阿里云租 GPU 不踩坑指南:GPU 实例选型、购买页配置、驱动自动安装与省钱停机策略
阿里云GPU服务器部署指南 本文提供阿里云GPU服务器从购买到深度学习环境配置的完整流程。首先需注册阿里云账号并完成实名认证,创建GPU实例时需注意选择按量付费模式、合适的地域和GPU型号(推荐gn7i/A10入门)。关键步骤包括:1)创建实例时勾选"安装GPU驱动"选项;2)配置存储(建议200GB系统盘);3)设置安全组规则。实例创建后,通过nvidia-smi命令验证驱动
阿里云部署 GPU 服务器 · 完整实操教程
下面按 从购买 → 驱动就绪 → 深度学习环境跑通 的顺序,给你一套可直接照做的流程(以 ECS GPU 实例 + Linux 为主流场景)。
一、准备工作
-
注册/登录 阿里云控制台,实名认证 + 绑定支付方式(GPU 按量付费需要)
-
如果你是学生/新用户,先看看有没有 "飞天加速计划/学生机/GPU 试用" 优惠券,能省不少
点击创建实例
二、创建 GPU 实例(最关键的一步)
路径:ECS 控制台 → 实例 → 创建实例 → 自定义购买
1️⃣ 付费模式 & 地域
|
配置项 |
推荐选择 |
|---|---|
|
付费类型 |
✅ 按量付费(调试/训练完随时释放);长期稳定用再转包年包月 |
|
地域 |
选离你近的(如 华东 2(上海)/华北 2(北京)),同时注意 哪些可用区有 GPU 库存 |
|
可用区 |
如果有多个可用区,逐个试(GPU 经常某个可用区缺货) |
2️⃣ 实例规格(选 GPU 型号)
在 实例规格 → 异构计算 / GPU 计算 里选,常见规格族:
|
规格族 |
GPU |
适用场景 |
性价比 |
|---|---|---|---|
|
gn7i(如 A10) |
NVIDIA A10 |
推理 / 中小训练 / 炼丹 |
⭐⭐⭐⭐ |
|
gn6v(V100) |
V100 |
重训练 |
⭐⭐⭐ |
|
ebmgn8v(H100/A100 类裸金属) |
高端 |
大模型分布式训练 |
很贵,企业级 |
|
gn6i / gn7(T4) |
T4 |
轻量推理 |
便宜 |
💡 入门/个人练手推荐:
ecs.gn7i-c16g1.4xlarge(A10,16 vCPU / 60GiB 左右,具体看控制台实际规格)
下面是实操:
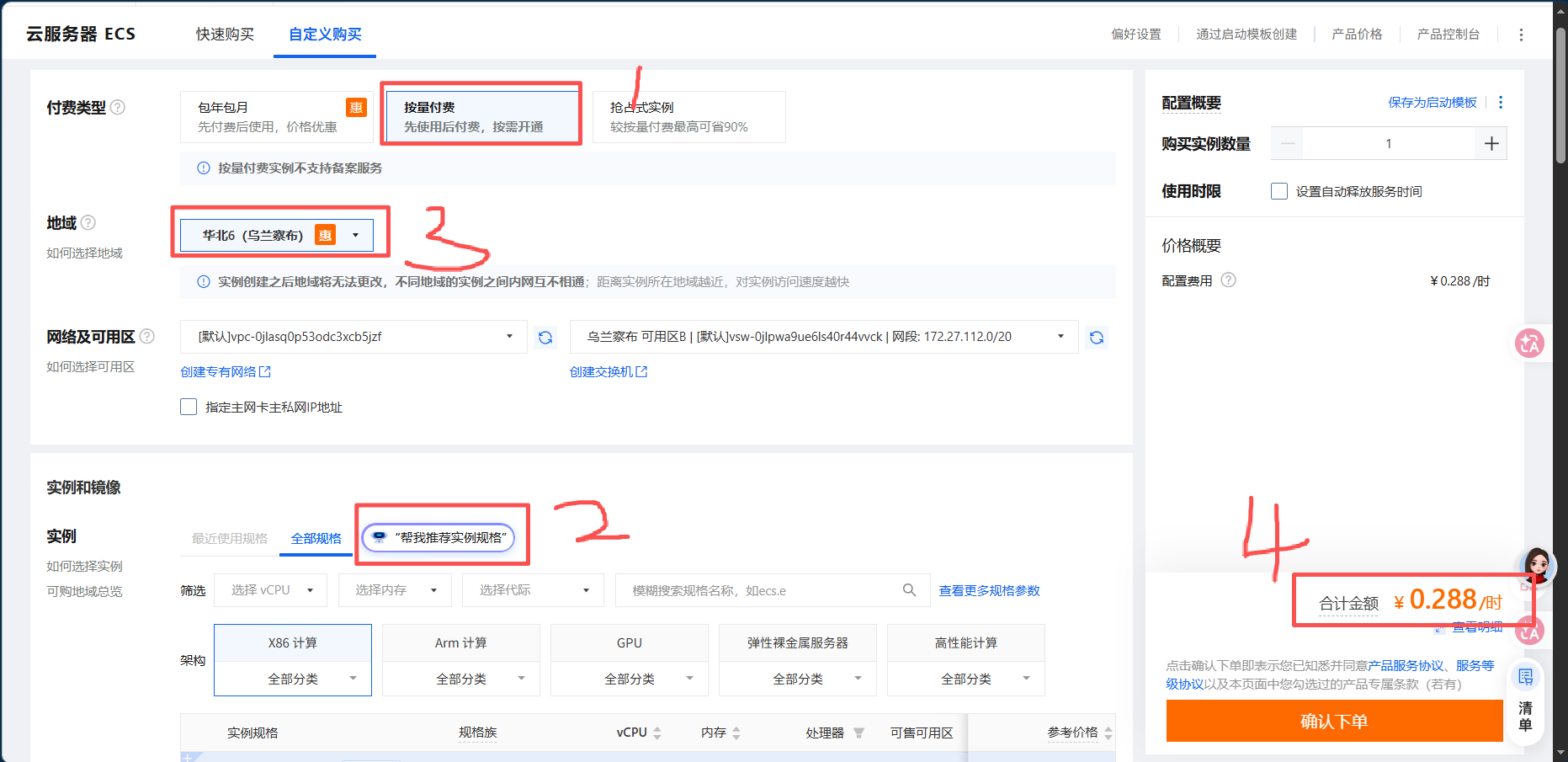
这里是实例创建页面
有几个关键点:
1.收费类型:有钱就选包月没毛病,这个服务器你任何时间启动都行;按量付费就是只算开机使用的价格,不过有个弊端就是,选这个尽量选一个不火爆的区域,不然GPU的资源容易被抢占,有可能会出现你想用的时候没有对应的GPU可以使用;抢占式的应该更难抢GPU。
3.实例选型:点击帮我推荐
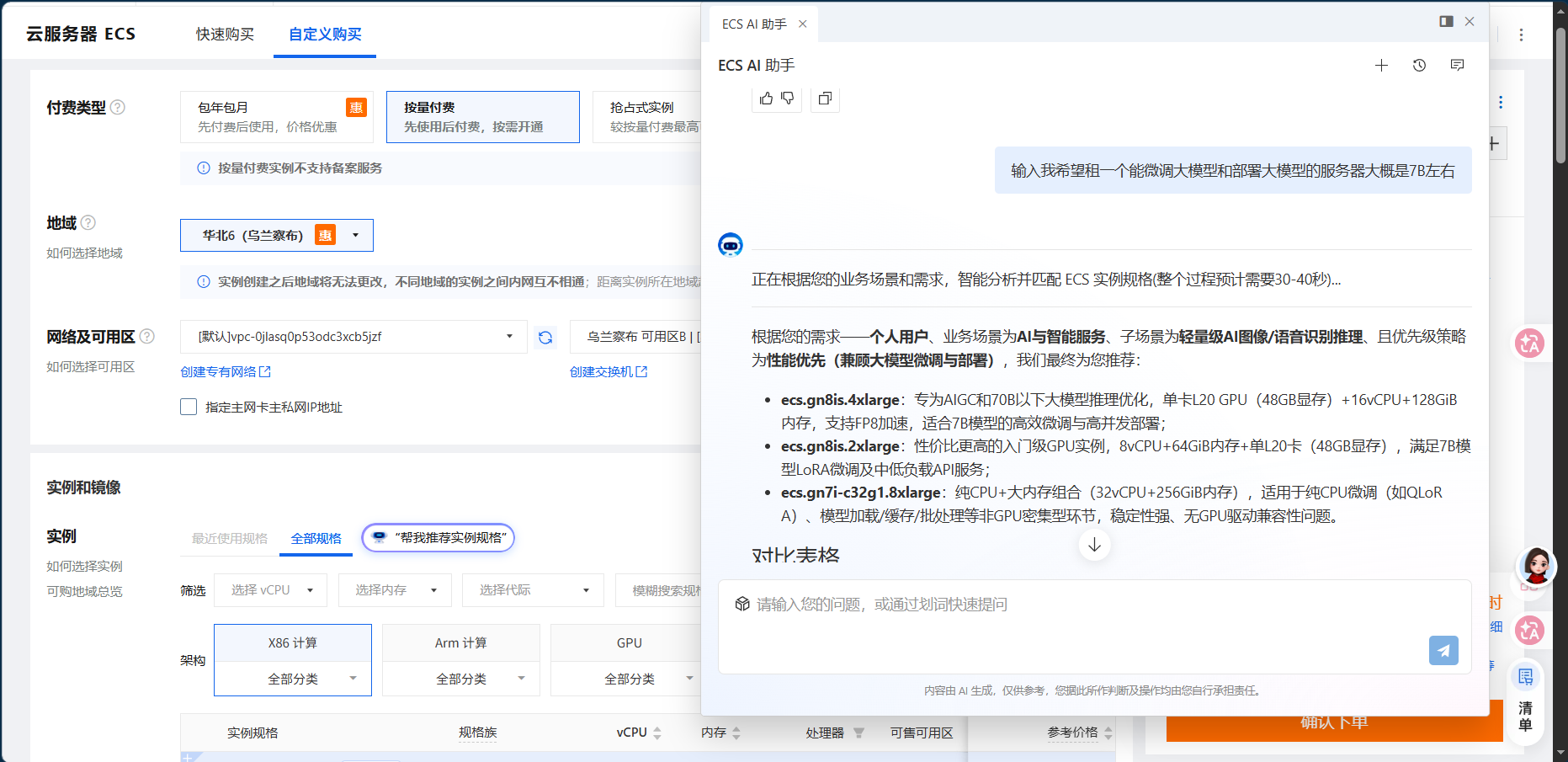

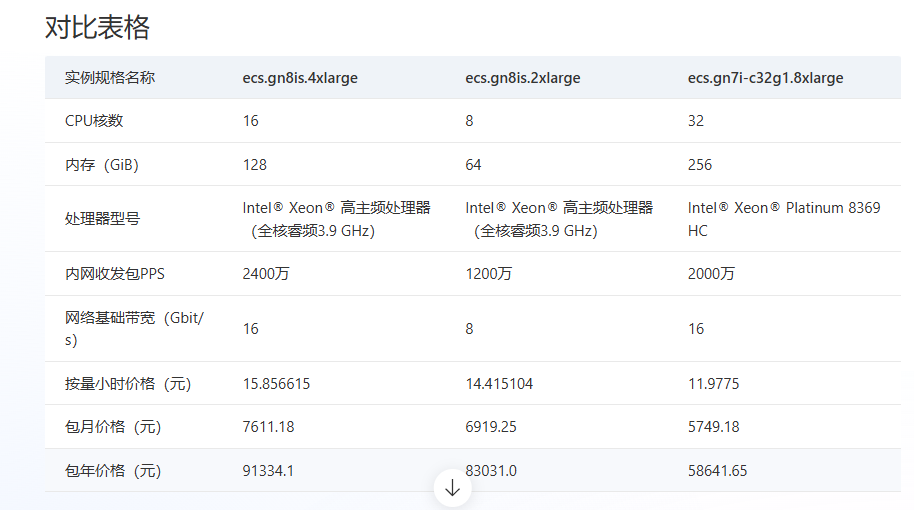
点击购买对应的型号,然后可以加入对比并看到价格
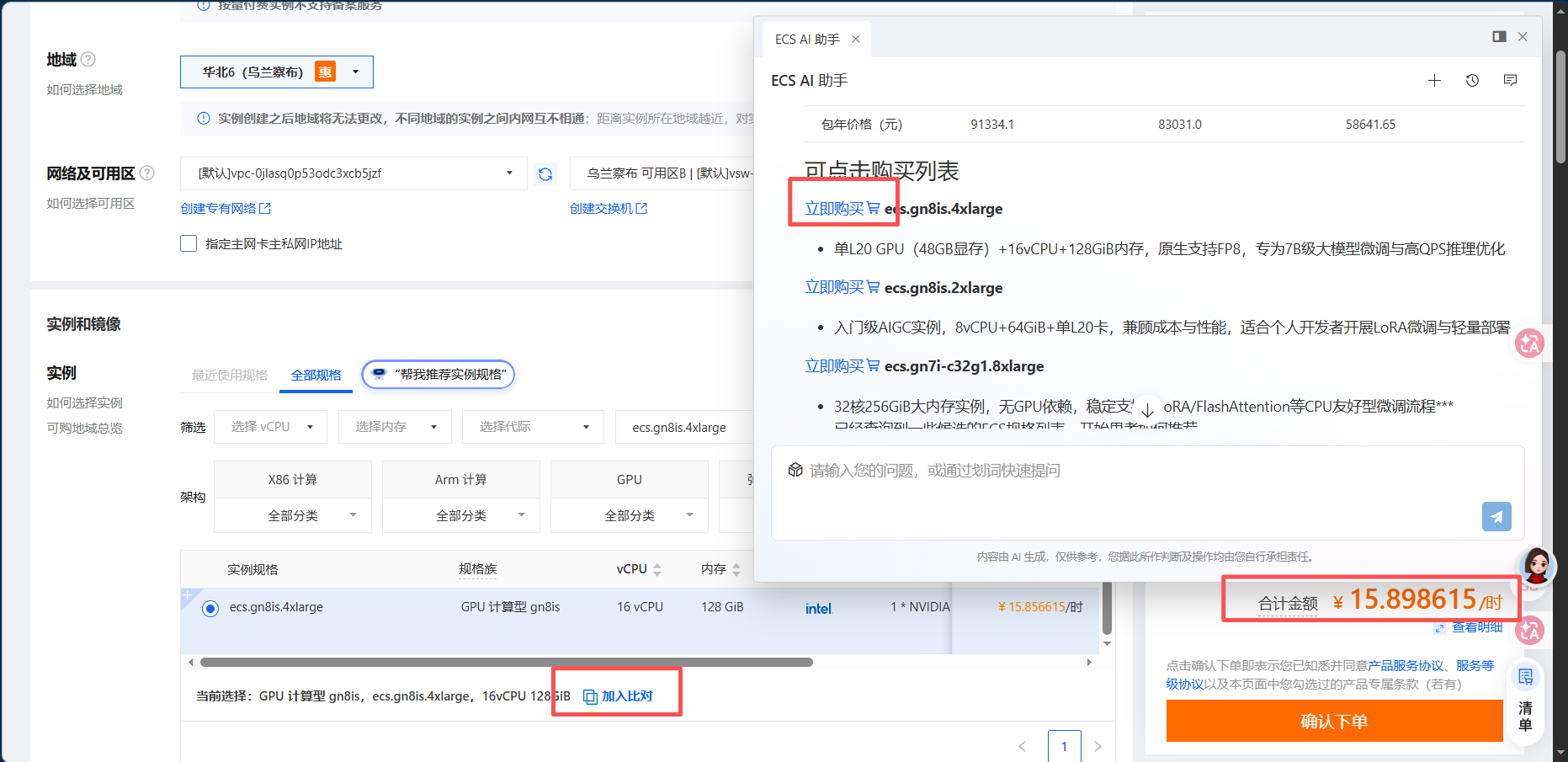
我这里发现第三个选项,最便宜的实例没了就只能对比前两个
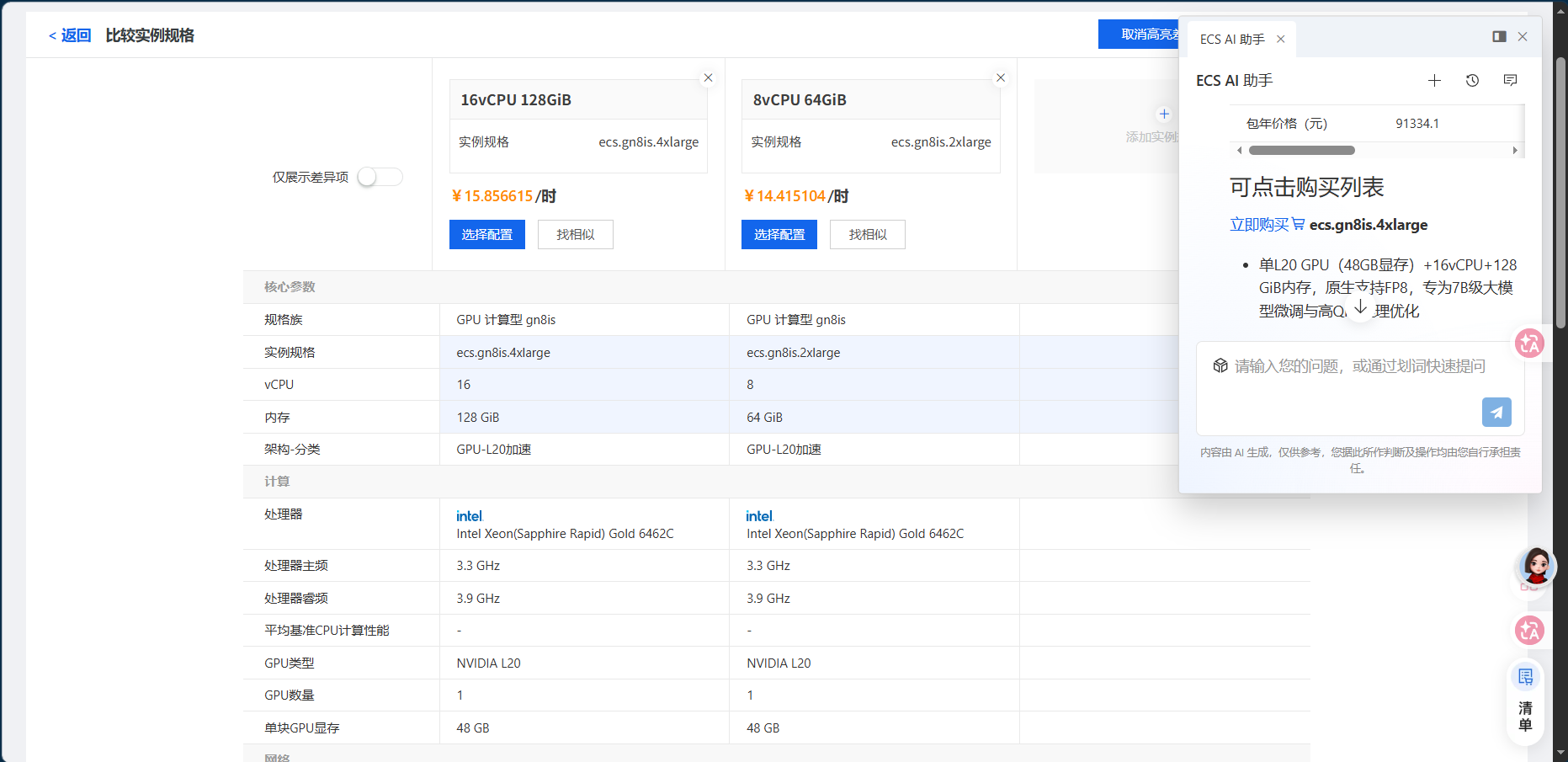
我们准备选第二个型号的ecs.gn8is.2xlarge 入门级AIGC实例,8vCPU+64GiB+单L20卡,兼顾成本与性能,适合个人开发者开展LoRA微调与轻量部署,下面列出了可用的区域
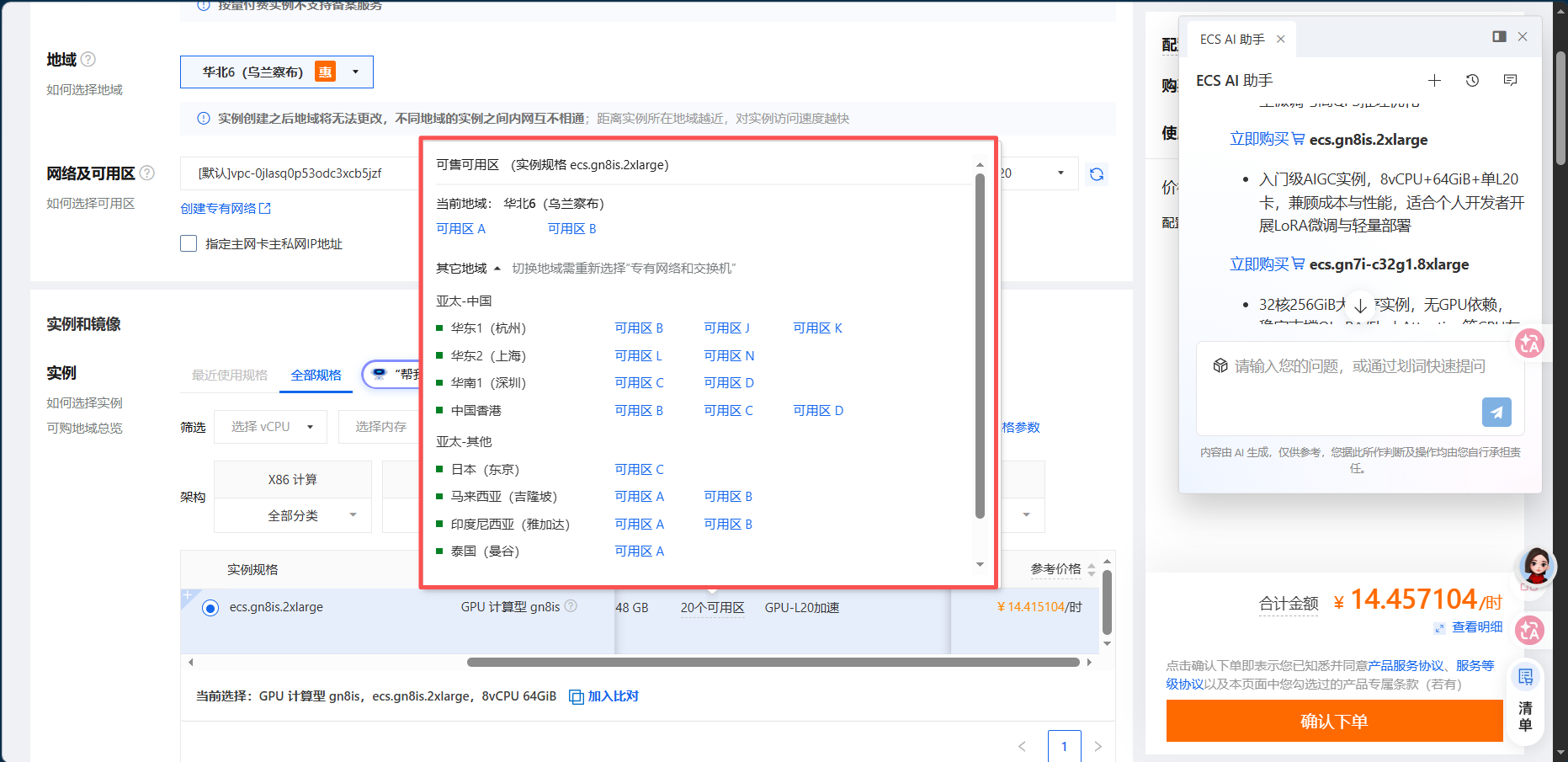
3.地域:按量付费的话一般我们会租两个实例,一个是有GPU的,用来下载或者上传大量数据到数据盘,然后再把这个数据盘挂载到GPU上减少消费的金额。(踩坑记录:自己通过cpu服务器下载好数据挂载给gpu服务器后发现这个gpu服务器资源就一直被占用,不能启动,不能训练数据还得一直缴费数据盘的钱,非常闹心)
实例创建之后地域将无法更改,不同地域的实例之间内网互不相通;距离实例所在地域越近,对实例访问速度越快

这个是元宝给的建议,我们可以选华北6(乌兰察布)试试
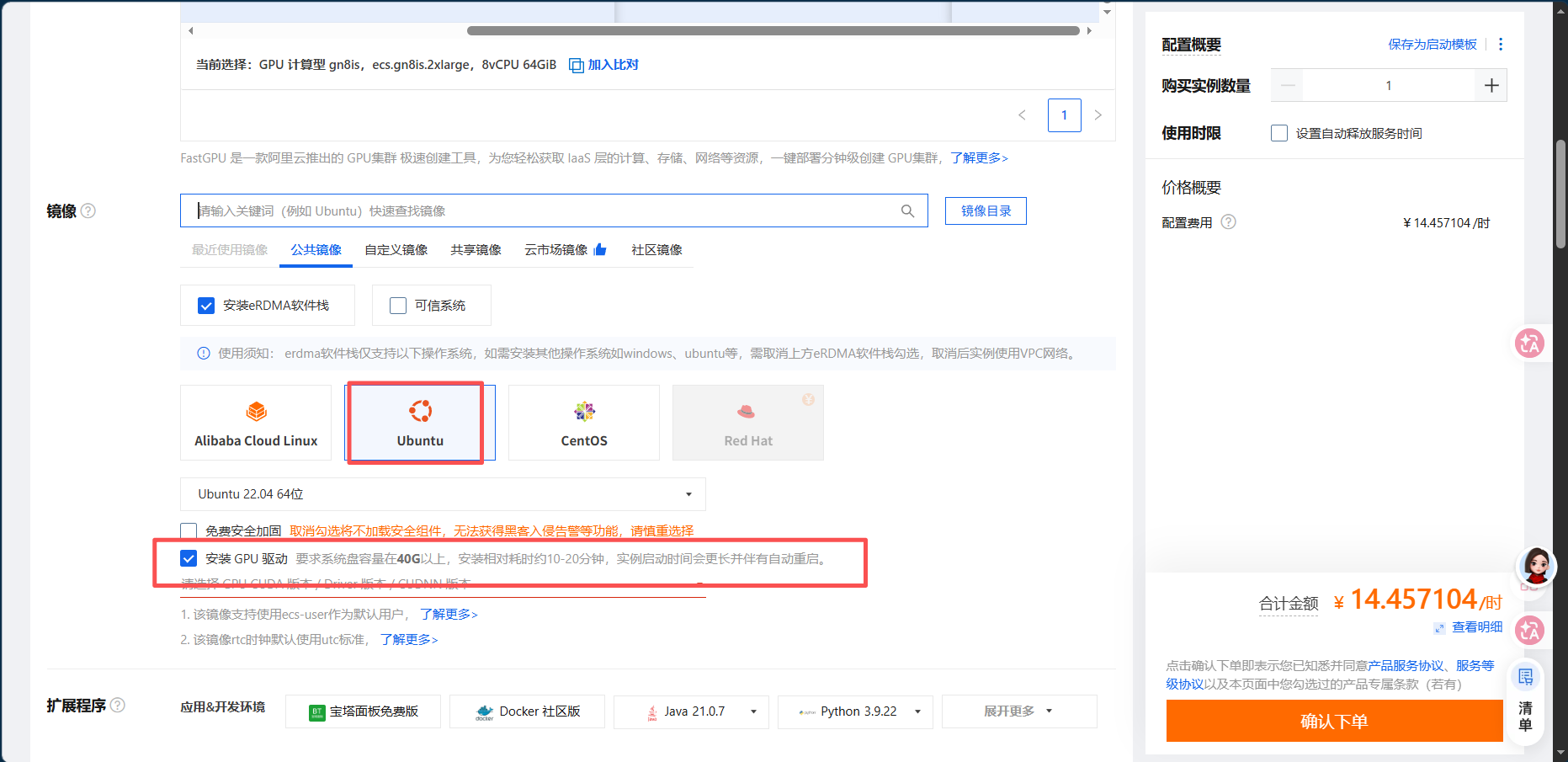
3️⃣ 镜像(⚠️ 重点:驱动怎么装最省事)
强烈推荐做法:用公共镜像 + 勾选「安装 GPU 驱动」,这样创建完实例后驱动会自动装好,不用你手动折腾。
|
选项 |
怎么选 |
|---|---|
|
镜像类型 |
公共镜像 → |
|
✅ 安装 GPU 驱动 |
勾选它!(会出现 CUDA / Driver / cuDNN 版本选择) |
|
CUDA 版本 |
选默认推荐即可(如 CUDA 12.x 系列) |
另一种路线:镜像市场搜 "深度学习" / "NGC" 预装镜像也行,但公共镜像 + 自动安装驱动最干净可控。
4️⃣ 存储
|
配置项 |
推荐 |
|---|---|
|
系统盘 |
ESSD,≥ 100~200 GiB(装框架+缓存很容易吃满) |
|
数据盘(可选但建议) |
再加一块数据盘挂 |
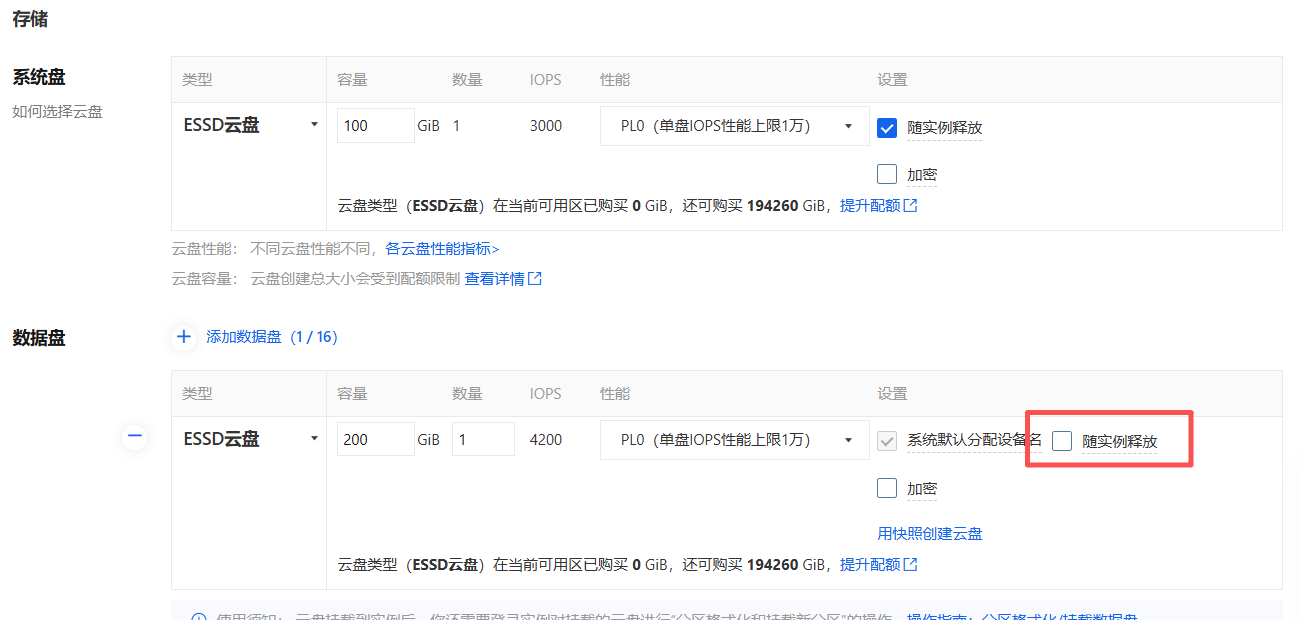
数据盘选择可以这样,建议取消数据盘随实例释放(不需要可以手动释放)
后面的配置按默认就好
5️⃣ 网络 & 公网 IP
-
✅ 分配公网 IPv4 地址
-
带宽计费:按使用流量(你只是下载模型/数据,流量计费更划算)
-
带宽峰值:先设
50~100 Mbps,用完可随时调
6️⃣ 安全组(防火墙)
至少放行这些:
|
端口 |
协议 |
用途 |
|---|---|---|
|
22 |
TCP |
SSH 登录 |
|
8888 |
TCP |
JupyterLab(可选) |
|
80/443 |
TCP |
Web 服务(如需对外开放) |
入口路径:控制台 → 网络与安全 → 安全组 → 入方向 → 添加规则
7️⃣ 设置登录密码 / 密钥对
-
推荐:密钥对(比密码安全)+ 留一个密码备用
-
确认后点 立即购买 / 确认下单
三、第一次登录 & 验证 GPU 驱动
1️⃣ 登录实例
在实例列表点 远程连接 → Workbench 远程连接(或用你本地 Terminal:ssh root@你的公网IP)
2️⃣ 等驱动自动装完(首次约 5~20 分钟)
# 看到这个表格 = GPU 驱动 OK
nvidia-smi你应该能看到类似输出:
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 535.xx Driver Version: 535.xx CUDA Version: 12.x |
|-------------------------------+----------------------+------------------+
| 0 NVIDIA A10 On | 0000... | X | 15360MiB / 23028MiB |
+-----------------------------------------------------------------------------+⚠️ 如果
nvidia-smi报找不到命令/驱动,说明自动安装还在跑,等一会再试;实在不行手动重装(见文末 FAQ)。
四、搭建深度学习环境(两种路线)
路线 A:Docker 方式(★ 最推荐,干净、可复现)
# 1. 安装 Docker(Ubuntu 为例)
sudo apt update
sudo apt install -y ca-certificates curl gnupg
sudo install -m 0755 -d /etc/apt/keyrings
curl -fsSL https://download.docker.com/linux/ubuntu/gpg \
| sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.gpg] \
https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" \
| sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt update
sudo apt install -y docker-ce docker-ce-cli containerd.io
# 2. 安装 NVIDIA Container Toolkit
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey \
| sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit.gpg
curl -fsSL https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list \
| sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit.gpg] https://#g' \
| sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt update
sudo apt install -y nvidia-container-toolkit
sudo nvidia-ctk runtime configure --runtime=docker
sudo systemctl restart docker
# 3. 拉一个官方 PyTorch GPU 镜像测试
docker run --rm --gpus all nvidia/cuda:12.1.0-base-ubuntu22.04 nvidia-smi然后用官方镜像跑你的代码:
docker run -it --gpus all --ipc=host -v $(pwd):/workspace \
pytorch/pytorch:2.1.0-cuda12.1-cudnn8-runtime \
python -c "import torch; print(torch.cuda.is_available(), torch.cuda.get_device_name(0))"路线 B:Conda 直装(更适合交互式开发 / Jupyter)
# 1. 安装 Miniconda
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.sh
# 按提示装完,重开 shell 或 source ~/.bashrc
# 2. 建环境
conda create -n torch python=3.10 -y
conda activate torch
# 3. 装 PyTorch(CUDA 版本要和 nvidia-smi 里的 CUDA Version 兼容)
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
# 4. 验证
python -c "import torch; print(torch.cuda.is_available()); print(torch.cuda.get_device_name(0))"预期输出:
True+ 你的 GPU 型号名 ✅
五、可选:配置 JupyterLab 远程访问
pip install jupyterlab
jupyter lab --ip=0.0.0.0 --port=8888 --no-browser --allow-root然后在浏览器访问 http://你的公网IP:8888,记得安全组要放行 8888。
六、省钱 & 避坑清单(非常重要)
|
坑 |
对策 |
|---|---|
|
GPU 闲置也在烧钱 |
✅ 不用就 停机(停止实例不计费,但云盘仍计费) |
|
想保留环境又不想付盘费 |
做个 自定义镜像(ECS → 实例 → 更多 → 创建自定义镜像),然后释放实例+盘 |
|
按量付费被打爆 |
设置 费用预警(控制台 → 费用 → 预算管理) |
|
库存不足 |
换可用区 / 换地域 / 选低一档规格(如 gn7i 没货试 gn6i) |
|
|
等 15 min → 仍不行就手动装驱动:[Tesla 驱动安装指引] |
七、快速决策表(你该怎么选)
|
你的情况 |
推荐规格 |
镜像策略 |
|---|---|---|
|
刚学 CUDA / PyTorch,跑小模型 |
|
Ubuntu 22.04 + ✅安装GPU驱动 |
|
训大模型(7B~14B) |
|
同上,系统盘 ≥200GiB + 数据盘 |
|
只想跑推理 API |
单卡 T4/A10,按流量带宽 |
Docker + 推理框架镜像 |
|
团队共享 / K8s |
ACK 智能托管 GPU 节点池 |
ContainerOS GPU 优化版 |
其他平民平台
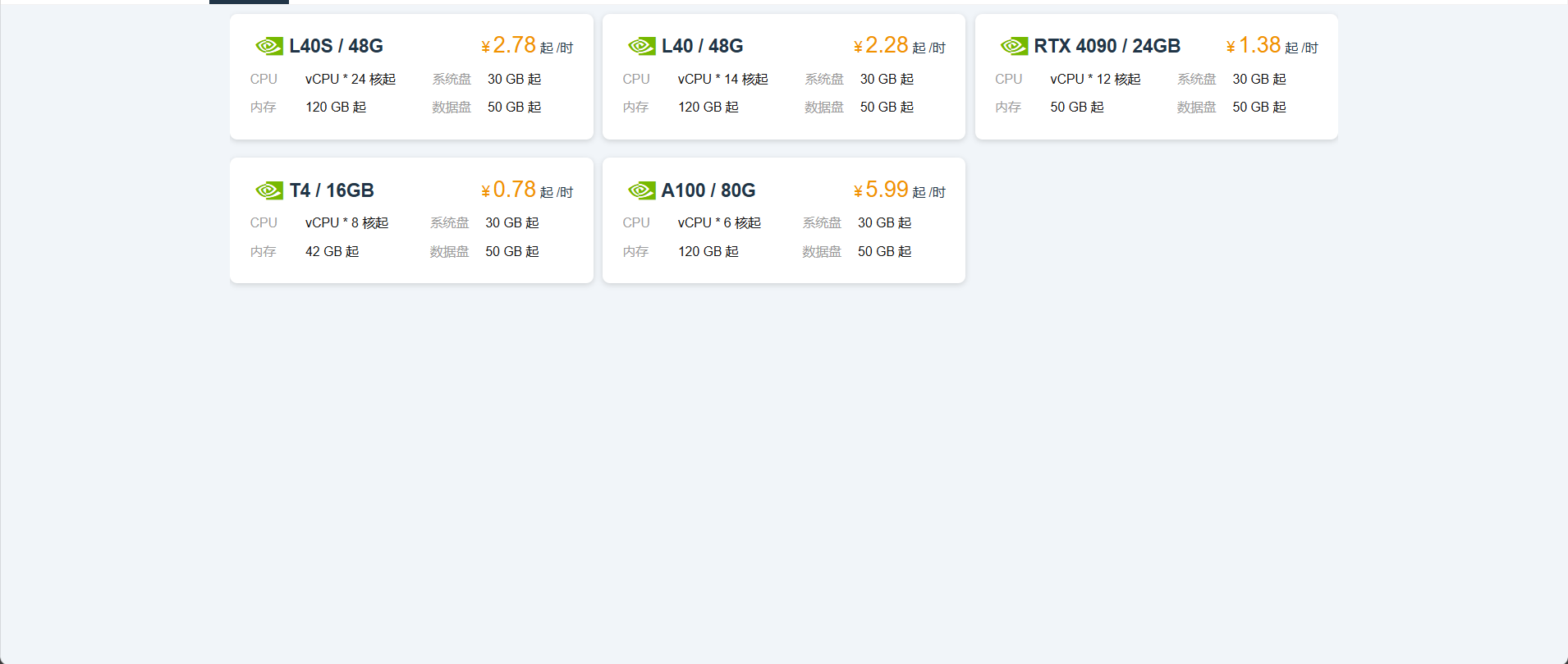
可以参考:

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐

 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)