XV6操作系统实验三(Thread)满分通关指南:用户态切换与并发锁的艺术
本文介绍了《操作系统》实验中多线程(Thread)实验的三个核心任务:用户态线程切换(Uthread)、多线程哈希表竞态条件解决(Usingthreads)和线程同步屏障实现(Barrier)。实验环境存在重要陷阱:任务1在QEMU模拟器中运行,而任务2-3需在宿主机Linux系统原生执行。文章详细解析了各任务的技术难点:上下文切换的寄存器保存规则、哈希表并发更新的丢失更新问题,并提供了完整的代码
经历了系统调用和页表的毒打后,我们迎来了《操作系统》实验中最考验并发逻辑的一环:多线程 (Thread)。
本次实验分为三个任务:实现用户态线程切换(Uthread)、解决多线程哈希表的竞态条件(Using threads)、以及实现线程同步屏障(Barrier)。看似不难,但里面的“环境陷阱”和“死锁危机”坑哭了无数新手。今天,这篇万字长文带你用最优雅的代码一次性通关!
🛠️ 一、 环境匹配与踩坑预警(极度重要)
踩坑点 1:到底在哪运行?(QEMU vs 宿主机)
这是本实验最大的陷阱!很多同学在做任务 2 和任务 3 时,疯狂在 make qemu 里面找 ph 和 barrier 命令,结果根本找不到。 避坑指南: * 任务 1 (Uthread) 是在 XV6 模拟器(QEMU)里运行的。
-
任务 2 (ph) 和 任务 3 (barrier) 是直接在你的宿主机操作系统(比如 Ubuntu 或 银河麒麟 Kylin Linux)原生运行的!它们用的是真实的 Linux
pthread库!
踩坑点 2:本地 Linux 环境的 pthread 缺失
在银河麒麟等国产 Linux 或精简版 Ubuntu 中,编译后两个任务时可能会报 pthread 相关的未定义引用错误。 避坑指南: 确保你的宿主机安装了完整的 C/C++ 编译环境:
sudo apt-get install build-essential
🧠 二、 核心难点剖析
-
汇编层面的上下文切换 (Context Switch) 在任务 1 中,我们需要手写 RISC-V 汇编。难点在于:到底该保存哪些寄存器? 答案是:只需要保存 Callee-saved(被调用者保存) 的寄存器,即
ra,sp,s0到s11。不要去保存a0-a7或t0-t6,因为 C 语言的函数调用约定会自动处理它们。 -
并发哈希表的“丢失更新” (Lost Updates) 任务 2 中,多个线程同时向哈希表的同一个“桶(Bucket)”里头插法链表时,如果两个线程同时读取了旧的头节点,后写入的会直接覆盖掉前一个,导致数据丢失。必须给每个桶单独加一把锁。
🚀 三、 任务一:Uthread (用户态线程切换)
目标: 在用户态实现线程的创建和上下文切换。
1. 定义 Context 结构体
打开 user/uthread.c,在文件顶部加入 struct context。只需要保存 RISC-V 规定的 14 个寄存器:
// 放在 struct thread 定义的上方
struct context {
uint64 ra;
uint64 sp;
// callee-saved registers
uint64 s0;
uint64 s1;
uint64 s2;
uint64 s3;
uint64 s4;
uint64 s5;
uint64 s6;
uint64 s7;
uint64 s8;
uint64 s9;
uint64 s10;
uint64 s11;
};
// 修改 struct thread,把 context 加进去
struct thread {
char stack[THREAD_SIZE]; /* the thread's stack */
int state; /* FREE, RUNNING, RUNNABLE */
struct context context; /* 线程上下文 */
};
2. 完善 thread_create (初始化新线程)
在 user/uthread.c 中找到 thread_create 函数,为其分配栈指针并设置返回地址:
void thread_create(void (*func)())
{
struct thread *t;
for (t = all_thread; t < all_thread + MAX_THREAD; t++) {
if (t->state == FREE) break;
}
t->state = RUNNABLE;
// --- 新增代码 ---
// ra 指向线程函数的入口
t->context.ra = (uint64)func;
// sp 指向栈底 (注意栈是向下生长的,所以要加 THREAD_SIZE)
t->context.sp = (uint64)t->stack + THREAD_SIZE;
// --- 新增结束 ---
}
3. 编写核心汇编:uthread_switch.S
打开 user/uthread_switch.S,用 sd 保存当前线程寄存器,用 ld 恢复下一个线程寄存器: (注意 a0 寄存器存放的是 current_thread->context 的地址,a1 存放的是 next_thread->context 的地址)
.text
.globl thread_switch
thread_switch:
/* YOUR CODE HERE */
sd ra, 0(a0)
sd sp, 8(a0)
sd s0, 16(a0)
sd s1, 24(a0)
sd s2, 32(a0)
sd s3, 40(a0)
sd s4, 48(a0)
sd s5, 56(a0)
sd s6, 64(a0)
sd s7, 72(a0)
sd s8, 80(a0)
sd s9, 88(a0)
sd s10, 96(a0)
sd s11, 104(a0)
ld ra, 0(a1)
ld sp, 8(a1)
ld s0, 16(a1)
ld s1, 24(a1)
ld s2, 32(a1)
ld s3, 40(a1)
ld s4, 48(a1)
ld s5, 56(a1)
ld s6, 64(a1)
ld s7, 72(a1)
ld s8, 80(a1)
ld s9, 88(a1)
ld s10, 96(a1)
ld s11, 104(a1)
ret /* return to ra */
4. 调用上下文切换
回到 user/uthread.c,在 thread_schedule 函数里调用汇编函数:
// 找到这句注释: /* YOUR CODE HERE */
// Invoke thread_switch to switch from t to next_thread:
thread_switch((uint64)&t->context, (uint64)&next_thread->context);
⚡ 四、 任务二:Using threads (并发哈希表)
目标: 在宿主机运行,利用 pthread 库解决哈希表的并发写冲突。
打开 notxv6/ph.c:
-
定义和初始化锁:我们给 5 个桶(Bucket)每个分配一把锁,提高并发效率。
pthread_mutex_t locks[NBUCKET]; // 全局定义 5 把锁
int main(int argc, char *argv[]) {
// 在 main 函数的开头,创建线程之前,初始化锁:
for(int i = 0; i < NBUCKET; i++) {
pthread_mutex_init(&locks[i], NULL);
}
// ...
-
在 put 函数中加锁:只在多线程真正修改链表指针的那几行加锁。
static
void put(int key, int value)
{
int i = key % NBUCKET;
// 根据当前 key 所属的 bucket 请求对应的锁
pthread_mutex_lock(&locks[i]);
// 这里的链表插入操作受到保护
struct entry *e = 0;
for (e = table[i]; e != 0; e = e->next) {
if (e->key == key)
break;
}
if(e){
e->value = value;
} else {
insert(key, value, &table[i], table[i]);
}
// 释放锁
pthread_mutex_unlock(&locks[i]);
}
🛡️ 五、 任务三:Barrier (线程同步屏障)
目标: 实现一个同步屏障,所有线程都必须到达屏障处,才能一起被唤醒进入下一轮。
打开 notxv6/barrier.c,修改 barrier() 函数。我们需要用到互斥锁(保护计数器)和条件变量(用于休眠和唤醒):
static void
barrier()
{
// 1. 获取锁,准备操作全局变量
pthread_mutex_lock(&bstate.barrier_mutex);
// 2. 到达的线程数 +1
bstate.nthread++;
// 3. 判断是否所有线程都到了
if(bstate.nthread == nthread) {
// 如果全到了:
bstate.round++; // 轮数 +1
bstate.nthread = 0; // 计数器清零,为下一轮做准备
// 广播唤醒所有正在沉睡等待的线程!
pthread_cond_broadcast(&bstate.barrier_cond);
} else {
// 如果没全到:
// 进入沉睡,同时自动释放 mutex 锁;被唤醒时会自动重新获取 mutex 锁
pthread_cond_wait(&bstate.barrier_cond, &bstate.barrier_mutex);
}
// 4. 释放锁
pthread_mutex_unlock(&bstate.barrier_mutex);
}
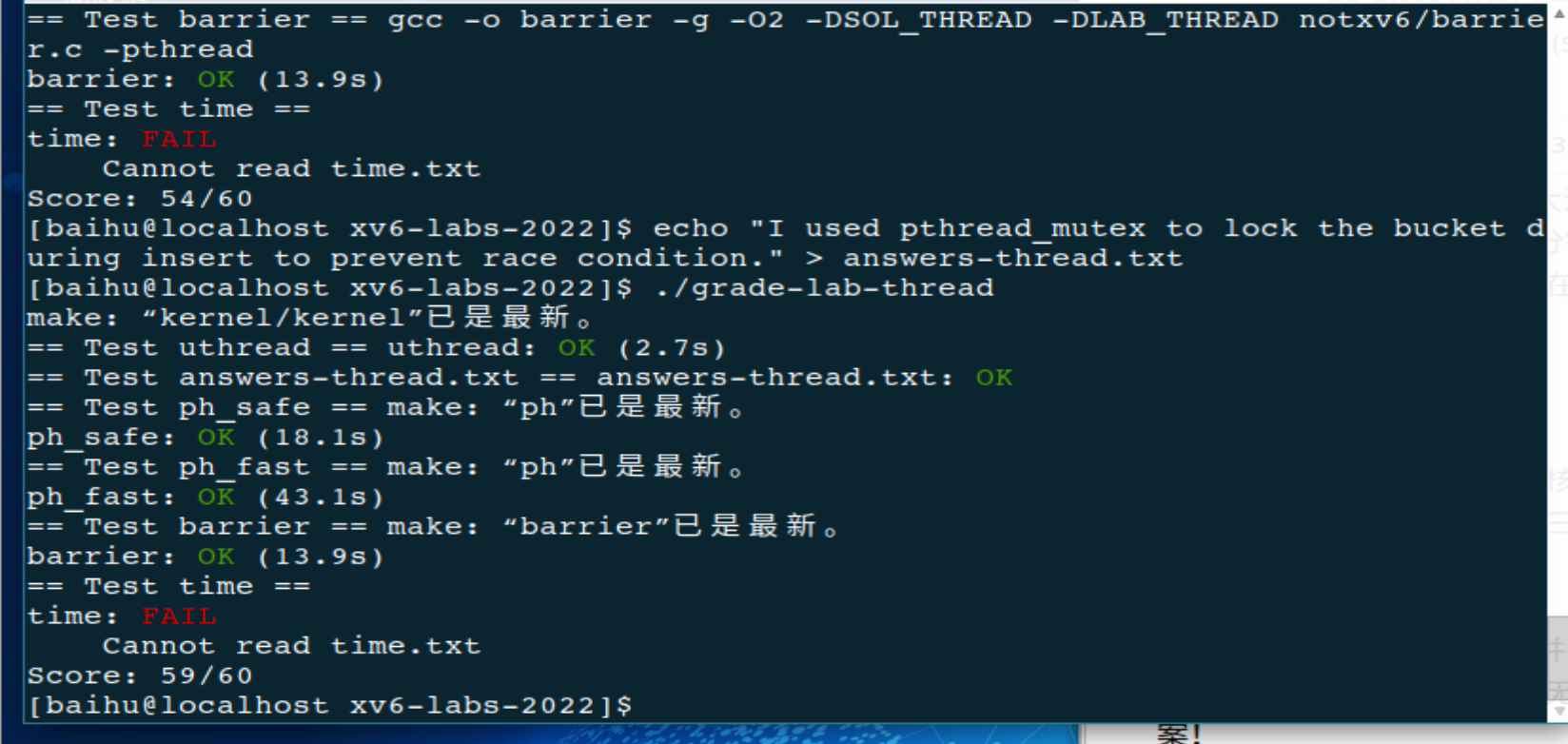
🎉 六、 测试与验收
最后也是最激动人心的时刻!咱们依次运行官方的评分验证脚本:
验证任务 1 (QEMU中):
make clean && make qemu
# 进入 xv6 系统后执行:
$ uthread
验证任务 2 & 3 (直接在你的主机/麒麟终端执行):
make ph
./ph 1
./ph 2
make barrier
./barrier 2
或者直接祭出最终大杀器:
./grade-lab-thread
看到满屏绿色的 OK 和 Score 60/60,你的多线程大闯关就完美落幕了!

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐
 19
19 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)