CentOS 7.9 服务器 企业级 Kubernetes 高可用部署方案
硬件需求:
- 3 台 CentOS 7.9
- 8 核 / 64G 内存 / 1T 硬盘
- 用途:搭建 生产可用、高可用、企业标准 K8s 集群
我直接给你 最简、最稳、可直接落地 的企业级方案: 3 节点 All-in-One 高可用 K8s(Master + Node 混合部署) 不用额外买服务器,3 台就能跑生产级 HA。
一、整体架构(企业标准)
3 节点角色(最优分配)
表格
| 节点 | IP | 角色 | 用途 |
|---|---|---|---|
| node1 | 10.10.6.27 | master + etcd + worker | 控制面 + 运行业务 Pod |
| node2 | 10.10.6.28 | master + etcd + worker | 控制面 + 运行业务 Pod |
| node3 | 10.10.6.29 | master + etcd + worker | 控制面 + 运行业务 Pod |
为什么这样设计?
- 3 台 = 高可用 etcd + 高可用 master
- 没有单点故障
- 资源利用率最高
- 企业中小规模生产环境标准架构
二、版本选择(企业最稳定)
- K8s 1.28.15(长期支持版)
- containerd 1.7.x
- Calico 网络插件
- Metrics + Dashboard + ingress-nginx + local-path-provisioner
三、前置要求(所有节点执行)
1、先把 CentOS7 系统源修好(必须第一步)
1)备份旧源
bash 运行
mkdir -p /etc/yum.repos.d/backup
mv /etc/yum.repos.d/*.repo /etc/yum.repos.d/backup/
2)写入可用的 CentOS7 阿里云 EOL 源
bash 运行
cat <<EOF > /etc/yum.repos.d/CentOS-Base.repo
[base]
name=CentOS-7-Base
baseurl=https://mirrors.aliyun.com/centos-vault/7.9.2009/os/x86_64/
gpgcheck=0
enabled=1
[extras]
name=CentOS-7-Extras
baseurl=https://mirrors.aliyun.com/centos-vault/7.9.2009/extras/x86_64/
gpgcheck=0
enabled=1
[updates]
name=CentOS-7-Updates
baseurl=https://mirrors.aliyun.com/centos-vault/7.9.2009/updates/x86_64/
gpgcheck=0
enabled=1
EOF
3)清缓存、重建缓存
bash 运行
yum clean all
rm -rf /var/cache/yum
yum makecache2. 关闭防火墙、selinux、swap
bash 运行
systemctl stop firewalld && systemctl disable firewalld
sed -i 's/enforcing/disabled/' /etc/selinux/config
setenforce 0
swapoff -a
sed -i '/swap/s/^/#/' /etc/fstab
3. 加载 overlay & br_netfilter 模块(kubelet 依赖)
bash 运行
modprobe overlay
modprobe br_netfilter
cat <<EOF > /etc/modules-load.d/k8s.conf
overlay
br_netfilter
EOF
3. 主机名、hosts 解析
bash 运行
# 所有节点 /etc/hosts
10.10.6.26 node-01
10.10.6.27 node-02
10.10.6.28 node-03
4. 内核参数(必须)
bash 运行
cat <<EOF > /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.ipv4.ip_forward = 1
EOF
sysctl --system
5. 安装 containerd
bash 运行
yum install -y yum-utils device-mapper-persistent-data lvm2
yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
yum install -y containerd.io
containerd config default > /etc/containerd/config.toml
sed -i 's/SystemdCgroup = false/SystemdCgroup = true/g' /etc/containerd/config.toml
systemctl enable containerd && systemctl start containerd
配置一下国内镜像加速【很重要】
bash 运行
# 备份原有配置
cp /etc/containerd/config.toml /etc/containerd/config.toml.bak
# 写入多国内加速源配置
sed -i '/\[plugins."io.containerd.grpc.v1.cri".registry.mirrors\]/,$d' /etc/containerd/config.toml
cat >> /etc/containerd/config.toml <<EOF
[plugins."io.containerd.grpc.v1.cri".registry.mirrors]
[plugins."io.containerd.grpc.v1.cri".registry.mirrors."docker.io"]
endpoint = [
"https://docker.mirrors.ustc.edu.cn",
"https://hub-mirror.c.163.com",
"https://mirror.ccs.tencentyun.com",
"https://docker.xuanyuan.me"
]
[plugins."io.containerd.grpc.v1.cri".registry.mirrors."registry.k8s.io"]
endpoint = ["https://registry.aliyuncs.com/k8s_images"]
EOF
# 重载+重启containerd
systemctl daemon-reload
systemctl restart containerd
6. 添加 K8s yum 源
bash 运行 【CentOS7 EOL → 旧 base/updates 源 404,yum 整体 “无可用镜像”】
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.28/rpm/
enabled=1
gpgcheck=0
exclude=kubelet kubeadm kubectl cri-tools kubernetes-cni
EOF7. 安装 kubeadm kubelet kubectl
bash 运行
yum install -y kubelet kubeadm kubectl --disableexcludes=kubernetes --nogpgcheck
systemctl enable kubelet && systemctl start kubelet
--disableexcludes=kubernetes:让 yum 强制安装 k8s 相关包,不被系统屏蔽
--nogpgcheck:不校验包签名,解决阿里云源无法验证签名的报错
我要强制安装 k8s 包,不要拦我,也不要检查签名,直接装!
只要你用 阿里云 kubernetes-new 源,安装时 必须加这两个参数,否则:
- 要么装不上
- 要么报 GPG 签名错误
8.锁定版本 + 开机自启
bash 运行
yum install -y yum-plugin-versionlock
yum versionlock add kubelet kubeadm kubectl
systemctl enable kubelet
四、初始化 3 节点高可用 K8s(核心步骤)
全部node 执行:
1)先手动拉齐所有 v1.28.15 镜像(所有节点都执行)
bash 运行
# 先列一下需要哪些镜像
kubeadm config images list --kubernetes-version=v1.28.15
然后手动拉(用 containerd 的 ctr,或者 docker,看你 runtime):
bash 运行
# 用阿里云 google_containers 拉取
IMAGES=(
kube-apiserver:v1.28.15
kube-controller-manager:v1.28.15
kube-scheduler:v1.28.15
kube-proxy:v1.28.15
pause:3.9
etcd:3.5.9-0
coredns/coredns:v1.10.1
)
for img in "${IMAGES[@]}"; do
ctr -n k8s.io images pull registry.cn-hangzhou.aliyuncs.com/google_containers/$img
ctr -n k8s.io images tag registry.cn-hangzhou.aliyuncs.com/google_containers/$img registry.k8s.io/$img
done
registry.cn-hangzhou.aliyuncs.com/google_containers/coredns/coredns:v1.10.1
阿里云没有这个路径!coredns 不在 google_containers 下面!
正确拉取命令:
ctr -n k8s.io images pull registry.aliyuncs.com/google_containers/coredns:v1.10.1
ctr -n k8s.io images tag registry.aliyuncs.com/google_containers/coredns:v1.10.1 registry.k8s.io/coredns/coredns:v1.10.1
在 所有节点 改 containerd 配置:
bash 运行
sed -i 's#sandbox_image = ".*"#sandbox_image = "registry.aliyuncs.com/google_containers/pause:3.9"#' /etc/containerd/config.toml
systemctl restart containerd
你现在直接执行:
如果你是 docker:把
ctr -n k8s.io images pull换成docker pull,tag同理。
-
registry.aliyuncs.com/k8sxio是第三方个人 / 小团队同步,不全、更新慢、部分版本缺失。 -
registry.aliyuncs.com/google_containers是阿里云官方镜像站同步,版本全、稳定、常用版本都有。
2)在 node-03 执行:
bash 运行
kubeadm init --control-plane-endpoint "10.10.6.29" \
--apiserver-advertise-address=10.10.6.29 \
--image-repository registry.aliyuncs.com/google_containers \
--kubernetes-version v1.28.15 \
--service-cidr=10.96.0.0/12 \
--pod-network-cidr=10.244.0.0/16 \
--ignore-preflight-errors=Swap \
--upload-certs
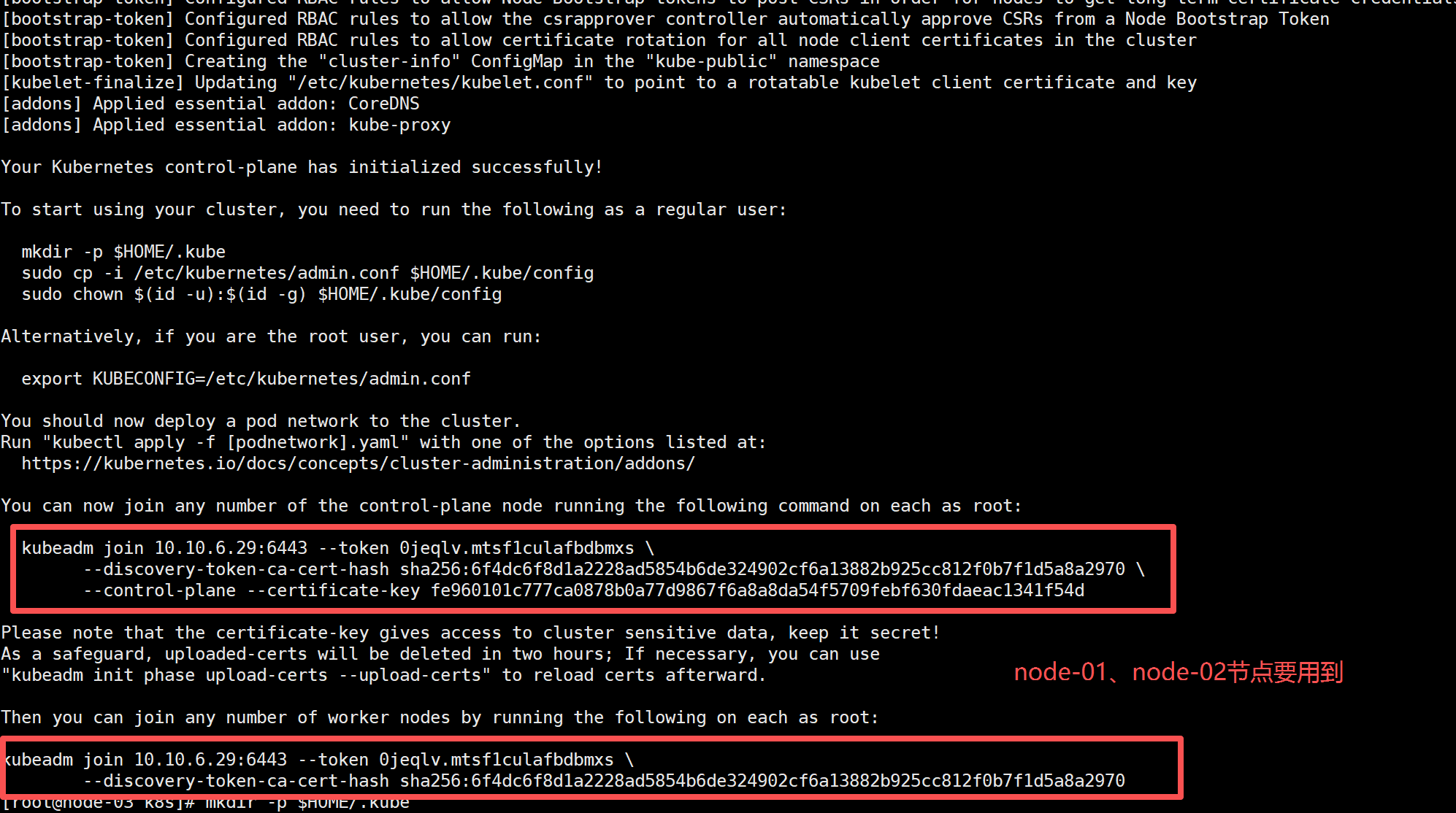
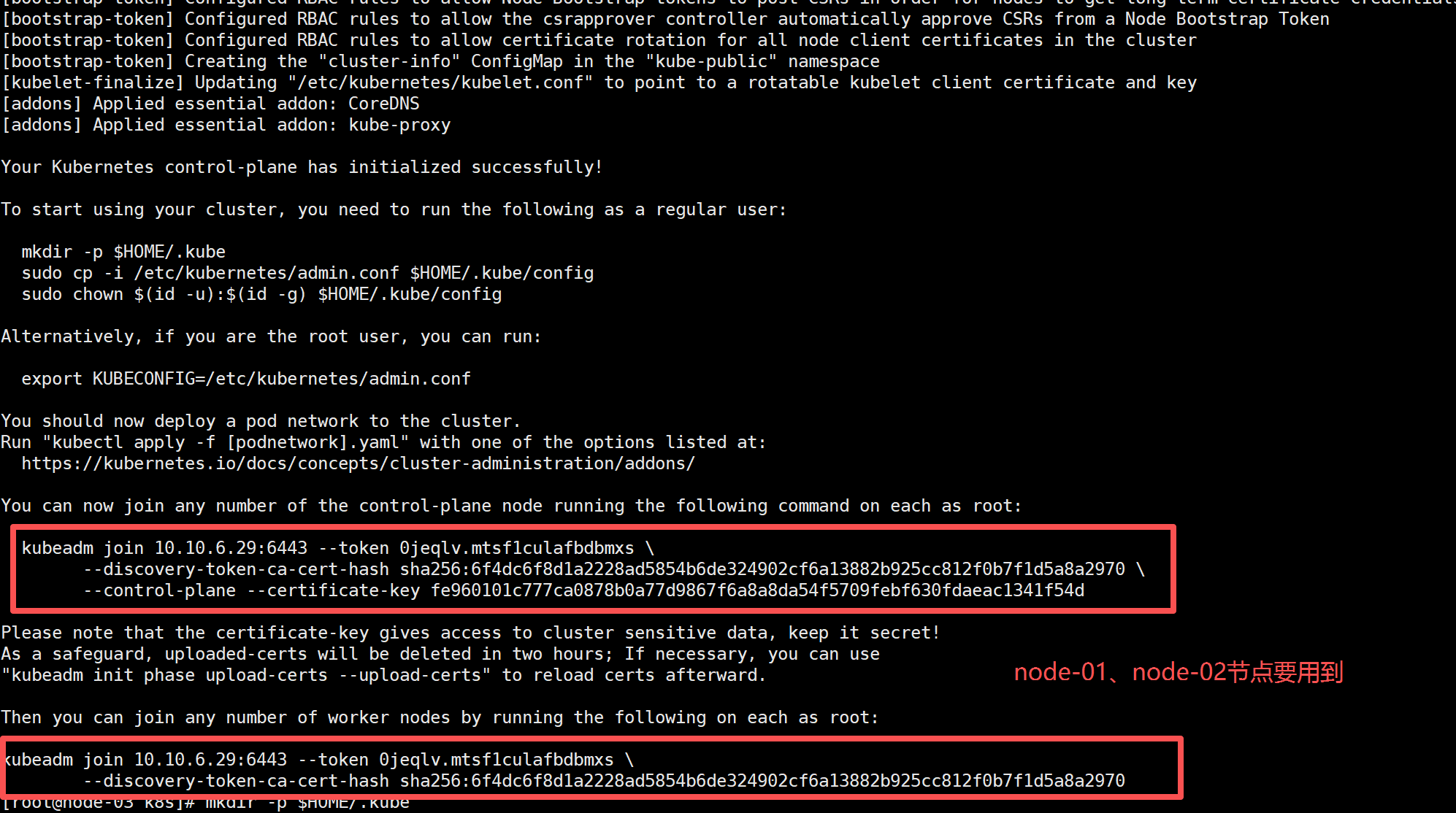
执行成功后,它会输出 两条 join 命令,复制这两条命令到node-01,node-02中执行:
- 一条给 master 节点加入
- 一条给 worker 节点加入
如果出现错误:[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s [kubelet-check] Initial timeout of 40s passed.
kubelet 还是没正常跑起来,所以控制平面起不来! 不是 init 命令错,是 containerd + kubelet 配合问题!
立刻执行这 4 步(3 台都执行)
1)重置 kubeadm(必须!)
bash 运行
kubeadm reset -f
rm -rf /etc/kubernetes/
rm -rf /var/lib/kubelet/
rm -rf /var/lib/etcd/
rm -rf ~/.kube/
2) 修复 containerd 关键配置(最关键!)
bash 运行
containerd config default > /etc/containerd/config.toml
sed -i 's/SystemdCgroup = false/SystemdCgroup = true/' /etc/containerd/config.toml
sed -i 's#registry.k8s.io/pause#registry.aliyuncs.com/google_containers/pause#g' /etc/containerd/config.toml
3)重启服务
bash 运行
systemctl daemon-reload
systemctl restart containerd
systemctl enable kubelet
systemctl restart kubelet
4)再检查 kubelet 状态(现在应该是启动中,正常!)
bash 运行
systemctl status kubelet
只要不是红色 failed,就可以继续!
3)在 node-02、node-01 执行
bash 运行
# 这条命令,直接从node-3 init初始化完成后的输出结果上复制即可
kubeadm join 10.10.6.28:6443 --token xxxx \
--discovery-token-ca-cert-hash sha256:yyyy \
--control-plane --certificate-key zzzz
上面的运行执令,来自于node-03 init输出的日志,例如下图。
五、安装 Calico 网络
1. 安装【仅在10.10.6.29上执行】
1)先下到本地(国内推荐用 GitHub 源)
bash 运行
# 下载yaml文件到本地
curl https://raw.githubusercontent.com/projectcalico/calico/v3.26.5/manifests/calico.yaml -O
# 或者直接执行,如果直接安装,则跳过下面步骤
kubectl apply -f https://raw.githubusercontent.com/projectcalico/calico/v3.26.5/manifests/calico.yamlv3.26.5 是适配 K8s 1.28 的稳定版。
2)修改 Pod 网段(必须和你 kubeadm init 一致)
init 用的是:
--pod-network-cidr=10.244.0.0/16
所以在 calico.yaml 里找到:
# - name: CALICO_IPV4POOL_CIDR
# value: "192.168.0.0/16"
改成:
- name: CALICO_IPV4POOL_CIDR
value: "10.244.0.0/16"
可以直接 sed 一键改:
bash 运行
sed -i 's|192.168.0.0/16|10.244.0.0/16|g' calico.yaml
3) apply 本地文件
bash 运行
kubectl apply -f calico.yaml
4)验证
bash 运行
kubectl get nodes
kubectl get pods -n kube-system | grep calico
所有 calico-xxx 都 Running,节点状态变成 Ready 就成功了。
5)异常处理【calico无法运行】:
国内网络拉不到 quay.io/docker.io 的 Calico 镜像,所以卡在 Init:ImagePullBackOff。下面给你一套一键替换国内源、重新部署的完整操作,马上能好。
a. 先把现在失败的 Calico 删掉
bash 运行
kubectl delete -f calico.yaml
# 确认 calico 相关 Pod 全部消失
kubectl get pods -n kube-system | grep calico
b. 重新下载并替换为国内可拉的镜像(v3.26.5)
bash 运行
# 下官方原始文件
wget https://raw.githubusercontent.com/projectcalico/calico/v3.26.5/manifests/calico.yaml
# 关键:把 quay.io 换成 DaoCloud 国内镜像
sed -i 's#quay.io/calico/#docker.m.daocloud.io/calico/#g' calico.yaml
# 顺便把 docker.io 也换掉(有的版本会写这个)
sed -i 's#docker.io/calico/#docker.m.daocloud.io/calico/#g' calico.yaml
这里用的是
docker.m.daocloud.io,国内基本秒拉,比阿里云还稳。
c. 应用改好的 yaml
bash 运行
kubectl apply -f calico.yaml
d. 观察状态(2–3 分钟内必成)
bash 运行
kubectl get pods -n kube-system | grep calico
正常结果:
calico-node-xxxx 3/3 Running
calico-kube-controllers-xxxx 1/1 Running
e. 再看 metrics-server
等 calico 全 Running:
bash 运行
kubectl get pods -n kube-system | grep metrics-server
会自动从 ContainerCreating 变成 1/1 Running。
然后:bash 运行
kubectl top nodes
kubectl top pods -A
就能看到监控数据了。
2. 配置同步
1)在 node-03 执行:
bash 运行
# 复制到 node-02
scp /etc/kubernetes/admin.conf root@10.10.6.28:/etc/kubernetes/
# 复制到 node-01
scp /etc/kubernetes/admin.conf root@10.10.6.27:/etc/kubernetes/
2)在 node-02 / node-03 执行配置
bash 运行
mkdir -p $HOME/.kube
cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
chown $(id -u):$(id -g) $HOME/.kube/config
3)完成!现在 所有节点 都能跑:
bash 运行
kubectl get nodes
✅ 全部节点都能正常使用 kubectl 了!
六、允许 Master 运行业务 Pod(企业常用)
bash 运行
kubectl taint nodes --all node-role.kubernetes.io/control-plane-
七、企业级必装组件
1. metrics-server 监控
bash 运行
# 直接 apply 官方 yaml 即可,它会自动调度到其中一个 master
# 只在一个节点上操作一次即可
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
连不上 GitHub 原始 yaml(国内网络超时),直接用我给你的改好国内镜像 + 跳过证书的完整 yaml 就行,不用再去拉官方文件。
1)直接用(复制保存为 metrics-server.yaml)
yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: metrics-server
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: system:metrics-server
rules:
- apiGroups:
- ""
resources:
- pods
- nodes
- nodes/stats
- namespaces
- configmaps
verbs:
- get
- list
- watch
- apiGroups:
- "metrics.k8s.io"
resources:
- pods
- nodes
verbs:
- get
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: system:metrics-server
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
roleRef:
kind: ClusterRole
name: system:metrics-server
apiGroup: rbac.authorization.k8s.io
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: metrics-server
namespace: kube-system
spec:
replicas: 1
selector:
matchLabels:
k8s-app: metrics-server
template:
metadata:
labels:
k8s-app: metrics-server
spec:
serviceAccountName: metrics-server
containers:
- name: metrics-server
# 国内阿里云镜像(不用翻墙)
image: registry.cn-hangzhou.aliyuncs.com/google_containers/metrics-server:v0.8.0
args:
- --cert-dir=/tmp
- --secure-port=4443
- --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname
- --kubelet-use-node-status-port
- --metric-resolution=15s
# 关键:跳过 kubelet 证书验证(解决 x509 错误)
- --kubelet-insecure-tls
ports:
- containerPort: 4443
name: https
protocol: TCP
resources:
requests:
cpu: 100m
memory: 200Mi
limits:
cpu: 500m
memory: 512Mi
readinessProbe:
httpGet:
path: /healthz
port: https
scheme: HTTPS
initialDelaySeconds: 30
periodSeconds: 10
livenessProbe:
httpGet:
path: /healthz
port: https
scheme: HTTPS
initialDelaySeconds: 60
periodSeconds: 30
---
apiVersion: v1
kind: Service
metadata:
name: metrics-server
namespace: kube-system
labels:
k8s-app: metrics-server
spec:
selector:
k8s-app: metrics-server
ports:
- port: 443
targetPort: 4443
2)直接部署(一条命令)
bash 运行
kubectl apply -f metrics-server.yaml
kubectl uncordon node-01 node-02 node-03
kubectl rollout restart deployment metrics-server -n kube-system4)验证是否成功
bash 运行
# 看 Pod 是否 Running
kubectl get pods -n kube-system | grep metrics-server
# 看节点/ Pod 监控
kubectl top nodes
kubectl top pods -A
能看到 CPU / 内存数据就 OK。
4)说明(为什么这么改)
- 镜像换成阿里云:
registry.cn-hangzhou.aliyuncs.com/google_containers/metrics-server:v0.8.0,国内直接拉取,不会超时。 - 加
--kubelet-insecure-tls:跳过 kubelet 自签名证书验证,避免x509报错(测试 / 内网集群安全可用)。 - 不需要每个节点装:只在集群部署一个 Deployment,自动跑在某个 master 上,一个实例监控所有节点。
5)如果上面不行,看如下步骤:
a. 先把现在坏掉的 metrics-server 删掉
bash 运行
kubectl delete -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
# 确认 metrics-server pod 消失
kubectl get pods -n kube-system | grep metrics-server
b. 下载官方 components.yaml 并改两点(国内必做)
bash 运行
# 下载
wget https://github.com/kubernetes-sigs/metrics-server/releases/download/v0.8.0/components.yaml
# ① 替换镜像为阿里云(解决拉取不到)
sed -i 's|registry.k8s.io/metrics-server/metrics-server|registry.aliyuncs.com/google_containers/metrics-server|g' components.yaml
# ② 追加 --kubelet-insecure-tls(解决证书报错 CrashLoop)
sed -i '/--kubelet-preferred-address-types/a \ - --kubelet-insecure-tls' components.yaml
c. 应用改好的配置
bash 运行
kubectl apply -f components.yaml
d. 等待 1–2 分钟,检查状态
bash 运行
kubectl get pods -n kube-system | grep metrics-server
正常会变成:
metrics-server-xxxx 1/1 Running
f. 验证(关键)
bash 运行
kubectl top nodes
kubectl top pods -A
能看到 CPU / 内存 数据就彻底好了。
2. ingress-nginx 网关
1)先全量清理:default 空间 Nginx + 所有 Ingress 规则 + 彻底卸载 ingress-nginx 控制器
a. 清理 default 命名空间 Nginx 应用(你之前创建的)
bash 运行
# 删除ingress路由规则
kubectl delete ingress nginx-ingress
# 删除nginx部署与service
kubectl delete deploy nginx
kubectl delete svc nginx
# 校验:下面两条输出无nginx才算删干净
kubectl get deploy,svc,ingress
b. 彻底卸载 ingress-nginx 控制器(分 Helm/YAML 两种,依次执行)
bash 运行
# ① 先查helm安装记录
helm list -n ingress-nginx
# 有release就卸载
helm uninstall ingress-nginx -n ingress-nginx --ignore-not-found
# ② 删除命名空间(清空ns内所有pod/svc/cm/sa)
kubectl delete ns ingress-nginx --ignore-not-found
# ③ 清理集群级残留(关键,不然重装冲突)
kubectl delete clusterrole ingress-nginx -ignore-not-found
kubectl delete clusterrolebinding ingress-nginx -ignore-not-found
kubectl delete validatingwebhookconfiguration ingress-nginx-admission -ignore-not-found
# 删除ingressclass(旧配置残留)
kubectl delete ingressclass nginx --ignore-not-found
c. 校验清理完成
bash 运行
kubectl get ns |grep ingress
kubectl get ingressclass
# 无任何ingress-nginx、nginx相关资源即清理完毕
2)安装 ingress-nginx
bash 运行
# 如果能访问到国外镜像源,可以直接用下面
kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/main/deploy/static/provider/baremetal/deploy.yaml
#如果上面的不能用,大多数没办法拉取国外镜像源的情况,可以用下面方式:
# 下载baremetal配置
wget https://raw.githubusercontent.com/kubernetes/ingress-nginx/main/deploy/static/provider/baremetal/deploy.yaml
# 全局镜像前缀替换(DaoCloud镜像加速,不用管版本、sha哈希)
sed -i 's|registry.k8s.io|m.daocloud.io/registry.k8s.io|g' deploy.yaml
# 开启hostNetwork: true(baremetal必加,直接占用宿主机80/443)
sed -i '/dnsPolicy: ClusterFirst/a \ hostNetwork: true' deploy.yaml
kubectl apply -f deploy.yaml实时查看状态,作为验证是否有效
bash 运行
kubectl get pod -n ingress-nginx -w
✅ 你一定会看到
NAME READY STATUS RESTARTS AGE
ingress-nginx-xxxxxx-xxxxx 1/1 Running 0 10s
正常顺序:
- admission-create、patch 从 ImagePullBackOff → Pulling → Pulled → Completed
- controller 从 ContainerCreating → Running
部署完发kubectl get pod -n ingress-nginx结果。
3. 本地存储类(自动 PVC)
bash 运行
kubectl apply -f https://raw.githubusercontent.com/rancher/local-path-provisioner/master/deploy/local-path-storage.yaml
kubectl patch storageclass local-path -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"true"}}}'
4. Dashboard 控制台
1)先清空所有错误资源
bash 运行
kubectl delete namespace kubernetes-dashboard
2)粘贴这个 100% 可运行 的官方完整 YAML(国内镜像版)
bash 运行
kubectl apply -f https://cdn.jsdelivr.net/gh/kubernetes/dashboard@v2.7.0/aio/deploy/recommended.yaml
3)立刻替换镜像(国内秒拉)
bash 运行
kubectl set image -n kubernetes-dashboard deployment/kubernetes-dashboard kubernetes-dashboard=registry.aliyuncs.com/google_containers/dashboard:v2.7.0
kubectl set image -n kubernetes-dashboard deployment/dashboard-metrics-scraper dashboard-metrics-scraper=registry.aliyuncs.com/google_containers/metrics-scraper:v1.0.8
4)改成 NodePort(外部可访问)
bash 运行
kubectl patch service kubernetes-dashboard -n kubernetes-dashboard -p '{"spec":{"type":"NodePort"}}'
5)现在查看状态(必 Running)
bash 运行
kubectl get pods -n kubernetes-dashboard -w
你会看到:
dashboard-metrics-scraper-xxx 1/1 Running
kubernetes-dashboard-xxx 1/1 Running
6)查看访问端口
bash 运行
kubectl get svc -n kubernetes-dashboard
你会看到类似:
443:32632/TCP
浏览器打开:
https://10.10.6.29:32632
7)获取登录 Token
bash 运行
kubectl create serviceaccount admin -n kube-system
kubectl create clusterrolebinding admin --clusterrole=cluster-admin --serviceaccount=kube-system:admin
kubectl create token admin -n kube-system
复制 Token → 登录 → 成功!
【硬件资源】
3 台 × 8 核 64G → 企业级生产完全够用
- Master 占用:每台 2 核 4G
- 剩余:每台 6 核 60G 可跑业务
- 硬盘 1T → 足够存镜像、日志、数据
【高可用方案】
3 个节点 All-in-One 高可用 K8s
- 高可用 etcd
- 高可用 master
- 3 台都能跑业务
- 无单点故障
- 企业生产标准架构
八、安全关闭 K8s 集群 标准顺序
总顺序(从业务 → 数据 → 控制面 → 节点)
- 排空节点(驱逐 Pod)
- 关闭节点调度
- 关闭 worker /master 节点
- 最后关闭 etcd 所在节点(3 台都关)
1. 逐行可直接复制的命令(安全关机流程)
1)在 任意 master 执行:排空所有节点(安全驱逐 Pod)
bash 运行
kubectl get nodes | awk '/node-/ {print $1}' | xargs -I {} kubectl drain {} --force --ignore-daemonsets --delete-emptydir-data
2)禁用调度(防止关机时飘 Pod)
bash 运行
kubectl get nodes | awk '/node-/ {print $1}' | xargs -I {} kubectl cordon {}
2. 关闭节点 顺序(非常重要!)
正确关机顺序(3 台)
先关 node2 → 再关 node3 → 最后关 node1(master1)
因为 etcd 集群必须保留最后一台为 leader,最后关闭第一个 master 最安全。
3. 每台机器执行关机命令(选一个)
bash 运行
# 安全关机
systemctl poweroff
# 或者
shutdown -h now
4. 如果你只是想 停止 K8s 服务,不关机
(适合维护、排错) 所有节点都执行:
bash 运行
systemctl stop kubelet
systemctl stop containerd
启动恢复:
bash 运行
systemctl start containerd
systemctl start kubelet
5、如果你想 彻底销毁集群(重装用)
所有节点执行:
bash 运行
kubeadm reset -f
rm -rf /etc/kubernetes
rm -rf /var/lib/kubelet
rm -rf /var/lib/etcd
rm -rf ~/.kube
iptables -F && iptables -t nat -F
ip link delete cni0
ip link delete flannel.1
# 杀掉线程
pkill -f kube
pkill -f etcd
pkill -f apiserver
pkill -f controller-manager
pkill -f scheduler
pkill -f containerd-shim
pkill -f cni
安全关机
先排空 → 再禁用调度 → 先关 2、3 节点 → 最后关 1 节点
停止服务
先停 kubelet → 再停 containerd
销毁集群
kubeadm reset -f → 删目录 → 清网络
九、常见问题
1. swap 没关(最常见)
bash 运行
free -m
看到 Swap 那行不是 0,就是问题。 解决:
bash 运行
swapoff -a
sed -i '/swap/s/^/#/' /etc/fstab
2. containerd 没开 systemd cgroup(你之前可能没生效)
bash 运行
grep SystemdCgroup /etc/containerd/config.toml
必须输出:plaintext
SystemdCgroup = true
如果是 false,重新执行:
bash 运行
containerd config default > /etc/containerd/config.toml
sed -i 's/SystemdCgroup = false/SystemdCgroup = true/' /etc/containerd/config.toml
systemctl daemon-reload
systemctl restart containerd
3. containerd 本身没启动 / 报错
bash 运行
systemctl status containerd
journalctl -u containerd -n 20
kubelet 依赖 containerd,containerd 挂了,kubelet 必挂。
4. kubelet 配置文件缺失 / 损坏
bash 运行
ls -l /var/lib/kubelet/config.yaml
ls -l /etc/kubernetes/kubelet.conf
这两个文件必须存在,否则 kubelet 起不来。
5. 证书问题(如果是 node 节点)
bash 运行
ls -l /etc/kubernetes/pki/
节点需要ca.crt 和 kubelet 证书,没证书连不上 master。
6. Dashboard 网页看不到 kubernetes-dashboard 命名空间 Pod
四步排查(90% 是RBAC 绑定异常)
1)先在命令行确认:集群里确实有 Pod
bash 运行
# 查看dashboard命名空间所有pod
kubectl get pods -n kubernetes-dashboard
有输出 = Pod 真实存在,纯页面权限问题;无输出 = 没部署 dashboard 组件。
2)校验你的 dashboard-admin 账号权限(核心)
a.测试账号能不能查看 pod
bash 运行
# 模拟这个sa去查pod,返回yes=有权限,no=绑定失效
kubectl auth can-i list pods -n kubernetes-dashboard \
--as=system:serviceaccount:kubernetes-dashboard:dashboard-admin
b.你之前报错:dashboard-admin-binding已存在,大概率绑定对象写错 / 失效,删掉重建
bash 运行
# 删除旧绑定
kubectl delete clusterrolebinding dashboard-admin-binding
# 重新正确绑定
kubectl create clusterrolebinding dashboard-admin-binding \
--clusterrole=cluster-admin \
--serviceaccount=kubernetes-dashboard:dashboard-admin
绑定格式:
命名空间:ServiceAccount名称,你是kubernetes-dashboard:dashboard-admin没错,旧绑定异常直接删了重建最稳妥。
c.退出网页,重新生成新 Token 登录
bash
运行
# 生成30天有效期token
kubectl create token dashboard-admin -n kubernetes-dashboard --duration=720h
- 浏览器清空缓存 / 无痕打开 dashboard
- 粘贴新 token 登录
- 顶部下拉框手动选中:kubernetes-dashboard命名空间,即可看到 Pod
7.查看 K8s 所有命名空间(Namespace)
1)查看所有 namespace(最常用)
bash 运行
kubectl get ns
或者完整写法:
bash 运行
kubectl get namespaces
你会看到类似这样的结果
NAME STATUS AGE
default Active 45d
kube-node-lease Active 45d
kube-public Active 45d
kube-system Active 45d
kubernetes-dashboard Active 45d
2)每个 namespace 是干嘛的?
- default:默认命名空间,你没指定时都在这里
- kube-system:K8s 系统组件(kube-proxy、coredns、metrics-server、calico)
- kube-public:公共信息
- kube-node-lease:节点心跳
- kubernetes-dashboard:你刚装的 UI 面板
3)想查看某个命名空间下的 Pod
例如看 kube-system 里的 Pod:
bash 运行
kubectl get pods -n kube-system
看 Dashboard:
bash 运行
kubectl get pods -n kubernetes-dashboard
x. 如果还有问题,就查看日志
bash 运行
journalctl -u kubelet -n 100 --no-pager
根据日志报错信息,看看怎么修。

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)