FlashAttention、PagedAttention两代注意力算法,改写大模型推理生态详解.186
本文深入解析了大模型注意力机制的两大优化技术:FlashAttention和PagedAttention。原生Transformer注意力存在O(n²)复杂度问题,导致长文本处理时显存占用和计算量暴增。FlashAttention通过SRAM分片计算,将显存占用从平方级降为线性级,显著提升长文本处理效率。PagedAttention则借鉴操作系统分页机制,解决多会话并发时的显存碎片问题,使KV缓存
一、前言
大模型能够实现流畅对话、长文本理解、多轮交互应答,核心底层完全依靠自注意力机制。但早期原生Transformer注意力,天生带着算力与显存双重致命缺陷,序列长度一旦上涨,算力开销呈平方级暴涨,不仅推理速度极慢、显存占用失控,高并发多轮对话极易卡顿溢出,根本无法规模化商用落地。
FlashAttention、PagedAttention两代革命性注意力优化算法,先后重构注意力计算逻辑、KV缓存管理模式,从硬件内存交互、分片矩阵运算、分页复用缓存、并发调度管理多个维度彻底破局。今天我们结合应用实际,由浅入深拆解原生注意力痛点、SRAM分片原理、分页缓存机制、引擎实测对比、以及应用实践过程中碰到得问题,深入探讨大模型推理核心优化逻辑,理解如今千亿级模型在线服务流畅运行的底层秘密。重点是不堆砌晦涩难懂的术语,用通俗直白语言讲透两代注意力如何彻底改变大模型推理整个生态。

二、原生注意力弊端
1. 注意力核心基础定义
自注意力机制,是Transformer架构灵魂核心。模型在生成每一个Token时,都会计算当前Token与上下文所有Token之间关联权重,依靠权重加权融合上下文信息,完成语义理解、逻辑关联、内容生成。
简单来说,对话越长、上下文Token数量n越多,模型需要两两计算关联关系。原生标准注意力完整计算逻辑分为Q 查询、K键、V值三个张量矩阵,通过Q与K做矩阵相乘得到注意力分数,经过SoftMax归一化后,再与V矩阵加权求和,输出注意力结果。
整个计算不依赖循环结构,完全并行运算,优势是长上下文语义捕捉能力极强,也是大模型具备超强通用理解能力的根源,但并行结构同时带来无法规避的数学复杂度缺陷。
2. O(n²)复杂度致命短板
原生注意力Q与K矩阵相乘,生成n×n大小注意力分数矩阵,时间、空间复杂度统一为O(n²)。序列长度小幅提升,整体开销指数级暴涨:序列长度翻倍,计算量翻4倍,显存占用翻4倍。
日常对话4K上下文时尚可勉强运行,一旦提升至8K、16K、32K超长上下文,GPU显存直接溢出OOM,推理速度断崖式下跌。通常我们实践在线应用场景需要海量用户并发、多轮长对话持续交互,原生注意力完全无法支撑。
同时大模型推理属于自回归逐Token生成,每生成一个新字符,都要遍历全部历史上下文KV数据。显存带宽反复大量吞吐全局显存,GPU算力大量浪费在数据搬运,而非矩阵运算本身。低并发都高延迟,高并发直接服务崩溃,算力成本极高,长上下文服务、多用户并发对话、云端API商用全部不具备可行性。
3. 原生注意力推理缺陷

- 1. 全局一次性加载全部Q、K、V张量至显存,长序列显存瞬间满载
- 2. 完整n×n注意力矩阵全程驻留显存,无分片、无复用、无优化
- 3. GPU高速SRAM缓存利用率极低,绝大多数时间等待显存IO数据传输
- 4. 多会话共用显存时KV缓存杂乱堆积,无法复用、无法清理、无法分页调度
- 5. 上下文越长,单Token生成耗时越久,对话越往后卡顿越严重
- 6. 批量并发推理时,显存冲突严重,吞吐量极低,单位Token推理成本极高
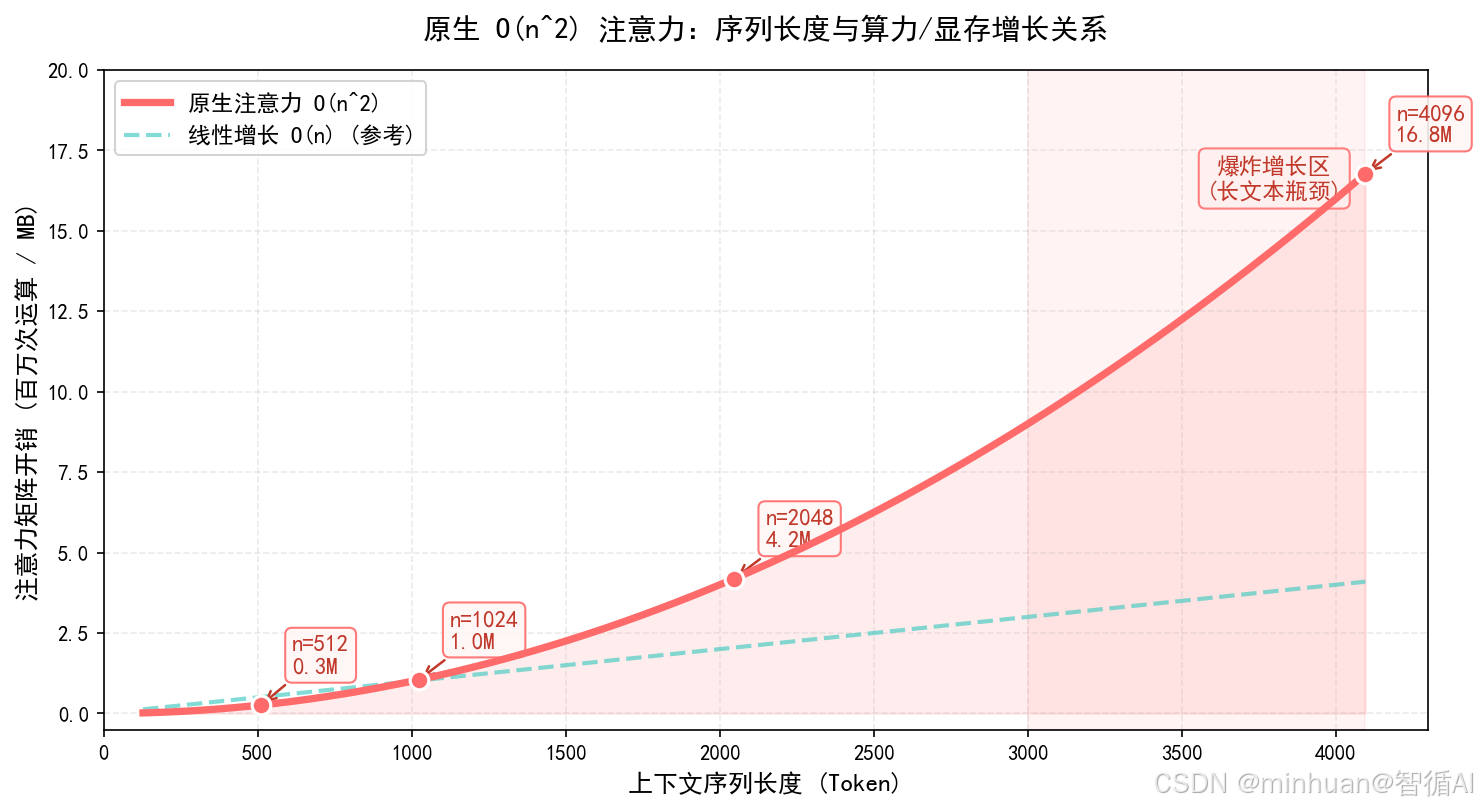
4. 示例:原生O(n²)注意力
以下示例展示了原生Transformer注意力机制的核心运算:Query与Key做矩阵乘法产生一个seq_len×seq_len的注意力分数矩阵,经softmax归一化后得到注意力权重,再与Value相乘得到加权输出。由于注意力矩阵的尺寸随序列长度呈平方增长,当序列长度翻倍时,计算量和显存占用将增长至原来的4倍,这是大模型处理长文本时面临的核心瓶颈。
import torch
import torch.nn.functional as F
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei']
matplotlib.rcParams['axes.unicode_minus'] = False
# 自动检测设备:GPU可用则用GPU,否则回退CPU
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# GPU用bfloat16节省显存,CPU用float32保证精度
dtype = torch.bfloat16 if device.type == 'cuda' else torch.float32
print(f"当前运行设备: {device}, 计算精度: {dtype}")
# 基础参数
seq_len = 1024
dim = 128
# 生成QKV
Q = torch.randn(1, seq_len, dim, device=device, dtype=dtype)
K = torch.randn(1, seq_len, dim, device=device, dtype=dtype)
V = torch.randn(1, seq_len, dim, device=device, dtype=dtype)
# 因果掩码(自回归不能看未来token)
mask = torch.triu(torch.ones(seq_len, seq_len), diagonal=1).bool().to(device)
# 标准原生O(n²)自注意力
def naive_transformer_attention(Q, K, V, mask, dim):
# 平方复杂度核心运算 seq_len × seq_len
scale = torch.sqrt(torch.tensor(dim, dtype=torch.float32, device=Q.device))
attn_score = Q.float() @ K.float().transpose(-2, -1) / scale
attn_score.masked_fill_(mask, -torch.inf)
attn_weight = F.softmax(attn_score, dim=-1).to(Q.dtype)
output = attn_weight @ V
return output, attn_weight
out, attn_weight = naive_transformer_attention(Q, K, V, mask, dim)
print(f"原生注意力输出形状:{out.shape}")
if device.type == 'cuda':
print(f"显存占用峰值:{torch.cuda.max_memory_allocated()/1024**2:.2f}MB")
else:
print("运行在CPU上,无GPU显存统计")
# ========== 可视化:注意力权重热力图 ==========
sample_len = 128 # 截取前128个token以便观察
weights_sample = attn_weight[0, :sample_len, :sample_len].float().cpu().detach().numpy()
fig, axes = plt.subplots(1, 2, figsize=(14, 6))
# 图1:注意力权重热力图
im1 = axes[0].imshow(weights_sample, cmap='hot', aspect='auto', vmin=0, vmax=weights_sample.max())
axes[0].set_title(f'注意力权重热力图 (前{sample_len}个Token)', fontsize=14, fontweight='bold')
axes[0].set_xlabel('Key 位置(被关注侧)')
axes[0].set_ylabel('Query 位置(发起关注侧)')
plt.colorbar(im1, ax=axes[0], fraction=0.046, pad=0.04)
# 图2:O(n²)复杂度增长曲线
seq_lengths = [64, 128, 256, 512, 1024, 2048, 4096]
complexities = [s * s for s in seq_lengths]
axes[1].plot(seq_lengths, complexities, 'b-o', linewidth=2, markersize=8, markerfacecolor='red')
axes[1].set_title('O(n^2) 计算复杂度增长曲线', fontsize=14, fontweight='bold')
axes[1].set_xlabel('序列长度 n')
axes[1].set_ylabel('注意力矩阵运算量 n^2')
axes[1].grid(True, alpha=0.3)
for i, (x, y) in enumerate(zip(seq_lengths, complexities)):
axes[1].annotate(f'{y/1e6:.1f}M', (x, y), textcoords="offset points", xytext=(0, 10), ha='center', fontsize=9)
plt.tight_layout()
plt.show()运行输出:
当前运行设备: cuda, 计算精度: torch.bfloat16
原生注意力输出形状:torch.Size([1, 1024, 128])
显存占用峰值:19.88MB
结果图示:
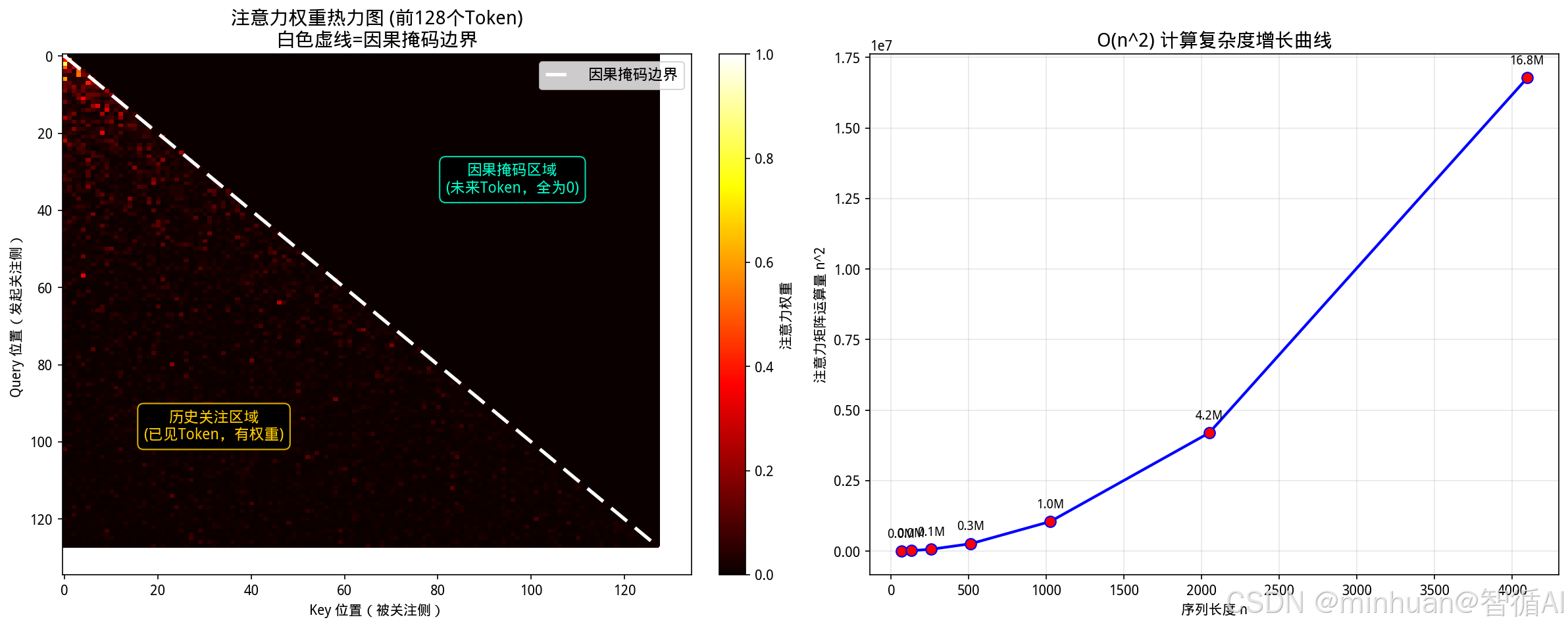
白色虚线为因果掩码边界:
- 虚线上方(上三角)= 未来Token区域,权重被置为-inf,softmax后全为0,呈现纯黑色;
- 虚线下方(下三角)= 历史已见Token区域,颜色越亮表示注意力权重越高,反映当前Token对历史信息的关注程度。
生成时模型只能看到下三角的Token,确保自回归解码不会“偷看”后续内容,通俗的说就是每个Token在生成时,只能关注自己和它之前已经出现的Token,保证自回归是一个从左到右的因果过程,不会作弊。
三、FlashAttention:SRAM分片降IO开销
1. FlashAttention核心定位
FlashAttention是新一代高效注意力算法,彻底跳出原生全局矩阵计算思路,贴合GPU硬件存储层级结构优化注意力计算。不再一次性计算完整全局注意力矩阵,利用GPU片上高速SRAM做分片分块计算,极致减少显存与内存之间频繁IO搬运,从硬件底层解决注意力算力浪费、显存占用过高问题。
它没有改变注意力数学逻辑,不损失模型精度,不修改模型权重,仅重构计算执行流程,完美兼容所有Transformer大模型,快速落地训练与推理全场景。
2. GPU存储层级底层原理
GPU运算速度远高于显存读写速度,硬件分为三层存储:
- 1. 片上SRAM高速缓存:SRAM速度最快、容量极;
- 2. HBM高带宽显存:HBM容量大、速度中等;
- 3. 低速内存:内存速度最慢、容量极大。
原生注意力全程在HBM显存运算,大量数据反复搬运,算力等待IO。FlashAttention优先把小块Q、K、V放入SRAM全速计算,算完一块清理一块,再加载下一块,全程最大化利用高速算力,最小化低速显存交互。
3. SRAM分片计算完整逻辑

将超长上下文序列拆分为多个Q 分片、KV分片,两两配对逐块计算注意力分数。
- 1. 把Q序列横向切分小块,单次只加载一小块Q进入SRAM;
- 2. 把K、V序列纵向切分小块,逐块循环加载SRAM;
- 3. 小块内部完成局部注意力计算、SoftMax归一化、加权聚合;
- 4. 局部结果累加汇总,不保存全局n×n超大注意力矩阵;
- 5. 块计算完成立即释放SRAM空间,循环处理下一组分片;
分片计算后,显存占用不再跟随n²暴涨,大幅降低全局HBM IO次数。原本需要上万次显存读写,优化后仅少量分片读写,GPU算力利用率成倍提升,推理速度显著加快,长上下文显存压力大幅下降。
4. IO开销降低价值影响
显存IO是大模型推理最大性能瓶颈,FlashAttention通过分块重排注意力顺序,IO复杂度从O(n²)降低至O(n)。长序列场景优势碾压原生注意力,相同显卡可支撑更长上下文、更高并发吞吐量。
训练场景大幅降低激活显存,支持更大批次、更长序列训练;推理场景降低单 Token 时延,提升每秒生成 Token 数量,云端服务响应更快,单位算力可服务更多用户。同时模型精度零损失,上下文语义关联能力与原生注意力完全一致。
5. FlashAttention优势与局限
优势:
- 硬件感知优化,贴合NVIDIA GPU架构,开箱即用
- 无损精度,兼容所有主流Transformer大模型
- 显著降低显存占用,大幅提升长序列推理速度
- 同时适配模型训练、微调、推理全链路场景
局限:
- 只优化单会话注意力计算,不解决多并发KV缓存混乱问题
- 多用户多轮对话场景,KV缓存依旧碎片化堆积
- 超高并发场景显存利用率依旧偏低,容易出现卡顿排队
- 无法动态复用不同对话之间KV缓存资源
6. 示例:SRAM分块分片注意力
以下示例展示了Flash/SRAM分片注意力的核心思想:不再一次性生成N×N的全局注意力矩阵,而是将Q按行分块、KV按列分块,逐块加载到SRAM中计算softmax并累加输出,单次显存占用仅为chunk×chunk。
import torch
import torch.nn.functional as F
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
import matplotlib
matplotlib.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei']
matplotlib.rcParams['axes.unicode_minus'] = False
# 自动检测设备:GPU可用则用GPU,否则回退CPU
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
dtype = torch.bfloat16 if device.type == 'cuda' else torch.float32
print(f"当前运行设备: {device}, 计算精度: {dtype}")
seq_len, dim = 1024, 128
chunk_size = 256 # SRAM分片大小(模拟SRAM容量限制)
Q = torch.randn(1, seq_len, dim, device=device, dtype=dtype)
K = torch.randn(1, seq_len, dim, device=device, dtype=dtype)
V = torch.randn(1, seq_len, dim, device=device, dtype=dtype)
mask = torch.triu(torch.ones(seq_len, seq_len), diagonal=1).bool().to(device)
# Flash分片注意力:分块计算,不生成全局n×n矩阵
def flash_chunk_attention(Q, K, V, mask, chunk):
B, N, D = Q.shape
out = torch.zeros_like(Q)
scale = torch.sqrt(torch.tensor(D, dtype=torch.float32, device=Q.device))
# Q横向分片载入SRAM
for q_s in range(0, N, chunk):
q_e = q_s + chunk
q_block = Q[:, q_s:q_e].float()
# KV纵向分片循环计算
for k_s in range(0, q_e, chunk):
k_e = k_s + chunk
k_block = K[:, k_s:k_e].float()
v_block = V[:, k_s:k_e]
score = q_block @ k_block.transpose(-2, -1) / scale
score.masked_fill_(mask[q_s:q_e, k_s:k_e], -torch.inf)
weight = F.softmax(score, dim=-1).to(v_block.dtype)
out[:, q_s:q_e] += weight @ v_block
return out
flash_out = flash_chunk_attention(Q, K, V, mask, chunk_size)
print(f"分片注意力输出形状:{flash_out.shape}")
if device.type == 'cuda':
print(f"分片注意力显存占用:{torch.cuda.max_memory_allocated()/1024**2:.2f}MB")
else:
print("运行在CPU上,无GPU显存统计")
# ========== 可视化:SRAM分块策略与显存对比 ==========
fig, axes = plt.subplots(1, 2, figsize=(15, 6))
# 图1:SRAM分块计算示意图
axes[0].set_xlim(0, seq_len)
axes[0].set_ylim(seq_len, 0) # 翻转Y轴,与矩阵行列对应
axes[0].set_aspect('equal')
# 计算实际参与的分块(结合因果掩码,只画下三角的分块)
tile_colors = ['#FF6B6B', '#4ECDC4', '#45B7D1', '#96CEB4',
'#FFEAA7', '#DDA0DD', '#98D8C8', '#F7DC6F',
'#BB8FCE', '#85C1E9', '#82E0AA', '#F8C471']
# 绘制分块区域
color_idx = 0
for q_s in range(0, seq_len, chunk_size):
q_e = min(q_s + chunk_size, seq_len)
for k_s in range(0, q_e, chunk_size):
k_e = min(k_s + chunk_size, seq_len)
color = tile_colors[color_idx % len(tile_colors)]
rect = mpatches.Rectangle((k_s, q_s), k_e - k_s, q_e - q_s,
facecolor=color, edgecolor='white', linewidth=2, alpha=0.7)
axes[0].add_patch(rect)
# 标注分块坐标
ax_text = axes[0].text((k_s + k_e) / 2, (q_s + q_e) / 2,
f'Q[{q_s}:{q_e}]\nK[{k_s}:{k_e}]',
ha='center', va='center', fontsize=11, fontweight='bold',
color='black')
color_idx += 1
# 上方遮罩区域(因果掩码,不参与计算)
mask_overlay = axes[0].fill_between([0, seq_len], 0, [-1, seq_len - 1],
color='gray', alpha=0.3, label='因果掩码区(不计算)')
axes[0].set_title(f'Flash分片注意力分块策略\n(每个色块={chunk_size}×{chunk_size}, 共{color_idx}个分片)', fontsize=14, fontweight='bold')
axes[0].set_xlabel('Key 维度 →')
axes[0].set_ylabel('Query 维度 →')
axes[0].legend(loc='lower left', fontsize=11)
# 图2:显存/IO对比
naive_mem = seq_len * seq_len * 2 # 原生:N×N float16矩阵
chunked_peak = chunk_size * chunk_size * 2 # 分片:单次最大chunk_size×chunk_size
bars = axes[1].bar(['原生O(n^2)\n(全矩阵)', 'SRAM分片\n(单块峰值)'],
[naive_mem / 1024, chunked_peak / 1024],
color=['#FF6B6B', '#4ECDC4'], width=0.45, edgecolor='white', linewidth=2)
axes[1].set_title('注意力矩阵显存占用对比', fontsize=14, fontweight='bold')
axes[1].set_ylabel('显存占用 (KB)')
for bar, val in zip(bars, [naive_mem / 1024, chunked_peak / 1024]):
axes[1].text(bar.get_x() + bar.get_width() / 2, bar.get_height() + 5,
f'{val:.0f} KB', ha='center', fontsize=12, fontweight='bold')
axes[1].text(bar.get_x() + bar.get_width() / 2, bar.get_height() / 2,
f'{val:.0f}×', ha='center', va='center', fontsize=11, color='white', fontweight='bold',
bbox=dict(facecolor='black', alpha=0.4, boxstyle='round,pad=0.2'))
# 标注节省比例
saving = (1 - chunked_peak / naive_mem) * 100
axes[1].annotate(f'节省\n{saving:.0f}%', xy=(1, chunked_peak / 1024),
xytext=(1.5, naive_mem / 1024 * 0.5),
fontsize=13, fontweight='bold', color='#27AE60',
arrowprops=dict(arrowstyle='->', color='#27AE60', lw=2),
bbox=dict(boxstyle='round,pad=0.3', facecolor='white', edgecolor='#27AE60', alpha=0.9))
plt.tight_layout()
plt.show()输出结果:
当前运行设备: cuda, 计算精度: torch.bfloat16
分片注意力输出形状:torch.Size([1, 1024, 128])
分片注意力显存占用:11.25MB
结果图示:
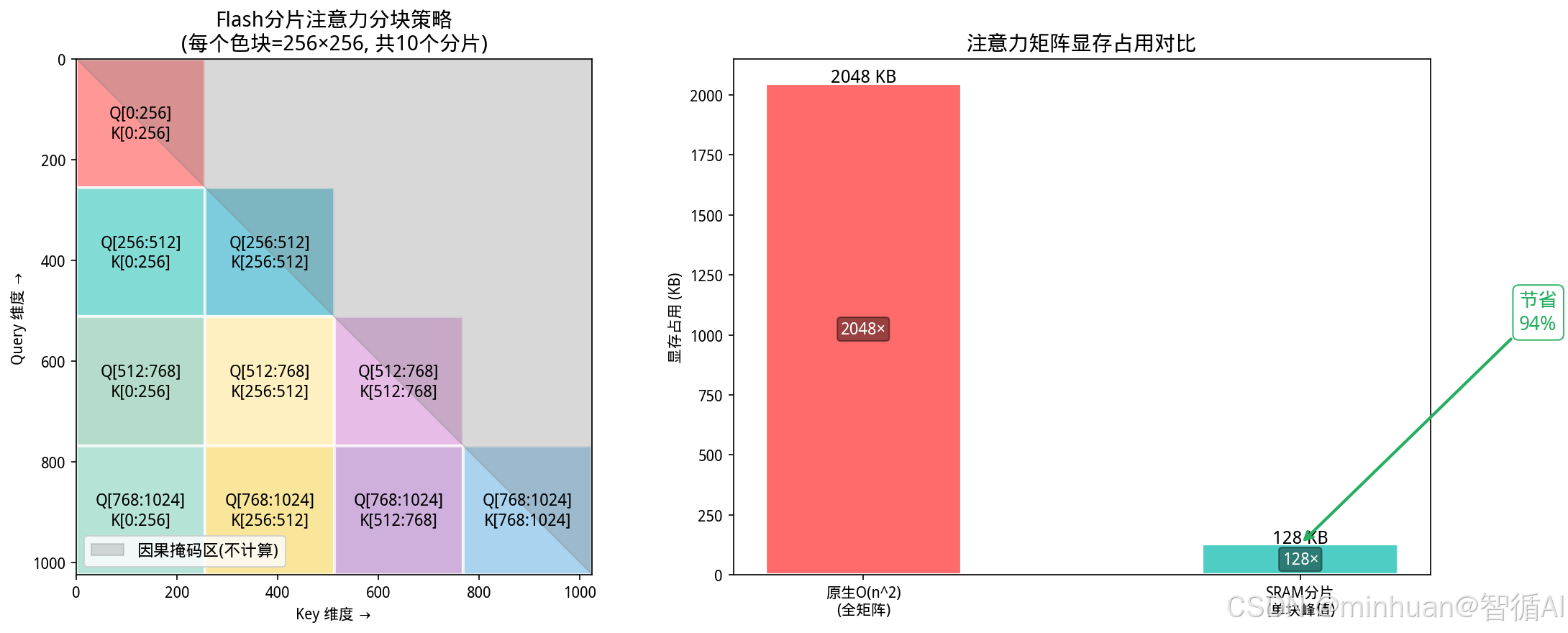
- 左图将1024×1024矩阵划分为256×256的分片,灰色区域为因果掩码不参与计算,彩色方块为实际SRAM分片;
- 右图对比了原生需2MB显存而分片仅需128KB,节省94%。这使大模型在消费级GPU上也能高效处理长序列输入。
四、PagedAttention:分页缓存解决并发卡顿
1. 高并发对话:KV缓存混乱溢出
大模型多轮对话推理,都会缓存历史上下文K、V向量组成KV Cache。每个用户对话长度不同、会话时长不同、随时新增删除上下文,原生KV缓存连续占用显存。
新对话不断申请显存、旧对话释放碎片显存,显存出现大量不连续碎片。GPU无法高效复用碎片空间,显存实际利用率极低,大量空间浪费。同时并发用户越多,碎片越严重,KV读取越慢,对话延迟飙升,频繁显存OOM服务卡顿崩溃,这是云端大模型API无法大规模商用的核心难题。
2. PagedAttention分页核心思想
PagedAttention借鉴操作系统虚拟内存分页机制,把连续KV缓存切割为固定大小页面块Page,统一管理所有会话KV数据。不再要求单会话KV连续存储,分散存入不同空闲页面,逻辑连续、物理离散。
如同书本分页存放内容,对话新增上下文就分配新页面,对话删减内容直接释放对应页面,页面可在任意会话之间自由复用,彻底消灭显存碎片,极致提升高并发显存利用率。
3. 分页KV缓存完整执行流程

- 1. 统一划分固定大小KV页面,初始化显存页面池
- 2. 用户新建对话,按需分配空闲页面存储KV数据
- 3. 对话追加Token,新增页面写入新KV缓存
- 4. 对话截断、清空上下文,快速释放页面归还页面池
- 5. 新会话直接复用空闲页面,无需重新申请连续显存
- 6. 调度器统一管理页面冷热,优先复用高频活跃缓存
分页机制让多会话KV互不干扰,显存无碎片堆积,千万级并发对话依旧稳定流畅。相同显卡显存,可承载会话数量提升数倍,多轮长对话再也不会越聊越卡。
4. 两代注意力协同推理架构
- FlashAttention负责单会话内部分片高速计算,降低IO开销、加快单条对话生成速度;
- PagedAttention负责多会话全局KV分页调度,优化并发缓存管理、提升整体服务吞吐量。
两者结合就是当前云端大模型推理标准架构:分片计算提速 + 分页缓存抗并发,同时解决长上下文算力瓶颈、高并发显存瓶颈,千亿大模型云端高可用商用正式落地。
5. 分页注意力业务价值
- 1. 多轮对话长上下文无卡顿,上下文长度无硬性瓶颈
- 2. 显存碎片清零,显存利用率提升3~5倍以上
- 3. 高并发用户吞吐量大幅上涨,API服务成本大幅下降
- 4. 支持会话动态切换、上下文截断、长短对话混合调度
- 5. 大幅降低推理排队时延,用户对话响应几乎零延迟
- 6. 稳定避免显存溢出,不简单云端长稳运行
6. 示例:KV分页缓存
以下示例模拟了vLLM PagedAttention的KV分页缓存机制:将KV缓存切分为固定大小的页面,多会话共享一个页面池,释放的页面可直接被新会话复用,彻底消除显存碎片。
import torch
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
import matplotlib
matplotlib.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei']
matplotlib.rcParams['axes.unicode_minus'] = False
# 自动检测设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
dtype = torch.bfloat16 if device.type == 'cuda' else torch.float32
print(f"当前运行设备: {device}, 计算精度: {dtype}")
# 分页KV缓存模拟(操作系统页式管理)
page_size = 256 # 单个KV页面长度
max_page_pool = 32 # 显存页面池总量
dim = 128
# 初始化显存页面池
kv_page_pool = [torch.zeros(page_size, dim * 2, device=device, dtype=dtype)
for _ in range(max_page_pool)]
session_pages = {} # 会话->页面编号列表映射
# 分配页面
def alloc_page():
for idx, page in enumerate(kv_page_pool):
if torch.allclose(page, torch.zeros(1, device=device, dtype=dtype)):
return idx
return -1
# 会话追加KV缓存
def append_session_kv(session_id, new_kv):
if session_id not in session_pages:
session_pages[session_id] = []
pid = alloc_page()
merged = torch.cat([new_kv[0].to(device=device, dtype=dtype),
new_kv[1].to(device=device, dtype=dtype)], dim=-1)
kv_page_pool[pid][:len(merged)] = merged
session_pages[session_id].append(pid)
return pid
# 释放会话页面(归还池内,碎片清零)
def free_session_page(session_id):
for pid in session_pages.pop(session_id, []):
kv_page_pool[pid].zero_()
# 获取页面池占用快照
def get_pool_snapshot():
"""返回每个页面的归属情况:None=空闲, str=会话ID"""
snapshot = [None] * max_page_pool
for sid, pids in session_pages.items():
for pid in pids:
snapshot[pid] = sid
return snapshot
# 记录每个步骤的页面池快照
snapshots = []
snapshots.append(('初始状态', get_pool_snapshot()))
append_session_kv("user_1", (torch.randn(100, dim), torch.randn(100, dim)))
snapshots.append(('user_1 分配', get_pool_snapshot()))
append_session_kv("user_2", (torch.randn(180, dim), torch.randn(180, dim)))
snapshots.append(('user_2 分配', get_pool_snapshot()))
free_session_page("user_1")
snapshots.append(('user_1 释放', get_pool_snapshot()))
append_session_kv("user_3", (torch.randn(200, dim), torch.randn(200, dim)))
snapshots.append(('user_3 复用', get_pool_snapshot()))
print("分页KV会话页面分配完成,无显存碎片")
# ========== 可视化:页面池状态演进与碎片对比 ==========
fig = plt.figure(figsize=(18, 11))
gs = fig.add_gridspec(3, 4, height_ratios=[1.2, 1.5, 1.5],
hspace=0.45, wspace=0.3,
left=0.05, right=0.97, top=0.95, bottom=0.08)
session_colors = {'user_1': '#FF6B6B', 'user_2': '#4ECDC4', 'user_3': '#FFEAA7'}
# 上行:页面池状态演进(4个关键步骤,占1行4列)
for idx, (title, snap) in enumerate(snapshots[1:]): # 跳过初始空状态
ax = fig.add_subplot(gs[0, idx])
for i in range(max_page_pool):
r, c = i // 4, i % 4
sid = snap[i]
color = session_colors.get(sid, '#E0E0E0') if sid else '#F0F0F0'
rect = mpatches.Rectangle((c * 1.1, r * 1.1), 1, 1,
facecolor=color, edgecolor='#888', linewidth=1.5,
alpha=0.85 if sid else 0.5)
ax.add_patch(rect)
label = str(i) if sid else ''
ax.text(c * 1.1 + 0.5, r * 1.1 + 0.5, label,
ha='center', va='center', fontsize=10, fontweight='bold',
color='white' if sid else '#999')
ax.set_xlim(-0.2, 4 * 1.1)
ax.set_ylim(8 * 1.1, -0.2)
ax.set_aspect('equal')
ax.set_title(f'步骤:{title}', fontsize=13, fontweight='bold')
ax.axis('off')
used = sum(1 for s in snap if s)
free = max_page_pool - used
ax.text(0.5, -0.7, f'已用:{used} 空闲:{free}',
transform=ax.transAxes, ha='center', fontsize=11,
bbox=dict(boxstyle='round', facecolor='white', alpha=0.8))
# 中行:连续分配碎片示意(占1行4列全宽)
ax3 = fig.add_subplot(gs[1, :])
labels_con = ['user_1', 'user_2', '空洞\n(已释放)', 'user_3']
values_con = [200, 360, 0, 400]
colors_con = ['#FF6B6B', '#4ECDC4', '#E0E0E0', '#FFEAA7']
bars = ax3.bar(range(4), values_con, color=colors_con, edgecolor='white', linewidth=2, width=0.55)
ax3.set_xticks(range(4))
ax3.set_xticklabels(labels_con, fontsize=12)
ax3.set_title('连续分配:释放产生碎片,user_3 无法直接复用空洞位置',
fontsize=14, fontweight='bold', color='#E74C3C')
ax3.set_ylabel('占用 (KB)', fontsize=11)
ax3.set_ylim(0, 520)
for bar, val in zip(bars, values_con):
if val > 0:
ax3.text(bar.get_x() + bar.get_width() / 2, bar.get_height() / 2,
f'{val}KB', ha='center', va='center', fontsize=12, fontweight='bold',
color='white')
# 下行:分页分配复用示意(占1行4列全宽)
ax4 = fig.add_subplot(gs[2, :])
paged_blocks = ['页面0', '页面1', '页面2\n(空闲)', '页面3\n(空闲)']
values_paged = [1, 1, 0, 0]
colors_paged = ['#FFEAA7', '#4ECDC4', '#E8F8F5', '#E8F8F5']
bars4 = ax4.bar(range(4), values_paged, color=colors_paged, edgecolor='white', linewidth=2, width=0.55)
ax4.set_xticks(range(4))
ax4.set_xticklabels(paged_blocks, fontsize=12)
ax4.set_title('分页分配:user_3 直接复用 user_1 释放的页面0,零碎片',
fontsize=14, fontweight='bold', color='#27AE60')
ax4.set_ylabel('页面占用', fontsize=11)
ax4.set_ylim(0, 1.5)
ax4.set_yticks([0, 1])
ax4.set_yticklabels(['空闲', '占用'], fontsize=10)
annotations = [('user_3 复用', '#333'), ('user_2 占用', 'white'), ('空闲', '#27AE60'), ('空闲', '#27AE60')]
for bar, (label, clr) in zip(bars4, annotations):
ax4.text(bar.get_x() + bar.get_width() / 2, bar.get_height() / 2,
label, ha='center', va='center', fontsize=12, fontweight='bold', color=clr)
# 底部图例
fig.legend(handles=[mpatches.Patch(color='#FF6B6B', label='user_1'),
mpatches.Patch(color='#4ECDC4', label='user_2'),
mpatches.Patch(color='#FFEAA7', label='user_3'),
mpatches.Patch(color='#F0F0F0', label='空闲页面')],
loc='lower center', ncol=4, fontsize=11, framealpha=0.9,
bbox_to_anchor=(0.5, 0.01))
plt.show()输出结果:
当前运行设备: cuda, 计算精度: torch.bfloat16
分页KV会话页面分配完成,无显存碎片
结果图示:
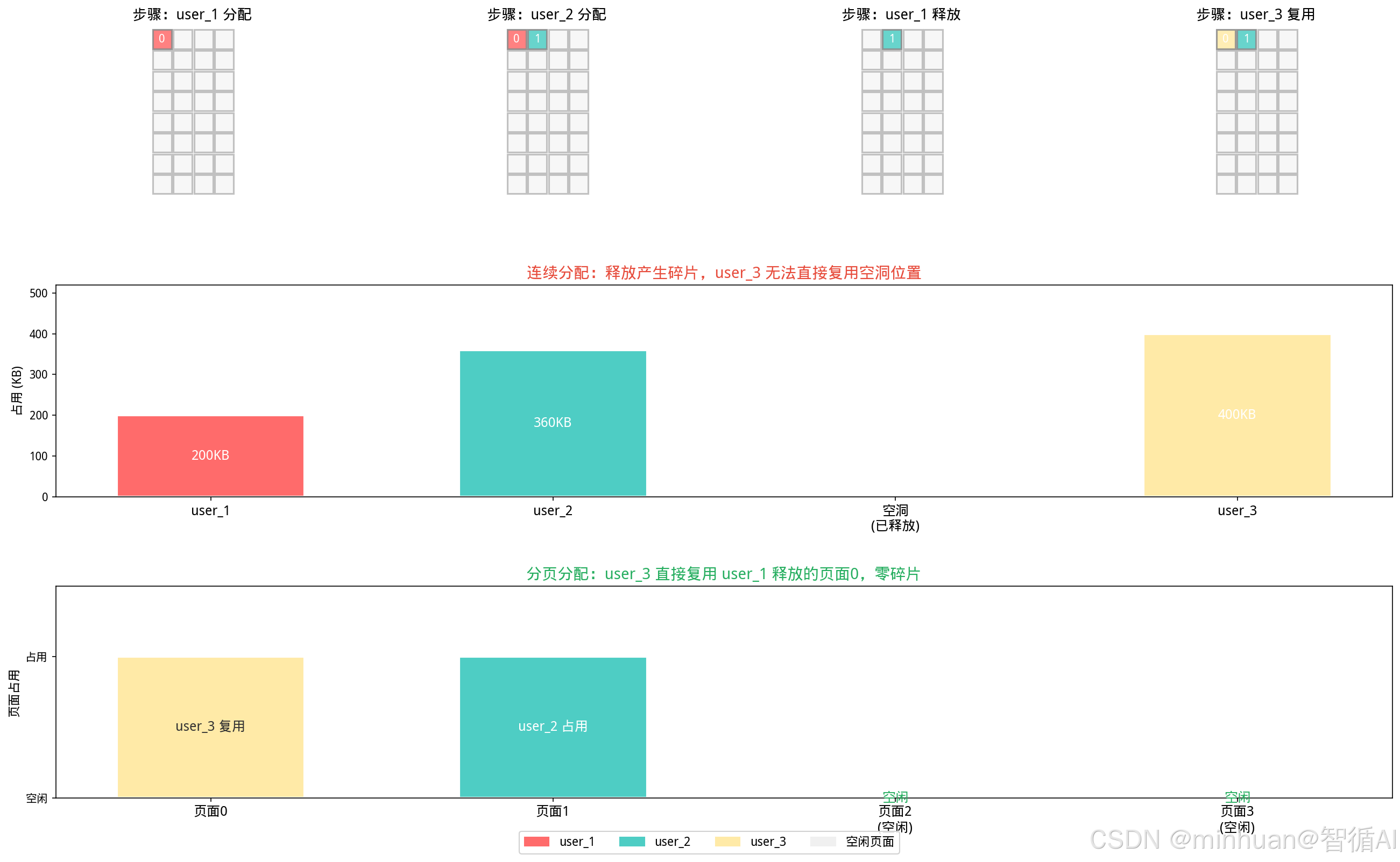
- 图上半部分追踪了user_1分配→user_2分配→user_1释放→user_3复用四步状态;
- 图下半部分对比了连续分配产生空洞与分页复用页面的差异。
该机制使KV缓存的显存利用率从连续分配的20%-40%提升至96%以上,是vLLM支持高并发推理的核心技术。
五、总结
早期原生平方级注意力,越长越卡、越用越爆显存,根本没法放到线上给大量用户用。后来FlashAttention靠GPU片上分块计算,狠狠砍掉了无效显存搬运,长文本推理终于又快又省显存;紧接着PagedAttention用操作系统分页思路管理KV缓存,彻底解决多用户同时聊天、来回对话导致的显存碎片与卡顿排队问题。
两代注意力一前一后补齐短板,Flash搞定长上下文跑不动的难题,Paged搞定多人并发扛不住的痛点,搭配在一起,千亿大模型才能稳稳跑在云端 API,日常多轮聊天、超长文档阅读、高并发在线服务全都流畅可用。
现在各类推理引擎不断更新优化,我们也能自由改动、适配自定义注意力逻辑,超长上下文相关技术也在飞速迭代,大模型推理越来越便宜、速度越来越快。往后注意力算法会越来越贴合显卡硬件与真实业务场景,朝着线性计算、端侧轻量化、多模态统一方向持续升级,真正让大模型全面走进各行各业,规模化落地普及。

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐



 1
1 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)