ORACLE异常sql解析的案例,偏偏遇见你
数据库版本为Oracle 12.2.0.1,可能是南方一些比较着急的单位当年选择这个版本,大多数人是从11.2.0.4直接到19.18。
有套库最近2天cpu越来越高:
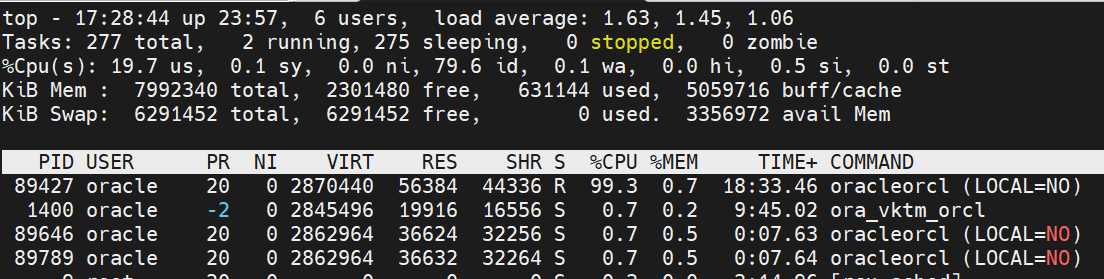
(上图仅为示例)实际us 和load average 都很高,操作系统cpu资源耗尽,主要是oracle会话进程。
看看数据库会话都在忙什么:
set lines 200 pages 1000
col sid for a15
col username for a16
col state for a20
col event for a25 trunc
col sql_id for a13
col logon_time for a19
col seconds for 99999
col blk for a15
col machine for a18 trunc
col program for a20 trunc
SELECT sid||','||SERIAL# sid, username, state,event,
status, LAST_CALL_ET,to_char(logon_time, 'yy-mm-dd hh24:mi:ss')
logon_time,sql_id, FINAL_BLOCKING_SESSION ||'#'||
FINAL_BLOCKING_INSTANCE blk,SECONDS_IN_WAIT
seconds ,program--,machine,
FROM V$SESSION
WHERE (WAIT_CLASS <> 'Idle'
or state <> 'WAITING') and SID <>
sys_context('userenv','sid') and
rownum < 201
ORDER BY SECONDS_IN_WAIT DESC,event;
会话状态为WAITED SHORT TIME,貌似没等待,只是最近执行的很快,等待事件也很有迷惑性SQL*Net more data from client,可以理解为从客户端发送更多数据给服务器进程,通常都是空闲类。
关于STATE字段的解释:

如果仔细观察,可以看到异常点:LAST_CALL_ET很长时间了,92秒未结束(真实情况会一直运行),从LOGON_TIME也可以看出端倪,是很长时间之前登录上来的会话。
看看活动占比

有sql_id但看不到文本,v$sql中也没有。
col sql_text for a80
select sql_text from v$sqltext where sql_id='&sql_id' order by piece;
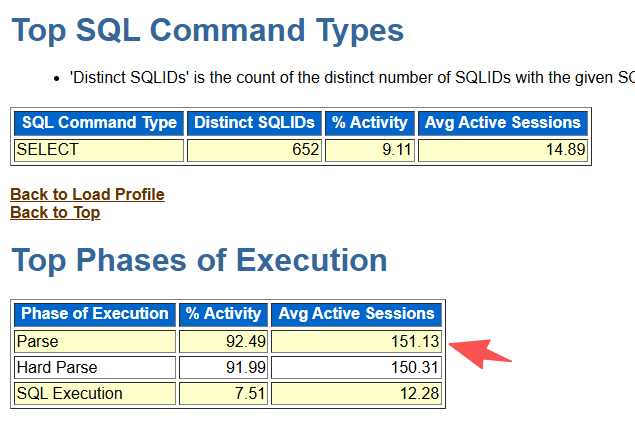
抓个最近15分钟内ash报告看看。
其他很空
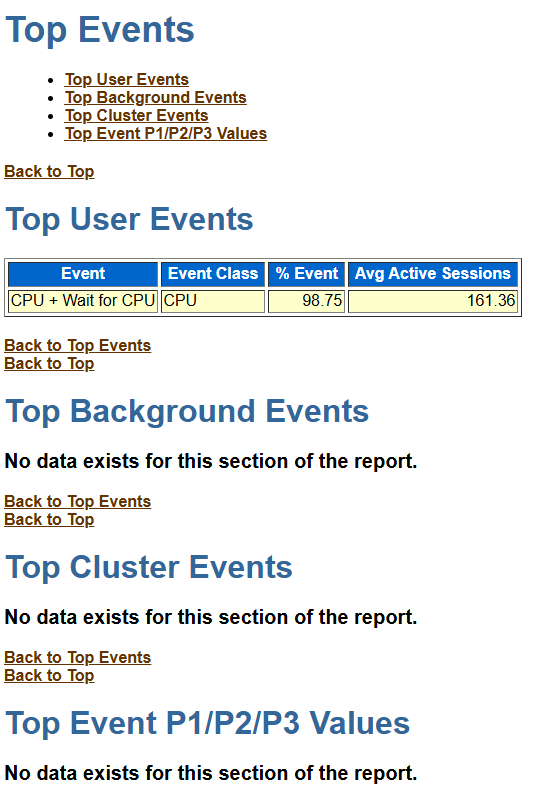
看整体等待事件会话统计
select event,count(0) from v$session
where wait_class<>'Idle' or state <> 'WAITING' group by event;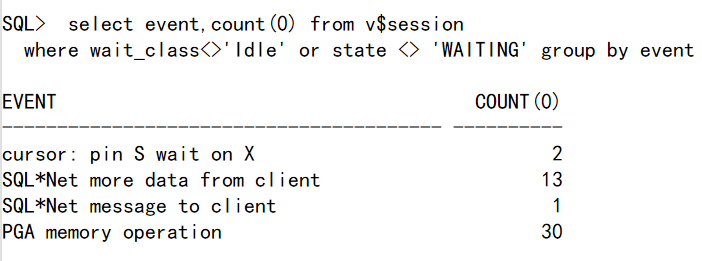
2个会话在ping S wait on X,13个会话在more data from client,30个会话在PGA memory operation。
目前看:
1、似乎“没有”异常等待事件;
2、活动会话的sql_id“没有”具体文本;
3、ash报告只有硬解析情况,其他内容空空。
导致高CPU的操作到底是什么呢?
还是从传统的等待事件分析方法入手,先对 PGA memory operation 事件分析一下。
这个event的实质:会话在请求分配 / 释放 PGA 内存时被强制等待,是 12.2 引入的PGA 硬限制保护机制的直接体现。
-- 查看PGA使用TOP10会话
col username for a20
col program for a30
set pages 100 lin 200
SELECT
s.sid, s.serial#, s.username, s.program,
ROUND(p.pga_used_mem/1024/1024, 2) AS pga_used_mb,
ROUND(p.pga_alloc_mem/1024/1024, 2) AS pga_alloc_mb,
s.sql_id, s.prev_sql_id
FROM v$session s
JOIN v$process p ON s.paddr = p.addr
ORDER BY p.pga_used_mem DESC
FETCH FIRST 10 ROWS ONLY;
-- 查看当前活跃的PGA工作区
SELECT
sql_id, operation_type,
ROUND(expected_size/1024/1024, 2) AS expected_mb,
ROUND(actual_mem_used/1024/1024, 2) AS actual_used_mb,
number_passes
FROM v$sql_workarea_active
ORDER BY actual_mem_used DESC;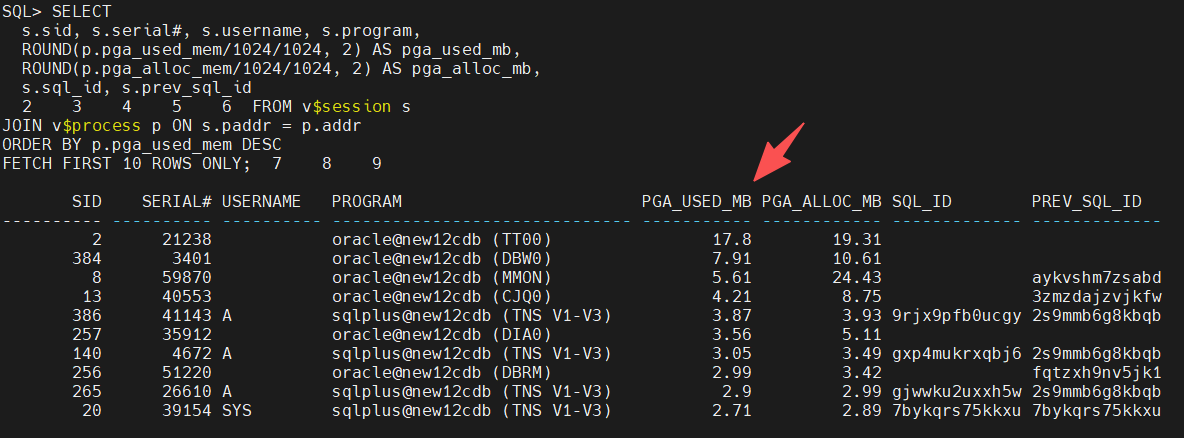
没有太多消耗pga的会话,pga参数比较充足,物理内存仍有剩余,不是常见的pga不足问题。
不确定这30个会话在干什么。
看看告警日志,无异常。看看诊断进程dia0的trc文件

base是基础,lws是“长等待会话”,有重大发现:

hm的Hang detection功能启用,发现会话140挂起,且处于“非等待”状态长达96秒,继续往下看
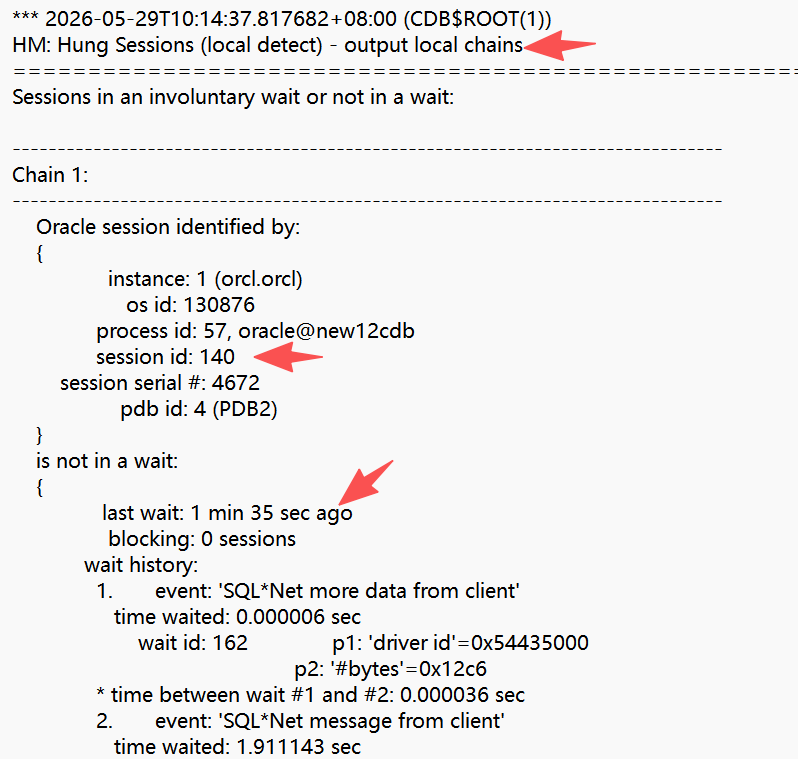
本地等待链,会话140最后一次等待持续了1分35秒,即95秒,还是没语句,需要看lws的trc文件 (Long Waiting Session)
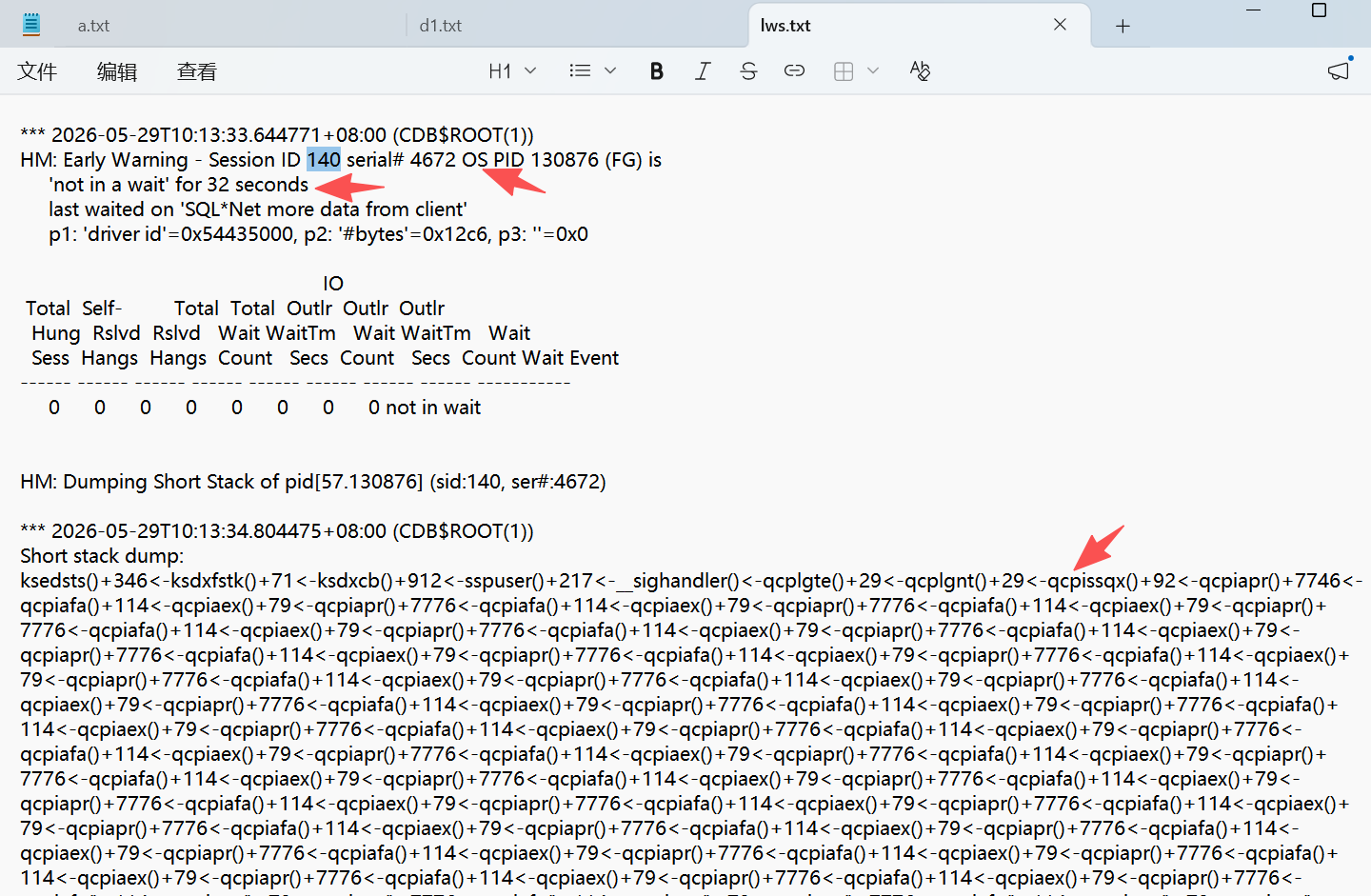
Short stack dump非常长,继续往下翻
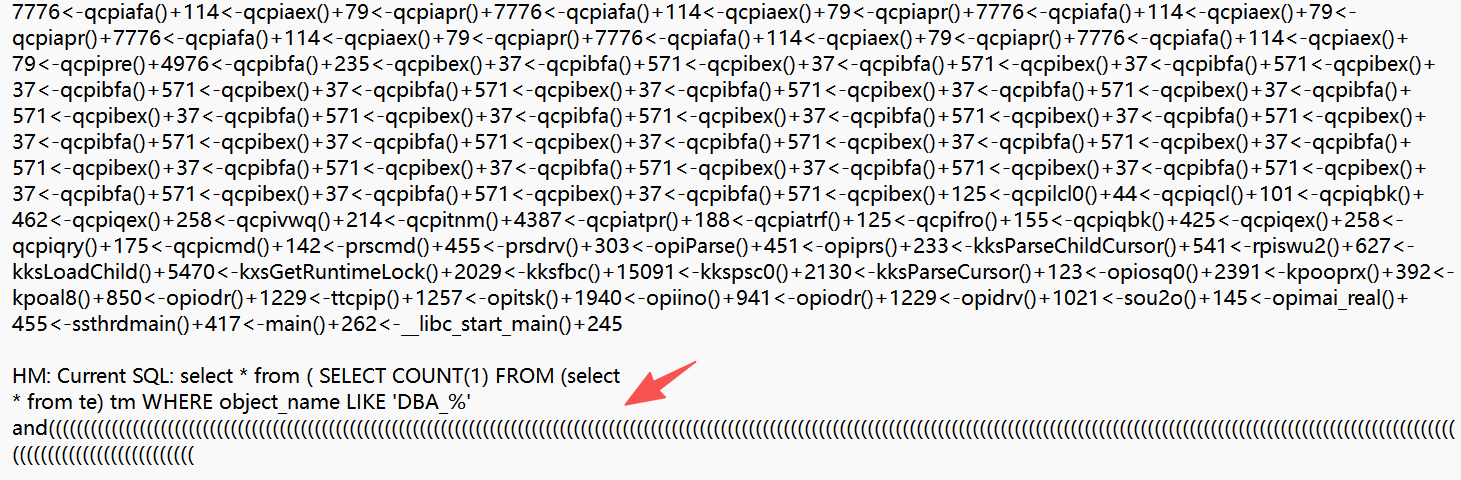
终于看到具体sql了,有很多括号,分析stack可知:

分析sql语句:
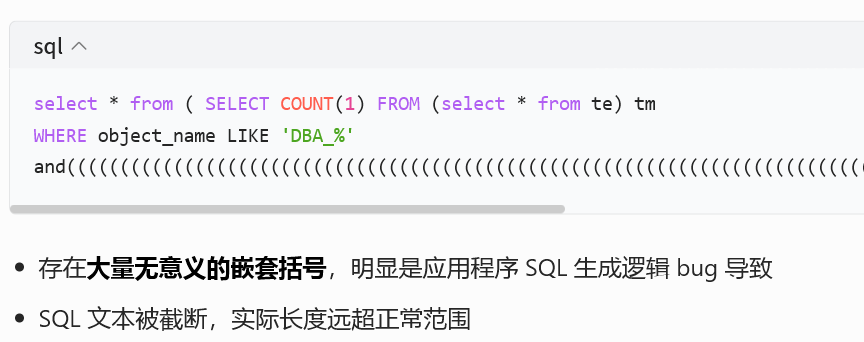
真相基本大白了,如果没有dia0相关trc呢?
对于有sql_id但是v$sql中看不到文本的,还可以试试底层视图
set serveroutput on size unlimited pages 100 lin 200
col SQL_TEXT_1000 for a60
SELECT
kglobt03 AS sql_id,
kglnahsh AS hash_value,
kglnaobj AS sql_text_1000,
kglnatim AS first_load_time,
kglhdadr AS handle_address
FROM x$kglob
WHERE kglhdadr = kglhdpar -- 只查询父游标
AND kglobt02 != 0 -- 排除非SQL对象
AND kglobt03='gxp4mukrxqbj6';输出如下:
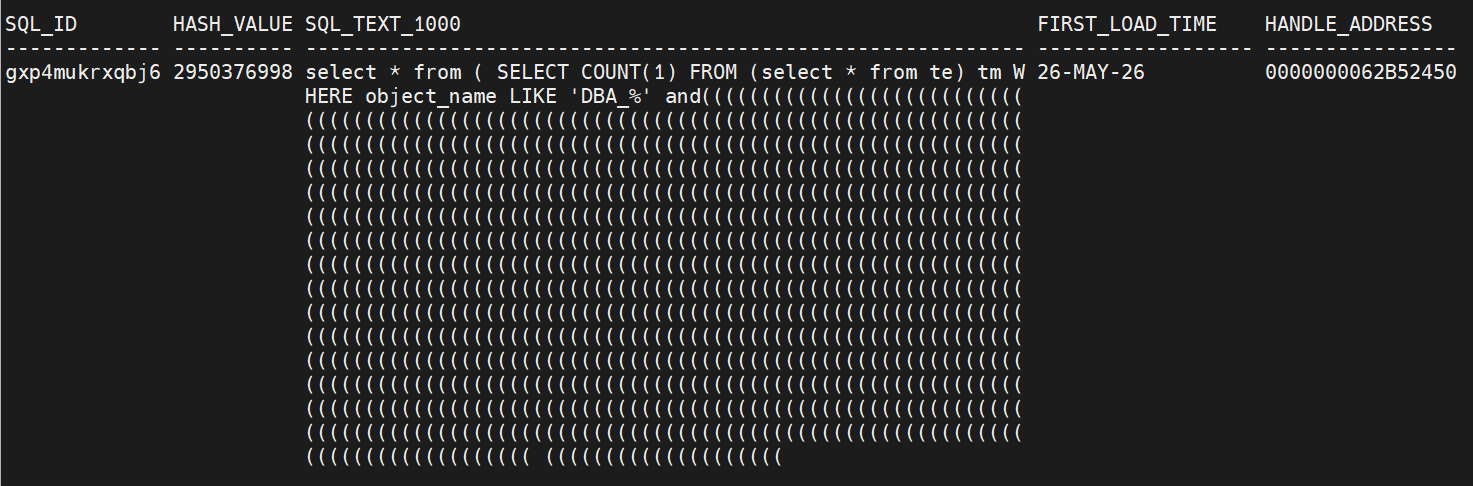 或
或
set serveroutput on size unlimited pages 100
SELECT kglnaobj
FROM x$kglcursor
WHERE kglobt03 = 'gxp4mukrxqbj6'
AND kglhdadr = kglhdpar; 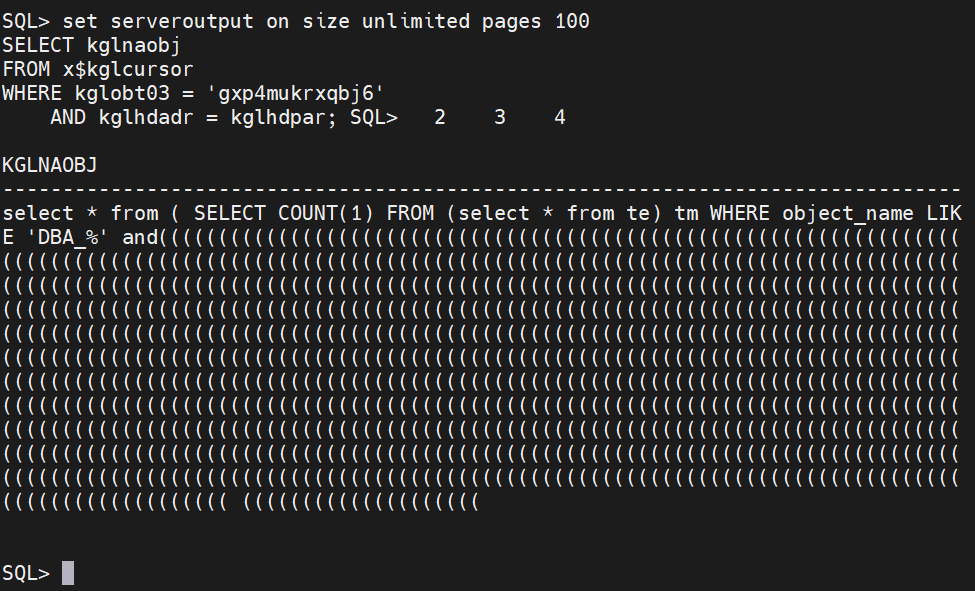
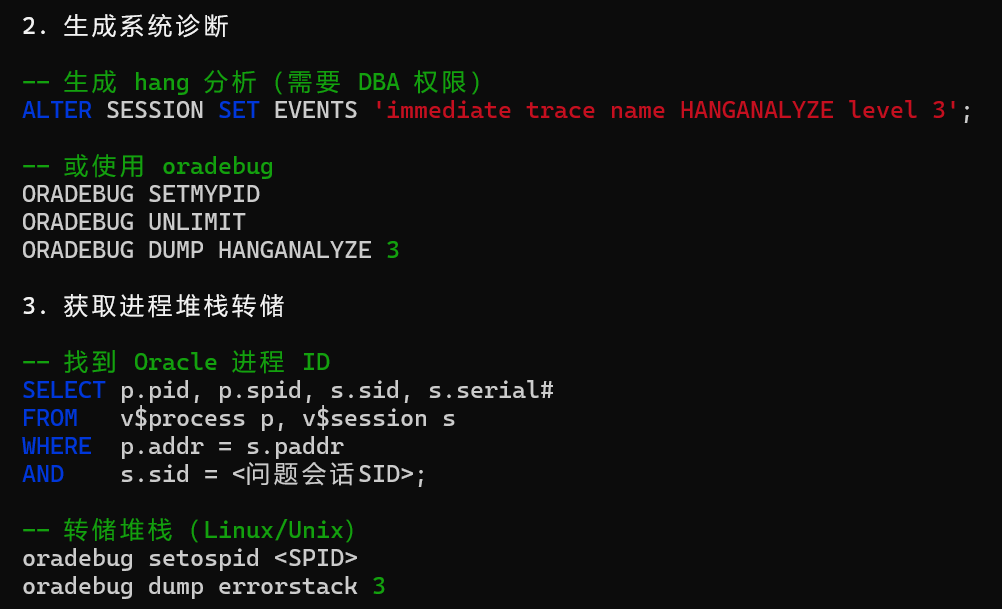
较为全面的诊断方法可以通过hanganalyze命令,会把数据库当前状态输出到一个trc中
oradebug setmypid
oradebug unlimit
oradebug hanganalyze 3
输出如下:

查看这个trc内容(跟HM的差不多)
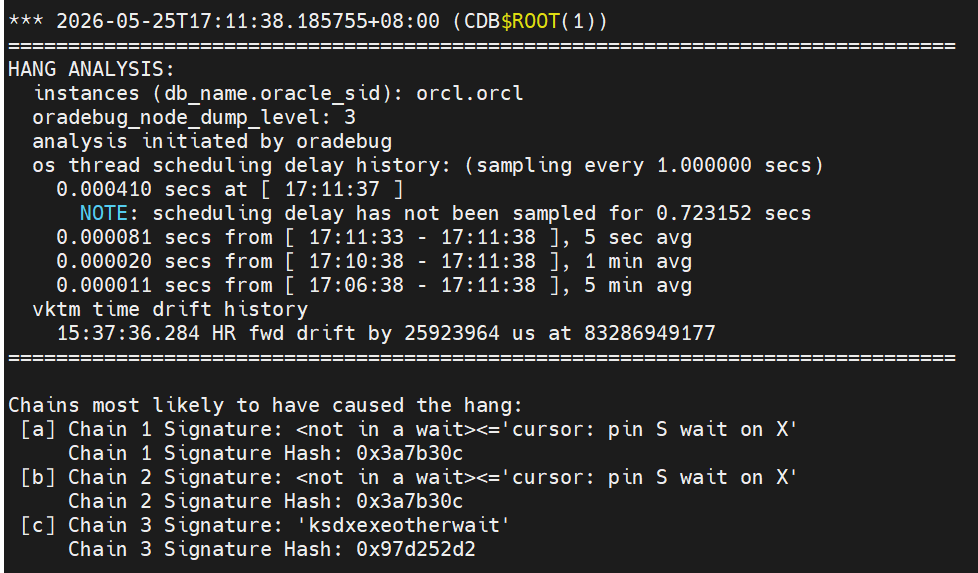
有2个cursor: ping S wait on X说明它俩正在以共享模式(S)请求游标(SQL 执行计划)的 Pin,但被一个以独占模式(X)持有游标 Pin 的会话阻塞,继续下翻
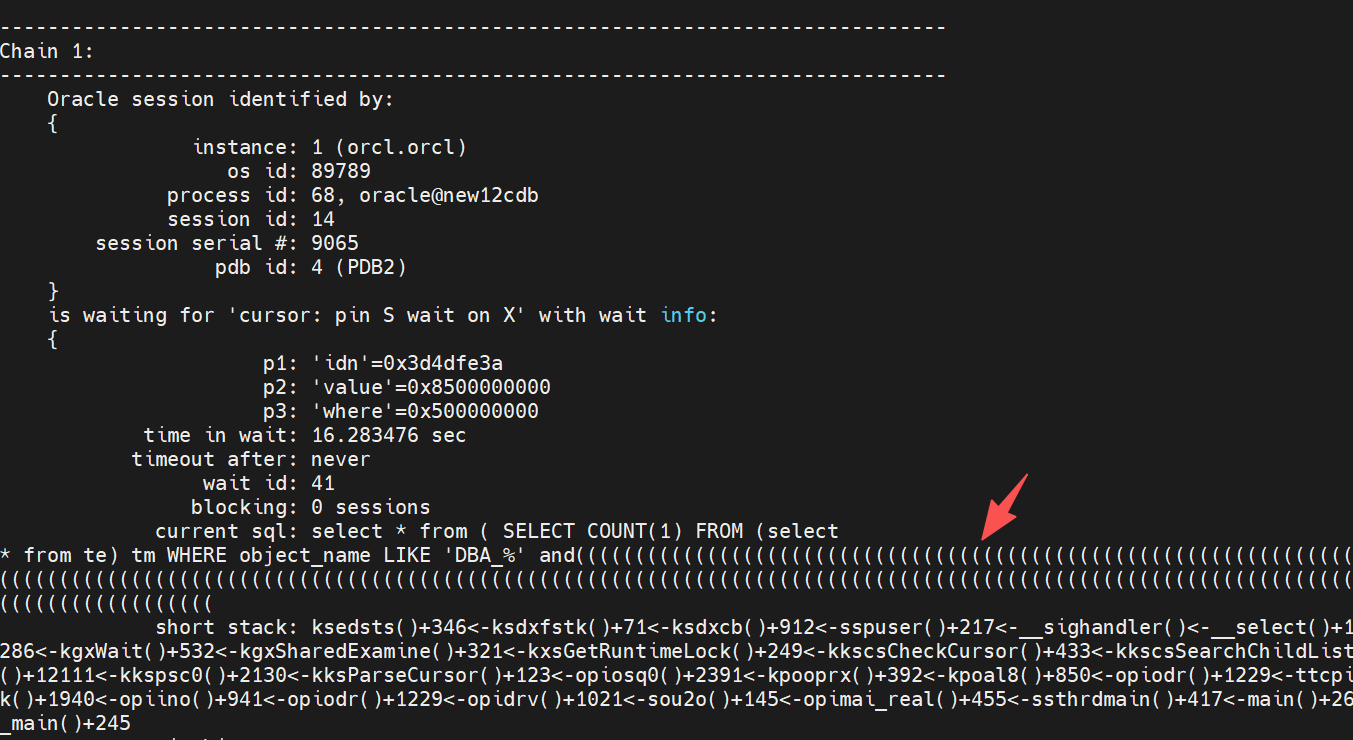
能看到详细的sql文本,具体的os id和sid等信息也都能看到。
分析stack堆栈(oracle的内部函数调用)信息:
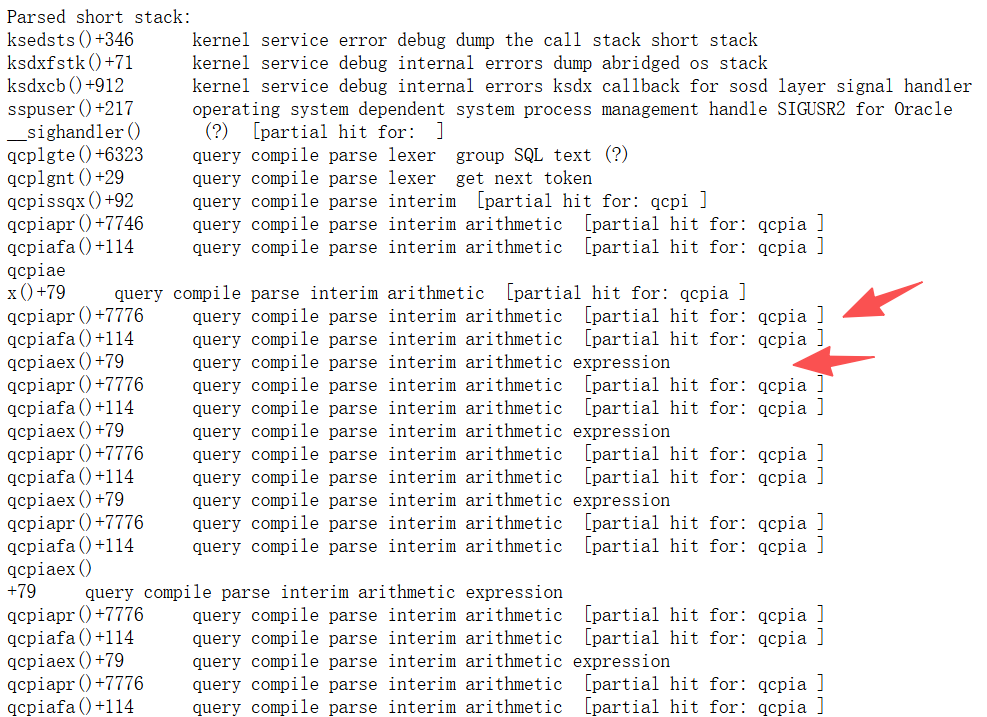
可以理解为“查询编译阶段中间结果算法”。
查询当前的锁也能看到一些特殊现象:
--当前全部锁
col sid for 99999999
set lin 200 pages 500
col username for a22
col OBJECT_NAME for a22
select a.sid,b.serial#,decode(a.type,'TM',c.object_name,NULL) OBJECT_NAME,
a.type,b.username,
decode(a.lmode, 0,'0:none', 1,'1:NULL',
2,'2:SS(Row-Share)', 3,'3:SX(Row-X)',
4,'4:S(Share)', 5,'5:SSX(S/Row-X)', 6,'6:X(Exclusive)') lmode,
decode(a.REQUEST, 0,'0:none', 1,'1:NULL', 2,'2:SS(Row-Share)',
3,'3:SX(Row-X)', 4,'4:S(Share)', 5,'5:SSX(S/Row-X)',
6,'6:X(Exclusive)') REQUEST, a.ctime,a.block
from v$lock a,v$session b ,dba_objects c
where b.sid=a.sid and c.object_id(+)=a.id1 and
a.con_id=b.con_id and b.username is not null;
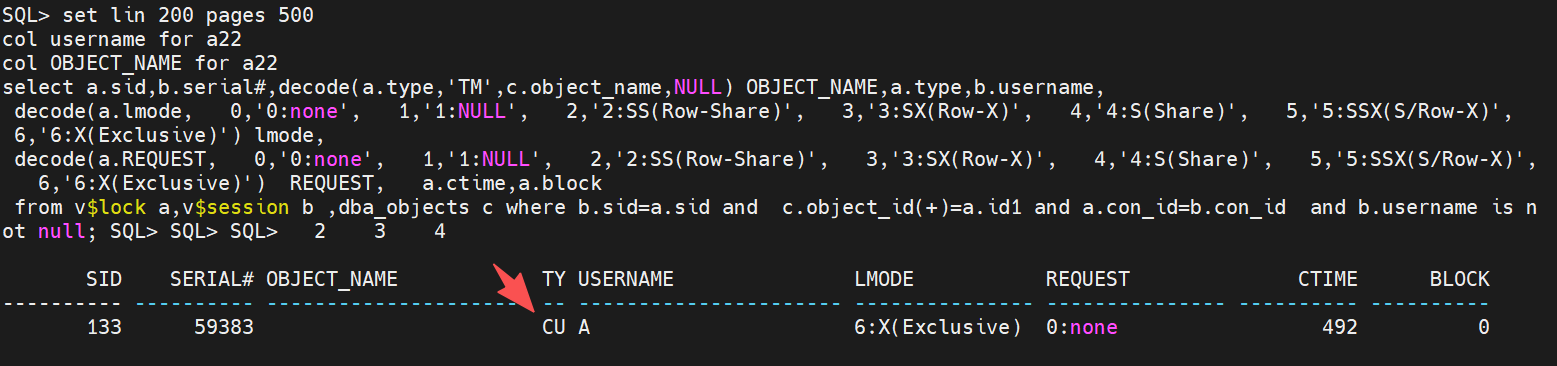

如果sql文本不同,那么就是下面这样了:

不存在阻塞情况,会话都是active的,这时就是3个CU锁:

还发现有个有趣现象,等待事件会变化
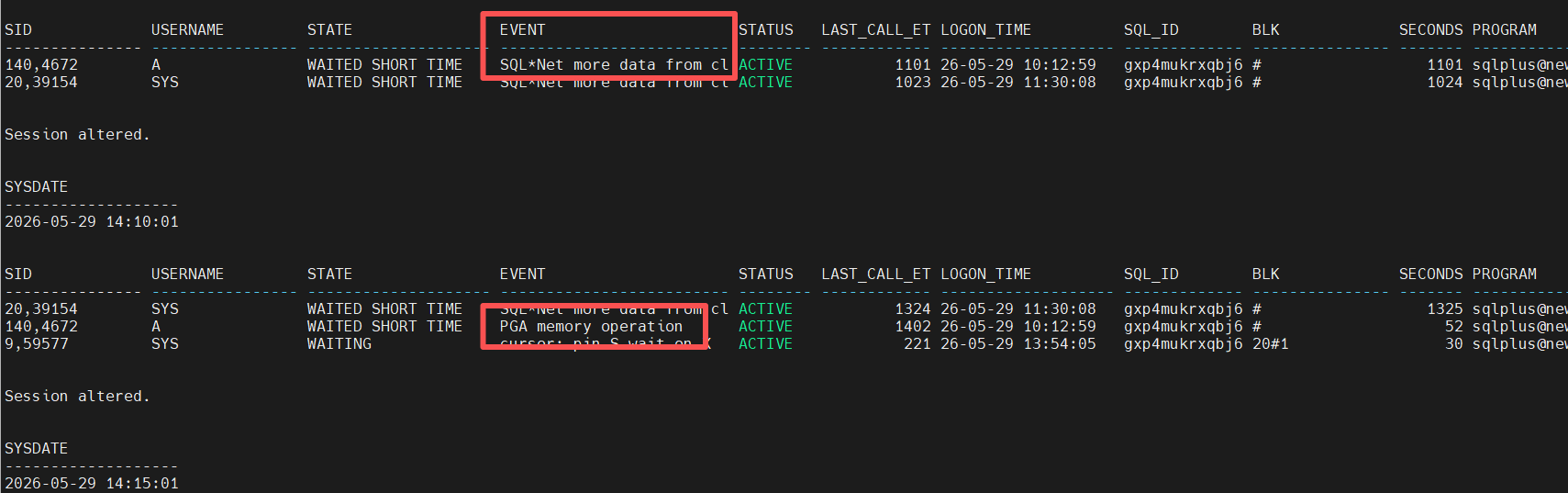
会话140执行了一段时间后(1400多秒),event从SQL*Net more data from client 改变为PGA memory operation。
真实现场往往更加复杂:

各种等待都有。
等待事件 cursor: pin S wait on X是因为相同sql执行时,前面执行的还没解析完,其他的就需要等待。

还可以通过pstack看看繁忙进程:
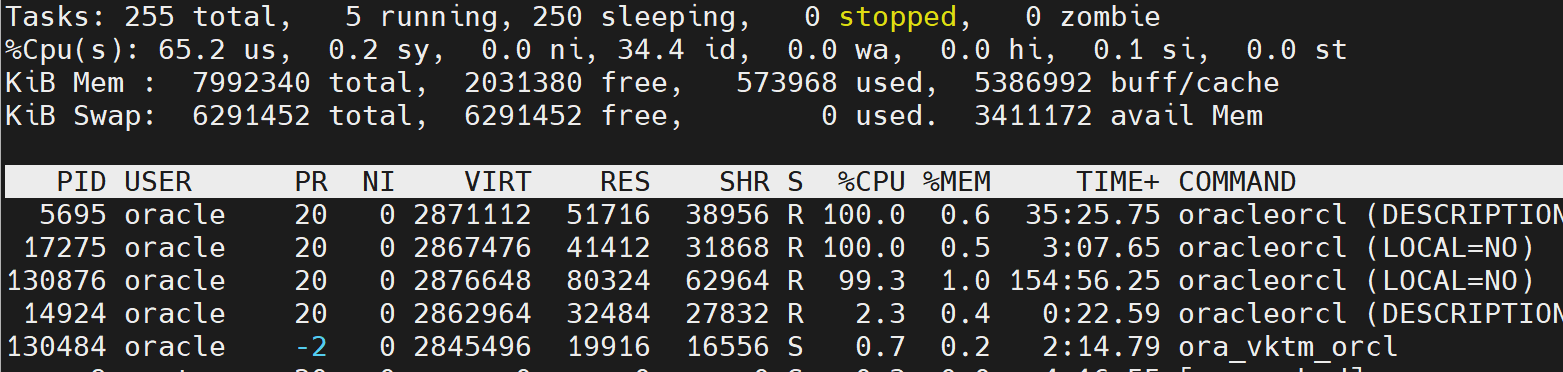
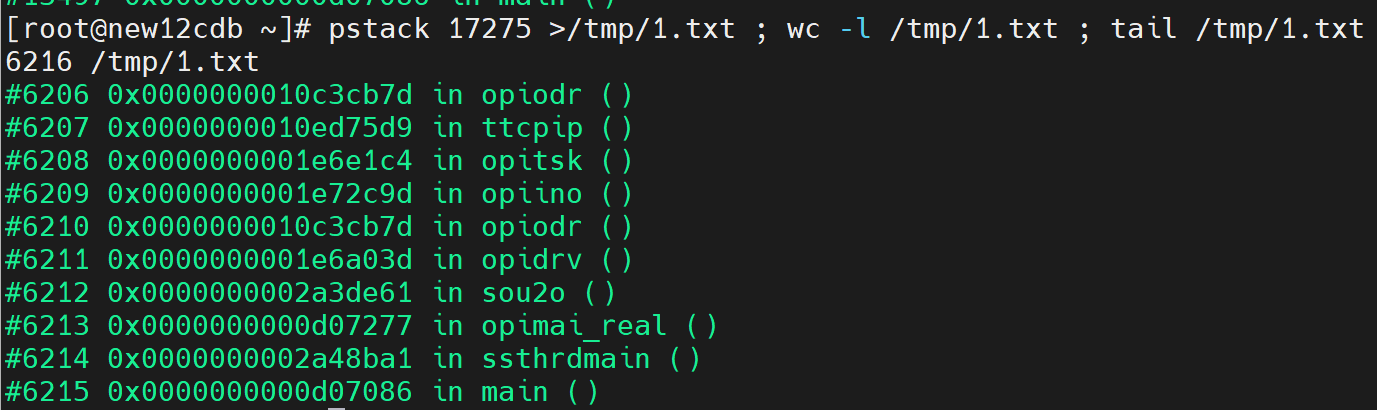
就拿进程 17275来说
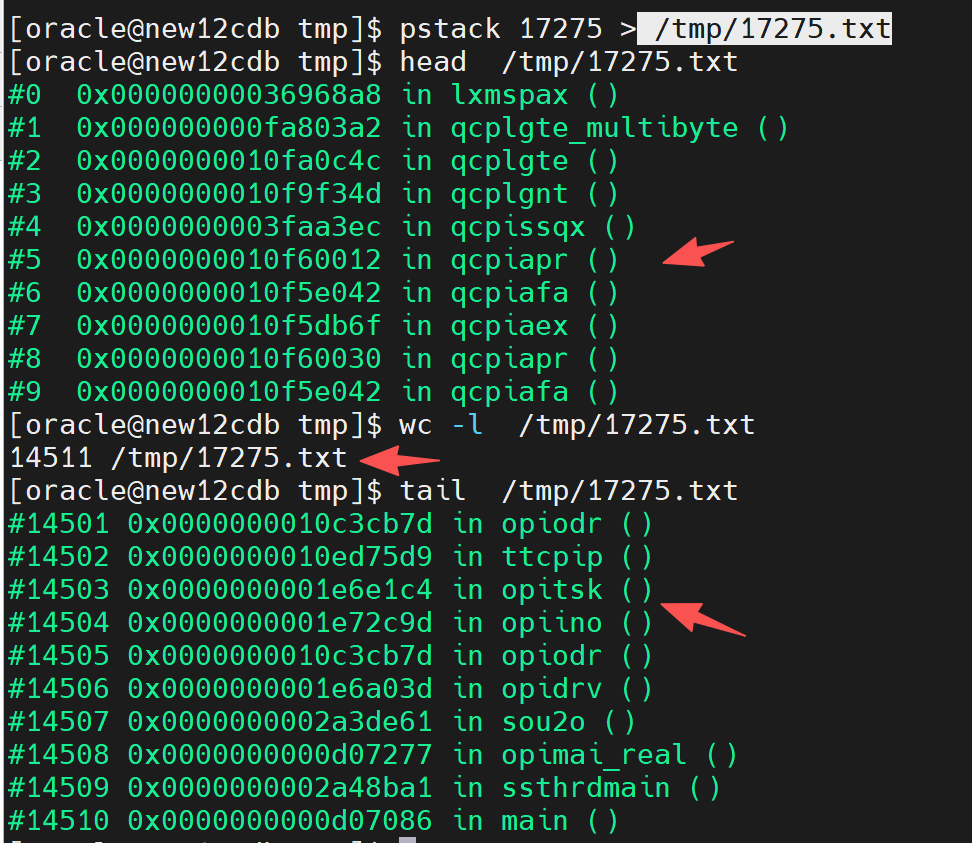
有的时候可能会输出上万行函数信息,有的时候输出几千行堆栈函数。
简介一下HM

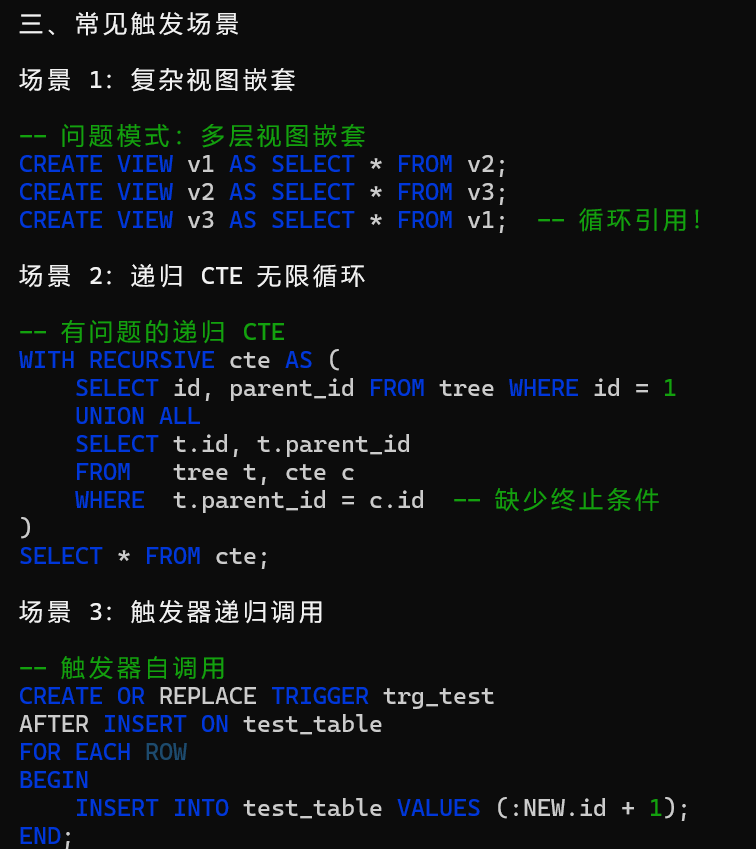
演示sql如下:
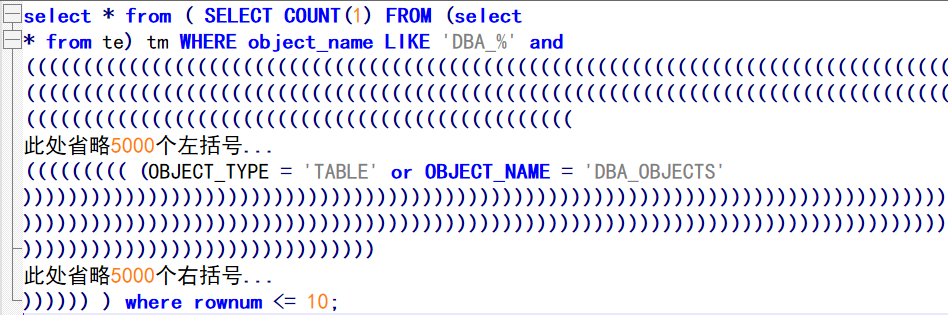 很多括号导致的高CPU。
很多括号导致的高CPU。
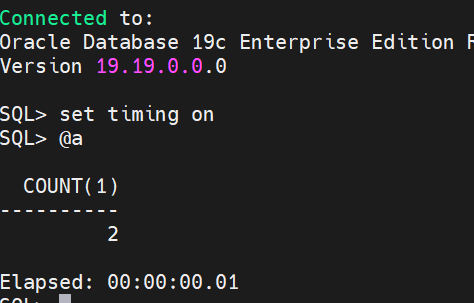
换做oracle 19c 或 26ai 这些版本就没事了,结果秒出:
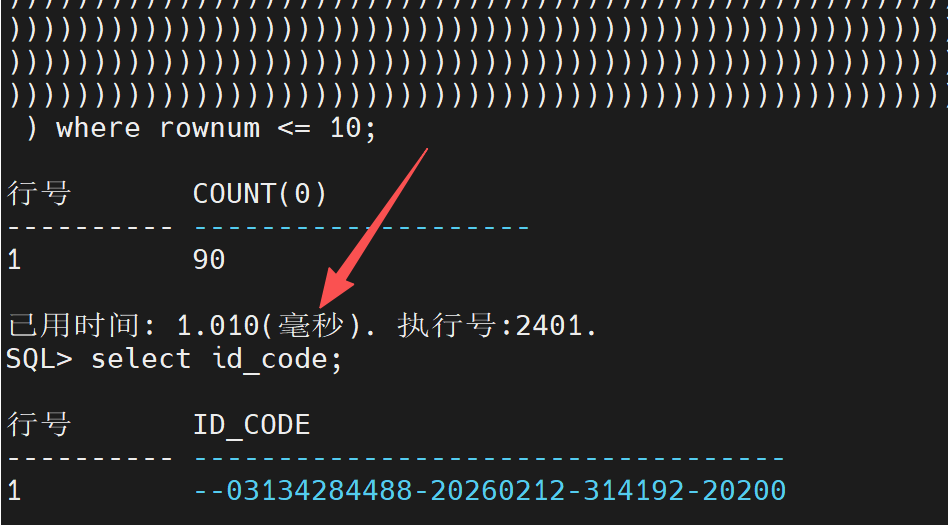
换做达梦8,也能秒出:
通过豆包ai确认这个行为:





最后不一定sql报错,像这种很多括号的情况。
再看看质谱ai的



ai给的建议很热闹,但是ORACLE官网上没搜到具体BUG,也许屏蔽了。
简介一下hanganalyze:

开启会话跟踪的方法:
--跟踪会话
begin
dbms_monitor.session_trace_enable(
session_id => 133,
serial_num => 10356,
waits => TRUE,
binds => TRUE
);
end;
/
--跟踪文件路径
select
p.tracefile
from v$session s
join v$process p on s.paddr = p.addr
where s.sid = 133;
/u01/app/oracle/diag/rdbms/orcl/orcl/trace/orcl_ora_32908.trc
--观察会话是否开启跟踪
col sid for 999999
SELECT sid, serial#, username,
sql_trace, sql_trace_waits, sql_trace_binds
FROM v$session
WHERE sid=133;
#操作系统跟踪会话对应的进程方法
strace -e write=all -e all -p 32908
跟踪这种会话,需要等待执行完毕才能看到结果。
会话的统计信息分析:
--创建临时表(针对sid=19的会话)
create table stat19 as select * from v$sesstat where 1=2;
truncate table stat19;
insert into stat19 select * from v$sesstat where sid=19 ;
--等待1分钟
col statname for a40
select * from (
select a.*,n.name statname,n.class,b.value-a.value as diffv
from stat19 a ,v$sesstat b, v$statname n
where a.statistic#=b.statistic# and a.statistic#=n.statistic# and b.sid=19
order by diffv desc)
where rownum<51;等待1分钟后,执行查询发现只有session pga memory增长

如果有耐心,等待会话结束,再查询差异值,排序较高的是以下几个:
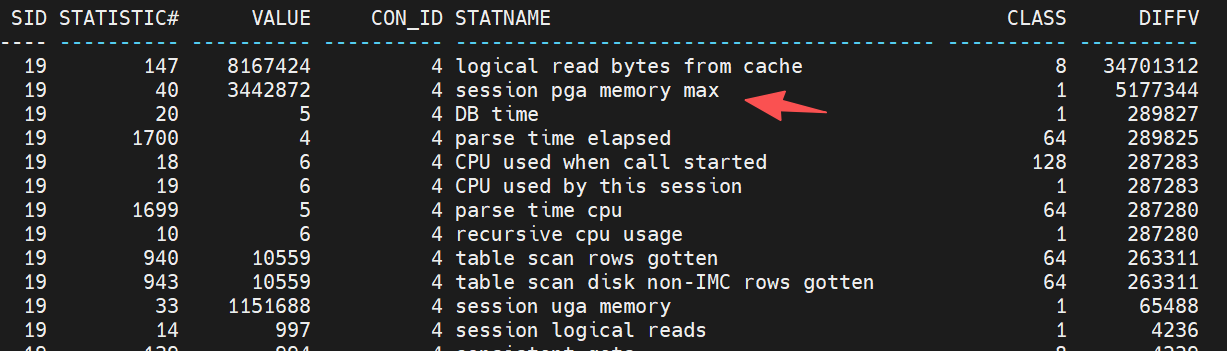
用deepseek分析一下:

SELECT sql_id, ROUND(SUM(pga_allocated)/1024/1024) AS total_pga_mb
FROM dba_hist_active_sess_history
WHERE sample_time > SYSDATE - 1/24
GROUP BY sql_id
ORDER BY total_pga_mb DESC
FETCH FIRST 10 ROWS ONLY;输出如下:
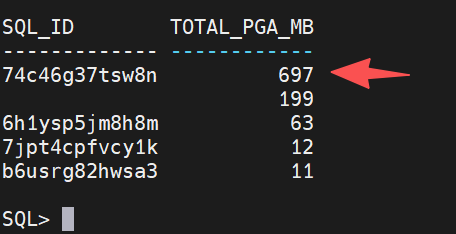
只有697MB的pga消耗,但是原因不是很清晰。
AI工具分析问题总是列出一堆可能情况,很可能误导决策,需要很好的经验来判断。不能给出准确的结论,应该是由于缺少信息,也许将 tfactl diagcollect -srdc dbrac结果发给原生的DEEPSEEK能够准确高效,下次试试。
总结一下:
1、高cpu还是先看会话状态,重点看event,本例中主要有SQL*Net more data from client 和PGA memory operation,这是因为session执行这类sql久了,自己发生了改变,其实都是一件事。cursor: pin S wait on X是多个会话执行的sql相同,后来的会话等第一个解析完成,还是在干同一件事,也就是说:45个非空闲会话都在解析这类有很多括号的语句。
2、找不到sql,可以尝试查询x$kglob底层视图;
2、数据库没有反应,可以考虑检查锁,或者通过 hanganalyze 分析状态;
3、查看 HM 自动诊断结果( dia0 进程的 trc 文件中),快捷得知数据库在干什么;
4、高CPU的进程,可以考虑 pstack 命令看看内部函数;
5、将 call stack 发送给 ai 工具协助诊断;
6、事件 PGA memory operation 并不一定代表 pga 不足。
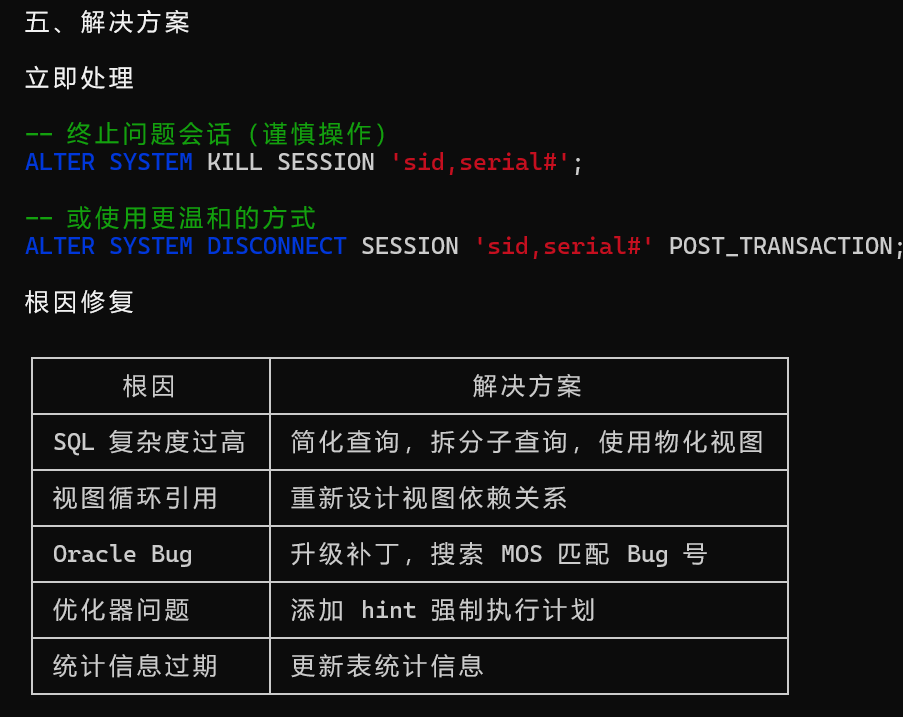
解决方法:
1、杀会话;
2、通知开发人员修改代码,去掉这些重复的括号;
3、如果sql里括号超过5层,就解决开发。
补充知识:
sql执行的5个阶段






说在最后:
感谢看到这里,一般来说,文档发布2周内可能会再更新部分内容,希望能有所帮助。

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐
 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)