【MySQL基础】一文搞懂数据库本质、架构、核心原理与基本操作

🔥个人主页:Cx330🌸
❄️个人专栏:《C语言》《LeetCode刷题集》《数据结构-初阶》《C++知识分享》
《优选算法指南-必刷经典100题》《Linux操作系统》:从入门到入魔
🌟心向往之行必能
🎥Cx330🌸的简介:

目录
前言:
作为一名合格的程序员,数据的存储和管理是我们绕不开的核心课题。日常开发中,我们天天在用数据库,但你是否真的思考过:既然我们已经有了文件系统,为什么还要大费周章地设计出数据库?MySQL 的客户端和服务端到底是如何交互的?它在 Linux 底层又对应着什么?
今天,我们将从最底层的存储本质出发,一路剖析到 MySQL 的架构设计、分类指令以及存储引擎,帮助大家建立起一套系统、扎实的数据库知识网络!
一. 探寻数据库的本质
1.1 为什么不直接使用普通文件存储数据?
在最原始的阶段,我们确实可以通过普通文件(如 .txt、.bin)来存储数据。但随着数据规模的增长,直接操作普通文件会暴露出以下致命的缺点:
-
安全性问题:普通文件权限难以做到细粒度的安全控制。
-
不利于海量数据查询与管理:在数百万条甚至数亿条的数据文件中,查找特定数据需要全文件扫描,效率低下。
-
程序控制极其不便:在多线程或多进程并发写入文件时,极易发生数据覆盖或损坏(缺少行级锁、事务保障)。
-
存储介质受限:文件系统通常基于磁盘,难以无缝地在磁盘与内存之间进行高效的协同调度。
为了解决上述痛点,数据库系统应运而生。它的本质是:在底层介质(磁盘、内存)之上的、由专家精心设计的一套高效率的数据管理与存储解决方案。
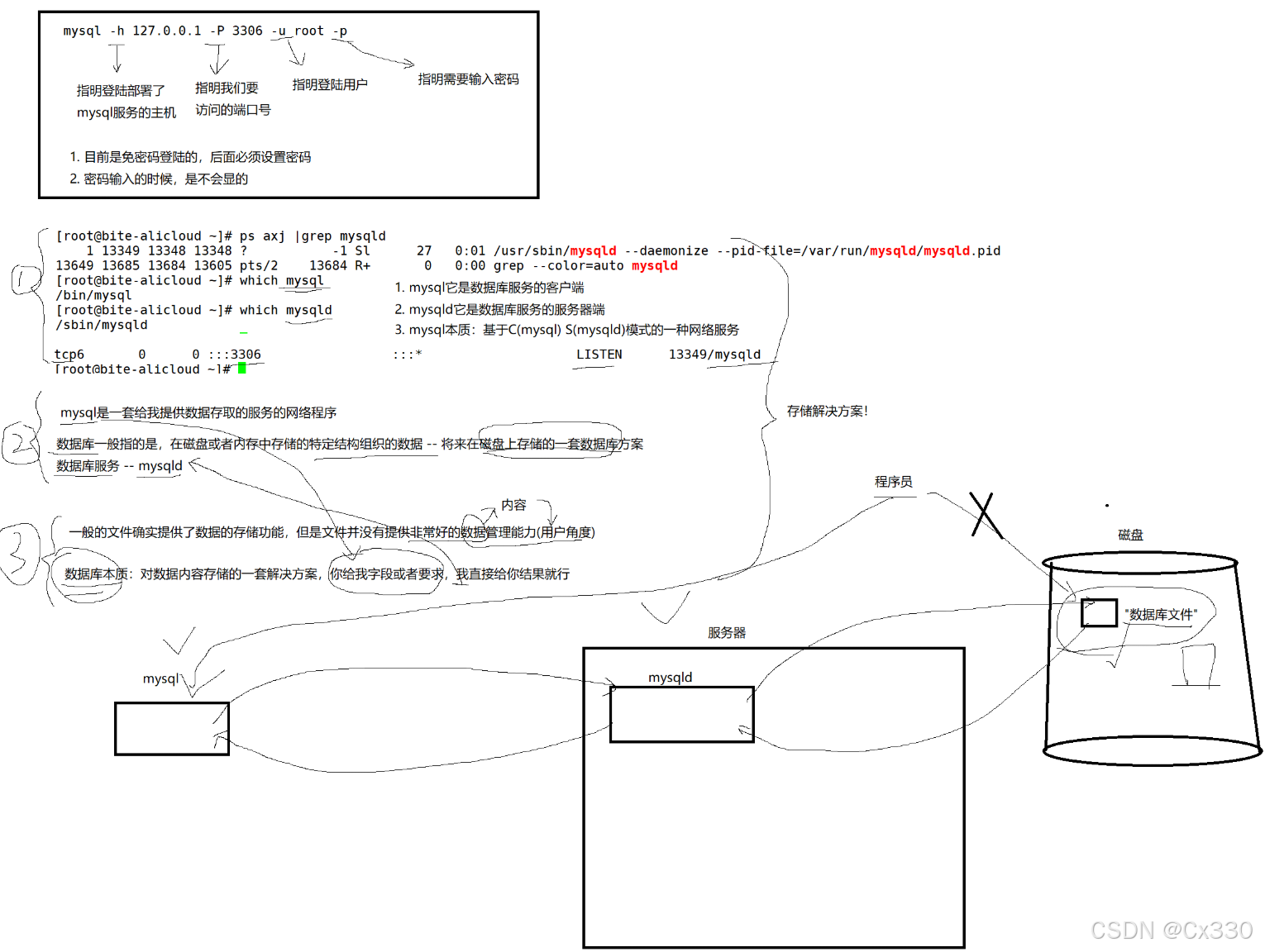
1.2 从底层看:什么是 mysql 与 mysqld?
很多初学者容易混淆 mysql 和 mysqld 这两个概念。其实结合 Linux 系统进程,它们的定位非常清晰:
-
mysqld(MySQL Daemon):-
角色:数据库服务端的后台守护进程。
-
本质:它是一套在后台运行的、网络服务程序。它负责接收请求、解析 SQL、调用存储引擎,并直接与操作系统底层的“数据库文件”打交道。
-
验证方法:在 Linux 下执行
ps axj | grep mysqld,你通常会看到类似以下的运行进程:/usr/sbin/mysqld --daemonize --pid-file=/var/run/mysqld/mysqld.pid
-
-
mysql:-
角色:数据库服务的客户端命令行工具。
-
本质:它只是一个用于向
mysqld发送服务请求、接收并展示结果的交互工具。
-
💡 核心结论: 程序员无法直接去修改磁盘上的“数据库文件”,而是通过
mysql客户端 发送指令,由mysqld服务端 替我们去操作磁盘或内存中的数据。这就是典型的 C/S(Client/Server)客户端/服务端模式。
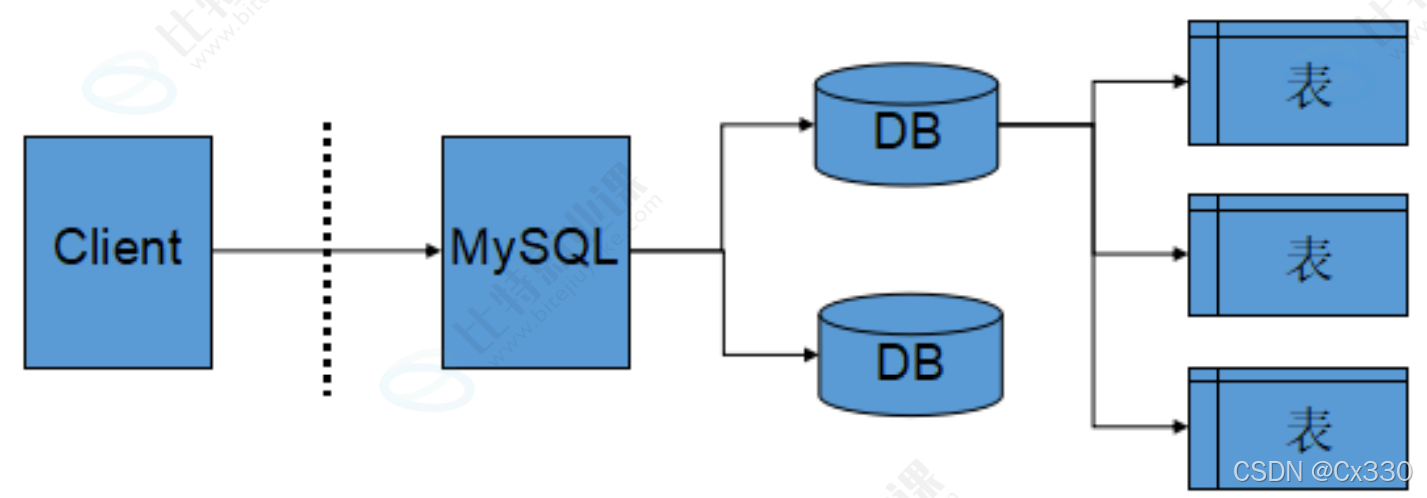
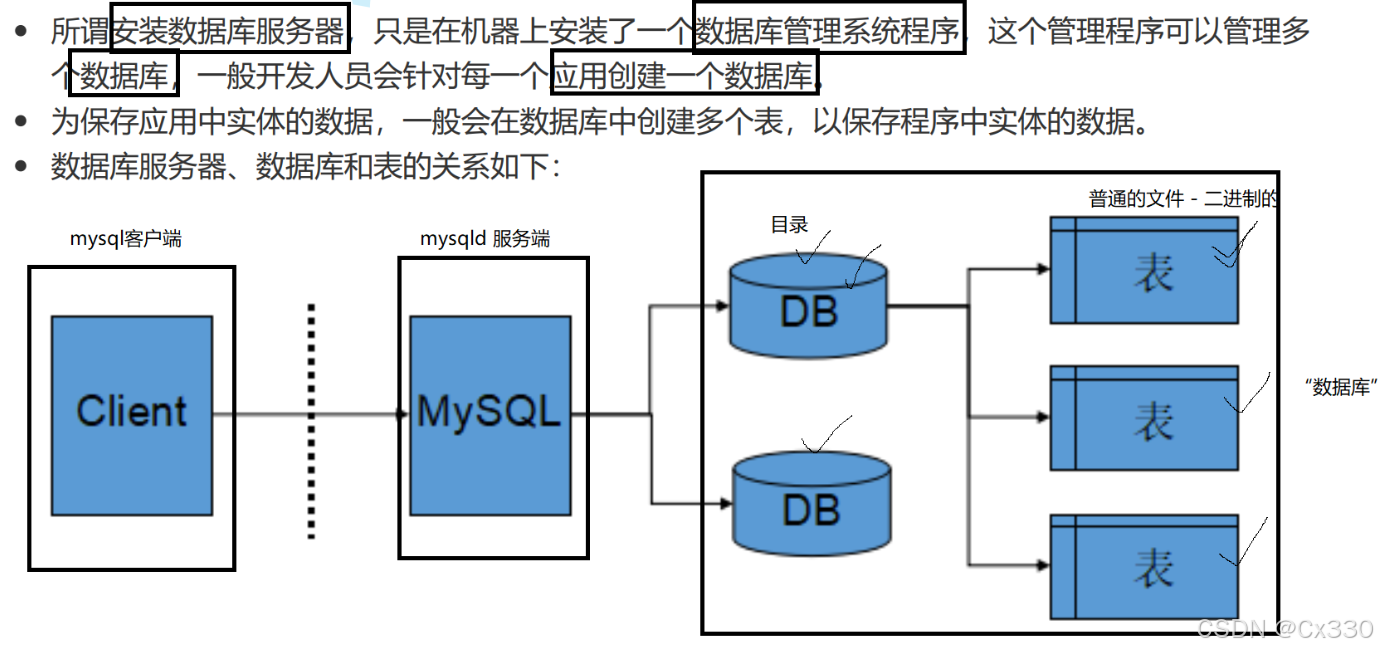
1.3 服务器、数据库、表的关系
很多初学者会混淆 “数据库服务器”“数据库” 和 “表” 的概念,其实三者是层层包含的关系:
- 数据库服务器:安装在机器上的数据库管理系统(如 MySQL),负责管理多个数据库;
- 数据库:为某个应用或项目创建的独立数据空间(如电商项目的
ecommerce_db),隔离不同项目的数据; - 表:数据库中存储具体实体数据的结构(如用户表
user、商品表product),表中的行对应一条数据,列对应数据的属性。
简单类比:数据库服务器是 “数据大厦”,数据库是 “大厦中的房间”,表是 “房间里的文件柜”,数据就是 “文件柜里的资料”。
+-------------------------------------------------------------+
| MySQL 客户端 (Client) |
+-------------------------------------------------------------+
|
[ 3306 端口网络连接 ]
|
v
+-------------------------------------------------------------+
| MySQL 数据库服务端 (mysqld 进程) |
| +-------------------------------------------------------+ |
| | 数据库管理系统 (DBMS) | |
| +-------------------------------------------------------+ |
| / \ |
| v v |
| +------------+ +------------+ |
| | 数据库 A | | 数据库 B | |
| | (目录 A) | | (目录 B) | |
| | +------+ | | +------+ | |
| | | 表 1 | | | | 表 1 | | |
| | +------+ | | +------+ | |
| | | 表 2 | | | | 表 2 | | |
| | +------+ | | +------+ | |
| +------------+ +------------+ |
+-------------------------------------------------------------+
-
MySQL 数据库服务器:一台物理机上运行着一个
mysqld进程。 -
数据库(DB):针对不同的应用项目,我们会在服务中创建不同的数据库,它们在物理上表现为不同的目录。
-
表(Table):用于存储具体实体的二维数据结构,每个表在物理上对应目录下的文件。
-
行与列:
-
列 (Column):定义了数据的属性(如:id、name、gender),也称为字段。
-
行 (Row):每一行代表一个具体的实体数据对象。
-
二. 数据库在 Linux 底层的物理表现
我们在命令行中敲下 create databases 和 create table时,Linux 操作系统底层发生了什么?
-
创建数据库:本质上就是在 Linux 的相关工作目录下 新建了一个目录(Folder)。
-
在数据库内建表:本质上就是在该数据库对应的目录下,创建了对应的文件。
-
数据库文件本身:它们就是普通的二进制文件。只不过我们不直接通过
vim或cat去编辑它们,而是让mysqld服务程序帮我们进行高效率的安全读写。
三. 常见主流数据库一览
在目前的工业界,根据应用场景的不同,有多种主流数据库可供选择:
|
数据库 |
出品方/背景 |
适用场景与特点 |
|---|---|---|
|
MySQL |
甲骨文 (Oracle) |
世界上最受欢迎的开源关系型数据库。并发性能极佳,非常适合电商、SNS、论坛等中轻量级、高并发的业务场景。 |
|
Oracle |
甲骨文 (Oracle) |
商业数据库巨头。适合大型闭源项目,具有极其复杂的业务逻辑支持,但在互联网高并发场景下性价比较低。 |
|
SQL Server |
微软 (Microsoft) |
与 |
|
PostgreSQL |
加州伯克利分校开发 |
功能极其强大的开源关系型数据库,完全免费,对复杂 SQL 和地理空间数据的支持优于 MySQL。 |
|
SQLite |
开源轻量级 |
嵌入式数据库的王者,整个系统包含在一个极小的 C 库中。占用资源极低(只需几百 KB 内存),广泛用于移动端(iOS/Android)和嵌入式设备。 |
|
H2 |
Java 语言开发 |
嵌入式内存数据库,主要作为 Java 类的形式直接嵌入到应用项目中,常用于本地测试和快速原型开发。 |
四. MySQL 的连接与基本使用
4.1 支持的操作系统
MySQL 具有良好的可移植性,支持 Unix/Linux、Windows、Mac、Solaris 等主流操作系统,不同系统的核心功能一致,仅安装和配置方式略有差异。安装的具体操作这里就先不介绍了,大家可以根据自己的系统(Linux,Windows)去网上搜索一下对应的下载教程,这个还是很多的。
4.2 命令行连接方式
在安装好 MySQL 之后,我们可以使用以下经典的命令来连接服务端:
mysql -h 127.0.0.1 -P 3306 -u root -p-
-h:指明要登录部署了mysql服务的主机 IP(省略时默认为连接本地127.0.0.1)。 -
-P:指明要访问的端口号(省略时默认为3306)。 -
-u:指明登录的用户名。 -
-p:指明需要输入密码(出于安全考虑,密码通常在紧接着的Enter password:提示后密文输入,输入时屏幕不显示任何字符)。
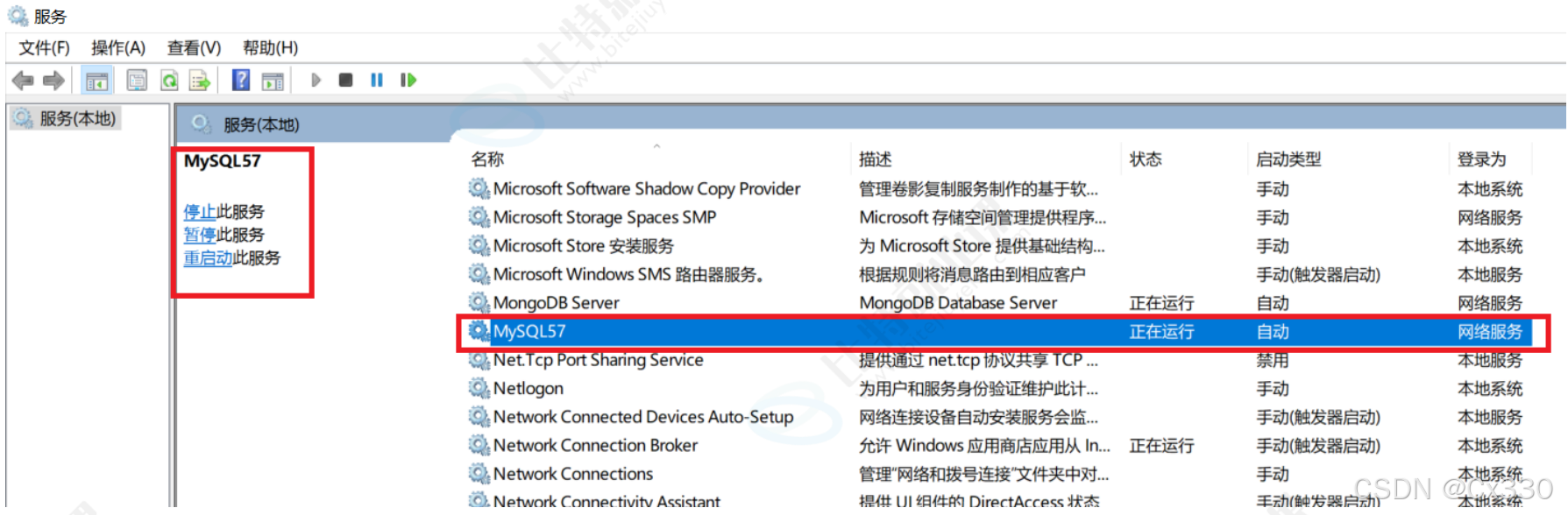
4.3 服务器管理(Windows)
Windows 系统中,可通过服务管理器管理 MySQL 服务:
- 按
Win+R,输入services.msc打开服务管理器; - 找到 MySQL 服务(如
MySQL57); - 可执行启动、停止、重启等操作,确保服务正常运行。
五. 快速上手MySQL:创建数据库与 CRUD 操作

5.1 核心 SQL 分类
为了更高效地分类管理数据,SQL(Structured Query Language)被划分为以下四大类:
-
DDL (Data Definition Language) 数据定义语言:
-
作用:用来维护和定义存储数据的结构(数据库、表、索引、视图等)。
-
代表指令:
CREATE、DROP、ALTER。
-
-
DML (Data Manipulation Language) 数据操纵语言:
-
作用:用来对表中的数据进行增、删、改。
-
代表指令:
INSERT、DELETE、UPDATE。
-
-
DQL (Data Query Language) 数据查询语言:
-
常归属于 DML,但在实际开发中因其地位极重,常被单独抽离出来。
-
代表指令:
SELECT。
-
-
DCL (Data Control Language) 数据控制语言:
-
作用:负责数据库的安全权限管理以及事务控制。
-
代表指令:
GRANT、REVOKE、COMMIT、ROLLBACK。
-
5.2 实战步骤
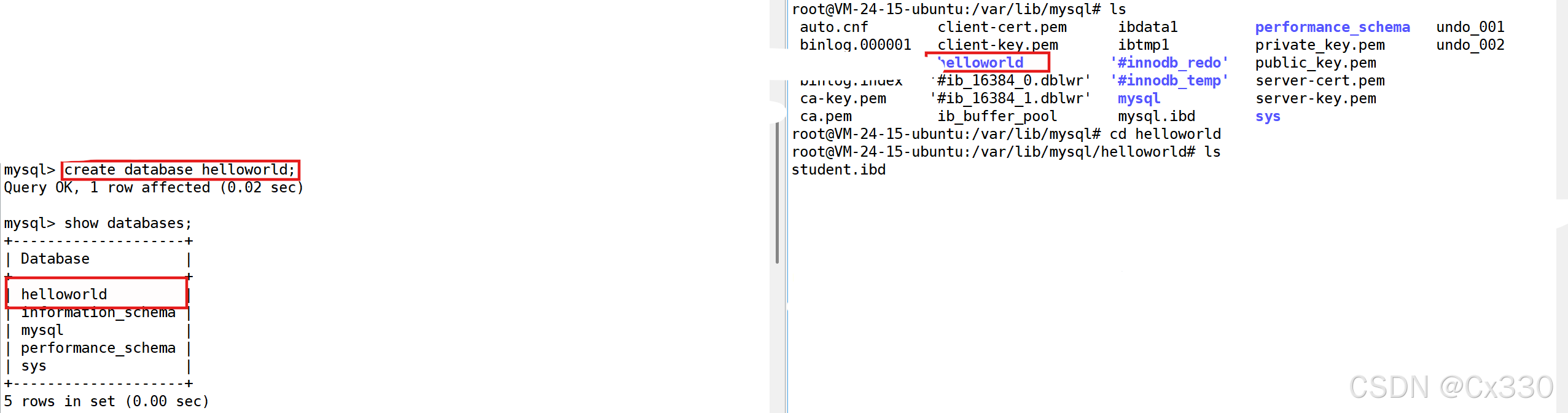
- 创建数据库
-- 1. 创建数据库 (本质:在底层建一个名为 helloworld 的文件夹)
create database helloworld;- 使用数据库
-- 2. 选中并使用该数据库
use helloworld;- 创建表
创建student表,包含id(学号)、name(姓名)、gender(性别)三个字段:
-- 3. 创建数据库表 (本质:在 helloworld 目录下建表文件)
create table student(
id int, -- 整数类型(学号)
name varchar(32), -- 字符串类型(姓名,最多32个字符)
gender varchar(2) -- 字符串类型(性别,最多2个字符)
);
- 插入数据
向表中添加三条学生数据:
insert into student (id, name, gender) values (1, '张三', '男');
insert into student (id, name, gender) values (2, '李四', '女');
insert into student (id, name, gender) values (3, '王五', '男');
- 查询数据
查询表中所有数据:
select * from student;
- 执行结果
+------+--------+--------+
| id | name | gender |
+------+--------+--------+
| 1 | 张三 | 男 |
| 2 | 李四 | 女 |
| 3 | 王五 | 男 |
+------+--------+--------+
3 rows in set (0.00 sec)
六. MySQL 经典分层架构
MySQL 之所以具备如此强大的生命力,很大程度上得益于其优秀的可移植性与插件式存储引擎架构。它在逻辑上主要分为四层:
+-----------------------------------------------------------------+
| 客户端连接器 (Client Connectors) |
| (JDBC, ODBC, .NET, PHP, Python, C API 等) |
+-----------------------------------------------------------------+
|
v
+-----------------------------------------------------------------+
| MySQL SERVER 核心层 |
| |
| +---------------------------------------------------------+ |
| | 1. 连接池 (Connection Pool) | |
| | - 连接处理、身份鉴权、安全管理 | |
| +---------------------------------------------------------+ |
| | 2. 系统服务与工具 (Services & Utilities) | |
| | - 备份/恢复、安全、复制、集群、分区管理 | |
| +---------------------------------------------------------+ |
| | 3. SQL 接口与解析/优化层 | |
| | - SQL Interface: 接收 DML, DDL, 存储过程, 触发器 | |
| | - Parser: 词法/语法解析,生成语法树 | |
| | - Optimizer: SQL 重写、扫描顺序、索引选择与优化 | |
| | - Caches & Buffers: 全局和引擎专属的高效缓存 | |
| +---------------------------------------------------------+ |
+-----------------------------------------------------------------+
|
v
+-----------------------------------------------------------------+
| 插件式存储引擎 (Storage Engines) |
| [InnoDB] [MyISAM] [Memory] [Archive] [Merge] |
+-----------------------------------------------------------------+
|
v
+-----------------------------------------------------------------+
| 系统文件层 (File System / Logs & Files) |
| (NTFS, ext4 / Error Log, Binary Log, Data, Index 等) |
+-----------------------------------------------------------------+6.1 架构各层核心职责:
-
客户端连接器 (Client Connectors):提供与各主流编程语言(C++, Java, Python 等)的对接接口。
-
连接池 (Connection Pool):处理客户端的网络连接,并负责用户的登录验证及权限判断。
-
SQL Interface & Parser:SQL 接口用于接收用户的 SQL 命令;解析器则对 SQL 进行词法解析和语法解析,识别其是否符合语法规则。
-
Optimizer (优化器):这是核心大脑。它会评估多种执行路径,选择最优的索引和读取顺序,最后生成执行计划。
-
Caches & Buffers (缓存与缓冲区):将高频访问的数据在内存中缓存,避免每次都直击磁盘,极大提升了吞吐量。
-
Pluggable Storage Engines (插件式存储引擎):这是 MySQL 区别于其他数据库的最大特点!存储引擎负责真正的数据写入和读取工作,它与具体的表相绑定。
七. 深度透视:MySQL 存储引擎
存储引擎是 MySQL 处理数据的底层技术实现。不同的引擎具备不同的并发控制、事务支持和存储特性。
7.1 查看当前系统支持的引擎
在命令行运行:
show engines;
常见的引擎包括:InnoDB(当前默认)、MyISAM、Memory、Archive 等。
7.2 核心存储引擎深度对比图
为了方便大家选型,我将最常用的几个存储引擎的关键指标进行了横向对比:
|
引擎特性 |
MyISAM |
InnoDB |
Memory |
Archive |
|---|---|---|---|---|
|
事务支持 (Transactions) |
❌ 不支持 |
\✔ 支持 |
❌ 不支持 |
❌ 不支持 |
|
锁粒度 (Locking) |
表锁 (Table-level) |
行锁 (Row-level) |
表锁 (Table-level) |
行锁 (Row-level) |
|
MVCC/一致性读 |
❌ 不支持 |
\✔ 支持 |
❌ 不支持 |
❌ 不支持 |
|
外键支持 (Foreign Key) |
❌ 不支持 |
\✔ 支持 |
❌ 不支持 |
❌ 不支持 |
|
索引结构 (Indexes) |
B-Tree |
B-Tree (聚集索引) |
Hash / B-Tree |
❌ 不支持 |
|
存储限制 (Storage Limits) |
无限制 |
64 TB |
受内存大小限制 |
无限制 |
|
内存消耗 (Memory Cost) |
低 |
高 |
中等 |
低 |
|
存储空间消耗 (Space Cost) |
低 |
高 |
N/A (存在内存) |
极低 (压缩存储) |
|
批量插入速度 |
高 |
低 |
高 |
极高 |
7.3 如何进行引擎选型?
-
InnoDB:它是绝大多数高并发、OLTP 业务(如电商交易、用户系统)的首选且默认引擎。如果你的业务需要事务保障、外键约束,或者有大量的高并发读写(需要行级锁避免锁冲突),请毫不犹豫选择 InnoDB。
-
MyISAM:不支持事务,但其读取速度极快。适合只读或读多写少、不需要事务支持的统计类系统。
-
Memory:数据完全存储在内存中。由于没有磁盘 I/O,它的读写速度堪称恐怖,但断电即失。适合作为临时表的缓存介质。
-
Archive:提供极高的压缩率,并且只支持
INSERT和SELECT两种操作。非常适合用来存储海量的历史日志、审计数据。
结语
从底层的 Linux 物理目录文件,到内存中复杂的 SQL 解析与优化,再到各种插件式存储引擎的相互配合——MySQL 为我们展示了一套优美、严谨且极致高效的系统工程美学。
掌握了这些底层基础,我们在后续面对索引优化、事务隔离级别和高并发锁机制时,才能真正做到“心中有数,手下有牌”。

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐


 69
69 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)