气球炸了 —— 服务器内存充足,ES 却被 OOM?
这次不是引发者,而是受害者
说明:文章及图中时间点、内存配置、使用率等具体值存在部分虚构,不影响具体原理及机制学习
一、背景
某天突然收到一个 ES 节点端口挂了,登录服务器查看 /var/log/messages,看到如下报错:
May 6 10:47:31 kernel: kworker/6:0 invoked oom-killer: gfp_mask=0x200d2, order=0
May 6 10:47:31 kernel: Out of memory: Kill process 14955 (java) score 551 or sacrifice child
报错本身很清楚:ES 进程(java,PID 14955)被 Linux 内核 OOM Killer 杀掉了。
环境信息:
VM: 配置 32 GB · 跑在 VMware ESXi 上
ES: JVM heap 17 GB · bootstrap.memory_lock = true
按理说一台 32G 的机器,扣掉 ES 的 17G 堆,应该还有 ~13G 可用,怎么会 OOM?翻看监控,更困惑了,可用内存还有10G,es日常也几乎没有负载,并不像是es本身使用内存过高造成的。
二、定位真凶:日志里的 vmw_balloon
完整的 OOM 调用栈是关键证据,截取核心几行:
kworker/6:0 invoked oom-killer: gfp_mask=0x200d2, order=0
Workqueue: events_freezable vmballoon_work [vmw_balloon] ★★★
Call Trace:
oom_kill_process
out_of_memory
__alloc_pages_nodemask
alloc_pages_current
vmballoon_work+0x3c8/0x63d [vmw_balloon] ★★★
两条加星的行直接锁定了元凶:
- 触发 OOM 的不是 ES 进程,而是内核线程
kworker kworker当时正在执行vmballoon_work—— 这是 VMware 的内存气球驱动vmw_balloon
也就是说:ES 不是自己撑爆的,而是因为 VMware 的 Balloon 驱动在 Guest 内申请内存时,内核没东西可给,只能挑一个最大的进程杀掉献祭,恰好就是 ES。
到这里方向明确了,但要把整件事讲清楚,得先理解 VMware Balloon 是什么。
三、VMware Balloon 是什么
1. 它解决什么问题
虚拟化环境最大的优势之一是内存超分:一台 64GB 的物理机可以跑 10 台标称 16GB 的 VM,因为大部分 VM 同一时刻并不会都用满内存。
但宿主机怎么"收回"VM 没用到的内存?两种思路:
| 方式 | 做法 | 缺点 |
|---|---|---|
| Hypervisor 强行换页 | ESXi 直接把 Guest 的内存换出到宿主 swap | 不知道哪些是热数据,可能把 JVM 堆、DB 缓存换出 → 性能塌方 |
| Balloon 驱动配合 | 让 Guest 内核自己挑冷页让出来 | 本文主角 |
2. 它怎么工作
ESXi 在每台 VM 的 Guest OS 内核里安装一个驱动 vmw_balloon。当宿主内存吃紧时:
ESXi 宿主 vmw_balloon 驱动 Guest 内核
(内存吃紧) (Guest 内的代理人)
│ │ │
│ ① 请帮我占住 N 个页 ────────►│ │
│ │ ② alloc_pages() ──────────►│
│ │ (内核 LRU 挑出冷页) │
│ │ ◄────── 返回页号清单 ──────┤
│ ◄──── ③ 上报页号清单 ───────│ │
│ │ │
│ ④ 在 EPT 页表层把这些页归还到宿主空闲池 │
可以用一个生活化比喻:
教务处派一个"占座员"进 A 班教室。占座员看到空椅子(page cache / free 内存)就放个书包"宣示主权",然后把占住的座位号报给教务处。教务处偷偷把这些椅子搬给隔壁 B 班用,A 班同学不会再去坐它们。
关键约束:占座员只能占空椅子,那些被同学用胶带粘死的椅子(mlock 锁定的内存)它永远碰不到。
3. 一个重要细节
Balloon 驱动调用 alloc_pages() 申请内存时,只能从"可分配池"里拿:
- ✅ 真·空闲内存
- ✅ page cache(可回收)
- ❌ 被 mlock 锁定的页 —— 标记为 Unevictable,永远不在可分配池里
- ❌ 内核自己用的页
这个"摸不到 mlocked 内存"的特性,正是本次事故的核心。
四、ES 的 mlock:17GB 的"胶带椅子"
ES 官方文档强烈推荐配置:
bootstrap.memory_lock: true
启用后,ES 启动时会调用 mlockall(),把整个 JVM 堆锁死在物理内存中,避免被 Linux 换出到 swap(否则 GC 性能会塌方)。
事故日志里能直接看到锁定规模:
Mem-Info:
unevictable: 4548419 ← 单位是 4KB 页 → 约 17.4 GB
Free swap = 0kB ← swap 已经耗尽
也就是说,事故发生时 Guest 内存的结构是:
┌─────────────────────────────────────────────────────┐
│ ES JVM 堆 (mlocked, 不可让出) 17.4 GB │
│ ████████████████████████████████████████████ 🔒 │
├─────────────────────────────────────────────────────┤
│ 内核 / 其他进程 ~4 GB │
│ ██████████ │
├─────────────────────────────────────────────────────┤
│ page cache + 真·空闲(可让出) ~10 GB │
│ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░ │
└─────────────────────────────────────────────────────┘
Balloon 能从这台 VM"借走"的内存上限,就只有最下面那 10 GB。
五、串联成线
把所有线索串起来,重新梳理事故的发生过程:
-
长期伏笔:ES 用了
bootstrap.memory_lock=true,17 GB 堆永远锁死;同时 ESXi 默认开启 Balloon;这台 VM 与其他 VM 共享物理内存池(超分)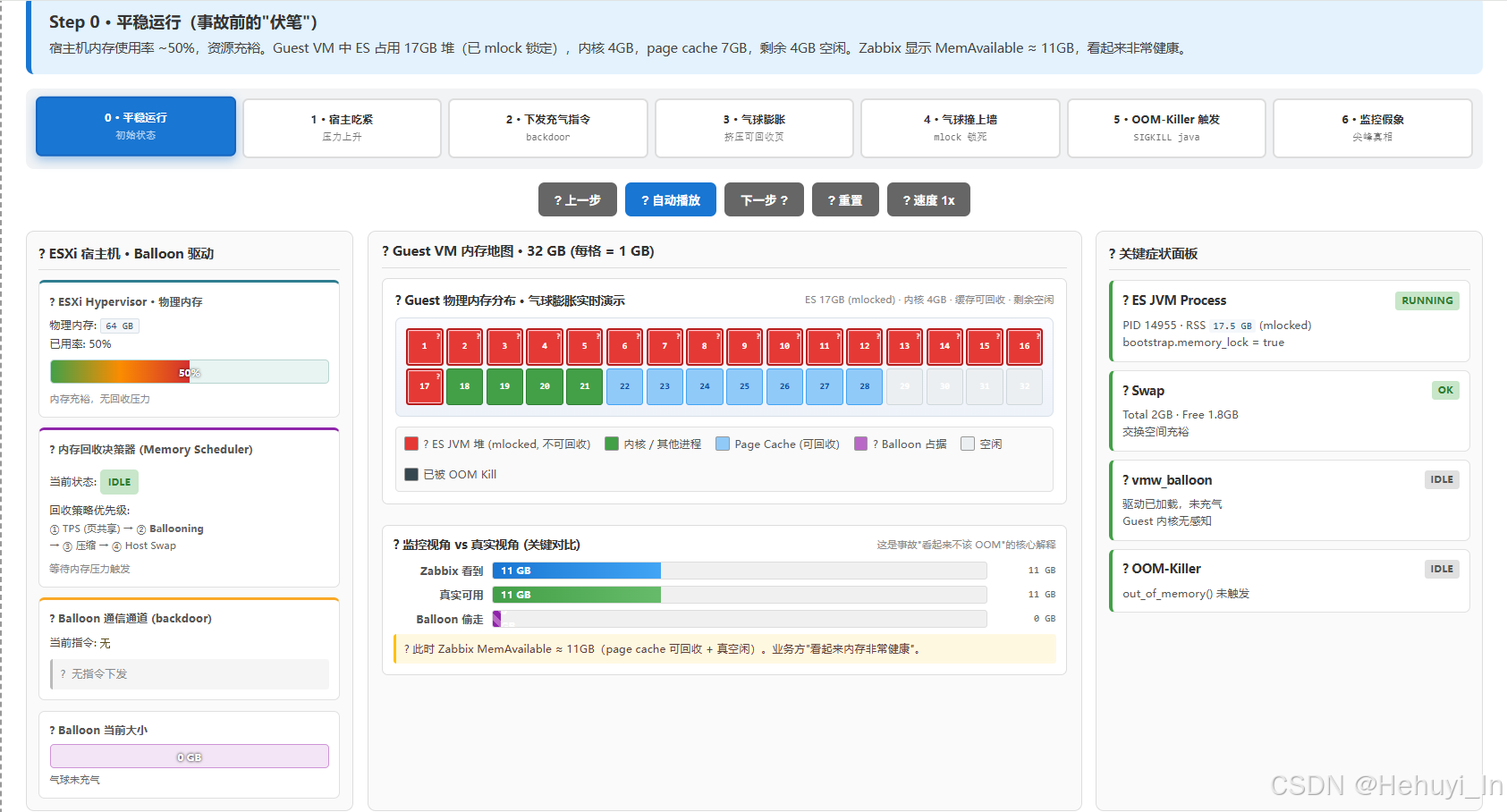
-
事故前:宿主因其他 VM 负载,物理内存吃紧,触发 Balloon 回收机制
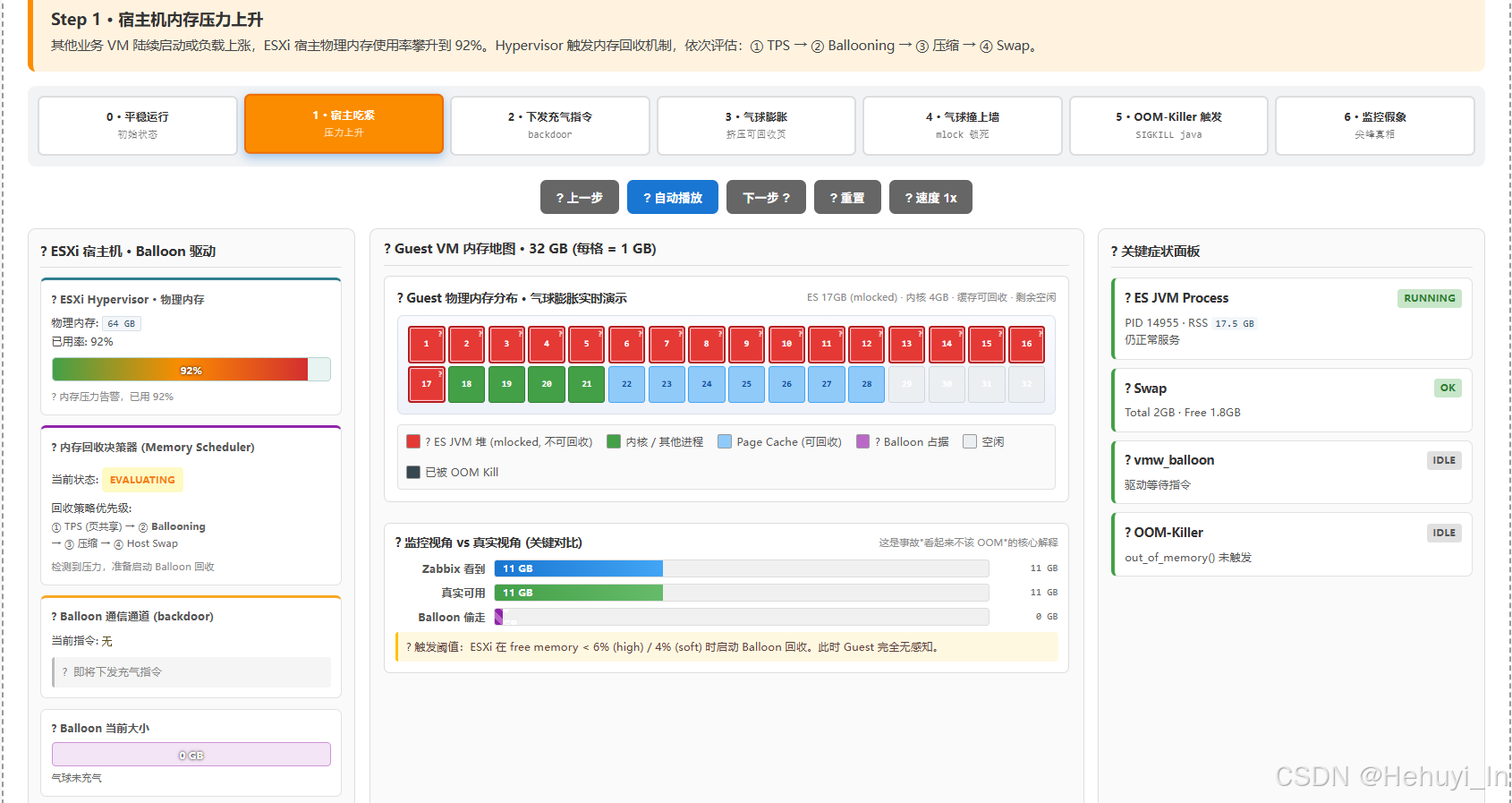
-
10:47 前后:ESXi 通过 backdoor 通道告诉这台 VM 的
vmw_balloon驱动"请帮我占住 X GB"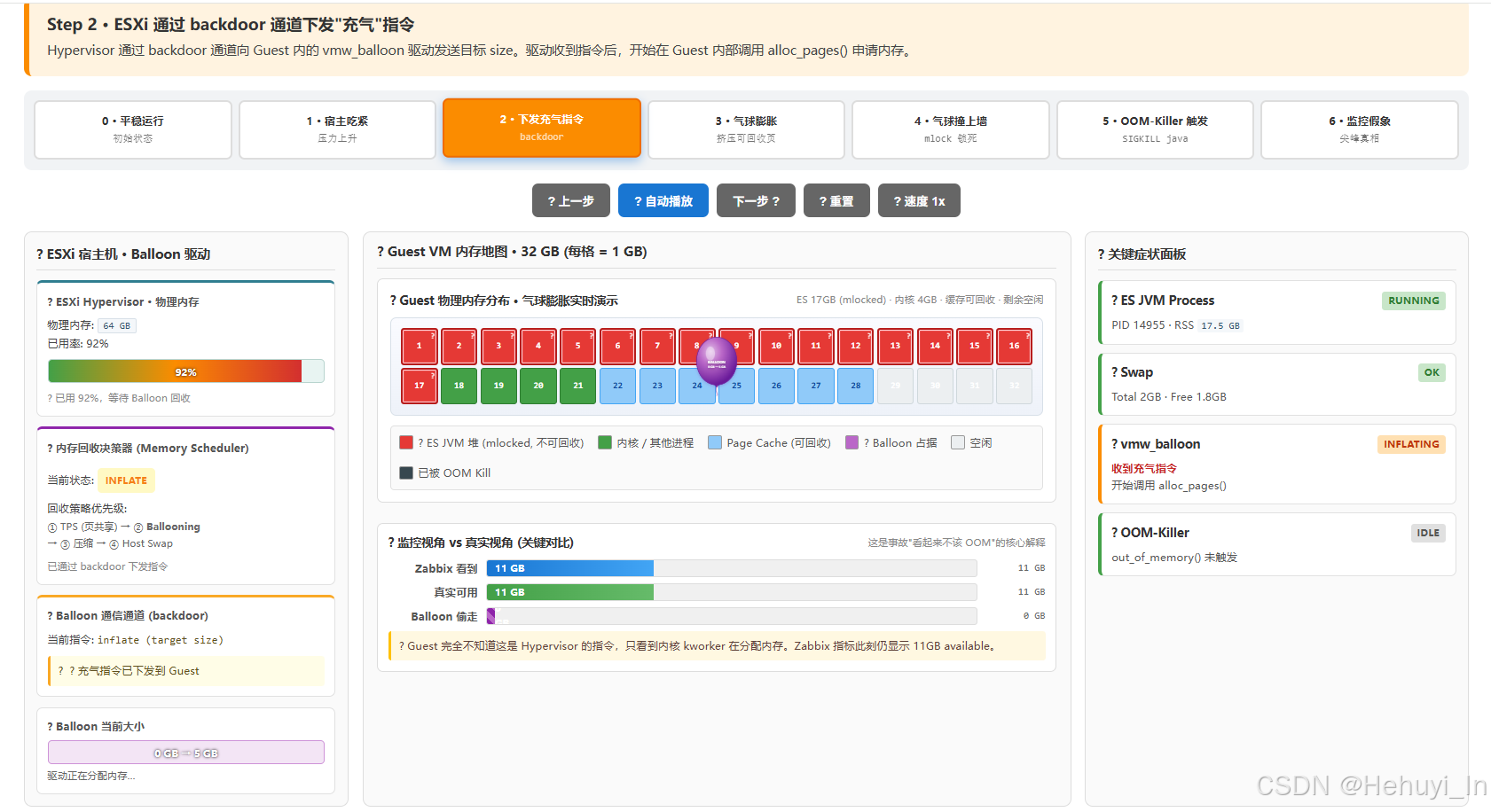
-
占座阶段:驱动开始
alloc_pages(),先吃掉 page cache + 真空闲 ≈ 10 GB,凑不够目标 size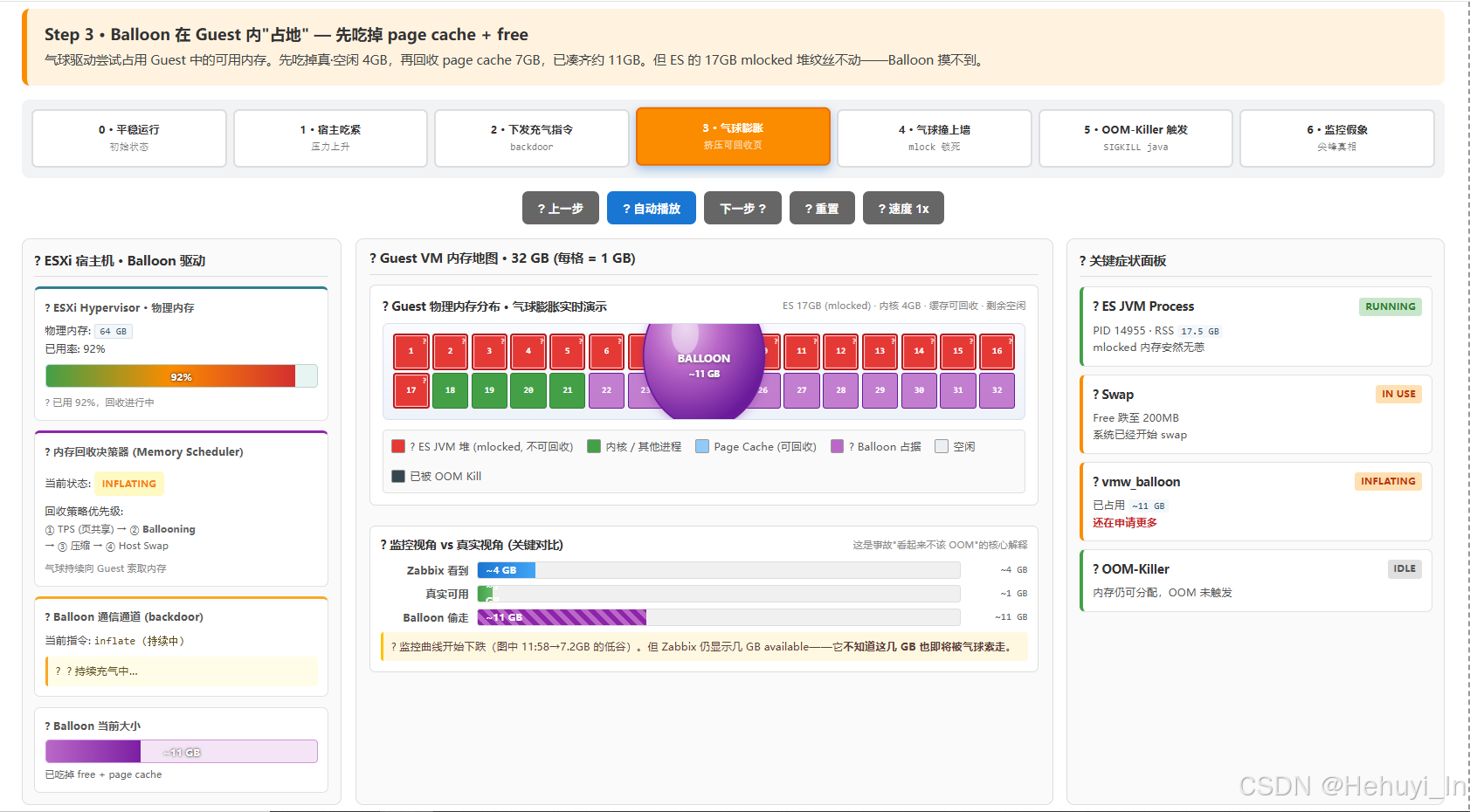
-
撞墙瞬间:剩下能要的内存只有 ES 那 17 GB,但全是 mlocked,摸不到;swap 也已经被压力榨干(Free swap = 0kB)
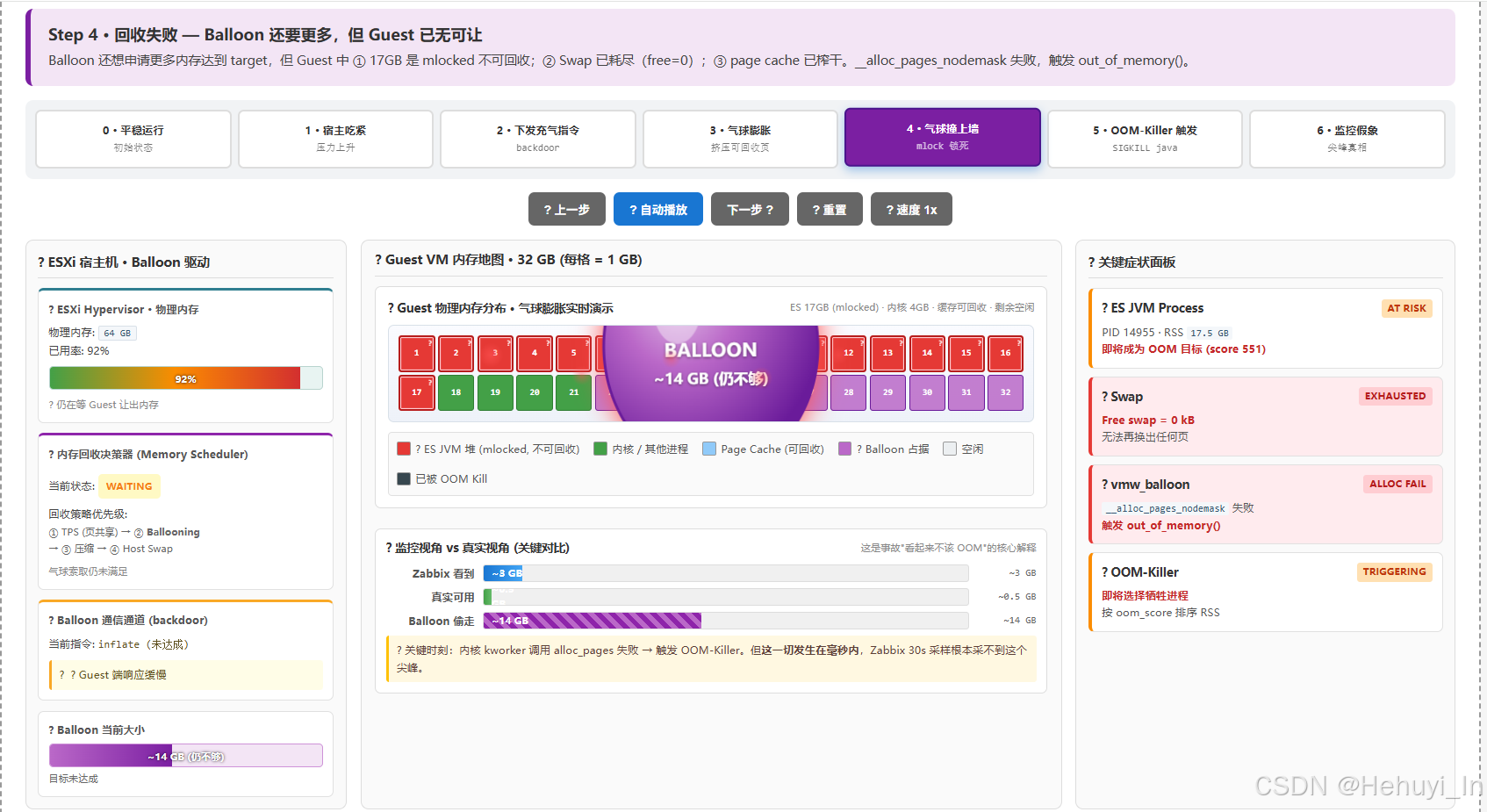
-
10:47:31:
__alloc_pages_nodemask失败 → 触发out_of_memory()→ 选 RSS 最大的进程杀掉 → java(score 551)中弹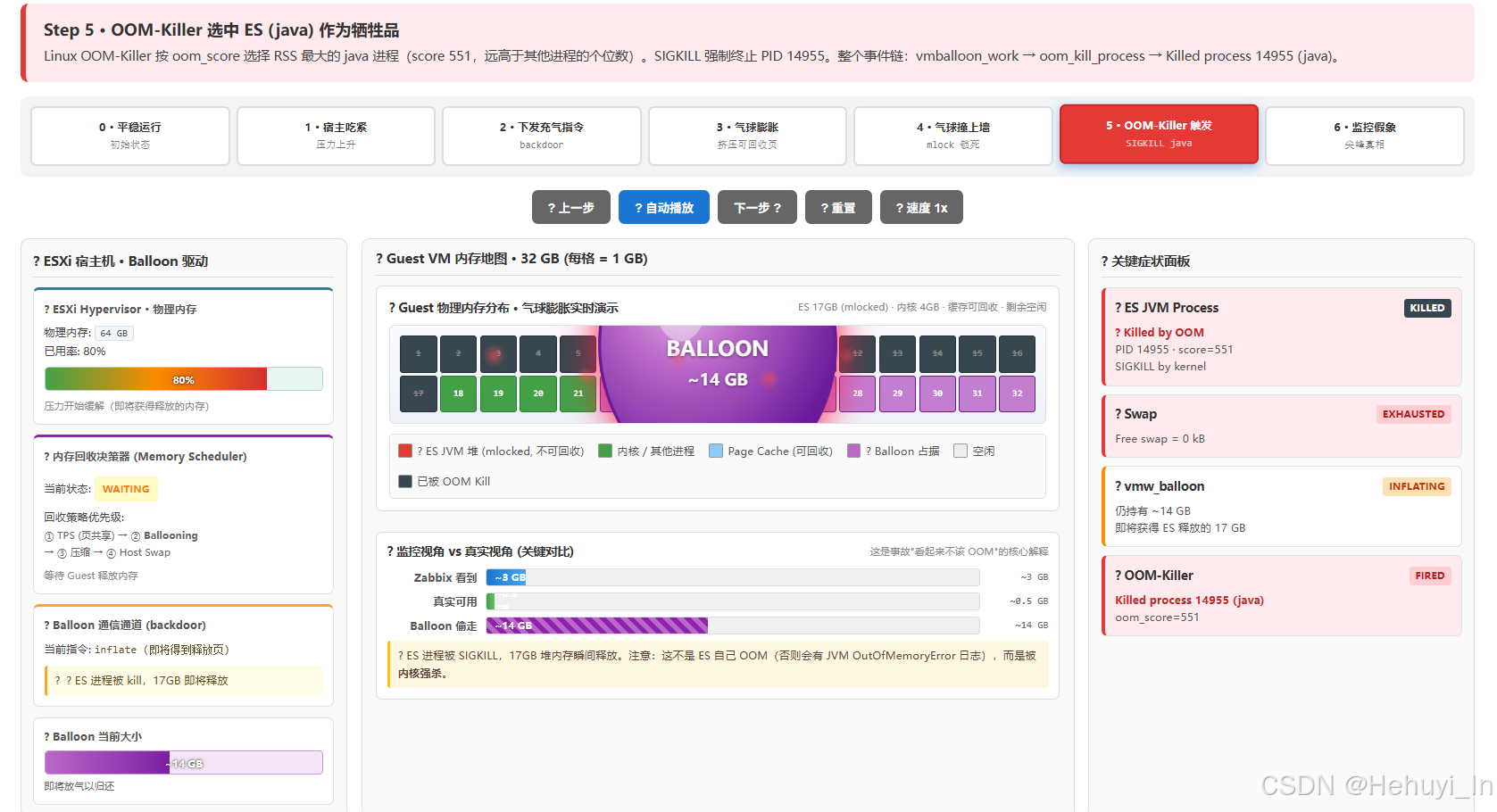
-
事故后:ES 进程死亡,17 GB mlocked 内存瞬间释放给内核,Balloon 拿够后归还宿主
-
下一次 监控采样:看到 MemAvailable 飙到 ~30 GB
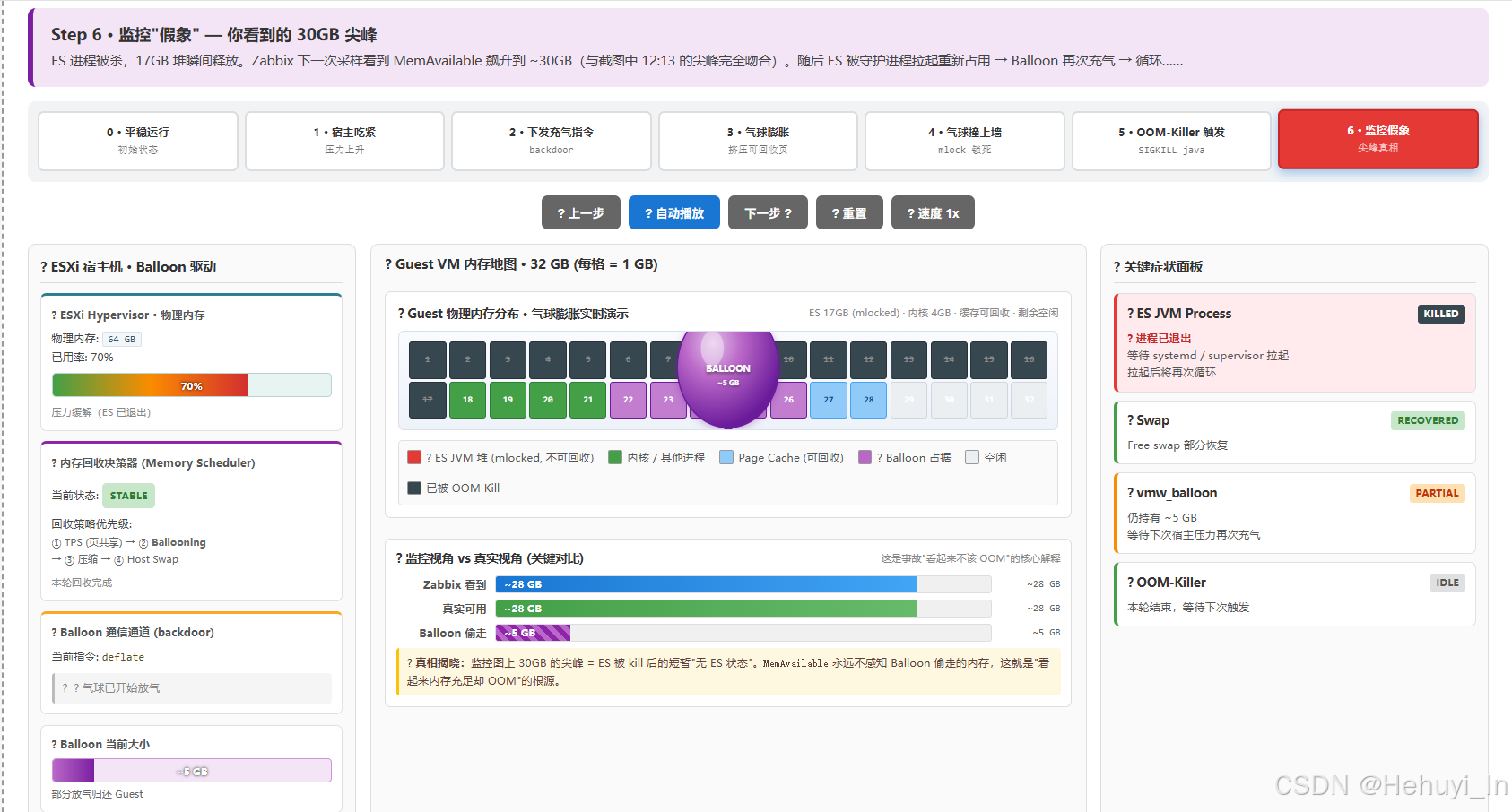
回到开头的疑问:
| 疑问 | 答案 |
|---|---|
| 监控显示 10GB 可用,为什么 OOM? | MemAvailable 指标不感知 Balloon 偷走的页面;且 Balloon 充气+OOM 整个过程是毫秒级,被 30 秒采样间隔吞掉了 |
六、整改方案
1. 虚拟化层:关键应用禁用 Balloon 或全预留
对于 ES / Oracle / MySQL / Redis 这类会大量锁定内存的应用,必须二选一:
# 方案 A: 禁用 Balloon
# vSphere → VM 设置 → Options → Advanced → Configuration Parameters
sched.mem.maxmemctl = 0
# 方案 B: 内存全预留(推荐,更彻底)
# vSphere → VM 设置 → Resources → Memory → Reservation
Reservation = VM 配置内存总量 (例如 32768 MB)
全预留的本质是这台 VM 不参与宿主超分池,Balloon 自然没机会启动。
2. 虚拟化层:虚拟机迁移
动静最小的方式,将其vmotion至内存充足的宿主机上
3. 应用进程异常退出告警
# ES 进程退出码 137 (= 128 + 9, 即 SIGKILL)
# Java 应用突然消失但没有 OOM Error 日志
→ 大概率是被内核 OOM Killer 杀的, 必查 /var/log/messages
七、总结反思
除了技术层面的整改,本次问题还暴露了几个值得关注的点:
- 官方推荐配置不能照搬到虚拟化环境:ES 官方推荐
bootstrap.memory_lock=true,这在物理机上完全正确;但在 VMware 虚拟机上,必须搭配"禁用 Balloon / 全预留"才安全,否则反而成为 OOM 的导火索 MemAvailable这个指标在 VMware 场景下不可信:习惯了看物理机监控的同学很容易被它误导- 诊断思路要跨层:Guest 内的指标只能反映 Guest 视角,事故的真凶可能在宿主层;遇到"内存看起来够却 OOM",第一时间去看宿主侧的
vmmemctl - 关注内核日志的调用栈:OOM 日志里的
Workqueue:行往往直接指出触发者,不要只看最后那行Killed process,否则容易误以为是应用自身的问题 - 事故后的"内存尖峰"是重要指纹:进程被 OOM 后释放的内存量如果远大于该进程的 RSS(如本案 ES RSS 17G 但 MemAvailable 涨了 18G+),基本可以确诊有外部回收机制在同步动作(如 Balloon)
最后用一句话收尾:ES 不是被自己杀死的,也不是被 ESXi 直接杀死的,是被 Guest 内核"为了满足 Balloon 驱动的内存申请"而牺牲的。这种跨虚拟化层的事故链条,对监控、对官方推荐配置的理解、对内核日志的解读,都提出了更高的要求。

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐
 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)