深入理解进程虚拟地址空间
这里有一大堆东西没讲到。页表到底长什么样?多级页表怎么省空间?TLB 是什么?页错误(page fault)怎么处理?ELF 可执行文件格式怎么和虚拟地址空间配合?缺页中断怎么触发、操作系统怎么响应?内存回收算法怎么决定把谁的页换出去?这些都不是一节课能讲完的。但你现在有了一张地图——不是"代码段、数据段、堆、栈"那个图,是理解这件事需要抓住的主线你看到的地址是假的。是虚拟地址,是地图上的坐标。这

.
专栏:数据结构|Linux|C语言
路漫漫其修远兮,吾将上下而求索
文章目录
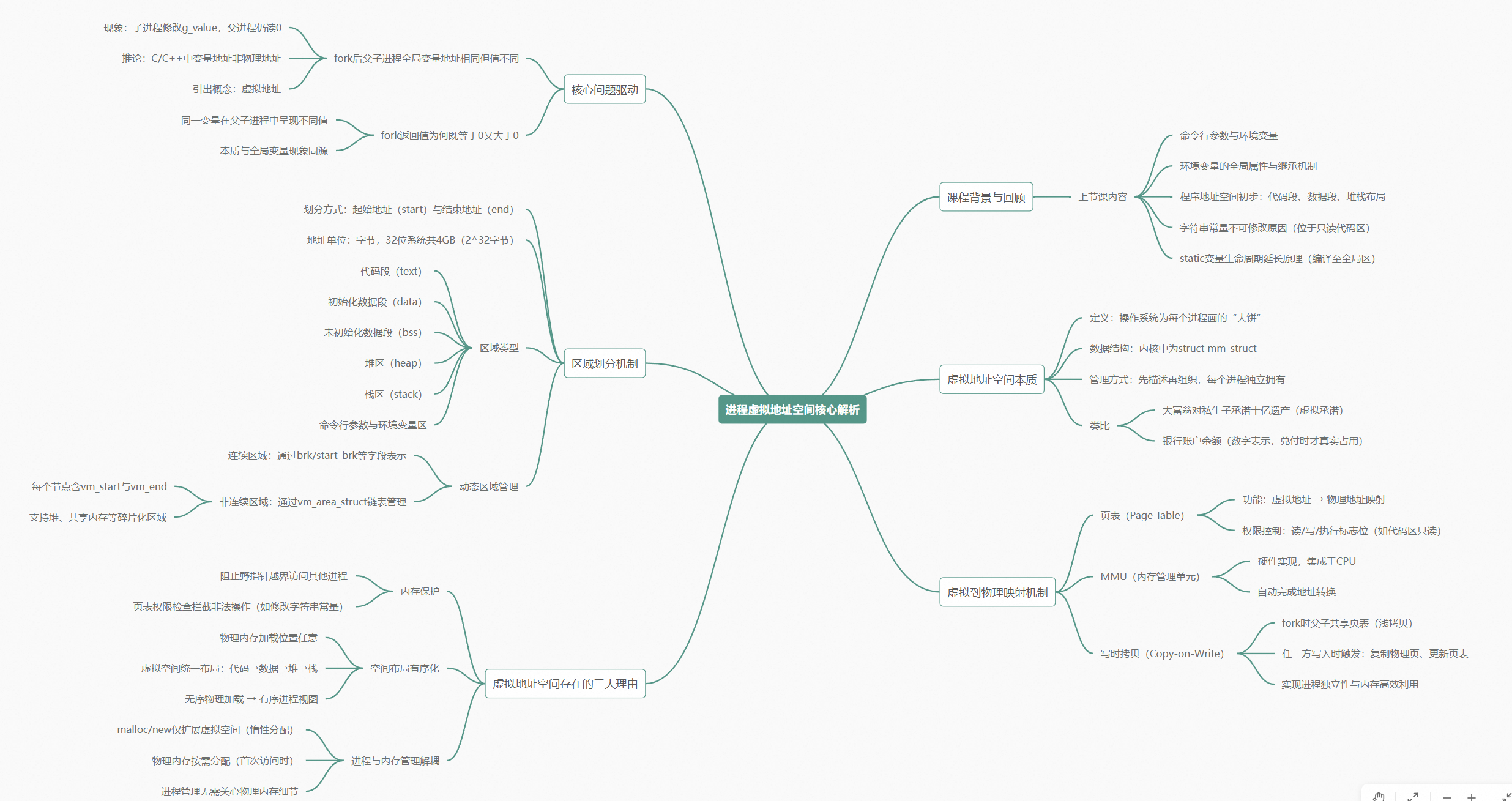
你看到的地址,从来都不是真的
引子:上节课留下的东西
先花三分钟把上节课的结论钉牢——它们跟今天的话题是连着的。
操作系统在 Bash 里维护了一组系统级的全局变量,叫环境变量。PATH 记录二进制程序的搜索路径,HOME 记录家目录,PWD 和 OLDPWD 分别记录当前和上一次的工作路径,HISTSIZE 记录历史命令条数,HOSTNAME 记录主机名,USER 记录用户名。它们各有各的功能,彼此独立,没有明显的逻辑关系。系统开机时,每个用户的 Bash 从系统配置文件里加载这些变量。
在进程——尤其是父进程 Bash——内部,存在两张表:命令行参数表和环境变量表。命令行参数用来给可执行程序设置选项,这就是为什么 ls -l、pwd 这些命令能带选项。获取环境变量有三种方式:通过 main 的第三个参数 envp、通过全局变量 environ、通过系统调用 getenv()。配套的命令有 echo $VAR(查看)、export VAR=value(导出)、env(查看全部)、set(查看含本地变量)、unset VAR(取消)。
环境变量为什么具有全局属性?因为环境变量表可以被子进程继承。父进程 Bash 从配置文件获取环境变量后,fork 创建子进程,子进程拿到父进程的环境变量表;子进程的子进程同样能拿到。从登录系统开始,所有任务形成一棵进程树——从 Bash 往后,所有直接或间接创建的子进程都能拿到环境变量,这就叫全局属性。而本地变量只在本 Bash 内部有效——比如你在命令行里用 while 循环定义的变量。
上节课末尾我们刚开了个头:程序地址空间。在 32 位平台下,从低地址到高地址,依次是代码段(正文段)、初始化数据区、未初始化数据区(BSS)、堆区、栈区——堆和栈相对而生。命令行参数和环境变量也在这张图里。我们当时用代码验证了这些区域的排布确实如此,并且解决了两个问题:为什么字符串常量不能修改?(因为它被编到了只读的代码区)为什么 static 变量生命周期变全局?(因为编译后局部变量被提升进了全局数据区。)
有了这些垫底,今天进入正题。今天的东西比较干——它是你第一次真正意义上的认知升级,往后学进程、学内存管理,全跟它有关。
一个实验,三个版本
版本一:都不改
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int g_val = 0;
int main()
{
pid_t id = fork();
if (id < 0) {
perror("fork");
return 0;
}
else if (id == 0) { // child
printf("child[%d]: %d : %p\n", getpid(), g_val, &g_val);
}
else { // parent
printf("parent[%d]: %d : %p\n", getpid(), g_val, &g_val);
}
sleep(1);
return 0;
}
编译运行:
gcc -o myproc myproc.c
./myproc
输出(与环境相关,观察现象即可):
parent[2995]: 0 : 0x80497d8
child[2996]: 0 : 0x80497d8
变量值和地址一模一样。这很好理解——子进程以父进程为模板,父子都没有对变量做任何修改。
版本二:子进程改,父进程等
把代码改一下:
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int g_val = 0;
int main()
{
pid_t id = fork();
if (id < 0) {
perror("fork");
return 0;
}
else if (id == 0) { // child:子进程先跑完,先修改,完成之后父进程再读取
g_val = 100;
printf("child[%d]: %d : %p\n", getpid(), g_val, &g_val);
}
else { // parent
sleep(3);
printf("parent[%d]: %d : %p\n", getpid(), g_val, &g_val);
}
sleep(1);
return 0;
}
输出:
child[3046]: 100 : 0x80497e8
parent[3045]: 0 : 0x80497e8
父子进程输出的地址一致,但变量内容不一样。
版本三:两个死循环同时跑
为了看得更清楚——让父子进程各自每秒打印一次,子进程每次对全局变量 ++:
#include <stdio.h>
#include <unistd.h>
int g_value = 0;
int main()
{
pid_t id = fork();
if (id == 0) {
// 子进程
while (1) {
printf("child: pid=%d, g_value=%d, &g_value=%p\n",
getpid(), g_value, &g_value);
sleep(1);
g_value++;
}
}
else if (id > 0) {
// 父进程
while (1) {
printf("parent: pid=%d, g_value=%d, &g_value=%p\n",
getpid(), g_value, &g_value);
sleep(1);
}
}
return 0;
}
运行一会儿:
- 最开始,父子打印的
g_value都是0,地址相同(比如都是0x601058)。 - 过了几秒,父进程始终打印
0(它不改),子进程打印1, 2, 3, 4, 5...(它每秒++)。 - 子进程认为变量已经是
2了,父进程读到的还是0——而两者的地址一模一样。 - 两个死循环同时在跑。如果是单进程,
if和else两个分支不可能同时进入。但因为fork创建了双进程,两个分支同时执行了。
停下来看清楚
你看到什么了?
站在实验结果前面,一个一个捋:
- 变量内容不一样 → 父子进程输出的变量绝对不是同一个变量。
- 但地址值是一样的 → 说明该地址绝对不是物理地址。如果
0x80497e8是内存芯片上某个晶体管的物理坐标,同一个物理位置不可能同时存着100又存着0。 - 在 Linux 下,这种地址叫做虚拟地址。
- 你在 C/C++ 语言里看到的地址,全部都是虚拟地址。 物理地址用户一概看不到,由操作系统统一管理。
- 操作系统必须负责将虚拟地址转化成物理地址。
你不是第一次遇到这种事了。之前讲 fork 返回值的时候就出现过:同一个 id 变量,在子进程里等于 0(进入 if (id == 0) 分支),在父进程里大于 0(进入 else 分支)。两个分支都进入了,两个死循环都跑了。这个现象和全局变量地址相同值不同的现象,本质上是一个原理。
物理内存、进程和页表
在往下走之前,先把几个东西摆到桌面上。
第一,物理内存。 不管你怎么玩虚拟地址,代码和数据最终一定在物理内存里。这是冯·诺依曼体系决定的客观事实——软件上怎么设置,数据都要在内存里保存。我们刚才访问的 g_value,它一定在物理内存里的某个位置。
第二,进程。 在 Linux 里,每个进程用一个 task_struct(PCB)来描述。操作系统会为每一个进程创建一个虚拟地址空间,在 32 位平台下就是 0 到 4GB。代码也是数据,初始化数据也是数据,堆也是数据——这上面所有的东西在计算机层面全是二进制数据。虚拟地址空间只是告诉我们:这些数据在 0 到 4GB 的范围内,各占多大区间。从全 0 到全 1,每个字节都有一个地址,这些地址就叫虚拟地址。
打个比方。你们班 40 个人,在教室里坐着的时候,你的座位号(第几排第几列)就是物理地址。全班同学去操场按大小个排队,从 1 排到 40——这个排队编号就是虚拟地址。无非都是数字,一个代表教室位置,一个代表队列位置。
第三,页表。 操作系统为了让进程能找到物理内存里的对应位置,会构建一张映射表——左侧是虚拟地址,右侧是物理地址。这张表叫页表。核心工作就是做虚拟地址到物理地址的转化。真实情况比这复杂得多(有各种标志位),但核心就是这个。
第四,访问内存的基本单位是字节。 原则上每个字节都有地址。一个整数占四个字节,取地址时取出来的是四个字节中最小的那个字节地址——这在我们讲进程双链表实现的时候就聊过。地址这个概念和字节是绑定的。
在 32 位平台下,一个地址用 32 个比特位表示。32 个比特位能表示 2³² 个不同的值。每个虚拟地址对应一个字节,所以总共能表达:
2³² × 1 字节 = 4GB
(2¹⁰ = 1KB,2²⁰ = 1MB,2³⁰ = 1GB,乘 2² 就是 4GB。)
物理内存通常小于等于 4GB。
所以,回到我们的 g_value。它在虚拟地址空间里有一个虚拟地址,比如说 0x601058。它在物理内存里也一定存在,假设物理地址是 0x1234。操作系统为当前进程构建映射:0x601058 → 0x1234。进程要访问 g_value,必须先查页表。查页表不是进程自己做的——是操作系统(准确说是 MMU 硬件)做的。
一个完整的进程,至少有三大块结构:task_struct(PCB)、mm_struct(虚拟地址空间)、页表。 后面还有补充,以后再说。
fork 到底干了什么
子进程以父进程为模板来创建。父进程的 PCB、虚拟地址空间、页表——全部拷贝一份。
页表里保存的是虚拟地址到物理地址的映射。拷贝页表的本质就是拷贝地址。子进程的虚拟地址空间跟父进程一模一样,所以 g_value 的虚拟地址也是 0x601058。页表映射关系也被拷过来了——父子进程的虚拟地址 0x601058 现在都指向物理内存里同一个位置。
这就好比你以前学字符串拷贝时遇到的浅拷贝:把一个指针赋给另一个指针,两个指针指向同一块内存。如果你要两个字符串彻底独立,你得给目标开辟新空间,再把内容拷过去——这叫深拷贝。但页表拷贝做的是浅拷贝——父子进程的虚拟地址指向了同一个物理地址。
这就是为什么 fork 之后父子进程代码共享、数据也默认共享。因为我们拷贝页表时,发生了地址级别的浅拷贝。父子此时指向同一个物理变量。如果映射的不是全局变量而是代码、初始化数据、堆、栈——父子同样可以访问同一块空间。
但进程是独立的
在 Linux 里,在操作系统学科里,进程具有独立性——一个进程运行不能影响另一个进程。如果父子对 g_value 都只是读取不做修改,双方不会影响彼此。只读不会产生问题。
但一旦子进程尝试对 g_value 做 ++ 修改——操作系统发现:“这个变量正被父子共享。你要写?”
操作系统在底层:
- 重新开辟一段同等大小的空间(比如物理地址
0x1111) - 把老空间的内容拷贝过去(内容为
0) - 修改子进程的页表:虚拟地址不变(还是
0x601058),但物理地址改成0x1111 - 子进程后续的
++操作,就在0x1111这个新空间上进行
整个过程中,子进程的虚拟地址空间没有变——它上面的虚拟地址和父进程的虚拟地址,数字是一样的。但虚拟地址到物理地址的映射关系变了。所以上层看到虚拟地址一样,打印出来的值却不同。
这个过程叫写时拷贝(Copy-on-Write)。只有修改时才重新开辟空间。不修改?那就共享。一旦修改,操作系统才把父子在数据层面分开。
为什么要这么设计?直接分开不就好了?
如果我定义的不是一个整型,而是一万个整型呢?一万个整型里,父子可能只会修改其中一小部分。如果在 fork 时就全部分开,那就申请了多余的空间——对可以共享的变量强行拆成两份,浪费内存,而且创建子进程的速度也会变慢(因为要完整拷贝数据)。
写时拷贝的本质是惰性申请空间。懒一点——当你要的时候我再给。创建进程时不做数据拷贝,快了;修改时才申请,慢了——用时间来换内存。
这就好比:你身上有 100 块钱,室友说一个礼拜后借 100 块。你现在就给他?他一个礼拜以后才用,这一周你的 100 块还可以借给其他人周转。资源的利用率就高了。等他真要的时候,你给他就行。写时拷贝就是这个思路。
整个过程全部由操作系统自动完成。
回到 fork 返回值
fork 返回时,返回值被写入变量 id。id 是父进程在栈空间创建的一个变量。返回值本身就是向 id 进行写入操作——谁先返回,谁写入,此时就发生写时拷贝。
父子进程的 id 虚拟地址一样,但经过页表映射到了不同的物理地址。子进程写入了 0,父进程写入了子进程的 PID(大于 0)。所以同一个变量,既等于 0 又大于 0——底层已经是两份数据了。
什么是虚拟地址空间?
到现在为止,我们搭了虚拟地址、页表、物理地址的概念架子,也在一定程度上理解了那个诡异的现象。但上面说的还是有点抽象。接下来要真正搞清楚:虚拟地址空间到底是个什么东西?
大富翁和他的私生子
从前有个大富翁,身价十个亿美元。他有四个私生子,彼此不知道对方存在。每个私生子都认为自己是老爹唯一的继承人。
大富翁逐一找到他们:
对老大说:"儿子,听说你在搞金融?好好搞。等老爹驾鹤西去了,十个亿家产全是你的。"老大欣喜若狂。
过了几天找到老二:"儿子,你好好读博士,出来直接来老爹公司上班。等老爹蹬腿了,十个亿全是你的。"老二也很高兴。
又找到老三:"闺女,化妆品生意怎么样?你好好弄,老爹给你兜底。等老爹走了,十个亿全是你的。"老三非常开心。
最后找到老四:"儿子,玩具还要不要?怎么不玩啊?"老四说:"我要好好学习,成为世界上最厉害的人!"大富翁说:“你好好上,等大学毕业了,老爹的十个亿全是你的。”
后来——
老大说:"老爹,能不能给我一万刀?我要买西装手表,搞金融排面得拉满。刚起步没钱。"大富翁转手就给了一万。
老二说:"老爹,能不能给我一千块?学校实验室买设备,没钱了。"大富翁转手给了一千。
老三说:"老爹,能不能给我两千美元?我要买个包。"大富翁转手给了两千。
老四说:"老爹,能不能把十个亿给我?我跟同学吹牛说我有十个亿,他们不信。"大富翁转手给了老四一个巴掌:“我还没死呢!”
老四虽然挨了巴掌,但依然坚信自己拥有十个亿。因为老大、老二、老三——他们要钱,老爹都给了。
这故事是对虚拟地址空间最精确的映射:
| 故事 | 系统 |
|---|---|
| 大富翁 | 操作系统 |
| 私生子 | 进程 |
| 十个亿 | 内存(物理内存) |
| 老爹给每个人画的饼 | 虚拟地址空间 |
虚拟地址空间,本质上是操作系统给进程画的大饼。 每个进程都以为自己独占 4GB。大富翁如果告诉老大"你只有 2.5 个亿",老大立刻就会问:“那剩下 7.5 个亿给谁了?”——其他私生子的存在就暴露了。操作系统就是要给进程一种错觉:你独占系统资源。
有了这个饼,进程就可以提前规划——前面 100MB 我放代码,再往后 50MB 放数据,中间这块给堆让它往上长,最上面那块给栈让它往下长。就像私生子听说自己有十个亿,就开始规划买豪车、买房子、买游艇。
但饼本身也需要被管理。 大富翁有四个私生子,画了四张饼。老板有十个员工,给每人画的饼不一样——“小王你好好干,明年让你当组长”、“小李你好好干,明年给你涨工资”、“小杨你好好干,明年大项目交给你”。饼对错了,员工就觉得你在骗他。
怎么管理这么多饼?跟管理任何东西一样——先描述,再组织。 所以虚拟地址空间在内核里就是一个结构体变量。这个结构体在 Linux 里叫 struct mm_struct。
银行存钱的类比
你去银行存 1000 块钱。银行给你的卡上打了一个数字 1000。实际上你那 1000 块并没有静静躺在银行里——银行赚的是息差,你的钱早就被借出去了。但只要你想取的时候银行能兑付,就没事。
银行给我们每个人画了一张饼。你知道自己卡上有 1000 块,从第 1 块到第 1000 块都是你的,你随时可以取。操作系统给每个进程画了 4GB 的饼,从地址 0 到地址 0xFFFFFFFF,全是你的——直到你真正要用的时候,操作系统才在物理内存里给你分配。
区域划分:三八线就够了
还有一个问题:就算我接受了"虚拟地址空间是一个结构体",但结构体里怎么表达区域划分?代码区、数据区、堆区、栈区——它们是明晃晃的不同区域,一个结构体怎么表示?
小胖和小花的桌子
幼儿园桌子宽 100 厘米。小胖和小花是同桌。小胖不爱干净,脸黑鼻涕多,还老把东西扔到小花那边。小花生气了,在桌子上画了一根线。
“老师说桌子宽度 100 厘米。我画一根线。1 到 50 厘米是我的,50 到 100 厘米是你的。从现在开始,不准越过这条线。越过了我就打你。”
这根线就是三八线。三八线的本质是什么?区域划分。
用计算机语言描述:
struct desk {
int total_size = 100;
int xiaohua_start = 1, xiaohua_end = 50;
int xiaopang_start = 50, xiaopang_end = 100;
};
因为区域是线性的——1, 2, 3, 4, 5, …, 100——所以划分区域只需要给每个人指定 start 和 end。
进程虚拟地址空间也是线性的:32 位系统下,从全 0(最低地址)到全 1(最高地址),一共 2³² 个地址(约 42 亿多),每个字节一个编号。要划分代码区、数据区、堆区、栈区,就是给每个区域一个 start_code、end_code、start_data、end_data……
内核里用的类型是 unsigned long,不是指针。地址本身就是一个数字——全 0 是 0,全 1 约 42 亿,中间是 1, 2, 3, 4, 5…,跟桌面上 1 到 100 厘米的刻度没区别。小花把铅笔放在 10 号刻度上——她就找自己桌面上刻度为 10 的位置。内核里表达地址空间范围,就是用 unsigned long 来表示这些"刻度"。
关键不是数字本身,是"之间"
给小花的区域是 1 到 50。这意味着什么?
意味着第 2 厘米、第 17 厘米、第 49 厘米——1 到 50 之间的每一个刻度,小花都可以随意使用。 不是只有 1 和 50 这两个端点属于她。
同样的道理:代码区 start_code 到 end_code 之间的每一个字节地址,进程都可以访问。虚拟地址不是只有区间端点有意义——区间里的每一个位置都叫虚拟地址,都可以用。划分好虚拟地址空间后,区域之间的任意一个地址,进程随时可以取用。
后来小胖还越过线。小花把三八线擦掉,往小胖那边又挪了 10 厘米。xiaohua_end 从 50 改成 60,xiaopang_start 从 50 改成 60——这就叫区域空间的调整(扩展或缩小)。把各自区域的 start 和 end 往大改或往小改。malloc 干的就是这个:如果堆区不够用,brk() 系统调用把堆区的 end 往后挪。你没"创建"任何东西——你只是重新画了根线。
代码区和数据区的大小怎么来的?
堆和栈是动态变化的——栈顶往下移、堆顶往上移,区间就扩了。哪怕刚创建时它们都是 0,后面也可以动态扩展。
代码区和数据区呢?每个程序无非由代码和数据构成。你写的函数、循环、类——这是代码。你定义的整型、浮点、结构体——这是数据。Hello World 和王者荣耀的规模根本不在一个量级。编译时,代码和数据的大小就确定了。
用 size 命令可以直接看:
$ size myproc
text data bss dec hex filename
168487 580 0 169067 2946b myproc
text 是代码段,data 是数据段。
程序编译好之后是一个二进制可执行文件(ELF 格式),里面记录了代码有多大、数据有多大。将来创建进程时,操作系统读取 ELF 头,就知道该分配多大的虚拟地址空间给代码区和数据区。然后把代码和数据从磁盘加载到物理内存里。物理地址有了,虚拟地址也在地址空间上开辟了等大的区间——虚拟和物理都有了,就可以填充页表,构建映射关系。此后,进程通过访问虚拟地址就能访问物理内存。
内核源码里长什么样
从 task_struct 到 mm_struct
struct task_struct
{
/* ... */
// 普通用户进程:指向它的虚拟地址空间(用户空间部分)
// 内核线程:这个字段为 NULL
struct mm_struct *mm;
// 内核线程使用。当 mm 为 NULL 时,内核线程借别的进程的地址空间用
// 因为所有进程关于内核的映射都是一样的
struct mm_struct *active_mm;
/* ... */
};
mm_struct(mm_types.h)
struct mm_struct
{
/* ... */
struct vm_area_struct *mmap; // 指向虚拟区间(VMA)链表
struct rb_root mm_rb; // 红黑树根(VMA 多时切换为树)
unsigned long task_size; // 该进程的虚拟地址空间总大小
/* ... */
// 各个区域的开始和结束
unsigned long start_code, end_code; // 代码区
unsigned long start_data, end_data; // 数据区
unsigned long start_brk, brk; // 堆区
unsigned long start_stack; // 栈区
unsigned long arg_start, arg_end; // 命令行参数
unsigned long env_start, env_end; // 环境变量
/* ... */
};
看到了吗?代码区开始、代码区结束;数据区开始、数据区结束;堆区开始、堆区结束;栈区开始;命令行参数开始结束;环境变量开始结束。这就是虚拟地址空间的区域划分——不是魔法,是 start 和 end。
每个进程有自己独立的 mm_struct,每个进程有自己独立的地址空间,互不干扰。
vm_area_struct:处理不连续区域
代码区和数据区是编译时确定的,整齐连续。但堆区呢?申请三次,释放中间那次——堆区就不连续了。一个 start_brk 和一个 brk 怎么能表达被掏了洞的堆区?
在 mm_struct 中,除了宏观的 start_code、end_code 这些字段,还维护了更细粒度的结构——vm_area_struct(VMA)。每个 VMA 描述一段连续的虚拟地址区域:
struct vm_area_struct {
unsigned long vm_start; // 本区域的起始虚拟地址
unsigned long vm_end; // 本区域的结束虚拟地址
struct vm_area_struct *vm_next; // 链表后指针
struct vm_area_struct *vm_prev; // 链表前指针
struct rb_node vm_rb; // 红黑树节点(VMA 多时用树管理)
struct mm_struct *vm_mm; // 属于哪个地址空间
pgprot_t vm_page_prot;
unsigned long vm_flags; // 权限标志位(可读?可写?可执行?)
struct {
struct rb_node rb;
unsigned long rb_subtree_last;
} shared;
struct list_head anon_vma_chain;
struct anon_vma *anon_vma;
const struct vm_operations_struct *vm_ops; // 本区域对应的操作函数表
unsigned long vm_pgoff; // 文件映射的偏移量
struct file *vm_file; // 映射的文件(如果是文件映射)
void *vm_private_data; // 私有数据
atomic_long_t swap_readahead_info;
#ifndef CONFIG_MMU
struct vm_region *vm_region;
#endif
#ifdef CONFIG_NUMA
struct mempolicy *vm_policy;
#endif
struct vm_userfaultfd_ctx vm_userfaultfd_ctx;
} __randomize_layout;
每个 VMA 用自己的 vm_start 和 vm_end 描述一段连续区域。堆区不连续?两个 VMA 节点,一个管洞前的连续段,一个管洞后的连续段。
所有 VMA 节点组织起来,有两种方式:
- 虚拟区间少时用单链表:
mmap指针指向链表头,vm_next/vm_prev串联 - 虚拟区间多时切换红黑树:
mm_rb指向树根,用vm_rb节点插入树中
不管哪种方式,每个节点都记录了一段区域的 vm_start 和 vm_end。代码区、数据区、堆区、栈区、mmap 映射的共享库、命令行参数、环境变量——所有这些区域在进程眼里是有序的,底层就是用这张链表(或红黑树)来管理的。
mm_struct 里的宏观字段(start_code、end_code 等)和 VMA 链表是同时使用的。宏观字段表达整体空间的大框架,VMA 链表提供细粒度的区域管理。它们在某些位置的值是相等的——比如代码区对应的某个 VMA 节点的 vm_start 就等于 start_code。
理解虚拟地址空间,建议以 VMA 这张图为主——它是一个一个 vm_start 和 vm_end 串起来的结构,合在一起就是进程看到的全部区域。
回到那个冰箱
现在重新看最早那个实验。把一个进程的完整结构画出来:
task_struct→mm_struct(虚拟地址空间),全局数据区里g_value的虚拟地址0x601058- 页表:
0x601058→0x1234 - 物理内存
0x1234处:g_value = 0
fork 创建子进程。PCB、地址空间、页表全部拷贝。因为虚拟地址空间完全一样,子进程的 g_value 虚拟地址也是 0x601058。页表发生浅拷贝,父子的虚拟地址都指向物理地址 0x1234。
子进程做 g_value = 100(或者 g_value++)。
操作系统发现:“这个物理页正被两个进程共享。你要写?我给你复制一份。”
于是:物理内存里开辟新空间(0x1111),拷贝旧值(0)过去,修改子进程页表——0x601058 → 0x1111。子进程在新空间上写 100(或做 ++)。
父进程的页表没动——还是 0x601058 → 0x1234,值还是 0。
虚拟地址相同,页表映射不同,物理地址不同,值不同。 这就是全局变量地址一样值不一样的根本原因。也是 fork 返回值既等于 0 又大于 0 的根本原因。
为什么非要虚拟地址空间?
这个问题等价于:如果程序直接操作物理内存,会有什么问题?
第一个时代:没有虚拟地址的时候
早期的计算机直接把整个程序装入物理内存运行。程序里指针指的就是物理地址。
比如物理内存 128MB,同时跑程序 A(占 10MB)和程序 B(占 110MB)。操作系统先把前 10MB 分给 A,再从剩余 118MB 中划出 110MB 给 B。A 和 B 都能跑,但问题一堆:
安全风险。 每个进程的内部指针就是物理地址。A 的一个野指针完全可能指向 B 的内存区域——读走密码、改掉余额。如果是木马病毒,随意修改系统内存,设备直接瘫痪。进程独立性无从谈起。
地址不确定。 程序编译好放在硬盘上,运行时搬到内存。如果直接使用物理地址,每次运行的加载位置都不确定——第一次跑 a.out 时内存空空,可能搬到 0x00000000;第二次跑时内存里已经有 10 个进程在跑,加载地址就不知道在哪了。操作系统必须把每个进程的加载地址全记下来,管理复杂。
效率低下。 物理内存不够用时,需要把不常用的进程整个拷贝到磁盘交换分区(swap out),腾出内存后再把需要的进程 swap in。如果直接操作物理地址,就得把整个进程一起拷走——内存和磁盘之间的拷贝时间太长,效率低。
有了虚拟地址空间之后
理由一:对内存进行保护。
虚拟地址到物理地址的转化由 MMU 完成。MMU 是一个集成在 CPU 内部的硬件。CPU 每次发出访存请求,MMU 自动查页表做翻译。
因为多了一层转化层,就在这层转化里做拦截:
- 你指的那个地址在页表里没映射?→ 转化失败 → 操作系统终止进程。不存在的东西你访问不了。
- 映射存在,但权限不对?页表条目里有权限标志位:可读(R)、可读写(RW)、可读可执行(RX)。代码区通常是只读的——你拿指针想往里写?权限不匹配 → 转化失败 → 进程崩掉。
这也就解释了为什么字符串常量不可被修改。char *msg = "hello world"——这个字符串编译时被放在了代码区。代码区对应的页表条目里,权限标志是 R(只读)。你想写?MMU 不让你过,操作系统把你进程毙掉。
怎么理解这个拦截的效果?
以前你拿着压岁钱直接跑去商店——没人拦你,买了一堆不需要的东西。后来你妈说:"压岁钱交给我。你要买什么跟我说,我告诉你能不能买。"你要买本子——你妈让你去。你要买游戏机——你妈说:"上学呢,玩什么游戏机?"拒绝了。因为你和商店之间多了层"你妈"这个角色,你的行为就可以在这一层被拦截。
虚拟地址空间 + 页表 + MMU,就是在进程和物理内存之间插了一层"你妈"。进程说"我要访问地址 X"——操作系统(通过 MMU)先查页表:X 在不在?权限对不对?不合法就不让你过去。地址空间和页表是操作系统创建和维护的,所有内存访问都得在操作系统的监管下进行。 这就保护了物理内存里所有合法数据——包括各个进程以及内核的数据。
再拿三八线来理解野指针检测。小花划分的区域是 1 到 60,小胖是 60 到 100。小胖把胳膊伸到 50 这个位置——小花立刻知道:"你的开始是 60,你把胳膊伸到 50 这里,你越界了!"同样的道理,进程的虚拟地址空间里,各个区域的 start 和 end 限定了合法范围。代码区只有这一段是你的,数据区只有那一段是你的,堆区只有这一段是——空白区域不是你的。你拿指针乱指向空白区域——这个地址没落在任何一个区间的 start/end 里。页表里也查不到。操作系统就识别到:刚才这个进程拿了一个乱指。直接把进程毙掉。你的进程崩溃了——不是因为操作系统脾气差,是因为你越界了。
理由二:把物理内存的无序变成进程视角的有序。
因为物理内存的分配是动态的,进程的代码可能在 0x1234,数据在 0xABCD,堆在 0x5678——在物理层面是杂乱无章的。
但因为有虚拟地址空间和页表的映射,每个进程看到的布局永远一样:代码段在最低处,数据段在上面,堆在数据上面往上长,栈在最高处往下长,命令行参数和环境变量在最顶上。无非你的代码比我大一点,我的堆比你大一点——但地图的结构是一致的。
因为页表的映射的存在,程序在物理内存中理论上可以在任意位置加载。它将虚拟地址和物理地址进行映射,在进程视角中所有的内存分布都可以是有序的。
这就是虚拟地址空间第二个核心价值:把无序变有序。
理由三:进程管理与内存管理解耦合。
因为有大富翁那张饼——你在 malloc 或 new 的时候,其实只是在虚拟地址空间上申请。mm_struct 里改几个 end 值,空间就有了。物理内存可以一个字节都不给你。
等到你真正对这个空间做写入时,操作系统才执行内存管理算法:申请物理页,填充页表映射关系。整个过程叫延迟分配——由操作系统自动完成,用户和进程完全零感知。
这样一来——
- 左边(进程的创建、调度、切换、空间申请)属于进程管理模块。进程申请空间,在虚拟地址空间上操作就够了。
- 右边(物理内存的分配、回收、换入换出)属于内存管理模块。独立负责物理层的操作。
物理内存的分配和进程的管理可以做到没有关系。进程管理模块和内存管理模块完成了解耦合。
malloc 了 1GB 但物理内存只有 512MB?没问题——只要你没真的同时用满 1GB,物理内存就不会被掏空。
还没讲到的
页表本身的内部结构(多级页表怎么省空间)、TLB(页表缓存)怎么加速翻译、缺页中断(page fault)怎么触发、ELF 可执行文件格式和虚拟地址空间怎么配合、动态库映射机制、物理内存管理的算法(buddy system、slab)、页框回收(page reclamation)怎么决定把谁的页换出去——这些话题,一节课塞不下。
但这个话题后续会再讲四次。每次各有侧重。今天的目标是搭出宏观框架:虚拟地址空间是什么、区域划分怎么来的、页表干嘛用的、写时拷贝怎么回事、为什么要有这一整套东西。
真正理解虚拟地址空间,需要掌握进程本身、硬件(页表、MMU)、程序翻译(编译器、ELF 格式)、内存管理——四块拼图。今天只是第一块。
你已经看到了这张地图的全貌:
- 你在 C 语言里看到的地址是假的。 虚拟地址,地图上的坐标,不是物理芯片上的位置。物理地址用户根本看不到。
- 这张地图是一个内核数据结构。
mm_struct,里面装了一堆start和end。vm_area_struct链表(或红黑树)处理不连续区域。 - 虚拟地址到物理地址,中间隔了页表。 查页表的工作是 MMU 这个硬件自动完成的。所有访问都经过这层翻译。
- 承诺和兑现是分开的。
fork时不拷数据(写时拷贝,谁写谁触发)。malloc时不分配物理内存(惰性分配,真用了才给)。你以为的"实时"全是延迟的。 - 这不是 bug,这是现代操作系统最精巧的设计。 安全靠它(MMU 在翻译层做拦截)、整齐靠它(无序物理内存映射成有序虚拟空间)、解耦靠它(进程管理和内存管理各干各的)。
你在 C 语言里写的每一行代码——每一个 &、每一个 malloc、每一个 fork——全都是在跟 mm_struct 交互。你以为你在操作内存,其实你在改 start 和 end。你以为你写的是物理地址,其实你写的是操作系统给你画的一张饼上的编号。
That’s the way it is.

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐


 4
4 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)