保姆级教程:手把手搭建MCP服务器让AI替你干活
摘要: MCP(Model Context Protocol)是一种让AI模型与外部工具交互的协议标准,解决了AI"只会说不会做"的问题。本文提供从零搭建MCP服务器的保姆级教程: MCP原理:作为AI与工具间的"翻译官",统一管理文件系统、数据库、API等工具的调用 快速体验:通过Claude Desktop一键安装文件系统工具,实测AI创建文件和文件夹 手动配置:使用Python搭建MCP服务
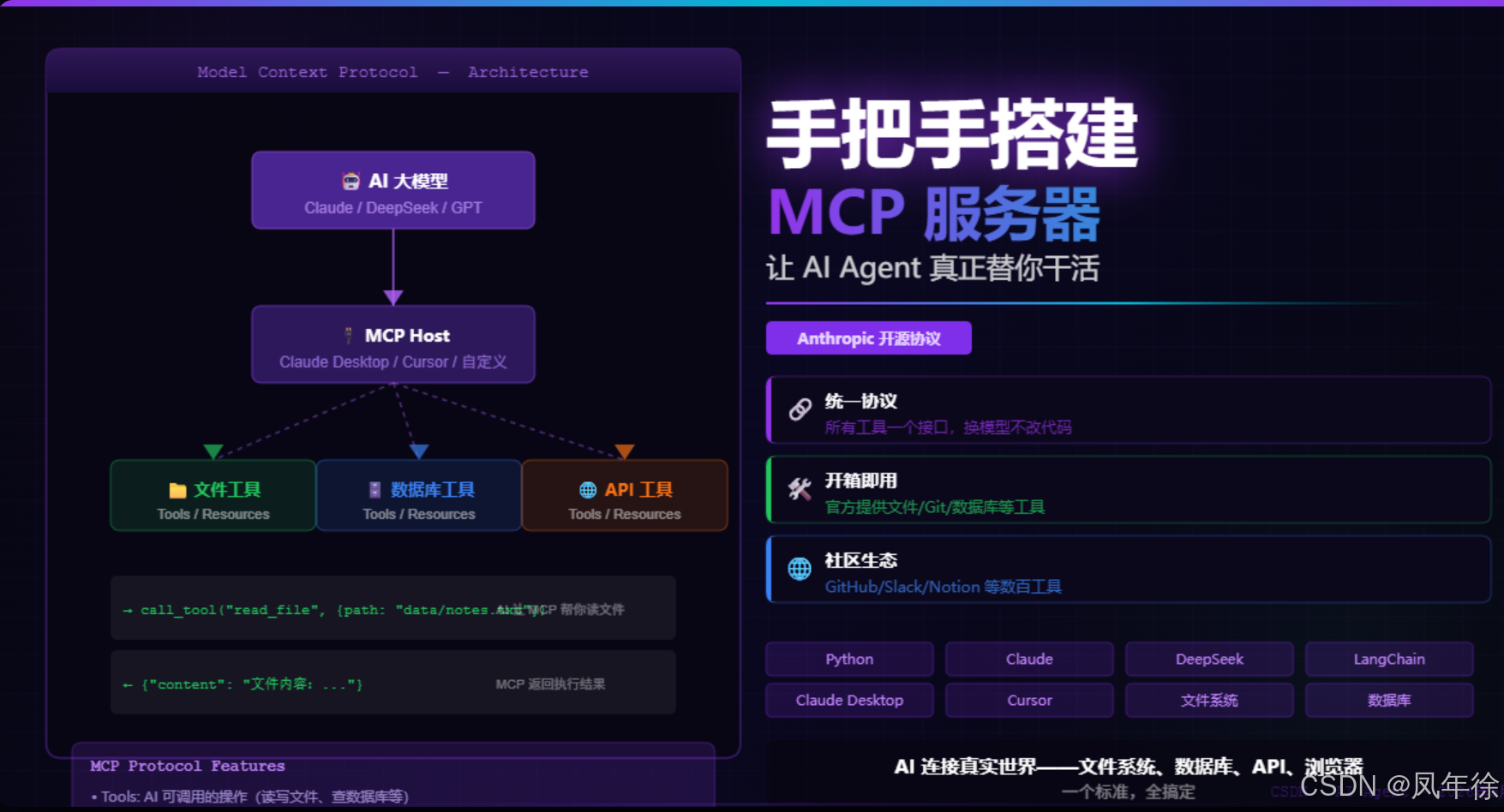
保姆级教程:手把手搭建 MCP 服务器,让 AI Agent 真正替你干活
让 AI 连接真实世界——文件系统、数据库、API、浏览器,一个标准全搞定
预计完成时间: 3 小时
所需技能: 基础 Python、会用命令行
适合人群: 想让 AI 真正执行任务而不是只会回答问题的同学
前言:AI 为什么会"说不会"?
用过 ChatGPT 或 Claude 的同学可能遇到过这种情况:
你问 AI:“帮我查一下今天A股涨了多少”,它回答:“我没有实时数据,无法查询”。
你问:“帮我把文件夹里的所有图片重命名”,它说:“我无法访问你的本地文件系统”。
你问:“帮我给张三发一封邮件”,它说:“我无法替你发送邮件”。
这是为什么?
原因很简单——大模型是一个"知识型选手",它能回答问题、生成内容,但它无法真正与这个世界交互。它不知道你电脑里有什么文件,不知道今天是几号,更不能替你发邮件。
那怎么办?
答案就是今天要讲的 MCP(Model Context Protocol,模型上下文协议)。
一句话解释 MCP:它是一个标准,让 AI 能够调用外部工具的"翻译官"。
没有 MCP 时,AI 说"我不会"是因为它真的没有能力;
有了 MCP 后,AI 可以调用文件工具、数据库工具、API工具——它从"说不会"变成"我去试试"。
一、先搞懂:MCP 到底是什么?
1.1 不用术语,用大白话
想象你是一个团队的老板(AI),你手下有很多能干活的员工(工具),但问题是你不知道每个员工会什么、怎么指挥他们。
没有 MCP 时:
老板(AI):"我需要查数据库,但不知道怎么找到会查数据库的员工"
员工(工具):"我会查数据库,但不知道老板什么时候需要我"
→ 两个人互相不认识,合作卡住了
有了 MCP 时:
MCP = 团队秘书(中间层)
老板(AI)告诉秘书:"我需要查数据库"
秘书说:"好,我让数据库管理员(工具)来做"
→ 秘书负责翻译和协调,AI 只管下命令
1.2 MCP 的工作原理
┌─────────────┐ MCP ┌──────────────┐ MCP ┌──────────────┐
│ AI 大模型 │ ←──────────→ │ MCP Host │ ←──────────→ │ MCP Server │
│ (Claude) │ │ (Claude App) │ │ (工具提供者) │
└─────────────┘ └──────────────┘ └──────────────┘
│
┌──────┼──────┐
↓ ↓ ↓
文件 数据库 API
工具 工具 工具
MCP 协议定义了三个核心交互:
| 交互 | 说明 |
|---|---|
| Tools(工具) | AI 可以调用哪些操作(如"读取文件"、“查数据库”) |
| Resources(资源) | AI 可以读取的数据(如"当前目录文件列表") |
| Prompts(提示模板) | 预定义的工作流(如"分析这张图片") |
1.3 为什么我们需要 MCP?
对比一下传统 AI 开发和 MCP:
| 对比项 | 传统方式 | MCP 方式 |
|---|---|---|
| 接入新工具 | 需要写大量代码适配 | 接入一个 MCP Server 就好了 |
| 工具管理 | 每个工具单独写 API 调用 | 统一协议,所有工具一个接口 |
| AI 模型切换 | 换模型要重写工具代码 | 不需要,协议通用 |
| 安全 | 每个工具单独做权限控制 | MCP 提供标准化的权限机制 |
| 社区生态 | 需要自己造轮子 | 社区已经造好了几百个工具 |
1.4 MCP 生态现状
MCP 是由 Anthropic(Claude 的公司)在 2024 年底开源的,目前生态已经非常丰富:
- 官方工具:文件系统、Git、数据库、浏览器等
- 社区工具:GitHub、Slack、Google Drive、Notion 等
- 企业工具:各种内部系统的 MCP 适配器
官方市场:https://modelcontextprotocol.io
第一阶段:快速体验——安装官方 MCP 工具(15 分钟)
第 1 步:安装 Claude Desktop(含 MCP 支持)
MCP 最成熟的客户端是 Claude Desktop(Anthropic 官方提供)。
下载地址: https://claude.ai/download
下载安装后,登录你的账号即可。
如果你用的是其他支持 MCP 的客户端(如 Cursor、VS Code 等),也可以直接跳过这一步,继续看第二阶段手动配置。
第 2 步:安装第一个 MCP Server——文件系统工具
Claude Desktop 支持一键安装 MCP 工具。
- 打开 Claude Desktop
- 点击左下角**「设置」→「开发者」**
- 点击**「Install MCP Server」**
- 找到 Filesystem,点击安装
安装完成后,Claude Desktop 就能读取和写入你电脑上的文件了!
第 3 步:实测体验
打开 Claude Desktop,对它说:
"帮我创建一个名为 test_project 的文件夹,并在里面放一个 hello.py 文件,内容是你好世界"
你会看到 AI 实际上调用了文件系统工具,创建了真实的文件和文件夹——它不再只是"说不会",而是真正帮你完成任务。
第二阶段:Python 手动配置 MCP(30 分钟)
虽然 Claude Desktop 提供了一键安装,但如果你想用 Python 代码自己搭建一个 MCP 集成,或者在自己的应用里接入 MCP,需要手动配置。
下面我们从零开始。
第 4 步:安装 Python 依赖
pip install mcp anthropic openai python-dotenv
第 5 步:目录结构
mkdir -p mcp-demo/src mcp-demo/tools mcp-demo/data
touch mcp-demo/src/__init__.py
touch mcp-demo/tools/__init__.py
touch mcp-demo/main.py
touch mcp-demo/.env
第 6 步:创建 MCP Server
MCP Server 是工具的提供者。我们先写一个最简单的——文件系统工具的 MCP Server。
新建 mcp-demo/tools/file_server.py:
"""
MCP Server 示例:文件系统工具
AI 可以通过这个 Server 读取、写入、搜索本机文件
"""
import os
from typing import Any
# MCP Server 核心
from mcp.server import Server
from mcp.types import Tool, TextContent
# 创建 MCP Server 实例
server = Server("filesystem-tools")
# ── 定义工具列表 ──────────────────────────────────────────────
@server.list_tools()
async def list_tools() -> list[Tool]:
"""返回这个 Server 提供哪些工具"""
return [
Tool(
name="read_file",
description="读取文件内容。参数:path(文件路径)",
inputSchema={
"type": "object",
"properties": {"path": {"type": "string", "description": "要读取的文件路径"}},
"required": ["path"]
}
),
Tool(
name="write_file",
description="写入内容到文件。如果文件存在则覆盖。参数:path, content",
inputSchema={
"type": "object",
"properties": {
"path": {"type": "string", "description": "文件路径"},
"content": {"type": "string", "description": "文件内容"}
},
"required": ["path", "content"]
}
),
Tool(
name="list_directory",
description="列出目录下的所有文件和文件夹。参数:path",
inputSchema={
"type": "object",
"properties": {"path": {"type": "string", "description": "目录路径"}},
"required": ["path"]
}
),
Tool(
name="search_files",
description="在目录中搜索包含关键词的文件。参数:path, keyword",
inputSchema={
"type": "object",
"properties": {
"path": {"type": "string", "description": "搜索的起始目录"},
"keyword": {"type": "string", "description": "要搜索的关键词"}
},
"required": ["path", "keyword"]
}
),
]
# ── 实现每个工具的具体功能 ──────────────────────────────────────
@server.call_tool()
async def call_tool(name: str, arguments: dict[str, Any]) -> list[TextContent]:
"""AI 调用工具时实际执行的代码"""
if name == "read_file":
path = arguments["path"]
if not os.path.exists(path):
return [TextContent(type="text", text=f"文件不存在:{path}")]
with open(path, "r", encoding="utf-8") as f:
content = f.read()
if len(content) > 2000:
content = content[:2000] + f"\n...(共 {len(content)} 字符,内容已截断)"
return [TextContent(type="text", text=f"读取成功\n\n文件:{path}\n\n内容:\n{content}")]
elif name == "write_file":
path = arguments["path"]
content = arguments["content"]
os.makedirs(os.path.dirname(path) or ".", exist_ok=True)
with open(path, "w", encoding="utf-8") as f:
f.write(content)
return [TextContent(type="text", text=f"写入成功:{path}")]
elif name == "list_directory":
path = arguments["path"]
if not os.path.exists(path):
return [TextContent(type="text", text=f"目录不存在:{path}")]
items = os.listdir(path)
if not items:
return [TextContent(type="text", text="目录为空")]
lines = [f"目录内容({path}):"]
for item in sorted(items):
full_path = os.path.join(path, item)
icon = "📂" if os.path.isdir(full_path) else "📄"
size = f" ({os.path.getsize(full_path)} bytes)" if os.path.isfile(full_path) else ""
lines.append(f" {icon} {item}{size}")
return [TextContent(type="text", text="\n".join(lines))]
elif name == "search_files":
path = arguments["path"]
keyword = arguments["keyword"]
results = []
for root, dirs, files in os.walk(path):
for file in files:
file_path = os.path.join(root, file)
try:
with open(file_path, "r", encoding="utf-8", errors="ignore") as f:
if keyword in f.read():
results.append(file_path)
except Exception:
pass
if not results:
return [TextContent(type="text", text=f"在 {path} 中没有找到包含「{keyword}」的文件")]
return [TextContent(type="text", text=f"找到 {len(results)} 个文件:\n" + "\n".join([f" {r}" for r in results]))]
else:
return [TextContent(type="text", text=f"未知工具:{name}")]
# ── 启动 Server ────────────────────────────────────────────────
async def main():
"""启动 MCP Server"""
print("MCP 文件系统工具 Server 已启动")
from mcp.server.stdio import serve
async with serve(handler=server):
pass
if __name__ == "__main__":
import asyncio
asyncio.run(main())
第 7 步:创建简单的 AI Agent 框架
新建 mcp-demo/main.py,把 AI 和 MCP 工具连接起来:
"""
MCP AI Agent 核心框架
把 Claude / DeepSeek 等大模型与 MCP 工具连接起来
"""
import os
import json
from dotenv import load_dotenv
load_dotenv()
class MCPAgent:
"""
基于 MCP 的 AI Agent
工作流程:
用户输入 → AI 判断是否需要工具 → 调用工具 → 把结果返回给 AI → 生成最终回答
"""
def __init__(self, model: str = "deepseek"):
self.model = model
self.tools = []
if model == "claude":
from anthropic import Anthropic
self.client = Anthropic(api_key=os.getenv("ANTHROPIC_API_KEY"))
elif model == "openai":
from openai import OpenAI
self.client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
elif model == "deepseek":
from openai import OpenAI
self.client = OpenAI(api_key=os.getenv("DEEPSEEK_API_KEY"), base_url="https://api.deepseek.com")
else:
raise ValueError(f"不支持的模型:{model}")
print(f"Agent 初始化完成,使用模型:{model}")
def register_tools(self, tools: list):
"""注册可用的工具"""
self.tools = tools
print(f"已注册 {len(tools)} 个工具")
for t in tools:
print(f" - {t['name']}: {t['description']}")
def chat(self, message: str) -> str:
"""对话:AI 判断是否需要调用工具,然后生成回答"""
messages = [
{
"role": "system",
"content": """你是一个智能助手,有以下工具可用:
- read_file: 读取文件内容
- write_file: 写入文件内容
- list_directory: 列出目录下的文件
- search_files: 搜索包含关键词的文件
如果用户要求你读取、创建、搜索文件,立即调用对应工具。"""
},
{"role": "user", "content": message}
]
response = self._call_ai(messages)
# 如果 AI 说需要调用工具
while response.get("tool_calls"):
for tool_call in response["tool_calls"]:
tool_name = tool_call["name"]
tool_args = tool_call["arguments"]
result = self._execute_tool(tool_name, tool_args)
messages.append({"role": "assistant", "content": response["content"]})
messages.append({"role": "user", "content": f"[工具结果]\n{result}\n\n请继续。"})
response = self._call_ai(messages)
return response.get("content", "AI 没有返回内容")
def _call_ai(self, messages: list) -> dict:
"""调用大模型"""
if self.model == "claude":
resp = self.client.messages.create(
model="claude-3-5-sonnet-20241022",
max_tokens=1024,
messages=messages,
tools=[{"name": t["name"], "description": t["description"], "input_schema": t["input_schema"]}
for t in self.tools]
)
return {
"content": resp.content[0].text if hasattr(resp.content[0], "text") else str(resp.content),
"tool_calls": [{"name": tc.name, "arguments": tc.input}
for tc in resp.content if hasattr(tc, "input")] if hasattr(resp, "content") else []
}
elif self.model in ("openai", "deepseek"):
resp = self.client.chat.completions.create(
model="gpt-4o" if self.model == "openai" else "deepseek-chat",
messages=messages,
tools=[{"type": "function", "function": {
"name": t["name"], "description": t["description"], "parameters": t["input_schema"]
}} for t in self.tools]
)
choice = resp.choices[0]
tool_calls = []
if choice.message.tool_calls:
for tc in choice.message.tool_calls:
tool_calls.append({"name": tc.function.name, "arguments": json.loads(tc.function.arguments)})
return {"content": choice.message.content or "", "tool_calls": tool_calls}
def _execute_tool(self, name: str, args: dict) -> str:
"""执行工具"""
if name == "read_file":
try:
with open(args.get("path", ""), "r", encoding="utf-8") as f:
return f"文件内容:\n{f.read()[:2000]}"
except FileNotFoundError:
return f"文件不存在:{args.get('path', '')}"
except Exception as e:
return f"读取失败:{e}"
elif name == "write_file":
try:
os.makedirs(os.path.dirname(args.get("path", "")) or ".", exist_ok=True)
with open(args.get("path", ""), "w", encoding="utf-8") as f:
f.write(args.get("content", ""))
return f"写入成功:{args.get('path', '')}"
except Exception as e:
return f"写入失败:{e}"
elif name == "list_directory":
try:
items = os.listdir(args.get("path", "."))
return "目录内容:\n" + "\n".join([f" - {i}" for i in items])
except Exception as e:
return f"列出失败:{e}"
elif name == "search_files":
results = []
for root, dirs, files in os.walk(args.get("path", ".")):
for file in files:
try:
with open(os.path.join(root, file), "r", encoding="utf-8", errors="ignore") as f:
if args.get("keyword", "") in f.read():
results.append(os.path.join(root, file))
except Exception:
pass
return f"找到 {len(results)} 个文件:\n" + "\n".join(results[:20])
return f"未知工具:{name}"
# ── 快速测试 ────────────────────────────────────────────────────
if __name__ == "__main__":
print("=" * 50)
print("MCP AI Agent 测试")
print("=" * 50)
agent = MCPAgent(model="deepseek")
tools = [
{"name": "read_file", "description": "读取文件内容",
"input_schema": {"type": "object", "properties": {"path": {"type": "string"}}, "required": ["path"]}},
{"name": "write_file", "description": "写入文件内容",
"input_schema": {"type": "object", "properties": {"path": {"type": "string"}, "content": {"type": "string"}}, "required": ["path", "content"]}},
{"name": "list_directory", "description": "列出目录下的文件",
"input_schema": {"type": "object", "properties": {"path": {"type": "string"}}, "required": ["path"]}},
{"name": "search_files", "description": "搜索包含关键词的文件",
"input_schema": {"type": "object", "properties": {"path": {"type": "string"}, "keyword": {"type": "string"}}, "required": ["path", "keyword"]}},
]
agent.register_tools(tools)
print("\n测试开始(输入 quit 退出)")
while True:
try:
user_input = input("\n你:").strip()
if not user_input:
continue
if user_input.lower() in ["quit", "exit", "q"]:
print("再见!")
break
response = agent.chat(user_input)
print(f"\nAI:\n{response}")
except (KeyboardInterrupt, EOFError):
print("\n再见!")
break
except Exception as e:
print(f"\n出错:{e}")
第三阶段:实战——构建个人知识库 Agent(45 分钟)
第 8 步:准备知识库文件
cd mcp-demo
mkdir -p data
# 创建 Python 笔记
cat > data/python笔记.txt << 'EOF'
Python 异步编程学习笔记:
一、asyncio 模块
asyncio 是 Python 标准库中的异步编程框架。
核心概念:
- Coroutine(协程):用 async def 定义的异步函数
- Task(任务):协程的封装,用于并发调度
- Event Loop(事件循环):协程的调度器
示例代码:
import asyncio
async def hello():
print("Hello!")
await asyncio.sleep(1)
print("World!")
asyncio.run(hello())
二、async/await 语法
- async def 定义协程函数
- await 等待一个协程完成(不阻塞其他任务)
- 不能在普通函数中 await 异步函数
三、应用场景
- 高并发网络请求(爬虫、API调用)
- IO 密集型任务(文件读写、数据库查询)
- Web 服务器(aiohttp、FastAPI)
四、注意事项
- 协程不能嵌套阻塞调用(如 time.sleep)
- 使用 asyncio.sleep 替代 time.sleep
- 错误处理用 try/except
EOF
# 创建服务器笔记
cat > data/服务器笔记.txt << 'EOF'
Linux 服务器运维笔记:
1. 常用命令
- top:查看进程和系统资源
- htop:更友好的 top
- df -h:查看磁盘使用情况
- du -sh:查看目录大小
2. SSH 免密登录
ssh-copy-id user@server_ip
3. 防火墙
# Ubuntu
ufw allow 22
ufw allow 80
# CentOS
firewall-cmd --permanent --add-port=80/tcp
firewall-cmd --reload
4. 常用服务
- Nginx:反向代理、Web服务器
- Supervisor:进程管理
EOF
echo "测试数据已创建"
第 9 步:运行测试
cd mcp-demo
python main.py
测试对话:
你:帮我搜索一下有没有关于 Python 的笔记
AI:正在搜索...
[工具调用] search_files(path="data", keyword="Python")
[工具结果] 找到 1 个文件:data/python笔记.txt
[继续] 现在读取这个文件...
[工具调用] read_file(path="data/python笔记.txt")
[工具结果] 文件内容:...
AI:找到了!关于 Python 的笔记在 data/python笔记.txt 中,内容包括:
1. asyncio 模块的使用(协程、任务、事件循环)
2. async/await 语法
3. 应用场景(高并发网络请求、IO密集型任务)
第四阶段:连接真实世界——常用 MCP Server(30 分钟)
第 10 步:GitHub MCP Server
如果想用 AI 管理 GitHub 仓库:
npm install -g @modelcontextprotocol/server-github
export GITHUB_TOKEN=ghp_xxxxxxxxxxxxxxx
mcp-server-github
可用工具:
github_list_repos: 列出所有仓库github_create_issue: 创建 Issuegithub_search_code: 搜索代码
第 11 步:数据库 MCP Server
AI 直接操作数据库:
pip install mcp-server-database
export DATABASE_URL=postgresql://user:pass@localhost:5432/mydb
python -m mcp.server.database
可用工具:
db_query: 执行 SQL 查询db_list_tables: 列出所有表db_describe_table: 查看表结构
第 12 步:浏览器 MCP Server
AI 控制浏览器自动化:
pip install mcp-server-browser
playwright install chromium
可用工具:
browser_navigate: 打开网页browser_click: 点击元素browser_screenshot: 截图
第 13 步:多个 MCP Server 同时使用
Claude Desktop 支持同时运行多个 MCP Server。
配置示例(~/.claude_desktop_config.json):
{
"mcpServers": {
"filesystem": {
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-filesystem", "/home/user"]
},
"github": {
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-github"]
}
}
}
第五阶段:进阶——构建生产级 Agent(30 分钟)
第 14 步:添加记忆功能
让 Agent 记住对话历史:
class PersistentMCPAgent(MCPAgent):
"""带记忆功能的 MCP Agent"""
def __init__(self, model: str = "deepseek", memory_size: int = 10):
super().__init__(model)
self.memory: list[dict] = []
self.memory_size = memory_size
def chat(self, message: str) -> str:
# 超过限制时删除最早的记录
if len(self.memory) >= self.memory_size * 2:
self.memory = self.memory[-self.memory_size * 2:]
context = self.memory[-self.memory_size * 2:] + [{"role": "user", "content": message}]
system_msg = {
"role": "system",
"content": """你是一个有记忆的智能助手。
你有以下工具可用:read_file, write_file, list_directory, search_files
根据用户需求调用工具。"""
}
response = self._call_ai([system_msg] + context)
self.memory.append({"role": "user", "content": message})
self.memory.append({"role": "assistant", "content": response.get("content", "")})
return response.get("content", "")
第 15 步:添加计划功能
让 Agent 先思考再行动:
def plan_and_execute(self, goal: str) -> str:
"""计划-执行模式:让 Agent 先规划步骤,再逐步执行"""
plan_prompt = f"""用户目标:{goal}
请制定一个逐步计划来完成这个目标。
每个步骤用一行描述,格式:1. xxx 2. xxx
记住你有这些工具:read_file, write_file, list_directory, search_files"""
plan_response = self._call_ai([{"role": "user", "content": plan_prompt}])
print(f"计划:\n{plan_response['content']}\n")
return plan_response["content"]
第 16 步:添加错误处理和重试
def chat_with_retry(self, message: str, max_retries: int = 3) -> str:
"""带重试的对话"""
for attempt in range(max_retries):
try:
return self.chat(message)
except Exception as e:
if attempt < max_retries - 1:
print(f"出错(尝试 {attempt + 1}/{max_retries}):{e}")
print("重试中...")
else:
return f"重试 {max_retries} 次后仍然失败:{e}"
常见问题与排错
Q:MCP Server 启动后 Claude Desktop 找不到?
# 检查配置路径
ls ~/.claude/
# 查看 Claude 日志
tail -f ~/.claude/logs/*.log
Q:工具调用返回"权限不足"?
MCP Server 需要在配置中指定允许的访问路径,例如:
{
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-filesystem", "/allowed/path1", "/allowed/path2"]
}
Q:MCP 协议和 Function Calling 有什么区别?
Function Calling:每个模型有自己的定义,OpenAI 有 OpenAI 的格式,Claude 有 Claude 的格式
MCP:一个标准协议,所有模型通用,所有工具通用
换句话说:
- Function Calling = 各个品牌手机的原装充电器(只能用在自己手机上)
- MCP = USB-C 接口(所有设备通用)
Q:如何找到更多的 MCP Server?
# 官方市场
# https://modelcontextprotocol.io
# npm 搜索
npm search @modelcontextprotocol
# GitHub 搜索 "mcp-server" 关键词
完整代码结构
mcp-demo/
├── data/
│ ├── python笔记.txt ← 知识库文件
│ └── 服务器笔记.txt
├── tools/
│ └── file_server.py ← MCP 文件工具 Server
├── main.py ← AI Agent 主程序
├── .env ← API Key 配置
└── requirements.txt ← 依赖列表
requirements.txt:
anthropic>=0.40.0
openai>=1.0.0
python-dotenv>=1.0.0
mcp>=0.9.0
总结:你学到了什么?
| 知识点 | 掌握程度 |
|---|---|
| MCP 核心概念(Server/Client/Tools) | 已掌握 |
| Claude Desktop 安装 MCP 工具 | 已掌握 |
| Python 实现自定义 MCP Server | 已掌握 |
| AI Agent 框架(判断→工具→结果→回答) | 已掌握 |
| 文件系统工具集(读/写/列目录/搜索) | 已掌握 |
| 实战:个人知识库 Agent | 已掌握 |
| MCP Server 生态(GitHub/数据库/浏览器) | 已掌握 |
| 进阶:记忆功能 + 计划功能 | 已掌握 |
| 多 MCP Server 同时使用 | 已掌握 |
下一步探索
MCP 打开了 AI Agent 的大门,接下来可以探索:
- Dify + MCP:用 Dify 可视化编排 Agent 工作流,接入 MCP 工具
- 钉钉/飞书 MCP:让 AI 帮你发消息、管日程、处理审批
- 数据库 MCP + LangChain:打造企业级 RAG 系统
- MCP + AI Coding:让 AI 帮你写代码、跑测试、部署上线
- MCP Server 开发:自己开发一个 MCP Server 连接你的业务系统
相关教程:
- 《保姆级教程:从零搭建你的第一个 AI Agent》
- 《保姆级教程:从零手写一个 RAG 系统》
- 《保姆级教程:零成本在本地跑 AI 大模型》

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐
 44
44 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)