Linux 线上性能排查实战指南:CPU · 内存 · 磁盘 IO · 网络的系统化定位方法
本文针对Linux服务器性能问题排查提出了一套系统化、分层次的排查方法。核心观点是:有效的排查不是从猜测开始,而是先建立全局视角,逐步缩小问题范围。作者强调了四个关键排查步骤: 全局快照:通过组合命令(uptime、top、vmstat、iostat、ss)快速判断系统整体状态,区分CPU、内存、磁盘I/O和网络四条主线问题。 CPU排查:通过top、vmstat、mpstat等工具确认是否真CP
0. 简介
线上机器一旦变慢,最怕的不是问题复杂,而是人一慌就开始乱猜。真正有效的排查,不是上来盯着某个进程猛看,而是先拿到全局快照,再把异常收敛到 CPU、内存、磁盘 IO 或网络中的一条主线,最后定位到具体进程、线程、系统调用或连接状态。这篇指南讲的不是零散命令,而是一套真正能落地的排查顺序——从 PSI 压力指标到容器环境,从 sar 历史回溯到级联故障识别,覆盖现代 Linux 运维排查的完整链路。
监控上显示,接口延迟从 50ms 突然涨到 3s,错误率开始抬头,机器 CPU 告警。你连上服务器,终端光标一闪一闪,脑子里却不一定立刻有答案。很多人这时候会直接猜:是不是流量暴涨了,是不是数据库慢了,是不是有人把日志开成了 DEBUG,是不是内存泄漏了。
猜测当然有时会猜中,但大部分线上排查真正浪费时间的地方,恰恰就是“太早下结论”。
服务器性能问题,表面上看都是“变慢了”,但底层成因并不一样。CPU 打满会变慢,内存回收压力大也会变慢,磁盘排队会变慢,网络链路抖动还是会变慢。更麻烦的是,这几类问题在监控上经常会互相伪装。比如磁盘 IO 排队,会把 load average 拉高;内存紧张导致频繁回收,也可能表现成 CPU 抖动;网络发送缓冲堆积,又可能看起来像应用线程卡住。
所以,线上排查最重要的不是“我会多少命令”,而是“我能不能先判断主矛盾在哪一层”。

1. 先建立全局视角,而不是上来就猜
线上机器出问题以后,第一反应应该是“先拍快照”,而不是“先判断根因”。
这里的所谓全局视角,核心就是两件事:
- 先看机器现在整体处在什么状态。
- 再判断 CPU、内存、磁盘 IO、网络,哪一条线最先失控。
如果这一步做对了,后面的排查会越来越窄;如果这一步做错了,后面的努力大概率是在错误方向上深挖。
1.1 为什么第一眼不能只看 top
很多人收到报警后第一条命令就是 top,这没错,但如果只看 top,信息是不够的。
top 能回答“当前谁最忙”,却不一定能回答“为什么忙”。一个进程 CPU 很高,可能真的是业务计算吃满;也可能只是别的资源拖住了系统,导致这个进程看起来异常活跃。更关键的是,load average 并不等于 CPU 使用率。Linux 会把可运行任务和不可中断等待任务一起计入负载,所以磁盘 IO 排队同样会把负载顶上去。
这就是为什么第一组命令最好不要只有一个 top,而应该是下面这套:
date
uptime
top -b -n 1 | head -n 25
vmstat 1 5
iostat -x -y 1 5
ss -s
这组命令的价值,不在于“全面”,而在于它们互相补位。
date用来记录故障时刻,后面要对日志、监控、链路追踪时很有用。uptime快速看负载是否突然抬高。top看进程层面的忙碌情况。vmstat看 CPU、内存、换页、块 IO 是否同步异常。iostat判断磁盘是否真的在排队。ss -s看连接状态有没有明显堆积。
1.2 拿到快照以后,先问自己四个问题
load average高,是 CPU 真不够,还是有大量任务在等 IO?MemAvailable是不是真的在掉,还是只是页缓存变大了?- 磁盘到底是忙,还是已经排队到影响前台请求?
- 网络到底是连接数太多,还是某些连接的 RTT、重传、队列出了问题?
只要把这四个问题依次问完,方向通常就不会偏。
1.3 全局判断时,最先看的几个信号
| 指标 | 优先级 | 它回答什么 |
|---|---|---|
load average |
高 | 机器整体压力大不大 |
%Cpu 中的 us/sy/wa/id |
高 | 压力更像来自计算、内核还是等待 |
vmstat 里的 r/b/si/so |
高 | 任务是在抢 CPU、等 IO,还是开始换页 |
iostat 里的 await/aqu-sz/%util |
高 | 磁盘是否已经明显排队 |
ss -s |
高 | TCP 状态是否堆积 |
其中最容易误判的是两个地方。
第一,load average 高,不等于 CPU 满。
第二,wa 高,也不能单独下结论说“磁盘有问题”,因为 iowait 本身并不是一个足够可靠的单指标,必须配合 iostat、vmstat 和进程级 IO 再判断。
1.4 一分钟内怎么做初判
| 现象 | 更像什么 | 先去哪条线 |
|---|---|---|
us+sy 高,id 很低,r 也高 |
计算或系统调用压力 | CPU |
MemAvailable 持续走低,si/so 不为 0 |
内存紧张甚至开始换页 | 内存 |
wa 高,b 高,await 高,aqu-sz 高 |
磁盘 IO 排队 | 磁盘 IO |
TIME-WAIT、CLOSE-WAIT、SYN-RECV 明显异常 |
连接模型或链路问题 | 网络 |
1.5 用 PSI 做更精确的压力判断
上面的初判方法已经够用了,但如果你的内核版本在 4.20 以上,还有一个更直接的工具可以用:PSI(Pressure Stall Information)。
PSI 的核心价值在于:它不是告诉你"某个资源的使用率是多少",而是直接告诉你"有多少比例的时间,任务因为等待这个资源而被卡住了"。这比传统指标更接近业务体感。
cat /proc/pressure/cpu
cat /proc/pressure/memory
cat /proc/pressure/io
每个文件会输出类似这样的内容:
some avg10=4.50 avg60=2.80 avg300=1.20 total=18923456
full avg10=0.00 avg60=0.00 avg300=0.00 total=0
这里面最关键的两个概念:
some:至少有一个任务因为等待该资源而被阻塞的时间占比full:所有任务都在等待该资源、没有任何有效工作在进行的时间占比
判断标准可以这样理解:
| 指标 | 含义 | 什么时候该紧张 |
|---|---|---|
cpu some avg10 > 20 |
最近 10 秒内有明显的 CPU 争抢 | 持续高于 25 就值得关注 |
memory some avg10 > 10 |
内存回收压力已经开始影响任务 | 持续高于 20 要警惕 |
memory full avg10 > 5 |
所有任务都在等内存回收 | 这已经是严重状态 |
io some avg10 > 15 |
IO 等待开始拖慢部分任务 | 持续高于 30 需要立刻排查 |
io full avg10 > 10 |
所有任务都卡在 IO 上 | 磁盘大概率已经成为瓶颈 |
PSI 的好处是它把"资源紧张程度"量化成了一个统一的百分比,不需要你自己去交叉对比多个指标。在全局初判阶段,先看一眼 PSI,往往能比传统方法更快地锁定主矛盾方向。
需要注意的是,PSI 在某些老内核或精简内核上可能没有开启。如果 /proc/pressure/ 目录不存在,说明内核编译时没有打开 CONFIG_PSI,这时就只能回到传统方法。
1.6 用 sar 回溯故障时段的历史数据
线上排查有一个非常现实的困境:你赶到现场时,故障可能已经过去了。
top、vmstat、iostat 这些命令都是实时采样,它们只能告诉你"现在怎么样",但如果问题发生在 10 分钟前、半小时前甚至昨天凌晨,这些命令就无能为力了。
这时候 sar 就非常关键。sar 是 sysstat 包的一部分,它会定期把系统指标写入二进制日志文件(通常在 /var/log/sa/ 或 /var/log/sysstat/),你可以事后回溯任意时间段的数据。
# 查看今天的 CPU 使用历史(每 10 分钟一个点)
sar -u
# 查看今天的内存使用历史
sar -r
# 查看今天的磁盘 IO 历史
sar -d -p
# 查看今天的网络流量历史
sar -n DEV
# 查看今天的负载历史
sar -q
# 查看指定时间段(比如下午 2 点到 3 点)
sar -u -s 14:00:00 -e 15:00:00
# 查看昨天的数据(sa 文件按日期编号)
sar -u -f /var/log/sa/sa$(date -d yesterday +%d)
sar 在排查中最常用的几个场景:
- 故障已经恢复,但你需要确认故障时段到底发生了什么。
- 需要对比"正常时段"和"异常时段"的指标差异。
- 需要判断某个指标是"突然飙升"还是"缓慢爬坡"——这对根因判断非常关键。
- 需要向团队或管理层提供故障时间线的数据支撑。
一个实用技巧:如果你发现机器上 sar 没有数据,大概率是 sysstat 没有安装或者 cron 任务没有启用。建议在所有生产机器上确保 sysstat 已安装并且 /etc/cron.d/sysstat 处于激活状态。这是一个成本极低但关键时刻能救命的配置。
打开配置文件:
sudo nano /etc/default/sysstat
找到 ENABLED=“false” 这一行,将其修改为 true:
ENABLED="true"
(或者你可以直接运行这条命令一键替换:sudo sed -i 's/ENABLED="false"/ENABLED="true"/g' /etc/default/sysstat)
2. CPU 排查:先判断它是不是“真 CPU 问题”
很多机器报“CPU 告警”时,真正的问题未必是 CPU。
这是线上排查里非常常见的误区。因为在监控系统里,CPU 和负载通常是最早出现在大盘上的,所以大家很容易本能地朝 CPU 方向钻。但 Linux 的负载统计不是“CPU 百分比”那么简单,大量等待磁盘 IO 的任务也会进入负载。所以你看到 load average 很高时,第一反应不应该是“扩容 CPU”,而应该是“先分清这些任务到底在跑,还是在等”。
2.1 CPU 这一段,先看四个点
top -b -n 1 | head -n 20
vmstat 1 5
mpstat -P ALL 1 5
ps aux --sort=-%cpu | head -n 10
这四条命令分别在回答不同的问题。
top看总量和热点进程。vmstat看可运行队列r、阻塞任务b、上下文切换cs。mpstat -P ALL看是不是只有少数几个核被打满。ps看哪些进程最吃 CPU。
2.2 us、sy、wa 分别意味着什么
很多人会背这几个缩写,但真到排查现场,不一定知道该怎么用它们判断。
us高,说明 CPU 时间主要花在用户态,常见于业务计算、循环、序列化、压缩、正则、GC。sy高,说明内核态开销偏大,常见于系统调用密集、网络包处理开销大、锁竞争严重、频繁fork。wa高,说明 CPU 有相当一部分时间在等 IO 完成,但这时不能只看 CPU 面板,必须继续结合磁盘维度看。
把这三个指标分清楚,排查速度会快很多。因为它们决定了你下一步要不要继续看 CPU,还是应该转向 IO 或网络。
2.3 什么时候才算“真 CPU 问题”
一般来说,下面这组信号同时出现,才更像是 CPU 本身成了主瓶颈:
us+sy很高,id很低vmstat的r长时间明显大于核数mpstat -P ALL显示多个核持续繁忙- 没有明显的高
wa、高b、高si/so
如果这些条件不满足,就不要急着把锅扣到 CPU 头上。
2.4 一旦确认是 CPU 方向,顺序怎么走
ps aux --sort=-%cpu | head -n 10
top -H -p <PID>
pidstat -t -u -p <PID> 1 5
ps -eLo pid,ppid,tid,psr,pcpu,stat,comm --sort=-pcpu | head
perf top -p <PID>
strace -f -tt -T -p <PID> -c
这个顺序不要乱。
先找进程,再找线程,再看函数热点,最后才去看系统调用统计。因为很多时候,问题在 perf top 那一步就已经收敛了,没必要一上来就进入最重的观察手段。
2.5 三种最常见的 CPU 高场景
2.5.1 us 高,说明算力真的被业务吃掉了
这种场景最典型。比如某段代码里有死循环,某个正则表达式触发了灾难性回溯,某个请求路径引入了巨大的 JSON 序列化开销,或者 Java 程序在高压下频繁 Full GC。它们的共同点是:CPU 时间主要耗在用户态,热点通常集中在少数业务线程上。
这时候最有用的命令是:
top -H -p <PID>
perf top -p <PID>
top -H 解决的是“哪个线程最热”,perf top 解决的是“热在哪里”。前者帮你缩小对象,后者帮你收敛到函数。
2.5.2 sy 高,说明开销大头在内核态
这类问题比单纯的业务计算更隐蔽。
如果你看到 sy 特别高,通常应该怀疑:
- 系统调用过于频繁
- 网络小包风暴
- 日志写得非常碎
futex很多,说明锁竞争明显- 频繁
open/close/stat
这时用 strace -c 很有效:
strace -f -tt -T -p <PID> -c
如果你看到 write、recvfrom、sendto、futex、epoll_wait 这些调用占比异常高,就不要再停留在“CPU 高”这个表象上了,而要追问:为什么这些系统调用会这么密集。
2.5.3 负载高,但 CPU 没满
这是最容易让人误判的一种情况。
表面看机器“负载爆了”,实际上真正忙的不是 CPU,而是别的资源。常见信号是:
load average很高us+sy没那么夸张wa较高,或者vmstat里的b很高
这时候如果你继续在 CPU 上深挖,大概率只会越查越偏。正确动作是立刻转到磁盘 IO 或锁等待链路。
2.6 CPU 方向最常见的四个误判
- 把
load average当成纯 CPU 指标。 - 看到某个进程
%CPU高,就不再往线程层细分。 - 只看总 CPU,不看
mpstat -P ALL,从而错过单核瓶颈。 - 在虚拟机里忽略
st,误把宿主机争抢当成业务退化。
3. 内存排查:分清是泄漏、缓存,还是回收压力
内存问题看起来比 CPU 更直观,因为“内存快满了”这句话非常容易理解。但真到了 Linux 上,反而更容易因为“看起来很满”而误判。
原因很简单:Linux 会主动用空闲内存做缓存。也就是说,“内存被用掉了”本身不是问题,关键要看这部分内存到底是什么。
3.1 第一眼不要盯着 free,先看 available
free -h
cat /proc/meminfo | egrep 'MemTotal|MemFree|MemAvailable|Cached|SwapTotal|SwapFree|Dirty|Writeback|Slab|SReclaimable|SUnreclaim|Committed_AS|CommitLimit'
vmstat 1 5
ps aux --sort=-%mem | head -n 10
很多人第一次看 free -h,会本能地关注 free 那一列,但线上排查时更有判断价值的是 available。
因为 available 更接近“在不明显触发交换的情况下,还能给新进程用多少”。如果 free 很低,但 available 还比较健康,同时 Cached 很大,那大概率只是页缓存正常占用了内存,并不是系统真的快撑不住了。
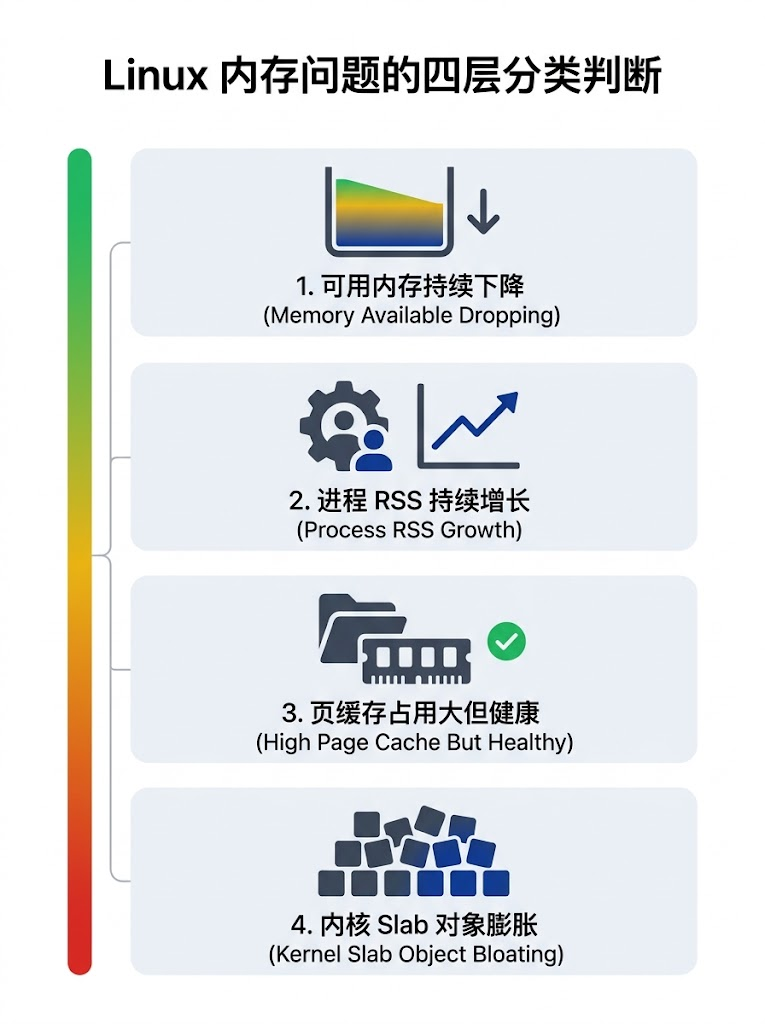
3.2 内存问题先分成四类看
| 现象 | 更像什么 | 核心判断 |
|---|---|---|
MemAvailable 低,si/so 持续非零 |
物理内存紧张 | 已经开始换页,性能通常会明显抖动 |
VmRSS、RssAnon 持续上涨 |
用户态内存泄漏或对象堆积 | 看趋势,不看某个瞬时值 |
Cached 很大,但 available 还可以 |
正常页缓存 | 不要误判为泄漏 |
Slab、SUnreclaim 异常上涨 |
内核对象膨胀 | 可能是 dentry、inode、socket 相关 |
3.3 为什么内存问题要特别强调“趋势”
因为单次截图很容易骗人。
某个进程此刻 VmRSS 很大,不代表它就有泄漏。可能只是它刚完成一轮批量处理,内存还没回落;也可能是它持有大量文件映射;还可能只是运行期缓存比较多。真正值得警惕的,是“业务高峰过去了,它的 RSS 还是持续往上走,而且回不来”。
所以内存问题的判断,最好带一点时间维度:
pidstat -r -p <PID> 1 5
cat /proc/<PID>/status | egrep 'VmSize|VmRSS|VmSwap|RssAnon|RssFile|RssShmem'
pmap -x <PID> | tail -n 20
如果还不够,再看:
grep -E '^(Size|Rss|Pss|Private|Shared|Anonymous|AnonHugePages)' /proc/<PID>/smaps | head -n 80
3.4 用户态泄漏通常长什么样
它往往不是“瞬间爆掉”,而是慢慢涨上去。
特征通常有这些:
VmRSS或RssAnon持续增长- 业务流量已经降下来,内存却不回落
MemAvailable越来越低- 如果已经开始换页,
si/so会变得明显
对 C/C++ 程序来说,这类问题经常和对象生命周期、容器无限增长、缓存淘汰策略失效、跨线程对象持有有关。
对 Java、Go 之类运行时语言来说,还要结合 GC 行为、堆上对象增长、逃逸、引用链去判断。
3.5 页缓存大,不是坏事
这是 Linux 新手最容易被误导的地方。
如果你看到:
Cached很大MemAvailable仍然不低- 业务没有明显换页
- 进程 RSS 也不夸张
那这通常不是问题,而是内核在正常利用内存做文件缓存。缓存本来就是为了提升 IO 命中率存在的,只有当它挤压到真正可用内存,或者引发回收压力时,才值得担心。
3.6 内核内存异常,怎么识别
有时候用户态进程看起来都不算夸张,但系统可用内存仍在明显下降。这时就要怀疑是不是内核对象在涨。
可以先看:
slabtop -o
如果 Slab、SUnreclaim 明显上涨,slabtop 里某类对象数量持续膨胀,那问题就未必在业务堆内存本身,而可能在 dentry、inode、socket buffer 之类的内核缓存。
3.7 容器环境里,宿主机“有内存”不代表容器能活
这是现代线上环境里非常值得补的一层。
如果你的服务跑在 cgroup v2 下,容器本身的 memory.max、memory.high、memory.current 比宿主机总内存更关键。很多时候宿主机还没 OOM,但容器因为超过自己的上限已经被强回收甚至被杀了。
cat /sys/fs/cgroup/<cg>/memory.current
cat /sys/fs/cgroup/<cg>/memory.peak
cat /sys/fs/cgroup/<cg>/memory.events
cat /sys/fs/cgroup/<cg>/memory.stat
如果 memory.events 里的 oom、oom_kill 在增长,那问题已经非常明确了。
3.8 现代系统里,别漏掉 systemd-oomd
不少人只会去 dmesg 里找 OOM 日志,但如果机器启用了 systemd-oomd,进程可能在传统内核 OOM 之前就被主动清理掉。
oomctl dump
dmesg -T | grep -Ei 'oom|killed process' | tail -n 20
这一步的价值在于:弄清楚“到底是谁杀了它”。如果这一点都没分清,后面的分析很容易走偏。
3.9 内存方向最常见的四个误判
- 看到
MemFree很低,就说机器内存不够。 - 看到
Cached很大,就下结论说“内存泄漏”。 - 只看宿主机总内存,不看 cgroup 限额。
- 用单次 RSS 截图判断泄漏,而不看趋势。
4. 磁盘 IO 排查:先确认是不是排队,再找谁在写
磁盘 IO 问题是最容易“伪装成 CPU 问题”的。
因为一旦块设备开始排队,任务就会进入不可中断等待,负载会上升,CPU 面板上也会出现明显的 wa。如果这时候只盯着 CPU 面板,很容易误以为“CPU 告警就是 CPU 不够”,实际上 CPU 只是在等磁盘。
4.1 这一段第一组命令最好是
vmstat 1 5
iostat -x -y 1 5
pidstat -d -p ALL 1 5
cat /proc/meminfo | egrep 'Dirty|Writeback'
这四个命令配在一起,基本能把 IO 的大方向看清楚。
vmstat里的b能看到有多少任务在阻塞。iostat -x能看到磁盘是不是在排队。pidstat -d用来找具体哪个进程在读写。Dirty和Writeback可以帮助判断页缓存回写压力。
4.2 iostat -x 里最值得看的,不是带宽,而是延迟和队列
很多人一看到 rkB/s、wkB/s 就开始紧张,觉得带宽很大就一定是问题。其实不是。
真正决定“业务为什么慢”的,通常不是吞吐数字本身,而是请求有没有在设备前排队。
判断这件事最有价值的三列是:
await:一次 IO 从入队到完成的平均时间aqu-sz:平均队列长度%util:设备忙碌时间占比
这里尤其要强调两个判断点。
第一,await 高而且 aqu-sz 高,才说明“慢是因为排队”。
第二,%util 很高并不永远等于“磁盘一定到极限了”,特别是在现代 SSD、RAID 或更复杂的存储栈上,不能机械地只拿这一列做结论。
4.3 进程级 IO 定位,为什么 /proc/<PID>/io 很关键
系统级看到“磁盘忙”以后,下一步一定要尽快把问题缩到进程层面。
pidstat -d -p ALL 1 5
cat /proc/<PID>/io
pidstat -d 可以快速找出哪个进程 kB_wr/s 或 kB_rd/s 异常高。
而 /proc/<PID>/io 更进一步,能帮你看清楚:
- 它发起了多少写系统调用
- 它真正写到了多少字节
- 有没有大量写调用其实只是碎小日志
如果你发现 syscw 特别高,但 write_bytes 并没有高到相同比例,常常意味着写得很碎,调用频率远高于有效写入量。这种场景在日志系统上非常常见。
4.4 fsync 为什么经常是关键嫌疑人
很多程序员以为“写文件慢”就是写得太多,其实线上更常见的情况是:写本身不算多,但每次写完都在同步刷盘。
这时可以用:
strace -f -tt -T -e trace=write,fsync,fdatasync -p <PID>
如果你在输出里反复看到 fsync() 或 fdatasync(),那延迟高的原因就不只是“有写”,而是“每次写都在等介质确认”。数据库、日志、消息持久化模块里,这类问题尤其常见。
4.5 页缓存回写压力,也会把前台请求拖慢
Linux 下大量写操作通常会先进页缓存,再由内核异步刷盘。这种设计本来是为了吞吐,但在写峰值特别高的时候,也可能积压出大量待回写脏页,最终反过来压到前台线程。
所以如果你看到:
Dirty很高Writeback持续不低await也逐步抬高
那就要考虑是不是页缓存和后台回写开始互相牵制了。
4.6 磁盘 IO 方向最常见的三个根因
- 生产环境日志级别过低,每个请求都写大量 DEBUG 日志
- 数据库或存储服务发生大量随机写或刷盘
- 应用写得很碎,还频繁做同步持久化
4.7 IO 方向最常见的三个误判
- 看到
%util=100%就直接断言“磁盘一定满了”。 - 只看带宽,不看
await和aqu-sz。 - 只停留在系统级,不继续追到具体进程和具体调用。
5. 网络排查:不要只数连接,还要看连接质量
网络问题看起来最杂,因为它既可能是链路问题,也可能是应用本身的连接管理问题,还可能是监听队列、socket 缓冲、DNS、对端处理能力共同作用的结果。
所以网络排查不能只看“连接多不多”,而要同时看三件事:
- 连接状态是否异常堆积。
- 单条连接的 RTT、重传、拥塞状态是否异常。
- 监听端口的接收能力和队列是否成了瓶颈。
5.1 第一组命令
ss -s
ss -tan
ss -tan state established
ss -tan state time-wait
ss -tan state close-wait
ss -ti
ss -m
ss -lnt
5.2 TIME-WAIT 多,不一定就是故障
这是网络排查里最经典的误判之一。
很多短连接服务天生就会产生大量 TIME-WAIT,这本身是 TCP 正常关闭流程的一部分。只有当它已经影响到端口资源、建连能力,或者和业务设计明显不匹配时,它才真正构成问题。
相比之下,CLOSE-WAIT 持续增长往往更值得警惕。因为它通常意味着:对端已经把连接关了,而本端没有及时 close()。这更像代码层面的连接清理问题。
5.3 为什么 ss -i 特别重要
很多人网络排查停在 ss -s 或 netstat 这一层,只能看到连接数量,却看不到连接质量。
ss -i 则能直接给出一些真正有判断价值的 TCP 内部信息,比如:
rtt:往返时延rto:重传超时cwnd:拥塞窗口ssthresh:慢启动阈值
如果一个接口超时,但你用 ss -i 看到连接的 rtt、rto 都明显升高,那就说明问题已经不是“连接有没有建立起来”这么简单,而是链路质量或对端处理能力已经出了明显问题。
5.4 ss -m 用来判断 socket 层是不是堆积了
如果连接数量看起来不夸张,但服务仍然发不动、收不动,就应该去看 socket 内存和队列。
ss -m 里值得关注的包括:
rmem_allocwmem_allocwmem_queuedback_logsock_drop
这些信息的意义在于:它能帮助你判断,问题是出在链路上,还是应用根本没来得及消费和处理。
5.5 监听端口的问题,别只看“有没有在 LISTEN”
一个端口在 LISTEN,不代表它就处理得过来。
如果服务端 accept() 太慢,或者用户态工作线程已经堆满,监听队列同样会积压。外部表现往往是:
- 建连慢
- 偶发连接失败
- 高峰期抖动特别明显
这时要一起看:
ss -lnt
cat /proc/sys/net/core/somaxconn
cat /proc/sys/net/ipv4/tcp_max_syn_backlog
它们能帮助你判断 backlog 上限和实际监听能力是否匹配。
5.6 网络方向最常见的几个根因
…详情请参照古月居

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐



 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)