从一台服务器到亿级流量:普通开发者的架构演进实战
本文通过一个网站从零到亿级用户的发展历程,系统梳理了架构演进的13个关键阶段。每个阶段都围绕"为什么改"、"怎么改"、"解决什么问题"展开,展示了如何通过引入新组件和拆分方式突破性能瓶颈。从单机架构到微服务、容器化、云原生,架构演进本质是用空间换时间、复杂度换性能,始终围绕高性能、高可用、可扩展等核心目标。文章强调没有完美架构,只有适合业
前言
你做了一个小网站,用户从几个到几万,再到几亿。每一次扛不住,都逼着你重构架构。本文用一个故事,带你走完整条演进之路,并回答三个核心问题:为什么改?怎么改?解决了什么?
每个阶段都会先讲演变原因,再展示叠加式架构图,最后总结解决的问题。
每个阶段的演进都是因为遇到了当前架构无法解决的瓶颈,而每次改造都引入新的组件或拆分方式,解决特定的问题。没有一步到位的架构,只有不断演进的设计。
| 阶段 | 演变原因(瓶颈) | 解决方案 | 解决的问题 |
|---|---|---|---|
| 1 单机 | 起步 | 无 | 从0到1 |
| 2 分离 | 资源争抢 | 应用/数据库分开 | 稳定性 |
| 3 集群+LB | 单机处理能力上限 | 多台+负载均衡 | 水平扩展、高可用 |
| 4 缓存 | 数据库 I/O 瓶颈 | 多级缓存 | 查询性能、降低 DB 压力 |
| 5 读写分离 | 写锁阻塞读 | 主从分离 | 读写互不影响 |
| 6 分库分表 | 数据量大 | 垂直+水平拆分 | 存储无限、并发提升 |
| 7 CDN+反向代理 | 访问慢、不安全 | CDN + 反向代理 | 加速、安全 |
| 8 搜索引擎+NoSQL | 复杂查询性能差 | ES + NoSQL | 搜索、灵活存储 |
| 9 分布式 | 巨石应用 | 拆服务+RPC+MQ | 独立部署、解耦、削峰 |
| 10 微服务 | 服务不够细 | 极致拆分+治理 | 弹性、隔离、团队自治 |
| 11 容器化 | 环境不一致 | Docker | 环境一致 |
| 12 容器编排 | 容器管理复杂 | Kubernetes | 自动化运维 |
| 13 云原生 | 底层运维成本高 | 上云+PaaS | 无限弹性、免运维 |
架构三句话:
-
没有最好的架构,只有最适合业务的架构。
-
架构演进的本质:用空间换时间,用复杂度换性能。
-
永远围绕五大目标:高性能、高可用、可伸缩、可扩展、够安全。
希望这篇带有“演变详解”的文章,能帮你真正理解每一个架构决策背后的原因。
第一阶段:单机架构
演变详解
-
为什么演变:这是起点,没有任何历史包袱。只想最快把网站跑起来。
-
怎么演变:在一台服务器上安装 Web 服务器(Apache/Nginx)、应用代码(PHP/Python/Java)和数据库(MySQL)。
-
解决了什么问题:实现了从 0 到 1 的部署,能支撑极低访问量(比如每天几十个 IP)。
架构图
代表技术:LAMP / LNMP。
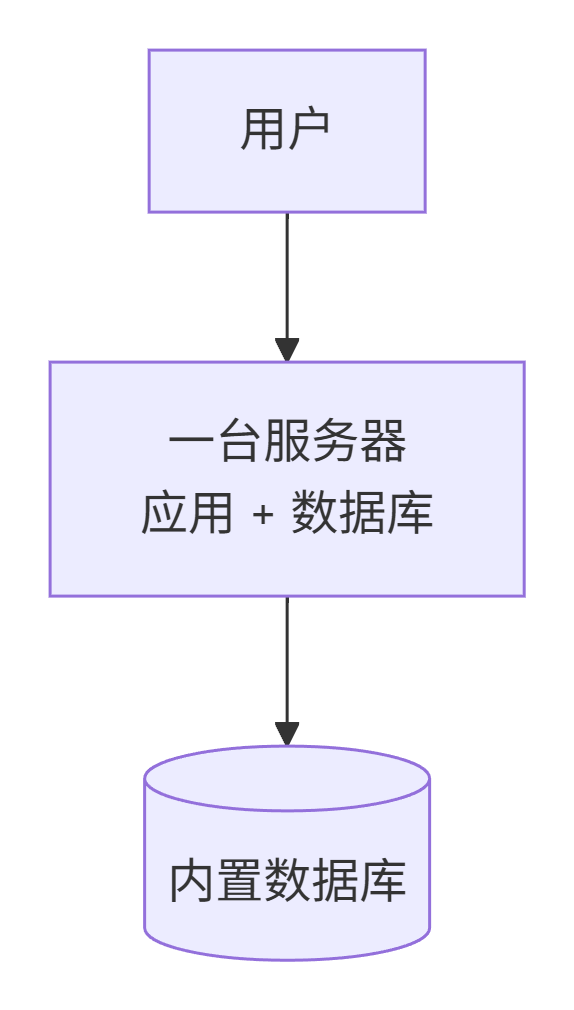
第二阶段:应用与数据库分离
演变详解
-
为什么演变:用户增加到几百,单机 CPU 和内存被应用和数据库互相争抢,响应变慢,甚至宕机。
-
怎么演变:增加一台服务器,将应用和数据库分开部署。应用服务器只管业务逻辑,数据库服务器只管数据存储和 I/O。
-
解决了什么问题:资源隔离,两者不再争抢硬件资源,系统稳定性提升,可各自按需优化。
架构图
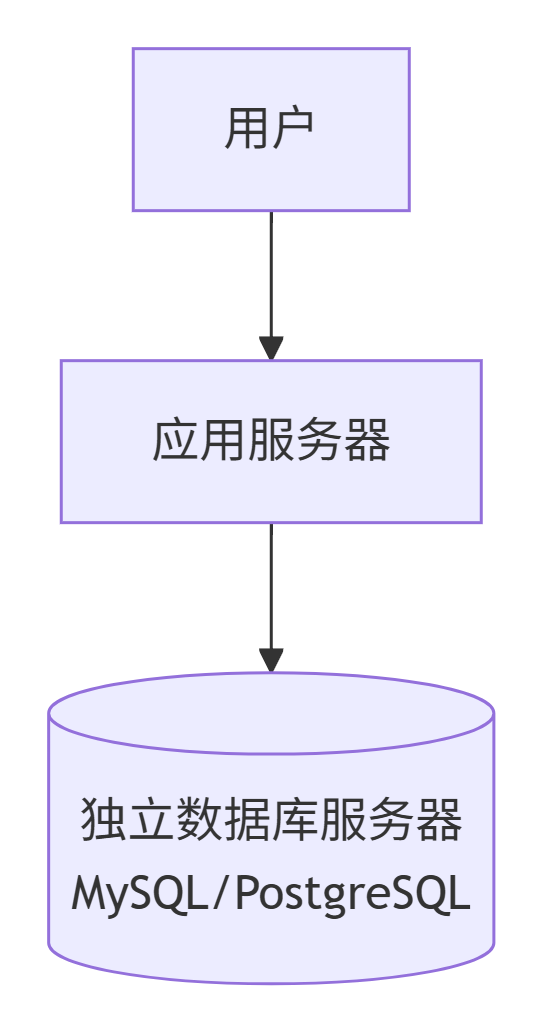
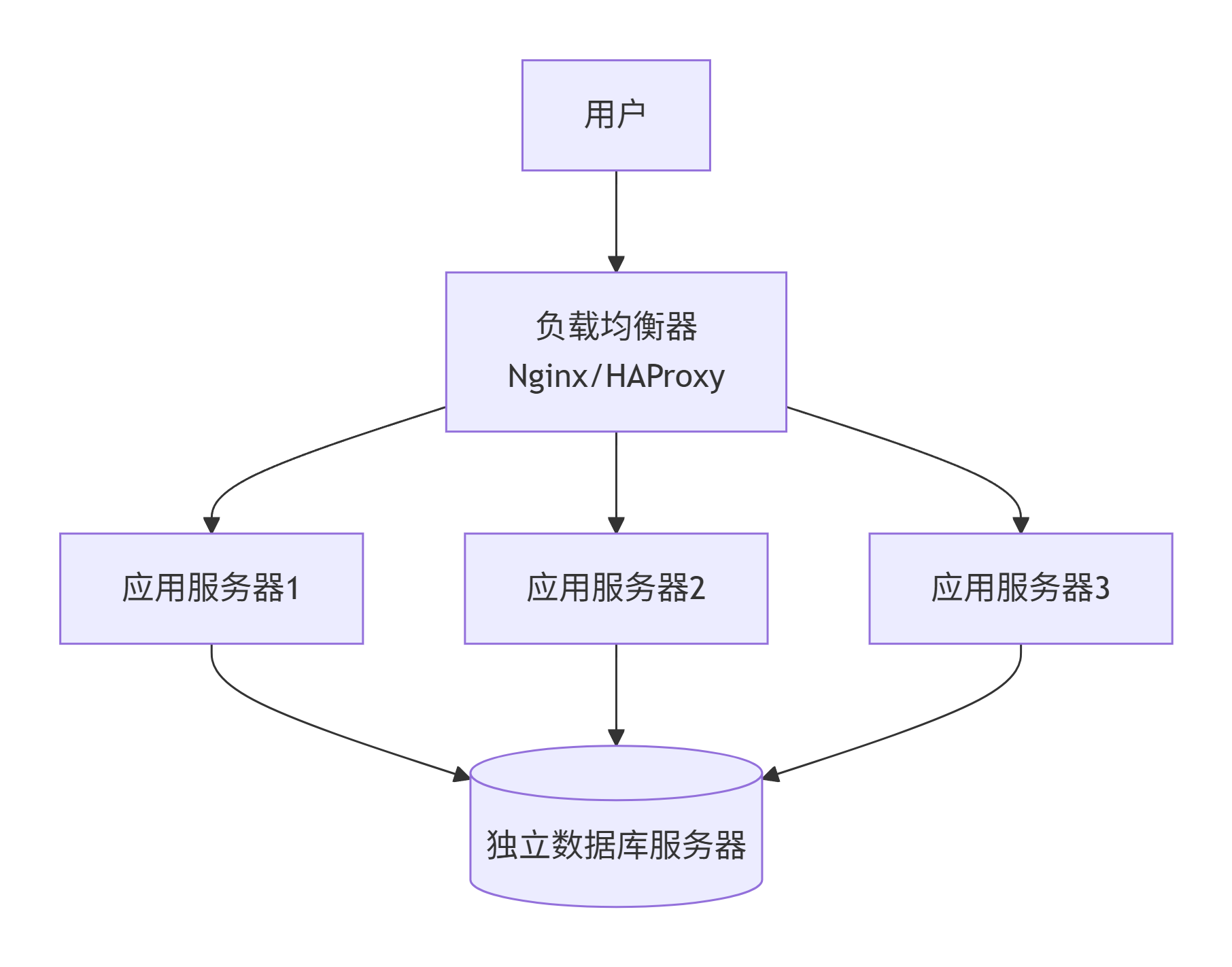
第三阶段:应用集群 + 负载均衡
演变详解
-
为什么演变:用户涨到几千,单台应用服务器 CPU 爆满,请求排队,响应时间飙升。
-
怎么演变:增加多台应用服务器(集群),前面加一个负载均衡器(Nginx/HAProxy),把请求分发给不同服务器。
-
解决了什么问题:
水平扩展:加机器就能扛更高并发。
高可用:一台应用服务器挂了,流量自动切到其他机器,用户无感知。
架构图
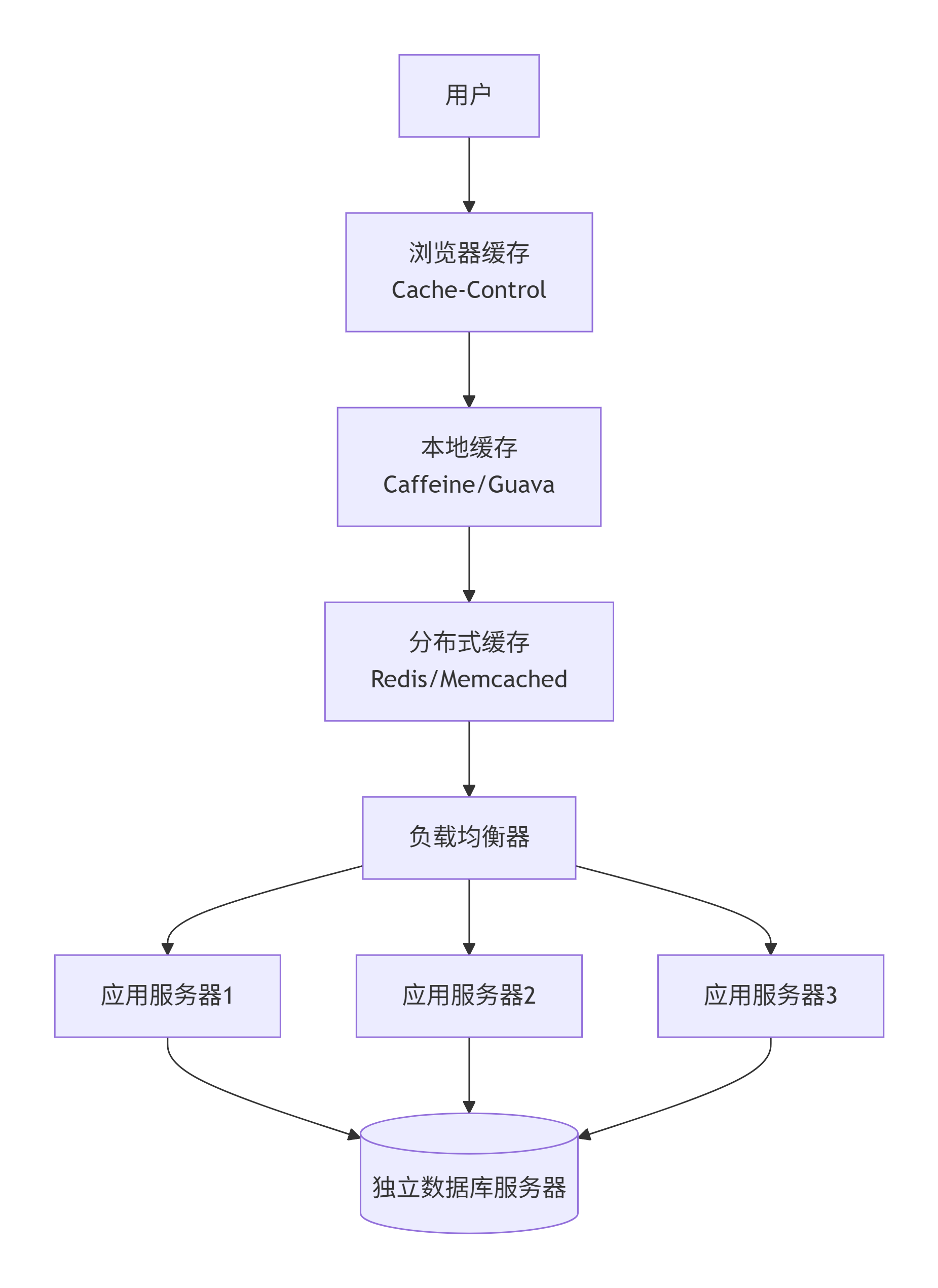
第四阶段:多级缓存
演变详解
-
为什么演变:虽然应用集群扛住了,但大量请求穿透到数据库,数据库连接数爆满,磁盘 I/O 成为新瓶颈。
-
怎么演变:在用户和数据库之间插入三层缓存:
浏览器缓存(静态资源)
本地缓存(应用服务器内存)
分布式缓存(Redis/Memcached)
-
解决了什么问题:
查询速度从毫秒级降到微秒级。
数据库压力减少 80%~90%。
缓存也可以集群,进一步抗高并发。
架构图
第五阶段:读写分离
演变详解
-
为什么演变:缓存挡住了读,但写请求(下单、评论、更新)和少量非热点读仍然直接打数据库。数据库写操作会锁表/锁行,高并发时大量写操作排队,读操作也被阻塞。
-
怎么演变:将数据库拆分为一个主库(负责写)和多个从库(负责读),通过主从复制同步数据。应用层根据操作类型选择主库或从库。
-
解决了什么问题:
读写互不阻塞,写操作不再拖慢读操作。
读性能线性提升(加从库即可)。
从库可分担报表查询等重量级读。
架构图
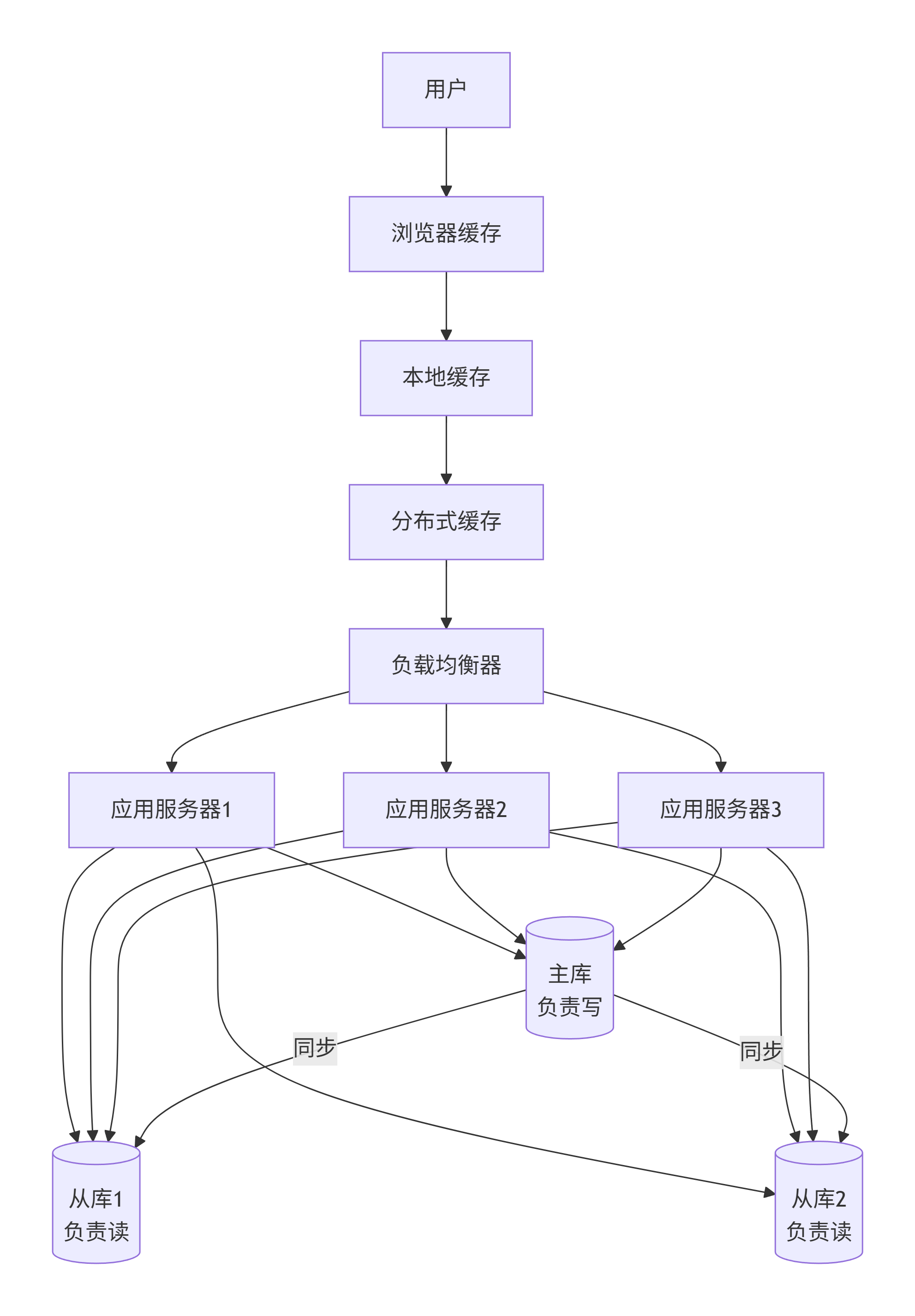
第六阶段:分库分表 + 分布式数据库
演变详解
-
为什么演变:系统运行几年,数据量突破亿级,单表太大(比如订单表几亿行),查询和写入都极慢,单库存储也快满了。
-
怎么演变:
垂直分库:按业务拆成用户库、订单库、商品库。
水平分表:单表拆成多张小表(如按 UID 哈希),通过数据库中间件(ShardingSphere/MyCAT)路由 SQL。
-
解决了什么问题:
突破单机磁盘和 CPU 上限。
查询和写入并行到多个分片,性能大幅提升。
存储容量可以无限扩展(加分片即可)。
架构图
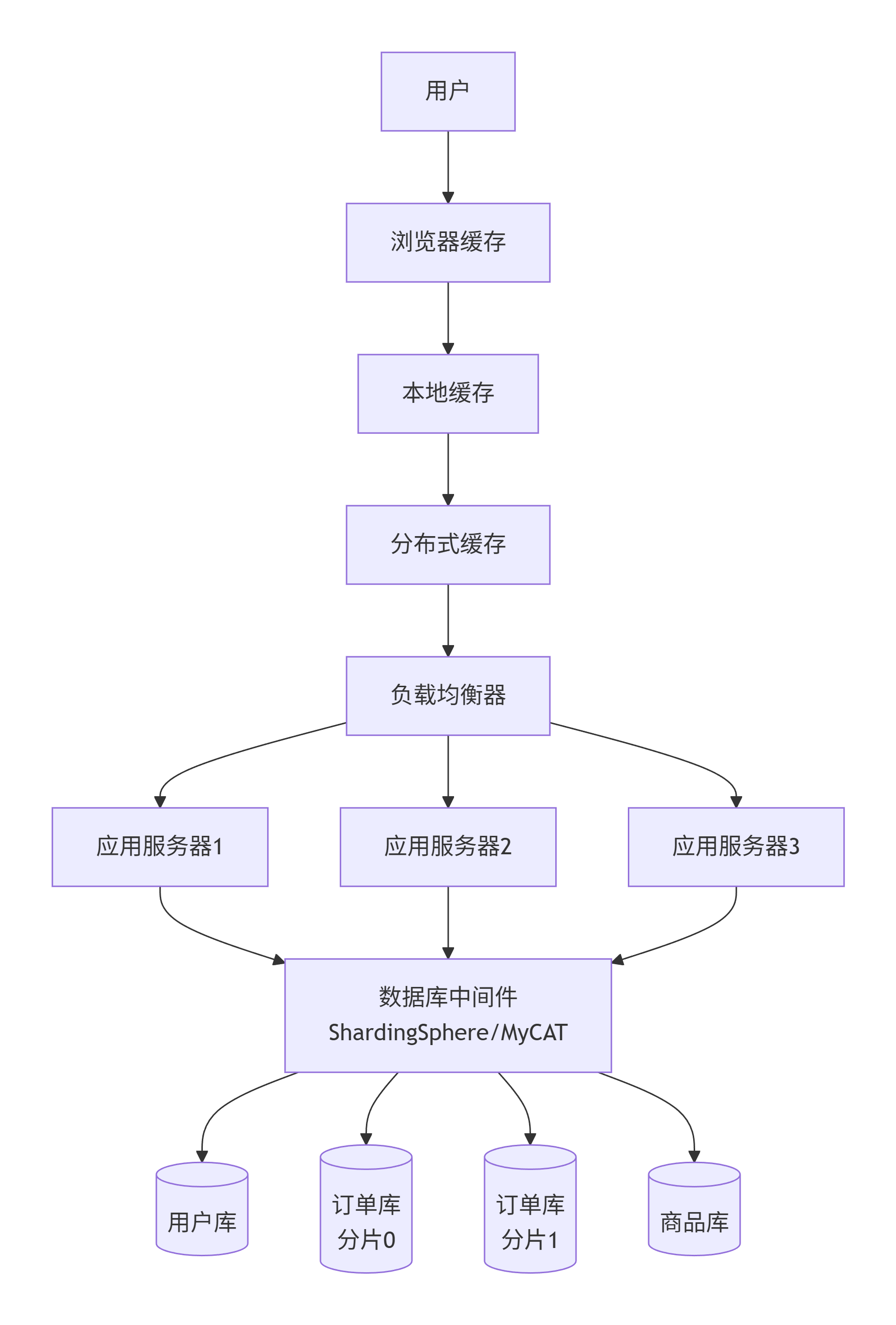
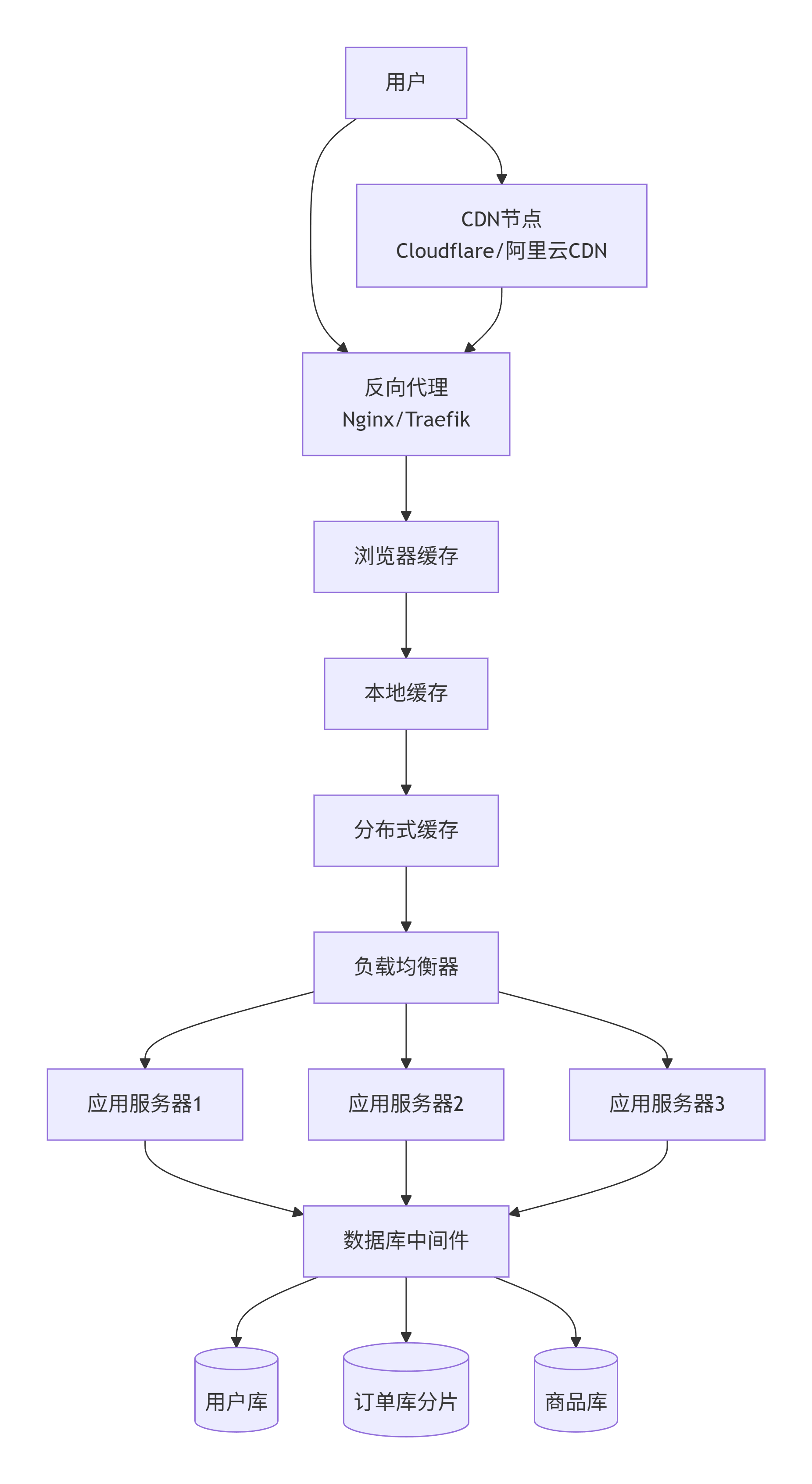
第七阶段:CDN + 反向代理
演变详解
-
为什么演变:
用户遍布全国甚至全球,静态资源(图片、CSS、JS)从中心机房加载慢。
应用服务器直接暴露在公网,容易被 DDoS 攻击或恶意扫描。
-
怎么演变:
引入 CDN:静态资源缓存到全国/全球边缘节点,用户就近访问。
引入反向代理(Nginx/Traefik):挡在应用服务器前面,隐藏真实 IP,做流量清洗和权限校验。
-
解决了什么问题:
访问速度大幅提升(尤其跨地域)。
安全性增强,攻击打到反向代理或 CDN,不伤及后端。
反向代理还可以做 SSL 卸载、压缩、限流。
架构图
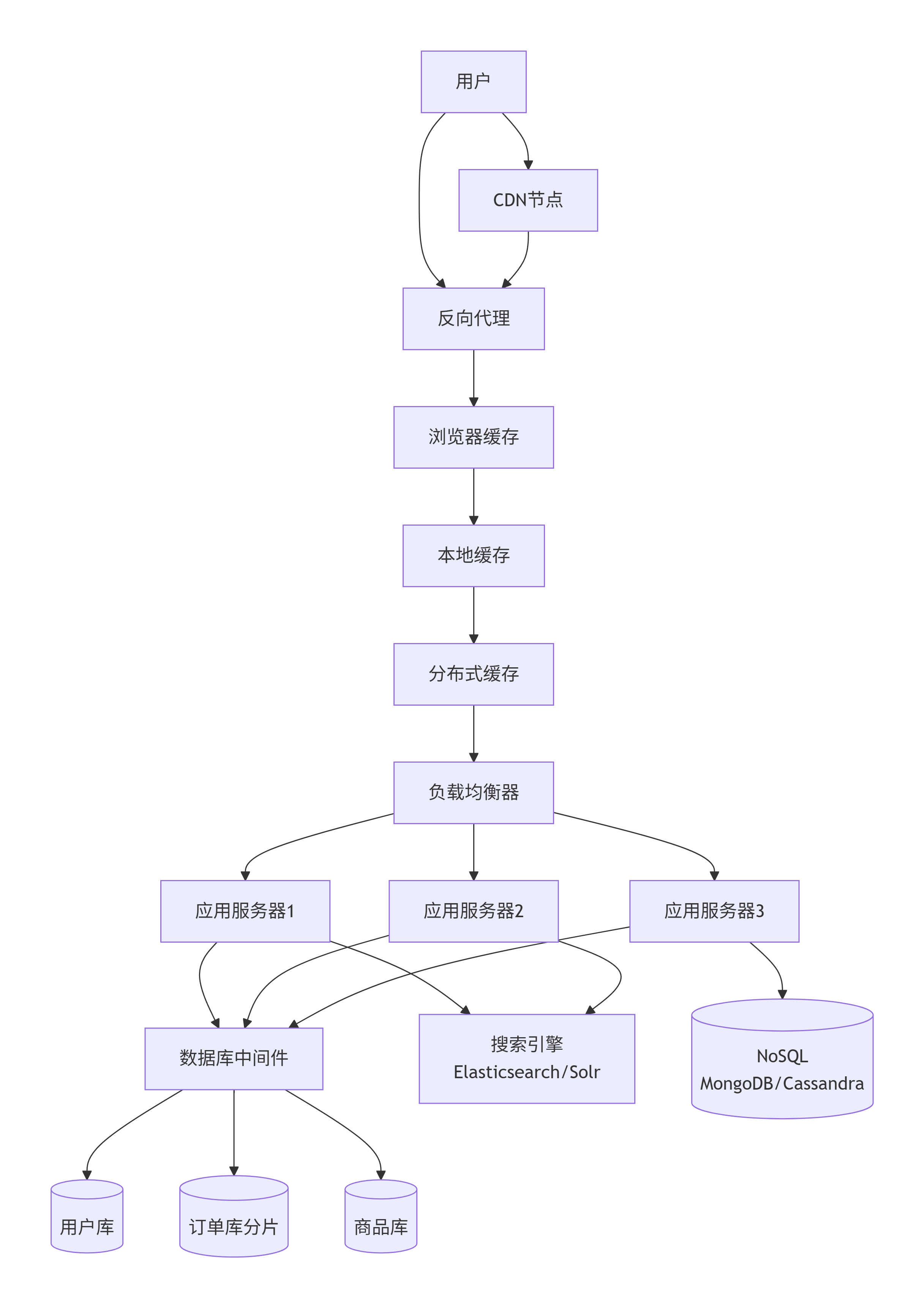
第八阶段:搜索引擎 + NoSQL
演变详解
-
为什么演变:业务需要模糊搜索、全文检索、多维统计,例如电商搜商品、日志分析。传统数据库 LIKE 查询极慢,且无法水平扩展;一些非结构化数据(用户评论、埋点日志)不适合存到关系库。
-
怎么演变:
引入搜索引擎(Elasticsearch/Solr),建立倒排索引,实现毫秒级搜索。
引入 NoSQL(MongoDB/Cassandra),存储半结构/非结构化数据,天然支持高并发和水平扩展。
-
解决了什么问题:
复杂查询能力质的飞跃。
数据模型更灵活。
减轻关系数据库的压力。
架构图
第九阶段:分布式架构 + RPC + 服务注册发现 + 消息队列
演变详解
-
为什么演变:业务越来越大,所有功能挤在一个应用里(巨石应用)。改一行代码要全量发布;多个团队改同一个仓库天天冲突;某个模块(比如订单)需要扩容,却只能把整个应用一起扩容,浪费资源。
-
怎么演变:
按业务边界拆分成多个独立服务(用户、订单、商品等)。
服务之间用 RPC(Dubbo/gRPC)调用。
引入服务注册中心(Nacos/Consul),服务启动时注册,调用方从注册中心发现地址。
引入消息队列(Kafka/RabbitMQ)处理异步场景(如下单后发短信),解耦服务,削峰填谷。
-
解决了什么问题:
独立开发、独立部署、独立扩容。
服务间解耦,一个服务挂了不影响其他(做好降级)。
高并发下消息队列缓冲请求,防止系统被冲垮。
架构图
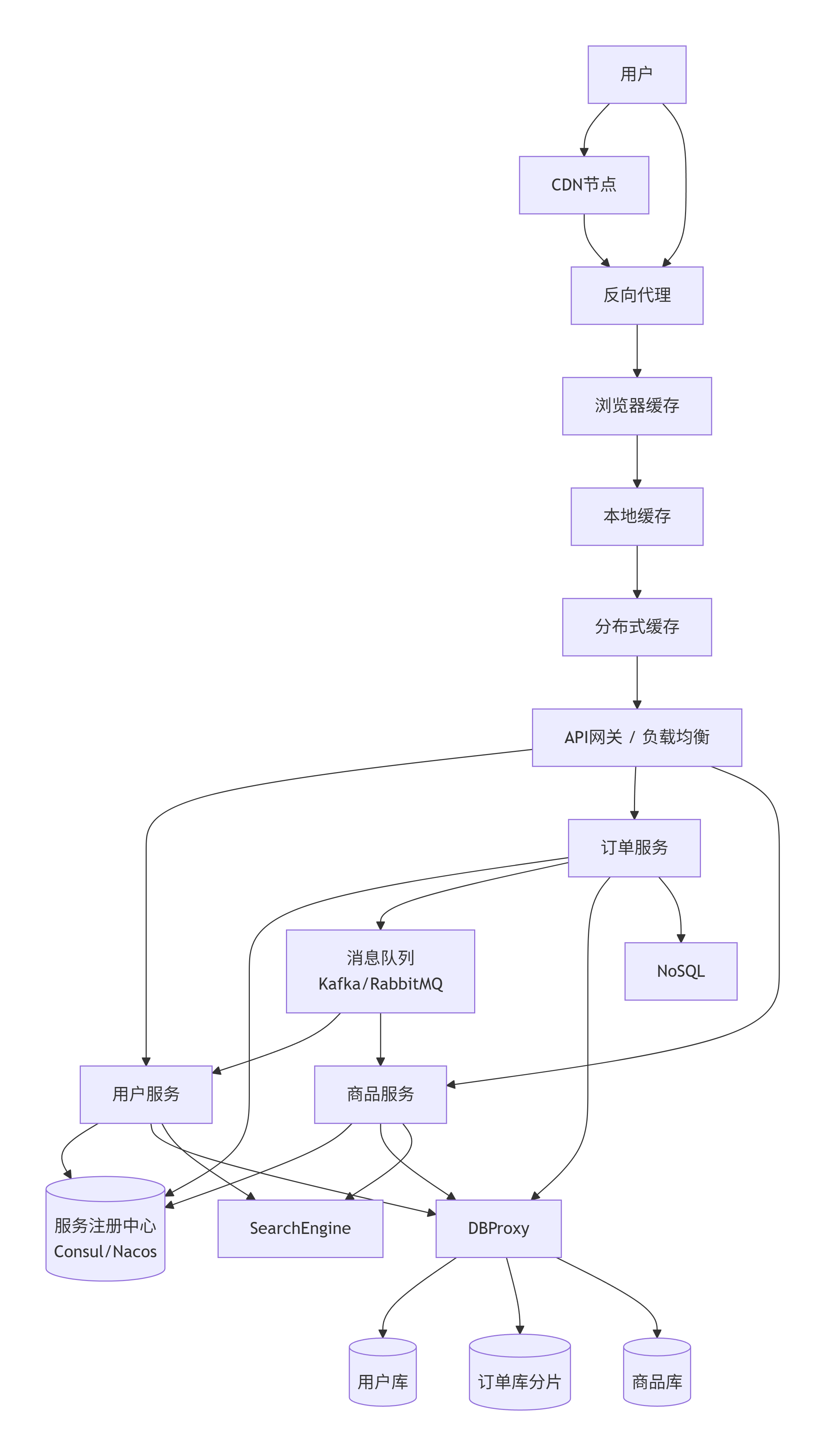
第十阶段:微服务架构
演变详解
-
为什么演变:服务虽然拆了,但像“用户服务”内部仍然包含了登录、会员、地址、积分等,还是很臃肿。不同团队技术栈不同(Java/Go),挤在一个服务里无法独立选型。大促时只希望扩容支付和订单,但被迫扩容整个用户服务。
-
怎么演变:按单一职责继续拆分,每个服务只干一件事(登录、会员、支付、库存等)。并增加服务治理组件:
全链路追踪(SkyWalking/Jaeger):定位跨服务慢调用。
限流/熔断/降级(Sentinel/Hystrix):防止雪崩。
配置中心(Nacos/Apollo):统一管理配置。
-
解决了什么问题:
极致弹性:热门服务单独加机器,冷门服务不动。
故障隔离:一个支付服务挂了,不影响浏览商品。
团队自治:每个小团队负责自己的微服务,技术栈自由。
架构图(微服务集合 + 治理组件)
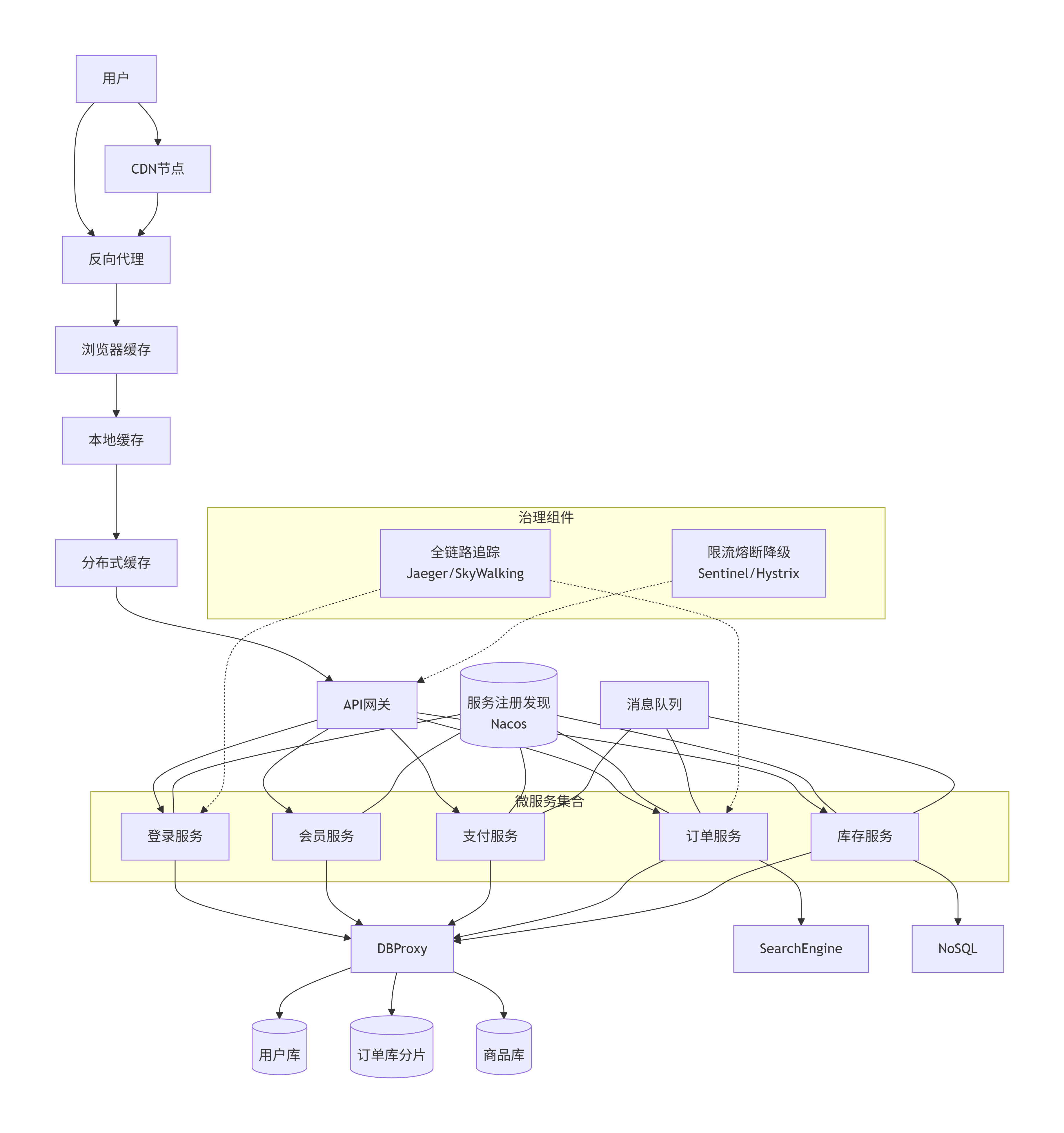
第十一阶段:容器化(Docker)
演变详解
-
为什么演变:微服务数量膨胀到几十上百个,每个服务依赖的环境(JDK 版本、库、配置文件)不一致,经常出现“在我电脑上能跑,测试服务器就崩”的玄学问题。上线要手动配环境,极易出错。
-
怎么演变:把每个微服务及其运行环境打包成 Docker 镜像(代码 + 依赖 + 配置 + 操作系统层)。镜像仓库(Harbor/Docker Hub)统一存储。任意服务器只要装了 Docker,就能跑同样的容器。
-
解决了什么问题:
环境一致性:一次打包,到处运行。
快速部署:镜像拉下来直接启动,无需手动配环境。
为后续容器编排打下基础。
架构图(仅展示关键新增:镜像仓库)
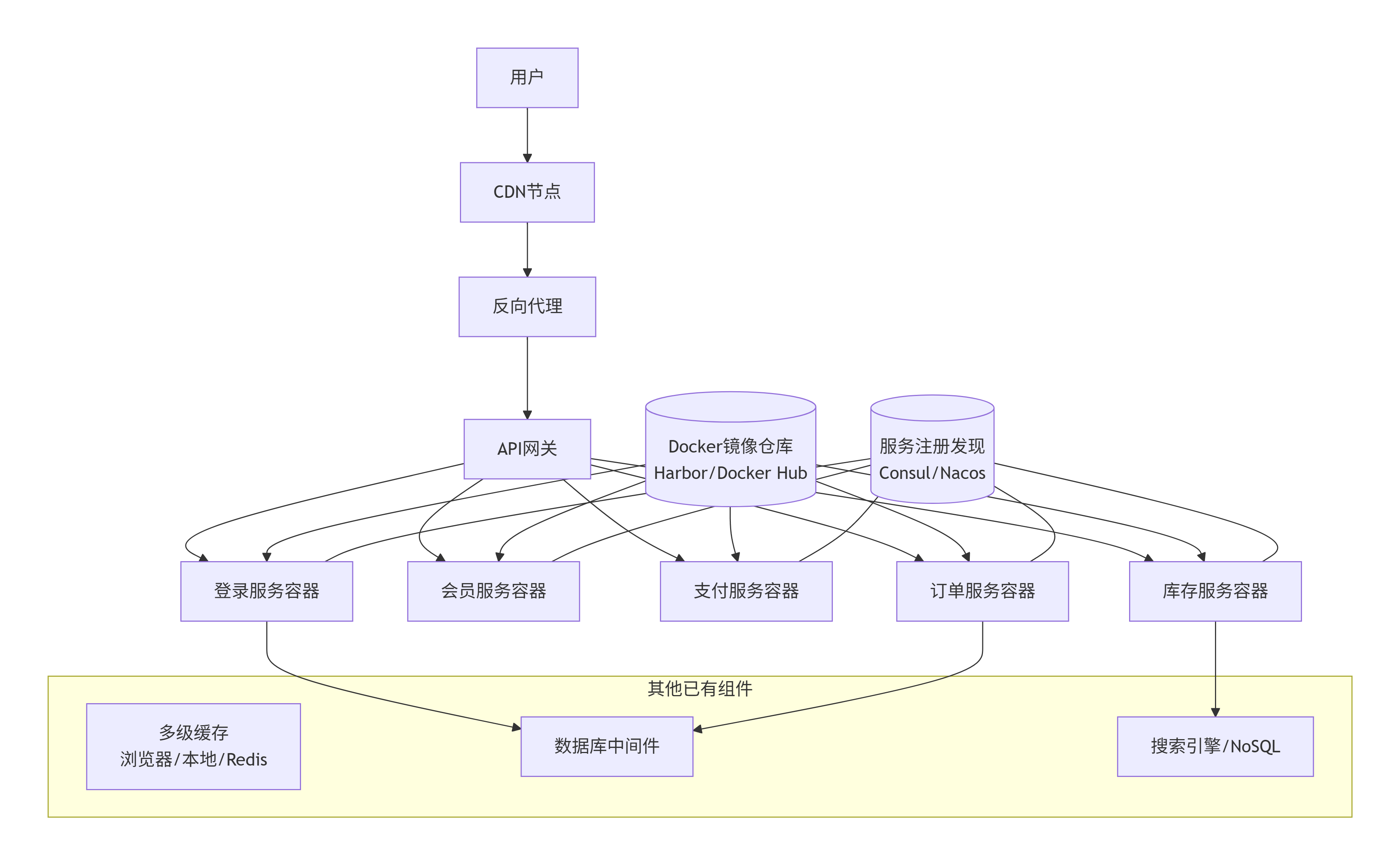
第十二阶段:容器编排(Kubernetes)
演变详解
-
为什么演变:几百个容器手动管理成了噩梦:容器挂了没人自动重启;流量高峰要人工加容器;新版本发布需要滚动更新;资源分配不合理。
-
怎么演变:引入 Kubernetes(K8s),将所有容器纳管为 Pod,通过 Master 节点调度。定义 Deployment、Service、Ingress、HPA(水平自动伸缩)。容器挂了自动重启,流量高了自动加 Pod。
-
解决了什么问题:
自动化运维:自愈、自动扩缩容、滚动升级。
资源利用率提升:多个容器混部在一台机器。
声明式 API:用 YAML 描述期望状态,K8s 负责实现。
架构图
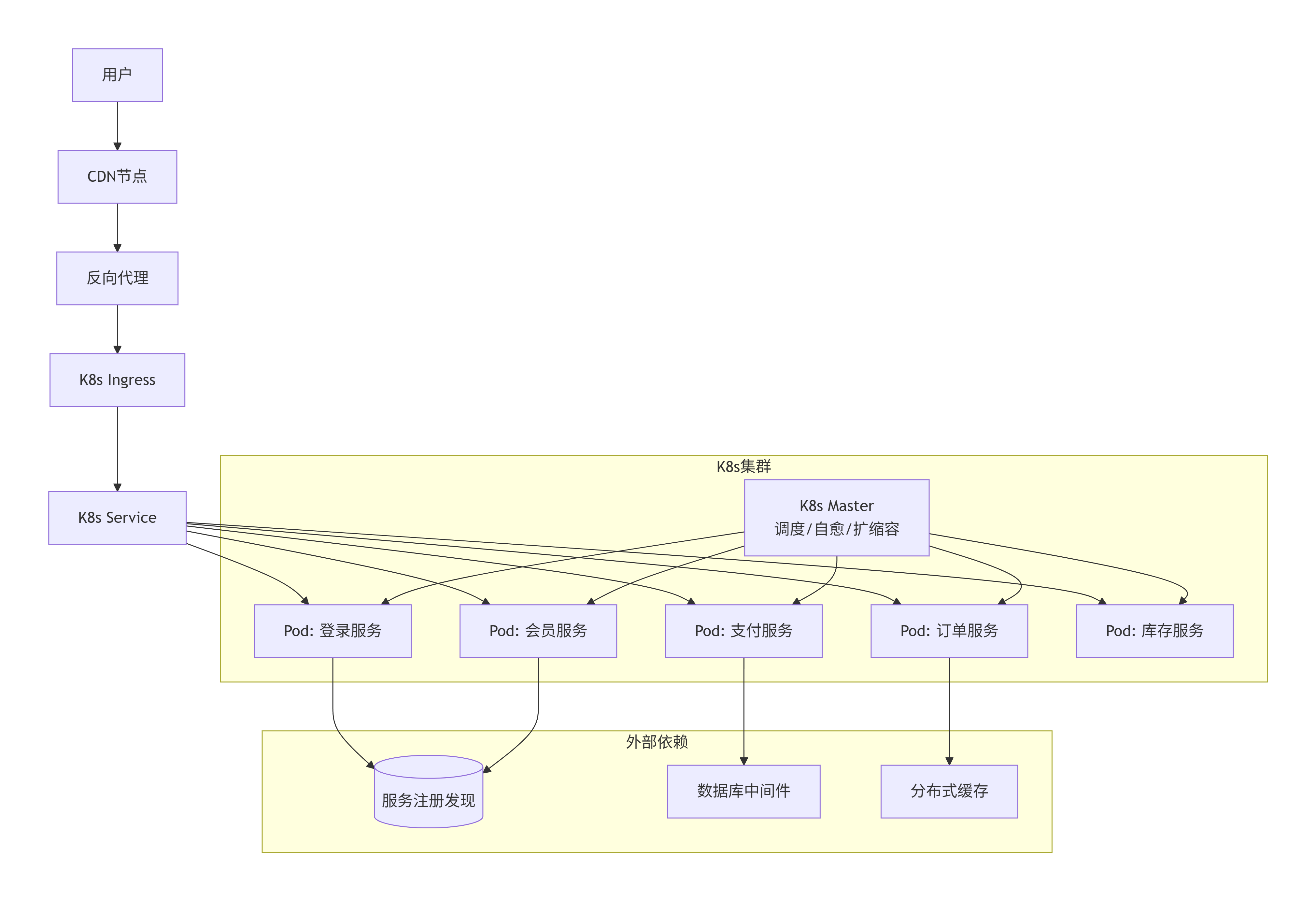
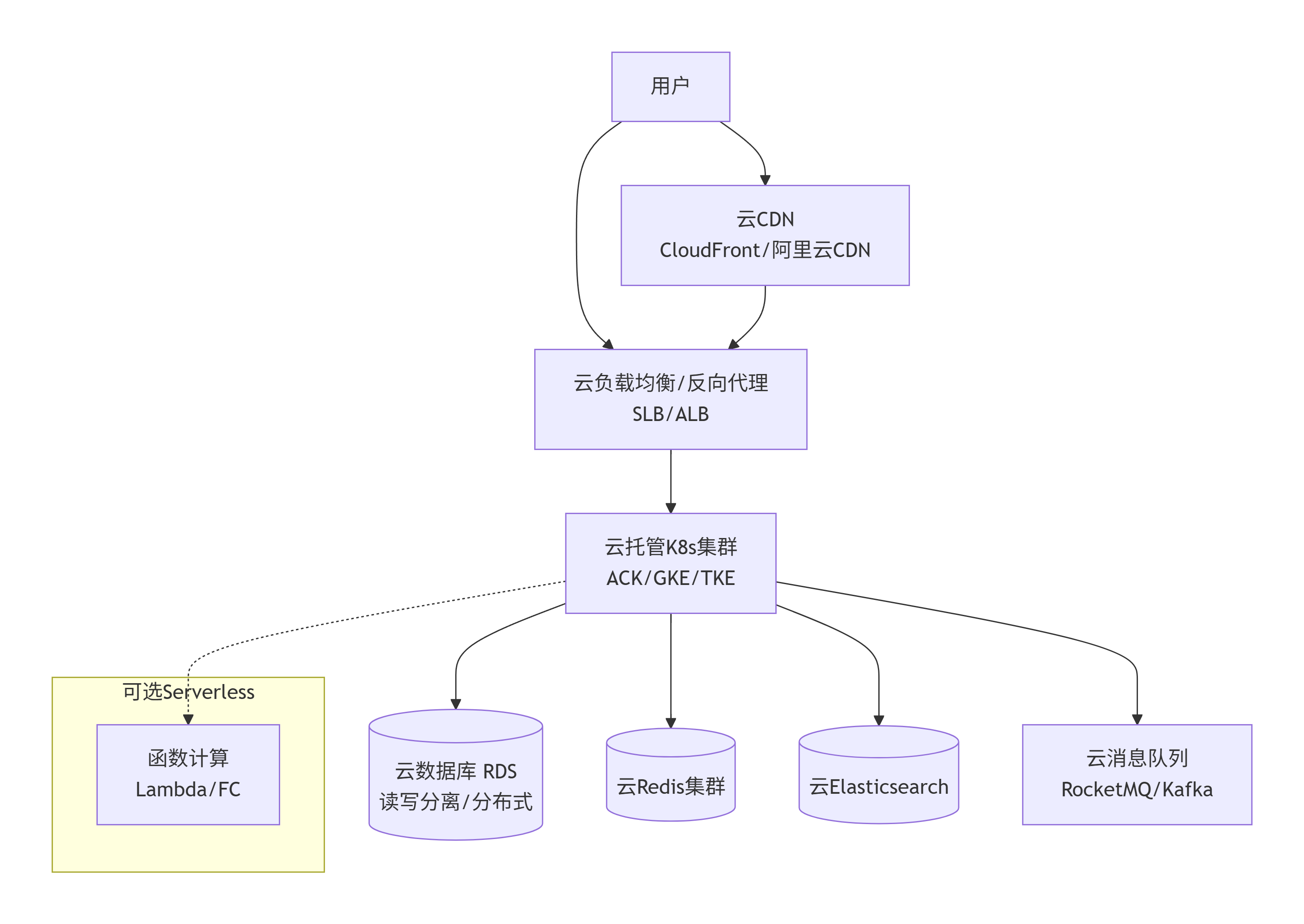
第十三阶段:云原生
演变详解
-
为什么演变:虽然有了 K8s,但底层还得自己买服务器、租机房、搞网络、配硬盘。大促前要提前备很多机器,大促后闲置浪费。运维成本依然很高。
-
怎么演变:把整个系统迁移到公有云(AWS/阿里云/腾讯云)。使用云托管 K8s(ACK/EKS/GKE),云数据库 RDS,云 Redis,云消息队列等 PaaS 服务。甚至部分逻辑用 Serverless(函数计算)。
-
解决了什么问题:
弹性资源:按需使用,按量付费,无限容量。
免运维:云服务负责高可用、备份、扩容。
聚焦业务:底层基础设施透明。
架构图

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐

 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)