(id==-1)
{
perror("创建进程失败\n");
exit(1);
}else if(id==0)
{
//child
printf("子进程开始运行了,将会运行3秒\n");
int cnt=3;
while(cnt)
{
sleep(1);
cnt--;
}
printf("子进程运行结束,设置的退出码是1\n");
exit(1);
}else
{
//father
int status;
int x=waitpid(id,&status,0);
if(x==-1)
{
perror("等待失败\n");
exit(1);
}else if(x==id)
{
printf("等待成功,进程的退出码是%d\n",status);
}
}
return 0;
}我们来看看这个代码的运行结果是什么
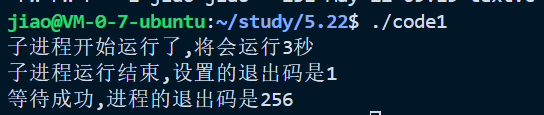
我们发现我们得到的进程的退出码和我们设置的居然不一样,这是怎么回事呢?
我们现在就需要了解一下这个status的真面了
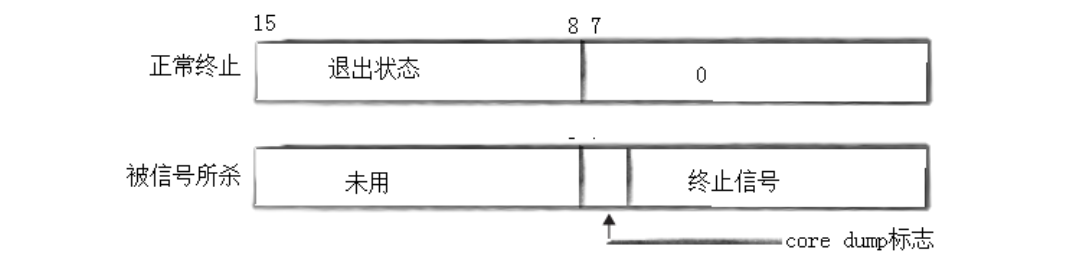
我们不能把这个int类型的看作一个整数,我们应该一个个比特位的看,看作一个位图
这个数据的15位到8位表示的是退出的信息我们来看看我们设置的是进程的退出的信息是1
那么他就应该是一个100000000也就是一个2的八次方对应的就是256;
所以我们的进程如果是正常退出的话我们想要得到正确的退出码的话我们需要的操作就是
(status>>8);
#include<stdio.h>
#include<stdlib.h>
#include<sys/types.h>
#include<sys/wait.h>
int main()
{
int id=fork();
if(id==-1)
{
perror("创建进程失败\n");
exit(1);
}else if(id==0)
{
//child
printf("子进程开始运行了,将会运行3秒\n");
int cnt=3;
while(cnt)
{
sleep(1);
cnt--;
}
printf("子进程运行结束,设置的退出码是1\n");
exit(1);
}else
{
//father
int status;
int x=waitpid(id,&status,0);
if(x==-1)
{
perror("等待失败\n");
exit(1);
}else if(x==id)
{
printf("等待成功,进程的退出码是%d\n",(status>>8));
}
}
return 0;
}
这样就对了
上面的情况上针对于正常退出的进程的,那么我们是怎么得到异常退出进程的信息的呢??
我们只需要&上1111111即可了因为正常退出的话他的这个后面的7个比特位都是0
#include<stdio.h>
#include<stdlib.h>
#include<sys/types.h>
#include<unistd.h>
#include<sys/wait.h>
int main()
{
int id=fork();
if(id==-1)
{
perror("创建进程失败\n");
exit(1);
}else if(id==0)
{
//child
printf("子进程开始运行了,我的pid是%d,将会运行3秒\n",getpid());
int cnt=3;
while(cnt)
{
sleep(1);
cnt--;
}
printf("子进程运行结束,设置的退出码是1\n");
exit(1);
}else
{
//father
int status;
int x=waitpid(id,&status,0);
if((status&0x7f)==0&&x==id)
{
printf("正常退出,退出码是%d\n",(status>>8)&0xff);
}else if(id==x)
{
printf("异常退出,退出码是%d\n",status&0x7f);
}
}
return 0;
}
那么我们尝试让这个进程异常退出
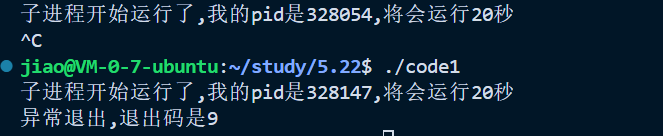

这样我们就可以得到了进程退出的详细的信息了
那么我们这个得到进程正常或者异常退出的运算是有一个宏的
WIFEXITED(status);
这个就是那个宏这个也就是我们刚才的&0x7f了但是这个只是底层的逻辑而已,但是他进行了一定的封装如果这个宏的返回值是零的话代表的是异常退出和我们的相反的
所以我们来总结一下:
WIFEXITED(status);如果为真正常退出,通过>>8的结果&0xff查看退出码WEXITSTATUS(status)
这个宏是把通过>>8的结果&0xff查看退出码封装成一个宏了
WIFEXITED(status);如果为假异常退出,&0x7f查看异常退出码
第三个参数:int options
在上面的讲解中我们知道了前面的两个参数的含义了,那么这第三个参数是怎么回事
我们在上面知道这个参数一般是一个0,那么这是代表的什么含义呢??
下面我们来了解一下
这个参数的是指就是来代表的是等待进程的方式
主要的是有两种方式:
阻塞等待和非阻塞等待
那么这两种的方式有什么区别呢?
我们来看一个例子:
张三和王五交往了,有一天他们约定要去吃一家网红餐厅,张三早早的来到了王五的家楼下,等待王五下楼.
王五是一个女孩子,他需要做一些防晒处理或者花一些妆所以在张三打来电话的时候说,啊这个你等一会我化个妆就下来了.张三想看看王五到底起床没,就给他打去了视频,发现王五真的在化妆,然后电话就挂了,张三就在楼下什么都不干就一直等,
这样的等待方式就是阻塞等待,张三这个进程什么都没干,就只等待了
那么什么是非阻塞等待呢?
那就是张三给王五说:那个啊,你先化着,我去给汽车加个油,顺便给你带杯奶茶.你化好妆了就给我打电话.这样在等待的时候又有了别的动作就是非阻塞等待
我们上面实现的代码都是阻塞等待的,下面我们来实现一个非阻塞等待的代码
#include <stdio.h>
#include<stdlib.h>
#include <unistd.h>
#include <sys/wait.h>
#include<vector>
typedef void (*hander_t)();
std::vector<hander_t> hander;
void fun_1()
{
printf("这是一个任务1\n");
}
void fun_2()
{
printf("这是任务2\n");
}
void otherwork()
{
hander.push_back(fun_1);
hander.push_back(fun_2);
for(auto t : hander)
{
t();
}
}
int main()
{
int id = fork();
if (id == -1)
{
perror("创建进程失败\n");
}
else if (id == 0)
{
// child
int cnt = 20;
printf("我是一个子进程,我要运行20秒\n");
while (cnt)
{
sleep(1);
cnt--;
}
exit(1);
}
else
{
// father
int status;
int x = 0;
do
{
x = waitpid(id, &status, 1);
if(x == 0 )
{
printf("子进程正在运行...\n");
}
sleep(1);
otherwork();
} while (x == 0);
if(WIFEXITED(status)&&x==id)
{
printf("进程正常退出,进程的退出码是:%d\n",WEXITSTATUS(status));
}else
{
printf("进程等待失败\n");
}
}
return 0;
}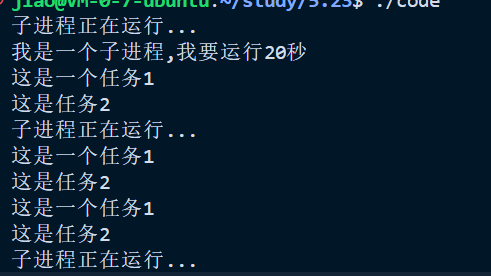
我们在这个代码中就可以看到这个非阻塞等待的时候父进程真的可以进行别的任务
总结
这篇文章
首先在进程创建部分,重点讲解了 fork 系统调用的使用,包括如何通过返回值区分父子进程,以及写时拷贝(COW)机制在资源管理中的高效应用。
其次是进程终止,详细阐述了子进程结束的多种方式(exit、_exit、return),并强调了退出码(Exit Code)作为父进程获取子进程状态的关键信息。
最后在进程等待部分,深入解析了 waitpid 函数。重点说明了其三个参数的作用:pid 指定目标进程,status 用于存储终止状态,而 options 则灵活控制等待行为(如阻塞或非阻塞)。这部分是父进程回收子进程资源、避免产生僵尸进程的关键操作。
之后将会讲解进程的替换的知识.
谢谢大家的观看!!!

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐
 39
39 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)