Elasticsearch实战排查cpu 100%导致服务器宕机-es问题bug排查
一、背景
本文从一个刚接管历史项目、对项目情况尚不了解的角色视角出发,分析问题,并记录逐步排查问题直至最终解决的过程。
运维人员发现Elasticsearch集群(包含3个节点)中的1个节点于某周日出现宕机情况,无法通过ssh和vnc登录,ping命令也不通。由于该集群宕机一个节点不影响业务使用,运维人员将其视为意外情况,未予以过多关注,仅进行了紧急恢复处理。然而,到下一个周日凌晨3点,相同问题再次出现,于是运维人员开始展开排查工作。
说明:每次宕机均为固定的同一个节点,另外两个节点运行稳定。此前也曾出现过系统负载过高、CPU使用率达到100%的情况,经排查,是由于es索引数据量过大导致查询超时,且当时3个es节点同时出现CPU 100%的情况,与本次情况有所不同。
二、分析前收集相关信息
1. 在ES集群的3个节点上安装多种中间件,包括Elasticsearch、minio、xxljob、nacos、kafka。
2. 通常情况下,ES集群三个节点的CPU、内存、磁盘使用率保持均衡一致。
3. 获取crontab任务
4. 该服务器为KVM虚拟机
5. 最后有指标数据的时间截止至3点,3点之前的指标均正常。
6. 尽管服务器宕机,但运维对该服务器有外部监控(即便系统崩溃,仍可实时监控该服务器的CPU、内存、磁盘使用率等),监控显示CPU异常升高,内存也有所升高。
7. 安装了多种代理agent
8. 保留宕机时间点/var/log目录下的日志
9. 中间件、定制化服务配置以及日志文件信息
三、分析过程
由于服务器在固定时间段出现宕机情况,首先对定时任务进行排查,发现crontab中并无有效信息。随后排查是否为xxljob定时任务中间件的问题,发现该中间件在相应时间段内并无任务执行。接着排查是否存在定制化程序在固定时间段内执行跑批任务,或者进行大量数据写入es、minio、kafka等情况,同时查看所有服务的配置是否存在数据推送配置,以及中间库和服务日志是否存在常见的内存泄露报错,结果均未发现问题。之后尝试查看系统相关日志,亦未发现有效信息。
经过全面排查,均未得到有效线索,遂怀疑服务器本身存在问题,或者管理kvm虚拟机的平台存在某种策略,可能存在跨机共享资源的情况,但最终也排除了这些可能性。
大量时间的排查,仍未找到问题所在,于是决定编写一个脚本进行监控:该脚本在每周日凌晨2点55分至3点10分执行,每两秒获取一次服务器上的各类资源使用情况、进程消耗资源排行榜(前五名),通过ss、netstat等命令获取连接信息,并将获取到的信息输出到文件中,以便后续查看。之后只能等待时间给出答案。
幸运的是,该周日服务器并未发生宕机情况,但CPU和内存使用率在每周日凌晨3点仍会出现上升。
此时,查看监控脚本输出的部分信息:
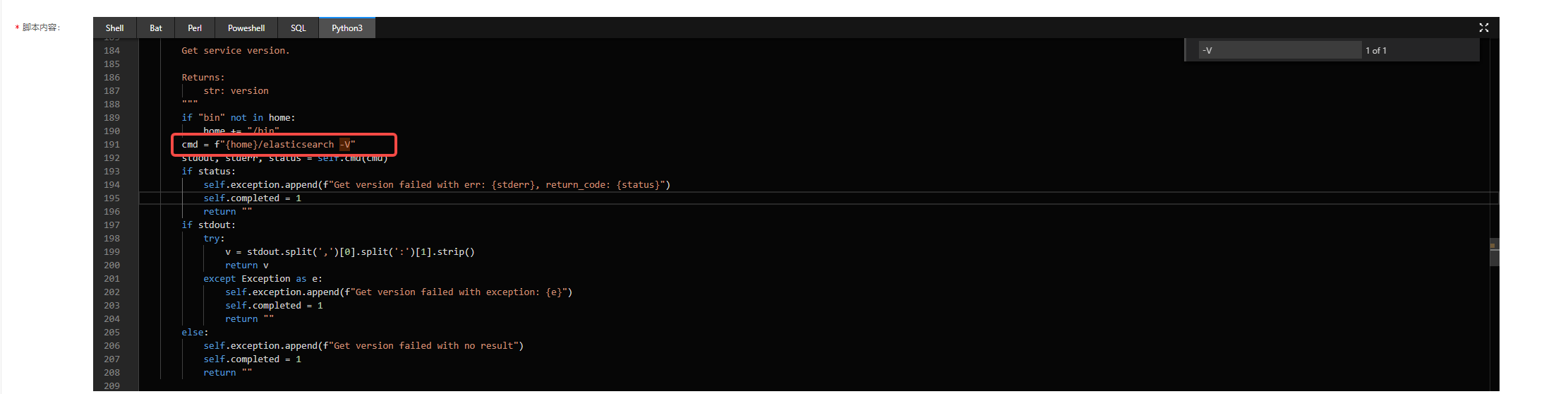
xxx/elasticsearch/jdk/bin/java -Xshare:auto -Des.networkaddress.cache.ttl=60 -Des.networkaddress.cache.negative.ttl=10 -XX:+AlwaysPreTouch -Xss1m -Djava.awt.headless=true -Dfile.encoding=UTF-8 -Djna.nosys=true -XX:-OmitStackTraceInFastThrow -XX:+ShowCodeDetailsInExceptionMessages -Dio.netty.noUnsafe=true -Dio.netty.noKeySetOptimization=true -Dio.netty.recycler.maxCapacityPerThread=0 -Dio.netty.allocator.numDirectArenas=0 -Dlog4j.shutdownHookEnabled=false -Dlog4j2.disable.jmx=true -Djava.locale.providers=SPI,COMPAT --add-opens=java.base/java.io=ALL-UNNAMED -Xms12g -Xmx12g -Dlog4j2.formatMsgNoLookups=true -XX:+UseG1GC -XX:G1ReservePercent=25 -XX:InitiatingHeapOccupancyPercent=30 -Djava.io.tmpdir=xxx/elasticsearch-7425771247901172471 -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=data -XX:ErrorFile=xxx/elasticsearch/hs_err_pid%p.log -Xlog:gc*,gc+age=trace,safepoint:file=xxx/elasticsearch/gc.log:utctime,pid,tags:filecount=32,filesize=64m -XX:MaxDirectMemorySize=6442450944 -Des.path.home=xxx/elasticsearch -Des.path.conf=xxx/elasticsearch/config -Des.distribution.flavor=default -Des.distribution.type=tar -Des.bundled_jdk=true -cp xxx/elasticsearch/lib/* org.elasticsearch.bootstrap.Elasticsearch -V分析进程:导致 CPU、内存暴增的进程已找到,该进程核心为 org.elasticsearch.bootstrap.Elasticsearch -V,显示正在查询 ES 版本号。执行 elasticsearch -V 或 elasticsearch --version 会产生该进程,经实测,执行 elasticsearch -V 确实会卡顿一段时间且资源占用量暴涨。暂且不探究执行查询 ES 版本号导致资源暴涨的原因,先查找执行的位置,推测应有脚本执行了查询 ES 版本号的操作。
随后尝试使用 grep -rn 查找 elasticsearch -V 在哪些日志文件中出现,排查发现服务器上安装的某个 agent 的日志存在该记录。顺着线索找到该 agent 对应的 master 平台,登录平台后最终找到了脚本。

四、解决办法
问题找到了,由于某平台定时下发执行了一个脚本,采集es信息。过程中执行了elasticsearch -V查询版本号导致服务器资源暴涨,影响服务器稳定性,运气不好服务器就会宕机了。
临时解决办法:
1. 停掉定时执行的es脚本,修改脚本不获取es版本或者写死版本号
2. 垂直扩容服务器资源,横向扩容es节点。
永久解决办法:
1. 换个es版本重建集群,迁移数据
五、小结
为何执行查询es版本号会导致服务器资源暴涨,问题原因不得而知,目前已提交问题到es官方等待解答吧。

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)