【Linux网络】彻底搞懂应用层自定义协议与序列化:从底层原理到工业级实战
很多 Linux 后端开发的新手,在学完 TCP Socket 基础 API 后,都能轻松写出一个 Echo 回显服务器,但一到真实业务场景就频频踩坑:想传输用户信息、计算请求等结构化数据,却不知道如何封装;客户端和服务端数据收发频繁出现解析错乱;明明 TCP 是可靠传输,却还是会出现 “粘包” 问题。这些问题的根源,在于只掌握了 Socket 的 API 调用,却没有理解应用层协议的核心价值,以

🎬 博主简介:

文章目录
前言:
很多 Linux 后端开发的新手,在学完 TCP Socket 基础 API 后,都能轻松写出一个 Echo 回显服务器,但一到真实业务场景就频频踩坑:想传输用户信息、计算请求等结构化数据,却不知道如何封装;客户端和服务端数据收发频繁出现解析错乱;明明 TCP 是可靠传输,却还是会出现 “粘包” 问题。这些问题的根源,在于只掌握了 Socket 的 API 调用,却没有理解应用层协议的核心价值,以及序列化与反序列化的底层逻辑。TCP 协议只负责字节流的可靠传输,却不关心字节流的业务含义,而应用层协议与序列化,正是我们在 TCP 之上构建业务能力的核心基石。本文将从 TCP IO 的底层本质出发,完整拆解应用层协议的设计逻辑、序列化与反序列化的核心原理,并基于 Jsoncpp 实现工业级的自定义协议,同时覆盖面试中 90% 的高频考点,让你不仅能写得出,更能懂底层、讲明白。
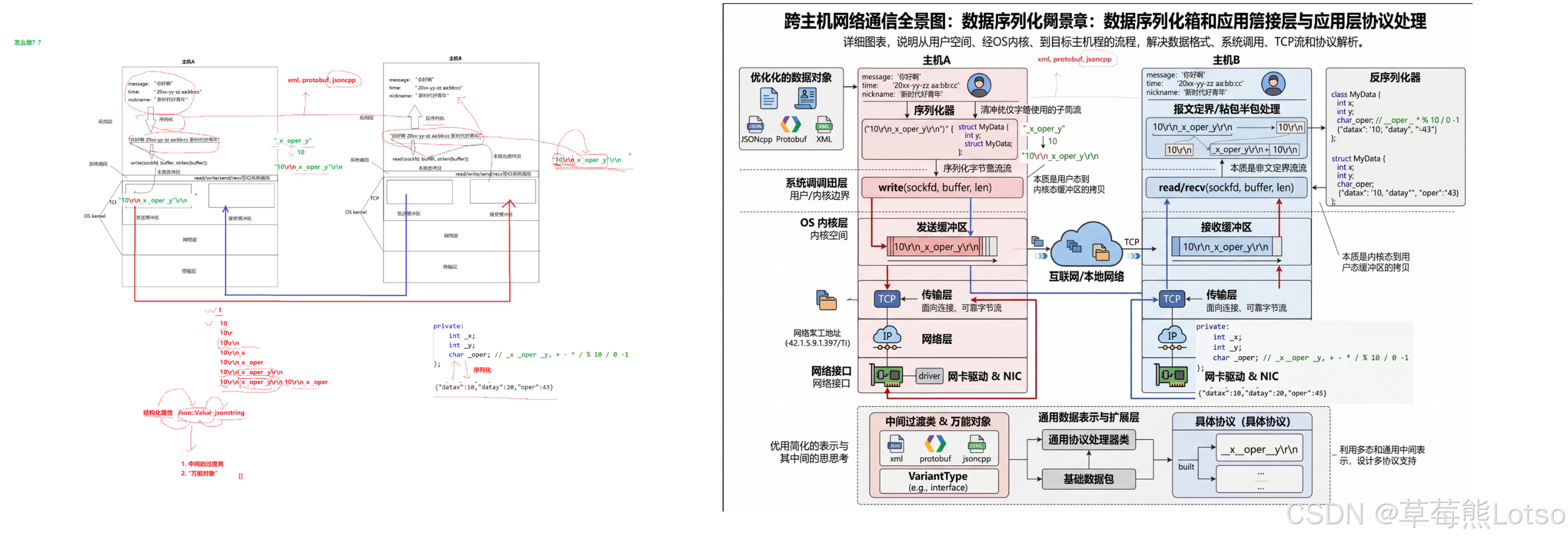
一. 重新理解 TCP IO 的底层真相(结合上面的前置知识图解来理解)
在正式进入协议设计之前,我们必须彻底搞懂read/write/recv/send这些 IO 系统调用的底层本质,这是理解网络通信的核心,也是面试的必考题。
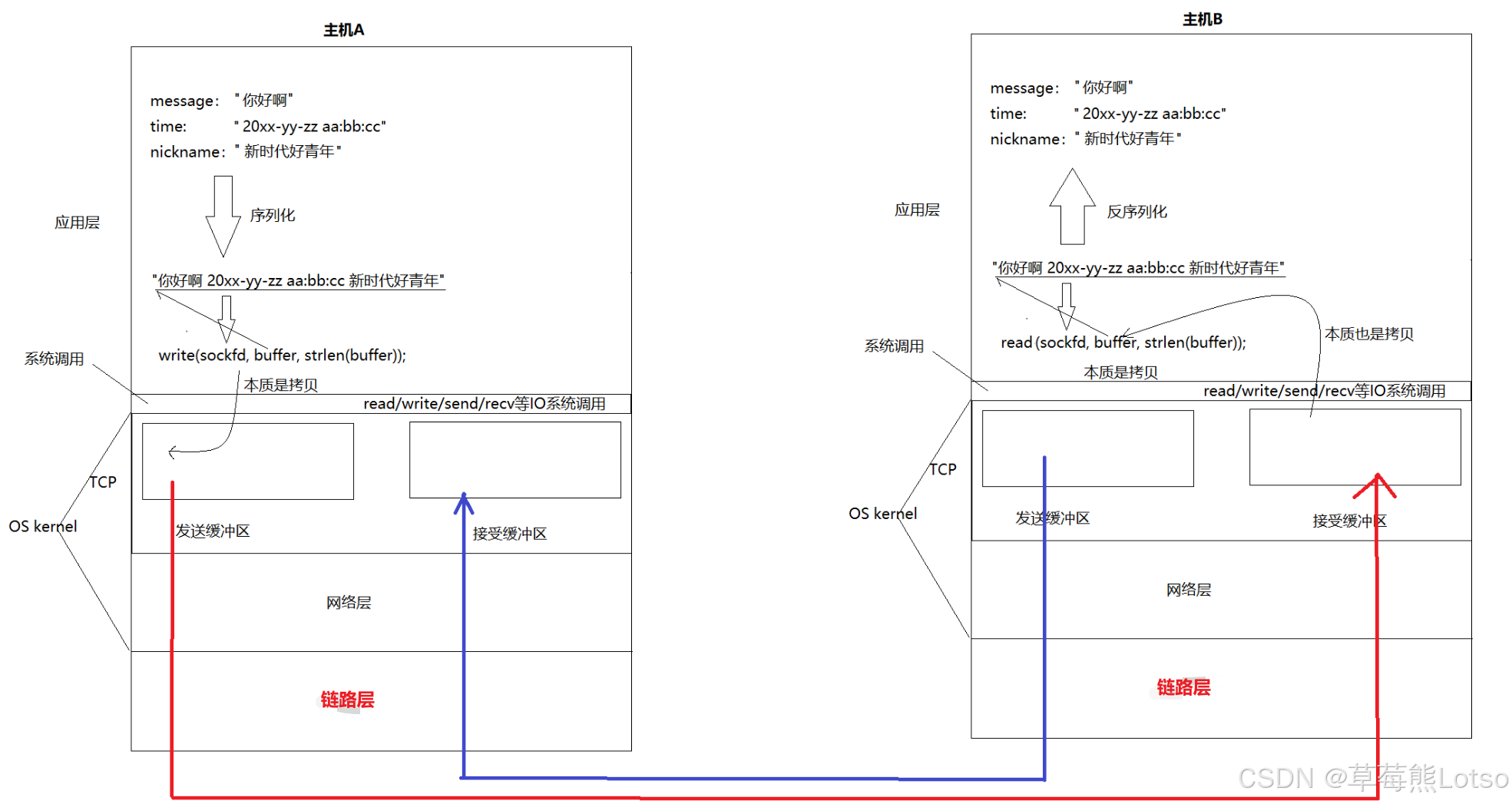
1.1 TCP 全双工的底层实现:收发缓冲区
TCP 之所以支持全双工通信(同一个 socket 可以同时发送和接收数据),核心在于 Linux 内核为每个 TCP socket 都创建了两个独立的缓冲区:发送缓冲区 (Send Buffer) 和接收缓冲区 (Receive Buffer)。
我们用文字描述完整的双工通信模型:
客户端应用层 服务端应用层
↑↓ ↑↓
客户端read/write 网络 服务端read/write
↑↓ ↑↓
客户端内核态 服务端内核态
[发送缓冲区] ←----------→ [接收缓冲区]
[接收缓冲区] ←----------→ [发送缓冲区]
这个模型带来了三个核心结论:
- 全双工的本质:发送和接收缓冲区相互独立,内核可以在向对端发送数据的同时,接收对端发来的数据,应用层可以在同一个 socket 上同时调用 read 和 write,不会产生冲突。
- IO 的异步性:应用层调用 write 成功,仅仅代表数据被拷贝到了内核的发送缓冲区,不代表数据已经发送到了对端,更不代表对端已经收到了数据。数据何时发送、一次发多少、出错后如何重传,完全由内核的 TCP 协议栈自主控制,这也是 TCP 被称为 “传输控制协议” 的原因
- 网络传输的本质:网络通信的全过程,本质上是发送方内核的发送缓冲区,通过网络将数据拷贝到接收方内核的接收缓冲区的过程。


1.2 IO 系统调用的本质:内存拷贝
无论是write/send还是read/recv,这些 IO 系统调用的核心动作只有一个:内存拷贝。
发送端:write/send 的执行流程
- 应用层调用
write(sockfd, buffer, len),传入用户空间的缓冲区地址和长度。 - 内核将用户空间 buffer 中的数据,拷贝到该 socket 对应的内核发送缓冲区中。
- 拷贝完成后,write 函数立即返回,后续由 TCP 协议栈根据滑动窗口、拥塞控制机制,将发送缓冲区中的数据封装成 TCP 报文,发送到网络中。
接收端:read/recv 的执行流程
- 内核通过网卡收到对端发来的 TCP 报文(怎么知道网卡有东西的,这个就是网卡触发了硬件中断),校验无误后,将数据放入该 socket 对应的内核接收缓冲区中。
- 应用层调用
read(sockfd, buffer, len),内核将接收缓冲区中的数据,拷贝到用户空间的 buffer 中。 - 拷贝完成后,read 函数返回实际读取到的字节数,应用层即可处理收到的数据。
这里有一个面试高频考点:调用 write 返回成功,就代表对方收到数据了吗?
答案是否定的。write 成功仅代表数据被成功拷贝到了内核发送缓冲区,此时如果服务器宕机,数据依然会丢失。TCP 协议栈会保证数据可靠地发送到对端,但应用层无法通过 write 的返回值感知这一点。
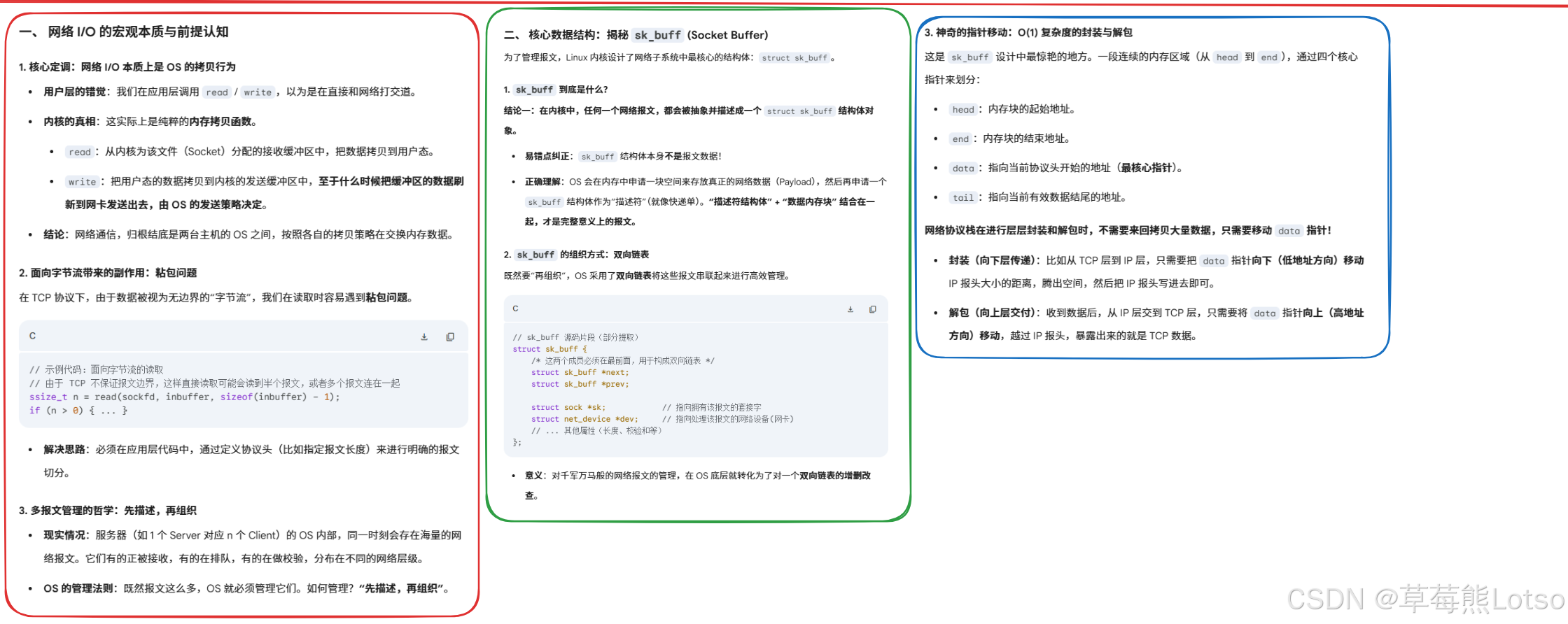
1.3 内核视角:TCP 报文的生命周期
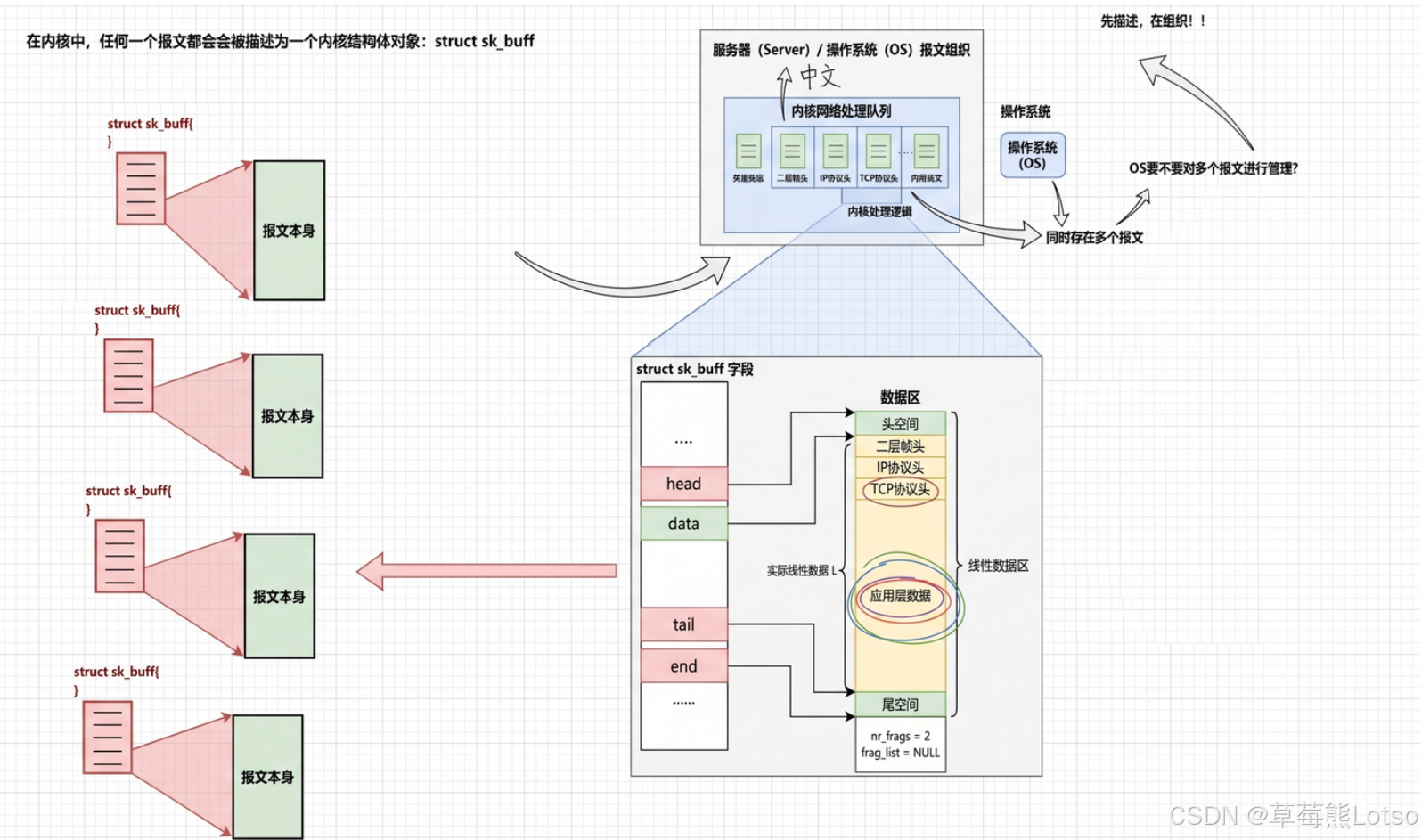
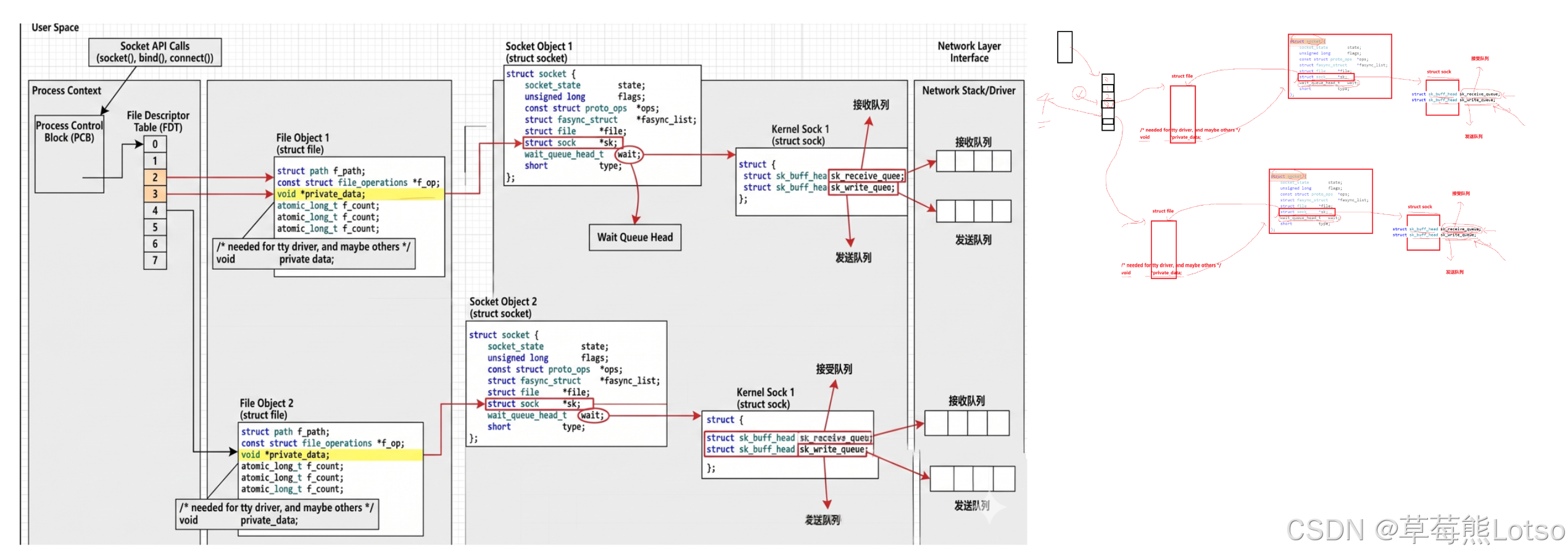
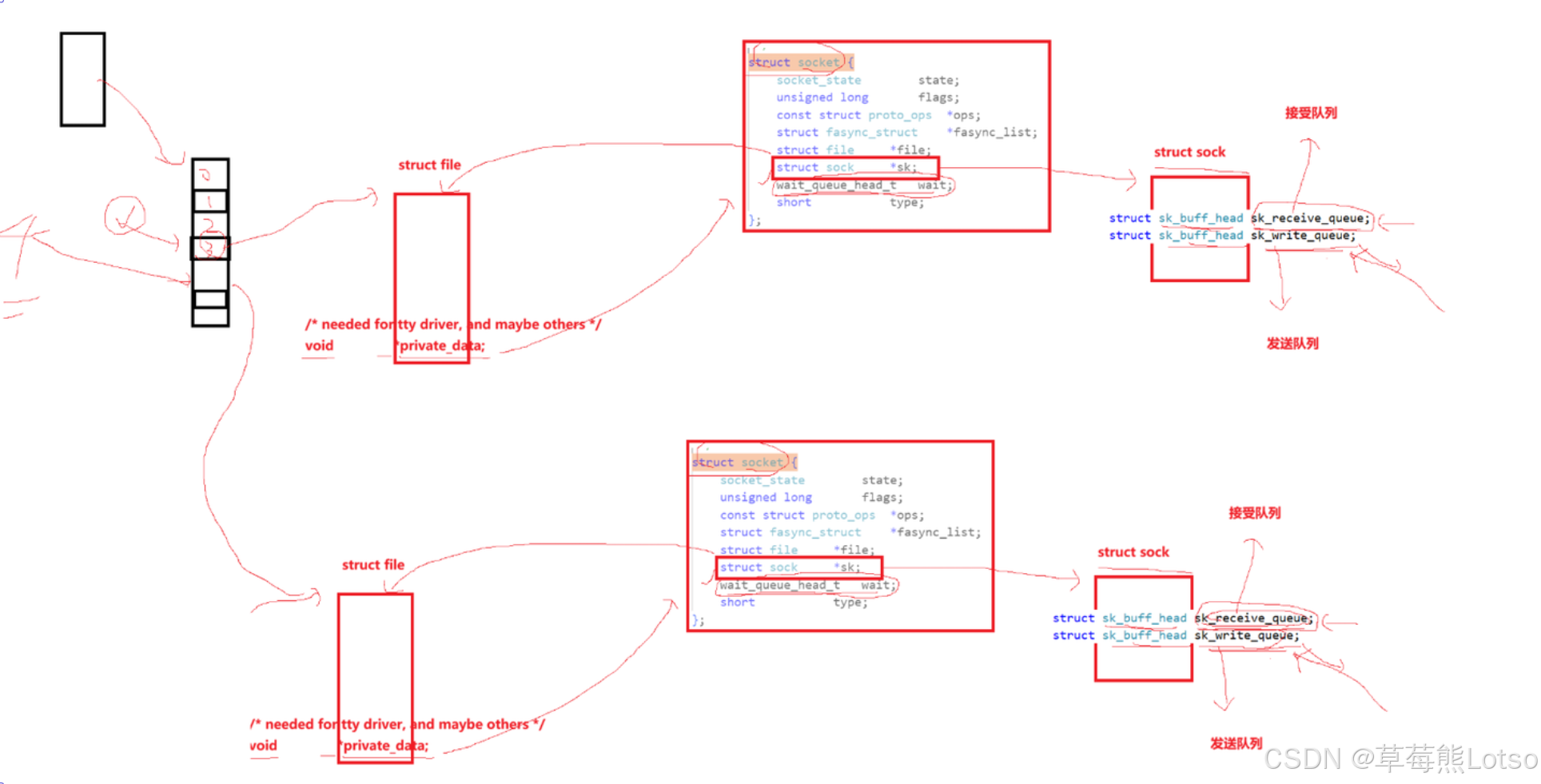
从内核的视角来看,所有的网络报文都会被封装成一个核心结构体:struct sk_buff(socket buffer),这是 Linux 内核网络协议栈的核心数据结构。
内核处理报文的完整流程:
- 网卡收到物理网络中的数据后,触发硬件中断,内核将数据拷贝到内核内存中,构建
sk_buff结构体,描述报文的完整信息。 - 内核通过链路层、网络层、传输层的逐层解析,确认报文对应的 socket,将
sk_buff放入该 socket 的 接收队列sk_receive_queue中。 - 应用层调用 read 时,内核从接收队列中取出
sk_buff,将数据拷贝到用户空间,完成读取操作。 - 应用层调用 write 时,内核将用户数据拷贝到发送缓冲区,构建
sk_buff结构体,放入该 socket 的 发送队列sk_write_queue中,由协议栈负责发送。
sk_buff的设计极其精妙,它通过head/data/tail/end四个指针,实现了协议头的快速封装与解包:添加协议头时,只需向前移动data指针;解包时,只需向后移动data指针,无需频繁的内存拷贝,这也是 Linux 网络协议栈高性能的核心原因。

二. 为什么我们需要应用层自定义协议?
2.1 再谈协议的本质
-
协议,本质上是通信双方的约定与规范。
-
Socket 的读写 API,在底层都是以字节流 / 字符串的形式收发数据。如果我们只需要传输简单的回显字符串,原生 API 完全够用;但在真实业务中,我们需要传输的往往是有明确业务含义的结构化数据:比如网络计算器需要传输两个操作数和运算符、聊天软件需要传输发送人昵称、消息内容、发送时间、用户头像等信息。
-
如何让发送方的结构化数据,能被接收方准确、无歧义地解析?这就需要双方提前约定好数据的格式、字段含义、边界规则,而这套约定,就是应用层协议。
举个最简单的例子:我们要实现一个网络版加法器,客户端向服务端发送两个数字,服务端计算后返回结果。这里就有两种最基础的协议约定方案:
- 方案一:简单字符串约定
- 客户端固定发送形如"1+2"的字符串,约定:字符串包含两个整形操作数,中间有且仅有一个运算符,数字与运算符之间无空格。服务端收到后按规则拆分字符串,提取数字和运算符进行计算。
- 方案二:结构化数据约定
- 定义结构体表示交互信息,发送方将结构体按照固定规则转换成字符串(序列化),接收方收到后按照相同规则还原成结构体(反序列化)。
方案一虽然简单,但扩展性极差,一旦业务需要新增字段、处理复杂逻辑,字符串的拆分与解析会变得极其繁琐,还极易出错;而方案二正是工业级开发的标准做法,也是本文的核心讲解内容。

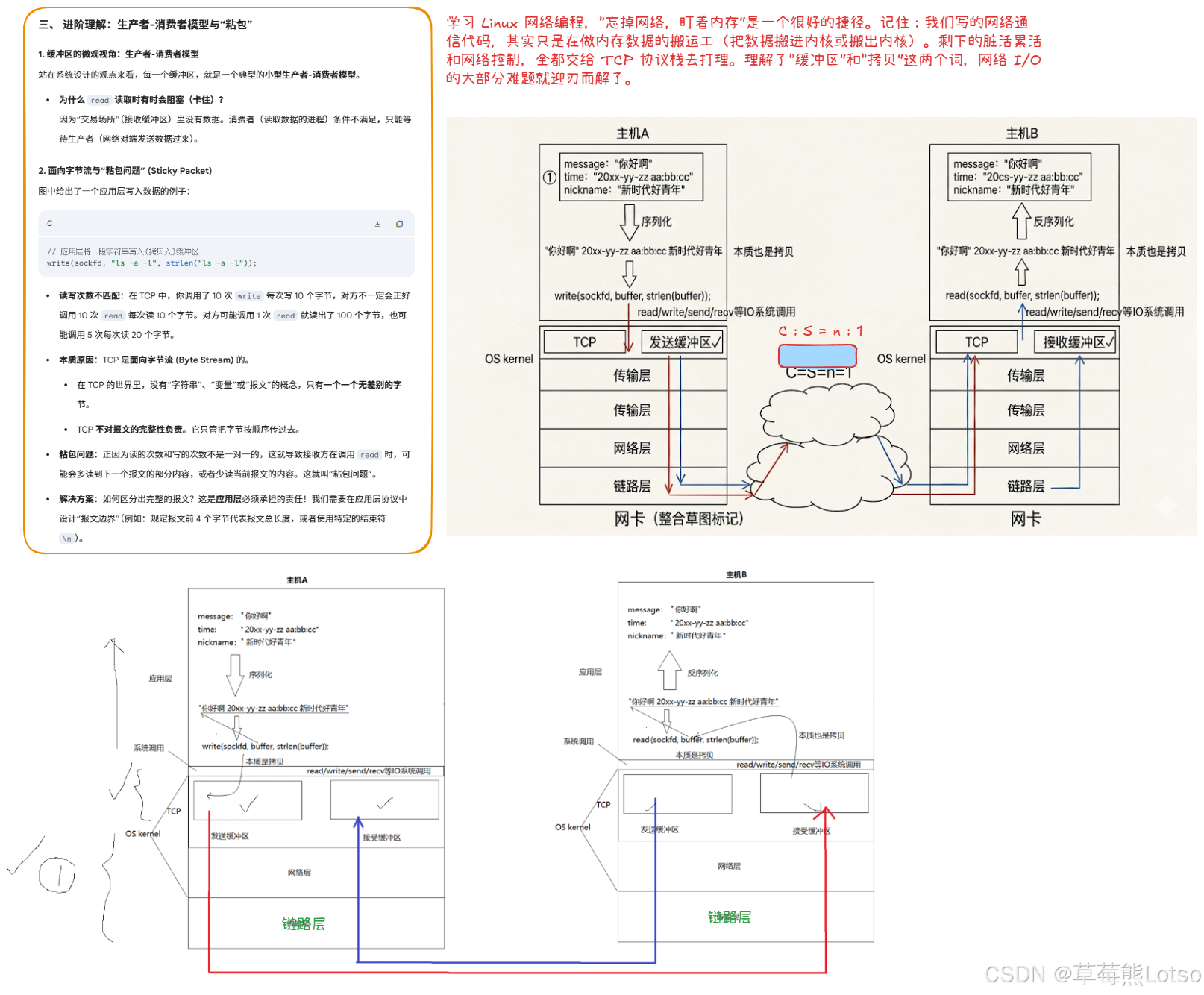
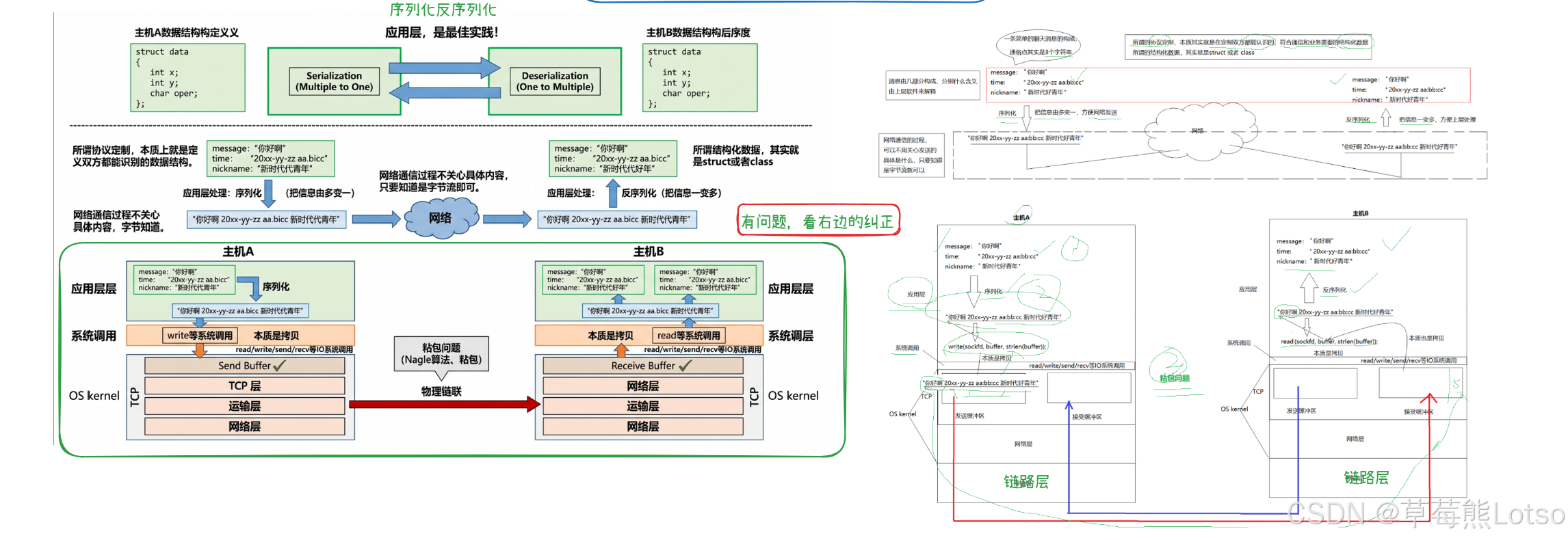
2.2 TCP 面向字节流的特性带来的核心痛点
TCP 是面向字节流的传输协议,这是它最核心的特性,也是绝大多数新手踩坑的根源。
面向字节流的核心含义是:TCP 不关心应用层传输的数据是什么格式、有没有业务边界,它只负责把发送方写入的字节流,可靠、有序地传递给接收方,但不保证接收方的 read 调用次数和发送方的 write 调用次数一一匹配。
举个例子:
- 客户端分两次调用 write,分别写入
"1+2"和"3*4"两个请求 - 服务端调用 read 时,可能一次性读到
"1+23*4",两个请求粘在了一起(粘包问题) - 也可能第一次读到
"1+",第二次读到"23*4",一个请求被拆分成了两次读取(半包问题)
TCP 本身不会帮我们处理业务报文的边界,这个问题必须由应用层协议来解决。
2.3 结构化数据的跨平台 / 跨语言传输痛点
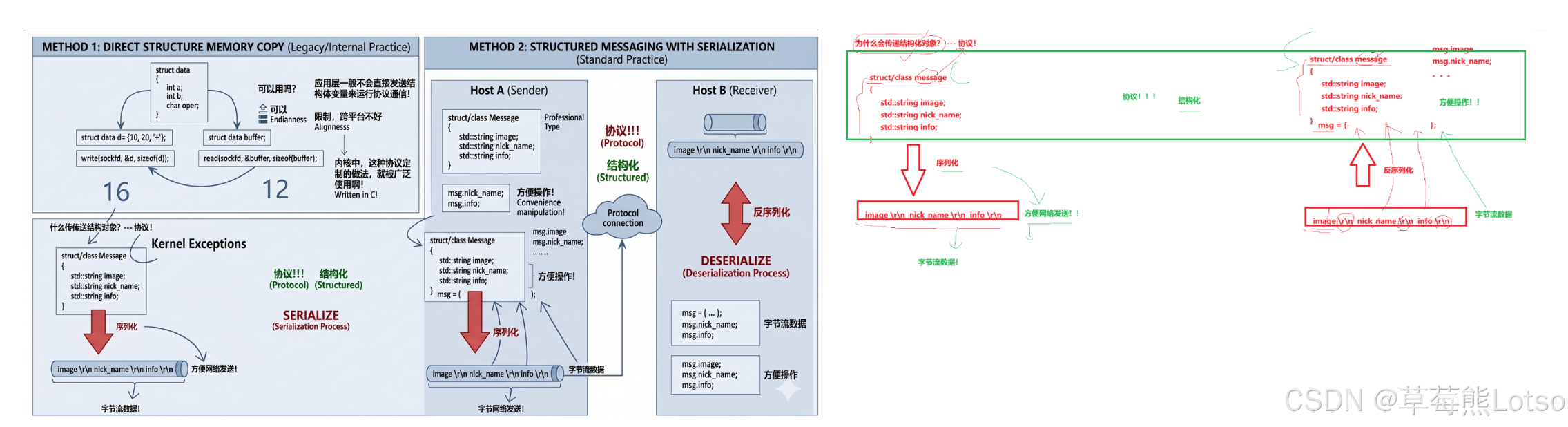
很多新手会问:我直接把结构体通过 socket 发送出去不行吗?为什么还要序列化?
直接发送结构体,在极其受限的场景下(客户端和服务端都是同平台、同语言、同编译器、同编译选项)可以运行,但在工业级开发中,这是绝对不推荐的做法,核心问题有两个:
- 平台字节对齐差异:不同平台、不同编译器对结构体的内存对齐规则不同,同样的结构体在 32 位和 64 位系统下,占用的内存大小可能完全不同,会直接导致数据解析错乱。
- 跨语言兼容性为零:结构体是 C/C++ 的语法特性,如果服务端用 C++ 开发,客户端用 Java/Python/Go 开发,对方根本无法识别 C++ 的结构体内存布局,完全无法通信。
而序列化,正是解决这个问题的核心方案:无论是什么语言、什么平台,都能将结构化数据转换成统一格式的字节流 / 字符串,接收方再按照统一规则还原成本地的结构化数据,实现跨平台、跨语言的网络通信。
三. 序列化与反序列化:网络传输的核心基石
3.1 核心定义
- 序列化:将内存中的结构化数据(结构体 / 类对象),按照固定规则转换成连续的字节流 / 字符串的过程,核心目的是方便网络传输与持久化存储。
- 反序列化:序列化的逆过程,将网络中收到的字节流 / 字符串,按照相同的规则还原成内存中的结构化数据,核心目的是方便上层业务逻辑处理。
简单来说,序列化就是 “多变一”,把分散的多个字段打包成一个可传输的整体;反序列化就是“一变多”,把收到的整体数据还原成可操作的多个字段。

3.2 主流序列化方案对比
在工业级开发中,我们不会手动实现序列化逻辑,而是使用成熟的开源方案,不同方案适用于不同的业务场景:
| 序列化方案 | 核心特点 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| Json | 文本格式,键值对结构 | 可读性极强、跨语言全兼容、使用简单、无需预编译 | 序列化后体积较大、性能一般 | Web API、配置文件、轻量级网络通信 |
| Protobuf | 二进制格式,Google 开源 | 序列化后体积极小、性能极高、支持版本兼容 | 可读性差、需要预编译 proto 文件 | 微服务 RPC、高性能后端通信、移动端网络通信 |
| XML | 文本格式,标签结构 | 规范性强、支持复杂嵌套结构 | 体积臃肿、解析性能差 | 传统配置文件、部分老系统接口 |
| 自定义二进制 | 手动定制二进制格式 | 极致的性能与体积控制 | 开发成本高、兼容性差、无跨语言能力 | 嵌入式设备、极致性能要求的底层通信 |
本文我们采用Jsoncpp库实现序列化与反序列化,它是 C++ 中最常用的 Json 处理库,API 简单易用,完全满足绝大多数后端业务场景的需求。

四. 实战落地:自定义协议完整实现
我们以网络版计算器为业务场景,完整实现一套工业级的应用层协议,包含:协议设计、序列化 / 反序列化、粘包问题解决三大核心模块。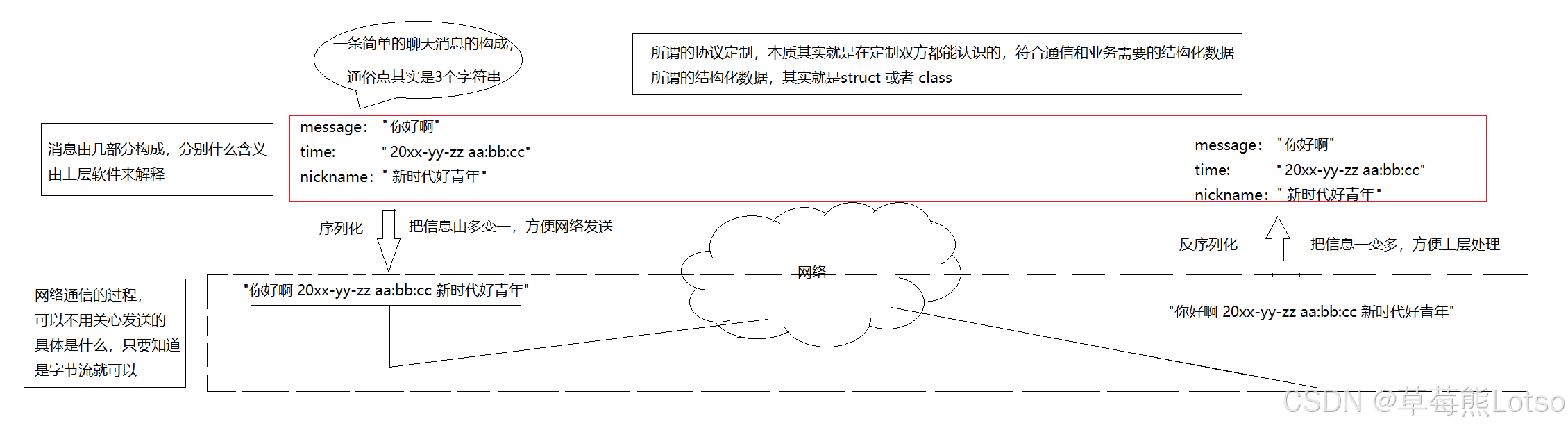
4.1 环境准备
Jsoncpp 库的安装非常简单,在 Ubuntu/Debian 系统下执行:
sudo apt-get install -y libjsoncpp-dev
CentOS/RHEL 系统下执行:
sudo yum install -y jsoncpp-devel
编译时需要链接 jsoncpp 库,编译指令需加上-ljsoncpp参数。

4.2 协议设计:请求与应答报文
协议设计的第一步,是定义通信双方的结构化报文,我们分为请求报文和应答报文两类。
请求报文(Client → Server)
客户端向服务端发送的计算请求,包含三个核心字段:
| 字段名 | 类型 | 含义 |
|---|---|---|
| datax | int | 第一个操作数 |
| datay | int | 第二个操作数 |
| oper | char | 运算符,支持+ - * / % |
应答报文(Server → Client)
服务端向客户端返回的计算结果,包含两个核心字段:
| 字段名 | 类型 | 含义 |
|---|---|---|
| result | int | 计算结果,仅当 exitcode 为 0 时有效 |
| exitcode | int | 状态码,0 表示计算成功,非 0 表示错误码(如除零错误、非法运算符) |
这套报文结构,就是我们自定义协议的核心,客户端和服务端都必须遵循这套规范进行数据的序列化与反序列化。
4.3 基于 Jsoncpp 的序列化与反序列化实现
我们将协议的核心实现封装在Protocol.hpp头文件中,客户端和服务端只需引入该头文件,即可使用统一的协议规范,这也是协议开发的最佳实践。
完整协议头文件实现
#ifndef __PROTOCOL__HPP
#define __PROTOCOL__HPP
#include <iostream>
#include <string>
#include <jsoncpp/json/json.h>
// 协议分隔符约定
const std::string LineBreakSep = "\r\n";
// ===================== 请求报文:client -> server =====================
class Request
{
public:
// 构造函数
Request() : _data_x(0), _data_y(0), _oper(0) {}
Request(int x, int y, char op) : _data_x(x), _data_y(y), _oper(op) {}
/**
* @brief 序列化:将结构化的请求对象,转换成Json字符串
* @param out 输出参数,存储序列化后的字符串
* @return 序列化是否成功
*/
bool Serialize(std::string *out)
{
Json::Value root;
// 将结构化字段填入Json对象
root["datax"] = _data_x;
root["datay"] = _data_y;
root["oper"] = _oper;
// 使用FastWriter生成无格式的紧凑Json字符串,减少传输体积
Json::FastWriter writer;
*out = writer.write(root);
return true;
}
/**
* @brief 反序列化:将Json字符串,还原成结构化的请求对象
* @param in 输入参数,收到的Json字符串
* @return 反序列化是否成功
*/
bool Deserialize(std::string &in)
{
Json::Value root;
Json::Reader reader;
// 解析Json字符串
bool parse_success = reader.parse(in, root);
if(!parse_success)
{
return false;
}
// 从Json对象中提取字段,还原结构化数据
_data_x = root["datax"].asInt();
_data_y = root["datay"].asInt();
_oper = root["oper"].asInt();
return true;
}
// 字段获取接口
int GetX() const { return _data_x; }
int GetY() const { return _data_y; }
char GetOper() const { return _oper; }
// 调试打印接口
void DebugPrint()
{
std::cout << "Request Debug:" << std::endl;
std::cout << "datax: " << _data_x << std::endl;
std::cout << "datay: " << _data_y << std::endl;
std::cout << "oper: " << _oper << std::endl;
}
~Request() = default;
private:
int _data_x; // 第一个操作数
int _data_y; // 第二个操作数
char _oper; // 运算符 + - * / %
};
// ===================== 应答报文:server -> client =====================
class Response
{
public:
// 构造函数
Response() : _result(0), _exitcode(0) {}
Response(int result, int code) : _result(result), _exitcode(code) {}
/**
* @brief 序列化:将结构化的应答对象,转换成Json字符串
* @param out 输出参数,存储序列化后的字符串
* @return 序列化是否成功
*/
bool Serialize(std::string *out)
{
Json::Value root;
root["result"] = _result;
root["code"] = _exitcode;
Json::FastWriter writer;
*out = writer.write(root);
return true;
}
/**
* @brief 反序列化:将Json字符串,还原成结构化的应答对象
* @param in 输入参数,收到的Json字符串
* @return 反序列化是否成功
*/
bool Deserialize(std::string &in)
{
Json::Value root;
Json::Reader reader;
bool parse_success = reader.parse(in, root);
if(!parse_success)
{
return false;
}
_result = root["result"].asInt();
_exitcode = root["code"].asInt();
return true;
}
// 字段设置与获取接口
void SetResult(int res) { _result = res; }
void SetCode(int code) { _exitcode = code; }
int GetResult() const { return _result; }
int GetCode() const { return _exitcode; }
// 调试打印接口
void DebugPrint()
{
std::cout << "Response Debug:" << std::endl;
std::cout << "result: " << _result << std::endl;
std::cout << "exitcode: " << _exitcode << std::endl;
}
~Response() = default;
private:
int _result; // 计算结果
int _exitcode; // 状态码:0成功,非0错误
};
#endif
源码核心解读
-
Json::Value 万能对象:Jsoncpp 的核心类,用于存储 Json 的键值对结构,支持 int、string、数组、嵌套对象等所有 Json 数据类型,我们通过
root["key"] = value的方式填充字段。 -
序列化核心逻辑:通过
Json::FastWriter将Json::Value对象转换成紧凑的字符串,相比StyledWriter,它不会添加额外的空格和换行,能有效减少网络传输的数据量。 -
反序列化核心逻辑:通过
Json::Reader解析收到的 Json 字符串,还原成Json::Value对象,再通过asInt()等方法提取对应类型的字段,还原成结构化数据。 -
接口封装:所有成员变量都设为 private,通过 public 接口访问,保证了数据的封装性,避免业务代码直接修改字段导致协议错乱。
-
下面的图中补充了一下JSONCPP的使用,比如
StreamWriterBulider,更详细的补充见飞书笔记


4.4 解决粘包问题:报文编解码方案(补充)
序列化解决了结构化数据的传输问题,但还没有解决 TCP 面向字节流带来的粘包 / 半包问题。我们采用 “报文长度 + 分隔符” 的经典方案,实现报文的编解码,彻底解决粘包问题。
我们约定最终的网络传输报文格式为:
[报文长度]\r\n[序列化后的业务报文]\r\n
例如:序列化后的业务报文长度为 30,那么最终发送的报文为"30\r\n{"datax":10,"datay":20,"oper":43}\r\n"。
编解码核心实现
我们在Protocol.hpp中补充编解码函数:
/**
* @brief 编码函数:给业务报文添加长度头部和分隔符,封装成完整的网络传输报文
* @param message 输入参数,序列化后的业务报文
* @return 封装后的完整网络报文
*/
std::string Encode(const std::string &message)
{
// 1. 将报文长度转为字符串
std::string len_str = std::to_string(message.size());
// 2. 按照约定格式封装报文
std::string package = len_str + LineBreakSep + message + LineBreakSep;
return package;
}
/**
* @brief 解码函数:从接收缓冲区中提取完整的业务报文,处理粘包/半包
* @param package 输入输出参数,当前的接收缓冲区数据
* @param message 输出参数,提取出的完整业务报文
* @return 是否提取到了完整的报文
*/
bool Decode(std::string &package, std::string *message)
{
// 1. 查找第一个分隔符,提取报文长度
auto pos = package.find(LineBreakSep);
if (pos == std::string::npos)
{
// 没找到分隔符,说明报文不完整,返回false
return false;
}
// 2. 提取报文长度字符串,转为整型
std::string len_str = package.substr(0, pos);
int message_len = std::stoi(len_str);
// 3. 计算完整报文的总长度
// 总长度 = 长度字符串长度 + 2个分隔符长度 + 业务报文长度
int total_package_len = len_str.size() + message_len + 2 * LineBreakSep.size();
// 4. 判断缓冲区中是否有完整的报文
if (package.size() < total_package_len)
{
// 缓冲区数据不足,报文不完整,返回false
return false;
}
// 5. 提取完整的业务报文
*message = package.substr(pos + LineBreakSep.size(), message_len);
// 6. 从缓冲区中移除已经处理过的报文,保留剩余数据
package.erase(0, total_package_len);
return true;
}
编解码逻辑核心解读
- 编码逻辑:在业务报文前添加长度字段,并用\r\n作为分隔符,让接收方可以明确知道业务报文的准确长度,从而判断报文是否完整。
- 解码逻辑的核心设计:
- 半包处理:如果缓冲区中没有找到分隔符,或者数据长度不足一个完整报文,直接返回 false,不做任何处理,等待下次读取更多数据后再解析。
- 粘包处理:提取完一个完整报文后,只移除缓冲区中已处理的部分,剩余的数据会保留在缓冲区中,等待下一次解码,不会丢失粘在一起的后续报文。
- 原子性处理:只有确认缓冲区中有完整报文时,才会提取数据,否则不修改缓冲区,保证了解析的安全性。
这套编解码方案,是工业级网络开发中处理粘包问题的标准方案,HTTP、RPC 等协议的底层,都是基于类似的 “长度 + 分隔符” 设计。
4.5 协议功能测试
我们编写简单的测试代码,验证序列化、反序列化、编解码的完整流程:
#include "Protocol.hpp"
int main()
{
// 1. 创建请求对象
Request req(10, 20, '+');
std::cout << "===== 原始请求 =====" << std::endl;
req.DebugPrint();
// 2. 序列化请求
std::string serialize_str;
req.Serialize(&serialize_str);
std::cout << "\n===== 序列化后的Json字符串 =====" << std::endl;
std::cout << serialize_str;
// 3. 编码成网络传输报文
std::string send_package = Encode(serialize_str);
std::cout << "\n===== 编码后的网络报文 =====" << std::endl;
std::cout << send_package;
// 模拟网络传输:接收缓冲区收到数据
std::string recv_buffer = send_package;
std::string message;
// 4. 解码提取业务报文
bool decode_success = Decode(recv_buffer, &message);
if(decode_success)
{
std::cout << "\n===== 解码后的业务报文 =====" << std::endl;
std::cout << message;
// 5. 反序列化还原请求对象
Request recv_req;
recv_req.Deserialize(message);
std::cout << "\n===== 反序列化后的请求 =====" << std::endl;
recv_req.DebugPrint();
}
return 0;
}
编译运行后,我们可以看到完整的流程执行成功,结构化数据经过序列化、编码、网络传输、解码、反序列化后,被完整还原,完美解决了结构化数据传输和粘包问题。
五. 面试高频核心考点总结
-
什么是粘包问题?为什么会出现?怎么解决?
- 粘包问题:TCP 面向字节流的特性,导致多个业务报文粘在一起,或者一个业务报文被拆分,接收方无法准确解析出完整的业务报文。
- 出现原因:TCP 不关心应用层的业务边界,只负责字节流的可靠传输;应用层多次 write 的数据,可能被内核合并成一个 TCP 报文发送;内核收到的多个 TCP 报文,可能被应用层一次 read 全部读取。
- 解决方案:应用层自定义协议,通过报文长度 + 分隔符、固定长度报文、特殊结束符等方式,明确业务报文的边界,其中 “报文长度 + 分隔符” 是工业级标准方案。
-
调用 write/send 返回成功,代表数据已经发送到对端了吗?为什么?
- 不代表。write/send 调用成功,仅代表数据已经从用户空间拷贝到了内核的 socket 发送缓冲区,不代表数据已经发送到网络,更不代表对端已经收到。数据的实际发送由内核的 TCP 协议栈控制,只有收到对端的 ACK 应答,才能确认数据被对端成功接收。
-
TCP 为什么支持全双工通信?底层实现是什么?
- TCP 全双工的底层实现,是内核为每个 TCP socket 分配了两个完全独立的发送缓冲区和接收缓冲区。发送和接收操作互不干扰,内核可以同时处理数据的发送和接收,应用层可以在同一个 socket 上同时进行读写操作,因此 TCP 支持全双工通信。
-
序列化与反序列化的核心作用是什么?为什么不能直接发送结构体?
- 核心作用:将内存中的结构化数据转换成可在网络中传输的字节流,实现跨平台、跨语言的数据交换,同时保证接收方可以准确还原结构化数据。
- 不能直接发送结构体的原因:① 不同平台、不同编译器的结构体内存对齐规则不同,会导致数据解析错乱;② 结构体是语言相关的,无法实现跨语言通信;③ 结构体中如果包含指针类型,直接发送只会传递指针地址,对端无法访问对应的数据。
-
TCP 已经是可靠传输协议了,为什么还需要应用层协议?
- TCP 的可靠,仅保证字节流能有序、无差错、不重复地从发送方传递到接收方,但它不理解字节流的业务含义,不处理业务报文的边界,也不保证应用层报文的完整性。
- 应用层协议的核心作用,是定义业务数据的格式、边界、交互规则,让通信双方能准确解析出有业务含义的数据,实现具体的业务逻辑。
结尾:
🍓 我是草莓熊 Lotso!若这篇技术干货帮你打通了学习中的卡点:
👀 【关注】跟我一起深耕技术领域,从基础到进阶,见证每一次成长
❤️ 【点赞】让优质内容被更多人看见,让知识传递更有力量
⭐ 【收藏】把核心知识点、实战技巧存好,需要时直接查、随时用
💬 【评论】分享你的经验或疑问(比如曾踩过的技术坑?),一起交流避坑
🗳️ 【投票】用你的选择助力社区内容方向,告诉大家哪个技术点最该重点拆解
技术之路难免有困惑,但同行的人会让前进更有方向~愿我们都能在自己专注的领域里,一步步靠近心中的技术目标!
结语:应用层自定义协议与序列化,是从 TCP Socket 入门到工业级网络开发的必经之路。我们日常使用的 HTTP、HTTPS、RPC、WebSocket 等所有应用层协议,其底层核心逻辑都离不开本文讲解的:结构化报文约定、序列化与反序列化、报文边界处理三大核心模块。理解了本文的内容,你不仅能解决网络开发中的粘包、数据解析等常见问题,更能读懂各类应用层协议的设计思路,为后续学习高性能网络框架、分布式系统、微服务开发打下最坚实的基础。
✨把这些内容吃透超牛的!放松下吧✨ ʕ˘ᴥ˘ʔ づきらど


openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐

 52
52 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)