深入理解进程虚拟地址空间
本文首先回顾了环境变量和命令行参数的概念,重点讲解了环境变量的全局属性和获取方式。然后通过实验揭示了fork创建子进程后的一个关键现象:父子进程访问相同虚拟地址却得到不同值,证明程序中看到的地址都是虚拟地址而非物理地址。文章深入分析了虚拟地址空间的原理,指出操作系统通过页表维护虚拟地址到物理地址的映射关系,解释了为什么同一虚拟地址在不同进程中可能指向不同的物理内存内容。最后强调访问内存的基本单位是

.
专栏:数据结构|Linux|C语言
路漫漫其修远兮,吾将上下而求索
文章目录
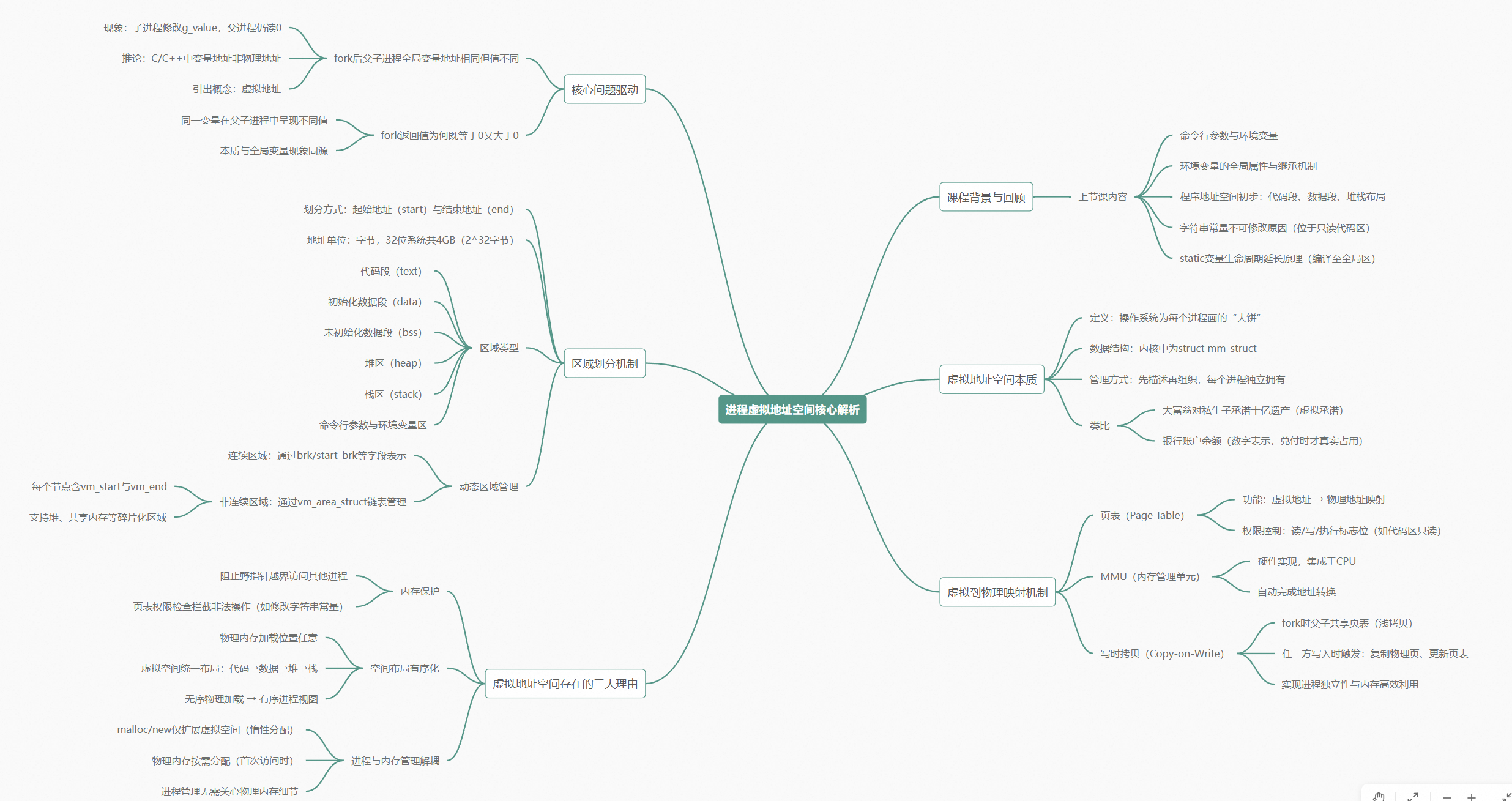
深入理解进程虚拟地址空间
一、上节课回顾:环境变量与命令行参数
上节课我们重点讲解了两大块内容:命令行参数和环境变量。
环境变量是系统在 Bash 中维护的一组系统级全局变量。不同的环境变量各有各的功能,彼此之间没有明显的逻辑关系,但侧重点不同:
PATH:记录二进制程序的搜索路径HOME:记录当前用户的家目录PWD和OLDPWD:记录当前工作路径和上一次的工作路径HISTSIZE:记录历史命令的条数HOSTNAME:记录主机名USER:记录用户名
这些环境变量在系统开机时,为每一个用户创建 Bash(命令行解释进程)时,从系统配置文件中加载。在编程中,我们可以通过多种方式获取环境变量。
在进程(尤其是父进程 Bash)当中,存在两张表:命令行参数表和环境变量表。命令行参数主要用来给可执行程序设置选项功能——我们平时使用的 ls、pwd 等命令可以带选项,就是因为命令行参数的存在。
获取环境变量的三种方式:
- 通过
main函数的第三个参数envp(也可以通过前两个参数argc和argv间接获取) - 通过第三方变量
environ - 通过系统调用
getenv()获取指定名称的环境变量内容
环境变量相关的常用命令:
| 命令 | 功能 |
|---|---|
echo $VAR |
查看环境变量的内容 |
export VAR=value |
导出环境变量 |
env |
查看所有环境变量 |
set |
查看包括本地变量在内的所有变量 |
unset VAR |
取消环境变量 |
环境变量的全局属性:环境变量表是可以被子进程继承的。父进程 Bash 从配置文件获取环境变量后,创建子进程时,子进程能拿到父进程的环境变量表。子进程的子进程同样也能获取。因此,从登录系统开始,我们创建的所有任务形成了一棵进程树,从 Bash 进程开始往后的所有子进程,都能拿到环境变量,所以环境变量具有全局属性。
与之相对的是本地变量,只在 Bash 内部有效——比如在命令行中用 while 循环定义的变量,就是本地的。
二、程序地址空间入门
上节课我们还初步进入了程序地址空间的话题。
在 C/C++ 编程中,我们经常会遇到程序地址空间的概念。在 32 位平台下,从低地址到高地址的布局如下:
- 代码段(代码区 / 正文段):存放程序的代码
- 初始化数据区:存放已初始化的全局变量和静态变量
- 未初始化数据区(BSS 段):存放未初始化的全局变量和静态变量
- 堆区:动态内存分配区域,从低地址向高地址增长
- 栈区:函数调用栈,从高地址向低地址增长,堆栈相对而生
- 命令行参数和环境变量:也隶属于程序地址空间
上节课我们用代码验证了这些区域在地址空间中的排布确实符合这个图。
同时也解决了两个问题:
- 为什么字符串常量不能被直接修改? 因为字符串常量在编译时被放到了代码区,而代码区是只读的,所以字符串常量也只能读不能写。
- 为什么
static修饰的变量生命周期变为全局? 因为static修饰的变量在编译之后,局部变量会被提升为全局变量,放入全局数据区。
三、从一个实验说起:fork 之后的诡异现象
实验一:父子都不修改
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int g_val = 0;
int main()
{
pid_t id = fork();
if (id < 0) {
perror("fork");
return 0;
}
else if (id == 0) { // child
printf("child[%d]: %d : %p\n", getpid(), g_val, &g_val);
}
else { // parent
printf("parent[%d]: %d : %p\n", getpid(), g_val, &g_val);
}
sleep(1);
return 0;
}
编译运行:
gcc -o myproc myproc.c
./myproc
输出结果(与环境相关,观察现象即可):
parent[2995]: 0 : 0x80497d8
child[2996]: 0 : 0x80497d8
父子进程打印出来的变量值和地址一模一样——这很好理解,因为子进程以父进程为模板,父子都没有对变量进行任何修改。
实验二:子进程修改全局变量
将代码稍加改动:
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int g_val = 0;
int main()
{
pid_t id = fork();
if (id < 0) {
perror("fork");
return 0;
}
else if (id == 0) { // child,子进程先跑完,先修改,完成之后父进程再读取
g_val = 100;
printf("child[%d]: %d : %p\n", getpid(), g_val, &g_val);
}
else { // parent
sleep(3);
printf("parent[%d]: %d : %p\n", getpid(), g_val, &g_val);
}
sleep(1);
return 0;
}
输出结果:
child[3046]: 100 : 0x80497e8
parent[3045]: 0 : 0x80497e8
诡异的现象出现了:父子进程输出的地址一致,但变量内容不一样!
实验三:循环版本——让两个进程同时运行
为了看得更清楚,我们改写为循环版本,让父子进程每隔一秒各自打印:
#include <stdio.h>
#include <unistd.h>
int g_value = 0;
int main() {
pid_t id = fork();
if (id == 0) {
// 子进程
while (1) {
printf("child: pid=%d, g_value=%d, &g_value=%p\n",
getpid(), g_value, &g_value);
sleep(1);
g_value++;
}
} else if (id > 0) {
// 父进程
while (1) {
printf("parent: pid=%d, g_value=%d, &g_value=%p\n",
getpid(), g_value, &g_value);
sleep(1);
}
}
return 0;
}
运行结果:
- 最开始:父子进程打印的
g_value都是0,地址也相同(例如都是0x601058) - 过了一会儿:父进程打印的
g_value始终是0(因为父进程没有修改它);子进程打印的g_value则是1, 2, 3, 4, 5...(因为子进程每秒对它做++操作)
子进程认为变量已经是 2 了,父进程读取时依旧是 0,但两者的地址竟然一样!同时两个死循环都在跑——如果是单进程,if 和 else 两个分支不可能同时进入,但因为 fork 创建了双进程,两个分支就同时执行了。
这引发了一个根本性的问题:如果父子双方访问的地址 0x601058 是物理内存地址,那么同一个物理内存地址被父进程读取时是 0,被子进程读取时却是 2——这种情况可能存在吗?
答案是不可能。 同一个物理内存地址在同一时刻只能存储一个值。
由此我们得出一个重要的结论:
- 变量内容不一样,所以父子进程输出的变量绝对不是同一个变量
- 但地址值是一样的,说明该地址绝对不是物理地址!
- 在 Linux 下,这种地址叫做虚拟地址
- 我们在 C/C++ 语言中所看到的地址,全部都是虚拟地址!物理地址用户一概看不到,由操作系统统一管理
- 操作系统必须负责将虚拟地址转化成物理地址
四、虚拟地址与物理地址
实际上,这种现象我们不是第一次见了。之前在讨论 fork 的返回值时,我们就遇到过:同一个 id 变量,在子进程里等于 0(进入 if (id == 0) 分支),在父进程里大于 0(进入 else if (id > 0) 分支)。两个死循环都在跑,两个分支都进入了——单进程不可能同时进入 if 和 else 两个分支,但因为 fork 创建了双进程,两个分支就同时执行了。
这个现象与全局变量地址相同但值不同,本质上是一个原理。
物理内存、进程与页表
不管怎么玩,代码和数据最终一定在物理内存中。这是冯·诺依曼体系决定的客观事实。
在操作系统中,每一个进程(task_struct)都有一个虚拟地址空间。在 32 位平台下,整个虚拟地址空间是 0 到 4GB。这上面的所有东西——正文段、初始化数据、未初始化数据、堆区、共享区、栈区、命令行参数、环境变量——在计算机层面全都是二进制数据。代码也是数据,就像"名字"也是"汉字"一样。
虚拟地址空间上的每一个字节都有一个地址,我们把这些地址叫做虚拟地址。
为了能让进程找到物理内存中对应的位置,操作系统内部会构建一张从虚拟地址到物理地址的映射表,这张表叫做页表。页表的左侧是虚拟地址,右侧是物理地址。页表的核心工作就是做虚拟地址到物理地址的转化。
打个比方:你在教室里坐的时候,你的座位号相当于物理地址;全班同学去操场按大小个排队,每个人在队列中的编号就相当于虚拟地址。同样是数字,一个代表教室里的位置,一个代表操场上的位置,两者之间的对应关系就类似于页表。
访问内存的基本单位
访问物理内存的最小单位是字节。原则上每一个字节都有对应的地址。一个整数占四个字节,取地址时取出的是这四个字节中最小的那个字节地址。
在 32 位平台下,一个地址用 32 个比特位来表示,一共可以表示 2³² 个地址。因为每个虚拟地址代表一个字节,所以能表达的虚拟地址空间大小是:
2³² × 1 字节 = 4GB
(2¹⁰ = 1KB,2²⁰ = 1MB,2³⁰ = 1GB,乘上 2² 就是 4GB)
物理内存一般小于等于 4GB。
一个完整的进程结构
回到我们的例子:定义了一个全局变量 g_value,它在虚拟地址空间中有一个虚拟地址 0x601058。这个变量最终在物理内存中也存在,假设它的物理地址是 0x1234。操作系统会为当前进程构建 0x601058 到 0x1234 的映射关系,保存在页表中。进程要访问物理内存时,需要经过一次查页表的过程(这个过程由操作系统完成,不是进程自己做的)。
一个完整的进程必须包含三大结构:
- PCB(进程控制块,
task_struct) - 虚拟地址空间(
mm_struct) - 页表
五、写时拷贝(Copy-on-Write)
当我们 fork 创建子进程时,子进程以父进程为模板来创建。父进程的 PCB、虚拟地址空间、页表,全部会拷贝一份给子进程。
因为虚拟地址空间一模一样,所以子进程中 g_value 的虚拟地址也是 0x601058。而拷贝页表的本质是拷贝地址——页表中虚拟地址到物理地址的映射关系也被拷贝下来。
这就像浅拷贝:两个指针指向同一块内存。父子进程此时指向同一个物理内存中的变量(虚拟地址相同,物理地址也相同),这就是为什么 fork 之后父子进程代码共享、数据也默认共享——因为我们拷贝页表时发生了地址级别的浅拷贝。
进程的独立性
在 Linux 系统中,进程是具有独立性的——一个进程的运行不能影响另一个进程。如果父子双方对 g_value 都只是读取不做修改,双方就不会影响彼此。但一旦子进程尝试对 g_value 做 ++ 修改,操作系统就会发现这个变量正被父子共享。
此时,操作系统会在底层:
- 重新开辟一段同等大小的空间(例如新物理地址
0x1111) - 把老空间的内容拷贝到新空间(内容为
0) - 修改子进程的页表:保持虚拟地址不变(仍是
0x601058),但把物理地址改为新空间的地址0x1111 - 子进程后续对
g_value的++操作,就在新的物理内存上进行
这样一来:
- 父进程的虚拟地址
0x601058→ 物理地址0x1234(值为0) - 子进程的虚拟地址
0x601058→ 物理地址0x1111(值为1, 2, 3...)
虚拟地址相同,但经过页表映射后被映射到了物理内存的不同位置,读到的值当然不一样。这个过程就叫做写时拷贝(Copy-on-Write)。
为什么需要写时拷贝?
你可能会问:进程不是具有独立性吗?为什么不直接在 fork 时就把父子进程的数据完全分开?
如果全局变量不是一个整型,而是一万个整型——其中大部分父子之间共享是没问题的,只有少数会被修改。如果在创建进程时就全部拷贝一份,那就申请了多余的空间,本质上是浪费内存,而且创建子进程的速度也会变慢(因为要完整拷贝数据)。
写时拷贝的本质是一种惰性申请空间的策略。它用"懒一点"的方式——当你要的时候我再给你——来换取效率:
- 创建进程变快了(不需要立即拷贝所有数据)
- 内存利用率提高了(共享的数据不重复占用内存)
- 修改时可能稍慢(需要现场申请空间并拷贝),但这是用时间来换内存
这就好比:你身上有 100 块钱,室友说一个礼拜后借 100 块。你不需要现在就给他——等一个礼拜后他真要的时候再给,这期间你的 100 块还可以借给其他人周转。资源的利用率就变高了。
回到 fork 返回值的问题
同样的原理也解释了为什么 fork 的返回值——同一个 id 变量——既能等于 0 又能大于 0。
id 是父进程在栈空间创建的一个变量。fork 返回时,返回值本质上是向 id 进行写入操作。谁先返回谁写入,此时就发生了写时拷贝。父子进程的虚拟地址一样,但经过页表映射到了不同的物理地址,数据就分开了——子进程写入了 0,父进程写入了子进程的 PID(大于 0)。
六、什么是虚拟地址空间?
到目前为止我们搭了一个概念架子:虚拟地址、虚拟地址空间、页表、物理地址,也在一定程度上理解了为什么虚拟地址相同但值不同。但要真正理解虚拟地址空间,我们需要继续深入。
大富翁与私生子的故事
在遥远的北美大陆,有一个身价十亿美元的大富翁。这个大富翁有很多私生子(彼此不知道对方的存在),每个私生子都认为自己是老爹唯一的继承人。
大富翁对每一个私生子都说同样的话:“你好好干,等老爹驾鹤西去了,老爹的十个亿家产全都是你的!”
每个私生子听了都非常开心,开始规划这笔钱该怎么花:买豪车、买房子、买游艇、买飞机……
后来:
- 私生子一找老爹要一万刀买西装手表 → 老爹转手就给了
- 私生子二找老爹要一千刀买实验设备 → 老爹也给了
- 私生子三找老爹要两千刀买包 → 老爹也给了
- 私生子四找老爹要十个亿 → 老爹给了他一个巴掌:“我还没死呢!”
私生子四虽然没要到钱,但依然坚信自己拥有十个亿——因为别人要钱老爹都给了。
这个故事里:
| 故事中的角色 | 对应的系统概念 |
|---|---|
| 大富翁 | 操作系统 |
| 私生子 | 进程 |
| 十个亿 | 内存(物理内存) |
| 给私生子画的饼 | 虚拟地址空间 |
虚拟地址空间,本质上是操作系统给进程画的大饼。 每个进程都以为自己独占 4GB 的内存空间。
为什么要画这个饼?操作系统想给进程一种错觉——让进程认为自己独占系统资源。就好比大富翁如果告诉私生子一"你只有 2.5 个亿",私生子一立刻就会问:"那剩下 7.5 个亿给谁了?"于是其他私生子的存在就暴露了。
银行存钱的类比
你去银行存了 1000 块钱,银行在你的卡上打了一个数字"1000"。实际上你那一千块钱并没有静静地躺在银行里——银行赚的是息差,你的钱早就被银行借出去赚利息了。但只要你想取钱的时候银行能兑付就行。
银行给我们每个人画了一张饼,告诉你有一千块钱,你只需要知道从第 1 块到第 1000 块都是你的,可以随时取用。同样的道理,操作系统给进程画了一个 4GB 的虚拟地址空间,进程可以在这 4GB 里自由规划。
饼本身也需要被管理
大富翁给每个私生子都画了饼,这些饼各不相同——私生子一要了一万,私生子二要了一千,每个人在饼里剩下的钱都不一样。老板给员工画饼也是一样——给小王说的是"明年当组长",给小李说的是"明年涨工资",给不同的人画不同的饼。
饼太多了,饼本身也需要被管理。如何管理?答案是先描述,再组织——这是管理任何事物的通用方法。
所以,虚拟地址空间本身在内核中就是一个结构体对象。在 Linux 内核中,这个结构体叫做 struct mm_struct。
七、区域划分的本质:三八线的故事
现在的问题是:虚拟地址空间里有代码区、初始化数据区、未初始化数据区、堆区、栈区……一个结构体如何表达"区域划分"这个概念?
小胖和小花的桌子
小胖和小花在幼儿园是同桌,桌子的宽度是 100 厘米。小胖不讲卫生,还老把自己的东西扔到小花那边。小花生气了,在桌子上画了一根线,然后说:
“老师说桌子宽度是 100 厘米。1 到 50 厘米是我的,50 到 100 厘米是你的。从现在开始,你不准越过这条线!”
这根线就是我们熟悉的三八线。画三八线的本质是什么?区域划分。
如果用计算机语言来描述这个划分过程:
struct desk {
int total_size; // 桌子总大小 = 100
int xiaohua_start; // 小花区域开始 = 1
int xiaohua_end; // 小花区域结束 = 50
int xiaopang_start; // 小胖区域开始 = 50
int xiaopang_end; // 小胖区域结束 = 100
};
因为区域是线性连续的(1 到 100),所以要划分区域,只需要给每个人指定"开始"和"结束"就行了。区域划分的本质就是指定 start 和 end。
区域划分的深层含义
划分区域不仅仅是指定一个数字范围。给小花划分了 1 到 50,意味着:1 到 50 之间的任意一个厘米位置,小花都可以随意使用。 第 2 厘米、第 3 厘米、第 49 厘米——桌子上的每一个刻度位置,都在小花的掌控范围内。
同样地,进程虚拟地址空间从全 0 到全 1(32 位下共 2³² 个地址),每个字节天然就有编号。给正文段划分开始和结束,意味着正文段区域内的任意地址都可以被进程随意访问。这就是逻辑上的空间划分。
后来小胖继续嚣张,小花把三八线擦掉,往小胖那边又挪了 10 厘米——这叫做区域空间的调整。在计算机语言中,就是把 xiaohua_end 从 50 改成 60,把 xiaopang_start 从 50 改成 60,这就完成了区域的扩展或缩小。
虚拟地址的概念也就出来了:给小花划分了 1 到 60 的虚拟地址空间,小花就拥有了 60 个地址——这一个个的地址,都是小花的虚拟地址。只要空间划分好了,上面的地址随时可以用。
所以,mm_struct 这个结构体里,应该会有大量 xxx_start 和 xxx_end 这样的成员。
八、内核源码中的 mm_struct
从 task_struct 到 mm_struct
每个进程只有一个 mm_struct 结构(内存描述符),在进程的 task_struct 中有一个指向它的指针:
struct task_struct
{
/* ... */
// 对于普通用户进程,该字段指向它的虚拟地址空间的用户空间部分;
// 对于内核线程,这部分为 NULL
struct mm_struct *mm;
// 该字段是内核线程使用的。当进程是内核线程时,mm 字段为 NULL,
// 表示没有内存地址空间,但也并不是真正的没有——这是因为所有进程
// 关于内核的映射都是一样的,内核线程可以使用任意进程的地址空间
struct mm_struct *active_mm;
/* ... */
};
可以说,mm_struct 结构是对整个用户空间的描述。每一个进程都有自己独立的 mm_struct,这样每一个进程都有自己独立的地址空间才能互不干扰。
mm_struct 结构体
mm_struct 所在的文件是 mm_types.h(与 task_struct 所在路径相同但文件不同):
struct mm_struct
{
/* ... */
struct vm_area_struct *mmap; // 指向虚拟区间(VMA)链表
struct rb_root mm_rb; // red_black 树
unsigned long task_size; // 具有该结构体的进程的虚拟地址空间的大小
/* ... */
// 代码段、数据段、堆栈段、参数段及环境段的起始和结束地址
unsigned long start_code, end_code;
unsigned long start_data, end_data;
unsigned long start_brk, brk;
unsigned long start_stack;
unsigned long arg_start, arg_end;
unsigned long env_start, env_end;
/* ... */
};
可以看到,这个结构体中用大量的 start 和 end 字段来划分区域,使用的类型是 unsigned long。为什么用 unsigned long 而不是指针?因为在 32 位系统中,地址本身就是一个 32 位(4 字节)的整数——从全 0 到全 1,就是 1, 2, 3, 4, 5… 一直到约 42 亿多。地址本身是一个数字,在内核中用 unsigned long 来表达,既直观又自然。就好比小花的桌面上有 1 到 100 的刻度,每个刻度都是一个整数编号。
区域划分的进一步理解
以 start_data 和 end_data 为例,它们限定了数据区从 10 到 50(假设)。这意味着数据区一共有 40 个字节,如果定义了 10 个整型变量,每个占 4 字节,这些变量就在数据区里从低地址到高地址依次排开。
关键点:限定区域内,开始和结束的数值很重要,但更关键的是——这个区域内的任何一个地址,当前进程都可以直接访问。
代码区和数据区的大小由谁决定?
堆区和栈区是动态变化的——栈顶向下移动、堆顶向上移动,区间就能扩大或缩小。但代码区和数据区的大小是怎么确定的?
一个程序无非由代码和数据构成。编译时,程序被编译成代码和数据——每个程序的代码量和数据量各不相同。Hello World 和王者荣耀的代码规模完全不在一个量级。
程序编译好之后,可以通过 size 命令查看可执行程序的代码和数据大小:
$ size myproc
text data bss dec hex filename
168487 580 0 169067 2946b myproc
其中 text 是代码段大小,data 是数据段大小。
当可执行程序加载到内存时(这就是创建进程的过程),物理内存中要为代码和数据分别开辟空间。代码有多大、数据有多大,程序自己知道(在 ELF 可执行文件格式中记录了这些信息)。所以代码区和数据区的大小,通常由二进制可执行程序的代码和数据大小决定。
当我们把代码加载到物理内存时,每一行代码都有对应的物理地址;同时,在虚拟地址空间中也给代码区开辟了等大的虚拟地址空间。虚拟地址和物理地址都有了,就可以填充页表,构建映射关系。之后,进程就可以通过访问虚拟地址来访问物理内存了。
九、为什么要有虚拟地址空间?
这个问题其实可以转化为:如果程序直接操作物理内存,会造成什么问题?
不直接使用物理内存的三大理由
理由一:更好地对内存进行保护
在早期系统中,进程直接使用物理内存地址。进程 A 和进程 B 各自占用物理内存的一部分,如果进程 A 发生了野指针问题,指针就可能指向进程 B 的空间,修改进程 B 的数据——进程的独立性无法保证。如果是木马病毒,随意修改内存空间,能让设备直接瘫痪。
有了虚拟地址空间之后,进程访问物理内存需要经过一次转化。这个转化工作由 MMU(Memory Management Unit,内存管理单元) 这个硬件完成——它集成在 CPU 内部,能自动完成虚拟地址到物理地址的转化。
关键点在于:地址空间和页表是操作系统创建并维护的! 这意味着,凡是想使用地址空间和页表进行映射,也一定要在操作系统的监管之下来进行访问。这就保护了物理内存中所有的合法数据——包括各个进程以及内核的相关有效数据。
- 如果虚拟地址对应的物理地址不存在 → 转化失败 → 操作系统直接终止进程,不会实际访问物理内存
- 每个区域的划分(
start~end)限定了合法地址范围,超出范围就是野指针 → 页表查不到 → 进程崩溃 - 页表中还有权限标志位:可读(R)、可读写(RW)、可读可执行(RX)等。代码区通常是只读的——如果尝试对代码区做写入,MMU 发现权限不匹配,直接拒绝并终止进程
这也就解释了为什么字符串常量不可被修改:字符串常量(如 char *msg = "hello world")编译后被放在代码区,代码区对应的页表条目中权限标志为只读(R)。一旦尝试写入,操作系统识别到不能对该物理内存做写操作,就直接拦截。
打个比方:以前你拿着压岁钱直接跑去商店,买了一大堆不需要的东西——没人能拦你。后来你妈说"压岁钱交给我,你要买什么跟我说"。你要买本子 → 你妈让你去;你要买游戏机 → 你妈说"上学呢玩什么游戏机"拒绝了。在进程和内存之间加了一层类似"你妈"的角色,很多非法行为就能被拦截了。
理由二:将物理内存的"无序"变成进程视角的"有序"
如果没有虚拟地址空间,进程的代码和数据可能被加载到物理内存的任意位置。进程 A 这次加载起始地址是这里,下次可能在那里——操作系统必须记录每个进程各自的物理起始地址。而且编译完成后的程序是放在硬盘上的,运行时需要搬到内存,如果直接使用物理地址,我们无法确定内存现在使用到哪里了,每次运行的加载地址都是不确定的:第一次执行 a.out 时内存空空,可能搬到 0x00000000;第二次执行时内存里已经有 10 个进程在跑,加载地址就不一定了。
有了虚拟地址空间和页表,代码和数据在物理内存的任意位置都可以加载。但因为有页表做映射,每一个进程都认为自己的布局是这样的:代码区在下面,数据区在上面,然后是堆区,再往上是栈区和命令行参数环境变量。只不过你的代码大一点我的小一点,你的堆区大一点我的小一点——但整体的空间排布对每个进程来说都是有序的、一致的。
因为页表的映射的存在,程序在物理内存中理论上就可以任意位置加载。它将地址空间上的虚拟地址和物理地址进行映射,在进程视角中所有的内存分布都可以是有序的。
虚拟地址空间 + 页表,把物理内存中杂乱无章的加载,映射成了进程视角中井井有条的布局。每个进程都认为自己独占 4GB 内存,按照同一个模板来组织自己的空间。
理由三:进程管理与内存管理解耦合
因为有地址空间的存在,我们在 C、C++ 语言中 new、malloc 申请空间的时候,其实是在地址空间上申请的,物理内存可以甚至一个字节都不给你。而当你真正对虚拟地址空间进行访问(写入)的时候,才执行内存的相关管理算法,帮你申请物理内存,构建页表映射关系——这叫做延迟分配。整个过程由操作系统自动完成,用户和进程完全零感知!
这就好比大富翁的故事:私生子一要一千块,大富翁承诺了,私生子就认为自己已经有一千块了。真正要花钱的时候,大富翁才把钱给他。
左侧(进程、虚拟地址空间)属于进程管理模块,右侧(物理内存分配回收)属于内存管理模块。因为有虚拟地址空间的存在:
- 物理内存的分配和进程的管理就可以做到没有关系——进程管理模块和内存管理模块就完成了解耦合
- 进程申请空间时,只需要在虚拟地址空间层面操作,不需要关心物理内存的实际状态
- 内存管理模块独立负责物理内存的分配和回收
- 只有进程真正访问(写入)虚拟地址时,才触发内存管理模块去实际分配物理内存
这种设计让两个模块可以各自独立演化,也实现了惰性分配——进一步提高内存利用率。
如果不使用虚拟地址空间会怎样?
早期计算机直接使用物理内存运行程序。假设物理内存 128MB,程序 A 占 10MB,程序 B 占 110MB,计算机先将前 10MB 分给 A,再从剩余 118MB 中划分 110MB 给 B。这种方式有三个问题:
- 安全风险:每个进程都可以访问任意的内存空间,任意一个进程都能够去读写系统相关内存区域。进程 A 的野指针可以读写进程 B 的内存区域,如果是恶意程序,可以随意修改内存
- 地址不确定:每次加载进程,物理地址都可能变化——第一次运行加载到
0x00000000,第二次就不知道在哪里了,管理复杂 - 效率低:物理内存不够时,需要把整个进程拷贝到磁盘交换分区(swap in / swap out)来腾出内存,整个过程需要将整个进程一起拷走,内存和磁盘之间拷贝时间太长,效率很低
有了虚拟地址空间和分页机制,这三个问题就都解决了。
十、vm_area_struct:管理不连续区域
为什么需要 vm_area_struct?
代码区和数据区通常是连续的——代码写了多少、定义了多少全局变量,编译后就确定了。但堆区不同:你可能申请三次堆空间,然后释放中间那次——堆区就不连续了。
不连续的堆区,怎么可能只用一个 start_brk 和一个 brk 来表示?
在 mm_struct 中,除了前面看到的宏观区域划分字段之外,还维护了两种组织结构来管理虚拟内存区域(VMA):
- 当虚拟区较少时采取单链表,由
mmap指针指向这个链表 - 当虚拟区间多时采取红黑树,由
mm_rb指向这棵树
vm_area_struct 结构体
Linux 内核使用 vm_area_struct 结构来表示一个独立的虚拟内存区域(VMA)。由于每个不同质的虚拟内存区域功能和内部机制都不同,因此一个进程使用多个 vm_area_struct 结构来分别表示不同类型的虚拟内存区域。
struct vm_area_struct {
unsigned long vm_start; // 虚存区起始
unsigned long vm_end; // 虚存区结束
struct vm_area_struct *vm_next; // 链表后指针
struct vm_area_struct *vm_prev; // 链表前指针
struct rb_node vm_rb; // 红黑树中的位置
unsigned long rb_subtree_gap;
struct mm_struct *vm_mm; // 所属的 mm_struct
pgprot_t vm_page_prot;
unsigned long vm_flags; // 标志位
struct {
struct rb_node rb;
unsigned long rb_subtree_last;
} shared;
struct list_head anon_vma_chain;
struct anon_vma *anon_vma;
const struct vm_operations_struct *vm_ops; // vma 对应的实际操作
unsigned long vm_pgoff; // 文件映射偏移量
struct file *vm_file; // 映射的文件
void *vm_private_data; // 私有数据
atomic_long_t swap_readahead_info;
#ifndef CONFIG_MMU
struct vm_region *vm_region; /* NOMMU mapping region */
#endif
#ifdef CONFIG_NUMA
struct mempolicy *vm_policy; /* NUMA policy for the VMA */
#endif
struct vm_userfaultfd_ctx vm_userfaultfd_ctx;
} __randomize_layout;
组织方式:链表 vs 红黑树
当进程的 VMA 数量较少时,用单链表就够了——遍历开销小,实现简单。当 VMA 数量增多(例如大型程序有大量动态库映射、内存映射文件等),链表遍历效率下降,就切换到红黑树来组织。
无论哪种组织方式,每个 VMA 节点都记录了该区域的 vm_start 和 vm_end,以及它所属的 mm_struct。通过这个结构:
- 固定区域(代码区、数据区等)在
mm_struct中有宏观的start_code/end_code等字段;在 VMA 链表中也有对应的节点,二者的起始和结束值是一致的 - 不连续区域(如被
free打断的堆区、共享库映射区等)则通过多个vm_area_struct节点来分别描述 - 如果堆区不连续,就在链表中多插入几个
vm_area_struct节点,每个记录一段连续区域的开始和结束
最终,整个进程的虚拟地址空间可以用下面这张图来描述:task_struct → mm_struct → vm_area_struct 链表/红黑树,其中每个 VMA 节点记录一段连续区域的 vm_start 和 vm_end,合在一起就构成了进程看到的所有虚拟地址区域——代码区、数据区、堆区、栈区、共享库映射区、命令行参数和环境变量等。
理解虚拟地址空间时,建议以这张完整的 VMA 组织图为准——它才是真正完整描述了进程虚拟地址空间的全部区域划分。
十一、总结
今天这节课的核心结论只有一个:虚拟地址空间是操作系统给进程画的大饼。
操作系统不仅要对进程做管理,也要对虚拟地址空间做管理。按照"先描述,再组织"的方法论,进程虚拟地址空间本身是一个结构体——在 Linux 内核中就是 mm_struct。
理解虚拟地址空间的关键概念:
- 虚拟地址:C/C++ 中看到的所有地址都是虚拟地址,不是物理地址
- 虚拟地址空间:操作系统给每个进程画的饼,让每个进程以为自己独占 4GB 内存
- 区域划分:通过
start和end来划分代码区、数据区、堆区、栈区等。划分好区域后,区域内的任意地址进程都可以随意访问——这就是虚拟地址的由来 - 页表:虚拟地址到物理地址的映射表,由 MMU(CPU 内部硬件)负责转化
- 写时拷贝:
fork后父子共享物理内存,只有当一方修改时才真正复制——是一种惰性申请空间的策略,用时间换内存 - vm_area_struct:通过链表管理不连续的虚拟地址区域
虚拟地址空间存在的三大理由:内存保护(通过 MMU 转化时做权限和合法性检查)、无序变有序(物理内存任意加载,进程视角统一布局)、进程管理与内存管理解耦合(惰性分配,模块独立)。
关于虚拟地址空间,真正理解还需要掌握:进程本身、页表硬件机制、ELF 可执行程序格式、内存管理算法等知识。后续课程中还会多次回到这个话题,每次侧重不同的层面去深入。今天的目标是搭建一个清晰的宏观框架——有了这个框架,后续的细节才能有地方安放。
下节预告:进程控制——如何创建、终止、等待、替换进程,以及自定义信号等话题。

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐


 2
2 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)