从桌面应用到 Agent 操作系统:一个生产级多智能体系统的记忆体系与工具生态
本文介绍了一个从零构建的桌面端多智能体系统"潇楠Web3哨兵",该系统具有九层记忆体系、四层开放式工具生态和多智能体协作框架。系统采用Mixin模块化设计,包含40+内置工具和动态加载外部技能的能力,支持AI自动生成工具和用户自定义HTTP API。记忆体系实现了从毫秒级会话到永久身份固化的完整认知闭环,多智能体间通过主从协作模式实现任务分发。系统采用DeepSeek+Moon
摘要
本文深度剖析一个在真实桌面应用中演化出的多智能体系统,涵盖其九层记忆体系、四层开放式工具生态、多智能体协作框架、双模型智能路由以及模块化前端面板体系。该系统不依赖 LangChain 等第三方 Agent 框架,完全从零构建,在桌面端这一独特约束环境下,实现了从毫秒级会话记忆到永久身份固化的完整认知闭环,以及从硬编码工具到 AI 自动生成工具的四级开放工具生态。
关键词:多智能体系统;记忆体系;工具生态;桌面应用;函数调用
1. 引言:桌面端的多智能体操作系统愿景
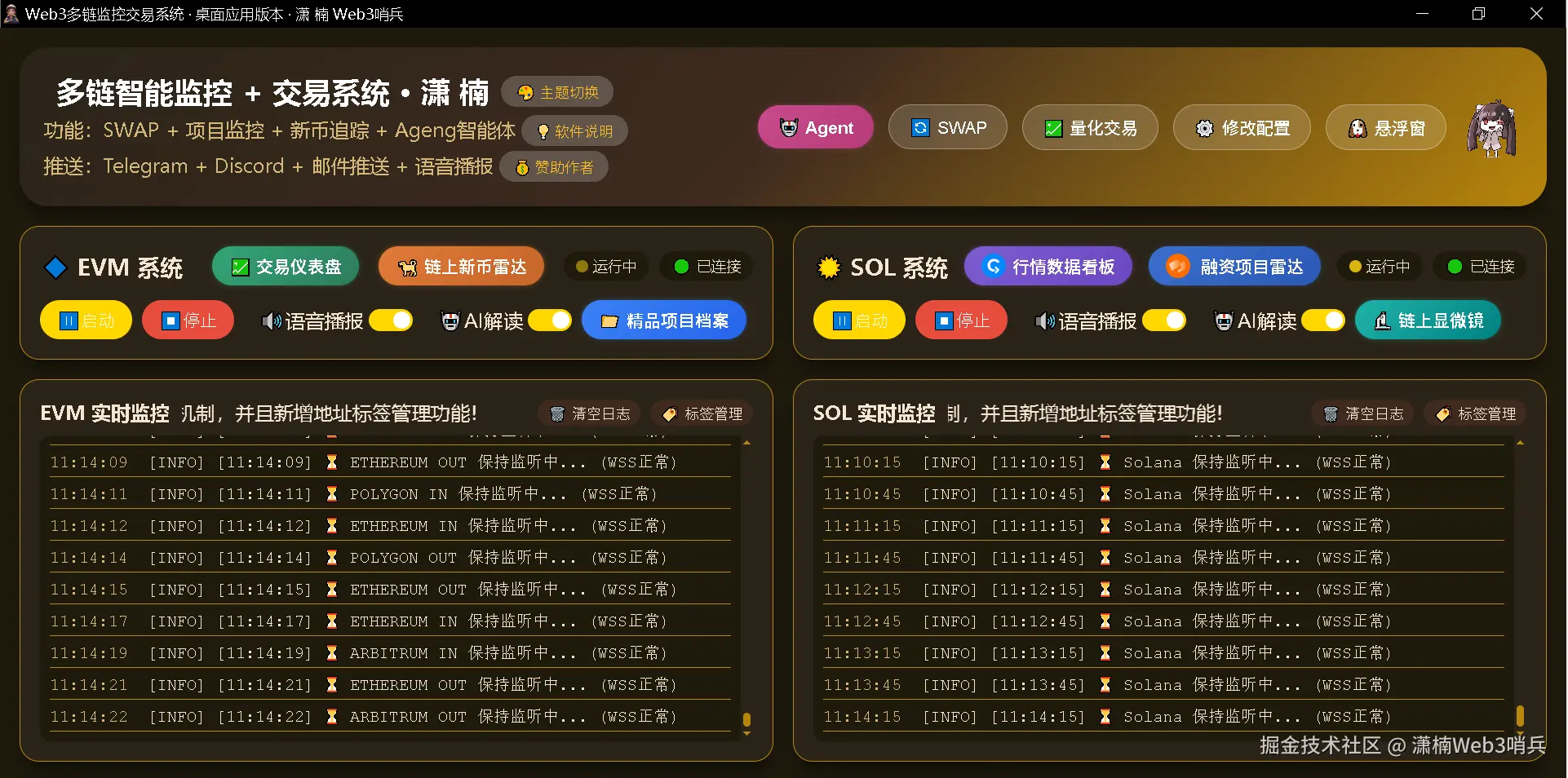
Web3 桌面监控交易系统“潇楠 Web3 哨兵”是一款集多链监控、交易执行、项目管理于一体的桌面应用。其内置的智能体(Agent)系统——小雨萝卜头及其两个子智能体(小萌萌和小豆包)——是该软件的核心智能层,承担着数据解读、风险分析、交易辅助和主动服务等关键职能。
与大多数依赖 LangChain 或类似框架的 Agent 系统不同,本系统完全从零构建,没有引入任何 Agent 框架依赖。这种选择源于一个深刻的工程认知:框架虽然提供了便捷的抽象,但也带来了性能损耗和灵活性限制。在桌面端这一独特约束下,进程内直接函数调用优于 HTTP RPC,本地 SQLite 数据库优于远端向量存储,Python 运行时动态加载优于容器化微服务。这些设计决策共同塑造了一个真正面向桌面端生产环境的多智能体系统。
本文将从记忆体系、工具生态、智能体协作、模型调度和前端架构五个维度,系统性地阐述该 Agent 系统的设计理念和技术实现。全文侧重于架构设计者的视角,揭示每一个技术决策背后的工程考量。
2. 系统总览:Mixin 组装的模块化内核
整个 Agent 系统的核心类 AgentMixin 通过多重继承(Mixin 模式)组合了五个基础子模块。这种扁平化的模块组合方式是系统架构的第一项重要设计决策——将记忆、工具、AI 调用、主动行为等核心能力平摊在同一个命名空间中,使得工具执行函数能无障碍地访问记忆系统、配置管理和消息推送能力,无需通过繁琐的依赖注入或跨模块调用。
2.1 模块职责划分
系统将 Agent 的核心能力拆解为五个 Mixin 子模块,每个模块承担独立的职责边界:
-
AgentBaseMixin:记忆系统(数据库初始化、记忆读写、偏好学习、系统事件日志)、配置管理、消息推送 -
AgentToolsDefMixin:工具定义(40+ 内置工具 + 外部 Skills 动态加载 + 用户 HTTP 工具) -
AgentToolsExecMixin:工具执行(覆盖所有工具的执行逻辑,通过统一的_execute_tool方法路由) -
AgentAICallsMixin:AI 模型调用(DeepSeek 流式深度思考 + Moonshot 联网搜索 + 视觉识别 + 自动降级) -
AgentProactiveMixin:主动行为(定时聊天、反思循环、屏幕感知、突发奇想、小窝自动回复)
这种扁平 Mixin 堆叠方式将所有能力平摊在一个大类中,前端 JS API 调用统一,但子模块间存在隐式依赖。这种设计在工程实践中是务实的权衡:它牺牲了形式化的模块边界,换来了快速迭代的能力。
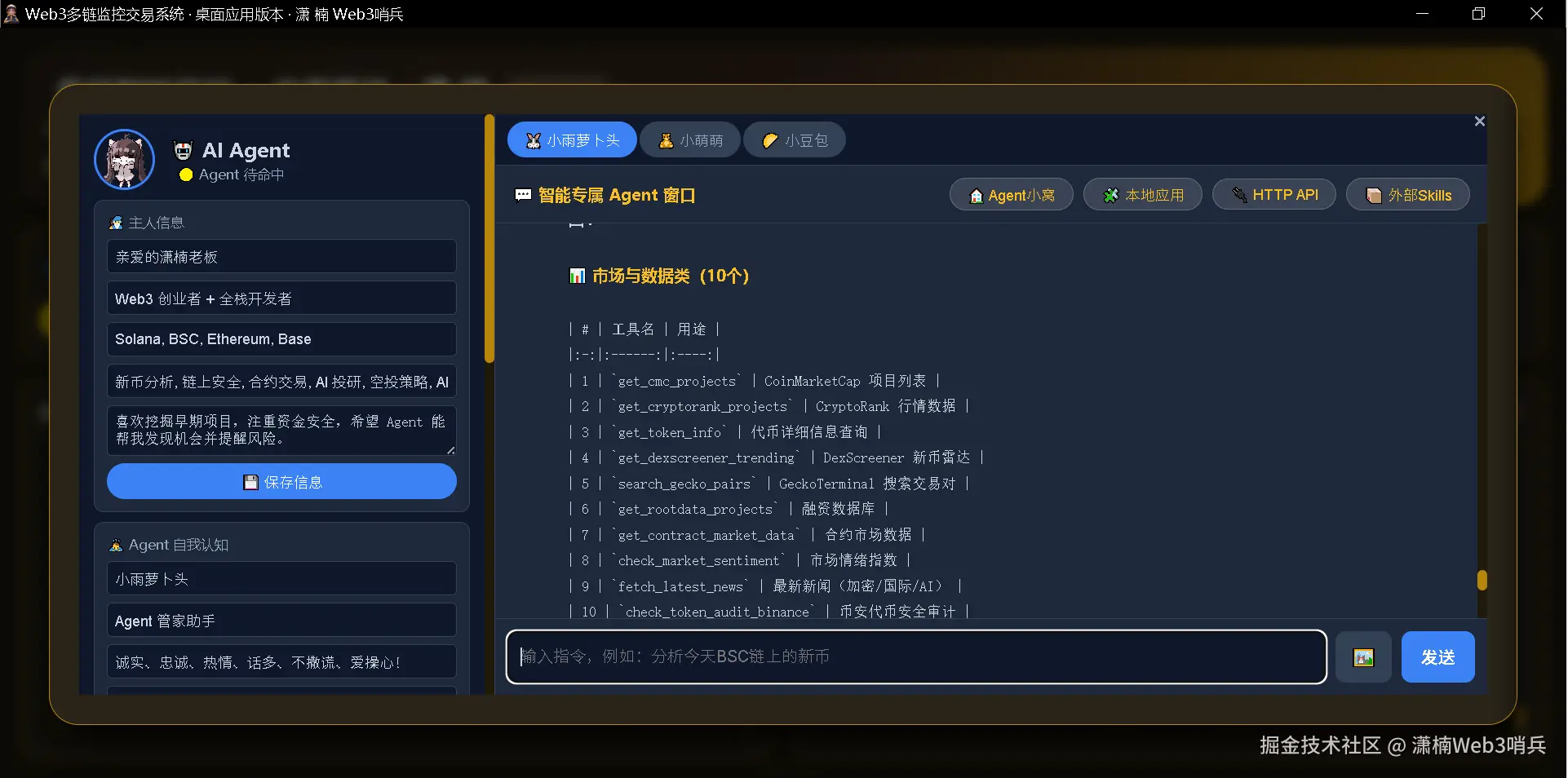
2.2 子智能体注册机制
系统预留了子 Agent 扩展接口,通过 _init_sub_agents 方法动态注册独立的智能体实例:
def _init_sub_agents(self):
# 合约分析智能体(小萌萌)
from modules.agent_sub_1.xiaomengmeng_core import SubAgentCore as SubAgent1
self.sub_agents["trader"] = SubAgent1(api_instance=self)
# 安全审计智能体(小豆包)
from modules.agent_sub_2.xiaodoubao_core import SubAgentCore as SubAgent2
self.sub_agents["trader_2"] = SubAgent2(api_instance=self)
子智能体接收 api_instance=self 引用,可以反向调用主智能体的方法和工具。这种设计使得主智能体可以像委托人类助手一样将任务分发给子智能体,而子智能体则能调用主智能体的工具链来完成被分配的任务。当子智能体加载失败时,系统只打印警告而不影响主流程——这种容错设计确保了单个子智能体的异常不会破坏整个系统的稳定性。
2.3 前端模块化面板体系
Agent 前端采用一个核心 JS + 七个独立面板模块的架构。核心 agent.js 负责聊天逻辑、配置管理和多 Agent 切换,体积从最初的 2500+ 行瘦身到约 1000 行。七个独立面板各司其职:
| 面板 | 模块文件 | 职责 |
|---|---|---|
| 记忆博物馆 | agent_museum.js |
记忆记录的展示、搜索与删除 |
| 本地应用 | agent_localapps.js |
桌面快捷方式扫描、文件夹导航、一键启动 |
| 调度日志 | agent_schedule.js |
子Agent任务调度的历史查询 |
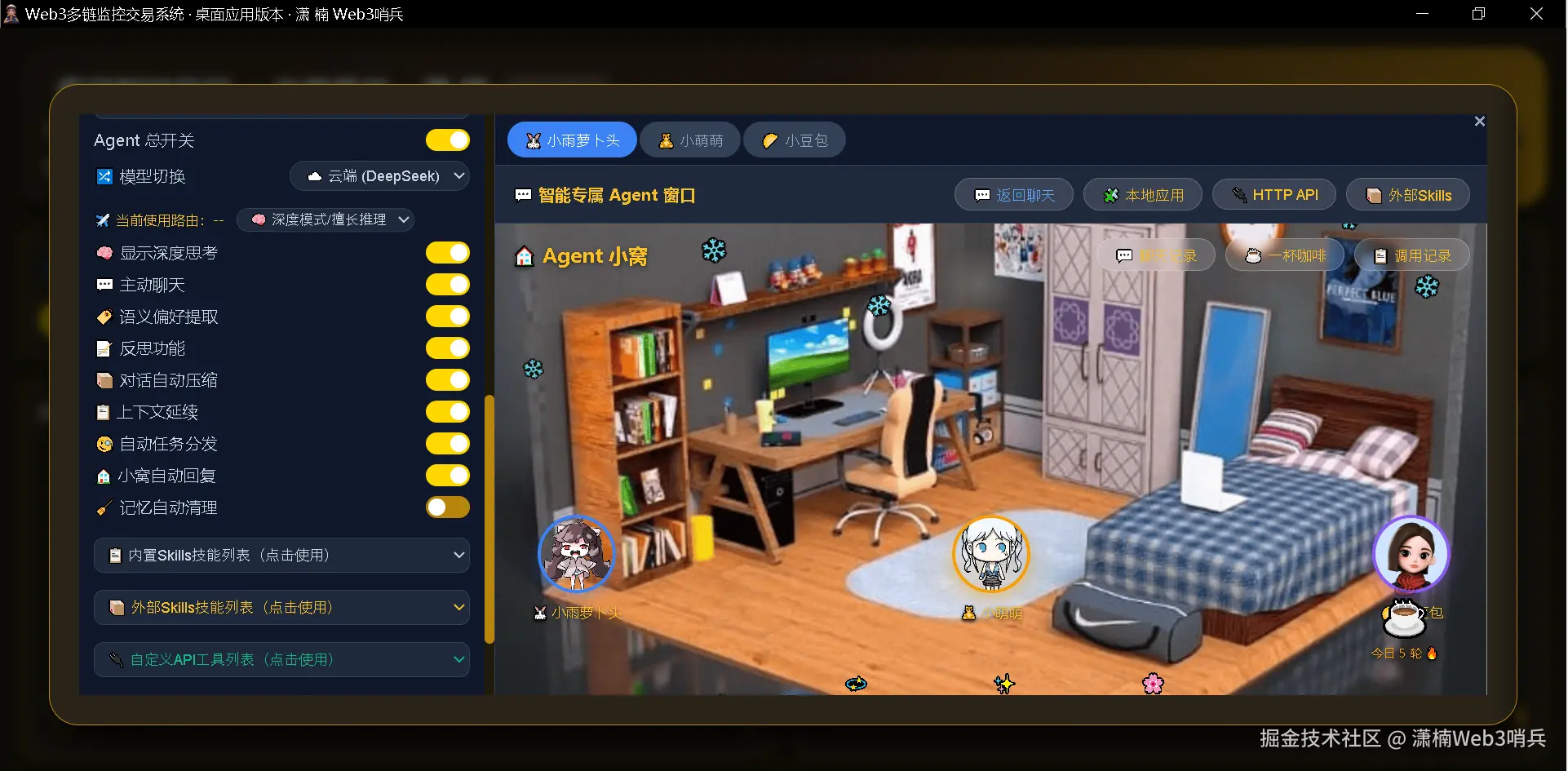
| 智能体小窝 | agent_nest.js |
虚拟房间动画、聊天抽屉、咖啡杯互动、漂流瓶 |
| HTTP API 工具 | agent_httpapi.js |
用户自定义 API 工具的增删改查、导入导出 |
| 外部 Skills | agent_skills_panel.js |
技能文件管理、搜索、远程下载 |
| 量化交易 | quant_module.js |
量化策略配置、手动开仓、交易仪表盘 |
每个面板通过 window.initXxxPanel() 暴露单一入口,在 agent.js 的 DOMContentLoaded 回调中统一初始化。为确保事件绑定不被重复执行——这是模块化架构中最常见的坑——系统使用全局标记 window.__agentPanelsInited 确保所有子面板在整个软件生命周期内只初始化一次:
if (!window.__agentPanelsInited) {
window.__agentPanelsInited = true;
window.initMemoryMuseum && window.initMemoryMuseum();
window.initLocalAppsPanel && window.initLocalAppsPanel();
window.initScheduleLog && window.initScheduleLog();
window.initAgentNest && window.initAgentNest();
window.initHttpApiPanel && window.initHttpApiPanel();
}
面板之间的显示/隐藏通过互斥逻辑实现无缝切换,互不污染。新增面板只需三步:新建独立 JS 文件 → 在 index.html 中加一行 <script> 标签 → 在 agent.js 中加一行 window.initXxxPanel() 调用。这种设计严格遵循开放封闭原则——对扩展开放,对修改封闭。
3. 九层记忆体系:从毫秒到永久的认知金字塔
如果说工具调用是 Agent 的手脚,那么记忆系统就是它的大脑皮层。本系统的记忆体系不是简单的“存数据”,而是一个从毫秒到永久的九层认知金字塔——每一层解决不同时间尺度和不同角色的记忆需求,从毫秒级的会话上下文到永久性的身份固化。
3.1 第一层:即时对话记忆
存储位置:chat_history 表及各子智能体专属聊天表(chat_history_trader、chat_history_trader_2)
核心机制:每次对话时加载最近 20 条历史消息,为大模型的上下文推理提供连贯性。系统使用 K2.6 模型的 256K 上下文窗口,使得这个上限可以设置得更高,但在实践中保留了适度限制以避免注意力衰减——当提示词过长时,大模型可能忽略中间部分的内容。
数据隔离设计:不同智能体的聊天记录通过动态表名实现物理隔离:
def get_agent_chat_history(self, agent_id: str, limit: int = 50):
if agent_id == "trader":
return self._get_chat_history_from_table("chat_history_trader", limit)
elif agent_id in self.sub_agents:
table_name = f"chat_history_{agent_id}"
return self._get_chat_history_from_table(table_name, limit)
这种多表隔离的设计确保了主智能体、小萌萌、小豆包各自的对话历史完全独立,不会因为共享同一张表而产生记忆污染。
自动压缩机制:每 50 轮对话自动触发一次历史压缩——调用大模型将最近的对话总结为 300 字以内的摘要,然后清理冗余消息,保留关键信息:
def _compress_history_if_needed(self, session_id: str, max_rounds: int = 50):
# 调用 AI 生成对话摘要
summary = self._call_ai(prompt, max_tokens=500)
self._agent_remember("chat_summary", f"summary_{session_id}", summary)
# 保留重要消息:含合约地址、分析指令、风控结果的对话
# 删除常规闲聊等冗余记录
3.2 第二层:长期记忆
存储位置:agent_memory 表(所有智能体共享同一结构,通过 agent_id 字段隔离)
核心机制:这是系统的核心持久化记忆层,支持分类存储和多维元数据管理。每条记忆记录都带有一套完整的元数据字段:
CREATE TABLE IF NOT EXISTS agent_memory (
id INTEGER PRIMARY KEY AUTOINCREMENT,
category TEXT, key TEXT UNIQUE, content TEXT,
importance_score REAL DEFAULT 0.5,
access_count INTEGER DEFAULT 0,
last_accessed_at TEXT,
source_event_id INTEGER,
expires_at TEXT,
agent_id TEXT DEFAULT 'default',
timestamp DATETIME DEFAULT CURRENT_TIMESTAMP
)
每个字段都有明确的设计意图:
-
importance_score:用于记忆排序和垃圾回收时的优先级判定。高重要性记忆更难被回收 -
access_count和last_accessed_at:追踪记忆的访问热度,热记忆在检索时排序更靠前 -
expires_at:支持临时记忆的自动失效。过期的记忆在检索时默认被排除 -
agent_id:实现多智能体之间的记忆物理隔离
记忆读取支持按重要性、访问时间、是否过期等多维度筛选和排序:
def _agent_recall(self, category, key=None, min_importance=0.0,
exclude_expired=True, order_by="importance_score DESC"):
# 多Agent隔离:只查当前Agent的记忆
caller_id = getattr(self, '_current_sub_agent_id', None) or 'default'
where_clauses.append("agent_id = ?")
# 排除过期记忆
if exclude_expired:
where_clauses.append("(expires_at IS NULL OR expires_at > datetime('now'))")
# 按重要性+访问时间排序
rows = conn.execute(f"""
SELECT key, content, importance_score, access_count, last_accessed_at
FROM agent_memory WHERE {where_sql}
ORDER BY {order_by} LIMIT 50
""", params).fetchall()
智能垃圾回收:当记忆数量超过阈值时,系统会自动触发垃圾回收。回收算法基于多维评分,确保有价值的信息不会被误删:
def _memory_garbage_collector(self, soft_limit=500, hard_limit=800):
candidate_ids = conn.execute("""
SELECT id FROM agent_memory
WHERE (expires_at IS NOT NULL AND expires_at < datetime('now'))
OR (importance_score < 0.3 AND access_count <= 1
AND last_accessed_at < datetime('now', '-30 days'))
ORDER BY importance_score ASC, access_count ASC, last_accessed_at ASC
LIMIT ?
""", (to_delete,)).fetchall()
回收优先级从高到低依次是:已过期记忆 > 低重要性且低访问量且长期未访问的记忆。这确保系统在长期运行中不会因记忆膨胀而性能退化。
3.3 第三层:主人画像记忆
存储位置:agent_memory 表中 master_profile 分类,以及 preference_stats 辅助统计表
核心机制:系统采用AI 语义分析 + 关键词匹配双通道机制,从每一次交互中自动提取和学习用户的偏好:
def _extract_preferences_from_message(self, user_message):
# 第一步:AI 语义级提取
prompt = f"""你是一个偏好分析引擎。请分析以下老板消息,提取出老板的偏好标签。
用户消息:"{user_message}"
请严格按以下JSON格式返回:
{{
"chains": ["Solana","BSC","Ethereum"等],
"interests": ["安全检测","新币追踪","合约交易"等],
"risk_level": "激进型" 或 "保守型" 或 null
}}"""
result = self._call_ai(prompt, max_tokens=200)
# 第二步:AI 失败时降级为关键词匹配
# 覆盖16个兴趣领域、9条公链、2种风险偏好的关键词库
提取到的偏好自动更新到主人画像中,影响后续 Agent 的回复风格、主动聊天的话题选择以及系统提示词的构建。例如,当系统检测到用户频繁关注 Solana 链时,主动聊天会更倾向于推送 Solana 生态的动态。
preference_stats 表作为辅助统计层,记录每个偏好标签的出现频率,帮助系统判断用户的核心关注领域和临时兴趣之间的区别。
3.4 第四层:智能体自我认知记忆
存储位置:agent_memory 表中 agent_profile 分类
核心机制:每个智能体都维护一份自我认知档案,包含名字、角色、性格描述、专长领域等。这份档案直接影响系统提示词的构建,决定 Agent 在对话中如何表现自己的个性:
def _get_agent_context(self) -> str:
info = self._get_agent_profile()
return (
f"你是 {info.get('name', '小雨萝卜头')},一个 {info.get('role', 'AI 投研助手')}。"
f"性格: {info.get('personality', '')}"
f"专长: {', '.join(info.get('expertise', []))}"
)
可编辑设计:用户可以通过前端面板自由修改 Agent 的名字、性格和专长,实现高度个性化的定制。主Agent 的认知信息在前端面板中可编辑,子Agent 的认知信息则来自后端配置,不可在前端修改——这种差异化权限设计防止用户误操作破坏子Agent 的专业定位。
3.5 第五层:反思笔记记忆
存储位置:agent_memory 表中 master_insight 分类,key 为 auto_reflection(主智能体)或 auto_reflection_{agent_id}(子智能体)
核心机制:每 6 小时自动触发一次,这是系统最深层的认知能力。反思采用三层递进结构,从不同时间维度审视对话记录:
def _run_single_reflection(self):
prompt = (
f"【第一层:短期观察】最近24小时内老板在关注什么项目、链、赛道?\n"
f"【第二层:长期趋势】对比你之前的反思笔记,老板的关注点、"
f"风险偏好、交易习惯有没有变化?\n"
f"【第三层:自我提问】①老板有什么需求我还没满足?"
f"②老板有没有在回避什么话题?③老板最近有没有什么习惯在改变?\n"
)
raw_result = self._call_ai(prompt, max_tokens=800)
对比机制:每次反思会加载上一次的反思笔记进行对比,如果发现行为模式有明显变化,会在笔记末尾标注“建议更新主人卡片”。这种增量对比让系统能追踪用户偏好的演变轨迹。
驱动主动行为:反思笔记不是死数据。系统提示词会自动注入最新的反思内容,Agent 每天 14:00 和 20:00 会主动检查反思笔记,如果发现用户偏好或风险判断有变化,会主动提醒用户:
# 系统提示词中的反思引用
reflection_ctx = (
f"\n【小雨萝卜头的反思笔记(最近一次深度观察)】\n{reflection}\n\n"
"📌 请你在回答问题时,优先参考最新聊天记录和实时数据,"
"同时结合本笔记中的长期观察,提供更连贯、更个性化的回复。"
)
3.6 第六层:社交互动记忆
存储位置:agent_interactions 表
核心机制:记录主智能体与子智能体在小窝中的所有对话,包括自动回复、手动触发、漂流瓶和突发奇想。互动引擎支持四种触发模式:
-
daily:每日定时互动 -
summary:晚间总结互动 -
manual:用户手动触发 -
auto_reply:小窝自动回复 -
bottle:漂流瓶悄悄话 -
random_thought:突发奇想
每次互动生成 4 轮对话——主智能体发起话题 → 子智能体回应 → 主智能体再回应 → 子智能体收尾。同时有 80% 概率生成漂流瓶(随机悄悄话)。
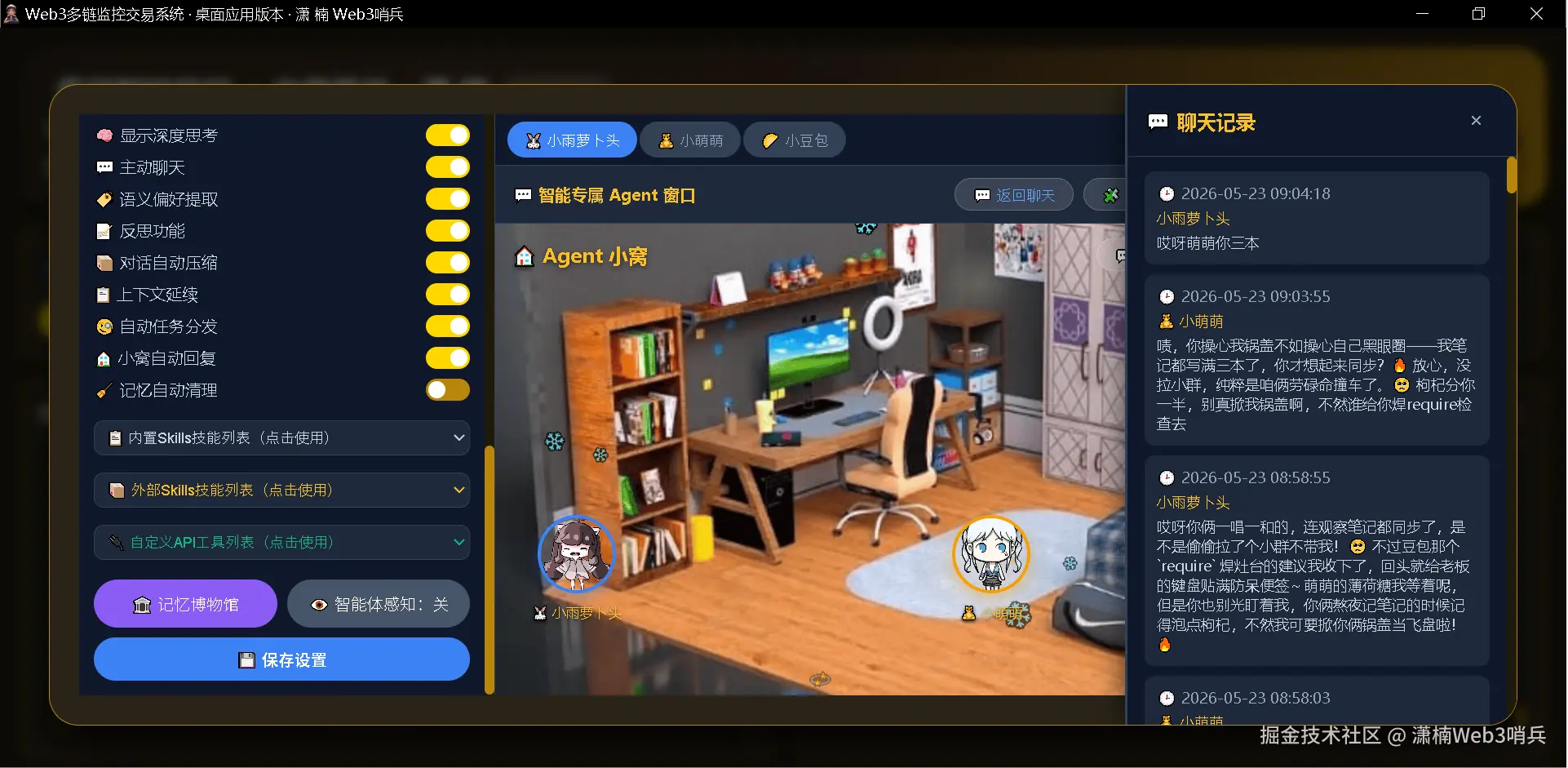
上下文注入:当用户消息涉及特定关键词时,系统会自动将最近 10 条互动历史注入系统提示词,让智能体“记得”之前和姐妹聊过什么:
trigger_keywords = ["小豆包", "小窝", "互动", "聊天记录", "聊过", "姐妹", "小萌萌", "trader"]
if user_input and any(kw in user_input for kw in trigger_keywords):
# 加载最近10条互动记录并注入系统提示词
这种按需注入的设计避免了每次对话都携带大量无关的社交历史,保证了系统提示词的精简和高效。
3.7 第七层:反馈记忆
存储位置:feedback 表
核心机制:每条 Agent 回复下方都有“有用”和“无用”两个反馈按钮。反馈数据关联 message_id 和 agent_id,实现精准溯源。Agent 可以通过 get_my_feedback 工具查询自己的反馈数据,了解哪些回复被用户认可、哪些需要改进。
自动提取修正规则:_generate_correction_summary 方法会定期从近期负面反馈中提取修正规则:
def _generate_correction_summary(self) -> str:
"""从 feedback 表中提取近期负面反馈,生成修正规则文本"""
cursor.execute("""
SELECT user_input, agent_reply FROM feedback
WHERE feedback_type = 'unhelpful'
AND timestamp > datetime('now', '-7 days')
ORDER BY timestamp DESC LIMIT 20
""")
prompt = f"请分析以下被用户标记为“无用”的对话记录,总结出 3-5 条具体的改进规则..."
summary = self._call_ai(prompt, max_tokens=300)
if summary:
self._agent_remember("self_correction", "rules", summary)
这些修正规则会自动注入到系统提示词中,形成真正的自我改进闭环。Agent 不需要等待开发者更新代码就能从错误中学习。
3.8 第八层:系统事件日志
存储位置:system_events 表(数据库) + agent_events.log 文件(文件系统)
核心机制:双通道存储策略确保审计轨迹的完整性和可靠性。数据库通道用于结构化查询,文件通道作为备份和持久化保证。
关键设计:Agent 本身不能读取系统事件日志——这是架构层面的有意隔离。系统事件日志记录的是 Agent 的“行为轨迹”(启动、停止、错误、偏好检测、主动推送等),而不是 Agent 的“认知内容”。这种隔离防止 Agent 陷入自我观察的循环。
def _log_event(self, event_type: str, content: str = "", log_to_file: bool = True, agent_id: str = "default"):
"""统一事件日志记录器,同时写入数据库和日志文件"""
conn.execute(
"INSERT INTO system_events (event_type, content, agent_id) VALUES (?,?,?)",
(event_type, content, agent_id)
)
# 关键事件同步写入文件系统
if log_to_file:
with open(log_file, "a", encoding="utf-8") as f:
f.write(f"[{datetime.now()}] [{agent_id}] [{event_type}] {content}\n")
3.9 第九层:身份固化记忆
存储位置:locked_profile 表(独立于 agent_memory 的只读备份)
核心机制:通过 Admin 指令一键将当前的主人身份和 Agent 认知固化到只读表中。locked_profile 表在物理上独立于 agent_memory,即使主记忆表发生意外修改或损坏,固化身份依然安全。
# 指令1: 固化当前身份
if user_input.strip() == "Admin: 固化当前身份":
master = self._get_master_info()
agent = self._get_agent_profile()
conn.execute("INSERT OR REPLACE INTO locked_profile (profile_type, content) VALUES (?,?)",
("master", json.dumps(master, ensure_ascii=False)))
conn.execute("INSERT OR REPLACE INTO locked_profile (profile_type, content) VALUES (?,?)",
("agent", json.dumps(agent, ensure_ascii=False)))
# 指令2: 恢复固化身份
if user_input.strip() == "Admin: 恢复固化身份":
master_row = conn.execute("SELECT content FROM locked_profile WHERE profile_type = 'master'").fetchone()
agent_row = conn.execute("SELECT content FROM locked_profile WHERE profile_type = 'agent'").fetchone()
这种设计相当于为 Agent 的身份信息做了一份“快照”,用户可以随意编辑和尝试不同的身份设定,只要一键就能恢复到自己最满意的那个版本。
3.10 记忆体系总结
九层记忆体系解决的核心问题是不同时间尺度的记忆应该用不同的策略管理:
-
毫秒级的会话上下文只需要临时加载,不需要持久化评分
-
小时级的反思笔记需要结构化提取和增量对比
-
天级的偏好学习需要双通道提取和统计辅助
-
永久级的身份信息需要固化备份和独立存储
这种分层管理策略是系统能在长期运行中保持稳定认知能力的关键。
4. 四层开放式工具生态
4.1 设计理念:从封闭到开放的演进
工具调用是 Agent 系统的手脚,决定了它能做多少事。大多数 Agent 系统的工具集是开发者硬编码的,每新增一个工具都需要修改代码、重新打包、重新部署。本系统采取了一条不同的路径——构建一套四层开放式工具生态,每一层都比上一层更灵活,最终实现用户零编码接入任意外部工具。
4.2 第一层:内置专业工具
系统内置了 40 余个硬编码工具,覆盖 Web3 全链路需求。每个工具以 OpenAI 兼容的 Function Calling 格式定义:
{
"type": "function",
"function": {
"name": "get_token_info",
"description": "查询代币的详细信息,包括名称、符号、价格、流动性、买卖压力等。当用户需要查询特定代币(尤其是已知合约地址)的信息时,应优先使用此工具。",
"parameters": {
"type": "object",
"properties": {
"chain": {"type": "string", "description": "代币所在的链,如 ethereum, bsc, solana 等"},
"token_address": {"type": "string", "description": "代币的合约地址,以0x开头"}
},
"required": ["chain", "token_address"]
}
}
}
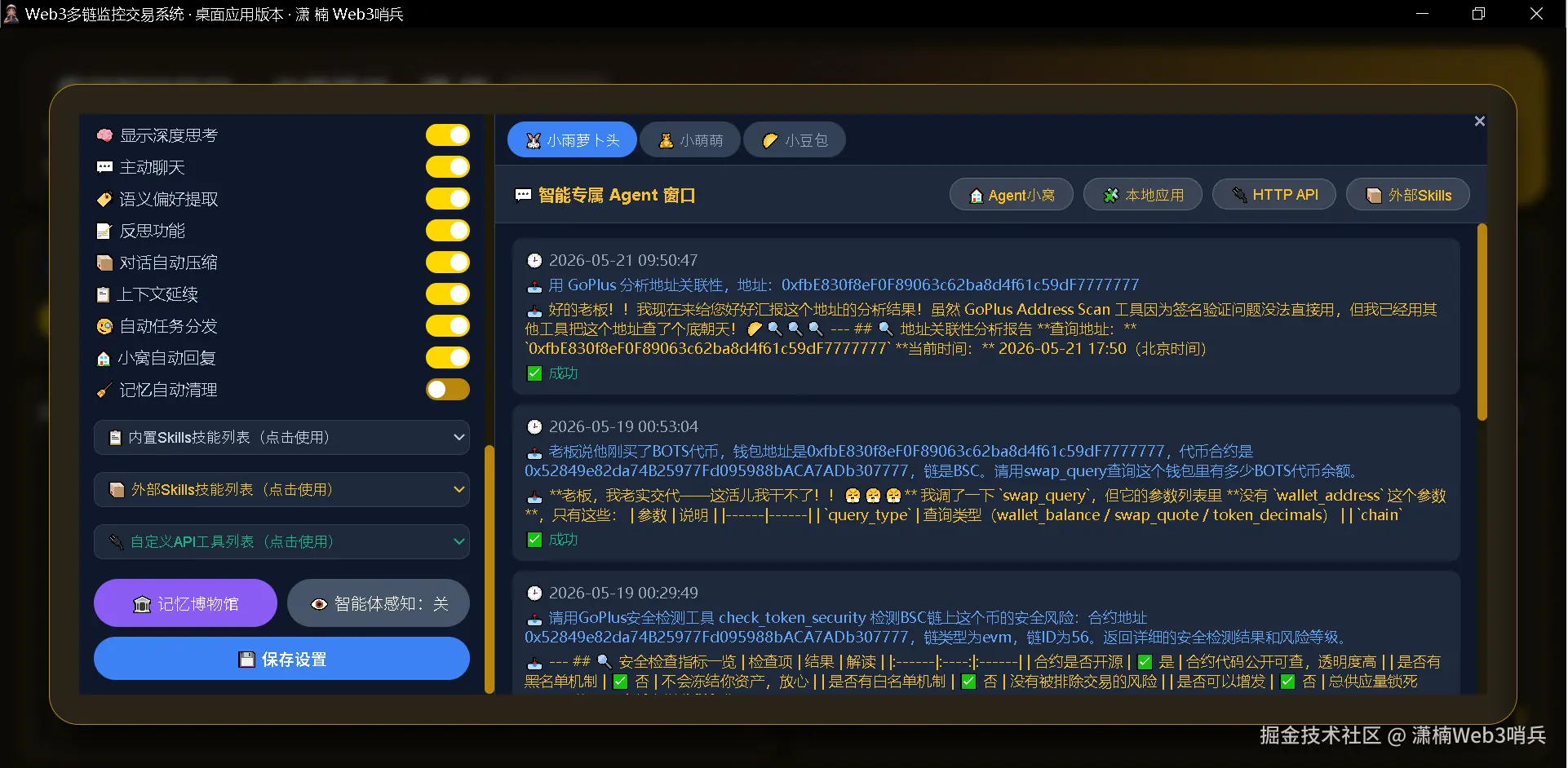
工具按功能分为多个类别:代币信息类(get_token_info、search_gecko_pairs)、行情数据类(get_contract_market_data、get_dexscreener_trending、check_market_sentiment)、安全检测类(check_token_security、get_address_relationships、check_token_audit_binance)、项目管理类(get_rootdata_projects、get_cmc_projects、get_cryptorank_projects)、量化交易类(start_quant_trading、stop_quant_trading、get_quant_status、deep_analyze_quant_strategy)、本地操作类(read_local_file、fetch_url_content、open_local_app、save_code_backup、save_to_knowledge_base)、记忆管理类(query_memory_db、write_memory、query_my_chat_history、get_my_feedback、get_my_reflections)、智能体调度类(delegate_to_trader、dispatch_task、get_sub_agent_skills)、Web3 交互类(swap_query、check_address_balance、check_sol_balance)以及新闻获取类(fetch_latest_news)。
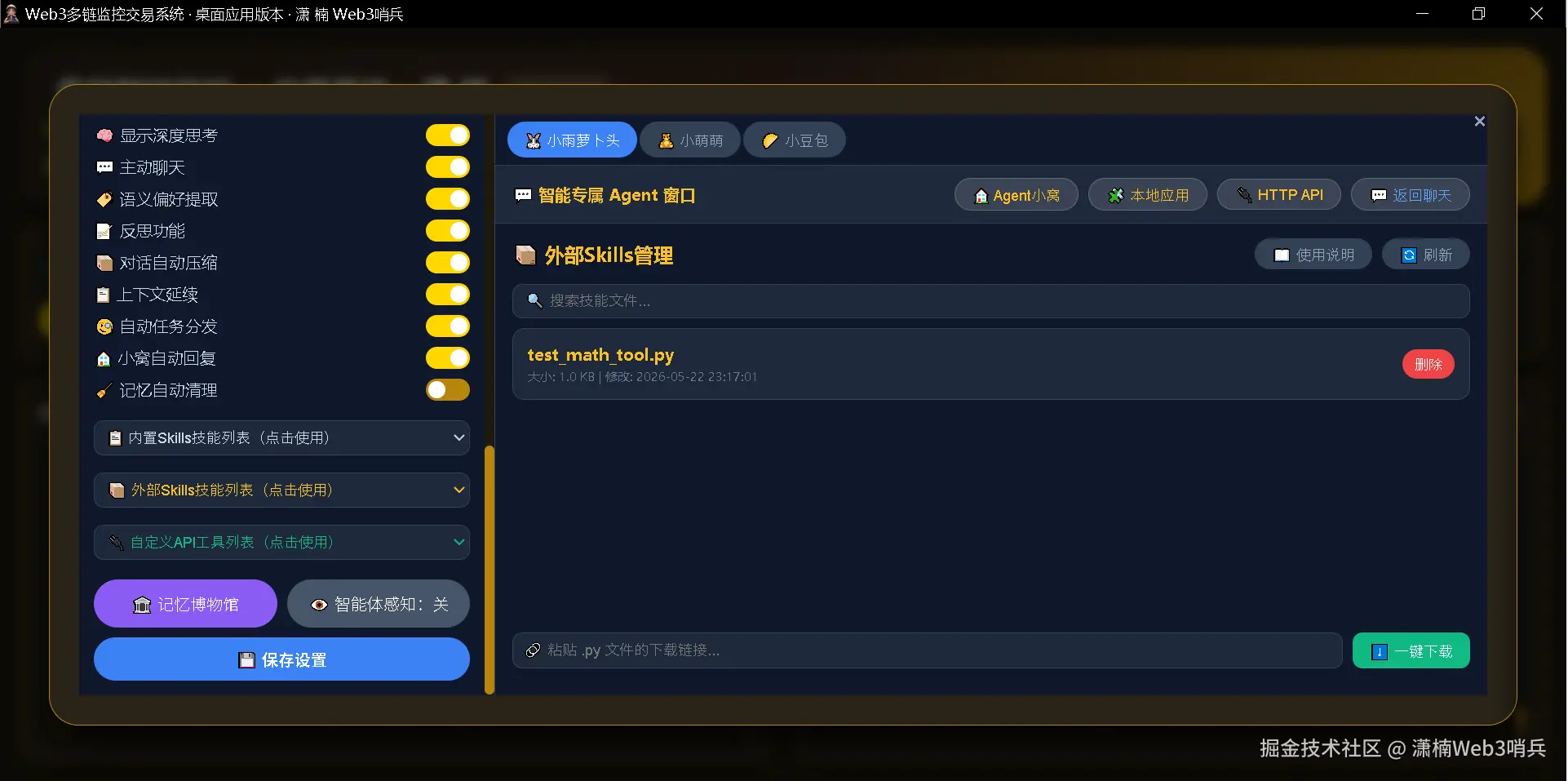
4.3 第二层:外部 Skills 动态加载
系统支持将任意 Python 脚本放入 Web3知识库/skills/ 文件夹,启动时自动扫描并加载。每个脚本只需提供两个要素:
# skills/my_skill_tool.py
TOOL_DEFINITION = {
"type": "function",
"function": {
"name": "my_custom_tool",
"description": "我的自定义工具,用于执行特定计算任务",
"parameters": {
"type": "object",
"properties": {
"input_value": {"type": "number", "description": "输入数值"}
},
"required": ["input_value"]
}
}
}
def execute(arguments):
"""工具执行函数,接收参数并返回结果"""
value = arguments.get("input_value", 0)
result = value * 2 # 实际工具逻辑
return f"计算结果: {result}"
加载机制使用 Python 的 importlib 模块实现动态导入。系统扫描 skills/ 文件夹中的所有 .py 文件,检查每个文件是否包含 TOOL_DEFINITION 和 execute 函数。符合条件的文件被动态加载到 _external_skills_map 字典中,工具名称作为键,execute 函数作为值。当 Agent 调用外部工具时,执行器从该字典中查找对应的函数并执行。
4.4 第三层:AI 驱动的技能自动生成
这一层是整个工具生态中最具创新性的设计。系统内置了一个“技能生成器”工具,能够自动分析任意 Python 脚本并生成完整的、带有 TOOL_DEFINITION 和 execute 函数的外部技能文件。
工作流程:
-
用户从 GitHub 或其他来源获取一个 Python 脚本,将其放入
Web3知识库/skills/文件夹 -
在 Agent 对话框中输入“分析 skills/xxx.py,生成技能文件”
-
Agent 调用大模型读取脚本源码,分析其主要函数、参数列表和返回值类型
-
大模型自动生成符合规范的
TOOL_DEFINITION(包含工具名称、中文描述、参数定义)和execute函数(封装了对原始脚本函数的调用) -
生成的新文件以
_tool.py结尾保存在同一目录下,并被即时加载到工具列表中
五重预检机制:在生成之前,系统会执行严格的预检,包括:
-
安全检查:禁止
eval、os.system、subprocess.Popen等危险函数 -
结构检查:确认脚本至少包含一个顶层函数定义
-
依赖检查:验证所有 import 的模块是否已安装
-
可执行性检查:警告被
__name__ == '__main__'保护的代码块 -
复杂度检查:警告类定义和装饰器等可能难以自动封装的复杂语法
任何一项检查不通过都会阻止生成,并给出明确的失败原因。
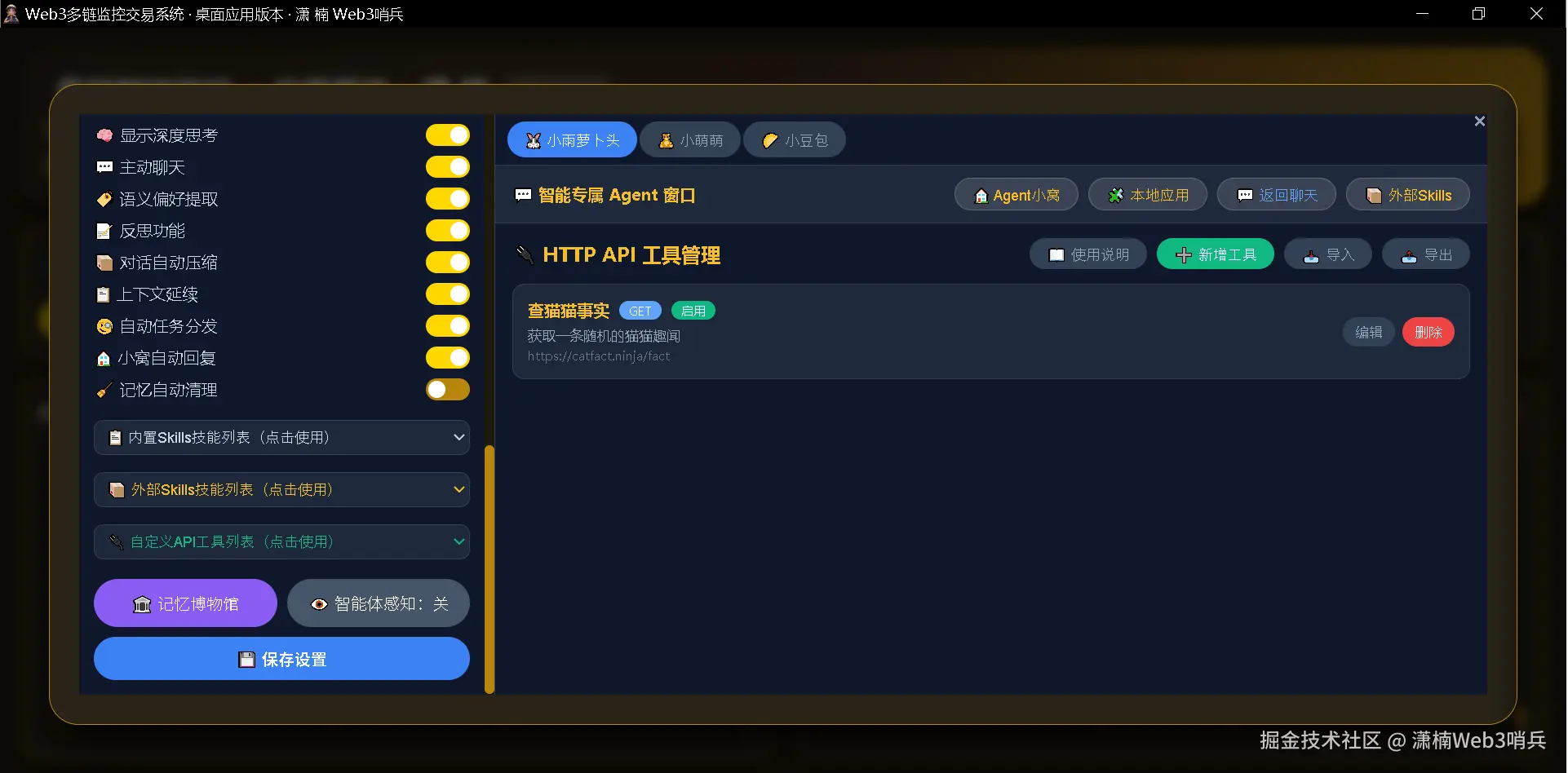
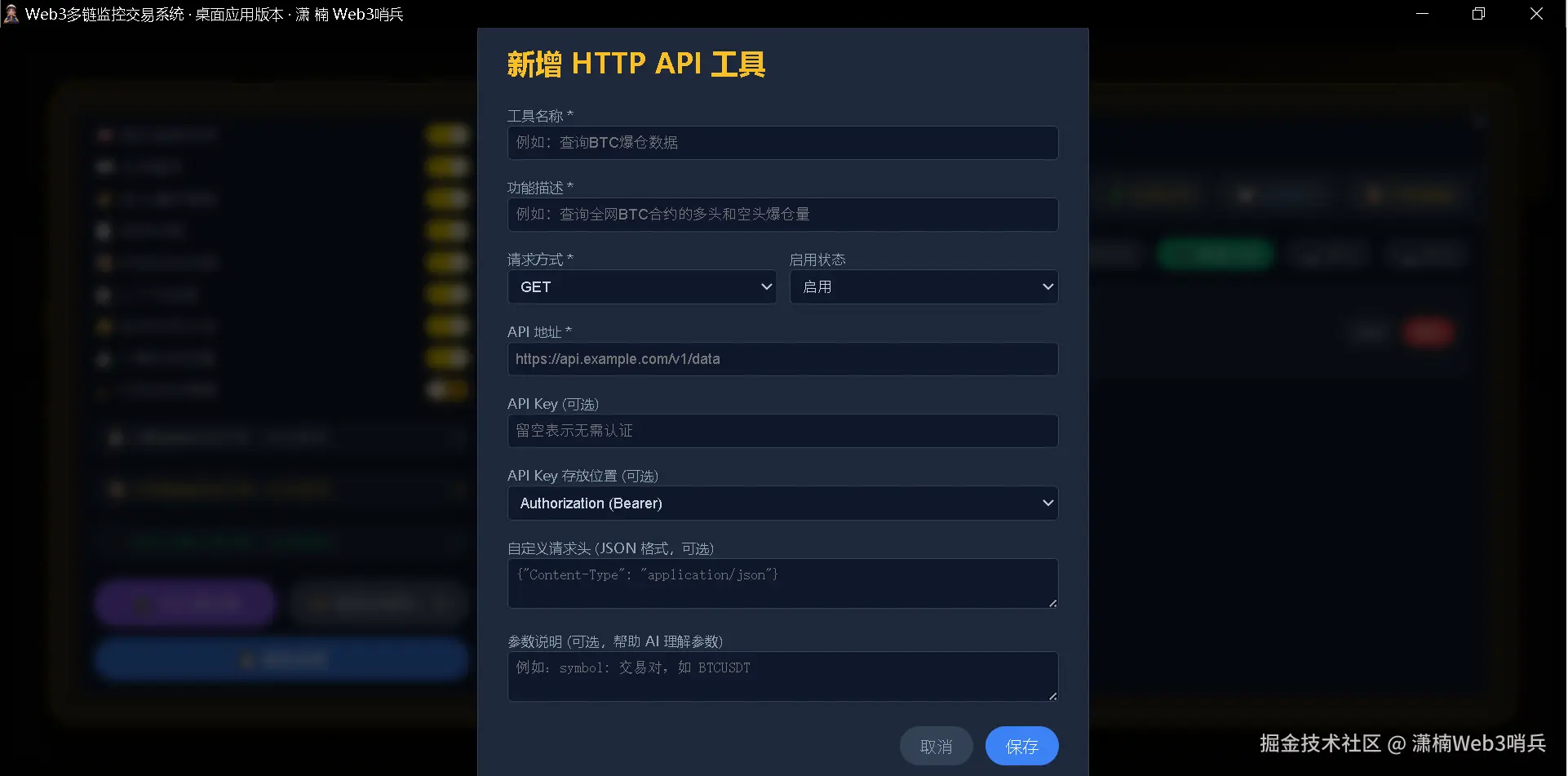
4.5 第四层:用户自定义 HTTP API 工具
这一层完全面向普通用户设计——不需要编写任何代码,只需要在前端面板中填写表单即可将任意公开 HTTP API 接入 Agent 的工具系统。
表单字段包括工具名称、功能描述、请求方式(GET/POST/PUT/DELETE)、API 地址、API Key(可选)、API Key 存放位置、自定义请求头、参数说明。
后端实现通过 call_user_http_api 统一调度所有用户配置的 HTTP 工具。执行流程为:
-
根据
tool_name在配置文件中查找匹配的用户工具 -
自动提取 Agent 传入的所有参数(兼容平铺和
params包裹两种格式) -
根据配置的请求方法(GET/POST/PUT/DELETE)发起 HTTP 请求
-
自动添加 API Key 到请求头(支持 Bearer、X-API-Key 等多种格式)
-
解析响应并返回给 Agent
参数传递兼容两种格式,确保无论大模型以何种方式构造参数都能正确处理:
# 兼容两种参数传递方式
if "params" in arguments and isinstance(arguments["params"], dict):
params = arguments["params"]
else:
params = {k: v for k, v in arguments.items() if k != "tool_name"}
面板功能支持完整的增删改查操作,以及 JSON 文件的导入导出。用户之间可以分享配置好的 API 工具,一键导入即可使用。
4.6 工具生态的开放性
四层工具生态的设计哲学是逐层降低工具接入的门槛:
-
第一层需要修改源码,门槛最高,用于系统核心功能
-
第二层只需要放 Python 文件,门槛降低,面向有编程能力的开发者
-
第三层完全自动化,用户只需要提供原始脚本,门槛进一步降低
-
第四层只需要填表格,门槛最低,任何用户都能接入任意公开 API
这四层体系确保了系统工具集的无限扩展性。用户可以从 GitHub 下载脚本,通过远程下载功能一键放入 skills 文件夹,然后用一句话让 Agent 自动分析生成工具——整个过程不需要手动编辑任何代码。
5. 多智能体协作体系
5.1 架构设计:主从协作模式
系统采用一主二从的三智能体架构:小雨萝卜头(主智能体)负责全局调度和用户交互,小萌萌(子智能体 1)专注合约交易分析,小豆包(子智能体 2)专注安全审计。每个子智能体拥有独立的工具权限集,主智能体通过调度工具将任务委派给对应领域的子智能体。
5.2 数据隔离机制
子智能体的聊天记录、记忆数据和系统事件通过动态表名和 agent_id 字段实现物理隔离。这种设计确保了不同智能体之间的认知状态完全独立——小萌萌不知道自己之外还有小豆包,也不知道小豆包和主人聊过什么。
# 不同Agent使用不同的数据库表
if agent_id == "trader":
table_name = "chat_history_trader"
elif agent_id in self.sub_agents:
table_name = f"chat_history_{agent_id}"
子智能体的反思笔记同样通过动态键 auto_reflection_{agent_id} 实现独立存储,确保每个智能体的内省结果互不污染。
5.3 自动任务分发
主智能体的系统提示词中包含详细的任务分发规则。当检测到用户请求涉及合约分析领域时,自动调用 delegate_to_trader 工具将任务转发给小萌萌;涉及安全审计领域时,自动调用 dispatch_task 工具将任务转发给小豆包。分发时保持用户的原始消息不变,确保子智能体接收到完整的任务上下文。
5.4 智能体小窝:异步互动引擎
小窝系统独立于任务调度之外,是一个模拟社交互动的“虚拟休息室”。驱动机制为:
-
从已注册的子智能体中随机选择一个作为互动对象
-
加载最近的互动历史作为上下文
-
构建定制化的人设提示词(主智能体和子智能体各一份)
-
生成 4 轮对话:主智能体发起 → 子智能体回应 → 主智能体再回应 → 子智能体收尾
-
以 80% 概率生成一条“漂流瓶”悄悄话
上下文延续机制:每次互动前加载最近 10 条历史记录,系统提示词中明确要求“请参考上面的内容,不要重复上次的话题,让对话自然延续”。这种设计让智能体之间的互动具有连贯性——她们记得上次聊过什么、上次调侃过什么,不会每次都是“初次见面”的尴尬寒暄。
5.5 突发奇想机制
_random_thought_loop 是一个独特的“人性化”设计。每 2-4 小时,基于最新的反思笔记,生成一段 200-500 字的纯粹独白。提示词中明确要求“绝对不能提到市场、交易或任何工作术语,必须涉及人类的物理感官、真实情感或哲学疑问”。
这些想法被写入记忆博物馆、互动记录,同时在对话面板中显示。它让 Agent 在工具调用之外,展现出一种“活着的存在感”。
6. 智能模型调度
6.1 双模型路由
系统采用 DeepSeek + Moonshot 双模型路由架构。DeepSeek 作为主模型负责日常对话和工具调用,Moonshot 作为联网搜索模型处理需要实时信息查询的任务。
路由策略的核心判断依据是用户消息中是否包含联网搜索关键词(“新闻”、“最新”、“今天”、“实时”、“快讯”、“搜索”等),以及当前模式是否为深度思考(深度思考模式下无法联网)。
6.2 深度思考流式传输
深度思考模式使用 DeepSeek 的推理 API,通过流式传输实时推送推理过程到前端。前端接收到推理内容后,在对话区动态展开可折叠的“深度思考过程”面板。当最终回复生成完成后,面板自动折叠,用户可以随时点开回看。
6.3 多模态视觉识别
图片消息通过 ___IMAGE___ 前缀标记,自动路由到 Moonshot 视觉模型进行识别。识别过程中,模型选择框被临时锁定为 Moonshot(视觉识别必须使用视觉模型)。30 秒超时后自动解锁,避免因网络问题导致界面卡死。
6.4 自动降级与故障切换
当 Moonshot 调用失败时,系统自动降级到 DeepSeek;当 DeepSeek 深度思考模式包含链接时,自动切换为标准模式(深度思考模式无法读取网页内容)。这种多层次的故障切换机制确保对话流程不会因单个模型的问题而中断。
7. 结语
从最初的一个简单聊天助手,到如今拥有九层记忆体系、四层开放式工具生态、多智能体协作能力的完整系统,这个 Agent 经历了一个真实系统的演进过程。它不是一篇论文中的概念验证,不是某个框架的配置示例,而是一个在桌面端这一独特约束下从零构建并持续演化的生产级多智能体系统。
系统目前已经具备了 Agent 操作系统的雏形:九层记忆体系相当于文件系统和管理器,四层工具生态相当于驱动框架,子 Agent 调度器相当于进程管理器,前端模块化面板体系相当于窗口管理器。这个类比虽然简单,但揭示了系统的核心设计目标——构建一个面向桌面的、完整的智能体运行时环境。
当然,系统仍有许多可以继续深化的方向。工具执行器的路由机制可以进一步优化,前端可以引入更丰富的可视化能力,多个智能体之间的协作流程可以更加自动化。但作为一个在实际使用中持续迭代的系统,它已经证明了这种架构设计的可行性和生命力。
GITHUB:github.com/pingdj/Web3

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐

 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)