从零构建高性能通用内存池:Aurorae HostMemPool 设计与实现
从零构建高性能通用内存池:Aurorae HostMemPool 设计与实现
本文介绍 Aurorae 深度学习框架第一代主机端内存池的设计与实现,涵盖三层分级缓存架构、核心数据结构、分配/释放流程,以及与 glibc malloc、mimalloc 的实测对比数据。
一、背景:为深度学习框架量身打造内存池
Aurorae 是我们自研的深度学习框架。在框架的运行时中,算子的内存分配/释放极其频繁——一次前向推理可能产生成千上万次临时张量的申请与归还,训练循环更是如此。通用的系统分配器(glibc malloc)在这种场景下暴露出三个致命问题:
- 锁竞争:glibc ptmalloc2 在多线程下使用全局 arena 锁,框架的多流并行执行会严重串行化
- 碎片化:不同大小的张量反复分配释放,产生大量无法复用的内存空洞,GPU 侧已通过显存池解决,但主机侧长期缺位
- 延迟不确定:系统调用路径长,耗时不稳定,无法满足推理场景的低延迟需求
- 重点: 自研的内存池完全透明可控,可以更精准地优化整体架构,从而更好地服务于训练和推理场景。
为此,我为 Aurorae 设计了第一代主机端内存池——HostMemPool V1。设计目标很明确:让绝大多数分配/释放在线程内部无锁完成,只在必要时才触碰全局资源,同时保持与框架算子分配模式的深度适配。
二、架构概览
HostMemPool 采用三层分级缓存架构: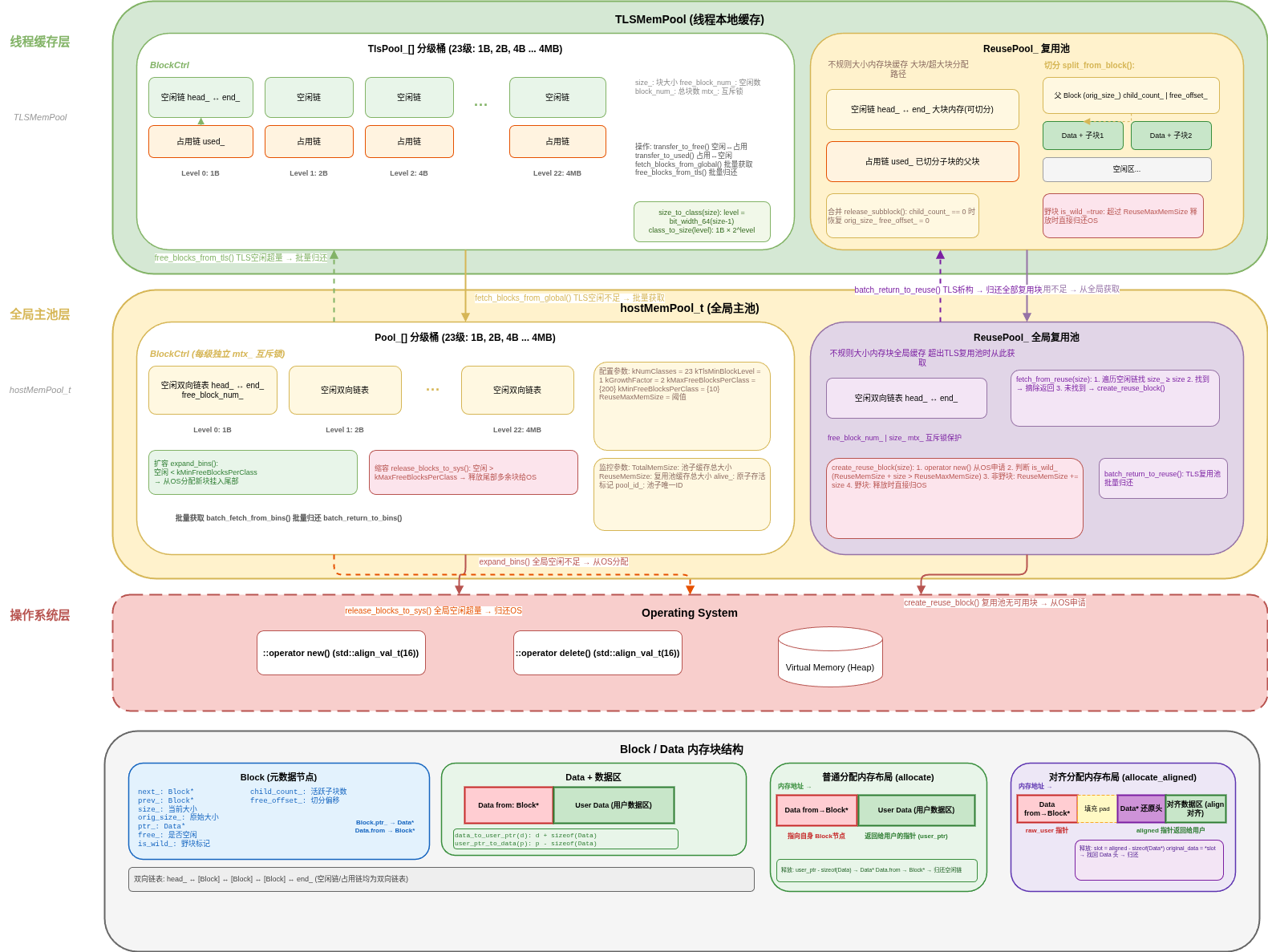
各层职责概览:
三层各司其职:
| 层级 | 职责 | 锁策略 |
|---|---|---|
| TLS 缓存层 | 线程内快路径分配/释放,命中率最高 | 无锁 |
| 全局桶层 | 跨线程共享资源池,按需批量转移 | 每级独立 mutex |
| 操作系统层 | 兜底分配与野块回收 | 无锁(系统调用) |
分流策略
请求到达后,按大小选择路径:
- ≤ 128MB(Level 0~27):走 TLS 分级桶 → 全局分级桶 → OS 扩容
- > 128MB:走 TLS 复用池 → 全局复用池 → OS 分配,复用池内通过切分/合并管理
三、核心数据结构
3.1 Data —— 数据头部
struct Data {
Block *from; // 反向指针,指向所属的 Block 元数据节点
};
每个分配出去的内存块,前方紧贴一个 Data 头部。用户拿到的指针在 Data 之后。from 指针是释放时定位归属 Block 的唯一途径——无需查表,O(1) 反查。
3.2 Block —— 内存块元数据节点
struct Block {
Block *next_ = nullptr; // 双向链表后继
Block *prev_ = nullptr; // 双向链表前驱
size_t size_ = 0; // 当前可用大小(切分后可能缩小)
size_t orig_size_ = 0; // 切分前的原始大小(合并时恢复)
Data *ptr_ = nullptr; // 指向数据区起始地址
bool is_wild_ = false; // 是否为野块(释放时直接归还 OS)
bool free_ = true; // 是否在空闲链
// 切分/合并相关
size_t child_count_ = 0; // 活跃子块数(>0 表示处于切分状态)
size_t free_offset_ = 0; // 下次可切分的起始偏移
};
为什么 Block 与数据区分离?
Block 是元数据节点(普通 new),ptr_ 指向数据区(::operator new + 16 字节对齐)。分离的好处:
- 链表操作(摘取、插入、转移)不触碰数据区,缓存友好
- 切分/合并只修改元数据字段,数据区零拷贝
- 数据区可以按对齐要求独立分配,不受 Block 布局干扰
3.3 BlockCtrl —— 桶控制器
struct BlockCtrl {
Block *head_ = nullptr; // 空闲链表头
Block *end_ = nullptr; // 空闲链表尾
Block *used_ = nullptr; // 占用链表头(头插法单链)
size_t size_ = 0; // 该级别的标准块大小
size_t free_block_num_ = 0; // 空闲块数量
size_t block_num_ = 0; // 总块数
std::unique_ptr<std::mutex> mtx_; // 该级别的独立锁
};
每个 BlockCtrl 管理一个"桶",维护空闲双向链表(头尾指针,支持 O(1) 头尾摘取)和占用单向链表(头插法,用于追踪已分配块)。
全局主池 28 个级别各有一个 BlockCtrl,全局复用池也有一个。TLS 池同理。
四、分级策略
4.1 等级划分
28 个等级(可自定义配置),2 倍增长:
| 等级 | 块大小 | 等级 | 块大小 | 等级 | 块大小 | 等级 | 块大小 |
|---|---|---|---|---|---|---|---|
| 0 | 1 B | 7 | 128 B | 14 | 16 KB | 21 | 2 MB |
| 1 | 2 B | 8 | 256 B | 15 | 32 KB | 22 | 4 MB |
| 2 | 4 B | 9 | 512 B | 16 | 64 KB | 23 | 8 MB |
| 3 | 8 B | 10 | 1 KB | 17 | 128 KB | 24 | 16 MB |
| 4 | 16 B | 11 | 2 KB | 18 | 256 KB | 25 | 32 MB |
| 5 | 32 B | 12 | 4 KB | 19 | 512 KB | 26 | 64 MB |
| 6 | 64 B | 13 | 8 KB | 20 | 1 MB | 27 | 128 MB |
映射函数只需一条位运算:
int size_to_class(size_t size) noexcept {
if (size <= 1) return 0;
return bit_width_64(size - 1); // ⌈log₂(size)⌉
}
例如:请求 100 字节 → bit_width_64(99) = 7 → Level 7(128 字节块)。
4.2 为什么选择 2 倍增长
- 映射 O(1):位运算直接完成,无需二分查表
- 碎片可控:最坏内部碎片率 50%,与 tcmalloc 等工业级分配器一致
- 等级紧凑:28 级覆盖 1B ~ 128MB,绝大多数分配命中低级别,缓存局部性好
相比更精细的分级(如 tcmalloc 的 ~88 级),2 倍增长牺牲了一些内部碎片率,换来的是代码简洁和映射速度。
五、普通分配与释放
5.1 内存布局

Data头部大小 =sizeof(Block*)(64 位平台 8 字节)- 用户指针 =
(char*)Data + sizeof(Data) - 释放时:
user_ptr - sizeof(Data)→ 还原Data*→Data.from→ 找到 Block
5.2 分配流程
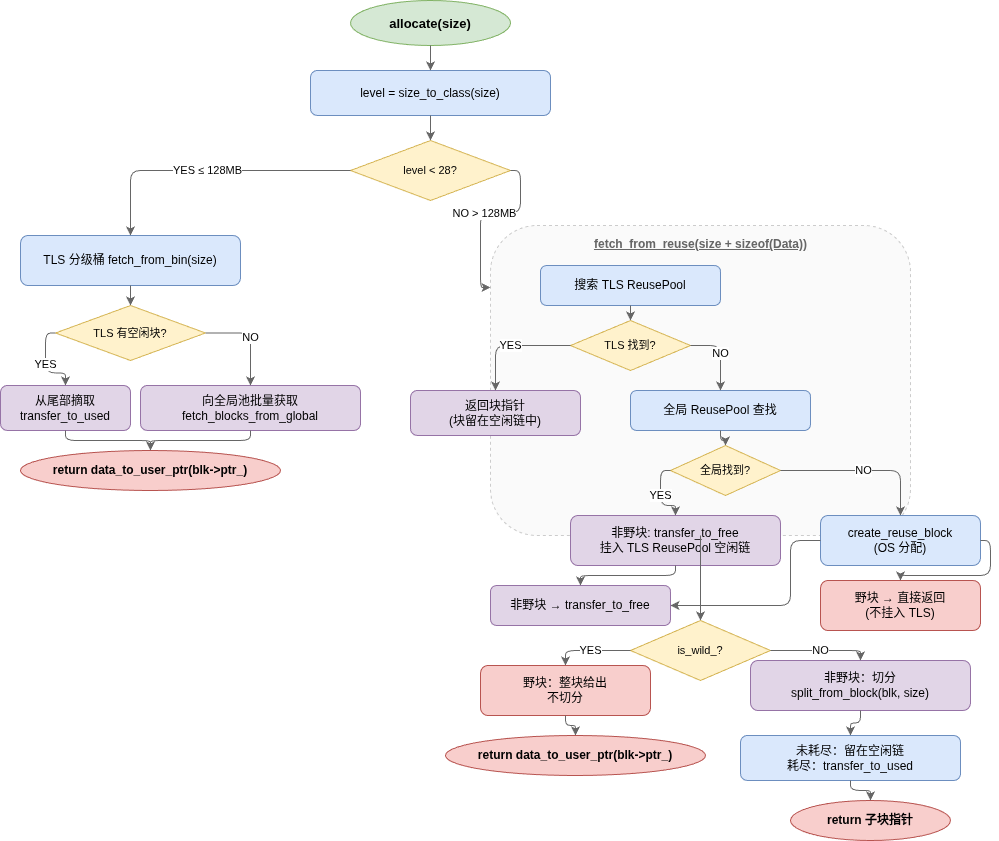
5.3 释放流程
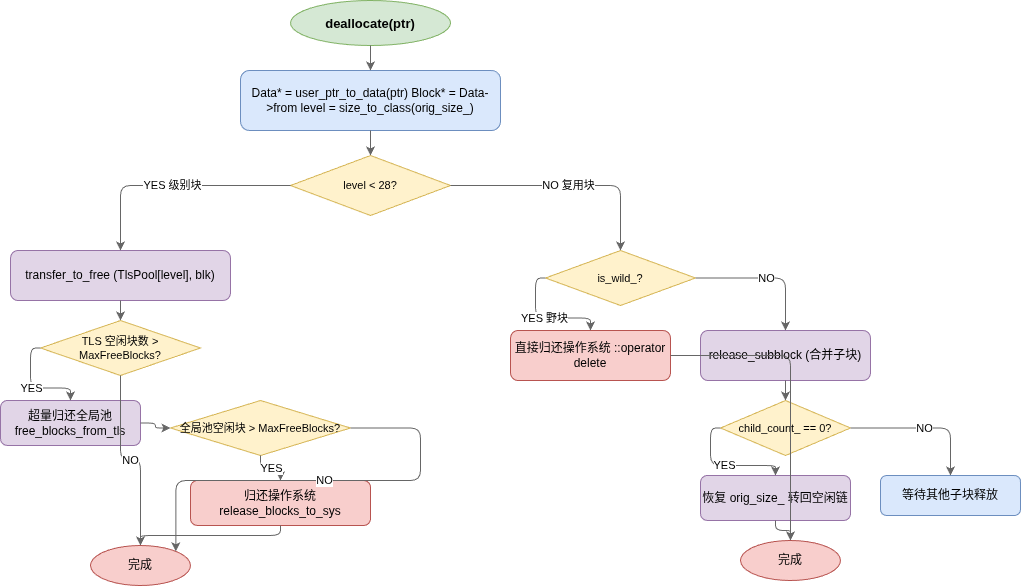
5.4 两级溢出回收
内存不会无限膨胀——两级溢出检测确保空闲时逐步归还 OS:
- TLS → 全局:TLS 某级空闲块超过
kTlsMaxFreeBlocksPerClass(默认 6),超量部分批量归还全局池 - 全局 → OS:全局池某级空闲块超过
kMaxFreeBlocksPerClass(默认 200),超量部分::operator delete归还操作系统
这种"逐级回收"的设计,让内存占用始终保持在合理水位。
六、对齐分配
对齐分配在普通分配基础上,利用填充区域实现对齐,同时在数据区前方埋入还原头,使释放时能反查原始块。
6.1 内存布局
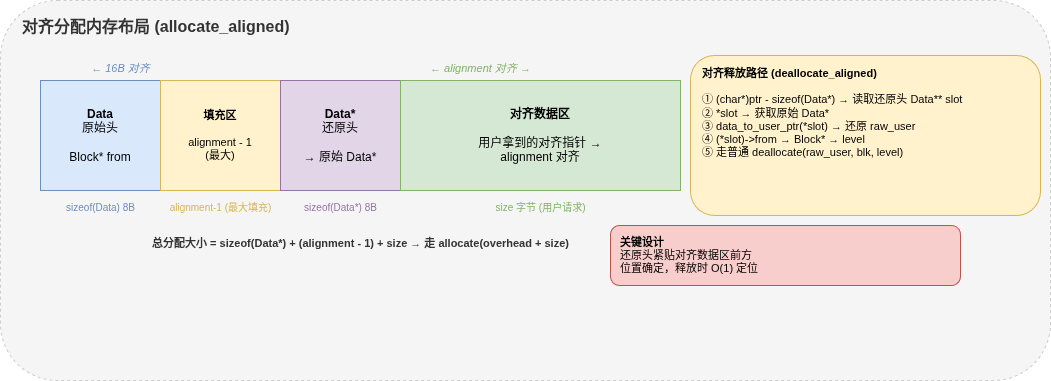
6.2 对齐分配流程
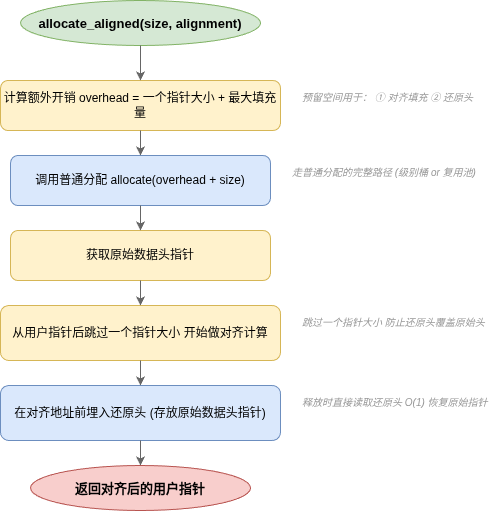
6.3 实现要点
void* allocate_aligned(size_t size, size_t alignment) {
// 1. 计算额外开销
const size_t overhead = sizeof(Data*) + (alignment - 1);
// 2. 走普通分配
void *raw_user = allocate(overhead + size);
// 3. 获取原始 Data 头
Data* original_data = user_ptr_to_data(raw_user);
// 4. 从 raw_user + sizeof(Data*) 起做对齐
// (保证还原头不覆盖原始 Data)
uintptr_t addr = raw_user + sizeof(Data*);
uintptr_t aligned = (addr + alignment - 1) & ~(alignment - 1);
// 5. 在对齐地址前埋入还原头
Data** slot = (Data**)(aligned - sizeof(Data*));
*slot = original_data;
return (void*)aligned;
}
释放时,从对齐指针前 sizeof(Data*) 处读取还原头,恢复原始 Data*,再走普通释放路径。
为什么还原头放在对齐地址前面而不是原始 Data 后面? 因为原始 Data 到对齐地址之间的填充量不确定,如果把还原头放在 Data 紧后面,可能被对齐地址覆盖。把还原头紧贴对齐数据区前方,位置确定,查找 O(1)。
七、复用池:大块切分与合并
复用池专为大块和不规则大小的内存分配设计。核心机制是父块切分 → 子块合并。
7.1 切分
分配时不消耗整块,而是从父块的空闲偏移处逐次切分子块: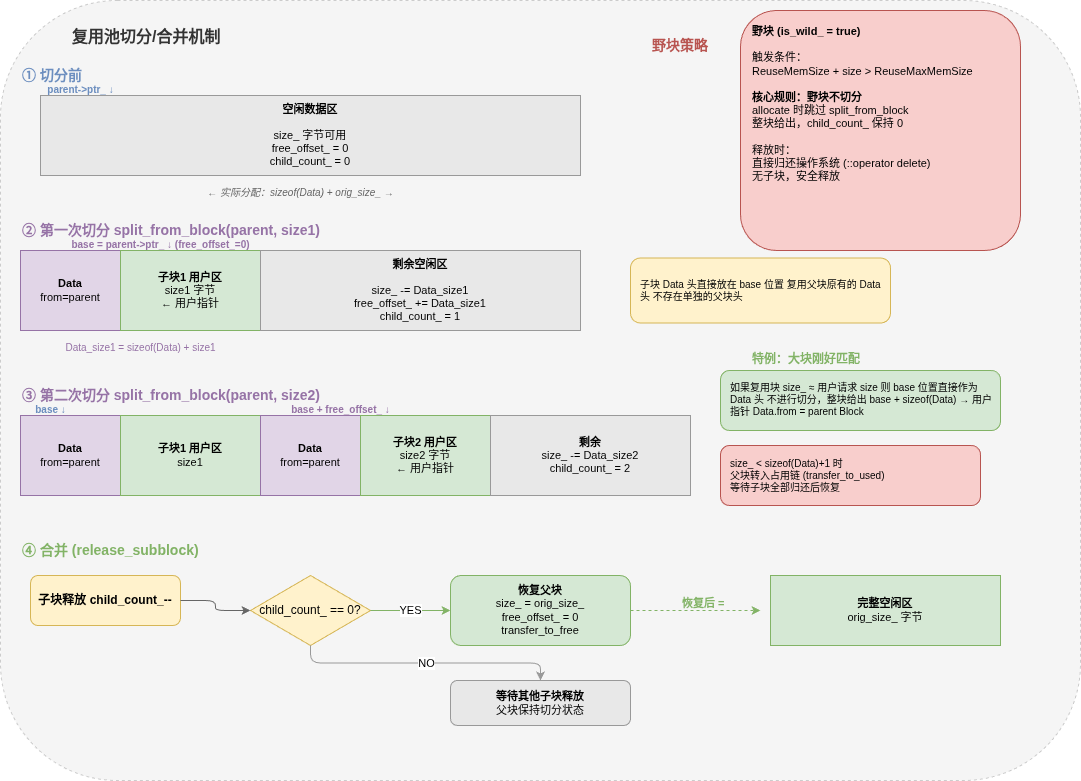
每次切分:child_count_++,free_offset_ 递增,size_ 递减。当 size_ 小于最小可切分大小(sizeof(Data) + 1)时,父块转入占用链,等待子块全部归还。
野块策略主要用于: 控制超大内存/复用内存块缓存量在阈值内
7.2 合并
子块释放时 child_count_--。所有子块归零后,父块恢复原始大小:
void release_subblock(Block *parent) {
parent->child_count_--;
//当子块归零时合并
if(parent->child_count_ == 0){
//恢复初始参数
parent->size_ = parent->orig_size_;
parent->free_offset_ = 0;
//如果在占用链
if(!parent->free_)
transfer_to_free(ReusePool_,parent); //转移到空闲链
}
}
7.3 野块策略
当复用池缓存总量超过 ReuseMaxMemSize 阈值时,新分配的块被标记为野块(is_wild_ = true)。野块释放时直接归还操作系统,不缓存——这是防止复用池无限膨胀的安全阀。
八、线程安全设计
8.1 TLS 无锁快路径
每个线程通过 thread_local 持有独立的 TLSMemPool,线程内的分配和释放完全无锁:
TLSMemPool& hostMemPool_t::get_tls() {
auto& slots = tls_slots(); // thread_local 容器
if (!slots[pool_id_]) {
slots[pool_id_] = std::make_unique<TLSMemPool>(this, alive_);
}
return *slots[pool_id_];
}
这是性能的核心——绝大多数请求在线程内完成,根本不触碰任何锁。
8.2 全局池细粒度锁
全局主池的每个级别桶拥有独立 mutex。不同级别的操作互不阻塞:
- 线程 A 操作 Level 3 全局桶,线程 B 操作 Level 7 全局桶 → 并行
- 同一级别并发操作串行化 → 但粒度足够细,竞争极低
8.3 生命周期安全
全局主池析构时,通过 alive_ 原子标记通知所有 TLS 实例:
hostMemPool_t::~hostMemPool_t() {
alive_->store(false, std::memory_order_release);
// 释放资源...
}
TLSMemPool::~TLSMemPool() {
if (global_pool_alive_->load(std::memory_order_acquire)) {
total_blocks_from_tls(); // 主池还活着,归还全局
total_block_from_reuse();
} else {
free_block_to_sys(); // 主池已死,直接归还 OS
}
}
alive_ 使用 shared_ptr<atomic<bool>>,确保主池析构后 TLS 不会悬空访问。
九、关键设计决策
为什么用分级桶而不是伙伴系统?
伙伴系统要求块大小严格为 2 的幂且对齐,分裂/合并开销大。分级桶只要求同级别块大小一致,分配时整块给出、释放时整块回收,不需要分裂和合并。代价是最大 50% 内部碎片,但换来了分配路径的极致简洁——摘链、挂链,两步完成。
为什么 TLS 用批量转移而不是逐块交互?
TLS 初始化时从全局池一次性预取多个块(默认 6 块/级),溢出时也批量归还。批量转移的优势:
- 锁摊销:一次加锁转移 N 块,均摊每块的锁开销为 1/N
- 缓存友好:批量操作链表的一段,局部性好
- 减少竞争:全局池的锁持有时间更短、频率更低
为什么 Block 和数据区分离?
非侵入式链表节点设计,Block 与数据区分离存放:
- 链表操作不触碰数据区,不影响用户数据缓存行
- 切分/合并只改 Block 元数据,数据区零拷贝
- 数据区可独立按 16 字节对齐分配,Block 无对齐要求
为什么复用池用切分/合并而不是直接分配?
大块分配如果每次都向 OS 申请,会产生大量碎片。复用池的切分机制让一个大块可以服务多次小请求,合并机制保证子块全部归还后父块恢复完整。这在不引入伙伴系统复杂度的前提下,有效减少了大块场景的系统调用次数。
十、性能评测
10.1 测试环境
| 项目 | 说明 |
|---|---|
| 测试套件 | mimalloc-bench(开源内存分配器基准测试套件) |
| 编译器及模式 | GCC 13,Release 模式 |
| 硬件平台 | AMD Ryzen 7 7435H,16 线程 |
| 对比对象 | aurorae:Aurorae HostMemPool V1 / sys:glibc malloc v2.35 / mi:mimalloc v2.1 |
| Aurorae 配置 | 最小块 1B,TLS 缓存 48 块/级,全局桶上限 200 块/级,扩容步长 16 块,复用池无限缓存,未预热,冷启动 |
10.2 多线程并发场景
| 测试项目 | aurorae (s) | sys (s) | mi (s) | aurorae vs sys | aurorae vs mi |
|---|---|---|---|---|---|
| larsonN | 5.556 | 6.007 | 3.706 | +7.5%(胜) | -49.9% |
| larsonN-sized | 5.914 | 6.013 | 3.697 | +1.6%(胜) | -60.0% |
| alloc-testN | 3.97 | 4.36 | 3.17 | +8.9%(胜) | -25.2% |
| rptestN | 2.515 | 2.675 | 3.051 | +6.0%(胜) | +17.6%(胜) |
| xmalloc-testN | 1.117 | 1.079 | 0.348 | -3.5% | -221% |
| glibc-thread | 8.663 | 7.403 | 4.025 | -17.0% | -115% |
解读:在多线程常规负载(larson 系列、alloc-testN)中,Aurorae 已稳定超越 glibc malloc。larsonN 领先 7.5%,alloc-testN 领先 8.9%,验证了 TLS 无锁缓存与细粒度锁架构的优势。rptestN 中更同时反超 glibc 与 mimalloc,领先 mimalloc 17.6%,说明 TLS 大块缓存机制在该场景极具竞争力。
在 xmalloc-testN 和 glibc-thread 等极端高并发、跨线程随机释放场景下,与 mimalloc 仍有较大差距。瓶颈在于 TLS 与全局桶之间的批量转移路径仍存在锁竞争开销,后续将重点优化。
10.3 单线程与低并发场景
| 测试项目 | aurorae (s) | sys (s) | mi (s) | aurorae vs sys | aurorae vs mi |
|---|---|---|---|---|---|
| alloc-test1 | 3.08 | 3.11 | 2.52 | +1.0%(胜) | -22.2% |
| cfrac | 3.57 | 3.40 | 3.14 | -5.0% | -13.7% |
| espresso | 3.81 | 3.79 | 3.32 | -0.5% | -14.8% |
| barnes | 2.54 | 2.54 | 2.50 | 0.0% | -1.6% |
| cache-scratch1 | 0.96 | 0.94 | 0.94 | -2.1% | -2.1% |
| cache-scratchN | 0.13 | 0.13 | 0.13 | 0.0% | 0.0% |
| glibc-simple | 2.36 | 2.22 | 1.82 | -6.3% | -29.7% |
解读:单线程场景中,Aurorae 与 glibc 性能几乎无差距(多数在 5% 以内),alloc-test1、barnes、cache-scratch 完全持平或小幅领先。与 mimalloc 相比存在合理差距,因 mimalloc 在单线程路径中大量使用手工内联和 SIMD 辅助,这是后续内联优化方向。
10.4 内存占用对比(RSS,单位 MB)
| 测试项目 | aurorae | sys | mi |
|---|---|---|---|
| larsonN | 114.2 | 118.6 | 155.5 |
| xmalloc-testN | 80.9 | 69.7 | 111.8 |
| glibc-thread | 6.2 | 3.8 | 68.1 |
| rptestN | 48.1 | 47.4 | 108.0 |
解读:Aurorae 内存占用与 glibc 基本持平或略高,远低于 mimalloc。分级桶 + 复用池的设计比 mimalloc 的预占式大块缓存更节省内存,glibc-thread 场景下 RSS 仅 6.2 MB,体现了良好的内存效率。
10.5 优势与差距总结
优势领域:
- 多线程常规负载反超 glibc,TLS 无锁缓存 + 细粒度锁架构得到充分验证
rptestN测试同时压制 glibc 和 mimalloc,凸显大块缓存机制的优势- 内存效率与 glibc 相当,显著优于 mimalloc
- 单线程性能与 glibc 基本持平
待提升领域:
- 极端高并发随机释放场景与 mimalloc 仍存在 2~3 倍差距,需优化批量转移路径
- 单线程密集分配存在微小的常数开销,可通过进一步内联与快速路径优化
十一、后续优化方向
基于最新测试数据,优化路线如下:
11.1 在下一代版本中,将彻底丢弃锁结构
11.2 优化切分机制
- 降低内部碎片
11.3 优化复用块查询,争取达到O(1)分配
11.4 持续迭代优化代码,修复已知BUG
- 修复BUG
- 优化整体代码性能
十二、源码地址
- Aurorae 内存池: https://gitee.com/skymist/aurorae-hostmempool.git
- mimalloc-bench测试: https://gitee.com/skymist/aurorae-mimalloc-bench.git
十三、总结
HostMemPool V1 作为 Aurorae 深度学习框架的第一代主机端内存池,始终遵循快路径优先的设计原则。针对深度学习算子分配频率高、大小集中、多流并行的特点,构建了三层分级缓存架构:TLS 无锁快路径解决频率问题,28 级 2 倍增长桶覆盖大小分布,细粒度独立锁适配并行执行。
实测数据验证了架构有效性:多线程常规负载已稳定超越 glibc malloc,部分场景反超 mimalloc;内存效率与 glibc 持平,远低于 mimalloc。极端高并发场景与 mimalloc 的差距,将是下一阶段批量转移优化的重要突破口。在简洁架构与性能之间,HostMemPool V1 找到了实用的平衡点,后续将持续演进,逐步缩小与顶级分配器的差距。
本报告基于 mimalloc-bench 标准套件全量测试结果,所有数据均在同一机器、相同编译模式下采集。

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐

 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)