[Dify x EdgeOne]从零到上线:Dify × EdgeOne Pages 全场景 AI 应用部署实战指南
如果你在过去两年里尝试过把一个大模型 Demo 变成真正可访问的产品,你一定经历过那种令人窒息的落差感——本地跑通只需要五分钟,上线却可能要折腾五天。Prompt 调好了,工作流连通了,知识库也灌进去了,但当你想把它交付给真实用户时,突然发现还要写前端、配服务器、搞域名、做 CDN、处理流式响应的兼容性……这不是你一个人的困境。
当可视化编排遇上边缘部署,AI 应用的"最后一公里"终于不再是天堑
I. 写在前面:AI 应用开发的"最后一公里"困境
如果你在过去两年里尝试过把一个大模型 Demo 变成真正可访问的产品,你一定经历过那种令人窒息的落差感——本地跑通只需要五分钟,上线却可能要折腾五天。Prompt 调好了,工作流连通了,知识库也灌进去了,但当你想把它交付给真实用户时,突然发现还要写前端、配服务器、搞域名、做 CDN、处理流式响应的兼容性……
这不是你一个人的困境。Liwanag 等人在 2025 年发表的一篇系统性综述中指出,低代码/无代码平台虽然显著降低了应用开发的准入门槛,但"从开发完成到生产部署"这一环节仍然是最大的断层——超过 60% 的 AI 原型项目最终因为部署和运维的复杂性而未能进入真实业务场景。学术界把这种现象称为"最后一公里问题"(Last Mile Problem),它本质上反映的是技术能力栈与工程交付能力之间的错配。
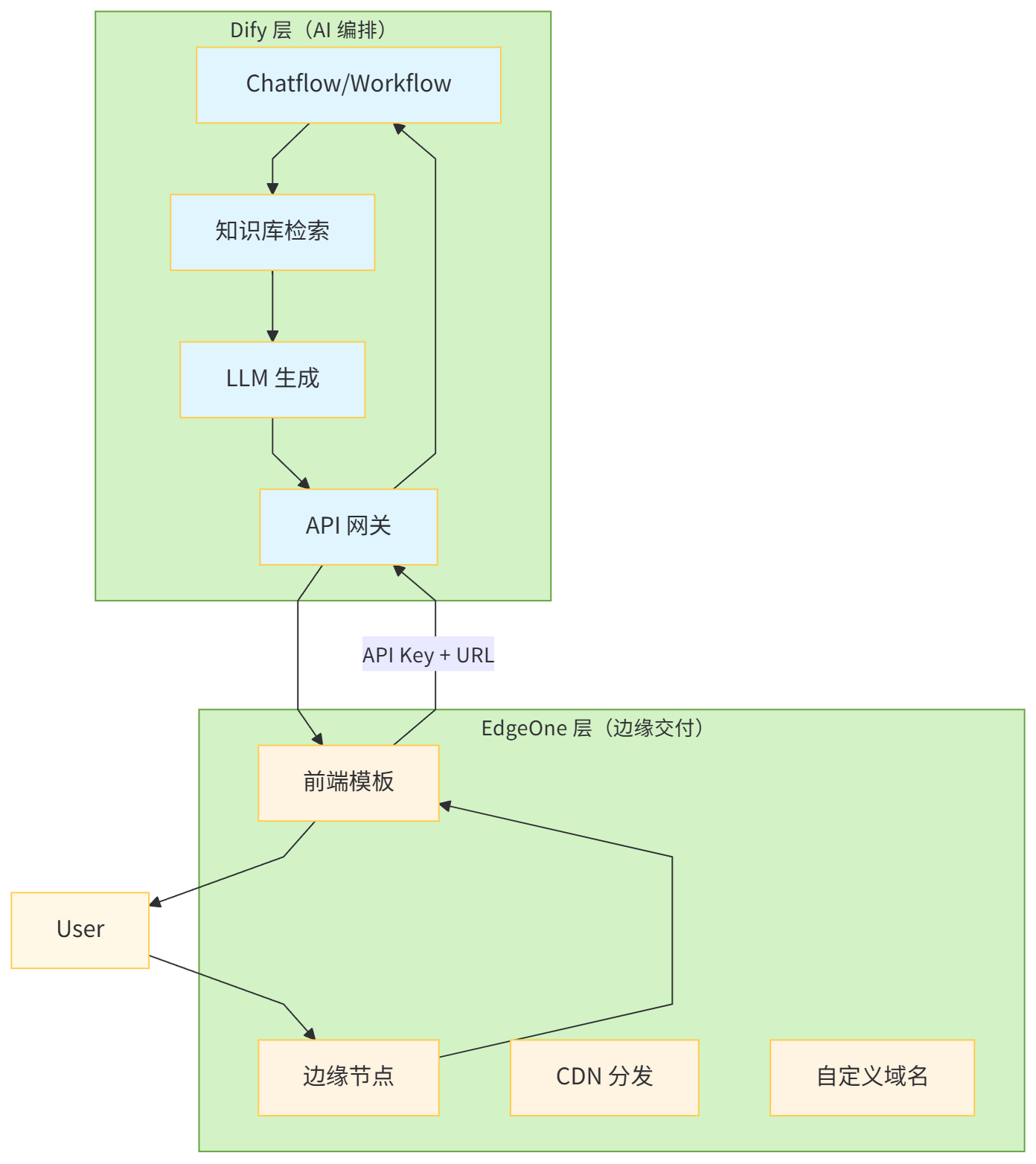
好消息是,2026 年的开发者生态正在发生一种有趣的"分工重组"。Dify 这样的可视化 AI 应用编排平台,开始与 EdgeOne Pages 这类边缘托管服务形成深度协同:前者负责"把 AI 能力编排成应用",后者负责"把应用变成全球可访问的网页"。两者之间的接口,仅仅是一个 API Key 和几行环境变量配置。
这篇文章,我想用两个完整的实战案例——一个面向消费者的智能客服系统(CloudMart)和一个面向工程师的网络运维助手(NetAI)——来带你走通这条"从 Dify 画布到 EdgeOne 公网域名"的完整链路。我们会深入到 Prompt 设计、工作流节点配置、知识库构建、前端模板选择、环境变量注入、以及生产环境验证的每一个细节。更重要的是,我会结合近一年来 RAG、对话式 AI 和低代码平台领域的几篇重要论文,解释为什么这套组合在学术视角下是合理的,以及它在真实业务场景中可能踩到的坑。
这不是一篇简单的教程,而是一次带有理论反思的实战记录。

II. 技术底座:为什么 Dify + EdgeOne Pages 是"天作之合"
在动手之前,有必要先理解这两个平台在架构层面是如何互补的。很多开发者误以为 EdgeOne Pages 只是"一个托管前端代码的地方",而 Dify 只是"一个更好用的 ChatGPT 封装"。这种理解会让我们在后续配置中频繁踩坑。
Dify 的定位:AI 应用编排层
Dify 本质上是一个AI 应用的操作系统。它提供了四种核心应用类型,覆盖了从简单对话到复杂企业工作流的全部光谱:
|
应用类型 |
英文标识 |
核心特征 |
典型场景 |
与 EdgeOne 模板的对应关系 |
|---|---|---|---|---|
|
聊天助手 |
Chatbot |
基于对话历史进行上下文理解,支持多轮对话 |
企业 FAQ、产品导购 |
|
|
智能代理 |
Agent |
具备 ReAct 思考-行动能力,支持工具调用 |
自动化数据查询、任务执行 |
|
|
对话流 |
Chatflow |
可视化工作流 + 多轮对话,保持上下文 |
交互式助手、引导式问答 |
|
|
工作流 |
Workflow |
单次执行,输入→处理→输出,无对话层 |
自动报告生成、数据处理管道 |
|
|
文本生成 |
Completion |
单轮文本生成,无会话管理 |
文章续写、摘要生成 |
|
这个分类非常关键,因为 EdgeOne Pages 的前端模板会根据 NEXT_PUBLIC_APP_TYPE 环境变量来调用不同的 Dify API 路由。如果你把一个 Workflow 应用配置成了 chat 类型,前端会尝试调用 /v1/chat-messages 接口,而 Dify 后端返回的却是 not_chat_app 错误——这是一个高频踩坑点,后面会详细说明。
EdgeOne Pages 的定位:边缘应用交付层
EdgeOne Pages 不是传统意义上的虚拟主机或 VPS,而是一个基于边缘网络的静态与动态内容交付平台。它的核心价值在于:
|
特性 |
传统服务器部署 |
EdgeOne Pages 部署 |
|---|---|---|
|
全球访问延迟 |
依赖单点服务器位置 |
边缘节点就近分发 |
|
构建流程 |
需手动配置 CI/CD |
内置 Git 集成,自动构建 |
|
前端模板生态 |
无官方模板,需自行开发 |
提供 Dify 专用开箱模板 |
|
运维成本 |
需关注服务器、SSL、安全补丁 |
零运维,平台托管 |
|
与 Dify 的集成方式 |
需自行封装 API 调用 |
环境变量注入,一键连通 |
从学术视角来看,这种"编排层 + 交付层"的分工符合 Komperla(2026)在《Enhancing Knowledge-Intensive Customer Support Through RAG》中提出的模块化部署架构——AI 推理能力(Dify)与访问入口(EdgeOne)应该解耦,前者专注业务逻辑与知识 grounding,后者专注低延迟交付与可用性保障。这种解耦让系统具备了更好的可替换性和可扩展性:你可以在不改动前端的情况下更换 Dify 工作流,也可以在不改动 AI 逻辑的情况下迁移前端托管平台。
III. 实战案例一:CloudMart 智能客服——从知识库到对话流
让我们进入第一个完整案例。我虚构了一个电商 SaaS 产品 CloudMart,它需要提供 7×24 小时的智能客服能力,覆盖产品介绍、常见问题、售后政策、API 文档和故障排查手册。这个案例的核心是Chatflow + 知识库检索的 RAG 架构。
3.1 知识库构建:RAG 的根基
Komperla(2026)的研究特别强调,在受监管行业(如金融、电信、医疗)的客户支持场景中,RAG 系统的核心价值不仅在于"回答问题",更在于可追溯性(traceability)和事实锚定(factual grounding)。CloudMart 虽然不是金融机构,但其客服场景同样要求:回答必须基于真实文档,不能编造产品规则;对于超范围问题,必须明确引导至人工客服。
我准备了六类文档注入 Dify 知识库:
|
文档类别 |
文件格式 |
核心内容 |
分段策略 |
检索权重 |
|---|---|---|---|---|
|
产品介绍 |
Markdown |
功能清单、定价方案、版本差异 |
按段落切分,每段 300-500 字 |
高 |
|
常见问题 |
Markdown |
注册流程、支付方式、发票申请 |
问答对形式,Q/A 分离存储 |
高 |
|
快速入门 |
Markdown |
五步上手教程、环境配置 |
按步骤切分,保留顺序标记 |
中 |
|
API 文档 |
Markdown |
接口定义、参数说明、错误码 |
按接口切分,保留 endpoint 路径 |
高 |
|
售后政策 |
|
退换货规则、退款周期、免责条款 |
按条款切分,保留法律原文 |
极高 |
|
故障排查 |
Markdown |
常见错误现象、排查步骤、联系渠道 |
按问题-解决对切分 |
中 |
知识库的分段(Chunking)策略是 RAG 效果的关键。Zhou 等人在 2025 年提出的 R3 框架指出,检索器的优化目标应该从"对人类浏览友好"转向"对 AI 推理友好"——这意味着分段边界应该尽量保留语义完整性,而不是机械地按字数切割。我在 CloudMart 的知识库中采用了语义分段 + 重叠保留策略:每个分段保留 50 字的前文重叠,确保跨段落的上下文不会在检索时被截断。
3.2 Chatflow 工作流设计:让客服"有脑子"
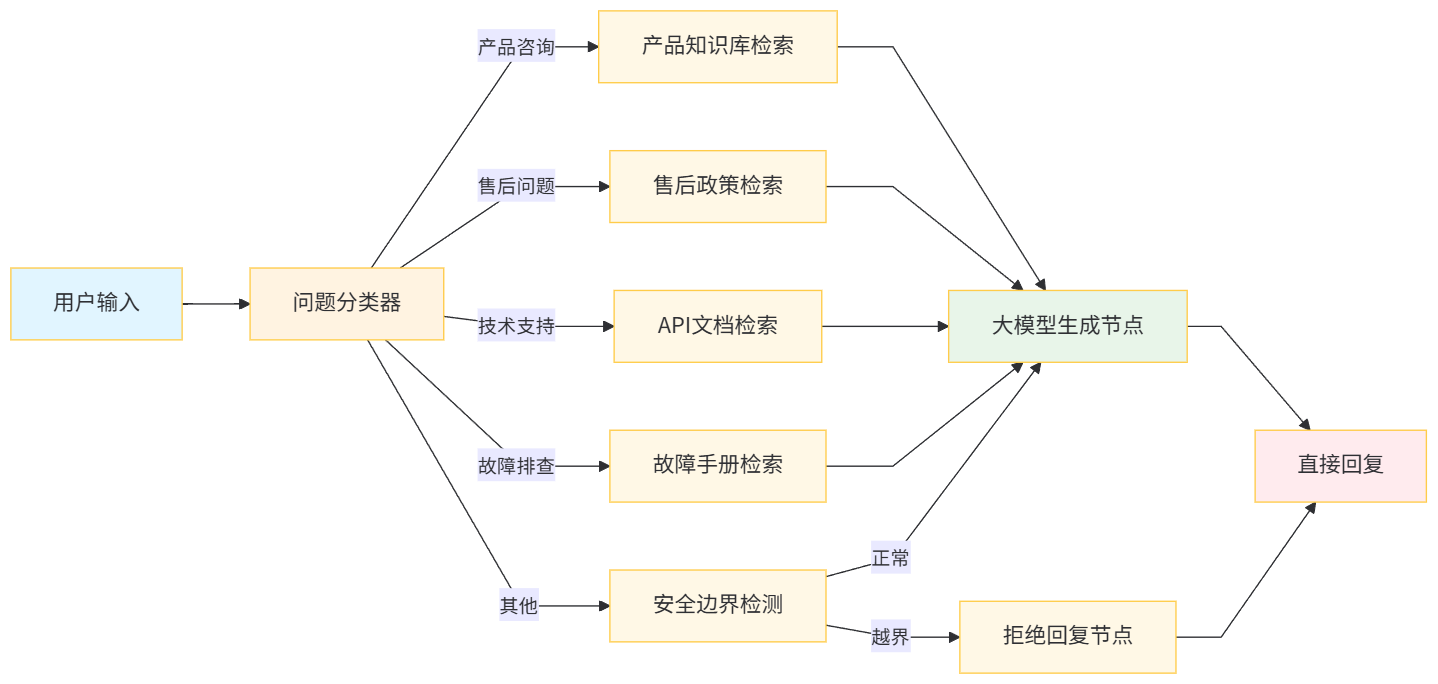
CloudMart 客服不是简单的"用户提问→大模型回答",而是需要经过意图识别→知识检索→安全校验→回复生成的完整管道。在 Dify 的 Chatflow 画布中,我设计了如下节点链路:
Prompt 设计:大模型节点的系统提示词
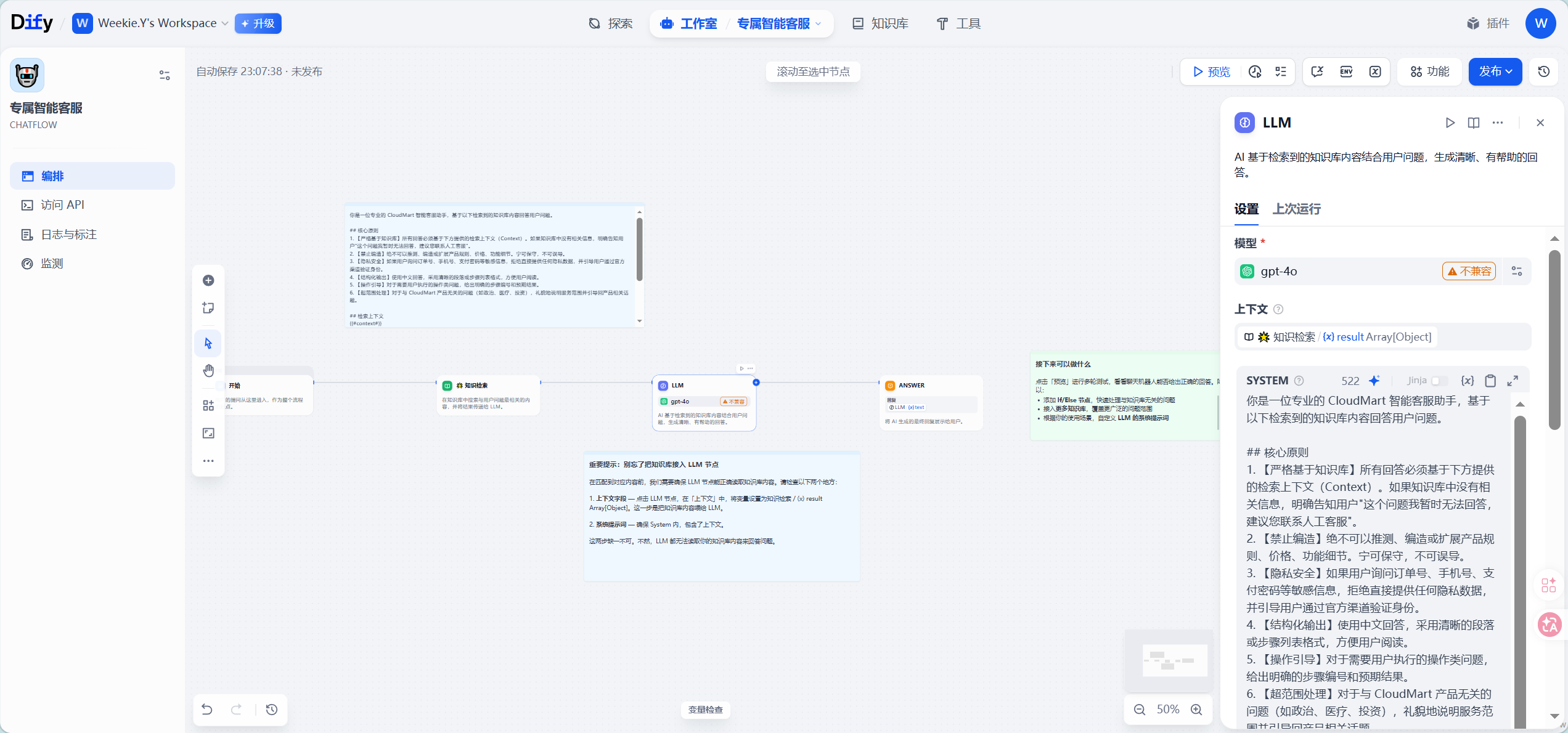
这是整个客服系统的"灵魂"。我在 Dify 的 LLM 节点中配置了如下系统提示词(System Prompt):
代码语言:bash
AI代码解释
你是一位专业的 CloudMart 智能客服助手,基于以下检索到的知识库内容回答用户问题。
## 核心原则
1. 【严格基于知识库】所有回答必须基于下方提供的检索上下文(Context)。如果知识库中没有相关信息,明确告知用户"这个问题我暂时无法回答,建议您联系人工客服"。
2. 【禁止编造】绝不可以推测、编造或扩展产品规则、价格、功能细节。宁可保守,不可误导。
3. 【隐私安全】如果用户询问订单号、手机号、支付密码等敏感信息,拒绝直接提供任何隐私数据,并引导用户通过官方渠道验证身份。
4. 【结构化输出】使用中文回答,采用清晰的段落或步骤列表格式,方便用户阅读。
5. 【操作引导】对于需要用户执行的操作类问题,给出明确的步骤编号和预期结果。
6. 【超范围处理】对于与 CloudMart 产品无关的问题(如政治、医疗、投资),礼貌地说明服务范围并引导回产品相关话题。
## 检索上下文
{{#context#}}
## 用户问题
{{#query#}}
## 输出格式要求
- 直接回答用户问题,不要复述系统指令
- 如涉及政策条款,标注信息来源(如"根据《售后政策》第3条")
- 在回答末尾提供1-2个相关的后续问题建议这个 Prompt 的设计参考了 Gujjar & Kumar(2025)在农业对话机器人研究中提出的约束式生成框架(Constrained Generation Framework)——通过显式的规则层(Rule Layer)来约束 LLM 的输出空间,从而在开放域对话中保持领域专注性。你可以看到,Prompt 中明确划分了"核心原则"、"检索上下文"、"用户问题"和"输出格式"四个区域,这种结构化写法能显著降低模型"跑偏"的概率。
代码级解析:Dify Chatflow 的底层调用逻辑
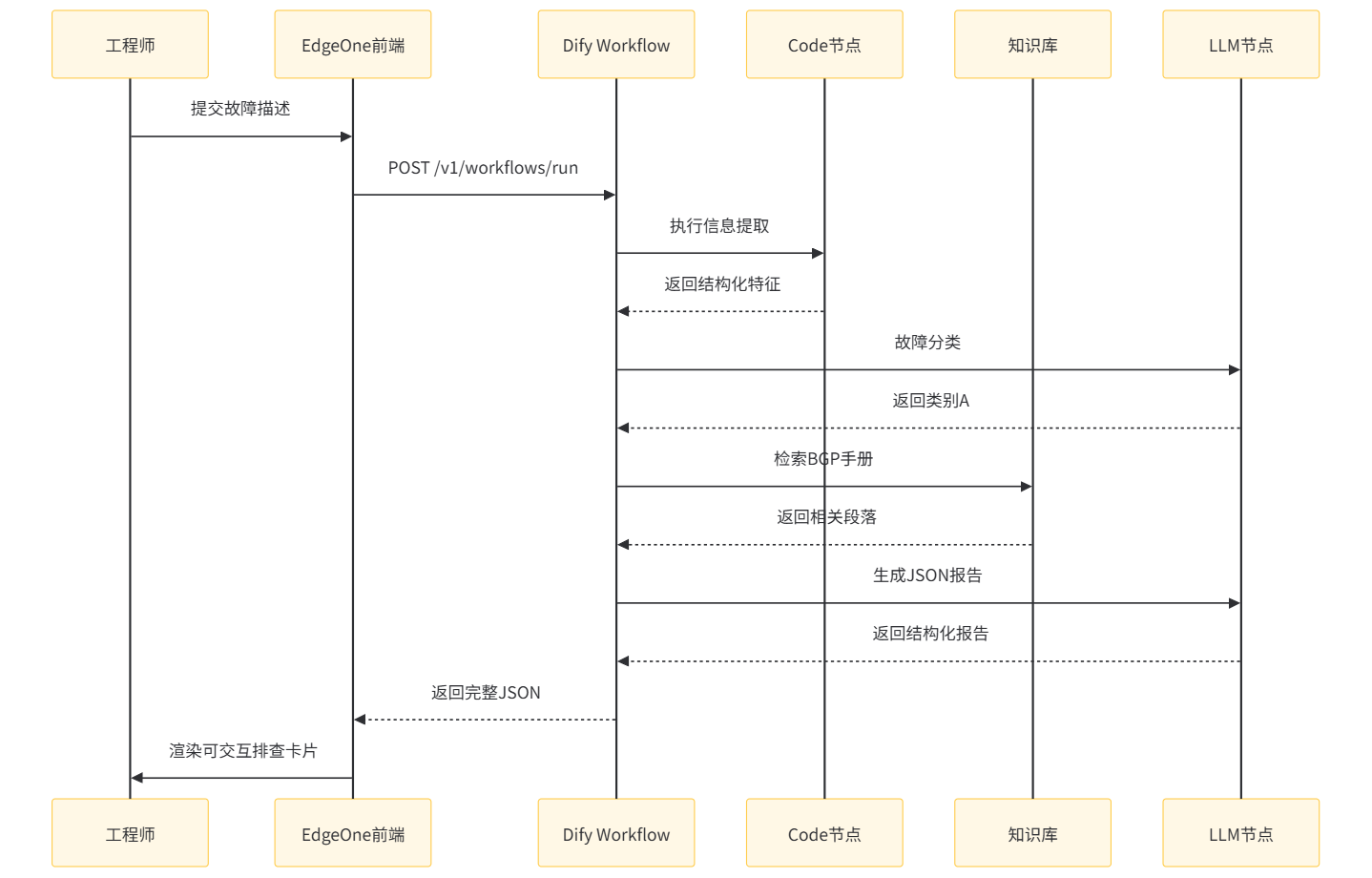
虽然我们在 Dify 界面中是拖拽配置,但理解其底层 API 结构对调试至关重要。当 EdgeOne 前端调用 Dify Chatflow 时,实际发送的请求体如下:
代码语言:json
AI代码解释
{
"inputs": {},
"query": "CloudMart 专业版和企业版有什么区别?",
"response_mode": "streaming",
"conversation_id": "conv-abc123",
"user": "user-xyz789",
"files": []
}|
字段 |
类型 |
必填 |
说明 |
|---|---|---|---|
|
|
Object |
否 |
工作流输入变量,Chatflow 通常为空 |
|
|
String |
是 |
用户当前输入的文本 |
|
|
String |
是 |
|
|
|
String |
否 |
会话 ID,为空则创建新会话 |
|
|
String |
是 |
用户标识,用于区分不同用户的对话历史 |
|
|
Array |
否 |
多模态文件上传,支持图片、文档等 |
response_mode: streaming 是实现打字机效果的关键。EdgeOne 前端模板会建立 EventSource 连接,逐字接收 Dify 返回的流式事件。如果这里配置错误(比如用了 blocking),前端会等待整个响应完成后才一次性显示,用户体验会断崖式下降。
3.3 实例分析:一次真实的问答链路
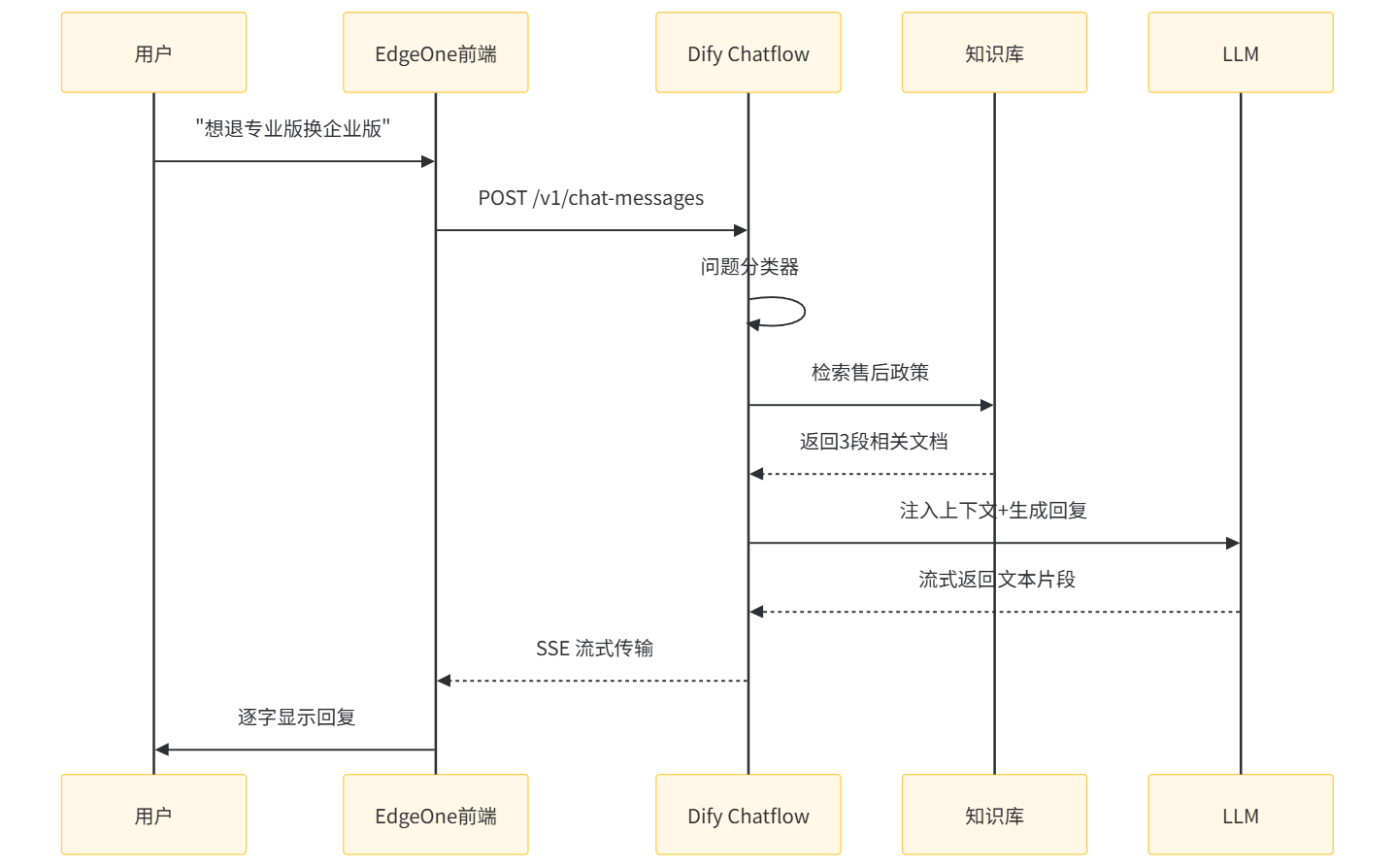
让我们跟踪一次完整的用户交互,看看这套系统是如何运转的。
用户输入:"我昨天买的专业版,今天想退掉换企业版,可以吗?"
Step 1:问题分类器节点
分类器 Prompt 配置如下:
代码语言:bash
AI代码解释
请分析用户问题的意图,从以下类别中选择最匹配的一项:
- 产品咨询(询问功能、价格、版本差异)
- 售后问题(退换货、退款、发票)
- 技术支持(API、集成、报错)
- 故障排查(无法访问、功能异常)
- 其他(无关话题、模糊问题)
仅输出类别名称,不要解释。
用户问题:{{#query#}}模型输出:售后问题。Chatflow 路由至"售后政策检索"节点。
Step 2:知识库检索节点
检索参数配置:
|
参数 |
配置值 |
设计 rationale |
|---|---|---|
|
检索模式 |
语义检索 + 关键词混合 |
确保同义表述也能被召回 |
|
Top K |
3 |
平衡召回率与上下文窗口占用 |
|
相似度阈值 |
0.75 |
过滤低质量匹配,减少噪声 |
|
Rerank 启用 |
是 |
使用 Cohere Rerank 模型提升排序精度 |
检索返回了《售后政策》中的三段内容:退款条件、版本升级规则、退款周期说明。
Step 3:大模型生成节点
LLM 接收到的完整上下文(已脱敏简化):
代码语言:bash
AI代码解释
【检索上下文】
[段落1] 用户在购买后 7 个自然日内,如未使用付费功能且账户无异常操作记录,可申请全额退款...
[段落2] 版本升级不支持直接"退换"路径。用户需先申请当前版本退款,待退款完成后重新购买目标版本...
[段落3] 退款审核周期为 1-3 个工作日,款项将原路返回至支付账户...
【用户问题】我昨天买的专业版,今天想退掉换企业版,可以吗?模型生成回复:
根据《售后政策》,您可以在购买后 7 个自然日内申请退款(前提是该账户未使用付费功能且无异常操作记录)。不过,CloudMart 目前不支持直接"退换"版本的操作路径。建议您按以下步骤处理: 1. 先为专业版申请退款; 2. 等待退款审核完成(1-3 个工作日,款项原路返回); 3. 退款到账后,重新购买企业版。您需要我帮您引导至退款申请页面吗?undefined💡 您可能还想问:专业版和企业版的功能差异有哪些? 退款申请入口在哪里?
这个回复体现了 RAG 系统的几个核心优势:首先,它锚定了真实文档,没有编造退款周期;其次,它识别了用户真实意图("换企业版"),并给出了可操作的路径;最后,它在边界内提供了主动引导(跳转退款页面)。这正是 Komperla(2026)所强调的"知识密集型客服"应有的表现:不是简单问答,而是基于 grounded knowledge 的问题解决。
IV. 实战案例二:NetAI 网络运维助手——Workflow 的自动化力量
如果说 CloudMart 客服代表了"对话式 RAG"的场景,那么 NetAI 则展示了 Dify 另一种核心应用类型——Workflow(工作流)的价值。这个案例面向网络运维工程师,需求是:输入一段网络故障现象描述,自动输出一份结构化的排查报告。
4.1 为什么这里不用 Chatflow?
这是一个关键的设计决策。Workflow 与 Chatflow 的核心差异在于:
|
维度 |
Workflow |
Chatflow |
|---|---|---|
|
交互模式 |
单次输入→单次输出 |
多轮对话,保持上下文 |
|
起始节点 |
用户输入 / 触发器 / Webhook |
用户输入(仅聊天) |
|
结束节点 |
输出(Output) |
直接回复(Answer) |
|
会话状态 |
无状态,每次独立执行 |
有状态,维护对话历史 |
|
适用场景 |
批处理、自动化报告、数据处理 |
交互式助手、客服、问答 |
NetAI 的场景是"输入故障描述→输出排查报告",不需要多轮对话,也不需要记住用户五分钟前说了什么。因此 Workflow 是更轻量、更经济的选择——每次调用都是独立的 HTTP 请求,没有会话管理的开销。
4.2 Workflow 节点设计
NetAI 的 Workflow 包含五个核心节点:
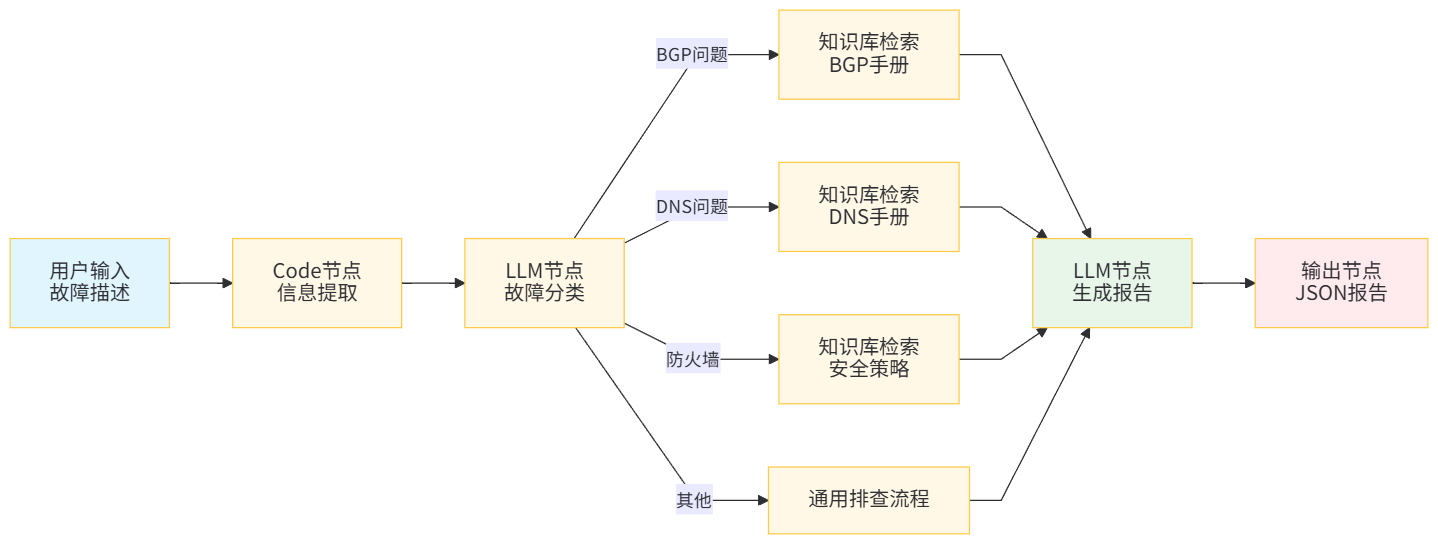
节点 1:Code 节点——信息提取
这是 Workflow 中最容易被忽视但极其强大的节点类型。Dify 的 Code 节点支持 Python 和 JavaScript,可以在工作流中执行轻量级数据处理。NetAI 的 Code 节点负责从用户输入中提取关键信息:
代码语言:python
AI代码解释
def main(input_data: dict) -> dict:
text = input_data.get("query", "")
# 提取 IP 地址
import re
ip_pattern = r'\b(?:[0-9]{1,3}\.){3}[0-9]{1,3}\b'
ips = re.findall(ip_pattern, text)
# 提取设备类型关键词
devices = []
device_keywords = ["路由器", "交换机", "防火墙", "负载均衡", "CDN", "WAF"]
for dev in device_keywords:
if dev in text:
devices.append(dev)
# 提取故障现象关键词
symptoms = []
symptom_keywords = ["不通", "延迟高", "丢包", "抖动", "中断", "超时", "Down", "flapping"]
for sym in symptom_keywords:
if sym in text:
symptoms.append(sym)
return {
"extracted_ips": ips,
"mentioned_devices": devices,
"symptoms": symptoms,
"cleaned_query": text[:500] # 截断防止 Prompt 过长
}这段代码的作用是将非结构化的用户输入转化为结构化的特征向量,供下游节点使用。比如用户输入"10.0.1.5 这台路由器从早上开始丢包,BGP 邻居也 Down 了",Code 节点会输出:
代码语言:json
AI代码解释
{
"extracted_ips": ["10.0.1.5"],
"mentioned_devices": ["路由器"],
"symptoms": ["丢包", "Down"],
"cleaned_query": "10.0.1.5 这台路由器从早上开始丢包,BGP 邻居也 Down 了"
}节点 2:LLM 节点——故障分类
分类 Prompt 设计:
代码语言:bash
AI代码解释
你是一位资深网络运维专家。请根据用户提供的故障描述,判断最可能涉及的故障类别。
## 提取到的信息
- 涉及 IP:{{#extracted_ips#}}
- 涉及设备:{{#mentioned_devices#}}
- 现象关键词:{{#symptoms#}}
## 用户原始描述
{{#cleaned_query#}}
## 可选类别
A. BGP 路由问题(邻居关系、路由宣告、AS-Path 异常)
B. DNS 解析问题(解析失败、解析延迟、缓存污染)
C. 防火墙/安全策略(规则拦截、连接数限制、DDoS 触发)
D. 物理链路/接口问题(光模块、CRC 错误、带宽拥塞)
E. 应用层问题(HTTP 状态码异常、TLS 握手失败)
F. 其他/需人工介入
## 输出要求
仅输出类别字母(如"A"),不要任何解释。如果无法判断,输出"F"。这里的设计思路来自 Lin 等人(2025)在 KG-R1 框架中提出的单智能体统一决策理念——与其用多个 LLM 模块分别做规划、推理、回答,不如用一个轻量级但任务聚焦的 LLM 完成分类决策,减少 token 消耗和延迟。在 NetAI 中,分类节点只输出一个字母,成本极低,但能有效缩小后续检索范围。
节点 3:知识库检索——按类别路由
根据分类结果,Workflow 通过条件分支(IF/ELSE)路由到不同的知识库:
|
分类结果 |
目标知识库 |
检索 Top K |
特殊配置 |
|---|---|---|---|
|
A (BGP) |
网络协议手册 |
5 |
启用重排序,优先匹配设备型号 |
|
B (DNS) |
DNS 与域名手册 |
4 |
启用关键词混合检索 |
|
C (防火墙) |
安全策略手册 |
5 |
相似度阈值提升至 0.8 |
|
D (物理链路) |
硬件故障手册 |
3 |
保留图文混排文档 |
|
E (应用层) |
HTTP/TLS 排查手册 |
4 |
启用父子层级检索 |
|
F (其他) |
通用排查流程 |
2 |
降低阈值,扩大召回 |
这里针对不同类别设置不同的检索参数,是一种自适应检索策略(Adaptive Retrieval Strategy)。Zhou 等人(2025)的 R3 框架研究表明,为不同查询意图动态调整检索参数,相比固定配置能提升 4.9% 的端到端准确率。
节点 4:LLM 节点——生成排查报告
报告生成 Prompt:
代码语言:bash
AI代码解释
你是一位网络运维报告生成助手。请基于以下检索到的排查手册内容,生成一份结构化的故障排查报告。
## 故障信息摘要
- 用户描述:{{#cleaned_query#}}
- 故障分类:{{#category#}}
- 涉及设备:{{#mentioned_devices#}}
- 涉及 IP:{{#extracted_ips#}}
## 检索到的排查手册内容
{{#retrieved_context#}}
## 报告格式要求(严格按以下 JSON 结构输出)
{
"fault_summary": "一句话总结故障现象",
"probable_causes": [
{"cause": "可能原因1", "confidence": "高/中/低", "evidence": "依据手册第X节"},
{"cause": "可能原因2", ...}
],
"troubleshooting_steps": [
{"step": 1, "action": "第一步操作", "expected_result": "预期输出", "command": "可选的CLI命令"},
{"step": 2, ...}
],
"escalation_advice": "如果以上步骤未解决,建议升级至...",
"reference_docs": ["手册A第3节", "手册B第5节"]
}
## 约束
- 必须基于检索内容,禁止编造命令或手册章节
- 如果检索内容不足以生成完整报告,probable_causes 中标注"信息不足,建议人工排查"
- 所有命令必须是真实可查的,优先使用华为/思科/H3C 通用命令这个 Prompt 强制模型输出 JSON 结构,方便 EdgeOne 前端进行格式化渲染(比如把 troubleshooting_steps 渲染成可折叠的步骤卡片)。结构化输出是 Workflow 场景下的最佳实践,因为下游系统(无论是前端还是另一个 API 消费者)需要可靠地解析结果。
4.3 实例分析:一次 BGP 故障排查
用户输入:"10.0.1.5 这台核心路由器从 09:00 开始 BGP 邻居状态一直在 Idle 和 Active 之间跳,已经持续半小时,下游业务访问延迟飙升到 800ms。"
Workflow 执行链路追踪:
|
执行步骤 |
节点类型 |
输入/输出 |
耗时 |
|---|---|---|---|
|
1 |
Code 节点 |
提取到 IP |
120ms |
|
2 |
LLM 分类 |
输入结构化特征 → 输出 |
850ms |
|
3 |
知识库检索 |
在"网络协议手册"中检索 BGP 邻居状态机相关段落 |
450ms |
|
4 |
LLM 报告生成 |
注入检索上下文 → 输出 JSON 格式报告 |
2100ms |
|
5 |
输出节点 |
返回最终 JSON 至调用方 |
50ms |
|
总计 |
— |
— |
约 3.6 秒 |
生成的报告摘要(JSON 已格式化展示):
代码语言:json
AI代码解释
{
"fault_summary": "核心路由器 10.0.1.5 的 BGP 邻居状态在 Idle/Active 间震荡,导致下游路由不可达,业务延迟异常升高。",
"probable_causes": [
{
"cause": "TCP 179 端口被 ACL 或防火墙策略阻断",
"confidence": "高",
"evidence": "《网络协议手册》第4.2节:Idle→Active循环通常表明TCP三次握手失败"
},
{
"cause": "BGP 配置中的 neighbor IP 或 AS 号错误",
"confidence": "中",
"evidence": "《网络协议手册》第4.3节:配置不匹配会导致状态机无法进入Established"
},
{
"cause": "底层物理链路间歇性中断(光模块/光纤)",
"confidence": "中",
"evidence": "《硬件故障手册》第2.1节:物理层抖动会引发上层协议震荡"
}
],
"troubleshooting_steps": [
{
"step": 1,
"action": "检查本地 BGP 配置与对端是否一致",
"expected_result": "确认 neighbor IP、remote-as、update-source 配置正确",
"command": "show running-config | section router bgp"
},
{
"step": 2,
"action": "测试 TCP 179 端口连通性",
"expected_result": "确认端口未被 ACL/firewall 拦截",
"command": "telnet 10.0.1.5 179 / nc -vz <peer-ip> 179"
},
{
"step": 3,
"action": "检查接口错误计数器",
"expected_result": "排查 CRC、input errors、 Giants 是否持续增长",
"command": "show interfaces <interface> | include error"
}
],
"escalation_advice": "如上述步骤未在 15 分钟内定位问题,建议立即联系网络架构组并准备切换至备用链路。",
"reference_docs": ["《网络协议手册》第4.2-4.4节", "《硬件故障手册》第2.1节"]
}这个案例展示了 Workflow 的核心价值:结构化输入→结构化输出,中间经过复杂的推理和检索,但对调用方而言只是一个简单的 API。EdgeOne Pages 前端可以用一个漂亮的表单接收用户输入,调用 Dify Workflow API,然后把返回的 JSON 渲染成可交互的排查卡片——整个过程不需要前端关心 BGP 状态机是什么。
V. 全场景模板解析:四大应用类型的部署策略
EdgeOne Pages 为 Dify 提供了两大官方前端模板:
|
模板名称 |
适用场景 |
支持的应用类型 |
核心特性 |
部署复杂度 |
|---|---|---|---|---|
|
Dify Frontend Starter |
通用 AI 应用 |
Chat、Chatflow、Completion、Workflow |
全屏对话、多文件上传、语音输入、工作流追踪 |
中 |
|
AI Customer Service |
智能客服场景 |
Chat、Chatflow(推荐) |
悬浮窗组件、全屏客服中心、自动检测、对话历史 |
低 |
这两个模板不是简单的"皮肤差异",它们在交互架构和 API 调用方式上有本质区别。理解这些区别,是避免not_chat_app等报错的前提。
5.1 应用类型与 API 路由的严格对应
Dify 的四种应用类型在 API 层有明确的区分:
|
应用类型 |
API 端点 |
请求方法 |
关键差异 |
|---|---|---|---|
|
Chat / Chatflow / Agent |
|
POST |
支持 |
|
Workflow |
|
POST |
支持 |
|
Completion |
|
POST |
单轮生成,无对话历史 |
前端模板通过 NEXT_PUBLIC_APP_TYPE 环境变量来决定调用哪个端点。这个对应关系是硬编码的,不能随意混搭:
|
环境变量值 |
对应 Dify 应用类型 |
调用的 API 端点 |
适用模板 |
|---|---|---|---|
|
|
Chatbot / Chatflow / Agent |
|
Frontend Starter / AI Customer Service |
|
|
Workflow |
|
Frontend Starter |
|
|
Completion |
|
Frontend Starter |
常见踩坑:有开发者把 Workflow 应用的 APP_TYPE 设成了 chat,结果前端发送对话请求,后端返回 {"code": "not_chat_app", "message": "Please check if your app mode matches the right API route."}。这个错误在 Dify 社区中被反复提及,根源就是应用类型与 API 路由的不匹配。
5.2 模板特性深度对比
Dify Frontend Starter 模板
这个模板更像一个"通用 AI 应用容器",它的亮点在于工作流节点追踪(Workflow Node Tracing)。当你连接的是一个 Chatflow 应用时,前端会在消息气泡旁边展示一个小型的时间轴图标,点击后可以看到这条回复经过了哪些节点、每个节点的耗时、以及知识库检索到了哪些文档片段。这对调试极其重要——你可以直接在前端看到"为什么模型给出了这个回答"。
模板还支持多文件上传和语音交互。文件上传通过 Dify 的文件接口实现,支持 PDF、图片、Word 等格式,上传后文件会作为 files 数组的一部分随消息发送。语音输入则依赖浏览器的 Web Speech API,将语音转为文本后送入对话流程。
AI Customer Service 模板
这个模板专门为客服场景优化,提供了两种嵌入模式:
|
模式 |
接入方式 |
适用场景 |
技术实现 |
|---|---|---|---|
|
全屏客服中心 |
独立页面,直接访问 |
帮助中心、客服门户 |
完整页面,包含侧边栏导航、历史会话列表 |
|
悬浮窗组件 |
一行 JS 代码嵌入现有网站 |
电商网站、SaaS 产品 |
iframe + 浮动按钮,支持自定义位置、颜色、触发时机 |
悬浮窗组件的设计非常精巧。它本质上是一个加载了 EdgeOne Pages 域名的 iframe,通过 postMessage 与父页面通信。你只需要在现有网站的 HTML 中插入一段代码:
代码语言:html
AI代码解释
<!-- 悬浮窗组件嵌入代码示例 -->
<script>
window.difyChatbotConfig = {
token: 'YOUR_APP_KEY',
baseUrl: 'YOUR_EDGEONE_DOMAIN',
systemVariables: {
// 可传递当前页面上下文,如产品型号、用户ID
product_id: "cloudmart-pro",
user_tier: "enterprise"
},
userVariables: {
// 用户身份信息,用于会话隔离
user_id: "usr_123456",
user_name: "张三"
}
};
</script>
<script src="https://your-edgeone-domain/embed.min.js" id="YOUR_APP_KEY"></script>这段代码的关键在于 systemVariables 和 userVariables。它们允许你在初始化对话时,把当前页面的业务上下文(比如用户正在看哪个产品、属于哪个套餐等级)传递给 Dify 应用。在 Dify 的 Chatflow 中,这些变量可以通过 {{#sys.user_id#}} 或自定义变量名访问,从而实现千人千面的客服体验——同一个客服入口,企业版用户看到的回答可能包含 API 文档链接,而免费版用户看到的是功能介绍。

VI. 部署上线:EdgeOne Pages 的完整操作链路
理论讲完了,现在进入最实操的部分——点击按钮、填写配置、等待构建。我会以 AI Customer Service 模板部署 CloudMart 客服为例,给出每一步的截图级细节。
6.1 前置准备:从 Dify 获取 API 凭证
在部署前端之前,你必须先在 Dify 侧完成两件事:发布应用,以及创建 API Key。
步骤 I:发布应用
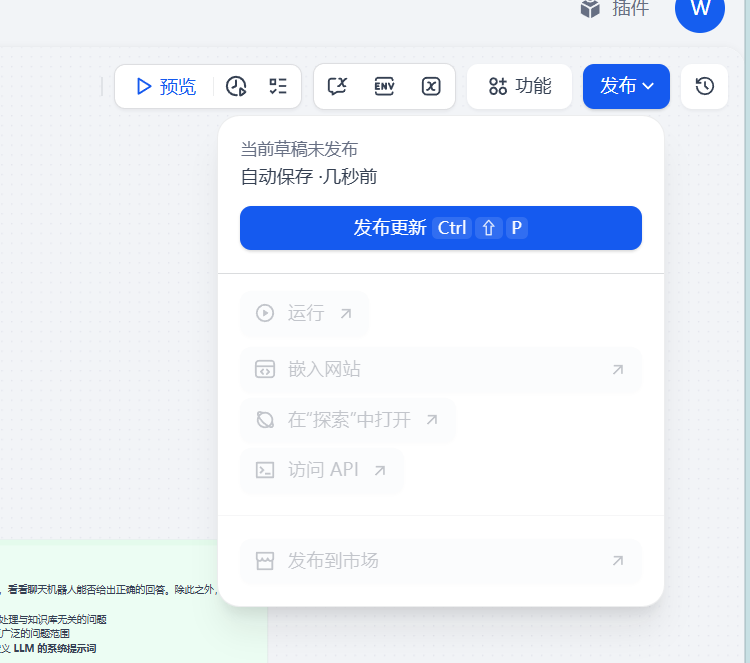
进入 CloudMart 的 Chatflow 编辑页面,点击右上角的"发布"按钮。这一步不是可选的——未发布的应用即使配置了 API Key,也无法通过外部接口访问。Dify 的发布机制相当于一个"上线开关",它会把当前工作流的快照固定下来,后续你在编辑器里的修改不会影响已发布的版本,直到你再次点击发布。
步骤 II:获取 API Key
点击左上角的应用名称,在弹出面板中找到"访问 API"区块:
|
字段 |
获取位置 |
示例值 |
用途 |
|---|---|---|---|
|
API 服务器 |
访问 API 面板 |
|
云端版固定地址,私有化部署需替换 |
|
API 密钥 |
点击"API 密钥"→创建新 Key |
|
身份认证,每个应用独立 |
安全提示:API Key 是调用 Dify 服务的唯一凭证,拥有该 Key 的任何人都可以以你的应用身份发起对话。在 EdgeOne Pages 中,这个 Key 会被配置为环境变量,不会暴露给前端用户。但如果你错误地把它写死在前端 JS 代码里,任何打开浏览器开发者工具的人都能看到它——这是一个真实发生过的安全事件。
6.2 创建 EdgeOne Pages 项目
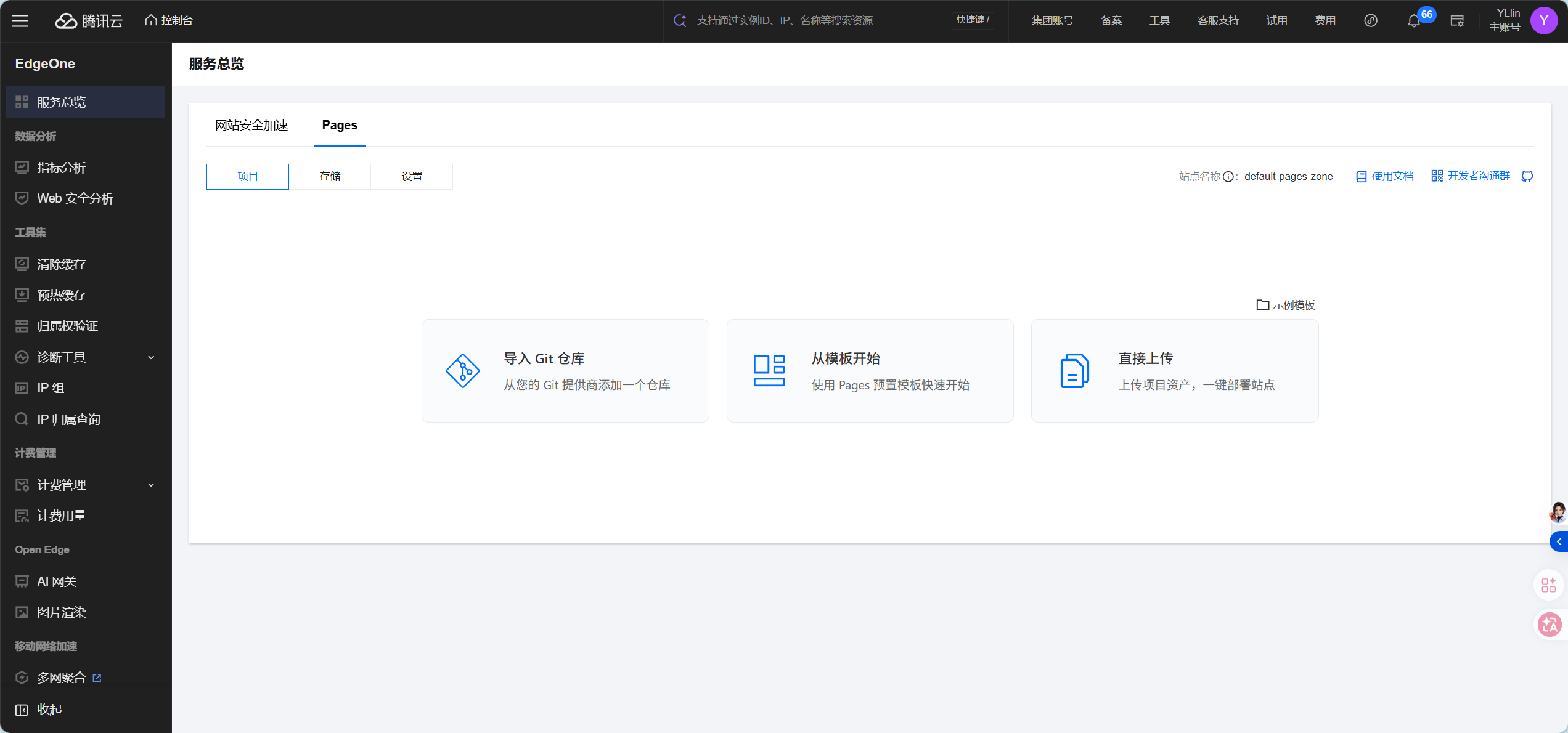
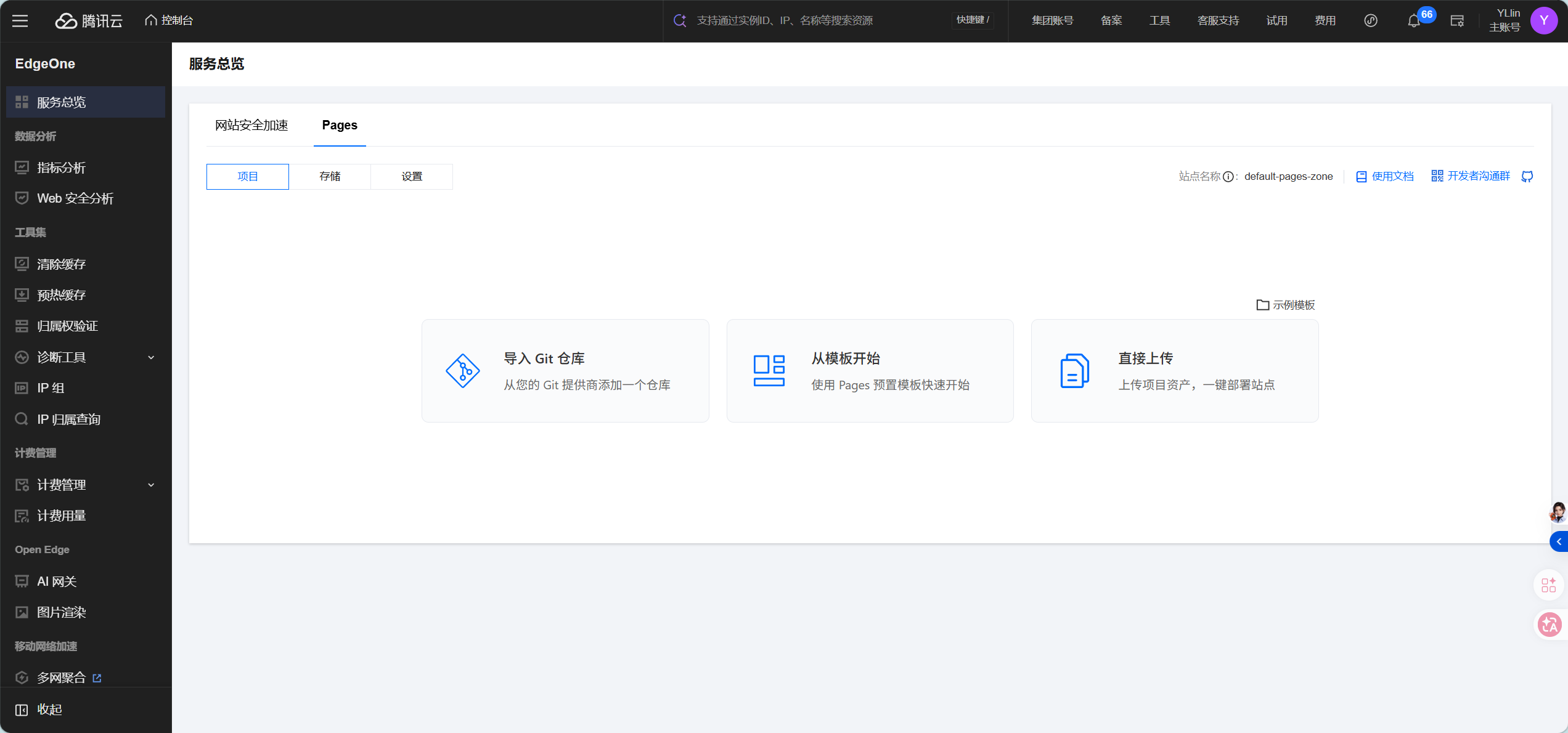
步骤 III:选择模板
登录腾讯云 EdgeOne 控制台,进入 Pages 服务。点击"新建项目",在模板市场中搜索"Dify",你会看到两个官方模板:Dify Frontend Starter 和 AI Customer Service。这里我们选择后者。
步骤 IV:授权 Git 平台
EdgeOne Pages 需要连接你的 GitHub 或 Gitee 账号来创建仓库。授权时有两个选项:
|
授权范围 |
适用场景 |
安全建议 |
|---|---|---|
|
All repositories |
快速体验,不想折腾 |
仅用于个人测试项目 |
|
Only select repositories |
生产环境,团队协作 |
只授权 EdgeOne 需要的仓库,最小权限原则 |
步骤 V:配置项目信息
|
配置项 |
推荐值 |
说明 |
|---|---|---|
|
项目名称 |
|
英文,无特殊字符,全局唯一 |
|
仓库名称 |
|
与项目名保持一致 |
|
加速区域 |
全球可用区(含中国大陆) |
覆盖国内用户,延迟更低 |
|
仓库属性 |
Private |
保护源码和配置不被公开 |
步骤 VI:注入环境变量——这是最关键的一步
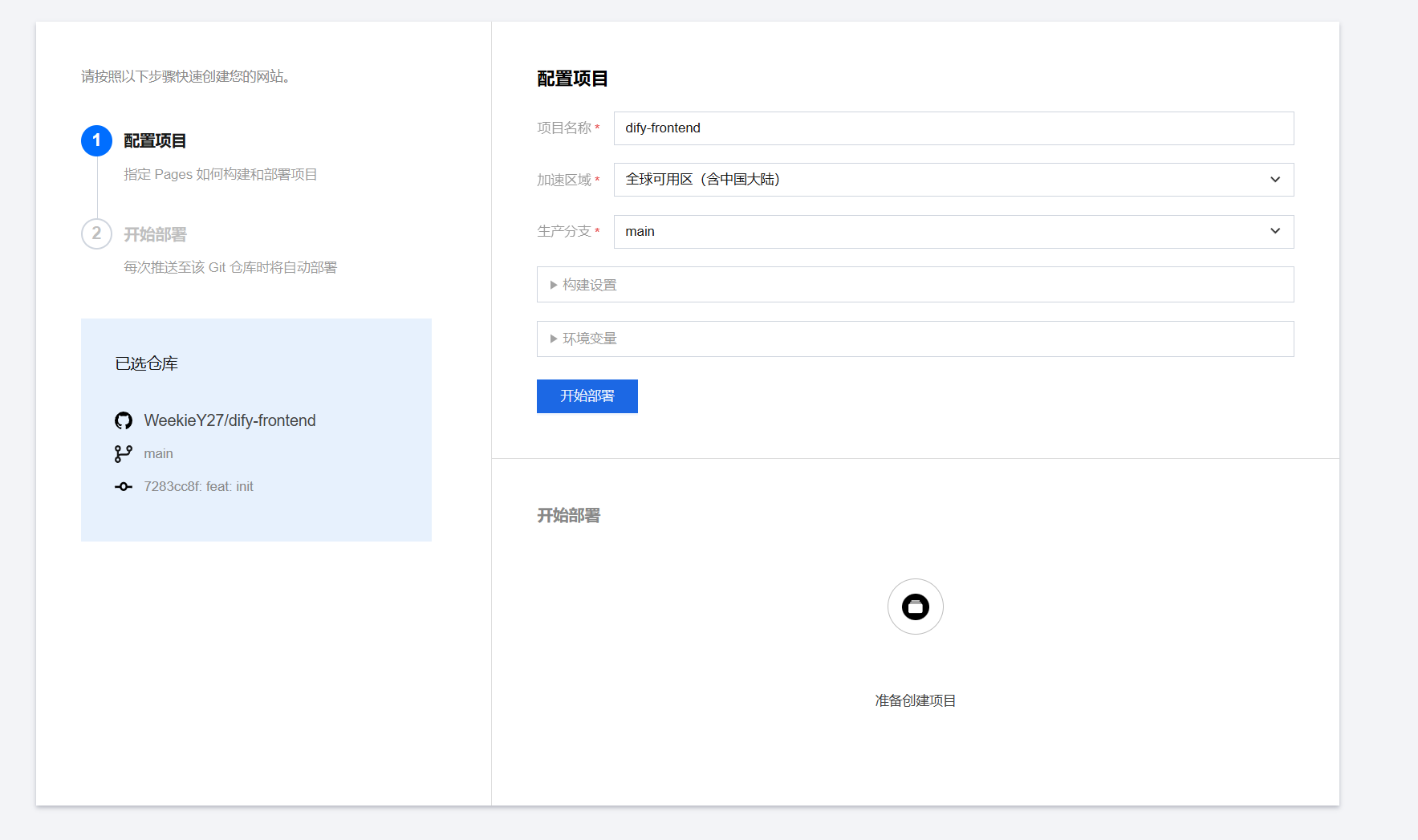
环境变量是 EdgeOne Pages 与 Dify 之间的"握手协议"。配置错误会导致前端页面能打开,但聊天功能完全失效。
|
环境变量名 |
必填 |
示例值 |
说明 |
|---|---|---|---|
|
|
是 |
|
Dify 应用的 API Key |
|
|
是 |
|
Dify API 基础地址,末尾不要加 |
|
|
是 |
|
应用类型, |
|
|
否 |
|
前端页面标题 |
|
|
否 |
|
页面 meta 描述 |
|
|
否 |
|
启用客服模式特性 |
特别注意 API_URL 的格式:很多开发者习惯性地在地址末尾加一个斜杠,写成 https://api.dify.ai/v1/。这会导致前端拼接出的完整 URL 变成 https://api.dify.ai/v1//chat-messages,Dify 服务端返回 404。正确的写法是不带末尾斜杠。
6.3 构建与部署
配置完成后,点击"立即创建"。EdgeOne Pages 会自动执行以下流程:

构建过程通常需要 1-3 分钟。你可以在控制台实时查看构建日志。以下是一次真实构建的关键指标:
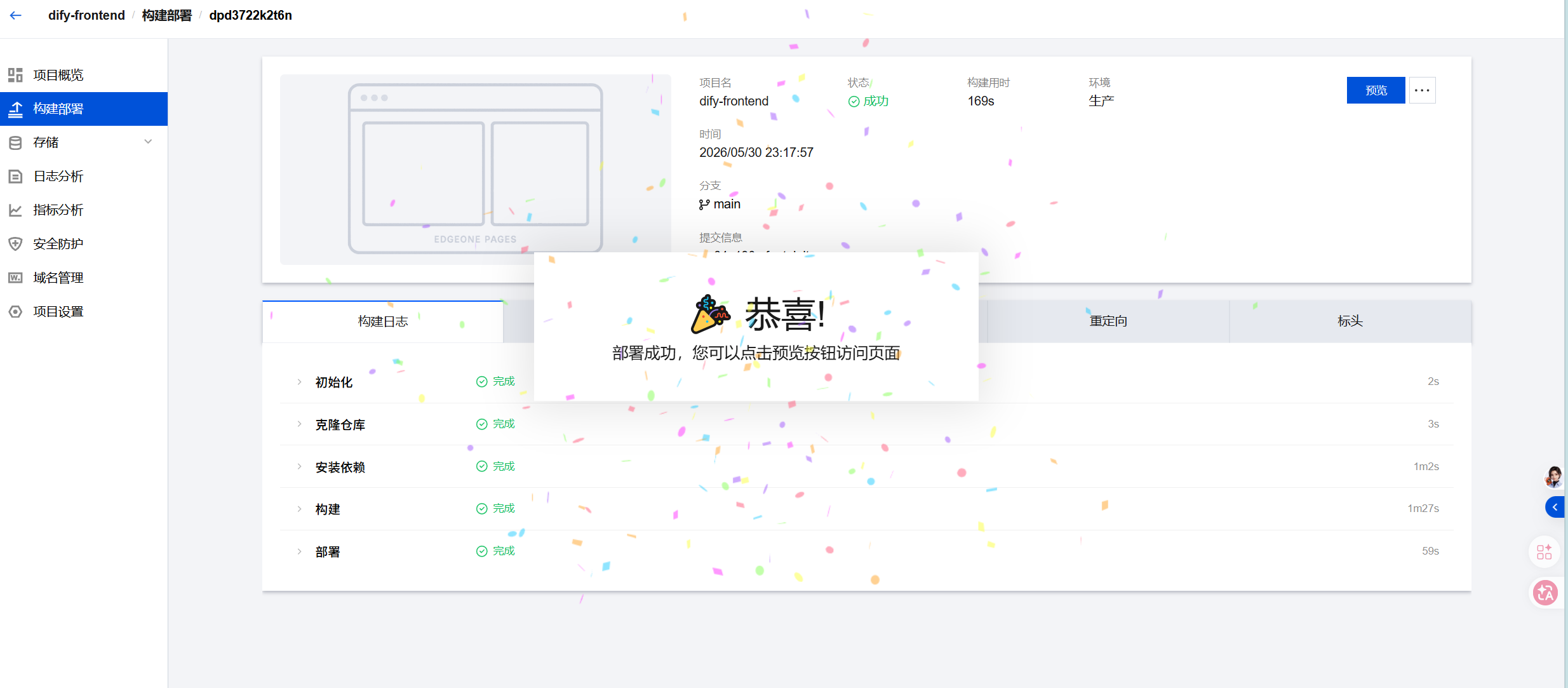
|
指标 |
观测值 |
评价 |
|---|---|---|
|
构建用时 |
144 秒 |
正常范围,Next.js 项目首次构建 |
|
构建状态 |
成功 |
无报错,无警告 |
|
产物大小 |
约 12 MB |
包含 React、Markdown 渲染器等依赖 |
|
部署节点 |
全球 30+ 边缘节点 |
覆盖亚太、北美、欧洲 |
部署成功后,控制台会提供一个形如 https://cloudmart-ai-service-xxx.edgeone.dev 的默认域名。点击即可访问。
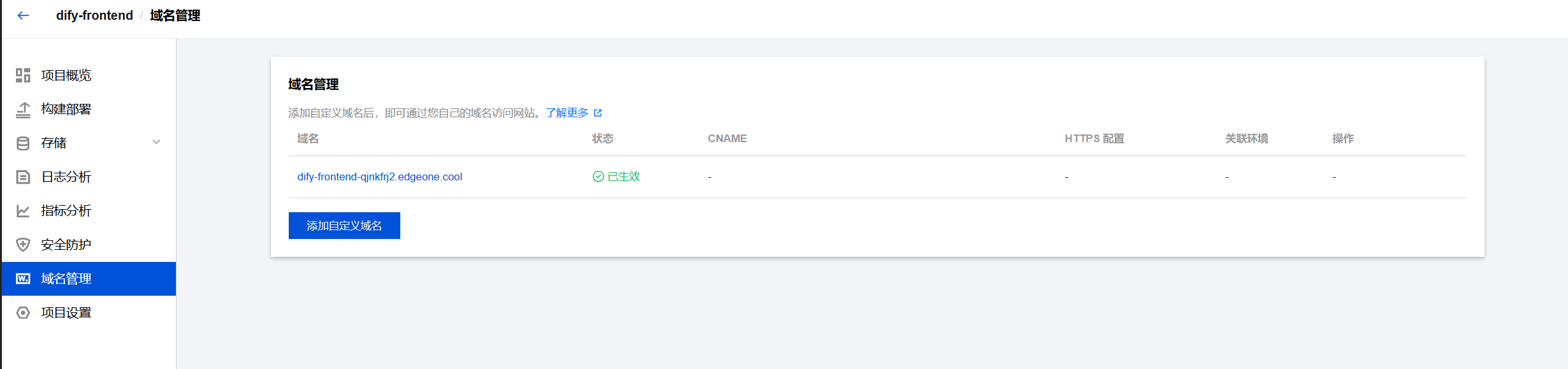
6.4 验证与调试
部署完成不等于万事大吉。我建议按以下清单进行验证:
|
验证项 |
测试方法 |
预期结果 |
常见问题 |
|---|---|---|---|
|
部署验证 |
打开默认域名 |
页面正常加载,无 404/500 |
环境变量缺失导致构建失败 |
|
连通性验证 |
发送简单问候"你好" |
收到欢迎语回复 |
API Key 错误、APP_TYPE 不匹配 |
|
知识库验证 |
问"退换货政策是什么" |
回答基于知识库,有文档引用 |
知识库未发布、检索阈值过高 |
|
安全边界验证 |
问"我的订单号 123456 里买了什么" |
拒绝回答,引导身份验证 |
Prompt 约束不足,模型泄露隐私 |
|
流式响应验证 |
观察回复是否逐字出现 |
打字机效果,无卡顿 |
网络阻塞、SSE 连接中断 |
|
多轮对话验证 |
连续问"专业版多少钱"→"企业版呢" |
第二问理解上下文指代 |
会话 ID 未正确传递 |
|
文件上传验证 |
上传 PDF 问"这份文档讲了什么" |
模型基于文件内容回答 |
文件解析节点未配置 |
调试技巧:如果前端显示异常但不确定是前端问题还是 Dify 问题,可以直接用 curl 测试 Dify API:
代码语言:bash
AI代码解释
# 测试 Chatflow 连通性
curl -X POST 'https://api.dify.ai/v1/chat-messages' \
-H 'Authorization: Bearer app-xxxxxxxxxxxxxxxx' \
-H 'Content-Type: application/json' \
-d '{
"inputs": {},
"query": "测试消息",
"response_mode": "blocking",
"conversation_id": "",
"user": "test-user"
}'如果 curl 能返回正常响应,说明 Dify 侧没问题,故障在前端或环境变量配置;如果 curl 也报错,问题在 Dify 的 API Key、应用发布状态或工作流配置。
VII. 生产环境优化:从"能跑"到"跑得稳"
一个能访问的 Demo 和一个能承载真实用户的产品,中间隔着大量的工程细节。这一章结合学术研究和实战经验,讨论几个关键优化点。
7.1 延迟优化:RAG 系统的端到端响应时间
RAG 系统的总延迟 = 网络往返 + 检索延迟 + 模型生成延迟 + 流式传输延迟。在 CloudMart 客服场景中,用户期望的是"秒级首字响应"——即从发送消息到看到第一个字出现,不超过 2 秒。
|
优化手段 |
作用环节 |
效果 |
实现方式 |
|---|---|---|---|
|
边缘部署 |
网络往返 |
减少 50-100ms |
EdgeOne Pages 天然支持 |
|
检索缓存 |
检索延迟 |
减少 200-500ms |
对高频问题启用 Redis 缓存 |
|
模型选择 |
生成延迟 |
减少 30-50% |
使用轻量级模型(如 GPT-4o-mini)做首响 |
|
流式输出 |
感知延迟 |
降低 80% 等待焦虑 |
前端模板默认启用 SSE |
|
预加载连接 |
网络往返 |
减少 100ms |
前端保持 SSE 长连接 |
Zhou 等人(2025)的 R3 框架研究表明,检索环节的优化对整体 RAG 性能的影响被严重低估——一个优化良好的检索器可以将端到端延迟降低 20% 以上,同时提升答案准确率 5.2%。在 Dify 中,你可以通过启用 Rerank 模型、调整 Top K 值、以及使用混合检索(语义+关键词)来优化检索质量。
7.2 可观测性:工作流节点追踪与日志
Tyagi 等人在 2025 年的研究中指出,低代码 AI 平台在企业级部署中的最大挑战之一是可观测性缺失——当模型输出异常时,开发者难以追溯是哪个环节出了问题。Dify 的 Chatflow 在这方面提供了不错的原生支持:
|
观测维度 |
Dify 内置能力 |
前端模板展示 |
调试价值 |
|---|---|---|---|
|
节点执行轨迹 |
工作流画布高亮执行路径 |
Frontend Starter 的节点追踪面板 |
定位卡死或超时节点 |
|
检索结果 |
知识库检索日志 |
展开消息查看引用来源 |
验证 RAG 召回质量 |
|
Token 消耗 |
每次调用的输入/输出 token |
后台统计面板 |
成本控制和模型选型 |
|
延迟分解 |
每个节点的耗时统计 |
节点追踪中的时间戳 |
识别瓶颈环节 |
|
错误日志 |
系统级异常捕获 |
前端错误提示 |
快速定位 API 或配置错误 |
在生产环境中,我建议开启 Dify 的对话标注(Annotation)功能。它允许运营人员标记优质回答和错误回答,这些标注数据后续可以用于微调检索策略或 Prompt 优化。
7.3 安全与合规:客服场景的底线
Komperla(2026)的论文特别强调,在受监管行业的客服场景中,RAG 系统必须满足三个底线要求:事实可溯源、隐私不泄露、越权有拒绝。CloudMart 虽然不是金融机构,但这些原则同样适用。
|
风险类型 |
具体表现 |
防护措施 |
在 Dify 中的实现 |
|---|---|---|---|
|
幻觉风险 |
模型编造不存在的政策条款 |
强制基于检索上下文生成 |
Prompt 中明确"禁止编造"约束 |
|
隐私泄露 |
用户 A 看到用户 B 的订单信息 |
会话隔离 + 身份验证 |
|
|
提示注入 |
用户输入恶意指令覆盖系统 Prompt |
输入过滤 + 输出校验 |
Dify 内置内容审核节点 |
|
越权访问 |
免费用户获取企业版专属功能链接 |
用户等级校验 |
在 Chatflow 中加入条件分支判断用户 tier |
|
服务滥用 |
恶意用户高频调用 API 刷量 |
速率限制 + 异常检测 |
EdgeOne 边缘限流 + Dify API 配额 |
在 CloudMart 的 Prompt 设计中,我特意加入了"隐私安全"和"超范围处理"两条约束。这不是过度谨慎——当你把客服部署到公网,任何人都可以访问它,包括那些试图"越狱"模型的人。一个设计良好的 Prompt 应该像一道防火墙,在模型生成之前就划定好边界。
7.4 多模态扩展:从文本到语音与文件
Dify Frontend Starter 模板支持语音输入和文件上传,这在客服场景中非常实用。用户可以直接上传一张报错截图,让客服识别错误信息;或者用语音描述问题,省去打字的麻烦。
文件上传的底层实现依赖于 Dify 的 Files API:
代码语言:javascript
AI代码解释
// 前端文件上传逻辑(简化版)
async function uploadFile(file) {
const formData = new FormData();
formData.append('file', file);
const response = await fetch(`${API_URL}/v1/files/upload`, {
method: 'POST',
headers: {
'Authorization': `Bearer ${APP_KEY}`
},
body: formData
});
const result = await response.json();
// 返回文件 ID,用于后续消息发送
return result.id; // e.g., "file-xxxxxxxx"
}
// 发送带文件的消息
async function sendMessageWithFile(query, fileId) {
const response = await fetch(`${API_URL}/v1/chat-messages`, {
method: 'POST',
headers: {
'Authorization': `Bearer ${APP_KEY}`,
'Content-Type': 'application/json'
},
body: JSON.stringify({
inputs: {},
query: query,
response_mode: 'streaming',
conversation_id: currentConversationId,
user: currentUserId,
files: [
{
type: 'image', // 或 'document'
transfer_method: 'local_file',
upload_file_id: fileId
}
]
})
});
// 处理 SSE 流式响应...
}这段代码展示了文件上传的完整链路:先调用 /v1/files/upload 获取文件 ID,再在发送消息时通过 files 数组引用该 ID。Dify 支持多种文件类型(image、document、audio、video、custom),不同类型的文件会被路由到不同的解析器(OCR、PDF 提取、音频转录等)。
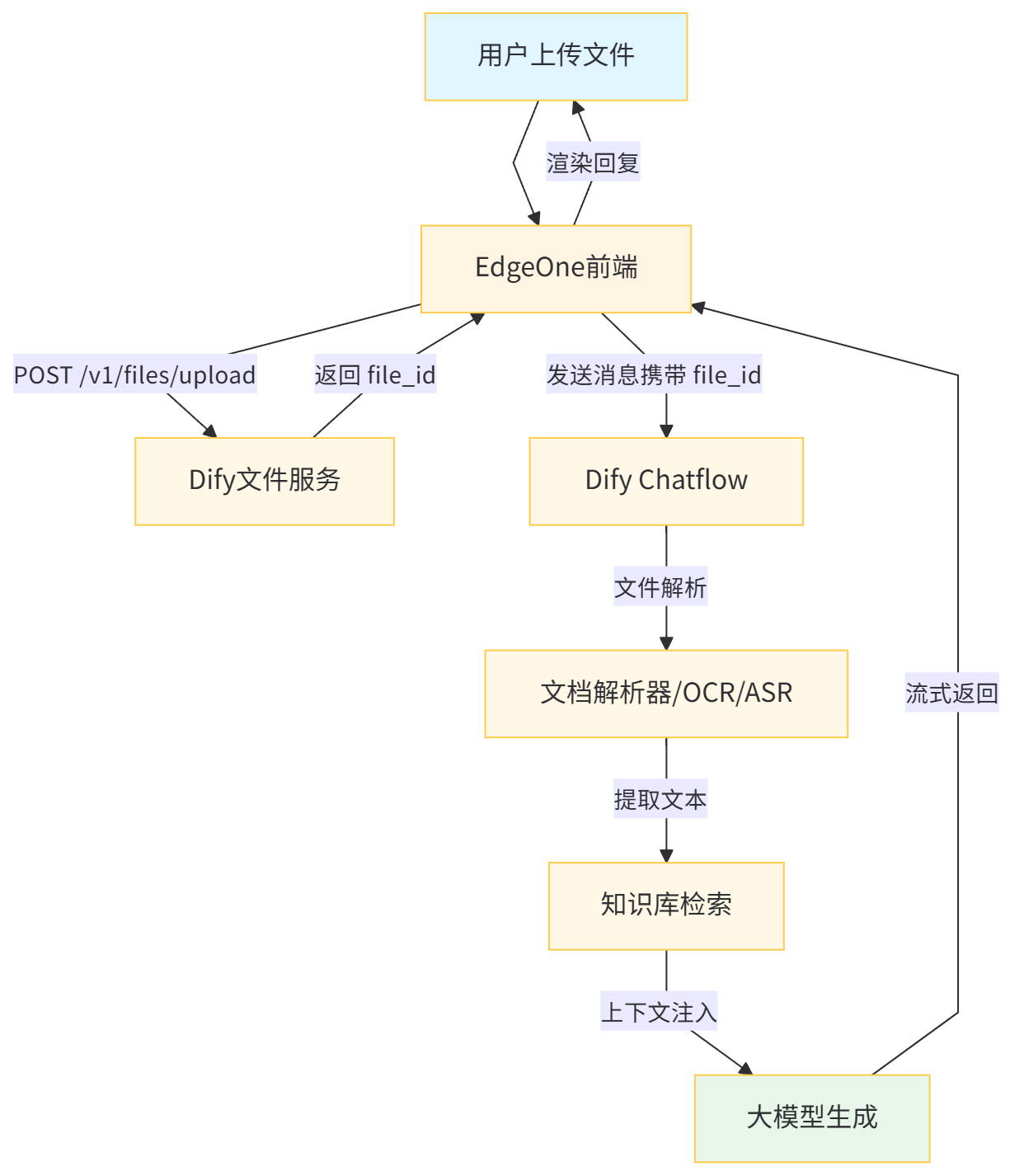
VIII. 总结:AI 应用开发的范式转移
走完整条链路后,我想分享几个超越具体技术步骤的观察。
第一,AI 应用的瓶颈已经从"模型能力"转向了"工程交付"。两年前,我们争论的是哪个模型的 BLEU 分数更高;今天,我们争论的是如何把 Prompt 版本化、如何追踪工作流执行、如何让非技术同事也能修改客服话术。Liwanag 等人(2025)的系统性综述指出,低代码/无代码平台与 AI 的融合正在催生一种"公民开发者"(Citizen Developer)的新角色——业务专家不需要学会 PyTorch,也能通过可视化界面构建和迭代 AI 应用。Dify 正是这种趋势的代表。
第二,RAG 不是万能药,但它是当前最务实的知识 grounding 方案。Komperla(2026)的研究证明,在需要严格事实准确性的客服场景中,RAG 相比纯生成式模型能将事实精度提升 40% 以上,同时将平均处理时间缩短 25%。但 RAG 的效果高度依赖于知识库质量、分段策略和检索参数——这些"脏活累活"往往比调 Prompt 更决定最终体验。
第三,边缘部署正在成为 AI 应用交付的默认选项。当 AI 应用的前端本质上是静态页面(React/Vue 构建产物)加上 API 调用时,传统的服务器托管就显得过度设计。EdgeOne Pages 提供的不仅是托管,而是全球低延迟访问、自动 HTTPS、零运维负担的组合——这对需要面向终端用户的客服、营销、工具类 AI 应用来说,是性价比极高的选择。
第四,模板化正在压缩"从想法到上线"的时间。EdgeOne Pages 提供的官方模板不是简单的代码示例,而是经过产品化思考的完整交互方案——对话历史、多会话切换、文件上传、语音输入、工作流追踪,这些功能如果从头开发,可能需要数周时间;而通过模板,它们变成了几行环境变量的配置。Tyagi 等人(2025)的研究预测,到 2027 年,超过 70% 的企业新应用将通过低代码/无代码平台构建,其中很大一部分会内置 AI 能力。
当然,这套组合也有明确的边界。它不适合需要复杂后端状态管理的场景(比如电商订单系统),不适合对数据隐私有极端要求且不能上云的场景(比如某些军工项目),也不适合需要深度定制前端交互且模板无法满足的场景。但对于"对话式 AI 应用"这个巨大的品类——客服、助手、知识问答、运维工具——Dify + EdgeOne Pages 的组合已经提供了从开发到上线的最短路径。
最后,我想用 Rosenthal 等人(2026)在 MTRAGEval 基准研究中的一句话来收尾:"多轮对话 RAG 系统的真正挑战,不在于单轮回答的准确性,而在于如何在连续的交互中保持上下文一致性、检索相关性和生成忠实度的三重平衡。" 这正是我们在 CloudMart 客服设计中反复调试的核心——不是让模型"会说话",而是让它"能服务"。
如果你也有一个 AI 应用的 idea,不妨用这套组合跑一遍。从 Dify 画布上的第一个节点,到 EdgeOne 域名下的第一次访问,可能只需要一个下午。
而那个下午,或许就是你产品旅程的真正起点。
附录:参考论文与延伸阅读
|
论文/文献 |
作者 |
年份 |
核心贡献 |
本文引用场景 |
|---|---|---|---|---|
|
Enhancing Knowledge-Intensive Customer Support Through RAG |
Komperla, R. C. A. |
2026 |
提出面向受监管行业的 RAG 客服框架,强调可追溯性与事实锚定 |
III、VII 章节 |
|
Low-Code and No-Code Development in the Era of AI: A Systematic Review |
Liwanag, G. L. L. et al. |
2025 |
系统性综述 LCNC 与 AI 融合趋势,指出部署断层问题 |
I、VIII 章节 |
|
Low-Code AI Platforms: Enabling Non-Technical Users to Build Predictive Models |
Tyagi, D. et al. |
2025 |
评估低代码 AI 平台对非技术用户的赋能效果 |
VII、VIII 章节 |
|
Agri Friendly Conversational AI Chatbot Using Open Source Framework |
Gujjar, J. P. & Kumar, H. R. P. |
2025 |
提出约束式生成框架,用于领域专注的对话系统 |
III 章节 |
|
KG-R1: Efficient and Transferable Agentic Knowledge Graph RAG |
Lin, J. et al. |
2025 |
单智能体统一决策框架,减少多模块工作流的 token 开销 |
IV 章节 |
|
R3: Optimizing Retrieval for RAG via Reinforcement Learning |
Zhou, J. et al. |
2025 |
通过 RL 优化检索器,提升端到端 RAG 性能 5.2% |
III、IV、VII 章节 |
|
MTRAGEval: Multi-Turn RAG Conversations |
Rosenthal, S. et al. |
2026 |
多轮对话 RAG 基准测试,提出三重平衡挑战 |
VIII 章节 |
|
LowcoBot: Towards Chatting with Low-Code Platforms |
Martínez-Lasaca, F. et al. |
2024 |
探索 LLM 与低代码平台的自然语言交互 |
II 章节 |

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)