链表(单链表、双链表、模拟链表)
链表是一种动态数据结构,通过指针连接节点,支持高效插入和删除操作(O(1)时间复杂度),适用于数据规模不确定或频繁修改的场景。其主要优势包括动态内存管理、高效增删、灵活适配不连续内存等,常用于实现栈、队列、哈希表等数据结构,以及操作系统任务调度、LRU缓存等应用。但与数组相比,链表不支持随机访问(O(n)查找),且存储指针有额外空间开销。双向链表通过增加前驱指针,支持双向遍历和O(1)节点删除,广
链表
一、链表的主要用途
链表的主要用途是支持高效插入与删除、动态内存分配,适用于数据规模不确定或频繁修改的场景。
1、动态大小管理:
无需预先分配固定内存,可按需申请/释放节点,适合数据量变化大的应用(如实现动态数组、内存池)。
2、高效插入/删除:
在已知位置时,时间复杂度为 O(1)(仅改指针),远优于数组的 O(n)(需搬移元素)。
3、实现其他数据结构:
底层常用于构建栈、队列、哈希表(解决冲突)、图的邻接表等。
4、避免内存碎片限制:
节点可分散存储,不依赖连续内存,适合嵌入式或内存碎片化环境。
5、特定算法与系统应用:
如文件系统目录、文本编辑器光标管理(双向链表)、操作系统任务调度、哈希冲突链式存储等。缺点是不支持随机访问(查找需 O(n))且额外存储指针开销大,故不适用于高频随机读取的场景。

二、链表的核心作用
链表的核心作用是适配动态数据场景,解决数组插入/删除效率低、需要预分配空间的问题。以下是具体作用和典型应用场景:
1、核心作用优势
(1)、高效插入删除:
插入或删除节点只需修改相邻节点的指针,时间复杂度为O(1),远优于数组的O(n)(数组需要移动大量后续元素)。
(2)、动态内存管理:
无需预先确定数据规模,节点可在运行时动态生成,用多少内存分配多少,不会造成空间浪费。
(3)、灵活适配不连续内存:
不需要整块连续内存空间,可利用内存中的零散碎片,提升内存利用率。
2、典型应用场景
(1)、底层数据结构实现:
常用来实现栈、队列、哈希表、图邻接表等基础数据结构,其中哈希表会用链表处理哈希冲突(存储相同哈希值的数据)。
(2)、操作系统内核:
操作系统的就绪表、等待表、挂起表等任务调度场景,普遍使用双向循环链表管理任务,方便快速增删任务节点。
(3)、高频增删业务场景:
如LRU缓存淘汰策略、音乐/视频播放列表,需要频繁增减条目,链表能保证操作高效。
(4)、编程语言内置容器:
Java的LinkedList、C++的std::list等内置容器底层都基于链表实现,提供动态增删能力。
3、局限性
链表也存在短板:访问指定元素需要从头开始遍历,随机访问的时间复杂度为O(n),比数组的O(1)慢;同时每个节点需要额外存储指针,空间开销更大。因此适合频繁增删、较少随机访问的场景。
三、链表和数组的具体适用场景差异
链表和数组的核心差异可以从5个关键维度对比,结合场景选择如下:
|
对比维度 |
数组 |
链表 |
|
存储方式 |
内存连续,无需额外指针存储关联 |
内存分散不连续,每个节点需要额外指针存储下一个节点地址 |
|
访问效率 |
支持索引随机访问,时间复杂度O(1),访问速度快 |
只能从头遍历,随机访问时间复杂度O(n),访问速度慢 |
|
增删效率 |
插入/删除需要移动大量元素,时间复杂度O(n),效率低 |
仅需修改指针,已知节点位置时增删时间复杂度O(1),效率高 |
|
空间特性 |
需要提前申请固定大小,提前预留空间易浪费,扩容需要复制整体元素 |
动态分配空间,用多少申请多少,无空间浪费,内存利用率高 |
|
缓 存 友好性 |
连续内存空间能提升缓存命中率,访问更快 |
分散内存导致缓存命中率低,访问开销更大 |
场景选择参考
1、选数组:满足以下任意一种场景优先用数组:
(1)、需要频繁随机访问元素,对访问速度要求高
(2)、元素总量提前确定,不会频繁变化
(3)、对内存空间利用率要求高,不希望有额外指针开销
(4)、典型场景:矩阵运算、排序算法底层、静态数据缓存、批量同类型数据存储
2、选链表:满足以下任意一种场景优先用链表:
(1)、需要频繁在任意位置插入、删除元素
(2)、元素总量不确定,运行过程中规模变化大
(3)、无法申请到足够大的连续内存空间
(4)、典型场景:任务调度队列、LRU缓存、播放列表、动态栈/队列、哈希冲突处理

四、如何根据场景选择适合的数据结构
选择适合的数据结构是解决编程问题的核心步骤,主要需要从操作频率、数据规模、内存限制、数据关系四个维度进行综合权衡。以下是具体的决策逻辑和常见场景映射:
1. 核心决策维度
A、操作类型(高频操作是什么?)
(1)、频繁查找/随机访问 → 优先选 数组 或 哈希表。
(2)、频繁插入/删除 → 优先选 链表。
(3)、频繁排序/查找极值 → 优先选 堆(Heap) 或 二叉搜索树(BST)。
(4)、频繁前缀匹配/字符串处理 → 优先选 字典树(Trie)。
B、数据规模与动态性
(1)、数据量固定或已知 → 数组(内存连续,效率高)。
(2)、数据量未知且剧烈波动 → 链表 或 动态数组(如 ArrayList)。
(3)、海量数据(内存放不下) → 考虑 外部排序 或基于磁盘的 B+树。
C、空间复杂度(内存是否敏感?)
(1)、内存极度受限 → 数组(无额外指针开销)。
(2)、内存充足,追求开发效率 → 哈希表 或 高级容器。
D、数据间的逻辑关系
(1)、线性关系 → 数组、链表、栈、队列。
(2)、层级/树状关系 → 树(二叉树、红黑树、B+树)。
(3)、网状/多对多关系 → 图(邻接矩阵或邻接表)。
2. 常见场景与数据结构映射表
|
业务场景/需求特征 |
推荐数据结构 |
理由 |
|
快速查找特定ID/Key |
哈希表 (HashMap) |
平均时间复杂度 O(1),查找速度最快。 |
|
需要保持插入顺序 + 快速查找 |
LinkedHashMap |
结合哈希表的查找优势和链表的顺序优势。 |
|
频繁在头部/中间增删数据 |
链表 (LinkedList) |
避免移动大量元素,O(1) 完成指针修改。 |
|
实现“最近最少使用”缓存 (LRU) |
哈希表 + 双向链表 |
哈希表负责快速定位,链表负责维护访问顺序。 |
|
表达式求值 / 括号匹配 / 递归模拟 |
栈 (Stack) |
符合“后进先出” (LIFO) 的逻辑特性。 |
|
任务调度 / 广度优先搜索 (BFS) |
队列 (Queue) |
符合“先进先出” (FIFO) 的逻辑特性。 |
|
获取最大/最小值 / 优先级任务 |
堆 (Heap/Priority Queue) |
能在 O(log n) 时间内获取极值,适合Top K问题。 |
|
数据库索引 / 文件系统目录 |
B+树 / B树 |
减少磁盘I/O次数,适合范围查询和大规模数据存储。 |
|
自动补全 / 词频统计前缀 |
字典树 (Trie) |
利用字符串公共前缀节省空间,检索效率高于哈希表。 |
|
社交网络关系 / 地图路径规划 |
图 (Graph) |
能够表达节点之间复杂的多对多连接关系。 |
3. 实战选择建议(简化版)
(1)、默认首选数组:
如果不确定选什么,且数据量不大、增删不频繁,直接用数组。它内存紧凑、CPU缓存友好,实际运行速度往往最快。
(2)、查得多用哈希:
如果核心需求是“通过Key快速找到Value”,毫不犹豫选哈希表。
(3)、改得多用链表:
如果需要在列表中间频繁插入或删除,且数据量较大,选链表。
(4)、有序用树/堆:
如果数据需要保持有序,或者需要频繁获取最大/最小值,选择平衡二叉搜索树(如红黑树、TreeMap)或堆。
(5)、层次用树,网状用图:
根据数据本身的逻辑结构决定,不要强行用线性结构去模拟复杂关系。
4. 避坑指南
(1)、不要过度优化:
在数据量较小(如小于1000)时,数组和链表的性能差异几乎可以忽略,此时应选择代码更简单、更易维护的结构(通常是数组)。
(2)、注意语言特性:
Java中的 ArrayList 底层是数组,LinkedList 底层是链表;Python的 list 底层是动态数组。了解语言内置容器的底层实现,能帮你做出更准确的选择。

五、如何权衡数组和链表的优缺点
权衡数组和链表的优缺点,核心是围绕「访问效率」和「增删效率」做 trade-off(取舍),关键看你的场景中「访问」和「增删」哪个更频繁,结合内存、性能要求综合判断,以下是清晰的权衡逻辑:
1. 先抓住核心矛盾:二者优缺点完全互补
|
优势维度 |
数组 |
链表 |
|
随机访问效率 |
✅ O(1),极快 |
❌ O(n),慢 |
|
任意位置增删效率 |
❌ O(n),慢(需要移动元素) |
✅ O(1),快(仅改指针) |
|
内存空间利用率 |
❌ 预分配浪费/需扩容复制,利用率低 |
✅ 动态分配,无浪费,利用率高 |
|
CPU缓存友好性 |
✅ 连续内存,缓存命中率高,实际访问更快 |
❌ 分散内存,缓存命中率低,访问开销大 |
|
空间额外开销 |
✅ 无额外指针,仅存数据 |
❌ 每个节点额外存指针,总空间开销更大 |
2. 分场景权衡决策逻辑
可以按以下优先级依次判断,快速做出选择:
第一步:看「什么操作是高频」
如果查找/随机访问是核心需求,增删很少:直接选数组。哪怕数据量小,增删慢的影响可以忽略,数组的访问速度优势会带来更大收益。
例:存储固定的配置列表、需要按下标快速取元素、排序算法的底层存储。
如果频繁插入/删除元素,访问多为顺序遍历:优先选链表。增删的效率收益远大于访问慢的损失。
例:LRU缓存的队列、操作系统任务链表、频繁增删的播放列表。
第二步:看「数据规模是否确定」
如果提前能确定数据总量,不会大幅变化:选数组,提前分配好空间,没有动态分配的开销,性能更稳定。
如果数据规模完全不确定,运行时波动极大:选链表,不会因为预分配空间不够扩容,也不会浪费预留的内存。
第三步:看「内存约束」
如果内存紧张,对空间开销敏感:选数组,没有额外指针的空间浪费,内存利用率更高。
如果内存充足,碎片化比较严重,找不到连续大块内存:选链表,利用零散内存就能存储。
3. 容易混淆的误区纠正
不要迷信“链表增删快”:只有找到插入位置后才是O(1)
如果需要先遍历找到插入位置,整体复杂度还是O(n),和数组差别不大。只有头尾增删、或已经定位到节点时,链表才真的快。
现代CPU架构下,数组实际性能往往比链表好
哪怕理论上链表增删是O(1),但因为缓存命中率极低,实际运行速度可能远慢于数组,只有数据量极大时,链表的优势才会体现。
大多数场景不需要硬选:动态数组(如Java ArrayList、Python list)已经兼顾两者优势
动态数组本质是数组,支持自动扩容,大部分常规开发场景直接用它足够,不需要刻意用链表。
一句话总结权衡口诀
查得多、规模定、内存紧,选数组;改得多、规模变、缺连续,选链表。

六、std::vector和std::list哪个更高效
在绝大多数现代 C++ 应用场景中,std::vector 比 std::list 更高效。
虽然从算法复杂度理论上看,std::list 在中间插入/删除是 O(1),而 std::vector 是O(n),但在实际硬件运行环境中,内存局部性(Cache Locality) 对性能的影响往往远超算法复杂度。
以下是详细的效率对比与选型指南:
1. 核心结论:为什么 std::vector 通常更快?
A、缓存友好(Cache Friendly):
(1)、std::vector 的元素在内存中连续存储。CPU 预取器(Prefetcher)可以高效地将后续数据加载到高速缓存(L1/L2 Cache)中。
(2)、std::list 的节点在堆上分散分配。遍历链表时,每次访问下一个节点都可能发生 Cache Miss(缓存缺失),导致 CPU 等待内存读取,这种延迟远高于简单的内存拷贝。
B、内存分配开销少:
(1)、std::vector 一次性分配一大块连续内存,扩容频率低。
(2)、std::list 每插入一个元素都要单独进行一次内存分配(new/malloc),频繁的小对象分配不仅慢,还容易导致内存碎片。
C、指令流水线优化:
(1)、连续内存允许 CPU 更好地进行分支预测和指令并行执行。
(2)、链表的指针跳转(Pointer Chasing)会导致流水线停顿。
2. 详细性能对比表
|
操作场景 |
std::vector |
std::list |
谁更高效? |
|
随机访问 (v[i]) |
O(1)O(1)O(1),极快 |
O(n)O(n)O(n),需遍历 |
Vector 完胜 |
|
尾部插入 (push_back) |
摊销 O(1)O(1)O(1),极快 |
O(1)O(1)O(1),快 |
Vector 略快或持平 |
|
头部插入 (push_front) |
O(n)O(n)O(n),需移动所有元素 |
O(1)O(1)O(1),仅改指针 |
List 胜 |
|
中间插入/删除 |
O(n)O(n)O(n),需移动元素 |
O(1)O(1)O(1),仅改指针* |
视情况而定 |
|
遍历/迭代 |
极快(缓存命中率高) |
慢(缓存命中率低) |
Vector 完胜 |
|
排序(std::sort) |
极快 |
不支持随机访问,需用 list::sort |
Vector 完胜 |
|
内存占用 |
低(无额外指针,可能有预留空间) |
高每个节点多2个指针+对齐开销 |
Vector 胜 |
注意:std::list 的中间插入 O(1) 前提是你已经拥有了指向该位置的迭代器。如果你需要先查找位置(O(n)),那么总耗时也是 O(n),且由于缓存不友好,实际运行往往比 vector 更慢。
3. 实测数据参考
根据多项基准测试(如 Bjarne Stroustrup 的测试或 GitHub 上的 benchmark):
(1)、遍历整数列表:
std::vector 比 std::list 快 5~10 倍甚至更多。
(2)、随机插入:
对于小数据类型(如 int),std::vector 往往仍然更快,因为移动几个字节的内存比分配一个新节点并处理指针要快得多。
(3)、大数据对象:
如果元素非常大(如包含大量数据的结构体),移动成本高,此时 std::list 的指针交换优势才会显现。
4. 什么时候应该选 std::list?
尽管 vector 通常更快,但以下场景 std::list 是更好的选择:
(1)、迭代器稳定性要求高:
在遍历过程中需要频繁插入/删除元素,且希望其他迭代器不受影响。vector 插入/删除可能导致所有后续迭代器失效,而 list 只有被删除节点的迭代器失效。
(2)、超大对象且频繁中间增删:
如果元素对象非常大(拷贝/移动代价极高),且在容器中间频繁增删,list 避免数据移动的优势会超过缓存劣势。
(3)、实现特定数据结构:
如实现 LRU 缓存、队列、或者需要 splice(拼接)操作时,list 的节点链接特性非常有用。
5. 最佳实践建议
(1)、默认首选 std::vector:
除非你有明确的理由证明 vector 不适用,否则永远优先使用 vector。它是 C++ 中性能最均衡、最通用的容器。
(2)、如果需要频繁头尾增删:
考虑 std::deque,它在头尾增删上是 O(1),且支持随机访问,性能介于 vector 和 list 之间。
(3)、如果必须用链表:
确保你真正需要双向链表(std::list)。
如果只需要单向链表,使用 std::forward_list,它更节省内存。
不要为了“理论上的 O(1) 插入”而盲目选择 list,务必通过 Profiling(性能分析工具)验证实际瓶颈。
6、总结:
(1)、追求极致性能、遍历、随机访问、尾部操作 → std::vector
(2)、追求迭代器稳定、频繁中间增删大对象、特定算法需求 → std::list

七、为什么要用双向链表,双向链表有什么用
双向链表(Doubly Linked List)是在单向链表的基础上,为每个节点增加了一个指向前驱节点(Previous Node)的指针。
它的核心作用是解决单向链表“只能前进、不能后退”以及“删除节点必须从头遍历找前驱”的效率瓶颈。
以下是双向链表的核心用途及为什么要使用它的详细分析:
1. 核心优势:为什么要用双向链表?
|
维度 |
单向链表 |
双向链表 |
优势解读 |
|
遍历方向 |
只能从头到尾(单向) |
支持双向遍历(头↔尾) |
可以从任意节点向前或向后查找,灵活性极高。 |
|
删除节点 |
需从头遍历找到前驱节点,复杂度 O(n) |
已知节点时,直接通过前驱指针修改,复杂度 O(1) |
这是最大的性能优势,无需额外遍历即可自我删除。 |
|
插入节点 |
需找到前驱节点,复杂度 O(n) |
已知位置时,直接修改前后指针,复杂度 O(1) |
在任意位置插入更高效。 |
|
空间开销 |
小(1个指针) |
大(2个指针:next + prev) |
用空间换时间,适合对增删效率要求高的场景。 |
2. 典型应用场景:双向链表有什么用?
A. LRU 缓存淘汰算法(最经典场景)
(1)需求:
需要快速访问数据(HashMap),同时需要维护数据的“最近使用顺序”,当缓存满时,淘汰最久未使用的数据(通常在链表尾部)。
(2)、为什么用双向链表:
当某个数据被访问时,需要将其从当前位置移除并移动到链表头部。
如果使用单向链表,移除节点需要从头遍历找到前驱节点,效率低。
(3)、使用双向链表,结合 HashMap 存储节点引用,可以直接通过 prev 和 next 指针在 O(1) 时间内完成节点的移除和重插。
Java中的 LinkedHashMap 底层就是基于双向链表实现的。
B. 浏览器的前进/后退功能
(1)、需求:
用户浏览网页时,可以点击“后退”回到上一页,也可以点击“前进”回到下一页。
(2)、为什么用双向链表:
- 当前页面作为链表中的一个节点。
- “后退”操作即访问 prev 节点。
- “前进”操作即访问 next 节点。
- 双向结构完美契合这种双向导航的需求。
C. 音乐/视频播放列表
(1)、需求:
支持“上一首”、“下一首”切换,支持在当前歌曲后插入新歌曲,支持删除当前歌曲。
(2)、为什么用双向链表:
- 双向遍历支持无缝切换上一首/下一首。
- 删除当前正在播放的歌曲时,不需要重新遍历列表,直接调整前后节点的指针即可保持播放顺序连贯。
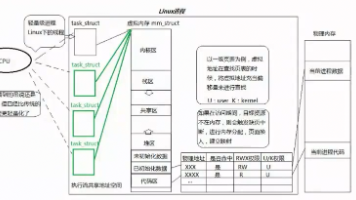
D. 操作系统内核任务调度
(1)、需求:
操作系统需要管理成千上万个进程/线程,频繁地进行任务的添加、移除、状态切换(如从“运行态”移到“等待态”)。
(2)、为什么用双向链表:
- Linux 内核中的进程控制块(PCB)通常通过双向链表连接。
- 当一个进程结束或被挂起时,内核需要迅速将其从就绪队列中移除,双向链表的 O(1) 删除特性至关重要。
E. 实现双端队列(Deque)
(1)、需求:
支持在头部和尾部都进行高效的插入和删除操作。
(2)、为什么用双向链表:
- 单向链表只能在头部高效操作,尾部操作需要遍历。
- 双向链表配合尾指针,可以在头尾两端都实现 O(1) 的增删,是实现 std::deque 或 Java ArrayDeque(部分实现)的基础结构之一。
3. 总结:何时选择双向链表?
(1)、选双向链表:
当你需要频繁在任意位置插入/删除节点,或者需要双向遍历(如前进/后退、上一首/下一首)时。
(2)、不选双向链表:
如果内存非常敏感,且只需要单向遍历、极少删除操作,单向链表或数组可能更合适。
双向链表是用额外的空一句话总结:
间(一个指针)换取了时间效率(O(1) 删除/插入)和操作灵活性(双向遍历),是处理动态数据序列的高级工具。

链表动画演示 等比数列 linux视频等
https://blog.csdn.net/dllglvzhenfeng/article/details/126691692
NOI入门数据结构:线性表之链表
https://blog.csdn.net/dllglvzhenfeng/article/details/123785589
信息学奥赛 链表专题
https://blog.csdn.net/dllglvzhenfeng/article/details/130900295
3440:【例77.1】模拟链表
https://blog.csdn.net/dllglvzhenfeng/article/details/141893048
分块、块状链表
https://blog.csdn.net/dllglvzhenfeng/article/details/123007049


openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐
 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)