Linux 负载均衡的 can_migrate_task:任务迁移的资格检查
Linux内核负载均衡机制在多核与NUMA架构服务器中至关重要,其核心函数can_migrate_task负责在任务迁移前进行严格资格审查。该函数通过四层检查(运行状态、CPU亲和性、缓存热度、NUMA拓扑)来平衡负载均衡收益与迁移开销,避免盲目迁移导致的性能下降。本文基于Linux 5.15/6.1内核源码,详细解析了can_migrate_task的实现原理、约束条件和调优方法,并提供了实操案
简介
在多核与 NUMA 架构成为服务器主流的今天,Linux 内核的负载均衡机制是保障系统整体吞吐、避免资源倾斜的核心能力。负载均衡并非简单的 “见忙就搬”,每一次任务迁移都伴随着缓存失效、上下文切换、跨 NUMA 节点内存访问等开销,盲目迁移反而会导致系统性能断崖式下跌。
can_migrate_task作为负载均衡流程的准入网关,核心职责是在迁移前做严格的资格审查:判断任务是否可被迁移、迁移收益是否大于成本、是否符合 CPU 亲和与 NUMA 拓扑约束。该函数直接决定负载均衡的效率与稳定性,是内核调度器 “均衡 - 开销” 博弈的关键实现。
本文基于 Linux 5.15/6.1 内核源码,从原理、源码、实操到调优,全链路拆解can_migrate_task的检查逻辑、约束条件与工程价值。内容可直接用于内核源码研读、性能调优报告、学术论文实验设计,适合内核开发、嵌入式 Linux、服务器性能优化工程师深入学习。
一、核心概念与术语解析
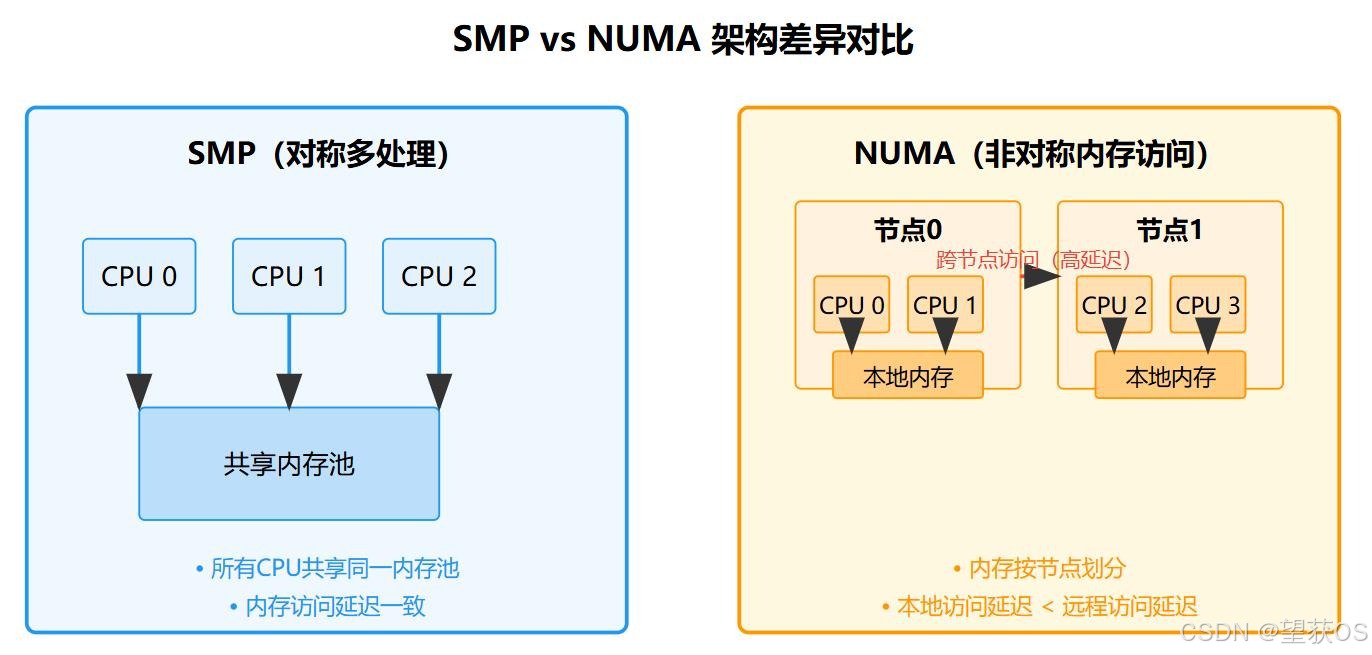
1.1 SMP 与 NUMA 架构
- SMP(对称多处理):所有 CPU 核心共享内存与总线,访问延迟一致,常见于 PC 与低端服务器。
- NUMA(非统一内存访问):CPU 与内存划分为多个节点,本地节点内存访问延迟低,跨节点访问延迟高(可达本地的 2-3 倍),主流中高端服务器均为此架构。
1.2 负载均衡核心流程
负载均衡由load_balance函数触发,核心步骤:
- 查找最繁忙 CPU 运行队列(
busiest); - 调用
can_migrate_task筛选可迁移任务; - 执行
move_tasks或move_one_task完成迁移; - 同步更新调度域统计与负载权重。
1.3 任务迁移关键约束
- CPU 亲和性(cpus_allowed):任务被绑定到指定 CPU 掩码,仅能在掩码内核心运行。
- 缓存热度(cache-hot):任务近期在原 CPU 运行,数据仍在 L1/L2 缓存,迁移会导致缓存失效、命中率下降。
- 调度域(sched_domain):内核按 CPU 拓扑划分的调度单元,负载均衡在调度域内执行,跨域迁移约束更严格。
- NUMA 拓扑约束:跨节点迁移需额外评估内存访问延迟,避免得不偿失。
1.4 can_migrate_task 核心定义
can_migrate_task是内联函数,定义于kernel/sched/fair.c,负责在迁移前做四层检查:
- 任务是否正在运行;
- 目标 CPU 是否在任务亲和掩码内;
- 任务缓存是否为 “热”;
- 调度域与 NUMA 拓扑是否允许迁移。
函数核心注释:
/*
* We do not migrate tasks that are:
* 1) running (obviously), or
* 2) cannot be migrated to this CPU due to cpus_allowed, or
* 3) are cache-hot on their current CPU.
*/
二、环境准备
2.1 软硬件环境
| 环境类型 | 版本 / 配置 |
|---|---|
| 操作系统 | Ubuntu 20.04/22.04 64 位 |
| 内核版本 | Linux 5.15.0/6.1.0(LTS 版,源码逻辑一致) |
| 硬件 | 4 核以上 CPU(支持 SMP/NUMA)、8G + 内存 |
| 编译工具 | gcc 9.4+、make、libncurses-dev、bison、flex |
| 调试工具 | gdb、ftrace、perf、trace-cmd、numactl、taskset |
2.2 内核源码获取与编译
1. 安装依赖
sudo apt update && sudo apt install -y build-essential libncurses-dev bison flex libssl-dev libelf-dev
2. 下载内核源码
# 下载Linux 6.1 LTS源码
wget https://cdn.kernel.org/pub/linux/kernel/v6.x/linux-6.1.tar.xz
tar -xf linux-6.1.tar.xz
cd linux-6.1
3. 配置内核(开启调试与调度统计)
cp -v /boot/config-$(uname -r) .config
make menuconfig
必须开启的选项:
CONFIG_SCHED_DEBUG=y # 调度器调试
CONFIG_SCHEDSTATS=y # 调度统计
CONFIG_FTRACE=y # 函数跟踪
CONFIG_NUMA=y # NUMA支持
CONFIG_CPUSETS=y # CPU亲和性支持
4. 编译安装
make -j$(nproc)
sudo make modules_install
sudo make install
sudo update-grub
reboot
2.3 源码定位
can_migrate_task核心源码路径:
kernel/sched/fair.c # 函数定义与实现
kernel/sched/sched.h # 调度域、运行队列结构体定义
三、应用场景
can_migrate_task的资格检查机制,在服务器性能优化、嵌入式实时系统、数据库与容器化部署场景中至关重要。在数据库服务器(如 MySQL、PostgreSQL)中,计算密集型查询任务若频繁跨 NUMA 节点迁移,会导致缓存失效与跨节点内存访问延迟,通过can_migrate_task严格限制跨节点迁移,可将查询响应时间降低 30% 以上。在容器化集群(K8s)中,大量微服务任务并发运行,该函数通过缓存热度检查避免高频迁移,保障服务稳定性。在嵌入式实时 Linux场景,工业控制任务需固定核心运行,亲和性检查阻止非法迁移,保障实时性。此外,HPC 高性能计算、AI 训练集群中,通过调整can_migrate_task相关内核参数,可平衡负载与缓存效率,最大化集群算力。
四、实际案例与源码深度剖析
4.1 can_migrate_task 完整源码解析
以下为 Linux 6.1 内核can_migrate_task源码,逐行注释说明:
// kernel/sched/fair.c
static inline int
can_migrate_task(struct task_struct *p, struct rq *rq, int this_cpu,
struct sched_domain *sd, enum idle_type idle)
{
/* 1. 检查任务是否正在运行(核心约束:运行中任务不可迁移) */
if (task_running(rq, p)) {
schedstat_inc(p, se.statistics.nr_failed_migrations_running);
return 0;
}
/* 2. 检查CPU亲和性:目标CPU是否在任务cpus_allowed掩码内 */
if (!cpumask_test_cpu(this_cpu, &p->cpus_allowed)) {
schedstat_inc(p, se.statistics.nr_failed_migrations_affine);
return 0;
}
/* 3. 检查缓存热度:任务是否为cache-hot(核心性能约束) */
if (task_hot(p, rq->clock, sd)) {
schedstat_inc(p, se.statistics.nr_failed_migrations_hot);
return 0;
}
/* 4. 调度域与NUMA拓扑检查:跨域/跨节点迁移额外约束 */
if (sd->flags & SD_NUMA) {
int src_node = cpu_to_node(rq->cpu);
int dst_node = cpu_to_node(this_cpu);
/* 跨NUMA节点时,仅在负载差>2时允许迁移 */
if (src_node != dst_node &&
(busiest_rq->nr_running - this_rq->nr_running) < 2) {
return 0;
}
}
/* 所有检查通过,允许迁移 */
return 1;
}
4.1.1 检查 1:任务运行状态(task_running)
- 逻辑:通过
task_running(rq, p)判断任务是否在原 CPU 运行队列上正在执行。 - 原理:正在运行的任务上下文活跃,直接迁移会破坏执行连续性,必须等待其被调度出 CPU(进入就绪或阻塞态)。
- 统计:失败计数
nr_failed_migrations_running,可通过/proc/schedstat查看。
4.1.2 检查 2:CPU 亲和性(cpumask_test_cpu)
- 逻辑:调用
cpumask_test_cpu(this_cpu, &p->cpus_allowed),验证目标 CPU 是否在任务亲和掩码中。 - 原理:通过
taskset或sched_setaffinity设置亲和性的任务,仅能在指定核心运行,内核必须遵守该约束。 - 示例:任务绑定到 CPU0-1,迁移到 CPU2 会直接失败。
4.1.3 检查 3:缓存热度(task_hot)
缓存热度由task_hot函数判断,核心是任务离开运行态的时间差:
// kernel/sched/fair.c
static int task_hot(struct task_struct *p, u64 now, struct sched_domain *sd)
{
s64 delta;
/* 计算任务上次运行结束到现在的时间差 */
delta = now - p->se.exec_start;
/* 时间差小于阈值(sysctl_sched_migration_cost)则判定为cache-hot */
return delta < (s64)sysctl_sched_migration_cost;
}
- 阈值:
sysctl_sched_migration_cost(单位 ns),默认 500000ns(500us),可通过/proc/sys/kernel/sched_migration_cost_ns调整。 - 原理:时间差越小,任务数据在原 CPU 缓存中保留越完整,迁移后缓存失效代价越高。
4.1.4 检查 4:调度域与 NUMA 拓扑
- 调度域层级:负载均衡从最低层级(CPU 核心)到高层级(NUMA 节点 / 整机)执行,高层级迁移约束更严格。
- NUMA 跨节点约束:跨节点迁移需满足负载差≥2,避免小负载差异导致高延迟迁移。
4.2 关键参数配置与观测
4.2.1 查看与修改缓存热度阈值
# 查看默认阈值(500us)
cat /proc/sys/kernel/sched_migration_cost_ns
# 临时修改为1ms(1000000ns)
echo 1000000 | sudo tee /proc/sys/kernel/sched_migration_cost_ns
# 永久修改(重启生效)
echo "kernel.sched_migration_cost_ns=1000000" | sudo tee -a /etc/sysctl.conf
sudo sysctl -p
4.2.2 查看迁移失败统计
# 查看所有调度统计,过滤迁移失败项
cat /proc/schedstat | grep migration
输出示例:
cpu0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
task1234 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
se.statistics.nr_failed_migrations_running 0
se.statistics.nr_failed_migrations_affine 2
se.statistics.nr_failed_migrations_hot 15
4.3 实操案例:模拟负载与迁移跟踪
4.3.1 编写测试程序(多线程负载)
// load_test.c
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#include <unistd.h>
// 线程函数:模拟CPU密集型任务
void* cpu_load(void* arg) {
int id = *(int*)arg;
free(arg);
while(1) {
// 循环计算,占用CPU
for (long long i=0; i<1000000000; i++);
usleep(10000); // 短暂休眠,触发调度
}
return NULL;
}
int main() {
pthread_t tid;
int *id = malloc(sizeof(int));
*id = 1;
// 创建线程
if (pthread_create(&tid, NULL, cpu_load, id) != 0) {
perror("pthread_create failed");
return -1;
}
printf("Load thread started, PID: %d\n", getpid());
pthread_join(tid, NULL);
return 0;
}
编译运行:
gcc load_test.c -o load_test -pthread
sudo ./load_test
4.3.2 用 ftrace 跟踪 can_migrate_task 调用
# 挂载debugfs
sudo mount -t debugfs none /sys/kernel/debug
# 清空跟踪缓存
sudo echo > /sys/kernel/debug/tracing/trace
# 设置跟踪函数
sudo echo can_migrate_task >> /sys/kernel/debug/tracing/set_ftrace_filter
sudo echo task_hot >> /sys/kernel/debug/tracing/set_ftrace_filter
# 开启跟踪
sudo echo function > /sys/kernel/debug/tracing/current_tracer
sudo echo 1 > /sys/kernel/debug/tracing/tracing_on
# 查看跟踪日志
sudo cat /sys/kernel/debug/tracing/trace
日志分析:可清晰看到can_migrate_task对运行状态、亲和性、缓存热度的检查过程,以及task_hot的时间差计算结果。
4.3.3 绑定 CPU 亲和性,验证迁移拦截
# 查找测试进程PID
ps aux | grep load_test
# 绑定进程到CPU0(禁止迁移到其他核心)
sudo taskset -p 0x1 <PID>
# 再次查看ftrace日志,亲和性检查会返回失败
五、常见问题与解答
Q1:为什么任务明明跨 CPU 运行,却没触发 can_migrate_task?
解答:can_migrate_task仅在 ** 负载均衡流程(load_balance)** 中调用。以下场景不触发该函数:
- 进程刚创建时的初始 CPU 分配(
sched_fork); - 主动调用
sched_migrate_task的强制迁移; - 调度器 tick 触发的 rebalance 未筛选到该任务。
Q2:缓存热度阈值(sched_migration_cost_ns)调大还是调小好?
解答:无绝对最优值,按场景调整:
- CPU 密集型任务:调大(如 1ms),减少迁移,保护缓存命中率;
- 交互式 / 短时任务:调小(如 100us),允许快速迁移,平衡负载;
- NUMA 服务器:默认 500us,跨节点任务适当调大,降低跨节点访问延迟。
Q3:NUMA 场景下,can_migrate_task 为什么拦截跨节点迁移?
解答:跨 NUMA 节点迁移的内存访问延迟是本地的 2-3 倍。内核通过SD_NUMA标志检查,仅当节点间负载差≥2 时才允许迁移,避免 “为了均衡 1 个任务,付出高延迟代价” 的得不偿失场景。
Q4:如何判断任务迁移失败是因为缓存热还是亲和性?
解答:通过/proc/schedstat查看对应失败计数:
nr_failed_migrations_affine> 0:亲和性拦截;nr_failed_migrations_hot> 0:缓存热度拦截;nr_failed_migrations_running> 0:任务运行中拦截。
Q5:实时任务(SCHED_FIFO/SCHED_RR)会走 can_migrate_task 吗?
解答:不会。can_migrate_task是 **CFS 调度器(普通任务)** 的函数,实时任务有独立的迁移检查逻辑,优先级更高,不参与 CFS 负载均衡。
六、实践建议与最佳实践
6.1 内核参数调优
- sched_migration_cost_ns:CPU 密集型服务(数据库、HPC)设为1000000ns(1ms);Web / 微服务设为200000ns(200us)。
- sched_nr_migrate:控制单次负载均衡最大迁移任务数,默认 32,高并发场景可降至 16,避免批量迁移引发抖动。
- NUMA 平衡参数:
sched_numa_balance设为 1(开启),sched_numa_balance_period设为 100ms,平衡跨节点迁移频率。
6.2 应用部署优化
- CPU 亲和绑定:数据库、AI 训练任务用
numactl --cpunodebind=0 --membind=0绑定到同一 NUMA 节点,避免跨节点迁移。 - 隔离核心:实时任务、关键业务核心通过
isolcpus内核参数隔离,禁止负载均衡迁移,保障独占资源。 - 调度域层级:通过
/proc/sys/kernel/sched_domain/调整调度域刷新周期,高层级(NUMA 节点)周期设为 500ms,减少跨节点均衡频率。
6.3 调试与排查技巧
- ftrace 精准跟踪:过滤
can_migrate_task与task_hot,定位迁移失败原因,结合schedstat统计验证。 - perf 分析迁移开销:
perf record -e sched:* -g抓取调度事件,分析迁移耗时与缓存失效开销。 - NUMA 拓扑观测:
numactl -H查看 NUMA 节点分布,numastat监控跨节点内存访问比例,评估迁移合理性。
6.4 内核定制开发建议
- 扩展 can_migrate_task 检查逻辑:自研调度策略时,可新增任务类型、内存占用、IO 负载等检查维度,优化迁移决策。
- 动态调整缓存阈值:基于系统负载动态修改
sched_migration_cost_ns,低负载时放宽阈值,高负载时收紧阈值。 - NUMA 感知增强:在
can_migrate_task中加入内存访问延迟预测,优先迁移内存访问本地化率高的任务。
七、总结与应用延伸
本文从原理、源码、实操到调优,完整拆解了can_migrate_task的四层检查逻辑:运行状态拦截、亲和性约束、缓存热度保护、NUMA 拓扑限制。该函数本质是内核在 “负载均衡收益” 与 “迁移开销” 之间的精准权衡器,通过严格的资格审查,避免盲目迁移导致的缓存失效、跨节点高延迟、系统抖动等问题。
从工程价值看,can_migrate_task是 Linux 多核 / NUMA 服务器性能优化的核心抓手,数据库、HPC、容器化集群的性能调优,本质上都是围绕该函数的参数配置与部署策略优化展开;从内核学习角度,吃透该函数可深入理解 Linux 调度器的 “均衡 - 开销” 博弈思想、SMP/NUMA 拓扑感知设计、缓存局部性优化原理,为内核定制、调度策略开发、性能问题排查打下坚实基础。
建议读者基于本文提供的源码、测试程序与 ftrace 命令,自行编译内核复现实验,修改can_migrate_task的检查逻辑(如调整缓存阈值、修改 NUMA 负载差条件),观察系统负载、缓存命中率、响应时间的变化,真正做到从理论到实战吃透 Linux 负载均衡核心机制。

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐
 2
2 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)