从操作系统看 Multi-Agent 协作:角色、调度与交接协议
从操作系统的进程、调度、IPC、共享状态和异常恢复出发,拆解 Multi-Agent 系统中的角色协议、交接协议、状态协议、调度协议、权限协议、预算协议和裁决协议,并结合 DebugMind 的构建思考说明专职 Agent 如何被放入更大的协作系统。
从操作系统看 Multi-Agent 协作:角色、调度与交接协议
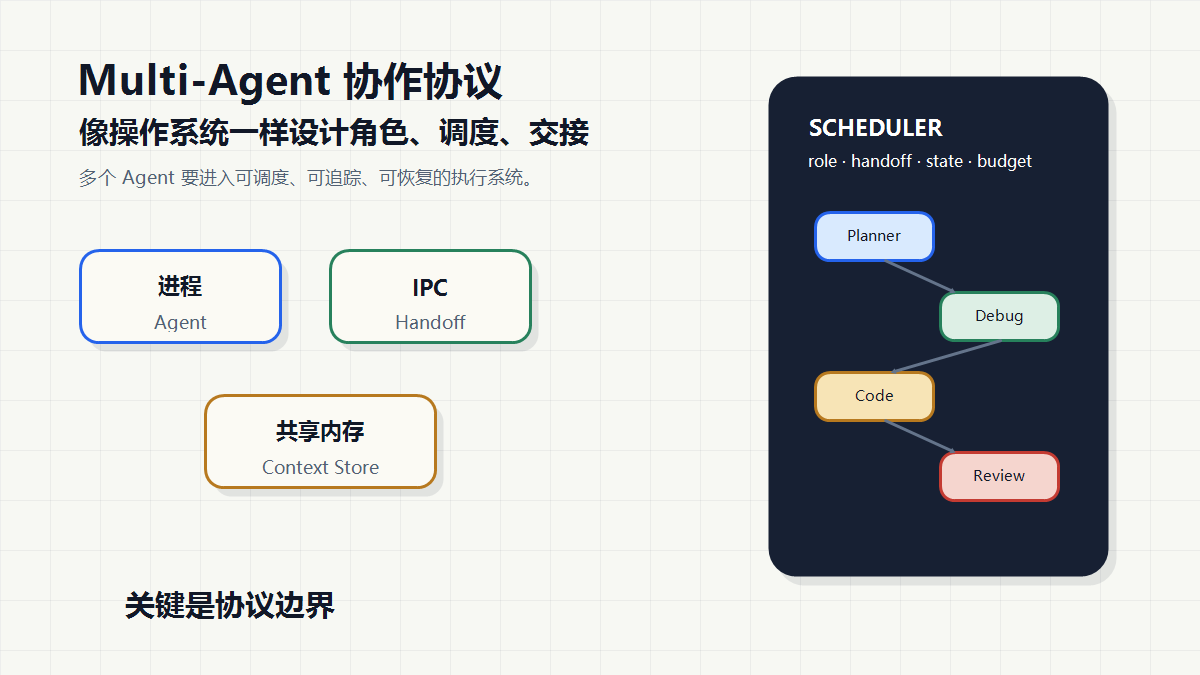
多个 Agent 一起工作,为什么反而更乱
很多人第一次设计 Multi-Agent 系统时,会很自然地画出这样的结构:
Planner Agent -> Coder Agent -> Tester Agent -> Reviewer Agent
看起来很合理。
一个负责拆任务,一个负责写代码,一个负责跑测试,一个负责审查。每个 Agent 都有自己的职责,组合起来似乎就能得到一个更强的系统。
但真实跑起来后,问题会很快出现:
- Planner 拆出来的任务太粗,Coder 只能重新理解一遍。
- Coder 改完后没有说清楚改了什么,Tester 不知道该测哪里。
- Tester 报了一个失败,Reviewer 又重新怀疑需求本身。
- 多个 Agent 同时读写同一份上下文,前面的错误判断会污染后面的判断。
- 每个 Agent 都觉得自己还需要更多信息,于是工具调用和 token 成本一路上涨。
这时候你会发现,Multi-Agent 的困难集中在系统协作,而不只是让多个模型开口说话。
我现在更愿意把 Multi-Agent 看成一个小型操作系统问题。
操作系统里,多进程本身并不神奇。真正重要的是调度器、进程间通信、锁、共享内存、权限边界、日志和异常恢复。Multi-Agent 也类似:多个 Agent 只是表象,背后需要一套协作协议。
一句话定义
Multi-Agent 协作的核心,是把多个具备局部能力的 Agent 放进一套可调度、可交接、可追踪、可恢复的执行协议里。
如果没有这套协议,多个 Agent 很容易变成一场“高级群聊”。
每个 Agent 都能说出一堆看似合理的话,但系统层面没有收敛能力。它不知道谁说了算,不知道状态归谁维护,也不知道一次任务什么时候算完成。
从经典 MAS 到 LLM 多智能体
Multi-Agent 这个概念早于 LLM。
经典多智能体系统,也就是 MAS,早就在分布式调度、博弈论模拟、机器人编队、专家系统里出现过。那一代系统更依赖预定义规则、状态机、通信协议和手写策略。Agent 的“智能”更多来自人写好的规则。
LLM 出现以后,多智能体的形态变了。
现在我们说 LLM Multi-Agent,通常指的是一组由大模型驱动的角色。它们可以阅读自然语言,调用工具,做计划,反思自己的输出,也能和其他 Agent 交换中间结果。协作从“机械执行预设规则”,变成了“用语义理解做动态协调”。
这带来一个很容易误判的地方:因为 LLM 会说话,所以我们会以为自然语言对话本身就是协作协议。
但工程上并不是这样。
自然语言可以承载解释,但很难稳定承载边界、权限、状态和一致性。越是开放的 LLM Agent,越需要外层协议来约束它。
所以 LLM 多智能体系统看起来比经典 MAS 更灵活,底层问题却没有消失:任务如何拆、状态如何同步、冲突如何裁决、失败如何恢复、成本如何限制。这些仍然是系统工程问题。
为什么单 Agent 会遇到天花板
我理解 Multi-Agent 的必要性,主要来自三个结构性限制。
第一是隧道视野。
单 Agent 往往沿着当前最像答案的线索一路往下推。这个能力在简单任务里很高效,但在复杂任务里容易忽略其他路径。比如 Debug 时,模型一旦认为是 Redis 问题,后面可能就会不断寻找 Redis 证据,而忽略线程池、配置、序列化、版本兼容这些方向。
第二是上下文和算力上限。
一个 Agent 的上下文窗口再大,也会遇到信息筛选问题。复杂任务里,代码、日志、需求、历史决策、测试输出都会挤进同一个窗口。上下文越大,噪音越多,推理质量未必线性提高。
Anthropic 在多 Agent 研究系统复盘里提到,token 使用量对任务表现有很强解释力,BrowseComp 评估中 token 使用量本身解释了大部分性能差异。这并不意味着“花 token 就一定更聪明”,但它说明复杂任务确实需要足够的有效推理预算。
第三是鲁棒性。
单 Agent 是单点故障。一次错误判断可能影响后面的全部推理。Multi-Agent 至少提供了几个缓冲手段:并行探索不同路径、让评估者检查生成者、让裁决者处理冲突、在关键节点引入人工审核。
不过这也说明一件事:Multi-Agent 是用更高成本换更强探索能力和鲁棒性。它不是默认选项。
先从操作系统类比开始
如果把一个 Agent 看成一个进程,那么 Multi-Agent 系统至少要面对五类问题:
| 操作系统问题 | Multi-Agent 对应问题 |
|---|---|
| 进程职责 | Agent 的角色边界 |
| 进程调度 | 谁决定下一个 Agent 做什么 |
| IPC | Agent 之间如何交接信息 |
| 共享内存 | 哪些上下文可以共享,哪些必须隔离 |
| 异常恢复 | 循环、超时、失败、冲突如何处理 |
这个类比不需要完全一一对应,但它能提醒我们一件事:并发系统的难点从来不只是“多开几个执行单元”。
多开进程以后,系统会遇到资源竞争、死锁、脏读、重复执行、异常传播。多开 Agent 以后,也会遇到类似问题:重复搜索、重复修改、上下文污染、职责漂移、结论冲突。

所以我看 Multi-Agent 时,第一反应会转向这些问题:
- 每个 Agent 的输入输出契约是什么?
- 谁负责调度?
- 谁负责裁决?
- 哪些信息可以进入共享状态?
- 失败后从哪里恢复?
- 成本和时间上限在哪里?
这些问题回答不清楚,Agent 越多,系统越不可控。
四种常见协作模式
把 Multi-Agent 当成系统工程之后,下一步应该先选协作模式,再写 prompt。
编排者-工作者
这是最常见的模式。
用户请求 -> Orchestrator
-> Worker A
-> Worker B
-> Worker C
-> 汇总结果
Orchestrator 负责任务拆解、分发和汇总,Worker 负责具体子任务。它适合能被明确拆成多个相对独立分支的场景,比如并行研究、代码审查、数据收集。
风险也很明显:Orchestrator 会成为单点瓶颈。任务拆不好,Worker 再强也会跑偏。
评估者-优化器
这种模式更像一个生成和审查闭环。
Generator -> 初稿 -> Evaluator -> 反馈 -> Generator
它适合代码生成、文案、方案设计、测试用例生成等质量要求较高的场景。优点是能降低单次生成的随机性,缺点是循环次数很容易失控,所以必须有终止条件。
层级/小组协作
这种模式模拟人类组织结构:项目经理 Agent、前端组、后端组、测试组、审查组。
它适合大型项目,但层级越多,信息传递失真越明显。上层摘要如果丢了关键约束,下层 Agent 会在错误前提上认真执行。
黑板/共享环境
黑板模式里,Agent 不一定直接互相发消息,而是向一个共享空间写入信息,再由其他 Agent 读取。
Agent A -> Blackboard <- Agent B
Agent C -> Blackboard <- Agent D
它适合异步协作、多专家融合和长期任务。问题是黑板会膨胀,信息质量也会参差不齐。没有冲突解决和版本控制,黑板很快会变成噪音堆。
这四种模式在真实系统里经常混用。比如外层是编排者-工作者,某个 Worker 内部用评估者-优化器,长期状态放在黑板里。
我在思考 DebugMind 时,也更倾向于把它放进“编排者-工作者”的一个 Worker 位置。它不做全局项目经理,而是作为 Debug Specialist 处理一类清晰任务:根据症状、日志、历史案例和代码线索,给出诊断候选。
角色协议:每个 Agent 都要有清晰边界
Multi-Agent 的第一层协议,是角色协议。
一个 Agent 不能只用一句“负责代码审查”来定义。更可执行的方式,是把它拆成三个问题:
这个 Agent 负责什么?
这个 Agent 明确不负责什么?
它的输出会交给谁,后续如何使用?
比如一个 Reviewer Agent,如果只写“检查代码质量”,它可能会同时评论命名、架构、需求、测试、性能、安全,最后输出一大段泛泛建议。
更好的定义可能是:
角色:Reviewer Agent
输入:diff、任务目标、测试结果
职责:找出会导致行为错误、回归风险、缺失测试的问题
不负责:重写实现、扩展需求、讨论产品方向
输出:按严重程度排序的问题列表,每个问题必须带文件位置和理由
这样它才像一个可以被调度的进程,而不是一个随时发散的聊天对象。
Anthropic 在复盘多 Agent 研究系统时也提到过类似问题:lead agent 给 subagent 的任务描述如果太短、太泛,subagent 就会重复工作、留下空白,或者误解任务边界。有效的委派需要目标、输出格式、工具使用范围和清晰边界。
我在做 DebugMind 时,也被这个问题反复提醒。
如果把 DebugMind 放进一个更大的 Multi-Agent 系统里,我不希望它变成“什么都能问的通用 Agent”。它更适合被定义成一个 Debug Specialist:
输入:故障描述、错误日志、环境信息、可选项目路径
职责:检索历史排障案例,结合日志和代码推断根因
输出:根因、证据、修复建议、置信度、相似案例
不负责:直接改代码、合并 PR、决定是否上线
这个边界看起来保守,但对协作系统很重要。
如果 Debug Agent 同时负责诊断、改代码、跑测试、决定上线,它就会变成一个权限过大的长流程 Agent。拆成 Specialist 后,它可以被 Orchestrator 调用,也可以把输出交给 Fix Agent、Test Agent 或 Reviewer Agent。
项目在这里的价值在于提醒我:一个好用的专职 Agent,首先要能被别的 Agent 安全调用。
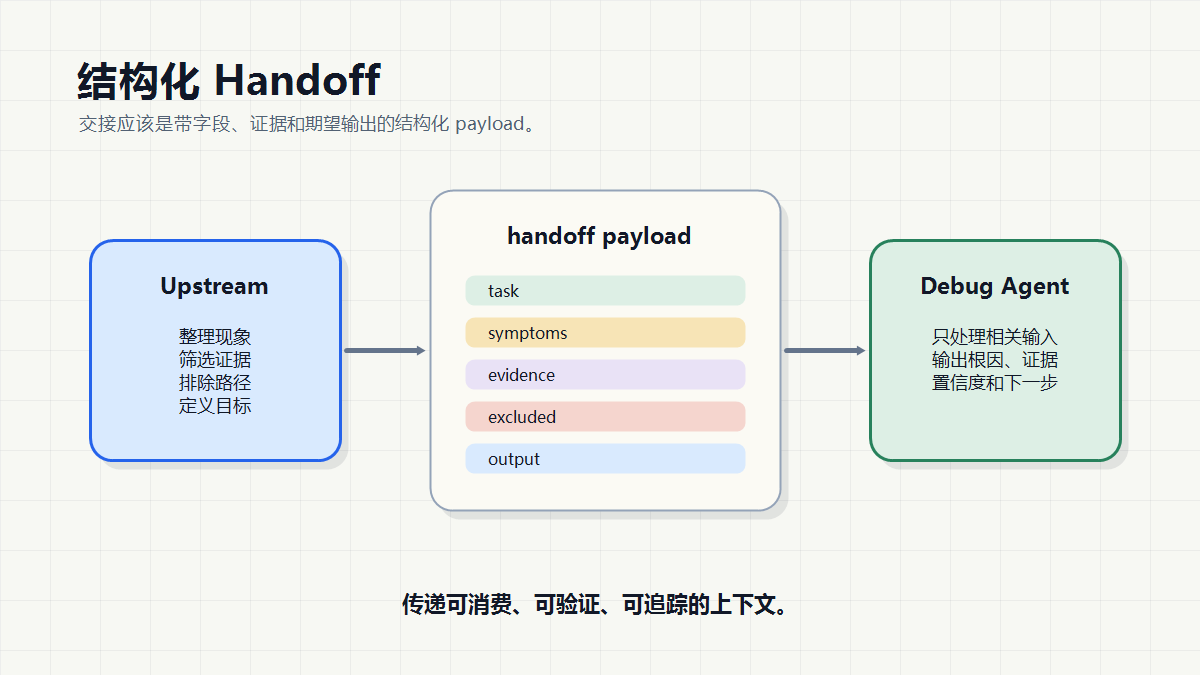
交接协议:Handoff 不能只是一句“你接着看”
Multi-Agent 的第二层协议,是交接协议。
很多 Agent 流程失败,单个 Agent 能力未必是主因,交接太随意才是更常见的根源。
人类协作里也一样。一个工程师把问题转给另一个工程师,如果只说“这个接口有点问题,你看看”,后面的人基本要重新排查一遍。更好的交接应该包括:
- 当前现象是什么。
- 已经看过哪些证据。
- 当前假设是什么。
- 哪些路径已经排除。
- 希望下一个人做什么。
- 输出需要满足什么格式。
Agent 之间也应该如此。
OpenAI Agents SDK 里的 handoff 设计很能说明这个方向。handoff 可以把对话的一部分委派给另一个专职 Agent,并且支持结构化输入、回调和输入过滤。这里的重点放在它给出的工程提醒:交接不能只靠一句自然语言提示,而应该是一个有 schema、有路由、有上下文裁剪的动作。
我更倾向于把 handoff payload 设计成类似这样:
{
"task": "diagnose_login_failure",
"symptoms": ["login returns 500", "NPE in UserService"],
"evidence": ["stack trace line 42", "Redis timeout before NPE"],
"excluded_paths": ["database connection is normal"],
"expected_output": ["root_cause", "fix_suggestion", "confidence"]
}
这样 Debug Specialist 接到任务后,不需要重新阅读整个聊天历史。它只需要处理与自己相关的信息。
这也是我设计 DebugMind 输入时比较在意的地方:症状、日志、环境、项目路径要分开,不要全塞进一个长 prompt。因为对于上游 Orchestrator 来说,结构化输入越清楚,越容易把 DebugMind 当成一个稳定的协作节点。
通信协议:路由和决策要分开看
Multi-Agent 的通信通常有两个层面:消息怎么流动,以及多个结果怎么合并。
消息流动可以有几种方式:
| 路由方式 | 适合场景 | 风险 |
|---|---|---|
| 固定顺序 | 简单流程、步骤稳定 | 不够灵活 |
| LLM 动态选择 | 开放式任务、研究任务 | 判断失误会导致乱跳 |
| 条件路由 | 工程工作流、明确分支 | 规则维护成本高 |
| 发布/订阅 | 异步协作、黑板模式 | 消息膨胀、重复处理 |
结果合并又是另一个问题:
| 决策方式 | 适合场景 | 风险 |
|---|---|---|
| 投票 | 多个独立判断 | 可能平庸化 |
| 辩论 | 高价值决策 | 成本高、耗时长 |
| Judge 裁决 | 需要证据权重 | Judge 本身会偏 |
| 加权聚合 | Agent 可信度差异明显 | 权重很难设定 |
很多系统把这两个问题混在一起,结果会变得混乱。
比如“让下一个 Agent 自己判断该做什么”,这是路由问题;“三个 Agent 给出不同结论后选哪个”,这是决策融合问题。前者更像消息调度,后者更像裁判机制。
Debug 场景里我会更保守:路由尽量规则化,决策尽量证据化。
也就是说,先用固定骨架决定什么时候调用 Debug Specialist,再让它输出带证据的诊断候选。最后是否采纳,不由它自己说了算,而交给后续测试、Reviewer 或人工节点。
状态协议:共享上下文越多,系统越容易互相污染
Multi-Agent 系统里最容易被低估的问题,是状态。
单 Agent 系统里,上下文污染已经很常见。模型前面做了一个错误假设,后面会沿着这个假设继续推理。到了 Multi-Agent,污染会被放大:一个 Agent 的中间判断进入共享上下文后,其他 Agent 可能把它当成事实继续使用。
这有点像多个进程共享内存。
共享内存很快,但也危险。没有边界时,一个进程写错,其他进程全都读到错误状态。
所以我现在会把 Agent 状态分成四类:
| 状态类型 | 是否应该共享 | 例子 |
|---|---|---|
| 原始输入 | 可以共享 | 用户需求、错误日志、代码 diff |
| 证据 | 可以共享,但要保留来源 | 测试输出、搜索结果、文件片段 |
| 中间假设 | 谨慎共享 | “可能是 Redis 连接池耗尽” |
| 最终结论 | 需要裁决后共享 | 根因、修复方案、发布建议 |
这里的关键是:不要把所有内容都塞进同一个全局上下文。
Microsoft 最近开源的 Conductor 也强调了类似取舍:每个 Agent 可以有独立 session,工作流可以显式控制上下文流动,避免“隐式对话泄漏”。它甚至提供了不同的 context mode,用来决定下游 Agent 看见全部历史、上一步输出,还是显式指定的依赖。
这点对 Debug 场景尤其重要。
故障诊断里有很多“看起来像事实,其实只是猜测”的内容。比如:
可能是连接池耗尽。
可能是线程池拒绝。
可能是配置没加载。
可能是版本不兼容。
这些都不应该和真实日志、真实代码、真实测试输出混在一起。
我在 DebugMind 里把 Markdown 作为记忆源头,也是出于这个考虑。向量索引可以帮助召回相似案例,但长期记忆必须能被人读、被 Git diff、被 review、被修正。否则一个错误诊断被写进黑盒记忆里,下次再被相似检索召回,系统就会越来越自信地重复错误。
所以,对 Multi-Agent 来说,状态协议至少要回答:
- 哪些内容是原始证据?
- 哪些内容是 Agent 推断?
- 哪些内容已经被验证?
- 哪些内容只是临时上下文?
- 哪些内容允许写入长期记忆?
这比“多接一个向量库”更重要。

调度协议:谁决定下一步由谁做
Multi-Agent 的第三个核心问题,是调度。
一个常见设计是让一个 Orchestrator Agent 动态决定下一步调用谁。这种方式灵活,适合开放式任务。Anthropic 的研究系统就是典型的 orchestrator-worker 模式:lead agent 规划研究策略,创建多个 subagent 并行探索不同方向,再汇总结果。
但动态调度也有代价。
Orchestrator 本身也是 LLM,它会消耗 token,会判断失误,会过度拆分任务,也可能低估任务复杂度。Anthropic 的文章里提到,他们早期遇到过 subagent 数量失控、重复搜索、无效探索等问题,后来通过更明确的任务边界、工具描述、努力规模规则和评测来收敛。
另一条路线是确定性编排。
比如 Conductor 这类工具,把流程写成 YAML:哪个 Agent 先跑,哪个 Agent 后跑,什么时候分支,什么时候循环,什么时候人工审批。它牺牲一部分动态性,换来可 review、可版本化、可预测的工作流。
我觉得这两种方式没有绝对优劣,关键看任务类型。
| 场景 | 更适合的调度方式 |
|---|---|
| 开放式研究、信息探索 | 动态 Orchestrator |
| 固定工程流程、代码审查、CI 修复 | 确定性工作流 |
| Debug 诊断 | 两者结合:固定骨架 + 局部动态 |
Debug 就是一个很典型的混合场景。
它有固定骨架:
收集症状 -> 查历史案例 -> 看日志 -> 看代码 -> 给出根因 -> 写回经验
但每一步内部又需要动态判断。比如日志指向 Redis,就该看连接池配置;日志指向线程池,就该看拒绝策略;日志指向 NPE,就该回到堆栈行附近读代码。
这也是我构建 DebugMind 时的取舍:整体流程固定,诊断循环内部保留 ReAct 式工具调用。固定流程给系统可控性,动态工具调用给它排障能力。
如果未来把它放进更大的 Multi-Agent 工作流,我更希望上层调度是清晰的:
Incident Triage Agent
-> Debug Specialist
-> Fix Proposal Agent
-> Test Agent
-> Human Review Gate
Debug Specialist 只输出诊断,不直接越权进入修复和上线。
并发协议:Multi-Agent 也会遇到分布式系统问题
多个 Agent 同时工作时,本质上会遇到分布式系统里的老问题。
比如共享状态竞争。
两个 Agent 同时写入同一个记忆库,一个把案例标成“已验证”,另一个又根据旧状态覆盖成“待确认”。如果没有版本号、锁或事件日志,最后状态就不可信。
再比如消息顺序。
Test Agent 的失败结果如果比 Fix Agent 的修复说明先到,Reviewer 可能会基于过时信息下判断。异步系统里,消息到达顺序和业务因果顺序经常不一致。
还有死锁。
Debug Agent 等 Code Agent 补充代码片段,Code Agent 又等 Debug Agent 给出更具体文件路径。两个 Agent 都在等对方,任务就停住了。
这些问题在传统后端里很熟悉:
| 分布式问题 | Multi-Agent 表现 | 常见处理 |
|---|---|---|
| 竞态条件 | 多个 Agent 同时写共享状态 | 锁、CAS、版本号 |
| 状态不一致 | Agent 读取到不同版本上下文 | 事件日志、版本控制 |
| 消息乱序 | 后发结果先到 | 序号、trace、因果关系 |
| 死锁 | Agent 互相等待 | 超时、DAG 依赖图 |
| 部分失败 | 某个 Agent 崩溃或超预算 | 降级、补偿、人工升级 |
这也是我为什么不喜欢把 Multi-Agent 只讲成“多个角色聊天”。
一旦它开始读写共享状态、调用工具、并发执行、长期运行,它就进入了分布式系统的世界。
权限协议:工具越多,越需要最小权限
Agent 的能力来自工具,但风险也来自工具。
在单 Agent 场景里,工具权限已经需要控制。到了 Multi-Agent,每个 Agent 能用哪些工具更要精细化。否则一个本来只负责总结的 Agent,可能拿到了写文件、删数据、调用生产 API 的权限。
MCP 的授权规范把授权能力放在传输层,要求受保护资源暴露授权服务器信息,并遵循 OAuth 2.1 的安全通信要求。对普通开发者来说,不一定每次都要完整实现复杂授权,但这个方向很明确:Agent 调工具时,权限应该是系统设计的一部分,而不是上线前补一个 token。
我在 DebugMind 的 MCP Server 里也做了一个很小的边界:读工具和写工具分开,写入、验证、删除这类操作可以通过 DEBUG_MIND_MCP_TOKEN 做鉴权,还加了写操作限流和审计日志。
这不是复杂安全系统,但它反映了一个设计原则:
能读历史案例,不代表能写入长期记忆。
能给出诊断,不代表能验证诊断正确。
能保存案例,不代表能删除团队经验。
Multi-Agent 系统里,每个 Agent 都应该拿到刚好够用的工具。
预算协议:并行能力不是免费的
Multi-Agent 经常看起来更强,是因为它能同时花更多 token、调用更多工具、探索更多路径。
Anthropic 的多 Agent 研究系统复盘里有一个很现实的提醒:他们的多 Agent 架构在内部研究评测上显著超过单 Agent,但 token 消耗也高很多。文章里提到,多 Agent 系统大约使用了聊天交互 15 倍的 token。
所以 Multi-Agent 并不是免费扩容。
更像是你开了更多进程、更多线程、更多网络请求。吞吐上去了,成本、调度复杂度和故障面也上去了。
一个工程系统至少要有这些预算限制:
- 最多启动多少个 subagent。
- 每个 Agent 最多跑多少轮。
- 每个工具最多并发多少次。
- 单次任务最大 token 成本是多少。
- 最大挂钟时间是多少。
- 超过预算后如何降级输出。
OpenAI Agents SDK 的 maxTurns、工具超时、error handler 和 tracing,其实都在提醒同一件事:Agent 运行不是一个无限对话,它应该有明确的停止条件和错误处理路径。
我在 DebugMind 里做 token/cost budget、最大诊断轮数和挂钟超时,也是因为 Debug Agent 很容易陷入“再看一个文件、再搜一次代码、再问一次模型”的循环。排障需要耐心,但系统必须知道什么时候停止。
可观测协议:没有 trace,Multi-Agent 很难 debug
Multi-Agent 系统的另一个讽刺点是:你用 Agent 去解决复杂问题,但 Agent 系统本身也很难 debug。
当结果不对时,你需要知道:
- 哪个 Agent 做了错误判断?
- 它看到了哪些上下文?
- 它调用了哪些工具?
- 工具返回了什么?
- 它为什么交接给下一个 Agent?
- 哪一步开始偏离目标?
没有 trace,只看最终答案,几乎无法定位问题。
OpenAI Agents SDK 的 tracing 会记录 LLM generation、tool call、handoff、guardrail、自定义事件等运行过程。Anthropic 也在多 Agent 系统复盘里强调,完整生产 tracing 帮助他们诊断 agent 为什么失败,比如搜索 query 是否糟糕、工具是否选错、来源是否低质量。
这和传统后端服务很像。
你不会把一个微服务系统上线后只看最终 HTTP 500。你会看 trace id、span、日志、指标、错误堆栈。Multi-Agent 也需要类似能力。
我在 DebugMind 里加入结构化日志、trace id、审计日志,也是因为诊断系统必须能被诊断。一个 Debug Agent 如果自己出了问题却没有日志,那它很难成为团队基础设施。
裁决协议:多个 Agent 给结论后,谁说了算
Multi-Agent 系统还有一个容易回避的问题:多个 Agent 给出不同结论时,谁说了算?
比如 Debug 场景里:
- Memory Agent 说:历史案例像 Redis 连接池耗尽。
- Code Agent 说:当前代码更像 Optional 使用错误。
- Log Agent 说:根因可能是线程池拒绝。
- Test Agent 说:复现失败。
这时候不能简单投票。
因为不同 Agent 的证据权重不一样。历史案例有启发价值,但不能压过当前日志。代码静态分析有价值,但不能替代复现。测试失败本身也要区分是修复失败,还是测试环境没搭好。
所以裁决协议要定义:
- 哪类证据优先级更高。
- 哪些结论必须被测试验证。
- 哪些结论只能作为候选假设。
- 哪些情况下必须交给人审。
- 最终输出是否允许带多个假设。
我的理解是,Multi-Agent 的最终节点应该更像一个 Judge 或 Reviewer,而不是简单的 Summarizer。
Summarizer 负责把大家的话合并成一段。Judge 要判断证据强弱、冲突来源、风险等级和下一步动作。
这也是为什么我在 DebugMind 的记忆里区分 verified 和 hit_count。一个案例被检索到,不代表它一定正确;一个诊断被写入,也不代表它应该永久作为高可信知识。经验需要被验证,命中次数也只能作为排序信号,不能代替事实。
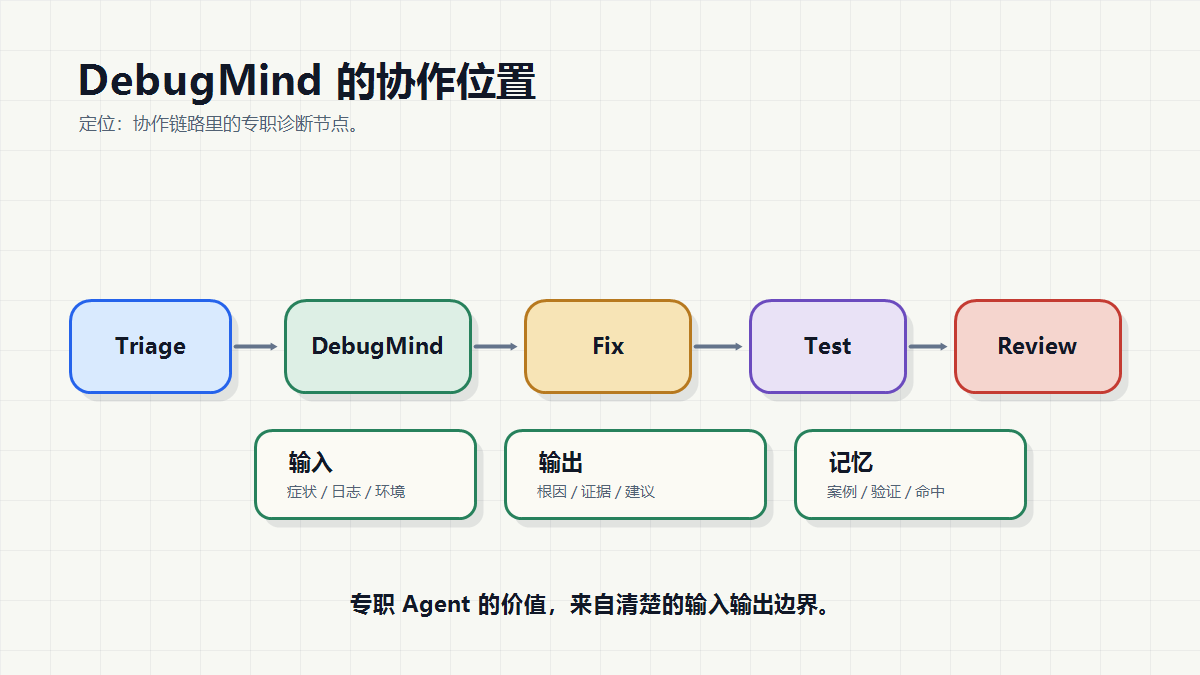
我现在会怎样设计一个最小 Multi-Agent Debug 工作流
如果要围绕 Debug 场景做一个最小可用的 Multi-Agent 工作流,我不会一上来做很多 Agent。
我会先做五个角色:
Triage Agent:整理故障现象,判断是否需要进入诊断流程
Debug Specialist:检索历史案例,结合日志和代码给出根因候选
Fix Proposal Agent:把根因转成最小修复方案
Test Agent:运行或生成验证步骤
Human Review Gate:决定是否采纳、回滚或升级
这里 DebugMind 更适合作为第二个节点。它不负责全链路自治,只负责把排障经验和当前证据结合起来。
这正是我构建它时的一个核心思考:先让一个专职 Agent 的边界足够清楚,再考虑它如何进入更大的协作系统。
从软件工程角度看,这比一开始就做“全自动修 Bug 大模型系统”更可靠。
因为你可以逐层验证:
- Debug Specialist 的检索质量是否稳定。
- 诊断输出是否结构化。
- 修复建议是否能被下游 Agent 消费。
- 历史案例是否能被人 review。
- 写回记忆是否有权限和审计。
每一层都能单独测试,系统才有机会长期演进。
常见坑
1. 用角色名代替角色协议
“Planner”“Coder”“Reviewer”只是名字,不是协议。
真正要写清楚的是输入、输出、权限、停止条件和失败处理。
2. 让所有 Agent 共享完整上下文
完整上下文看起来信息最多,但会带来污染和成本问题。
更好的方式是让每个 Agent 看到它真正需要的证据、约束和上游输出。
3. 交接只靠自然语言
自然语言适合解释,但不适合做稳定接口。
关键交接应该有结构化字段,比如任务类型、证据列表、假设、已排除路径、期望输出。
4. 缺少预算上限
没有最大轮数、最大成本、最大时间,Multi-Agent 很容易把一个小问题排查成一次长跑。
5. 把记忆当成万能共享区
长期记忆必须可审查、可回滚、可验证。
错误经验一旦进入共享记忆,后续 Agent 会反复继承这个错误。
6. 没有裁决者
多个 Agent 输出多个观点后,需要一个明确的裁决节点。
否则系统只是在收集意见,没有形成判断。
7. 群体思维
多个 Agent 看起来很多样,但如果它们共享同一段上下文、同一套提示词、同一种模型偏好,很容易一起走向同一个错误结论。
解决办法是有意识地引入不同视角,比如反例检查、风险审查、证据核查,而不是盲目增加 Agent 数量。
8. 责任分散
多 Agent 系统里很容易出现“每个 Agent 都以为别人会处理”的情况。
所以每个任务都要有明确 owner。协作可以多人参与,责任不能悬空。
9. 级联幻觉
一个 Agent 的错误判断如果被后续 Agent 当成事实,就会逐级放大。
这也是为什么我强调证据、假设、结论要分层。中间假设不能直接进入长期记忆,未经验证的诊断也不能被当成高可信案例。
最小落地清单
如果你准备做一个 Multi-Agent 系统,我建议先写一份很短的协议文档,而不是直接开工写 Agent。
可以按这几个问题写:

-
角色协议
每个 Agent 的职责、非职责、输入、输出、权限是什么? -
交接协议
上游 Agent 交给下游 Agent 的 payload 长什么样? -
状态协议
哪些内容是证据,哪些内容是假设,哪些内容可以进入长期记忆? -
调度协议
流程是动态 Orchestrator,还是确定性工作流,还是混合模式? -
权限协议
每个 Agent 能调用哪些工具?读写权限是否分离? -
预算协议
最大轮数、最大 token、最大成本、最大并发和超时是多少? -
可观测协议
如何记录 trace、tool call、handoff、错误、审计日志? -
裁决协议
多个 Agent 结论冲突时,谁决定最终输出? -
评测协议
你评估最终状态,还是评估每一步路径?有没有小样本回归集? -
并发协议
多个 Agent 同时读写共享状态时,如何处理锁、版本、消息顺序、超时和部分失败?
写完这些协议,你可能会发现,很多任务根本不需要 Multi-Agent。一个单 Agent 加几个工具就够了。
这不是坏事。
Multi-Agent 应该用在真正需要并行探索、角色隔离、复杂交接、长期状态和多步验证的地方。它更接近系统工程,不是提示词工程的自然升级版。
总结
我现在看 Multi-Agent,最关心的已经不是“几个 Agent”。
我更关心它有没有像操作系统一样定义清楚:
- 谁是进程。
- 谁是调度器。
- 谁能读写共享状态。
- 谁能调用危险工具。
- 谁负责异常恢复。
- 谁负责最终裁决。
从这个角度看,一个真正可落地的 Multi-Agent 系统,重点会落在协作协议上,而不是模型数量上。
这也是我构建 DebugMind 时得到的一个提醒:先把一个专职 Agent 的输入、输出、记忆、预算、权限和评测做清楚,再把它放进更大的协作系统里。否则 Agent 越多,系统越像一团没有边界的上下文。
如果你对 Debug Specialist 这种 Agent 形态感兴趣,可以看一下我最近开源的 DebugMind:
https://github.com/zavoryn/debug-mind
我更希望它被看作一个实践样本:当一个 Agent 要进入协作系统时,它应该如何定义自己的边界。
参考资料
- Anthropic Engineering: How we built our multi-agent research system
- OpenAI Agents SDK: Handoffs
- OpenAI Agents SDK: Sessions
- OpenAI Agents SDK: Tracing
- Microsoft Open Source Blog: Conductor: Deterministic orchestration for multi-agent AI workflows
- Model Context Protocol: Authorization
- DebugMind: zavoryn/debug-mind

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐


 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)