【Linux网络】Linux 网络编程:HTTP(五)HTTP收尾,从Cookie会话保持、抓包问题到 HTTPS 初识
HTTP Cookie(也称为 Web Cookie、浏览器 Cookie)是服务器发送到用户浏览器并保存在本地的一小块数据。当浏览器后续向同一服务器发起请求时,会自动将这些 Cookie 携带在请求头中发送回服务器。Cookie 的核心作用是告知服务器两个请求是否来自同一个浏览器,从而实现用户登录状态保持、用户偏好记录、购物车功能等。HTTP Session 是一种服务端状态存储机制。其核心思想

《Linux操作系统编程详解》《笔试/面试常见算法:从基础到进阶》《Python干货分享》
🎬 艾莉丝的简介:

文章目录

HTTP收尾思维导图
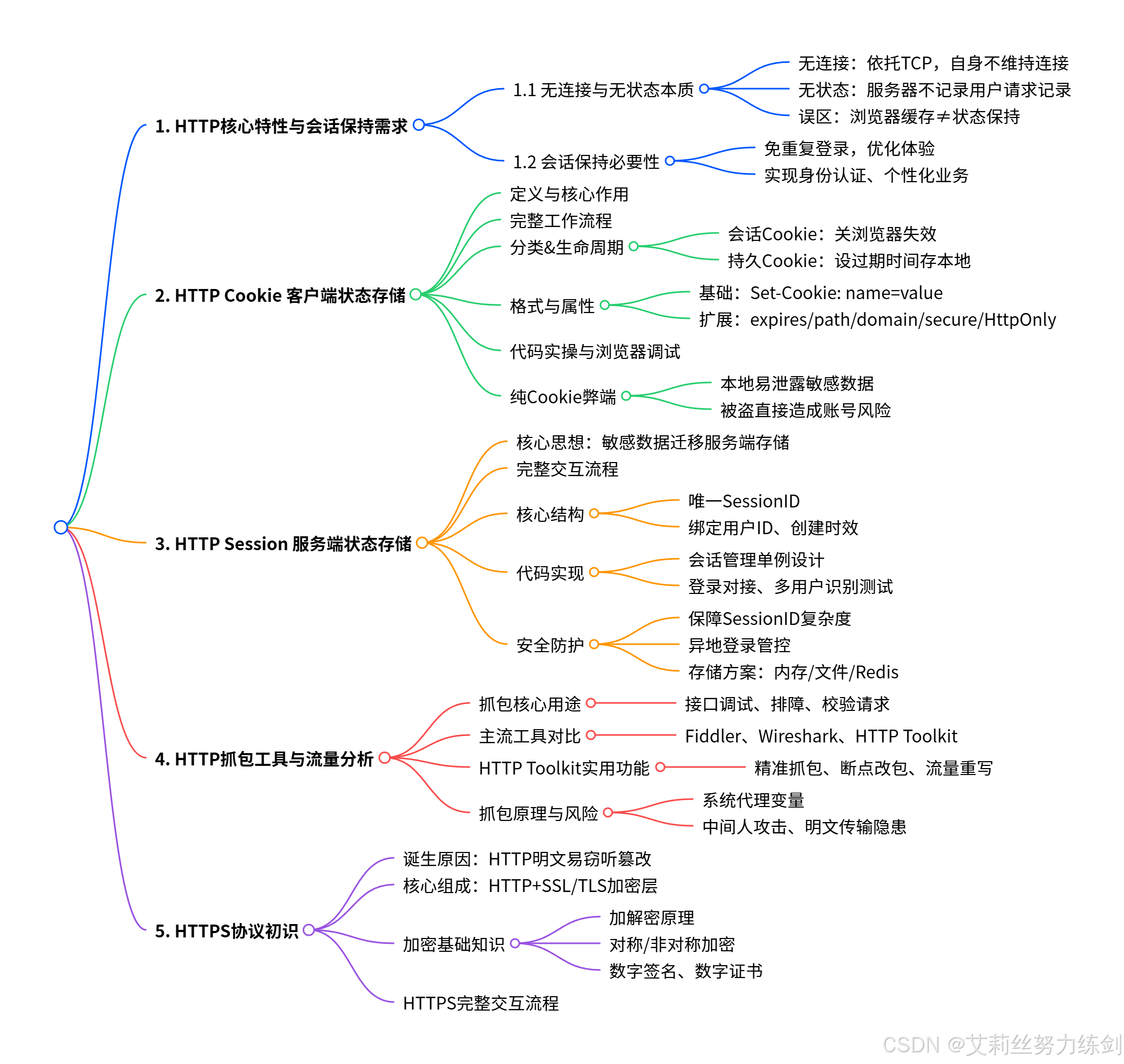
HTTP协议收尾学习框架
HTTP协议收尾学习框架
├─ 1. HTTP核心特性与会话保持需求
│ ├─ 1.1 HTTP的无连接与无状态本质
│ │ ├─ 无连接:HTTP本身不维护连接,依赖TCP底层
│ │ ├─ 无状态:服务器不记录用户的历史请求
│ │ └─ 误区澄清:浏览器缓存≠HTTP状态保持
│ └─ 1.2 会话保持的必要性
│ ├─ 避免频繁身份验证,提升用户体验
│ └─ 实现用户权限控制与个性化服务
├─ 2. HTTP Cookie:客户端状态存储
│ ├─ 2.1 Cookie定义与核心作用
│ ├─ 2.2 Cookie完整工作流程
│ ├─ 2.3 Cookie分类与生命周期
│ │ ├─ 会话Cookie:浏览器关闭即失效
│ │ └─ 持久Cookie:带过期时间,存储为本地文件
│ ├─ 2.4 Cookie格式与核心属性
│ │ ├─ 基本格式:Set-Cookie: <name>=<value>
│ │ └─ 扩展属性:expires、path、domain、secure、HttpOnly
│ ├─ 2.5 Cookie代码实现与实验
│ │ ├─ 服务端Set-Cookie代码编写
│ │ ├─ 浏览器Cookie查看与删除
│ │ └─ 路径、过期时间等属性测试
│ └─ 2.6 纯Cookie方案的安全缺陷
│ ├─ 本地存储易泄露用户敏感信息
│ └─ Cookie被盗取直接导致账号被盗
├─ 3. HTTP Session:服务端状态存储
│ ├─ 3.1 Session定义与核心思想
│ │ └─ 本质:将用户敏感信息从客户端转移到服务端
│ ├─ 3.2 Session完整工作流程
│ ├─ 3.3 Session核心数据结构
│ │ ├─ Session ID:全局唯一随机字符串
│ │ ├─ User ID:关联用户身份
│ │ └─ 创建时间:用于计算过期时间
│ ├─ 3.4 Session代码实现与实验
│ │ ├─ SessionManager单例类设计
│ │ ├─ 登录接口集成Session
│ │ └─ 多用户会话识别测试
│ └─ 3.5 Session安全性与防护
│ ├─ Session ID的随机性与长度要求
│ ├─ 异地登录检测与强制失效
│ └─ 服务端Session存储方案(内存/文件/Redis)
├─ 4. HTTP抓包工具与流量分析
│ ├─ 4.1 抓包工具的核心价值
│ │ ├─ 调试HTTP请求与响应
│ │ ├─ 排查网络问题
│ │ └─ 验证接口正确性
│ ├─ 4.2 主流抓包工具对比
│ │ ├─ Fiddler:功能全面的HTTP代理工具
│ │ ├─ Wireshark:底层网络协议分析器
│ │ └─ HTTP Toolkit:零配置开源跨平台工具
│ ├─ 4.3 HTTP Toolkit核心功能
│ │ ├─ 一键抓包:精准捕获特定应用流量
│ │ ├─ 断点修改:实时编辑请求与响应
│ │ └─ 自动重写规则:批量处理流量
│ └─ 4.4 抓包原理与代理劫持
│ ├─ 系统代理环境变量(HTTP_PROXY/HTTPS_PROXY)
│ ├─ 中间人攻击原理
│ └─ HTTP明文传输的安全隐患
└─ 5. HTTPS协议初识
├─ 5.1 HTTPS诞生背景
│ └─ HTTP明文传输导致数据被窃听、篡改
├─ 5.2 HTTPS核心概念
│ └─ HTTP + SSL/TLS加密层
├─ 5.3 加密基础概念
│ ├─ 加密与解密的定义
│ ├─ 对称加密与非对称加密
│ └─ 数字签名与证书
└─ 5.4 HTTPS工作流程概述
导入语
在日常使用互联网的过程中,我们会遇到很多需要保持用户状态的场景:登录网站后跨页面保持登录状态、点击 “记住我” 实现长期免登录、网站根据用户偏好展示个性化内容等。这些功能的实现都依赖于 HTTP 协议的会话保持机制。
HTTP 协议本身是无连接、无状态的,它不会记录用户的历史请求信息。为了解决这一问题,工程师们先后设计了 Cookie 和 Session 两种机制,共同实现用户状态的持久化。同时,HTTP 的明文传输特性带来了数据泄露和篡改的风险,这催生了 HTTPS 协议,通过加密技术保障通信安全。
本文将从 HTTP 协议的核心特性出发,系统讲解 Cookie 和 Session 的工作原理、代码实现与安全问题,介绍主流 HTTP 抓包工具的使用方法与原理,并初步阐述 HTTPS 协议的核心概念与加密机制,为后续学习传输层协议奠定基础。
1 ~> HTTP 核心特性与会话保持需求
1.1 HTTP 的无连接与无状态本质
HTTP 协议最核心的两个特性是无连接和无状态,这是所有会话保持机制需要解决的根本问题。
无连接:HTTP 协议本身不维护客户端与服务器之间的连接状态。HTTP 运行在 TCP 协议之上,TCP 负责建立和维护连接,HTTP 仅利用 TCP 连接传输数据,传输完成后 HTTP 本身不保留任何连接信息。
无状态:HTTP 服务器不会记录任何来自客户端的历史请求信息。对于服务器而言,每一个 HTTP 请求都是独立的,即使同一个客户端连续发送多个请求,服务器也会将其视为互不相关的新请求。
需要澄清一个常见误区:浏览器缓存是浏览器的功能,与 HTTP 协议本身无关。站在 HTTP 协议的角度,它不负责也不关心任何状态的保持,所有状态保持工作都需要在应用层通过额外机制实现。
1.2 一个网站为什么要记住用户?会话保持的必要性
如果没有会话保持机制,用户在访问网站的不同页面时,每次都需要重新进行身份验证,这会严重影响用户体验。同时,服务器也无法根据用户身份进行权限控制和个性化服务。
会话保持的核心目的有两个:
- 提升用户体验:避免用户在访问不同页面时频繁输入账号密码,实现无缝浏览。
- 实现权限控制:服务器可以根据用户身份判断其是否有权限访问特定资源,如 VIP 内容、个人中心等。
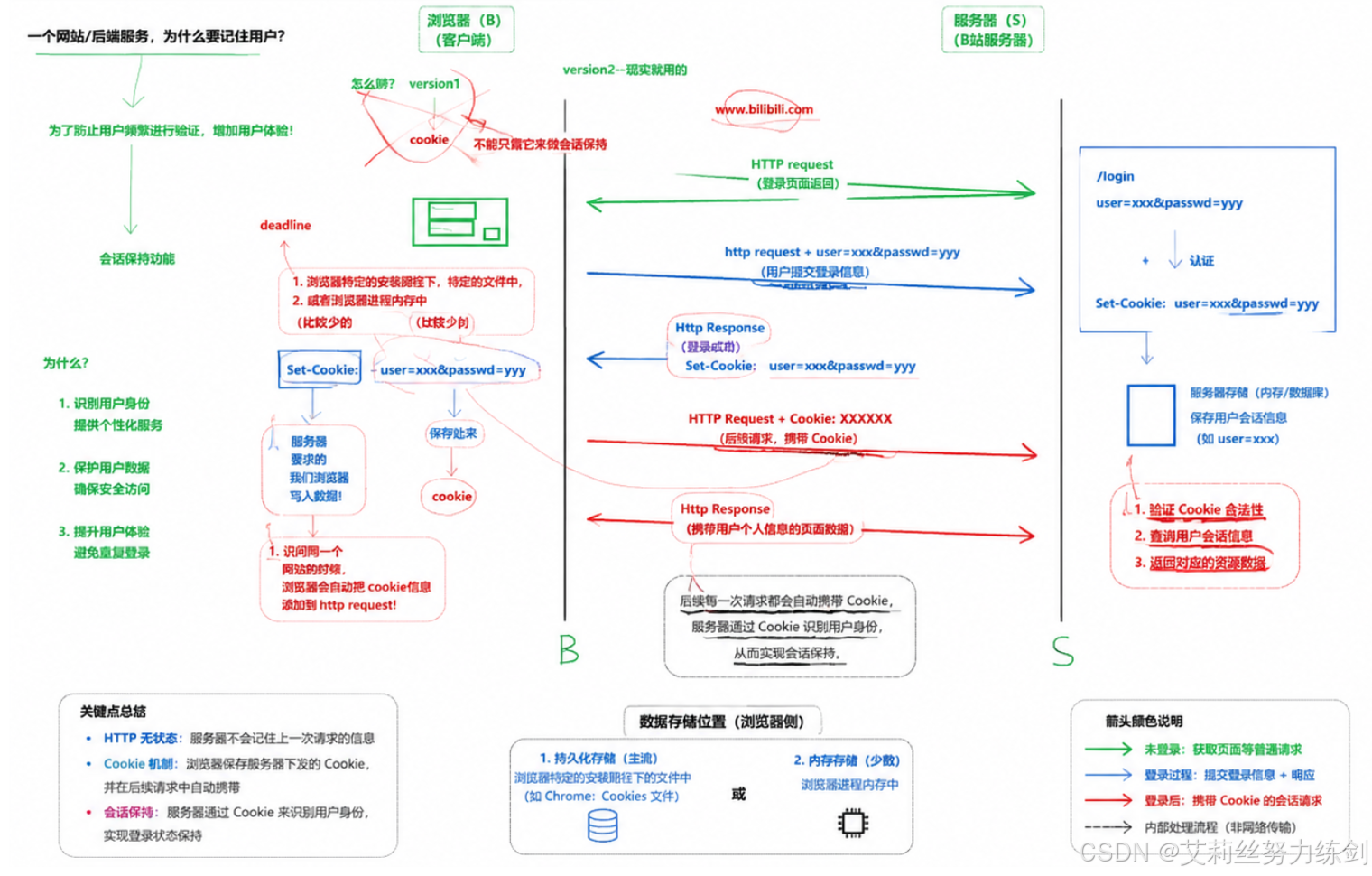
2 ~> HTTP Cookie:客户端状态存储机制
2.1 Cookie 的定义与核心作用
HTTP Cookie(也称为 Web Cookie、浏览器 Cookie)是服务器发送到用户浏览器并保存在本地的一小块数据。当浏览器后续向同一服务器发起请求时,会自动将这些 Cookie 携带在请求头中发送回服务器。
Cookie 的核心作用是告知服务器两个请求是否来自同一个浏览器,从而实现用户登录状态保持、用户偏好记录、购物车功能等。
2.2 Cookie 的完整工作流程
Cookie 的工作过程分为三个步骤:
- 首次访问与 Cookie 下发:用户第一次访问网站时,浏览器发送无 Cookie 的 HTTP 请求。服务器处理请求后,在响应头中添加
Set-Cookie字段,将需要保存的信息发送给浏览器。 - 浏览器本地存储:浏览器解析
Set-Cookie字段,将 Cookie 信息保存在本地。根据类型不同,Cookie 可能保存在浏览器进程内存中,也可能保存在硬盘文件中。 - 后续请求自动携带:用户再次向同一服务器发送请求时,浏览器自动在请求头中添加
Cookie字段,将保存的 Cookie 信息发送给服务器。服务器解析 Cookie 后识别用户身份。
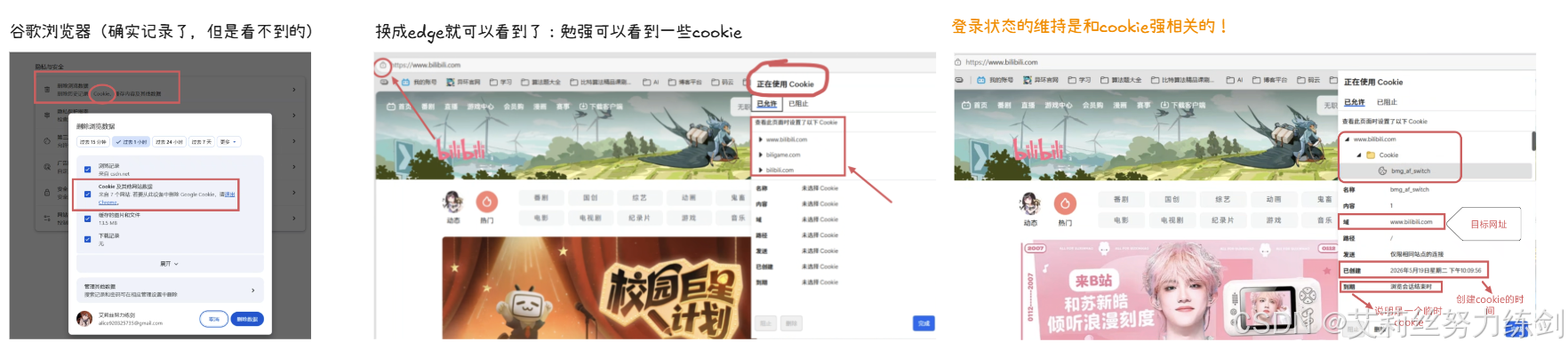
2.3 Cookie 的分类与生命周期
根据生命周期不同,Cookie 分为两大类:
- 会话 Cookie(Session Cookie):无明确过期时间,保存在浏览器进程内存中。浏览器关闭时,会话 Cookie 自动失效。通常用于保存临时会话信息。
- 持久 Cookie(Persistent Cookie):通过
expires或max-age属性设置明确过期时间。保存在硬盘文件中,即使关闭浏览器或重启电脑,只要在过期时间内,Cookie 依然有效。“记住我” 功能即通过持久 Cookie 实现。
Cookie 并非永久有效,即使是持久 Cookie 也有最长有效期(通常为几周至几个月)。过期后浏览器会自动删除 Cookie,用户需要重新登录。
2.4 Cookie 的格式与核心属性
Cookie 的基本格式为:
Set-Cookie: <name>=<value>
其中<name>是 Cookie 名称,<value>是 Cookie 值。
实际应用中通常会添加扩展属性控制 Cookie 行为,完整示例如下:
Set-Cookie: username=peter; expires=Thu, 18 Dec 2024 12:00:00 UTC; path=/; domain=.example.com; secure; HttpOnly
各属性含义:
expires:Cookie 过期时间,必须遵循 RFC 1123 标准格式,如Thu, 18 Dec 2024 12:00:00 UTC。path:Cookie 有效路径。只有请求 URL 路径匹配该属性时,浏览器才会发送该 Cookie。设置为/表示全站有效。domain:Cookie 有效域名。设置为.example.com表示在example.com及其所有子域名下有效。secure:标记为secure的 Cookie 只能通过 HTTPS 协议发送,防止传输过程中被窃听。HttpOnly:标记为HttpOnly的 Cookie 无法通过 JavaScript 访问,可有效防止跨站脚本攻击(XSS)窃取 Cookie。
2.5 Cookie 代码实现与实验测试
以下是 C++ 实现的登录接口,用户登录成功后服务器下发 Cookie:
// 登录接口处理函数
// req: 客户端HTTP请求对象,封装请求方法、URL、参数、请求头等信息
// resp: 服务器HTTP响应对象,用于构建状态码、响应头、响应体等
void Login(const HttpRequest &req, HttpResponse &resp)
{
// 从请求中获取URL查询参数或POST表单参数(格式如username=xxx&passwd=yyy)
std::string args = req["args"];
std::cout << "-----> Login service, args:" << args << std::endl;
// 设置HTTP响应状态码为200,表示请求成功
resp.SetCode(200);
// 设置响应内容类型为纯文本
resp.SetHeader("Content-Type", "text/plain");
// 设置Cookie字段
// status=online: Cookie名称和值,表示用户在线状态
// expires: Cookie过期时间,使用UTC标准时间
// path=/: Cookie在整个网站根目录及子目录下有效
resp.SetHeader("Set-Cookie", "status=online; expires=Sat, 20 May 2026 00:00:00 UTC; path=/;");
// 设置响应体内容,返回登录成功提示
resp.SetBody("Login success!\n");
}
2.5.1 常见坑点说明
- 路径默认值问题:若未显式设置
path属性,Cookie 默认仅在当前请求路径及其子路径下有效。例如在/app/login接口设置的 Cookie,默认不会被/index.html页面携带,必须显式设置path=/实现全站生效。 - 时区一致性问题:
expires属性必须使用 UTC 时间,不能使用本地时间。浏览器会自动将 UTC 时间转换为本地时间判断过期,使用本地时间会导致 Cookie 提前或延迟失效。 - 时间格式严格性:
expires的时间格式必须严格遵循 RFC 1123 标准,错误格式会被浏览器忽略,Cookie 将被视为会话 Cookie,关闭浏览器即失效。 - 多 Cookie 存储问题:若使用
unordered_map存储响应头,无法设置多个同名Set-Cookie字段(后设置的会覆盖先设置的)。解决方案是使用vector单独存储所有 Cookie,序列化响应时逐个添加到响应头。 - 安全属性缺失:用于身份验证的 Cookie 必须添加
HttpOnly属性,防止 XSS 攻击通过 JavaScript 窃取 Cookie;生产环境必须添加secure属性,仅允许 HTTPS 传输。
2.6 纯 Cookie 方案的安全缺陷
纯 Cookie 方案存在两个致命安全缺陷:
- 敏感信息本地泄露:Cookie 保存在用户本地设备上,如果直接存储账号密码等敏感信息,一旦设备被入侵或 Cookie 文件被恶意程序窃取,用户敏感信息会直接泄露。
- Cookie 被盗导致账号被盗:黑客可通过 XSS 攻击、网络窃听等方式窃取用户 Cookie。只要获取 Cookie,黑客就能冒充用户身份登录网站,完全控制用户账号。
因此,纯 Cookie 方案已不再是主流的会话保持方式,取而代之的是 Cookie 与 Session 结合的方案。

3 ~> HTTP Session:服务端状态存储机制
3.1 Session 的定义与核心思想
HTTP Session 是一种服务端状态存储机制。其核心思想是:将用户的敏感信息从客户端转移到服务端存储,客户端仅保存一个不包含任何敏感信息的 Session ID。
这样即使黑客窃取了客户端的 Session ID,也无法获取用户的账号密码等敏感信息,大幅提高了系统安全性。
3.2 Session 的完整工作流程
Session 的工作过程分为四个步骤:
- 用户身份认证:用户输入账号密码并提交登录请求,服务器验证用户身份合法性。
- 服务端创建 Session:身份验证通过后,服务器创建 Session 对象,为用户分配全局唯一的 Session ID,并将用户登录信息、权限信息等保存在 Session 中。
- Session ID 下发:服务器在响应头中添加
Set-Cookie字段,将 Session ID 发送给浏览器。浏览器将 Session ID 保存在本地 Cookie 中。 - 后续请求身份验证:用户再次发送请求时,浏览器自动将 Session ID 携带在 Cookie 中。服务器根据 Session ID 查找对应的 Session 对象,识别用户身份。
3.3 Session 的核心数据结构
标准 Session 对象通常包含以下核心字段:
- Session ID:全局唯一随机字符串,是 Session 的唯一标识。为防止暴力猜测,建议长度至少 128 位,并使用强随机数生成算法。
- User ID:关联用户在数据库中的唯一 ID,服务器通过 User ID 获取用户详细信息。
- 创建时间:Session 创建时间戳,用于计算过期时间。
- 过期时间:Session 失效时间戳,超过该时间后 Session 会被服务器自动清理。
- 用户数据:存储用户个性化信息,如用户偏好、购物车内容等。
3.4 Session 代码实现与实验测试
以下是 C++ 实现的简单 Session 管理系统:
#include <unordered_map>
#include <memory>
#include <string>
#include <cstdlib>
#include <ctime>
#include <unistd.h>
// Session结构体,存储单个用户的会话信息
struct Session
{
int user_id; // 关联数据库中的用户唯一ID
time_t create_time; // Session创建时间戳(秒级)
time_t expire_time; // Session过期时间戳(秒级)
// 可扩展字段:用户权限、购物车数据、个性化设置等
};
// Session管理类,单例模式,负责所有Session的创建、查询、删除
class SessionManager
{
public:
// 构造函数,初始化随机数种子
SessionManager()
{
// 使用当前时间与进程ID异或作为种子,避免多进程生成相同随机序列
srand(time(nullptr) ^ getpid());
}
// 添加新的Session,返回生成的全局唯一Session ID
// s: 指向Session对象的智能指针,自动管理内存
std::string AddSession(std::shared_ptr<Session> s)
{
// 生成临时Session ID(生产环境需替换为安全算法,如boost::uuid)
uint32_t random_id = rand() + time(nullptr);
std::string session_id = std::to_string(random_id);
// 将Session存入哈希表,键为Session ID,值为Session对象指针
_sessions.insert(std::make_pair(session_id, s));
return session_id;
}
// 根据Session ID查询对应的Session对象
// session_id: 客户端Cookie中携带的Session ID
// 返回值:找到返回Session智能指针,未找到返回nullptr
std::shared_ptr<Session> GetSession(const std::string &session_id)
{
auto it = _sessions.find(session_id);
if (it != _sessions.end())
{
return it->second;
}
return nullptr;
}
private:
// 哈希表存储所有活跃Session,键为Session ID,值为Session智能指针
std::unordered_map<std::string, std::shared_ptr<Session>> _sessions;
};
// 全局唯一的SessionManager实例,整个程序共享
SessionManager g_session_manager;
集成 Session 功能的登录接口:
// 集成Session机制的登录接口
void Login(const HttpRequest &req, HttpResponse &resp)
{
std::string args = req["args"];
std::cout << "-----> Login service, args:" << args << std::endl;
// 1. 解析请求参数中的账号和密码(此处省略参数解析代码)
// 2. 查询数据库验证用户身份(此处省略数据库查询代码)
// 假设身份验证通过,用户ID为123
// 3. 创建Session对象并初始化核心字段
auto session = std::make_shared<Session>();
session->user_id = 123;
session->create_time = time(nullptr);
session->expire_time = time(nullptr) + 86400; // 设置有效期为1天(86400秒)
// 4. 将Session添加到全局管理器,获取生成的Session ID
std::string session_id = g_session_manager.AddSession(session);
// 5. 将Session ID通过Cookie下发给客户端
resp.SetCode(200);
resp.SetHeader("Content-Type", "text/plain");
// 设置Cookie:session_id=xxx
// path=/:全站有效
// HttpOnly:禁止JavaScript访问,防止XSS攻击窃取
resp.SetHeader("Set-Cookie", "session_id=" + session_id + "; path=/; HttpOnly");
resp.SetBody("Login success!\n");
}
3.4.1 常见坑点说明
- Session ID 生成安全问题:示例中使用
rand() + time(nullptr)生成 Session ID,随机性不足,易被暴力破解。生产环境必须使用安全随机数生成器(如 Linux 下的/dev/urandom、Windows 下的CryptGenRandom)或专业 UUID 库。 - 过期 Session 内存泄漏:示例中未实现过期 Session 清理机制,长期运行会导致内存泄漏。需添加定时任务,定期遍历哈希表删除
expire_time小于当前时间的 Session。 - 分布式系统 Session 共享问题:多服务器部署时,内存中的 Session 无法跨服务器共享。解决方案是使用 Redis、Memcached 等分布式缓存统一存储 Session。
- Session 固定攻击:黑客可先获取一个有效 Session ID,诱导用户使用该 ID 登录。解决方案是用户登录成功后,重新生成新的 Session ID,并销毁旧 ID。
- Cookie 禁用兼容问题:若用户浏览器禁用 Cookie,Session ID 无法保存。解决方案是使用 URL 重写,将 Session ID 附加在 URL 参数中(如
/index.html?session_id=xxx)。
3.5 Session 的安全性与防护策略
虽然 Session 比纯 Cookie 方案安全,但仍存在一些安全问题,需要采取相应防护策略:
- Session ID 安全性:Session ID 必须足够长且具有足够随机性,防止暴力猜测。建议使用 128 位以上的强随机数生成。
- Session 过期机制:服务器必须定期清理过期 Session,防止内存溢出。同时,对于长时间不活跃的用户,应自动使其 Session 失效。
- 异地登录检测:服务器记录用户登录的 IP 地址和设备信息。如果发现同一个 Session ID 在不同 IP 地址或设备上使用,应立即使该 Session 失效,并要求用户重新登录。
- 服务端 Session 存储:小型项目中 Session 可保存在内存中;大型分布式系统中,应使用 Redis 等内存数据库存储 Session,实现多服务器共享。
需要注意的是,Session 机制不能完全解决盗号问题。如果黑客窃取了用户的 Session ID,仍可冒充用户登录。但 Session 机制大幅提高了盗号门槛,并可通过异地登录检测等策略及时发现并阻止盗号行为。

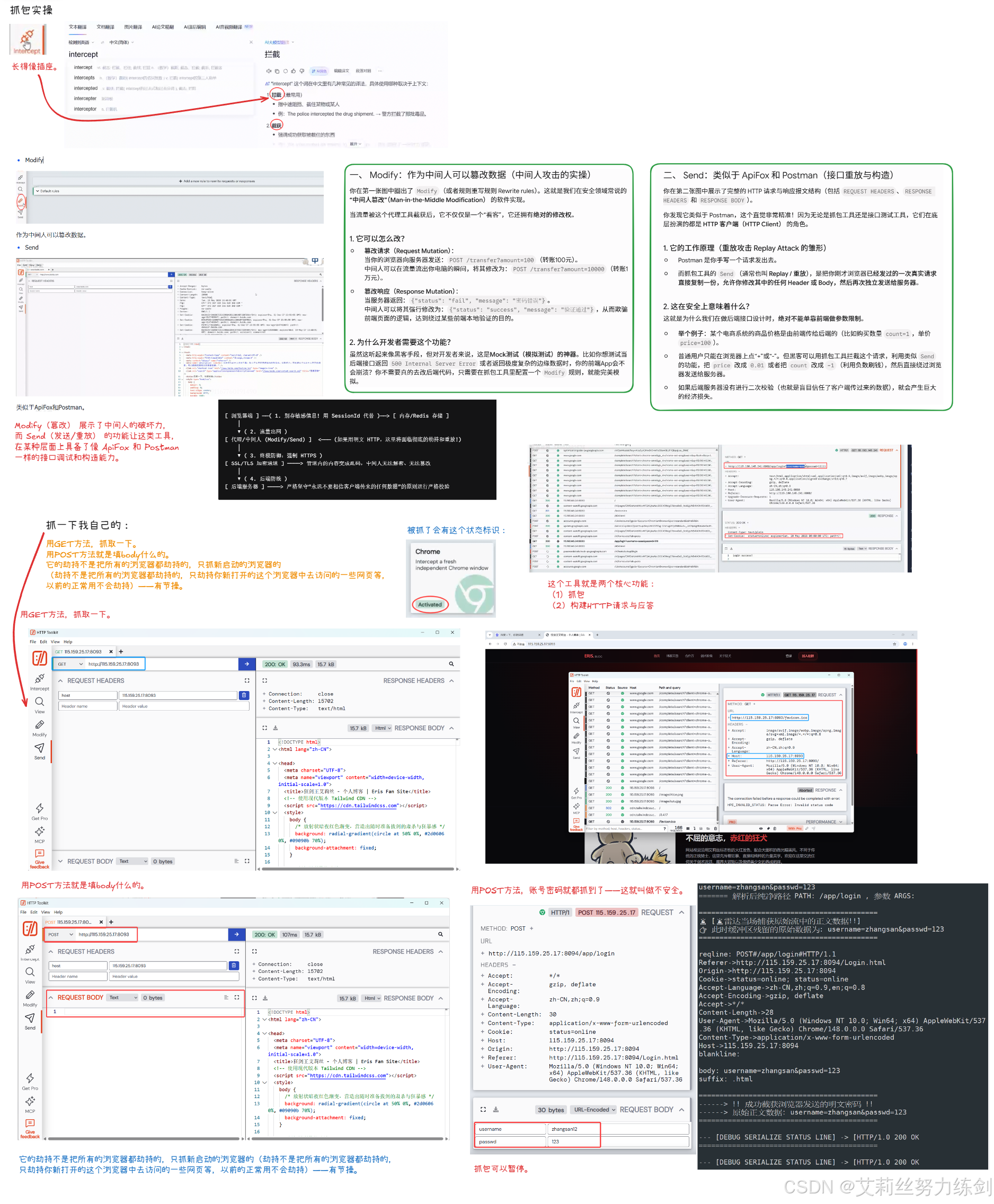
4 ~> HTTP 抓包工具与流量分析
4.1 抓包工具的核心价值
抓包工具是 Web 开发和网络调试中不可或缺的工具,可捕获客户端与服务器之间传输的所有 HTTP 数据包,清晰展示请求和响应的详细内容。
抓包工具的核心价值:
- 调试 HTTP 接口:查看请求参数、请求头、响应状态码、响应体等信息,快速定位接口问题。
- 排查网络问题:分析 TCP 连接、重传、延迟等网络层问题,找出故障原因。
- 学习 HTTP 协议:通过实际数据包深入理解 HTTP 协议的工作原理和各个字段的含义。
- 安全测试:检测网站是否存在明文传输敏感信息、SQL 注入、XSS 等安全漏洞。
4.2 主流抓包工具对比
| 工具名称 | 平台支持 | 核心优势 | 使用限制 | 适用场景 |
|---|---|---|---|---|
| Fiddler | Windows、macOS、Linux | 功能全面,支持 HTTPS 解密、请求重放、断点调试 | 界面不够直观,需手动配置代理 | Web 开发调试、API 测试 |
| Wireshark | Windows、macOS、Linux | 最强大的底层网络协议分析器,支持捕获所有 TCP/IP 数据包 | HTTPS 需导入服务器私钥才能查看明文 | 网络层问题排查、TCP 协议分析 |
| HTTP Toolkit | Windows、macOS、Linux | 零配置,一键抓包,界面直观,开源免费 | 高级功能需付费 | 快速调试、入门学习 |
4.3 HTTP Toolkit 的核心功能与使用
HTTP Toolkit 是一款适合初学者的抓包工具,以 “零配置” 为核心卖点,无需手动设置系统代理,点击即可开始抓包。
HTTP Toolkit 的核心功能:
- 一键抓包:支持捕获来自浏览器、后端进程(Node.js、Java、Python 等)、Docker 容器、手机 App 的 HTTP/HTTPS 流量。自动打开独立浏览器窗口,捕获该窗口的所有流量。
- 断点修改:在请求发送前或响应返回前设置断点,实时编辑请求头、请求体、响应头、响应体等内容,然后继续发送。适用于测试接口异常情况。
- 自动重写规则:创建自动重写规则,批量修改请求或响应内容。例如,将所有请求的
User-Agent修改为特定值,或将所有响应的状态码修改为 200。 - 请求构建:手动构建 HTTP 请求,发送给服务器并查看响应,功能类似于 Postman 和 ApiFox。
4.4 抓包原理与代理劫持

所有 HTTP 抓包工具本质上都是代理服务器。其工作原理是通过修改系统的代理环境变量,将浏览器的所有流量转发到抓包工具,再由抓包工具转发到目标服务器。
具体工作过程:
- 抓包工具启动后,在本地开启代理服务(通常监听 8000 或 8888 端口)。
- 抓包工具修改系统的
HTTP_PROXY和HTTPS_PROXY环境变量,将代理地址设置为本地代理服务地址。 - 浏览器发送 HTTP 请求时,根据系统代理设置,将请求发送到抓包工具的代理服务。
- 抓包工具记录请求详细信息,然后将请求转发到目标服务器。
- 目标服务器返回响应后,抓包工具记录响应详细信息,然后将响应转发回浏览器。
这种代理机制也被称为中间人攻击。正常情况下,自己安装的抓包工具是可信的。但如果恶意程序修改了系统代理设置,将流量转发到恶意代理服务器,所有网络流量都会被窃听和篡改。
可通过以下命令检查系统代理环境变量:
# Windows CMD
echo %HTTP_PROXY%
echo %HTTPS_PROXY%
4.5 抓包实战
5 ~> HTTPS 协议初识
5.1 HTTPS 的诞生背景
HTTP 协议的所有内容都以明文形式在网络上传输,导致以下安全问题:
- 数据窃听:任何人都可通过抓包工具窃取传输的数据,包括账号密码、银行卡信息等。
- 数据篡改:中间人可修改传输的数据,例如修改转账金额。
- 身份伪造:中间人可冒充服务器身份,发送虚假信息骗取用户敏感信息。
为解决这些问题,网景公司于 1994 年推出 HTTPS 协议。HTTPS 并非全新协议,而是在 HTTP 基础上引入 SSL/TLS 加密层,为 HTTP 通信提供加密、认证和完整性保护。
5.2 HTTPS 的核心概念
HTTPS 的全称是 Hyper Text Transfer Protocol Secure(超文本传输安全协议),其本质是:
HTTPS = HTTP + SSL/TLS
其中,SSL(Secure Sockets Layer,安全套接层)是最早的加密协议,后来被 IETF 标准化为 TLS(Transport Layer Security,传输层安全)。现在所说的 SSL 通常指 TLS 协议。
SSL/TLS 协议位于 HTTP 协议和 TCP 协议之间,主要作用:
- 加密数据:将 HTTP 明文加密为密文后传输,防止数据被窃听。
- 身份认证:验证服务器身份,防止中间人冒充服务器。
- 完整性保护:验证数据在传输过程中是否被篡改。
5.3 加密基础概念
要理解 HTTPS 的工作原理,需了解以下基本加密概念:
- 加密:将明文通过一系列变换生成无法直接阅读的密文。
- 解密:将密文通过一系列逆变换还原为明文。
- 密钥:加密和解密过程中使用的辅助数据,类似于开锁的钥匙。
根据密钥使用方式不同,加密算法分为两大类:
- 对称加密:加密和解密使用同一个密钥。优点是速度快,适合加密大量数据;缺点是密钥分发和管理困难。常见算法:AES、DES、3DES。
- 非对称加密:加密和解密使用不同的密钥,分别称为公钥和私钥。公钥可公开,私钥必须严格保密。用公钥加密的数据只能用对应的私钥解密,用私钥加密的数据只能用对应的公钥解密。优点是密钥分发简单,安全性高;缺点是速度慢,不适合加密大量数据。常见算法:RSA、ECC。
另外两个重要概念:
- 数字签名:用于验证数据完整性和发送者身份。通过将数据摘要用发送者的私钥加密生成。接收者用发送者的公钥解密数字签名,与自己计算的数据摘要对比,一致则说明数据未被篡改且来自指定发送者。
- 数字证书:由权威证书颁发机构(CA)颁发的电子文件,用于证明服务器身份。证书包含服务器公钥、域名、有效期等信息,并由 CA 的私钥进行数字签名。浏览器内置所有权威 CA 的公钥,可验证证书合法性。
5.4 HTTPS 的工作流程概述
HTTPS 的工作流程主要步骤:
- 客户端发起 HTTPS 请求:向服务器的 443 端口发送 HTTPS 请求。
- 服务器返回数字证书:将自己的数字证书发送给客户端。
- 客户端验证数字证书:使用内置的 CA 公钥验证证书合法性。合法则提取证书中的服务器公钥。
- 客户端生成会话密钥:生成随机对称密钥(会话密钥),用服务器公钥加密后发送给服务器。
- 服务器解密会话密钥:用自己的私钥解密,得到会话密钥。
- 加密通信:客户端和服务器使用会话密钥进行对称加密通信。
这种 “非对称加密 + 对称加密” 的混合方式,既解决了对称加密密钥分发困难的问题,又解决了非对称加密速度慢的问题,是目前最安全高效的加密通信方式。
思考 && 总结
本文系统讲解了 HTTP 协议的会话保持机制、抓包工具与 HTTPS 协议的基础知识,核心要点总结如下:
- HTTP 核心特性:HTTP 是无连接、无状态的协议,所有状态保持工作都需要在应用层实现。浏览器缓存是浏览器自身功能,与 HTTP 协议本身无关。
- Cookie 机制:Cookie 是保存在客户端的小块数据,通过
Set-Cookie响应头下发,后续请求自动携带。分为会话 Cookie 和持久 Cookie,支持过期时间、路径、域名等属性。纯 Cookie 方案存在敏感信息本地泄露和 Cookie 被盗导致账号被盗的风险。 - Session 机制:Session 是保存在服务端的状态信息,客户端仅保存不包含敏感信息的 Session ID。核心思想是将用户敏感信息从客户端转移到服务端存储,大幅提升安全性。Session 可存储在内存、文件或分布式缓存中,需配合过期清理、异地登录检测等防护策略。
- 抓包工具:主流抓包工具有 Fiddler、Wireshark 和 HTTP Toolkit,本质都是代理服务器,通过修改系统代理环境变量实现流量劫持。抓包工具是 Web 开发和网络调试的必备工具,但也可能被恶意利用进行中间人攻击。
- HTTPS 协议:HTTPS 是 HTTP 与 SSL/TLS 加密层的组合,通过加密、身份认证和完整性保护解决 HTTP 明文传输的安全问题。采用 “非对称加密交换会话密钥 + 对称加密传输数据” 的混合加密方式,使用数字证书验证服务器身份。
至此,应用层 HTTP 协议的核心内容已学习完成。后续将深入传输层,学习 UDP 和 TCP 协议的工作原理,重点掌握 TCP 的三次握手、四次挥手、流量控制和拥塞控制等核心机制。
结尾
uu们,本文的内容到这里就全部结束了,艾莉丝在这里再次感谢您的阅读!
|

结语:希望对学习Linux相关内容的uu有所帮助,不要忘记给博主“一键四连”哦!
往期回顾:
【Linux网络】Linux 网络编程:HTTP(四)从手写服务器到生产级 Nginx 与 cpp-httplib 实战
🗡博主在这里放了一只小狗,大家看完了摸摸小狗放松一下吧!🗡 ૮₍ ˶ ˊ ᴥ ˋ˶₎ა


openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐

 2
2 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)