Prometheus + Grafana 服务器监控实战:Docker Compose 一键部署,从零搭建运维监控看板
用 Docker Compose 一键部署 Prometheus + Grafana + NodeExporter,实时监控服务器CPU、内存、磁盘、网络。包含架构详解、配置逐行解释、4个踩坑记录,适合运维新手入门。
作为运维,服务器出了问题才去排查?太被动了。真正的做法是:让问题主动来找你。本文用 Docker Compose 一键部署 Prometheus + Grafana 监控系统,实时掌握服务器的 CPU、内存、磁盘、网络状态,把被动救火变成主动预防。
前言
刚学运维的时候,我对"监控"没什么概念。服务器能用就行,出了问题再排查呗。
直到有一次,线上服务器磁盘满了,服务挂了两个小时才被用户反馈发现。领导问了一句:“你们没有监控吗?”
从那之后我才意识到:监控是运维的基本功,不是可选项。
本文记录我用 Docker Compose 部署 Prometheus + Grafana 监控系统的完整过程,包括架构设计、配置详解、踩坑记录,适合和我一样的运维新手入门。
一、为什么需要监控?
传统运维的痛点
| 场景 | 没有监控 | 有监控 |
|---|---|---|
| CPU 飙高 | 用户反馈卡顿才发现 | 提前告警,主动处理 |
| 磁盘满了 | 服务挂了才知道 | 80% 就提醒,提前清理 |
| 内存泄漏 | 运行几天后崩溃 | 趋势图一眼看出来 |
| 流量突增 | 不知道,直到服务器扛不住 | 实时看到流量变化 |
监控系统的价值
- 主动发现问题:不用等用户反馈,指标异常自动告警
- 快速定位原因:CPU 高?内存满?网络拥堵?图表一目了然
- 数据驱动决策:该扩容了还是该优化代码?看数据说话
- 事后复盘分析:回溯故障时间段的指标变化,找到根因
二、Prometheus + Grafana 是什么?
一句话解释
- Prometheus — 采集数据、存储数据(时序数据库)
- Grafana — 展示数据、生成图表(可视化看板)
- Node Exporter — 采集服务器指标的"探针"
类比理解
把监控系统想象成医院的体检中心:
| 组件 | 医院类比 | 作用 |
|---|---|---|
| Node Exporter | 检测仪器 | 采集心跳、血压、体温等数据 |
| Prometheus | 检验科 | 把检测数据存档、分析 |
| Grafana | 体检报告 | 把数据变成直观的图表 |
架构图
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ 服务器 │ │ Prometheus │ │ Grafana │
│ │ │ │ │ │
│ Node │────▶│ 采集数据 │────▶│ 展示图表 │
│ Exporter │ │ 存储数据 │ │ 生成看板 │
│ (采集指标) │ │ │ │ │
└─────────────┘ └─────────────┘ └─────────────┘
端口:9100 端口:9090 端口:3000
数据流向:
- Node Exporter 部署在服务器上,每时每刻采集 CPU、内存、磁盘、网络等指标
- Prometheus 每 15 秒主动去 Node Exporter 拉取一次数据,存入自己的时序数据库
- Grafana 从 Prometheus 读取数据,生成实时更新的图表
为什么是 Prometheus 主动拉而不是 Node Exporter 主动推?
这叫 Pull 模型。好处是:
- Prometheus 统一控制采集频率,不用每个采集目标都配置
- 采集目标挂了,Prometheus 立刻知道(拉不到数据了)
- 方便扩展,新增服务器只需在 Prometheus 配置里加一行地址
三、什么是时序数据库?
Prometheus 用的是时序数据库(TSDB),专门存储按时间顺序排列的数据。
和 MySQL 的区别
MySQL 存用户信息:
| 姓名 | 年龄 | 城市 |
|--------|------|--------|
| 张三 | 20 | 北京 |
| 李四 | 22 | 上海 |
这种数据不怎么变,叫"状态数据"。
时序数据库存监控数据:
| 时间 | CPU使用率 |
|----------------|-----------|
| 10:00:00 | 30% |
| 10:00:15 | 35% |
| 10:00:30 | 28% |
| 10:00:45 | 90% |
| ...每15秒一条... |
为什么不用 MySQL?
假设 15 秒采一次,1 台服务器 1 天 = 5760 条数据,10 台服务器 1 个月 = 170 万条。
用 MySQL 存也能跑,但:
- 查询"最近 1 小时 CPU 平均值"要扫大量行,慢
- 数据都是追加,不需要 MySQL 的修改、删除、关联查询功能,浪费
- 存储效率低,同样的数据占更多空间
时序数据库专门为这种场景优化:
- 写入极快(数据天然按时间排好)
- 查询某个时间段极快(索引按时间建的)
- 压缩率高(相邻时间的值差不多,压缩后省空间)
简单理解:MySQL 是通用工具箱,时序数据库是专用工具。监控数据这种"按时间排列、只增不改"的场景,专用工具更快更省。
四、Docker Compose 一键部署
4.1 项目结构
prometheus-grafana/
├── docker-compose.yml # 主编排文件
├── prometheus/
│ └── prometheus.yml # Prometheus 配置
├── grafana/
│ ├── provisioning/
│ │ ├── datasources/
│ │ │ └── prometheus.yml # 数据源自动配置
│ │ └── dashboards/
│ │ └── dashboards.yml # 看板自动配置
│ └── dashboards/
│ └── node-exporter.json # 看板模板(从 Grafana 社区下载)
└── README.md
4.2 Prometheus 配置
global:
scrape_interval: 15s # 每 15 秒采集一次
scrape_timeout: 10s # 采集超时时间
scrape_configs:
# 监控 Prometheus 自身
- job_name: "prometheus"
static_configs:
- targets: ["localhost:9090"]
# 监控服务器(通过 Node Exporter)
- job_name: "node-exporter"
static_configs:
- targets: ["node-exporter:9100"]
逐行解释:
scrape_interval: 15s— Prometheus 每 15 秒去抓一次数据,生产环境一般 15-60 秒job_name— 采集任务的名称,可以理解为一组采集目标targets— 采集目标的地址,用容器名node-exporter而不是localhost,因为它们在同一个 Docker 网络里
4.3 docker-compose.yml
services:
# Prometheus — 时序数据库,采集和存储监控数据
prometheus:
image: prom/prometheus:latest
container_name: prometheus
restart: unless-stopped
ports:
- "9090:9090"
volumes:
- ./prometheus/prometheus.yml:/etc/prometheus/prometheus.yml:ro
- prometheus_data:/prometheus
command:
- "--config.file=/etc/prometheus/prometheus.yml"
- "--storage.tsdb.retention.time=15d"
- "--web.enable-lifecycle"
networks:
- monitoring
# Node Exporter — 采集服务器指标(CPU/内存/磁盘/网络)
node-exporter:
image: prom/node-exporter:latest
container_name: node-exporter
restart: unless-stopped
ports:
- "9100:9100"
volumes:
- /proc:/host/proc:ro
- /sys:/host/sys:ro
- /:/rootfs:ro
command:
- "--path.procfs=/host/proc"
- "--path.sysfs=/host/sys"
- "--path.rootfs=/rootfs"
- "--collector.filesystem.mount-points-exclude=^/(sys|proc|dev|host|etc)($$|/)"
networks:
- monitoring
# Grafana — 可视化看板,把数据变成图表
grafana:
image: grafana/grafana:latest
container_name: grafana
restart: unless-stopped
ports:
- "3000:3000"
environment:
- GF_SECURITY_ADMIN_USER=admin
- GF_SECURITY_ADMIN_PASSWORD=admin
volumes:
- grafana_data:/var/lib/grafana
- ./grafana/provisioning/datasources:/etc/grafana/provisioning/datasources:ro
- ./grafana/provisioning/dashboards:/etc/grafana/provisioning/dashboards:ro
- ./grafana/dashboards:/var/lib/grafana/dashboards:ro
depends_on:
- prometheus
networks:
- monitoring
volumes:
prometheus_data:
grafana_data:
networks:
monitoring:
driver: bridge
关键配置解释:
Node Exporter 的 volumes:
- /proc:/host/proc:ro
- /sys:/host/sys:ro
- /:/rootfs:ro
Node Exporter 需要读取宿主机的 /proc(进程信息)和 /sys(内核信息)来采集指标。挂载时加 :ro(只读),安全起见只让它读,不让它改。
--collector.filesystem.mount-points-exclude:
--collector.filesystem.mount-points-exclude=^/(sys|proc|dev|host|etc)($$|/)
排除 /proc、/sys 等虚拟文件系统。这些不是真实磁盘,Node Exporter 需要读它们获取数据,但不需要监控它们的"磁盘使用量"(这个问题本身就不存在)。
注意 $$ 是 Docker Compose 的转义写法,因为 $ 在 YAML 里有特殊含义。传到容器里后 $$ 变成普通的 $。
Grafana 的 volumes:
- ./grafana/provisioning/datasources:/etc/grafana/provisioning/datasources:ro
- ./grafana/provisioning/dashboards:/etc/grafana/provisioning/dashboards:ro
- ./grafana/dashboards:/var/lib/grafana/dashboards:ro
这三行实现了自动化配置:
- 第一行:自动连接 Prometheus 数据源,不用手动在 Grafana 界面添加
- 第二行:告诉 Grafana 去哪里找看板 JSON 文件
- 第三行:把看板 JSON 文件挂载到容器里
数据持久化:
volumes:
prometheus_data: # Prometheus 的时序数据
grafana_data: # Grafana 的配置和看板
不用 Docker Volume 的话,容器删了数据就没了。加了这两个卷,容器重建后历史数据还在。
4.4 Grafana 配置文件
除了 docker-compose.yml,Grafana 还需要两个 provisioning 配置文件,实现数据源和看板的自动配置。
数据源配置(grafana/provisioning/datasources/prometheus.yml):
apiVersion: 1
datasources:
- name: Prometheus
type: prometheus
access: proxy
url: http://prometheus:9090
isDefault: true
editable: true
这个文件告诉 Grafana:Prometheus 数据源在哪(http://prometheus:9090),并且设为默认数据源。Grafana 启动时自动连接,不需要手动在界面添加。
看板配置(grafana/provisioning/dashboards/dashboards.yml):
apiVersion: 1
providers:
- name: "default"
orgId: 1
folder: ""
type: file
disableDeletion: false
editable: true
options:
path: /var/lib/grafana/dashboards
foldersFromFilesStructure: false
这个文件告诉 Grafana:去 /var/lib/grafana/dashboards 目录找 JSON 看板文件,找到就自动加载。
看板模板:从 Grafana 社区下载 Node Exporter 看板(Dashboard ID: 1860),访问 https://grafana.com/grafana/dashboards/1860 获取 JSON 文件,放入 grafana/dashboards/ 目录。
4.5 一键启动
docker-compose up -d
三个容器几秒钟就全部启动完成。
五、效果展示
5.1 容器运行状态
docker-compose ps
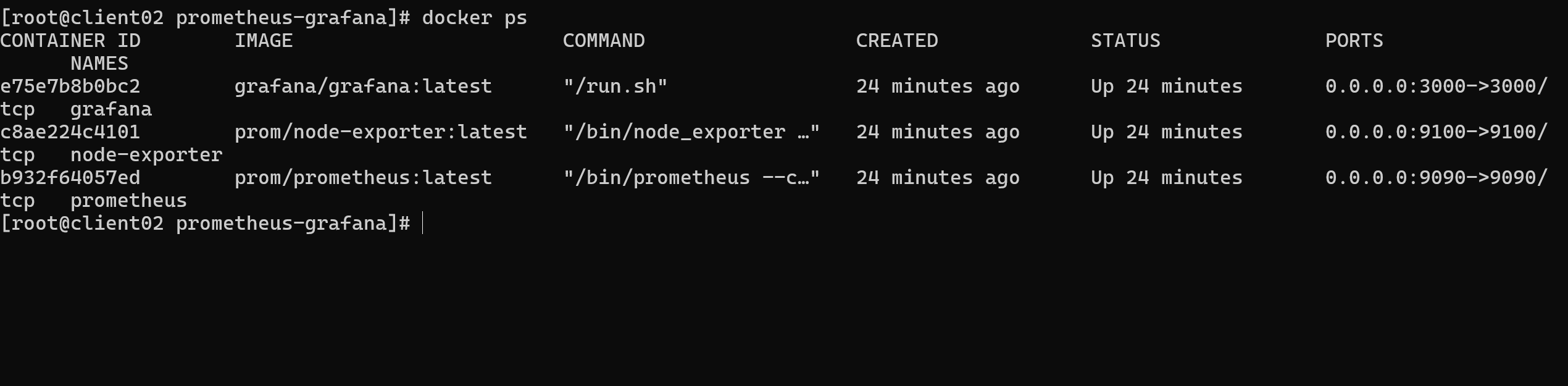
三个容器全部 Up:Prometheus(9090)、Node Exporter(9100)、Grafana(3000)。
5.2 Prometheus 监控目标
访问 http://localhost:9090/targets:
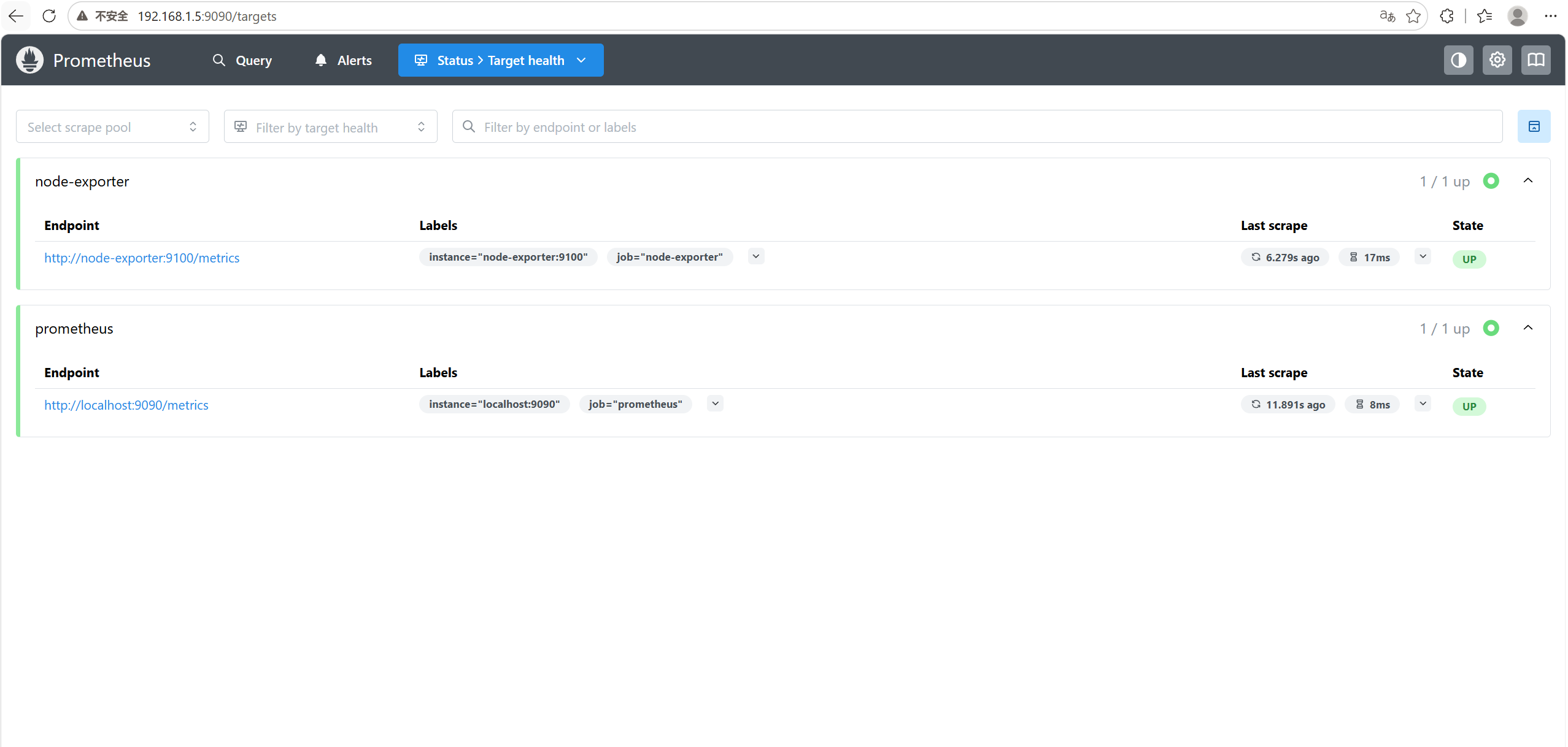
两个 Target 状态都是 UP,说明 Prometheus 已经在正常采集数据。
5.3 Grafana 监控看板
访问 http://localhost:3000,默认账号密码都是 admin:
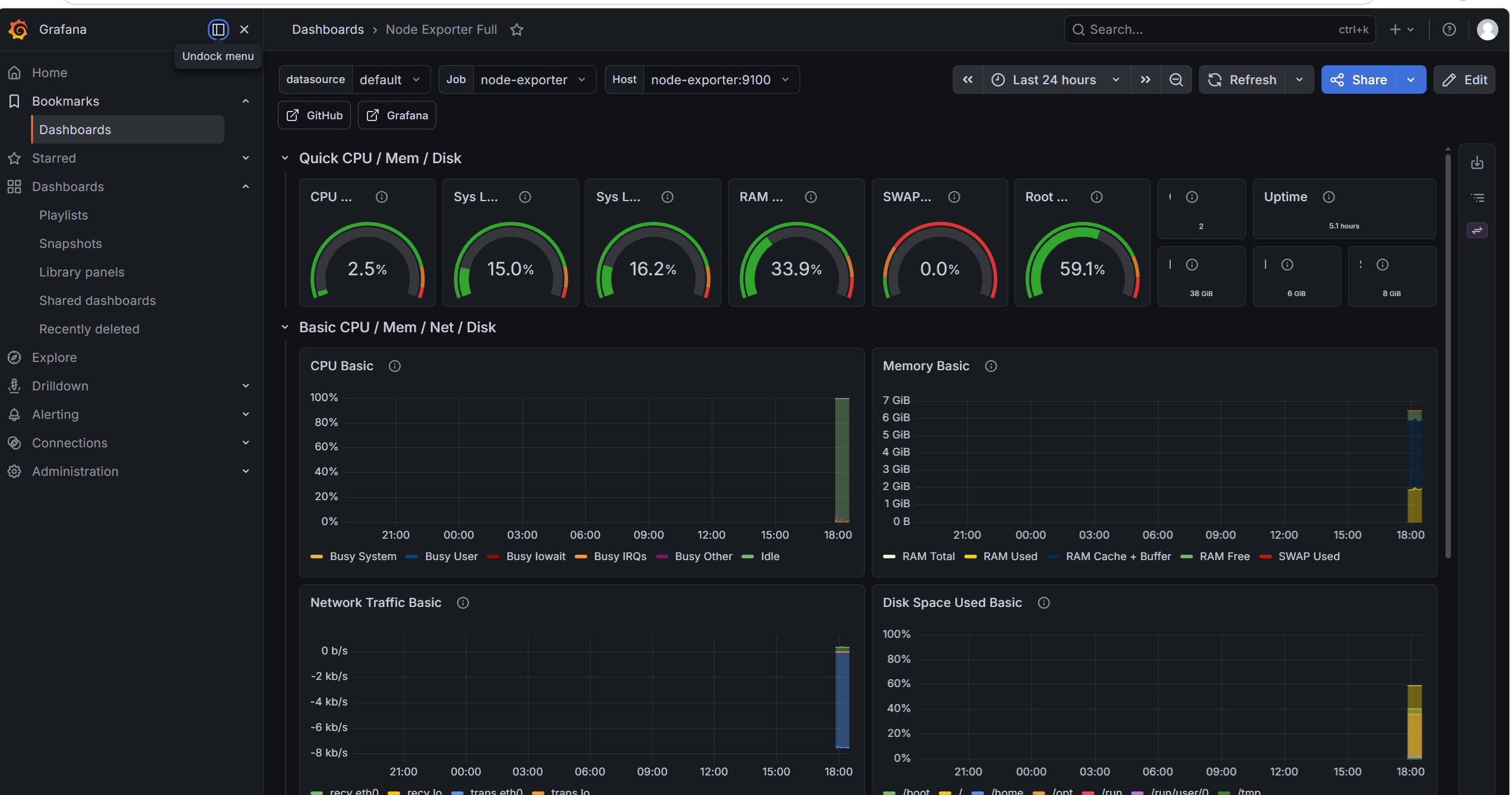
看板实时展示服务器核心指标:
- CPU Busy — CPU 使用率
- RAM Used — 内存使用率
- Root FS Used — 磁盘使用率
- Uptime — 服务器运行时长
数据每 15 秒自动刷新,不需要手动操作。
5.4 图表详情
点击某个图表可以放大查看详细数据:
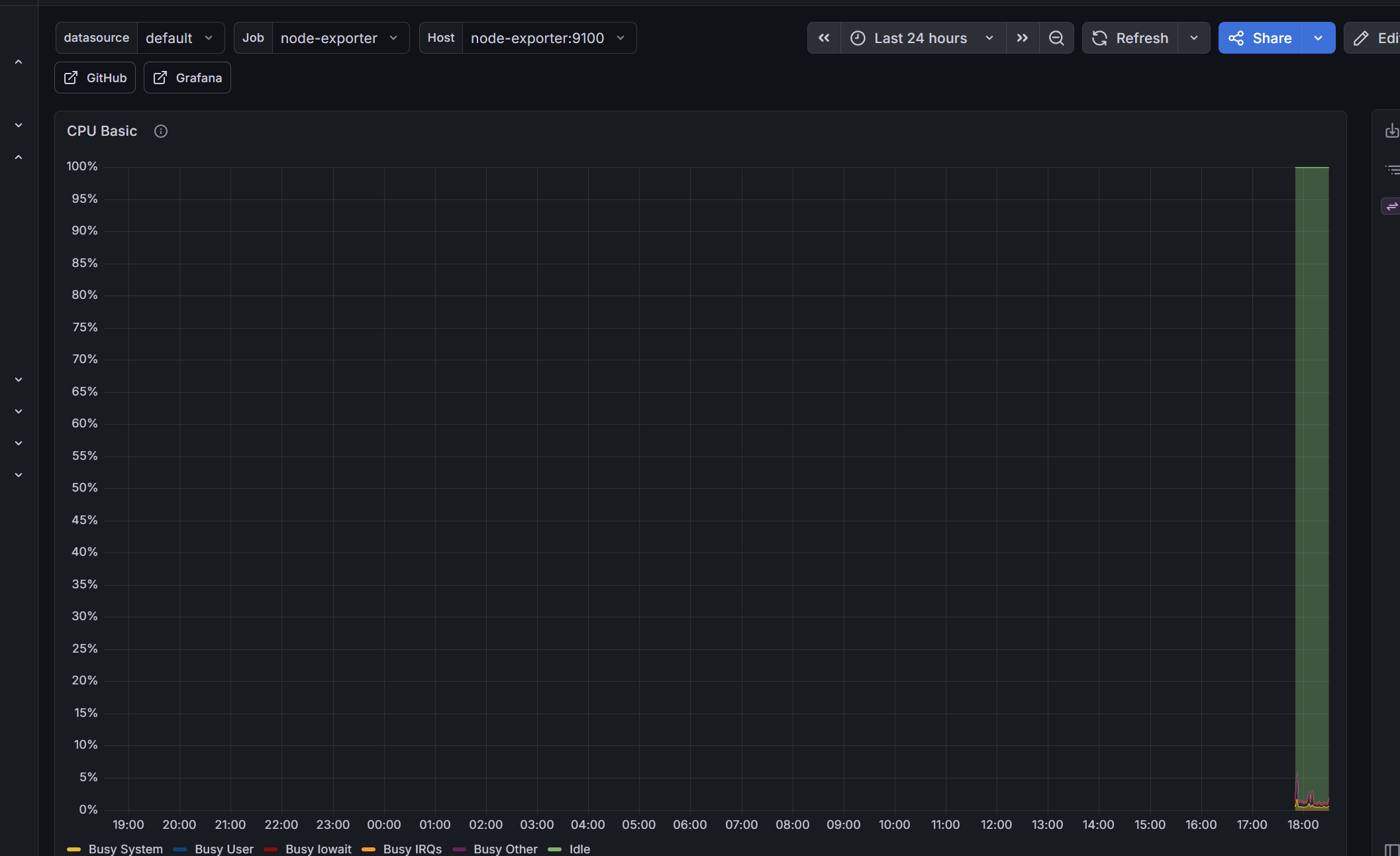
CPU 图表展示了 System(系统态)、User(用户态)、Iowait(IO等待)等各项细分指标。生产环境中,这些线条会随着服务器负载实时波动,一眼就能看出哪里有问题。
六、踩坑记录
踩坑 1:Prometheus 一直 Restarting
现象:docker-compose up -d 后,Prometheus 容器状态一直是 Restarting,无法正常运行。
排查:
docker-compose logs prometheus
日志报错:
field scarpe_timeout not found in type config.plain
原因:prometheus.yml 里 scrape_timeout 拼写成了 scarpe_timeout,少了个 r,a 和 p 的顺序也反了。
解决:修正拼写后重启:
docker-compose restart prometheus
教训:YAML 配置文件的字段名拼错,程序不会自动纠正。容器出问题第一反应是看日志,Restarting 状态只说明容器在循环重启,日志里才有真正的错误原因。
踩坑 2:Grafana 看板不显示
现象:Grafana 启动正常,登录后 Dashboards 页面是空的。
排查:检查 grafana/provisioning/dashboards/dashboards.yml,发现第 4 行:
provides: # ← 错的,少了字母 r
应该是:
providers: # ← 正确的
解决:修正拼写后重启 Grafana:
docker-compose restart grafana
教训:和踩坑 1 一样,拼写错误是最容易犯也最难发现的错误。肉眼检查很容易漏掉,所以看日志是第一优先级。
踩坑 3:$$ 在 docker-compose.yml 中是什么意思?
现象:Node Exporter 配置里看到 ($$|/),不理解为什么是两个 $。
解释:$ 在 docker-compose.yml 里是变量引用的前缀(如 ${HOME})。要表示一个普通的 $ 字符,需要用 $$ 转义。
传到容器里后,$$ 变成 $,正则表达式变成 ($|/),意思是"字符串结尾或斜杠"。
踩坑 4:容器出问题怎么排查?
这次实验让我总结出一个排查流程:
容器状态异常
↓
docker-compose logs 容器名 ← 第一步永远是看日志
↓
找到报错信息
↓
配置文件拼写错误 / 端口冲突 / 依赖服务未启动
↓
修正后 docker-compose restart
90% 的容器问题都能靠看日志解决。剩下 10% 可能需要进容器里面排查:
docker exec -it 容器名 /bin/sh
七、常用运维命令
# 查看所有服务状态
docker-compose ps
# 实时跟踪日志
docker-compose logs -f
# 查看某个服务的日志
docker-compose logs prometheus
# 停止服务(保留数据)
docker-compose down
# 停止并删除数据
docker-compose down -v
# 重启服务
docker-compose restart
# Prometheus 热重载配置(不用重启)
curl -X POST http://localhost:9090/-/reload
八、PromQL 基础查询
PromQL 是 Prometheus 的查询语言,在 http://localhost:9090/graph 可以直接执行:
# CPU 使用率(排除空闲)
100 - (avg(rate(node_cpu_seconds_total{mode="idle"}[5m])) * 100)
# 可用内存(GB)
node_memory_MemAvailable_bytes / 1024 / 1024 / 1024
# 磁盘使用率
(node_filesystem_size_bytes{mountpoint="/"} - node_filesystem_avail_bytes{mountpoint="/"}) / node_filesystem_size_bytes{mountpoint="/"} * 100
# 网络接收速率(bytes/s)
rate(node_network_receive_bytes_total[5m])
这些查询在 Grafana 的图表里也会用到,理解 PromQL 能让你自定义更精确的监控图表。
九、总结
通过这次实验,我学到了:
- 监控的重要性 — 运维不是出了问题才去修,而是要提前发现问题
- Prometheus 的 Pull 模型 — 主动拉取比被动推送更容易管理
- 时序数据库的原理 — 专用工具比通用工具更适合监控场景
- Docker 网络 — 同一网络内的容器可以用容器名互相访问
- 数据持久化 — Docker Volume 让容器删了数据不丢
- 日志排查 — 容器出问题第一反应是看日志
Prometheus + Grafana 是目前最主流的开源监控方案,企业里广泛使用。对于运维新手来说,这是一个非常值得掌握的技能。
项目已开源,欢迎 Star:https://gitee.com/pengjia12345/prometheus-grafana

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐
 20
20 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)