计算机操作系统期末重要知识点整理
沈阳工业大学-计算系系统期末考点讲解与总结
此笔记用作作者复习期末考试的考点与知识点
分享与我同校的学生用于减少复习时间 - 沈阳工业大学
目前暂未更新完
计算机操作系统重要知识点整理
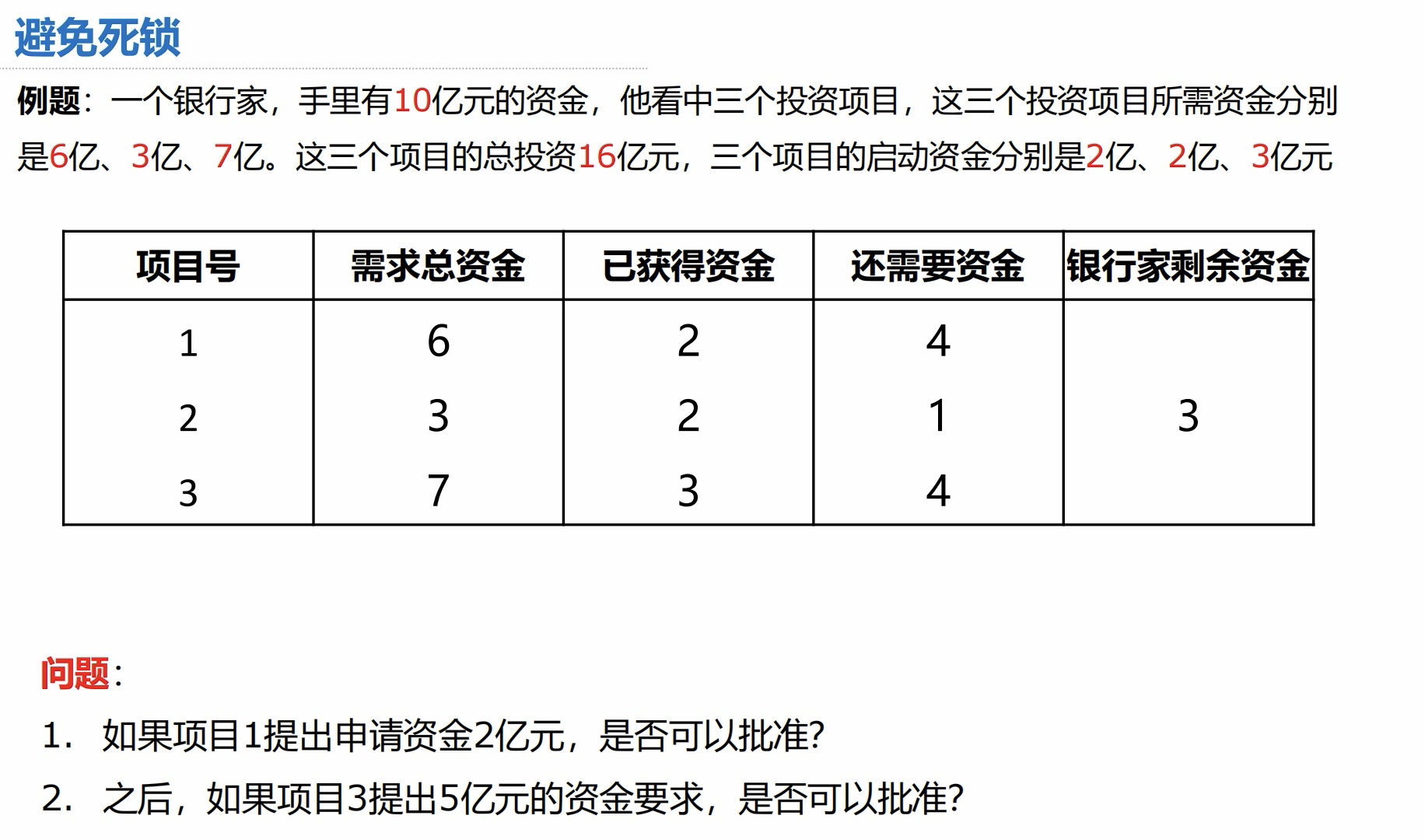
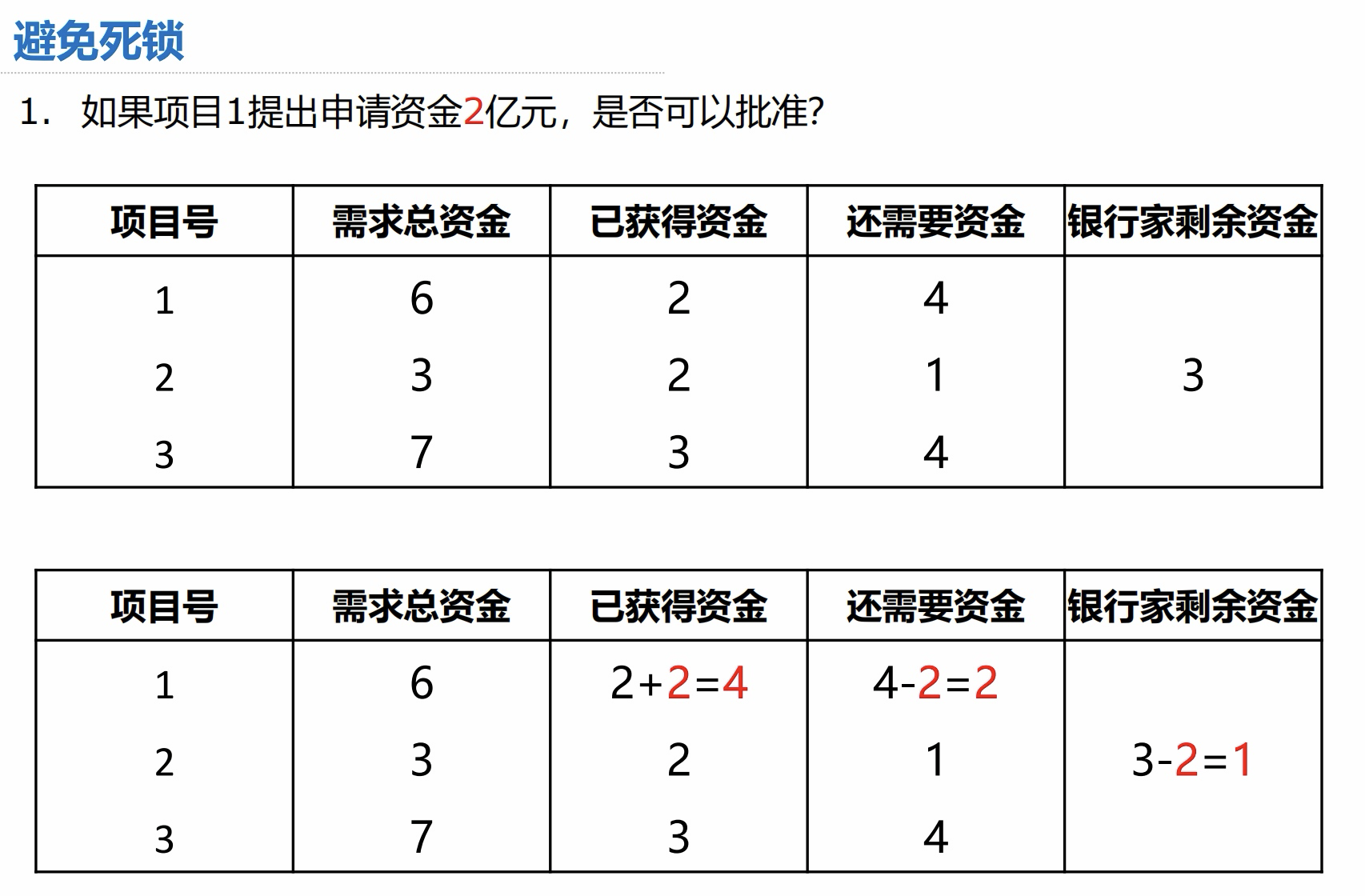
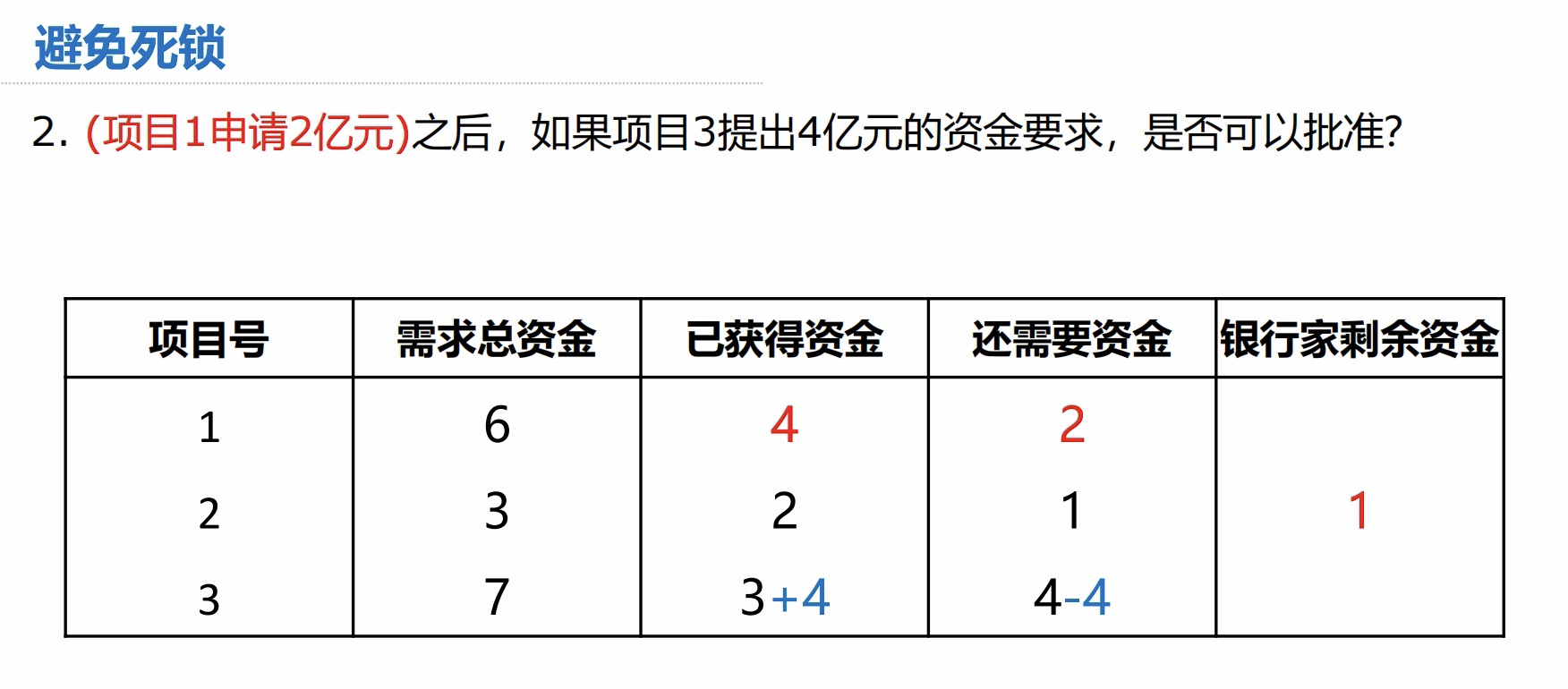
1.进程调度算法
- CPU 利用率:忙碌的时间 ➗ 总时间
- 系统吞吐量:一共完成多少道作业 ➗ 一共花费多少时间
- (重要)周转时间:作业完成时间 - 作业提交时间
- (重要)平均周转时间:各作业周转时间之和 ➗ 作业数
- (重要)带权周转时间:作业周转时间 ➗ 作业实际运行的时间 = (作业完成时间 - 作业提交时间)➗ 作业实际运行时间
1.1 先来先服务算法(FCFS, First Come First Serve)
【例】各进程到达就绪队列的时间、需要的运行时间如下表所示。使用FCFS调度算法,计算各进程的周转时间、平均周转时间、带权周转时间、平均带权周转时间。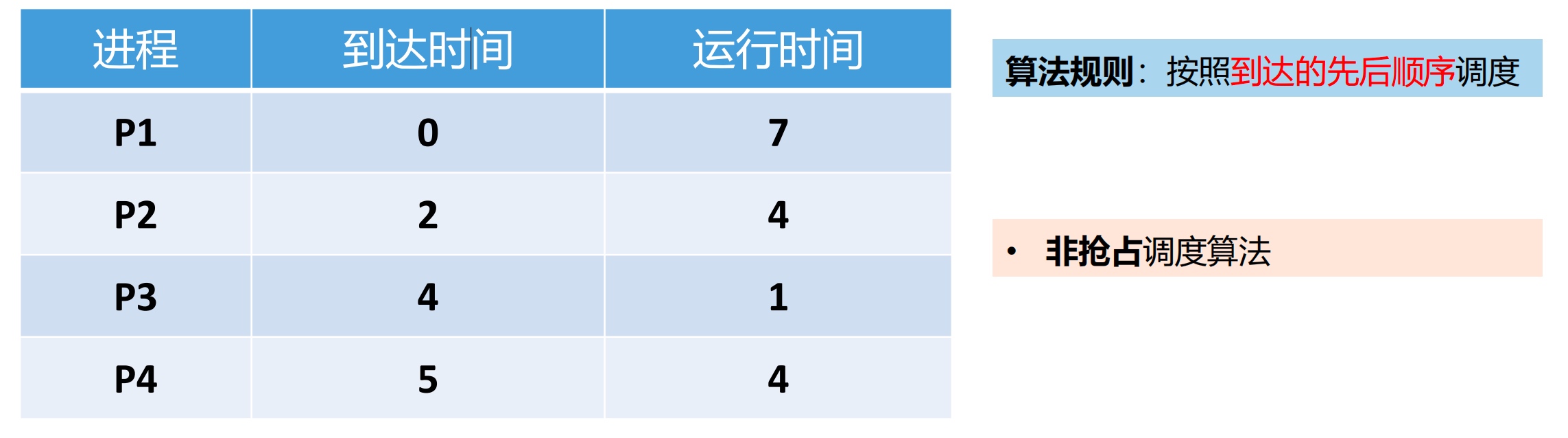
答案:

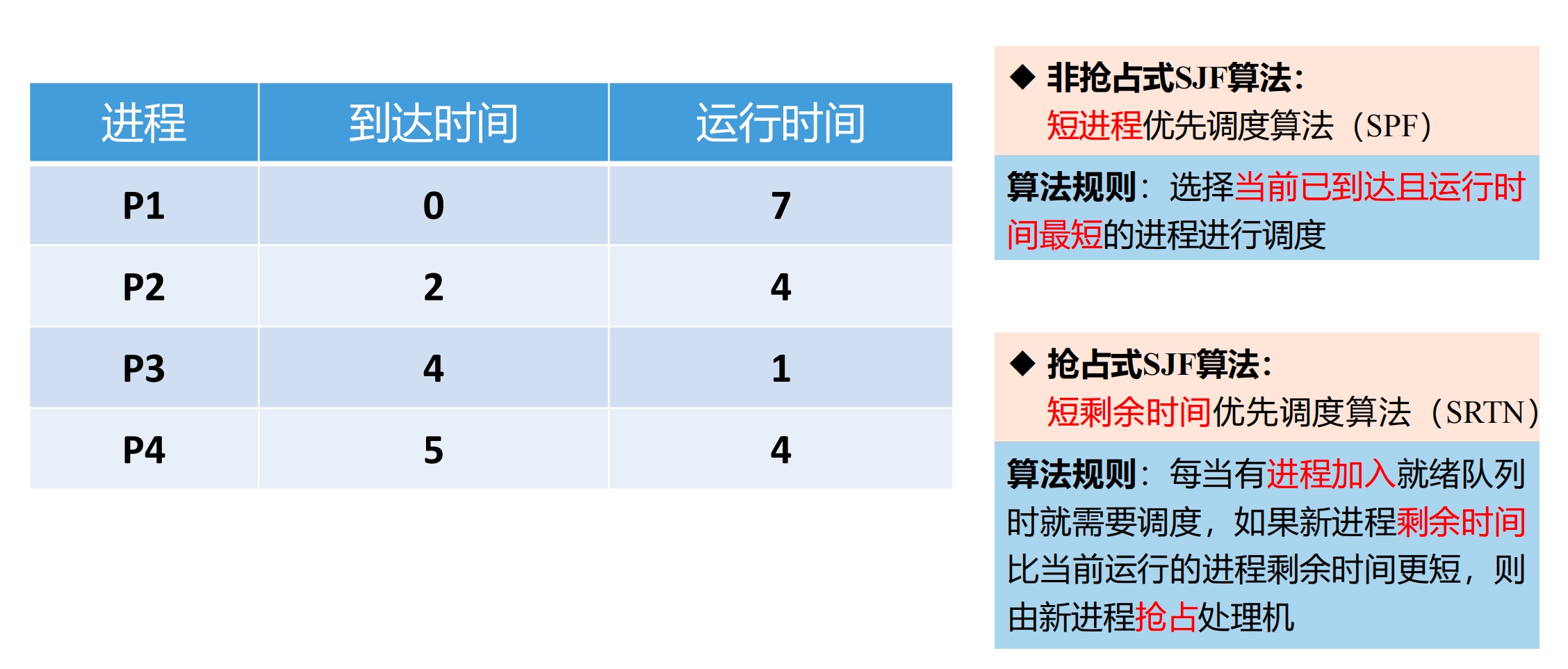
1.2 短作业优先算法(SJF, Shortest Job First)
算法分为:
-
非抢占式 SJF 算法:短进程优先调度算法(SPF)
- 算法规则:选择当前已到达且运行时间最短的进程进行调度
-
抢占式 SJF 算法:短剩余时间优先调度算法(SRTN)
- 算法规则:每当有进程加入就绪队列时就需要调度,如果新进程剩余时间比当前运行的进程剩余时间更短,则由新进程抢占处理机
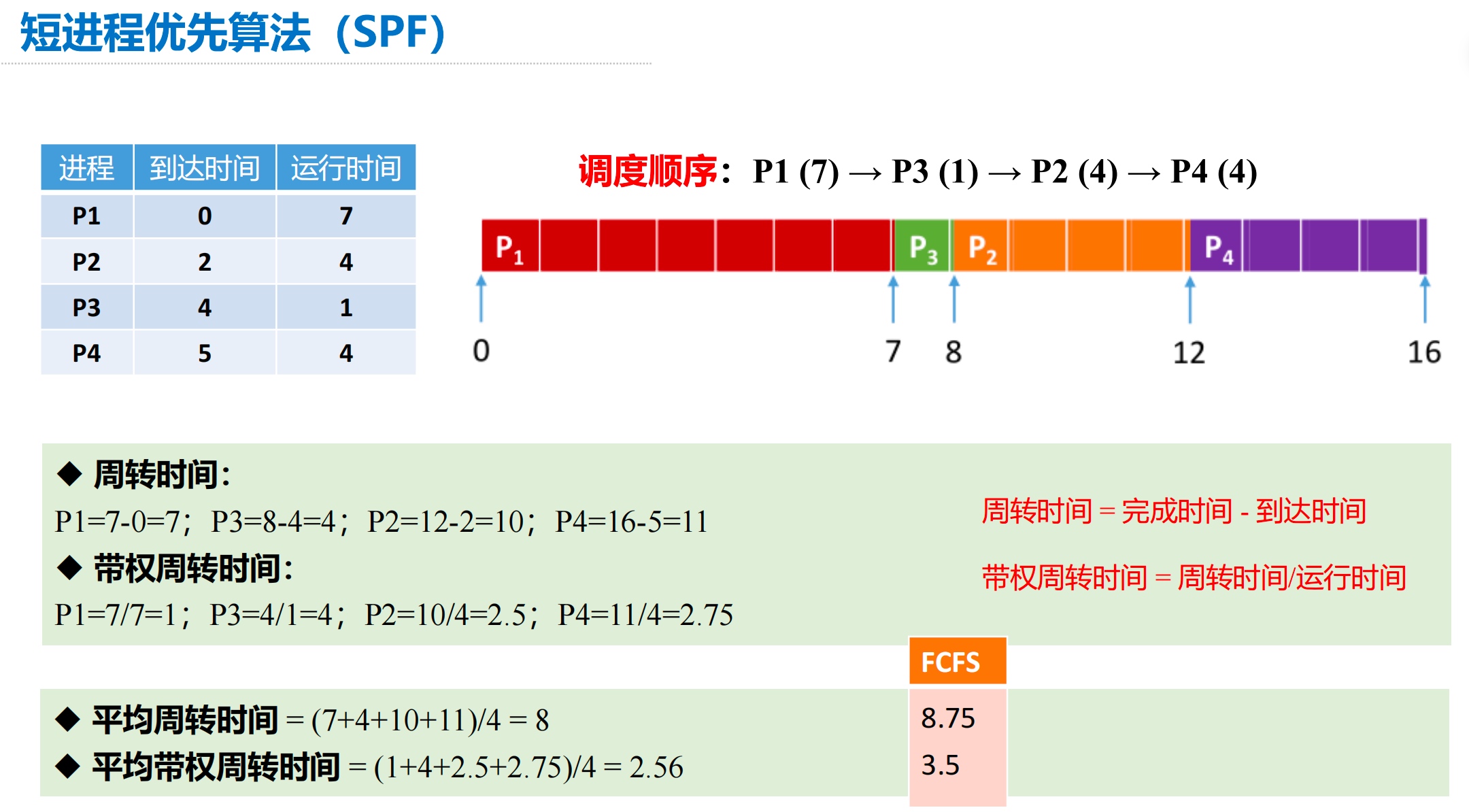
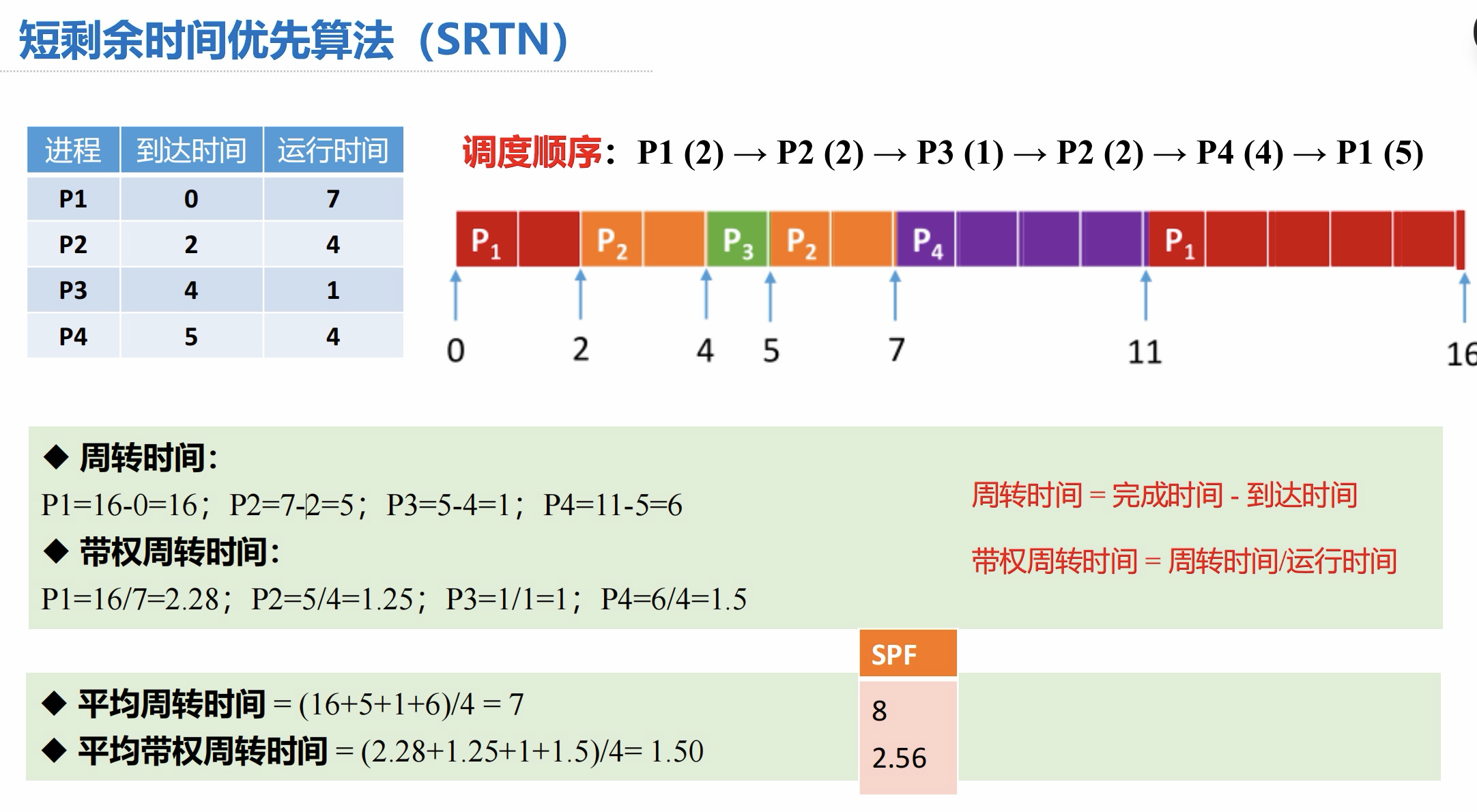
【例】各进程到达就绪队列的时间、需要的运行时间如下表所示。使用SJF调度算法,计算各进程的周转X 时间、平均周转时间、带权周转时间、平均带权周转时间。
使用短进程优先算法进行计算(SPF 非抢占式 SJF 算法):
使用短剩余时间优先算法(SRTN 抢占式 SJF 算法):
1.3 高响应比优先算法(HRRN, Highest Response Ratio Next)
HRRN 算法是非抢占式的调度算法。
算法规则:
- 只有当前运行的进程主动放弃CPU时(正常/异常完成,或主动阻塞),才需要进行调度,调度时计算所有就绪进程的响应比,选响应比最高的进程上处理机。
响应比 =(等待时间 + 要求服务时间)➗ 要求服务时间
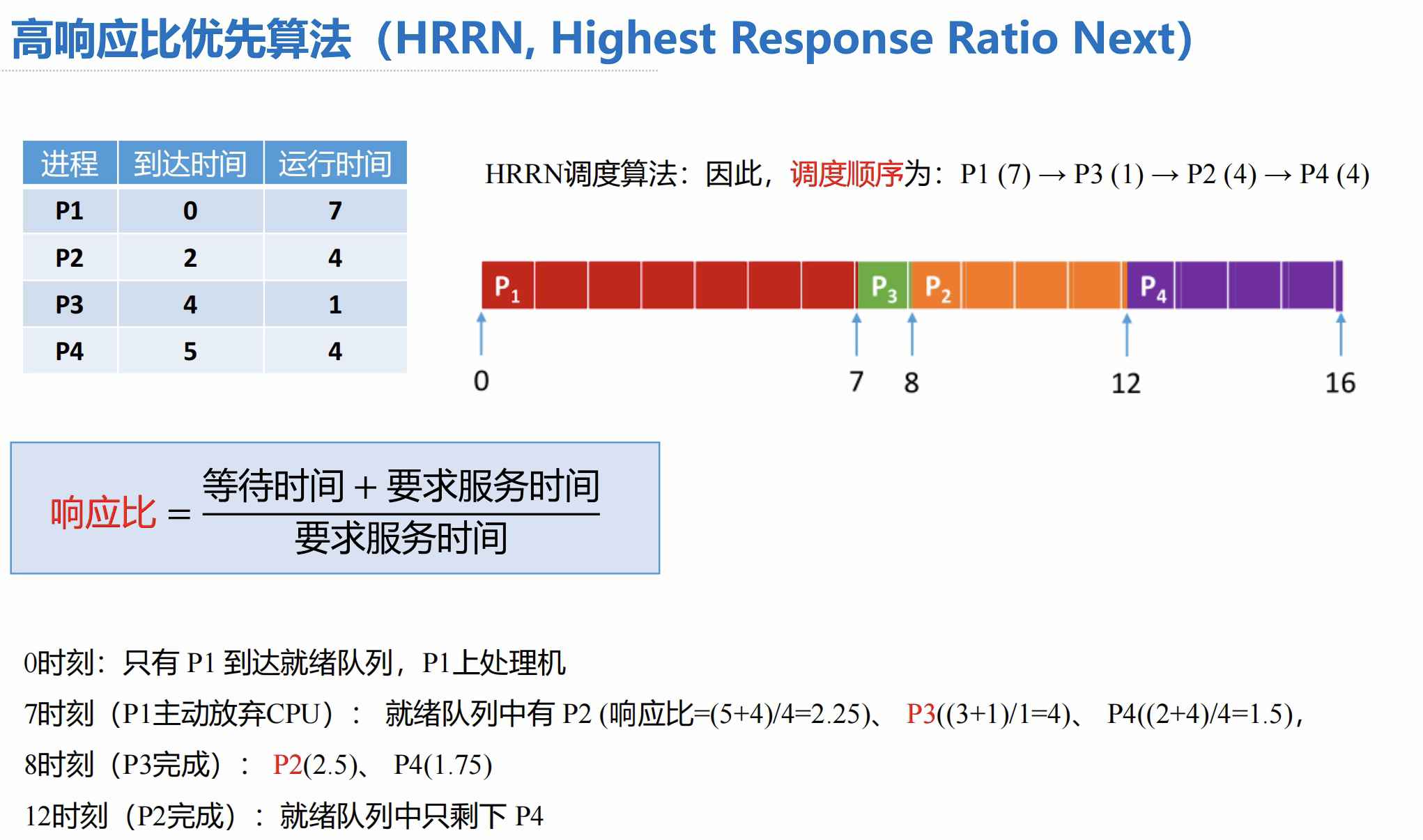
【例】各进程到达就绪队列的时间、需要的运行时间如下表所示。使用 HRRN 调度算法,计算各进程的等待时间、平均等待时间、周转时间、平均周转时间、带权周转时间、平均带权周转时间。
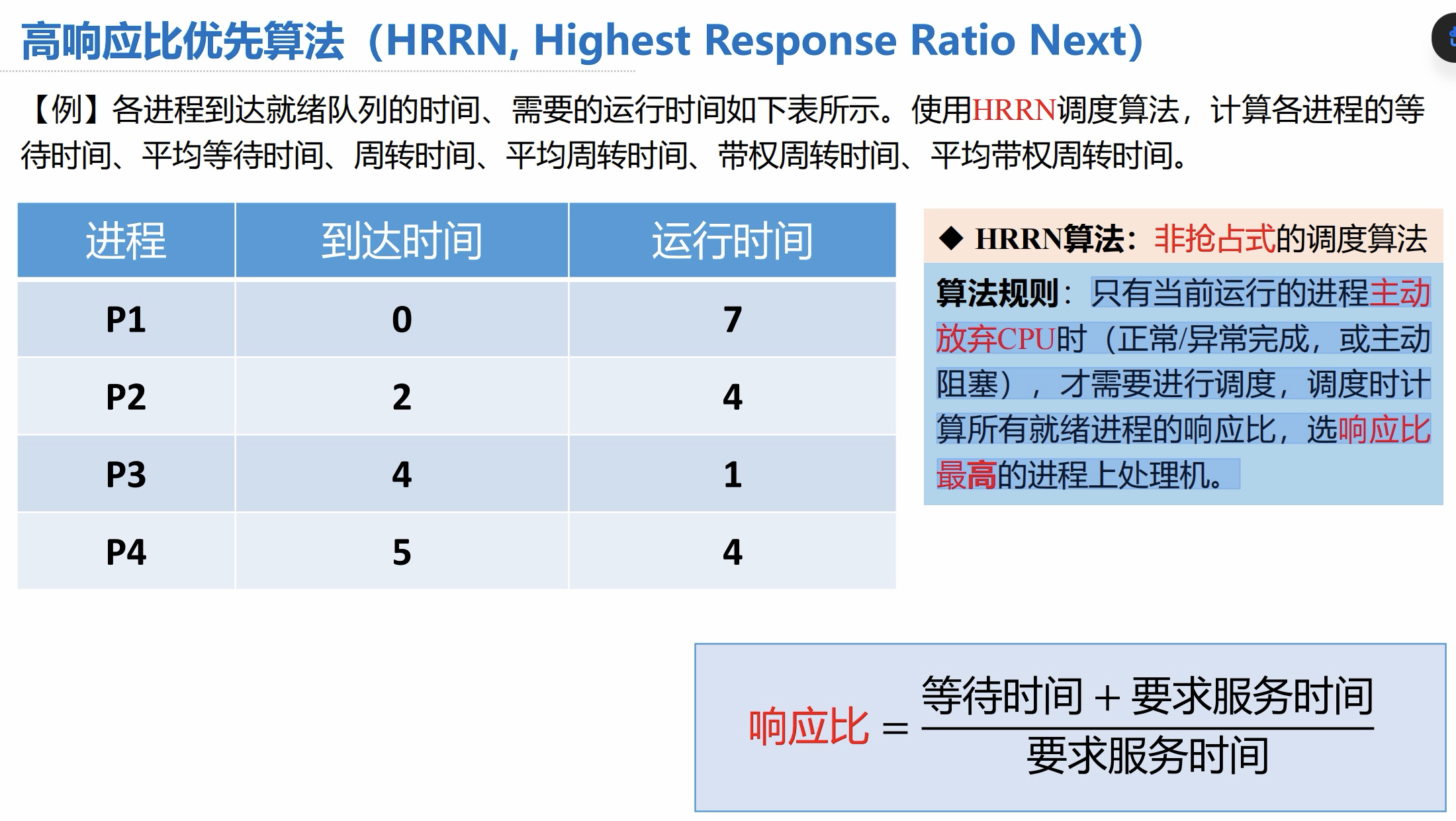
答案:
1.4 时间片轮转算法
算法规则:
- 轮流让就绪队列中的进程依次执行一个时间片(每次选择的都是排在就绪队列队头的进程)
例题:各进程到达就绪队列的时间、需要的运行时间如下表所示。使用时间片轮转调度算法,分析时间片大小分别是2、5时的进程运行情况。(常用于分时系统,更注重“响应时间”,因而此处不计算周转时间)
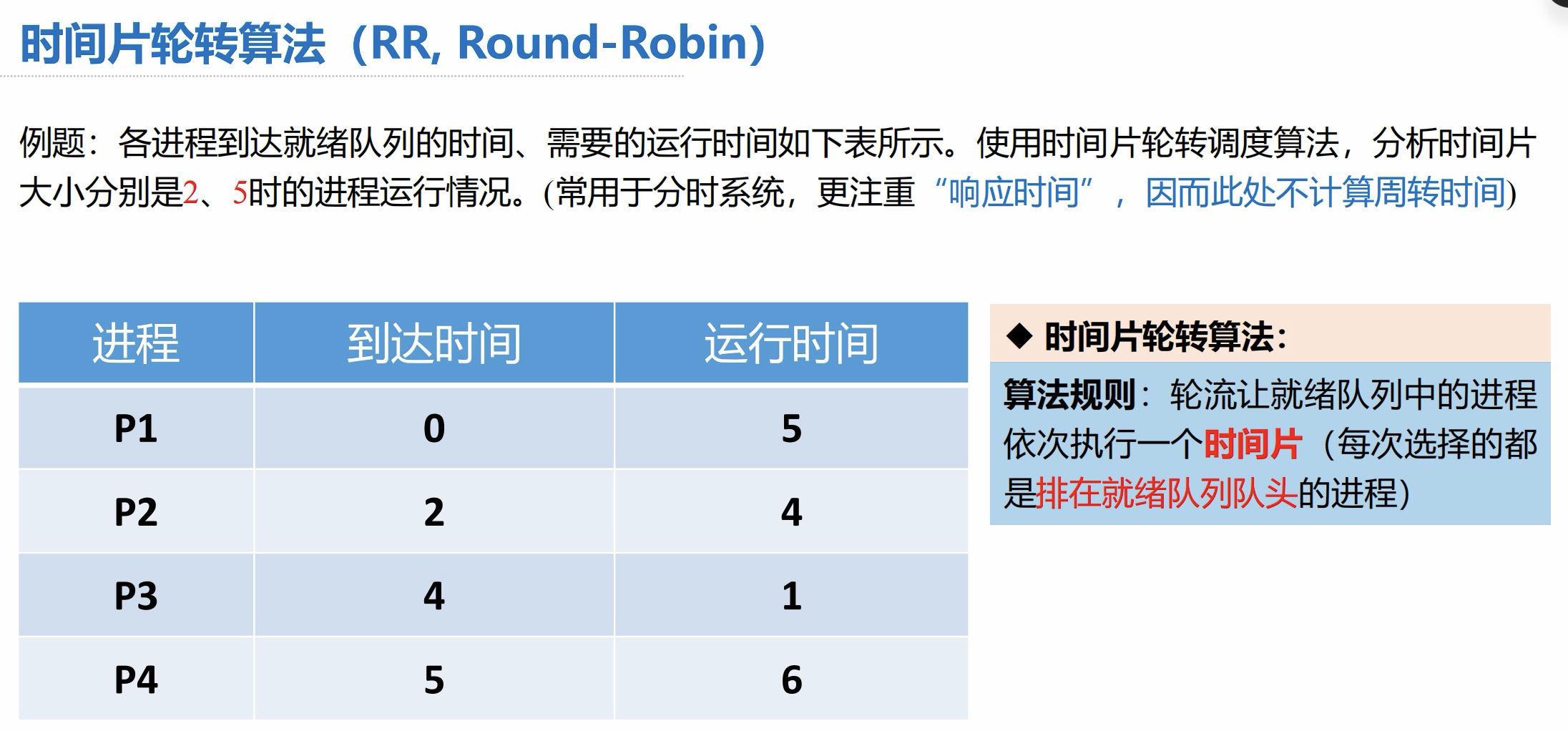
答案:

在解答时间片轮转算法题目的时候注意就绪队列,对队列的处理要注意新来的进程和时间片结束为执行结束的进程,都要按照顺序排到就绪队列的末尾,这样才可以保障就绪队列顺序的正确性。
1.5 优先级调度算法
-
非抢占式优先级调度算法:
- 算法规则:每次调度选择当前已到达且优先级最高的进程;当前进程主动放弃处理机时发生调度。
-
抢占式优先级调度算法:
- 算法规则:每次调度时选择当前已到达且优先级最高的进程;当前进程主动放弃处理机时发生调度;同时,当就绪队列发生改变时需要检查是会发生抢占
例题:各进程到达就绪队列的时间、需要的运行时间、进程优先数如下表所示。使用非抢占式的优先级调优先级调度算法,分析进程运行情况。(注:此题优先数越大,优先级越高)
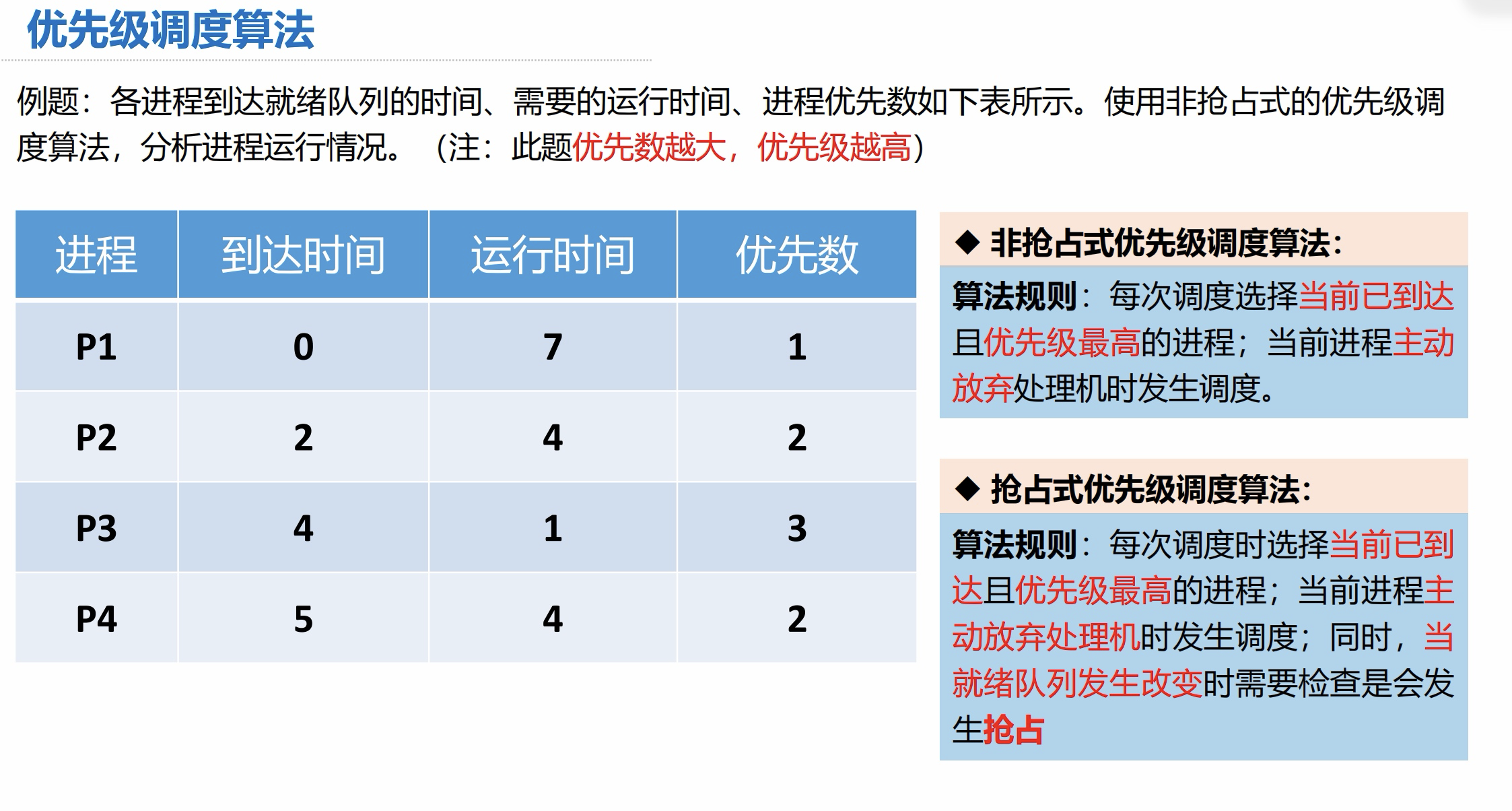
使用优先级调度算法——非抢占式:

使用优先级调度算法——抢占式:

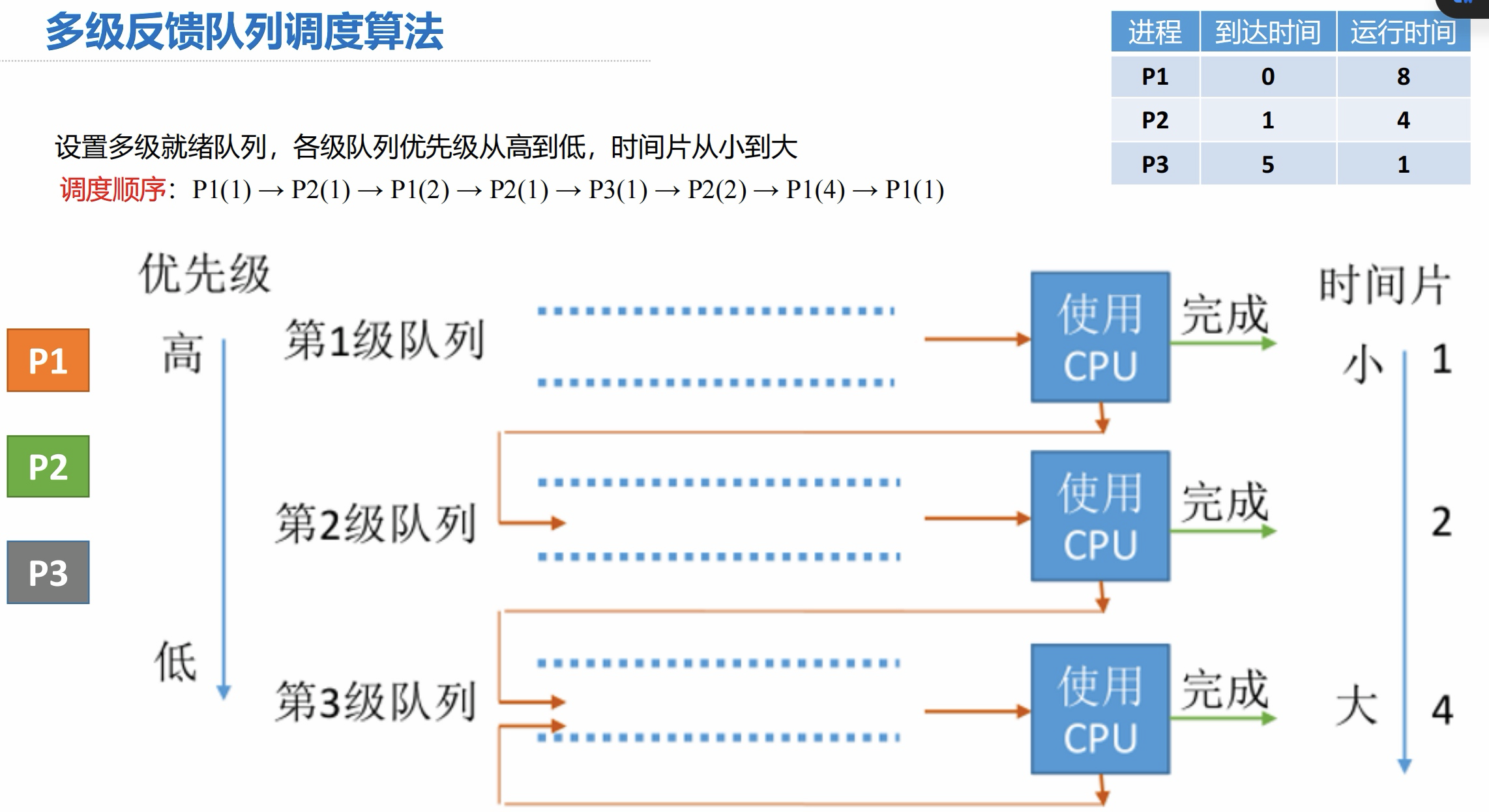
1.6 多级反馈队列调度算法
2. 进程同步问题
需要掌握的知识点:
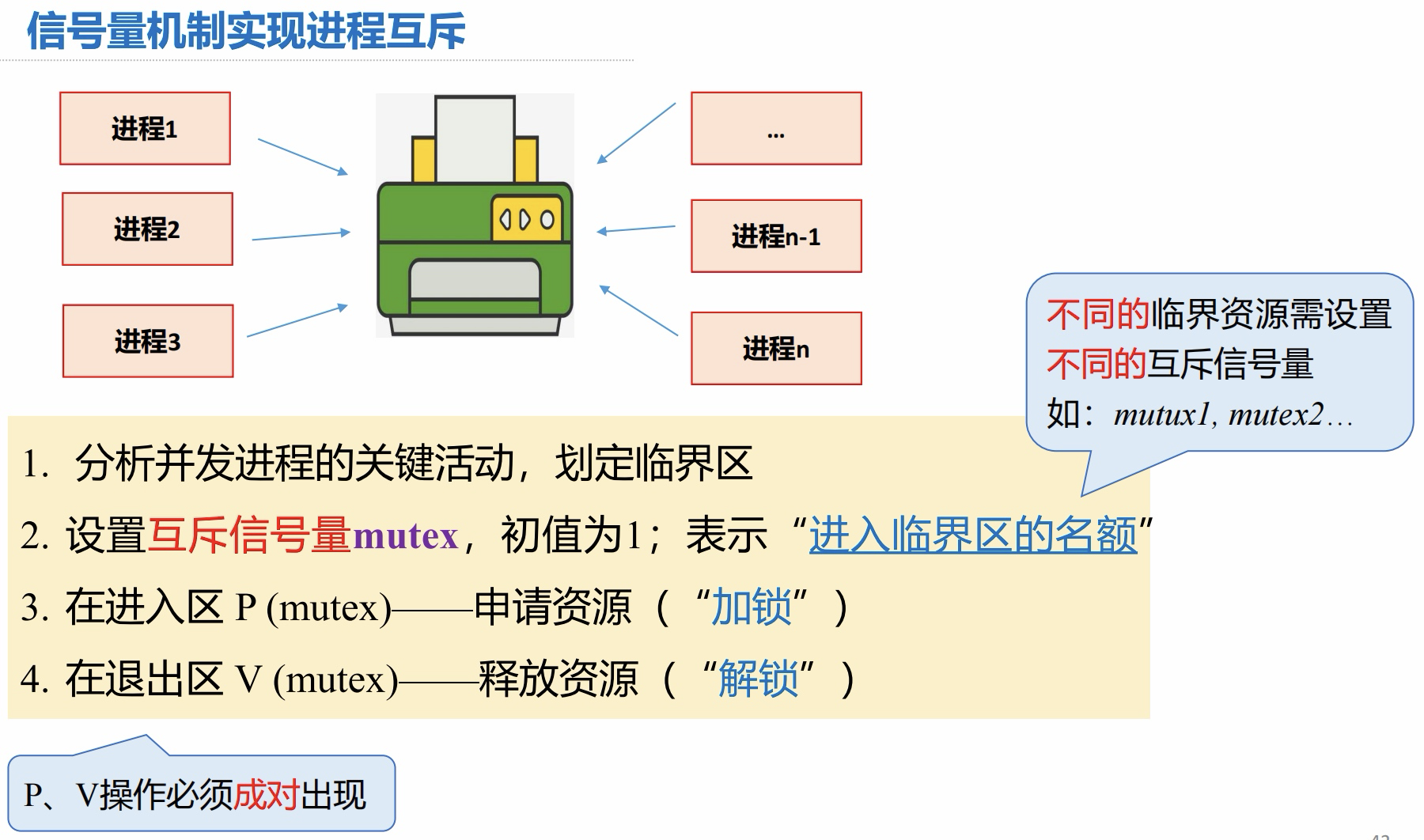
- 一个信号量对应一种可用资源
- 信号量的值 = 这种资源的剩余可用数量(信号量的值如果小于0,说明此时有进程在等待这种资源)
- P(S) —— 申请一个资源 S,如果资源不够就阻塞等待
- V(S) —— 释放一个资源 S,如果有进程在等待该资源,则唤醒一个进程

2.1 如何去思考设置信号量
在学完这部分内容后,作者觉得解题的精髓就是分析出信号量该如何设置,然后思路就会豁然开朗,,所以接下来对如何设置信号量的思考步骤做详细讲解
第一步:找出所有“角色”与“资源”
先不管代码怎么写,把所有参与者(进程)和它们争夺的“东西”列出来。
- 进程:有几个不同类型的进程?(比如:生产者、消费者、读者、写者、过桥的人)。
- 共享资源:它们共享什么?(比如:缓冲区、文件、打印机、桥、整型计数器)。
- 资源大小:资源有几个?是单个(size=1)还是多个(size=N)?
例子(生产者-消费者):
- 进程:生产者和消费者。
- 资源:大小为 N 的缓冲区。
第二步:判断两类关系
这是最关键的一步。你需要判断进程之间是互斥还是同步,或者两者都有。
-
互斥 (Mutex):
- 场景:多个进程不能同时访问某个共享区域(否则数据会乱)。
- 信号量含义:mutex。
- 初始值:通常为 1(像一把锁)。
-
同步 (Synchronization):
- 场景:一个进程必须等待另一个进程做完某件事后才能继续。
- 信号量含义:empty(空位)、full(满位)。
- 初始值:
- empty = 资源总量 N。
- full = 0(初始没有产品)。
口诀:资源是计数器(同步),区域是锁(互斥)。
第三步:设置信号量
根据第二步的结果,确定你需要定义几个信号量。
- 互斥信号量:mutex 或 lock,初值 1。
- 同步信号量:A_wait_B(A 等待 B 完成),初值 0。A_has_B(A 占用了 B),初值 N。
数量参考:
- 有 N 个不同类型的进程?可能 N 种信号量。
- 有 M 个不同的共享资源?可能 M 种信号量。
例子(读者-写者):
- 互斥:mutex(保护计数器),初值 1。
- 互斥/同步混合:rw(控制文件读写权),初值 1。
- 同步(用于公平调度):w(写优先信号量),初值 1。
第四步:确定 PV 顺序
这步决定了你的代码会不会死锁。
-
互斥锁的顺序:
- 黄金法则:如果既有互斥锁(mutex)又有同步信号量(empty/full),千万不要在持有互斥锁时去等待同步信号量!
- 正确写法:P(同步信号量) -> P(互斥锁) … V(互斥锁) -> V(同步信号量)。
- 原因:防止因为“拿着钥匙睡觉”导致死锁。
-
分配资源的顺序:
- 思考哪个资源是“门槛”,哪个是“核心”。
例子(读文件):
先看能不能读(P(w))。
再看文件是否空闲(P(rw))。
检查计数器并修改计数器(mutex保护)。
第五步:构思代码骨架
用伪代码填空。
- 进程循环:while(1) { … }
- 临界区入口:写 P 操作。
- 核心操作:具体读写、打印、过桥的动作。
- 临界区出口:写 V 操作。
2.2 生产者-消费者问题
关于生产者和消费者问题,老师的 PPT 讲解的足够详细,我不再做补充,只将 PPT 呈现出来,这部分也是考点之一,也在习题中出现
概念定义:

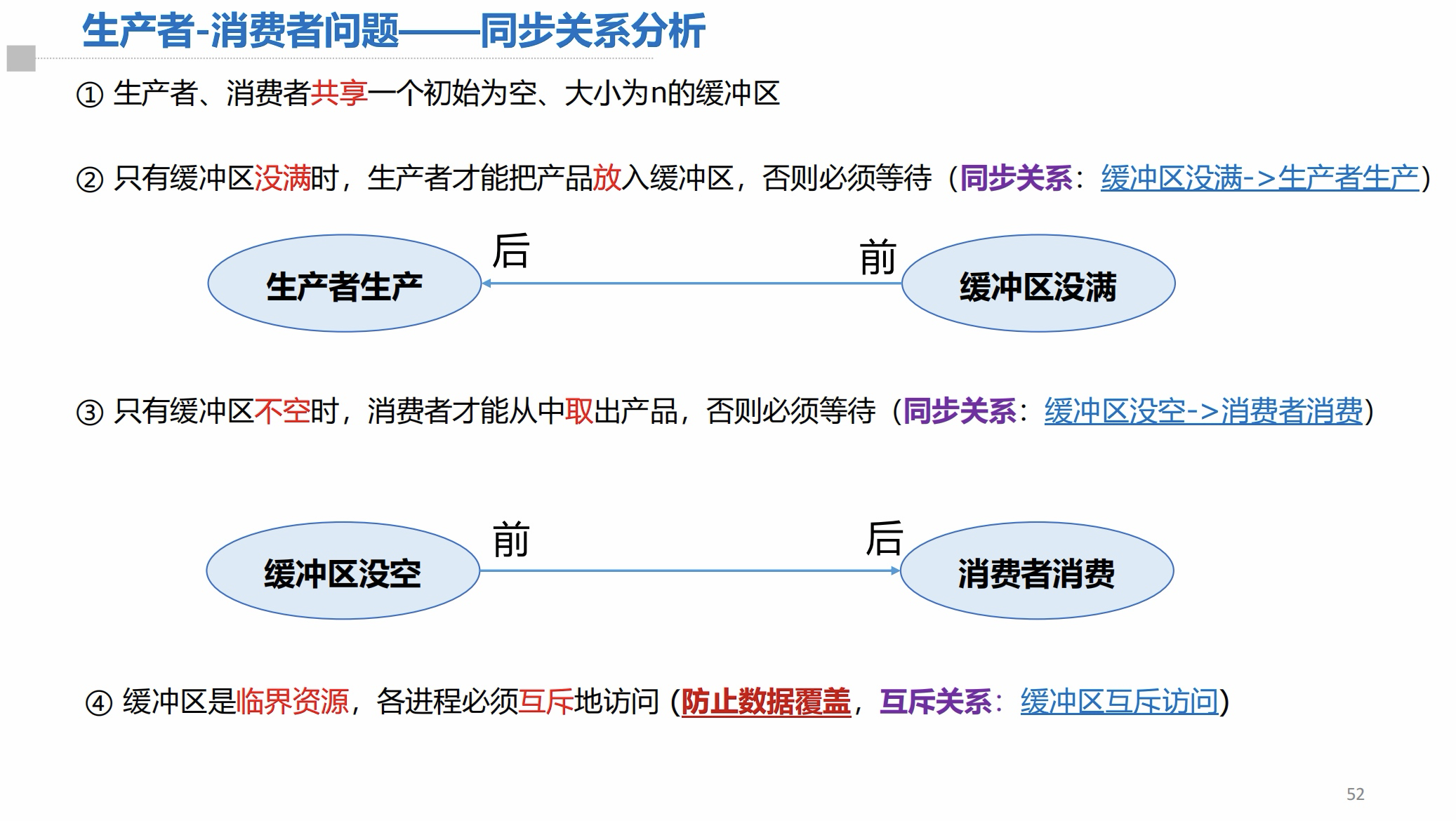
同步关系分析:
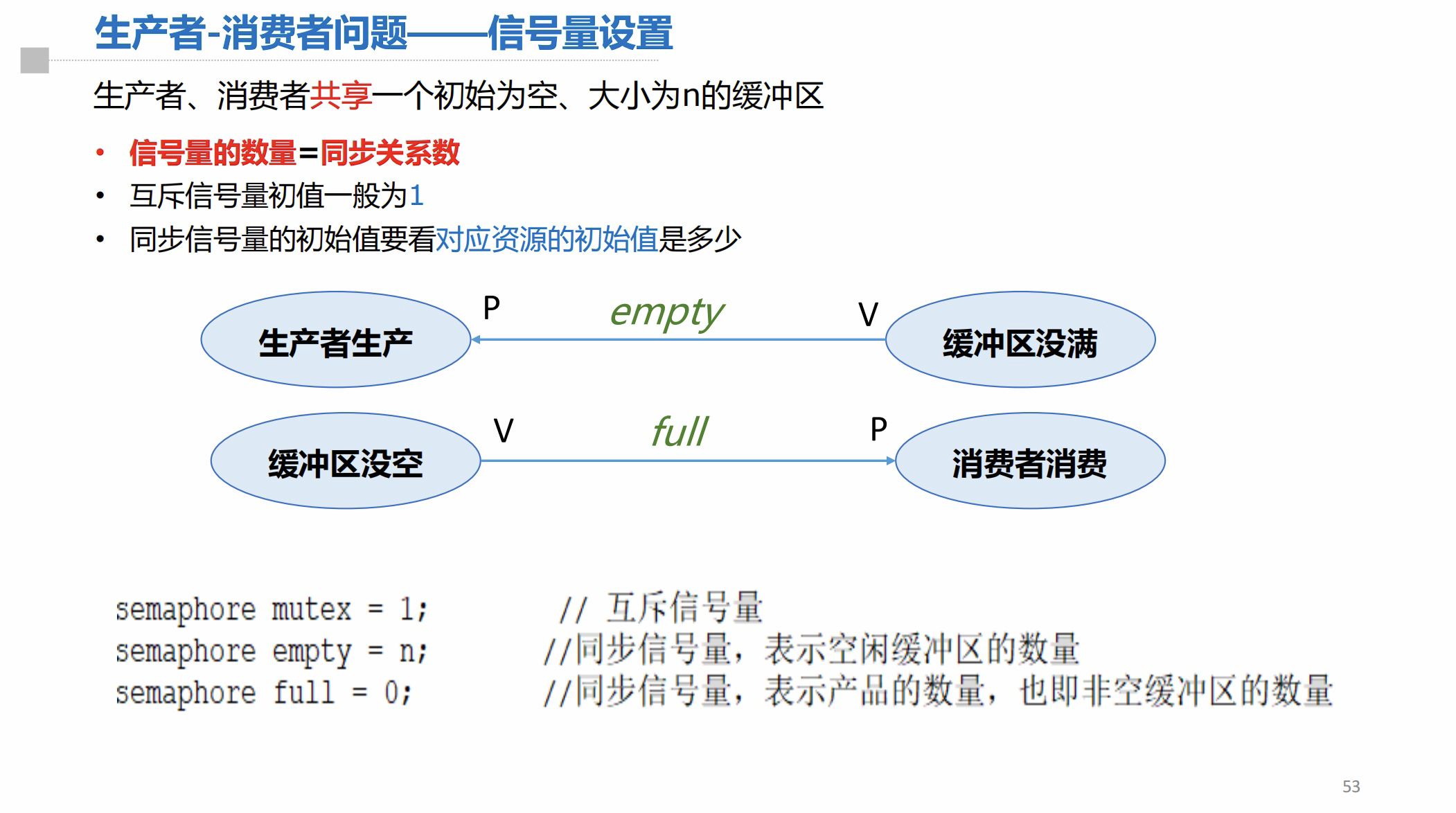
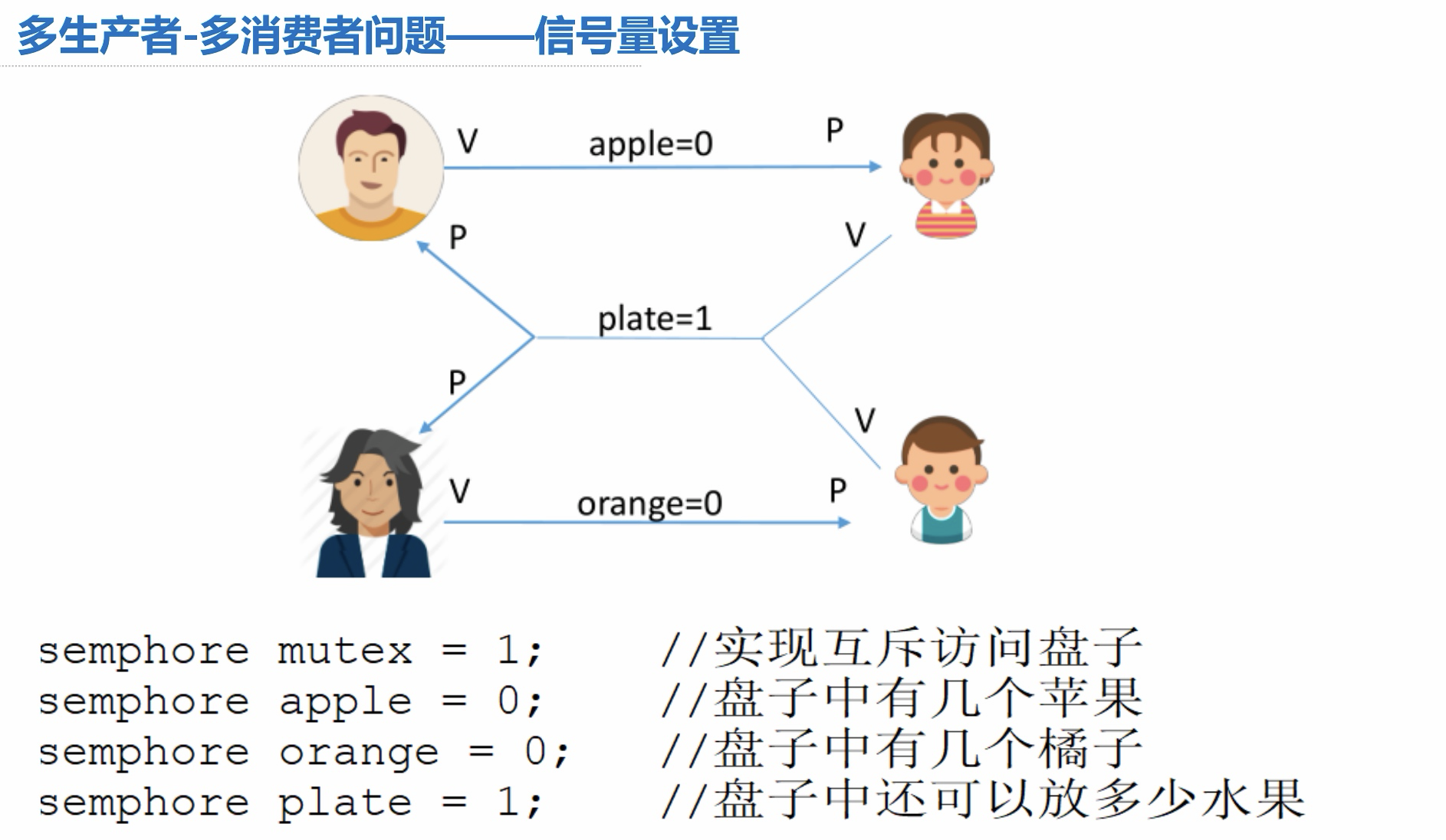
信号量设置:
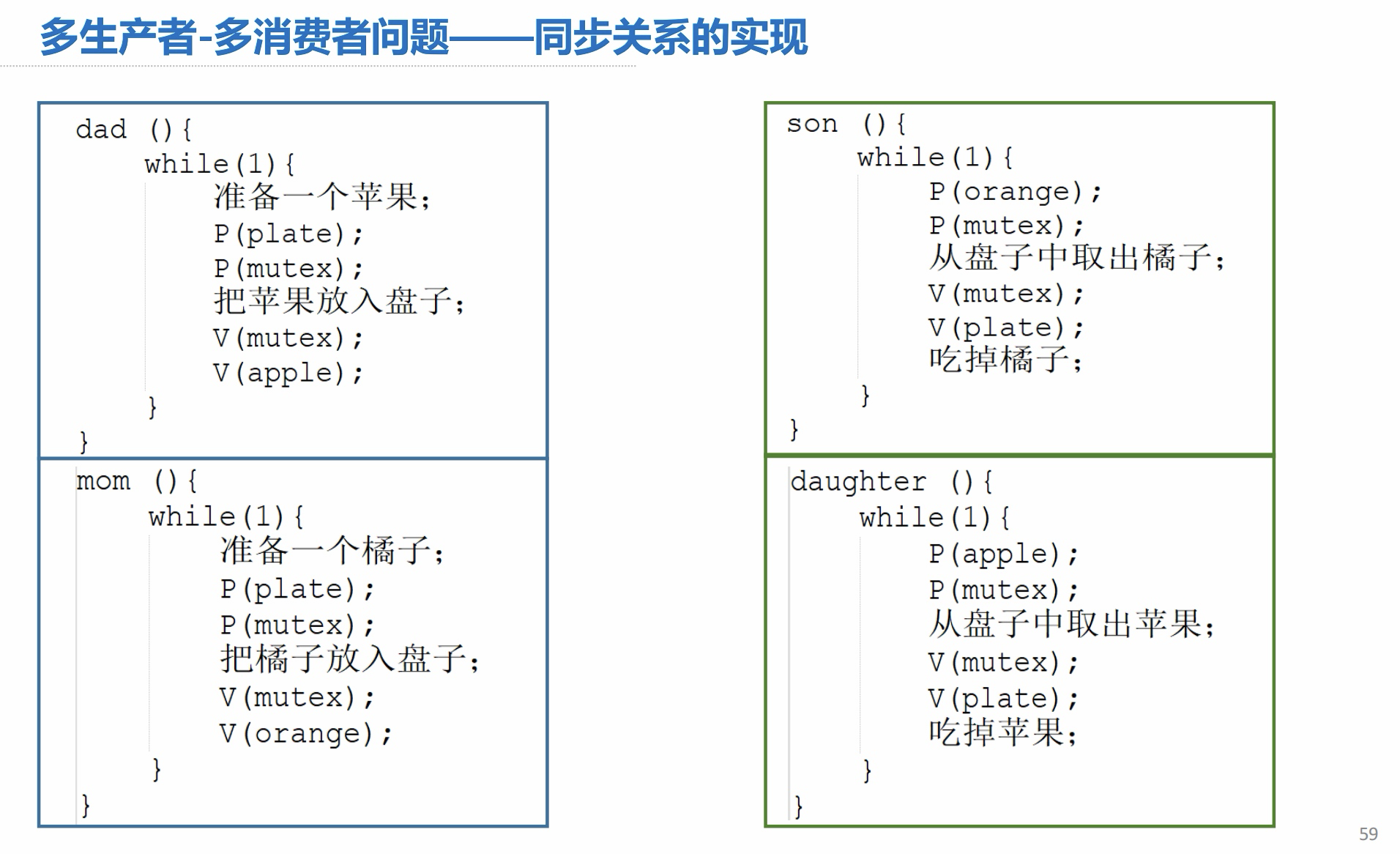
同步关系的实现:


在这里补充知识点:为什么实现互斥的P操作一定要在实现同步的P操作之后
以生产者为例,如果我们先执行实现互斥的P操作,意味着先申请了缓冲区的锁,如果此时缓冲区中没有空闲缓冲区,此时生产者就等待消费者消费,空出缓冲区,不幸的是当消费者尝试申请锁,进去缓冲区中取数据消费时,却发现锁死死捏在生产者手里,这是消费者没办法进行消费,无法空出缓冲区,生产者因为没有空闲缓冲区,所以一直捏着锁,造就了死锁情况。
消费者同理,不再赘述。
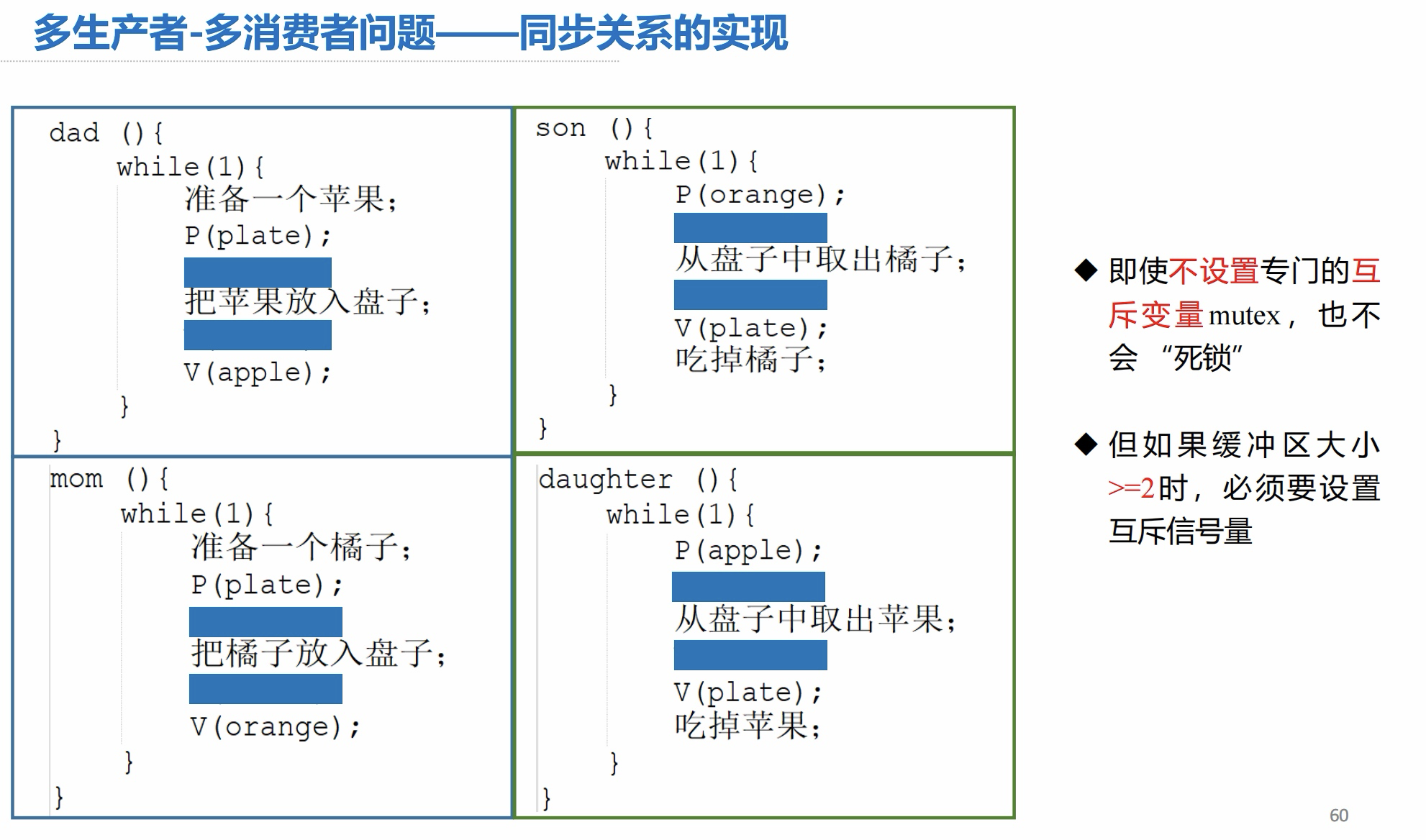
2.3 多生产者-多消费者问题
问题描述:
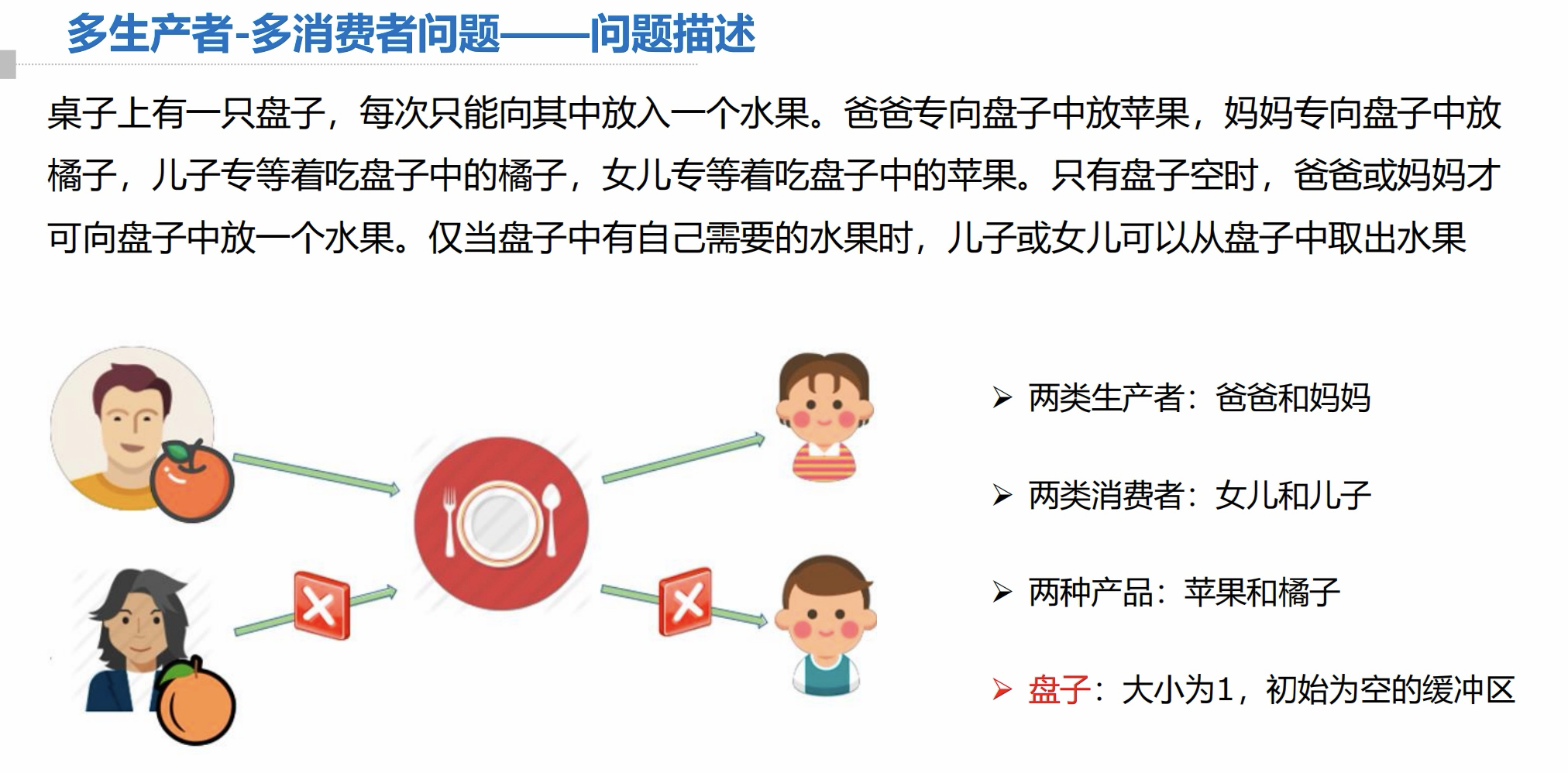
同步关系分析:
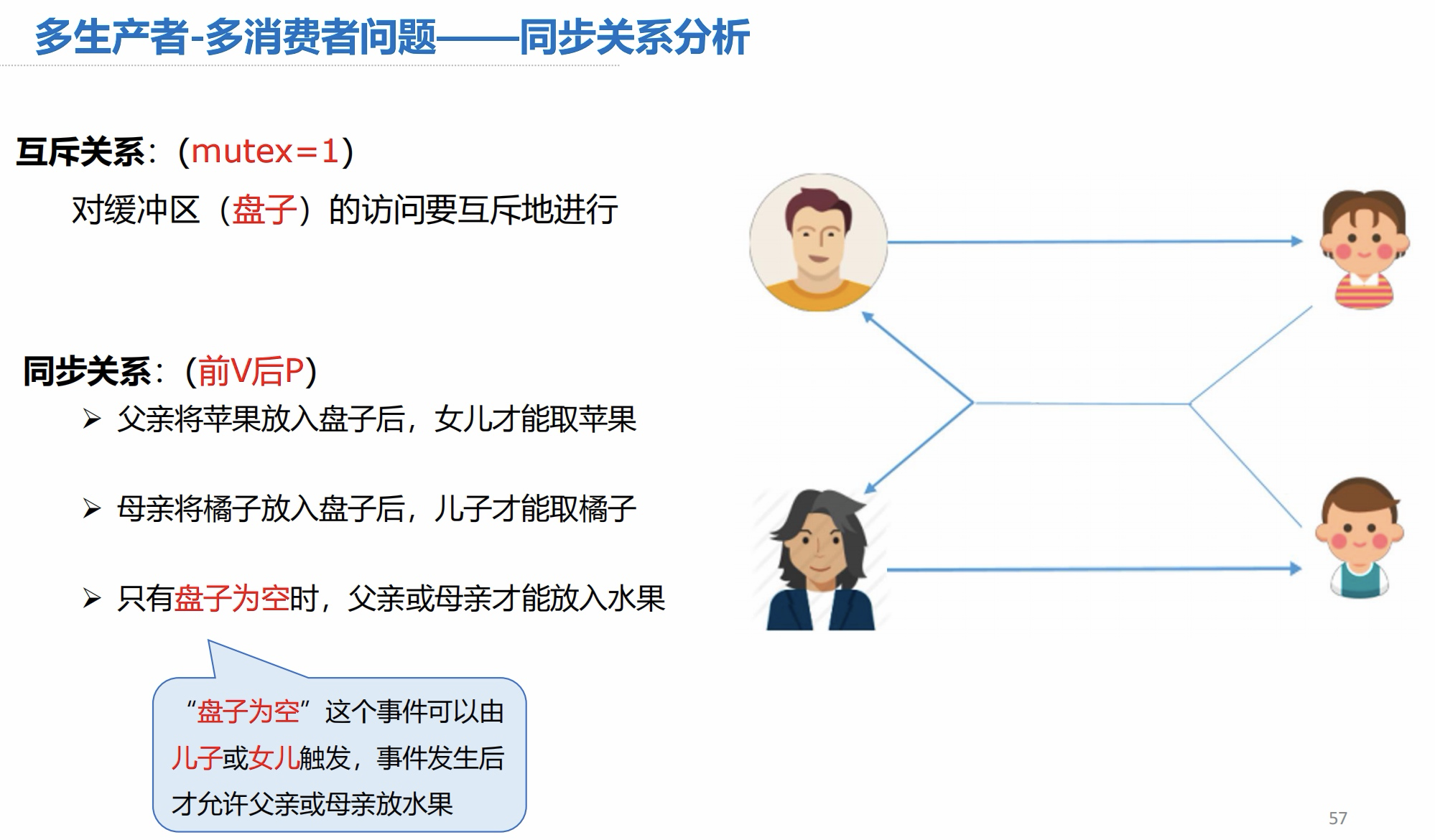
信号量设置:
同步关系的实现:
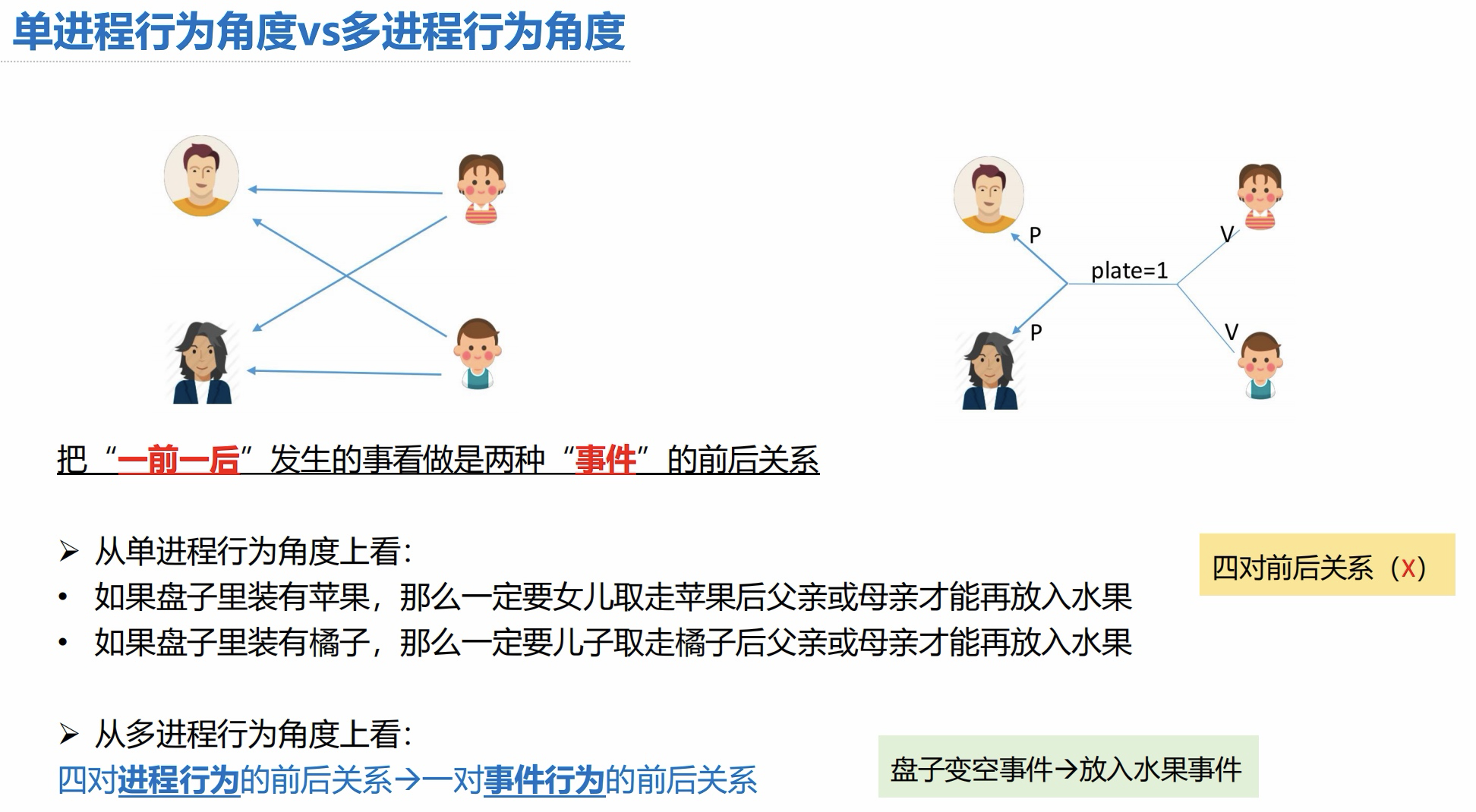
单进程行为角度 - 多进程行为角度:
多生产者-消费者 和 单生产者-消费者 编码其实非常类似,一定要类比进行学习
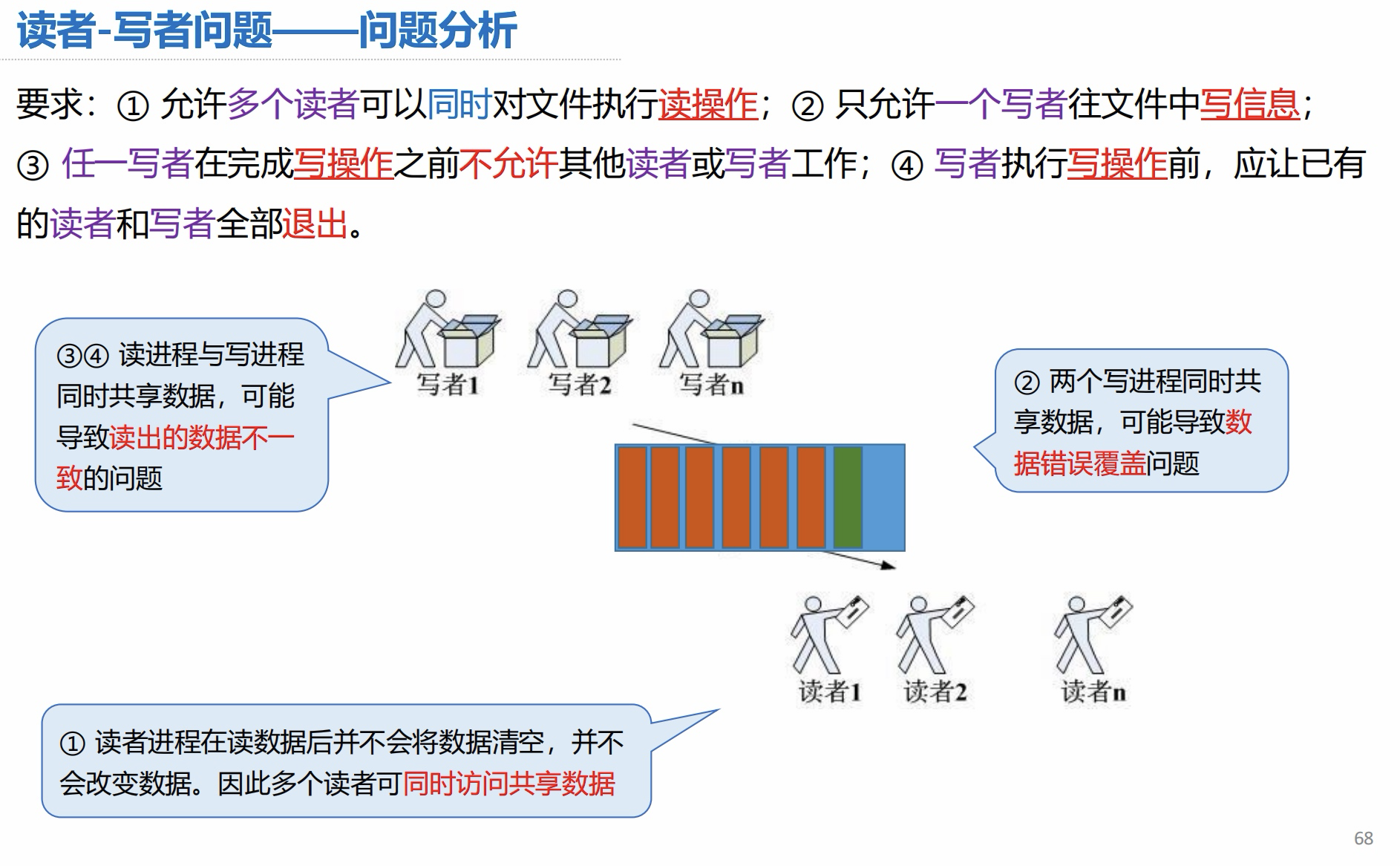
2.4 读者-写者问题
问题描述:

问题分析:
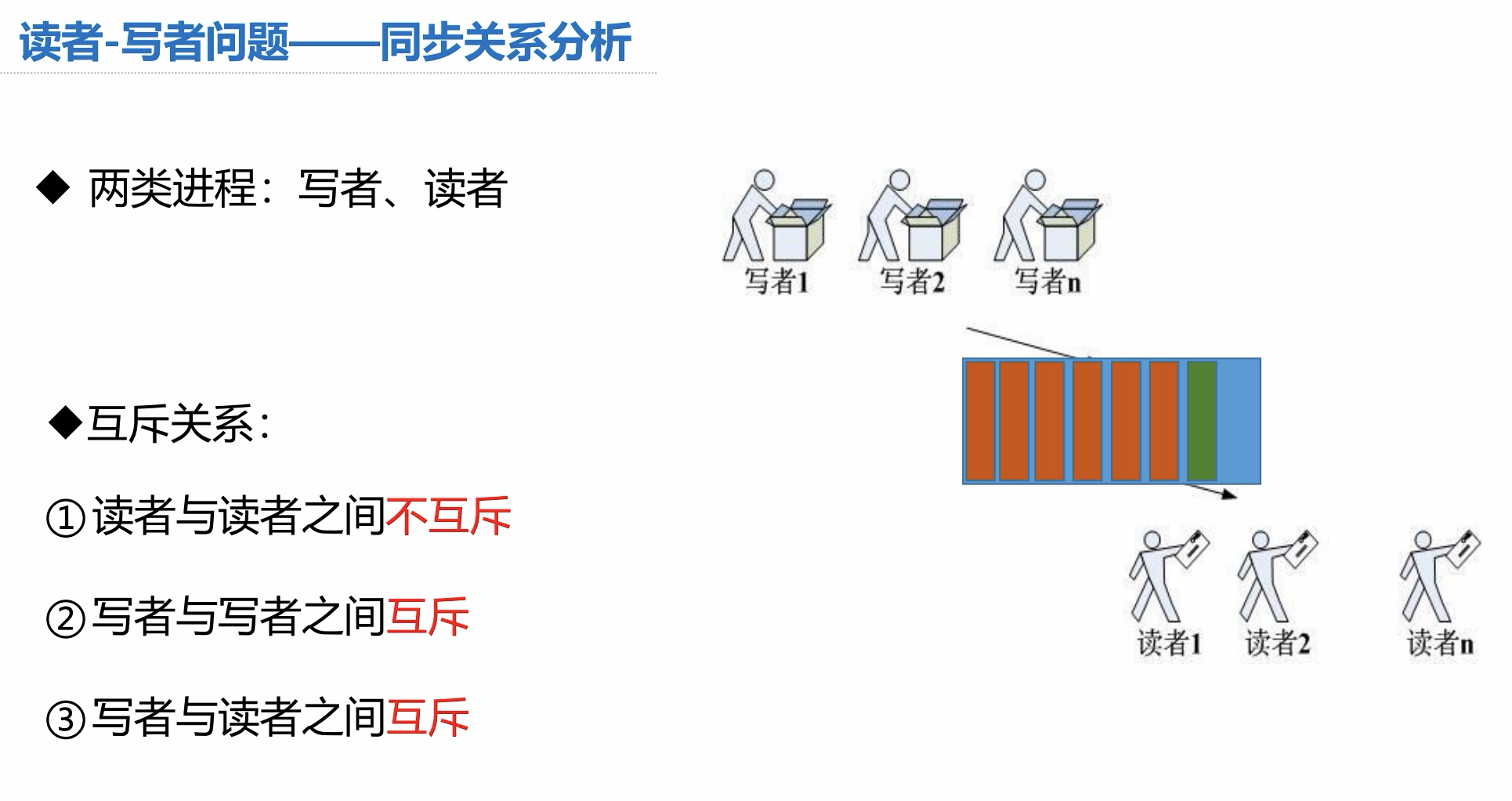
同步关系分析:
信号量设置:

同步关系实现:


这版比上一版添加了新的信号量
mutex,用于保护临界资源count,在多线程情况下count变量可能会被多个线程进行更改操作,所以要加信号量限制

这一版代码新增信号量
w,实现了写优先,上一版代码中,如果读者源源不断,那永远轮不到写者进行写入,所以此时添加一个信号量,让读者不会一直持有这个信号量,中途释放,如果此时有写者进入,那写者就会持有这个信号量,读者因为无法申请到w,从而读者的个数不会再增加,直到减少为 0,释放共享文件的锁,此时写者就可以获取,从而进行写入操作,实现了读写平衡。
2.5 类型题练习

答案:
semaphore empty1 = 1; //表示缓冲区1是否为空(能否放数据)
semaphore full1 = 0; //表示缓冲区1是否已满(是否有数据可取)
semaphore empty2 = 1; //表示缓冲区2是否为空
semaphore full2 = 0; //表示缓冲区2是否已满
// 进程 PA
void PA() {
while (TRUE) {
P(empty1); // 申请缓冲区1的空位
从磁盘读取一个记录写入缓冲区1;
V(full1); // 通知缓冲区1已满,有数据
}
}
// 进程 PB
void PB() {
while (TRUE) {
P(full1); // 等待缓冲区1有数据
P(empty2); // 申请缓冲区2的空位
将缓冲区1的内容复制到缓冲区2;
V(empty1); // 释放缓冲区1
V(full2); // 通知缓冲区2已满,有数据
}
}
// 进程 PC
void PC() {
while (TRUE) {
P(full2); // 等待缓冲区2有数据
将缓冲区2的内容打印出来;
V(empty2); // 释放缓冲区2
}
}
在此题中明确有两个缓冲区 缓冲区1、缓冲区2,分析出三个进程之间为同步关系,所以无需设计维持缓冲区互斥的锁,仅需设置标志缓冲区资源状态的信号量即可。

semaphore bridge = 1; // 桥的互斥锁
semaphore mutexA = 1; // 保护A方人数计数
semaphore mutexB = 1; // 保护B方人数计数
int countA = 0; // A方当前桥上人数
int countB = 0; // B方当前桥上人数
// A方向行人过桥进程
void A_Side() {
P(mutexA);
if (countA == 0) {
P(bridge); // A方第一个人上桥,锁住桥,阻止B方进入
}
countA++;
V(mutexA);
过桥; // 执行过桥动作
P(mutexA);
countA--;
if (countA == 0) {
V(bridge); // A方最后一个人下桥,释放桥,允许B方进入
}
V(mutexA);
}
// B方向行人过桥进程
void B_Side() {
P(mutexB);
if (countB == 0) {
P(bridge); // B方第一个人上桥,锁住桥,阻止A方进入
}
countB++;
V(mutexB);
过桥; // 执行过桥动作
P(mutexB);
countB--;
if (countB == 0) {
V(bridge); // B方最后一个人下桥,释放桥
}
V(mutexB);
}
3. 银行家问题
银行家问题前言:
什么是安全状态

- 只要找出一个序列,系统就处于安全状态,如果一个也找不出来,就处于不安全状态
- 安全序列可以存在多个
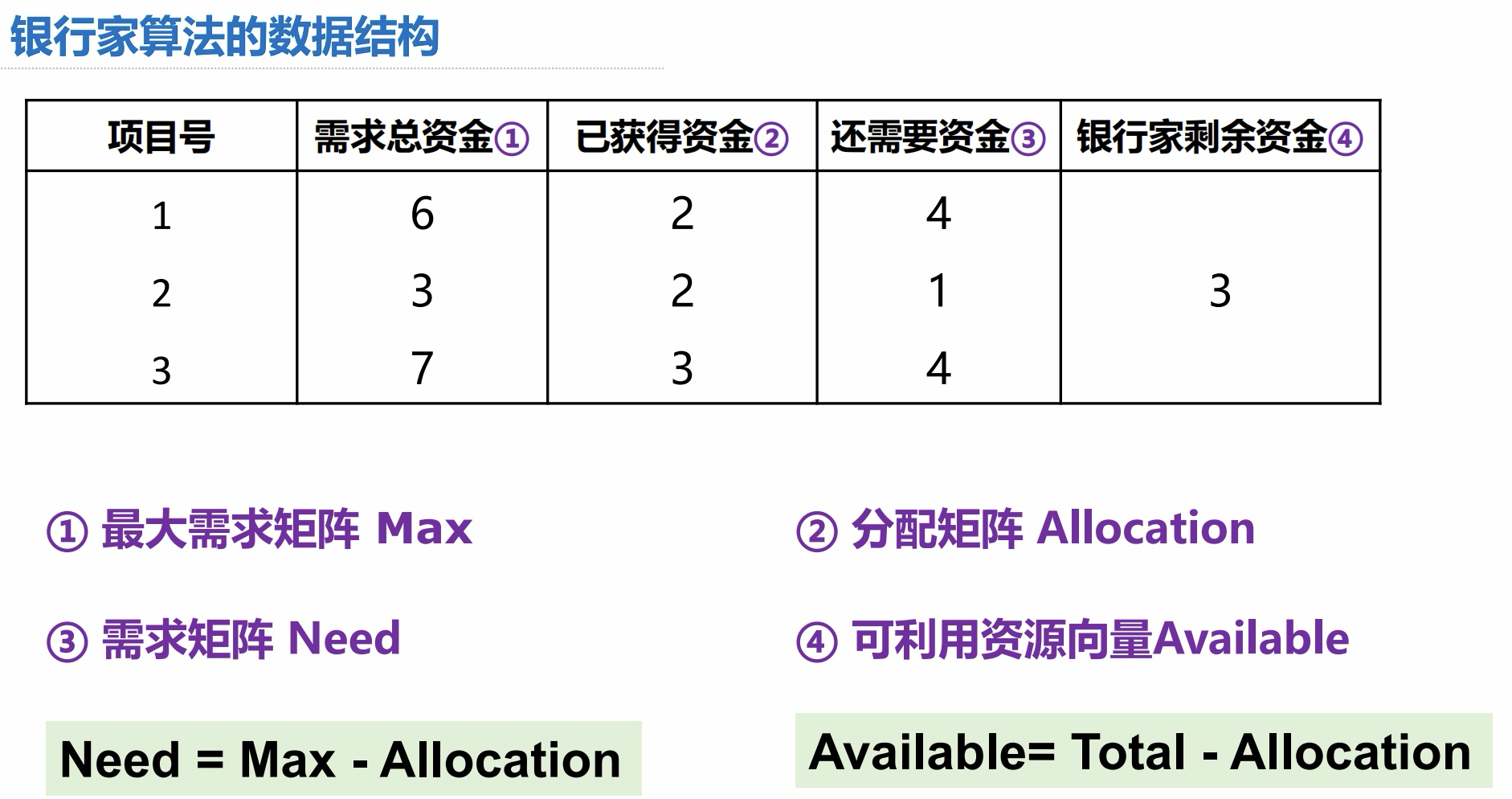
3.1 银行家算法

银行家算法的数据结构
练习例题:
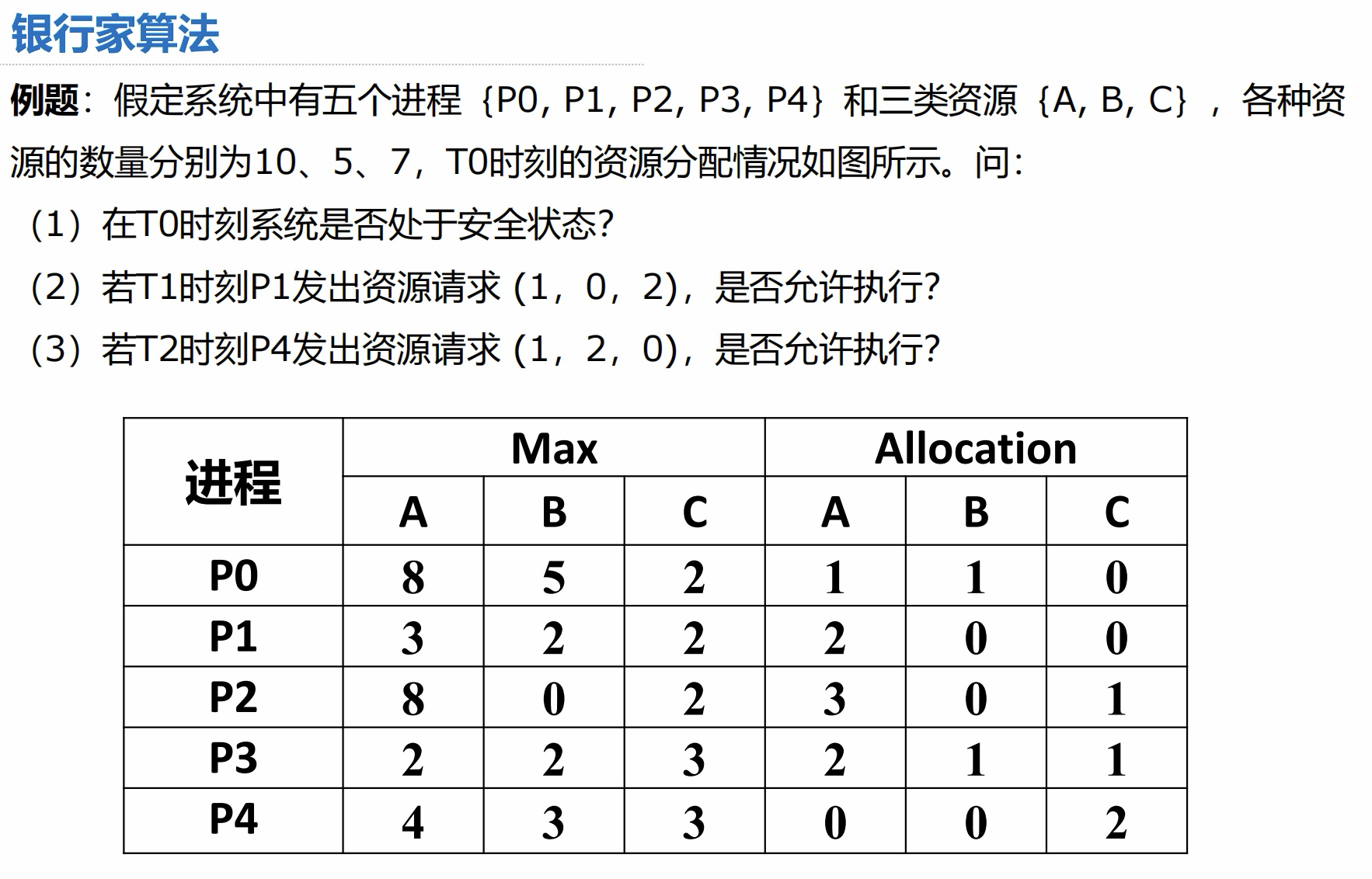
(1)答案
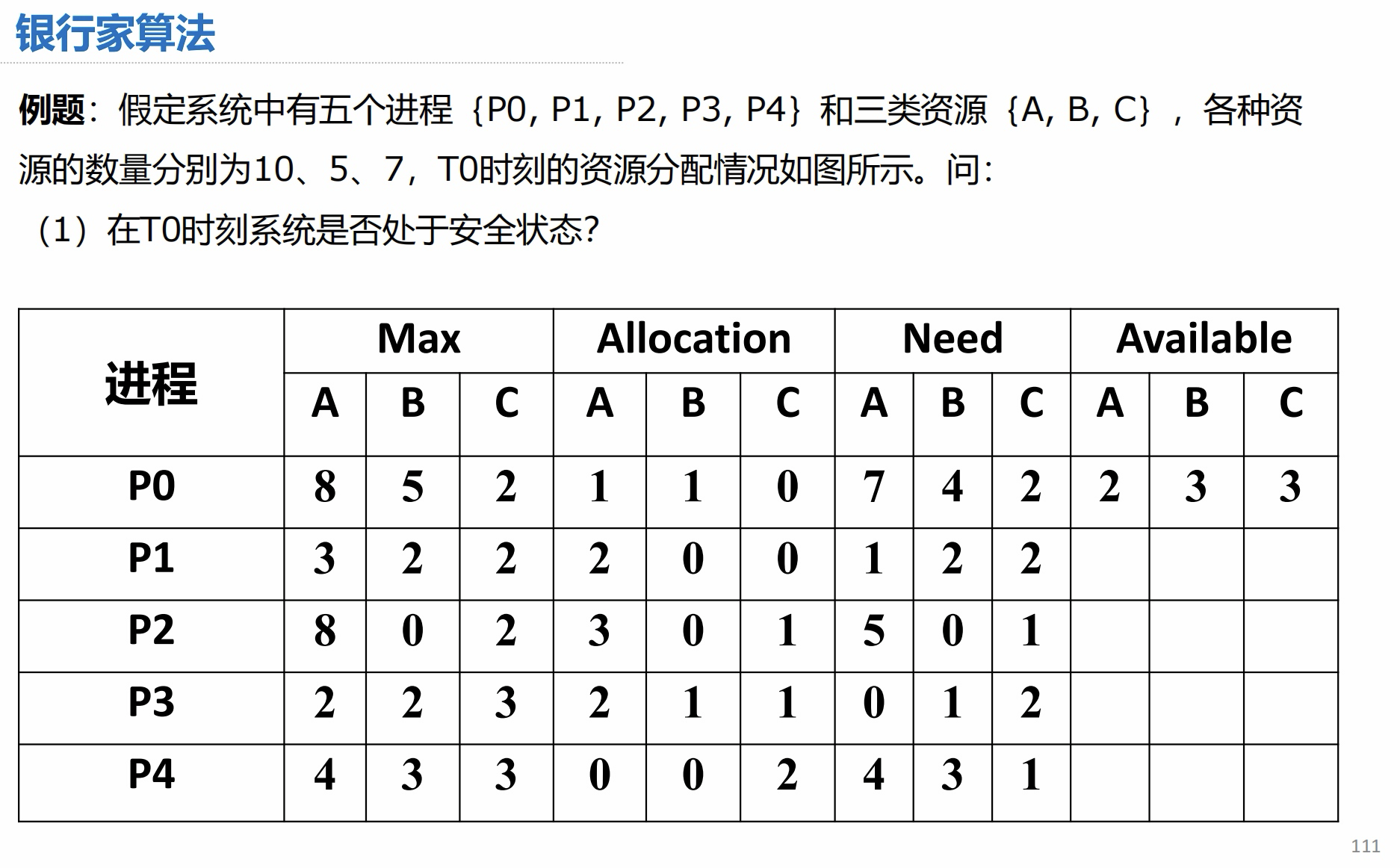

我在看这道题时提出了一个问题,可用资源为什么是(2, 3, 3):

(2)答案:
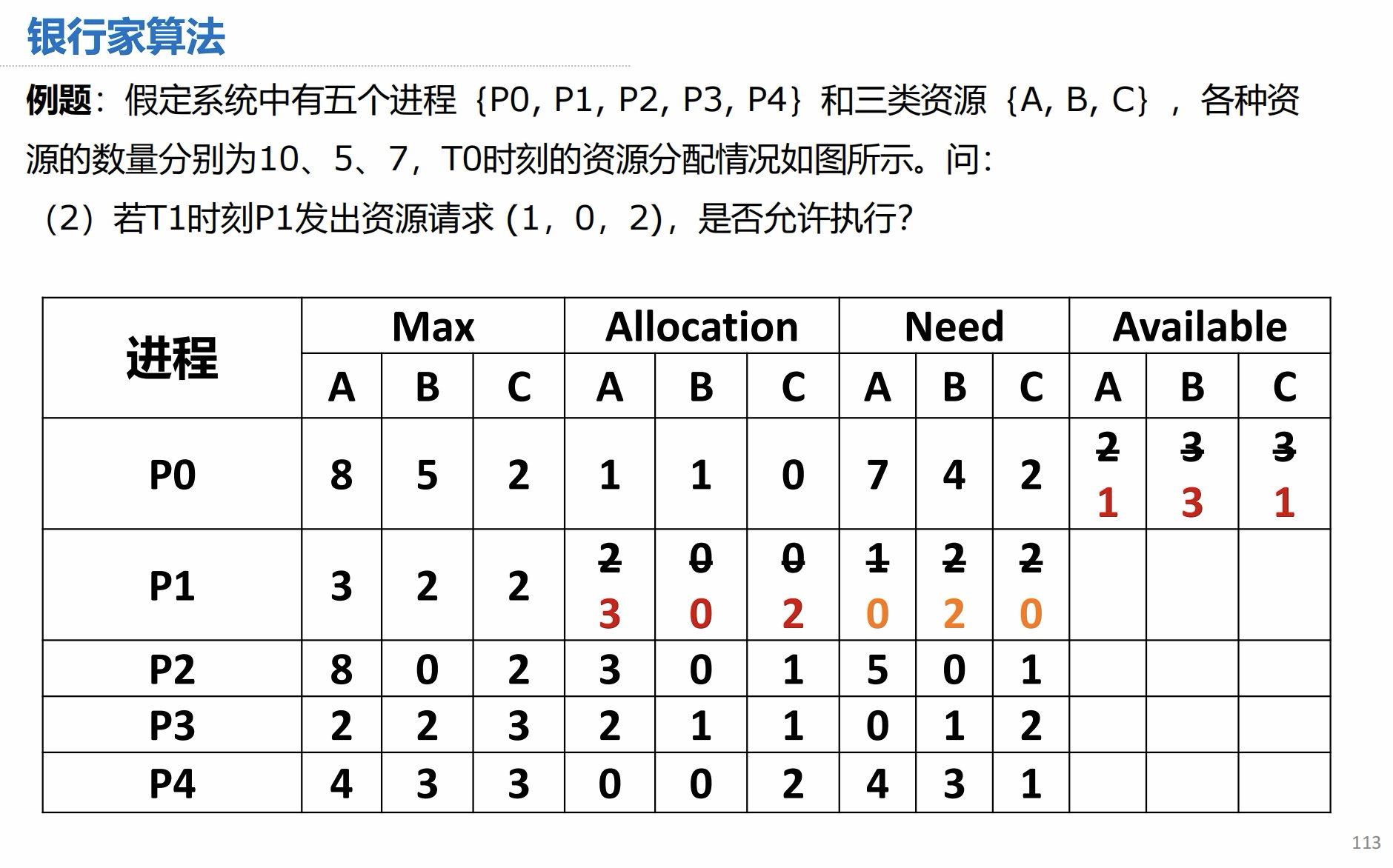

(3)答案:
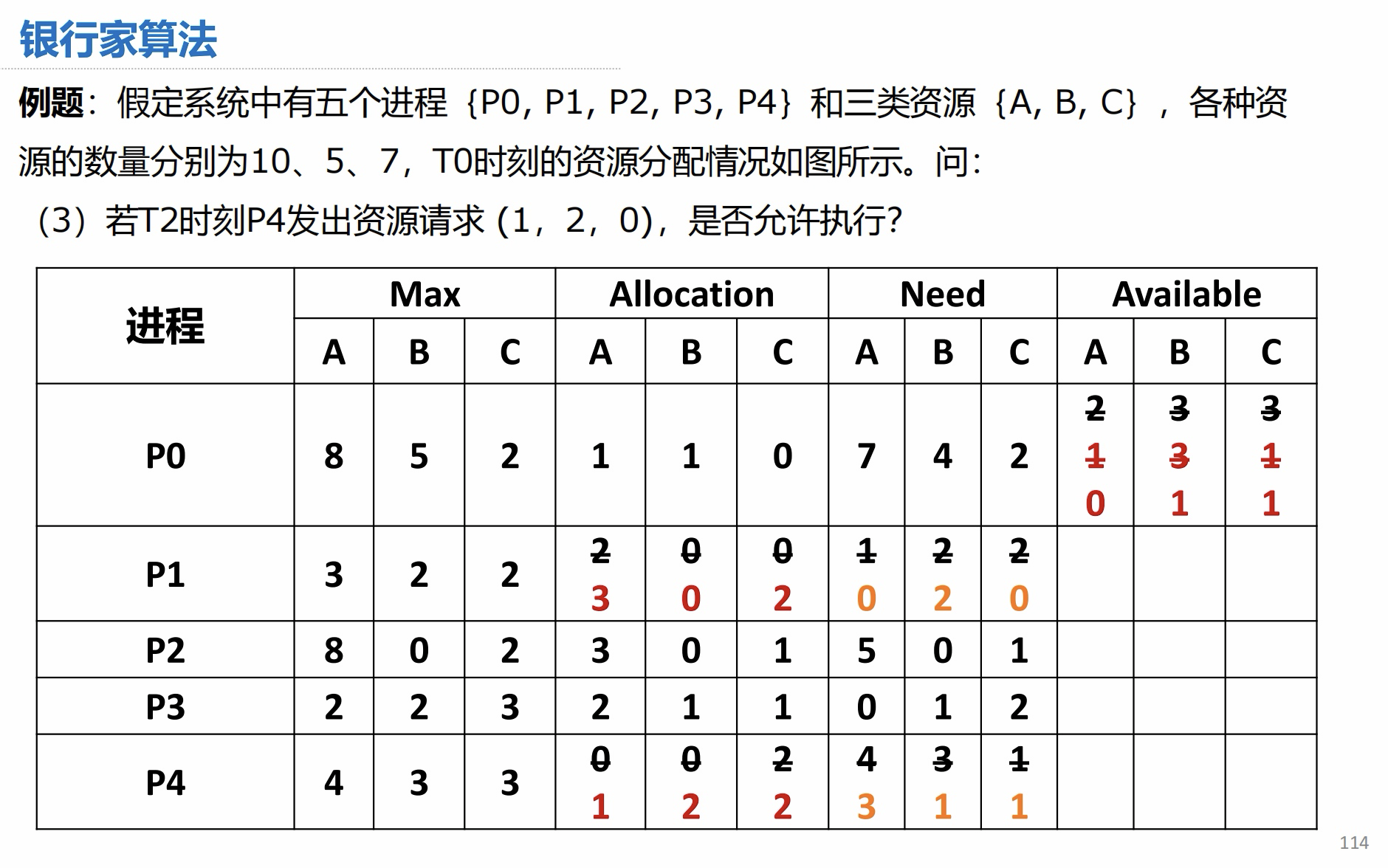
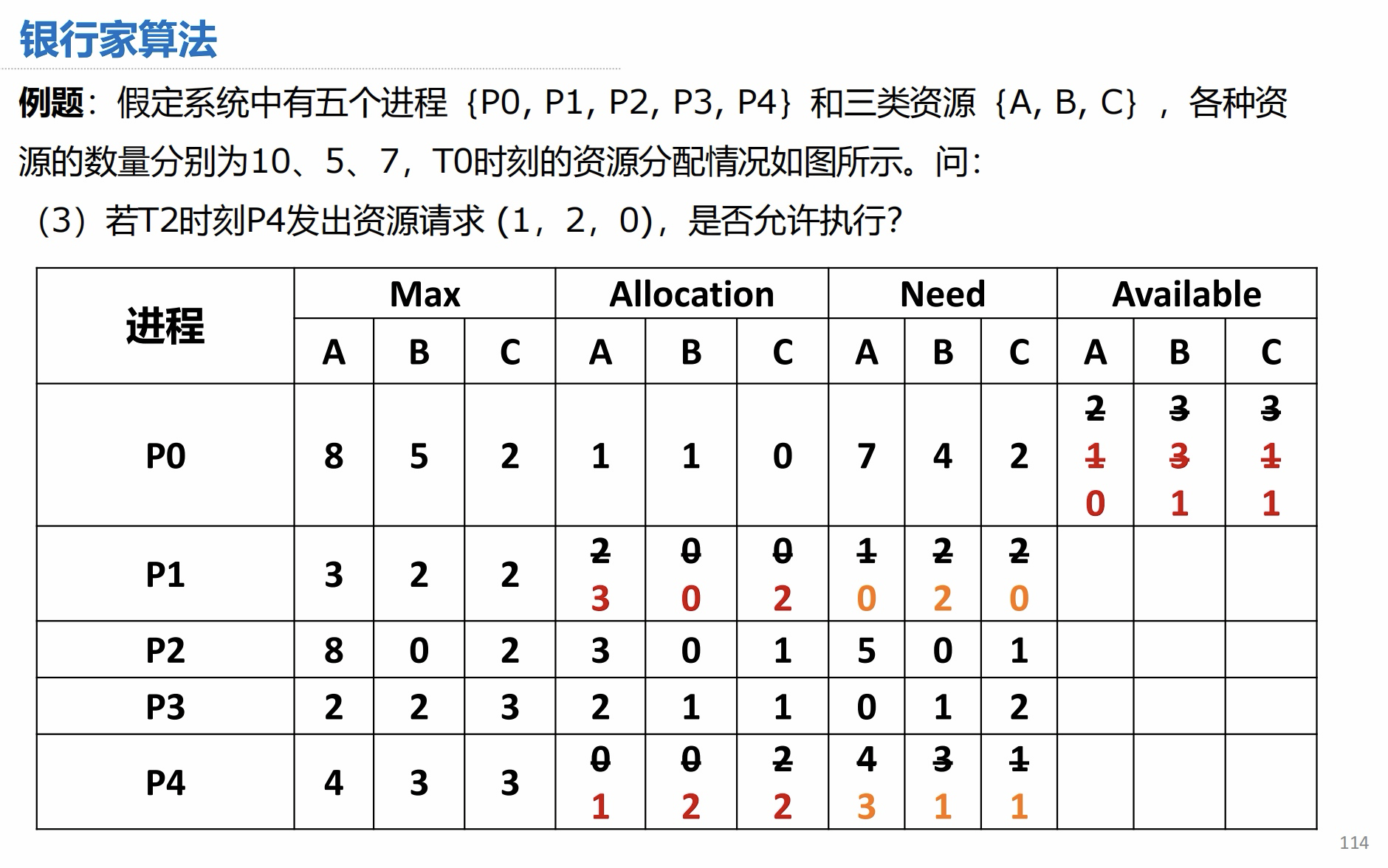
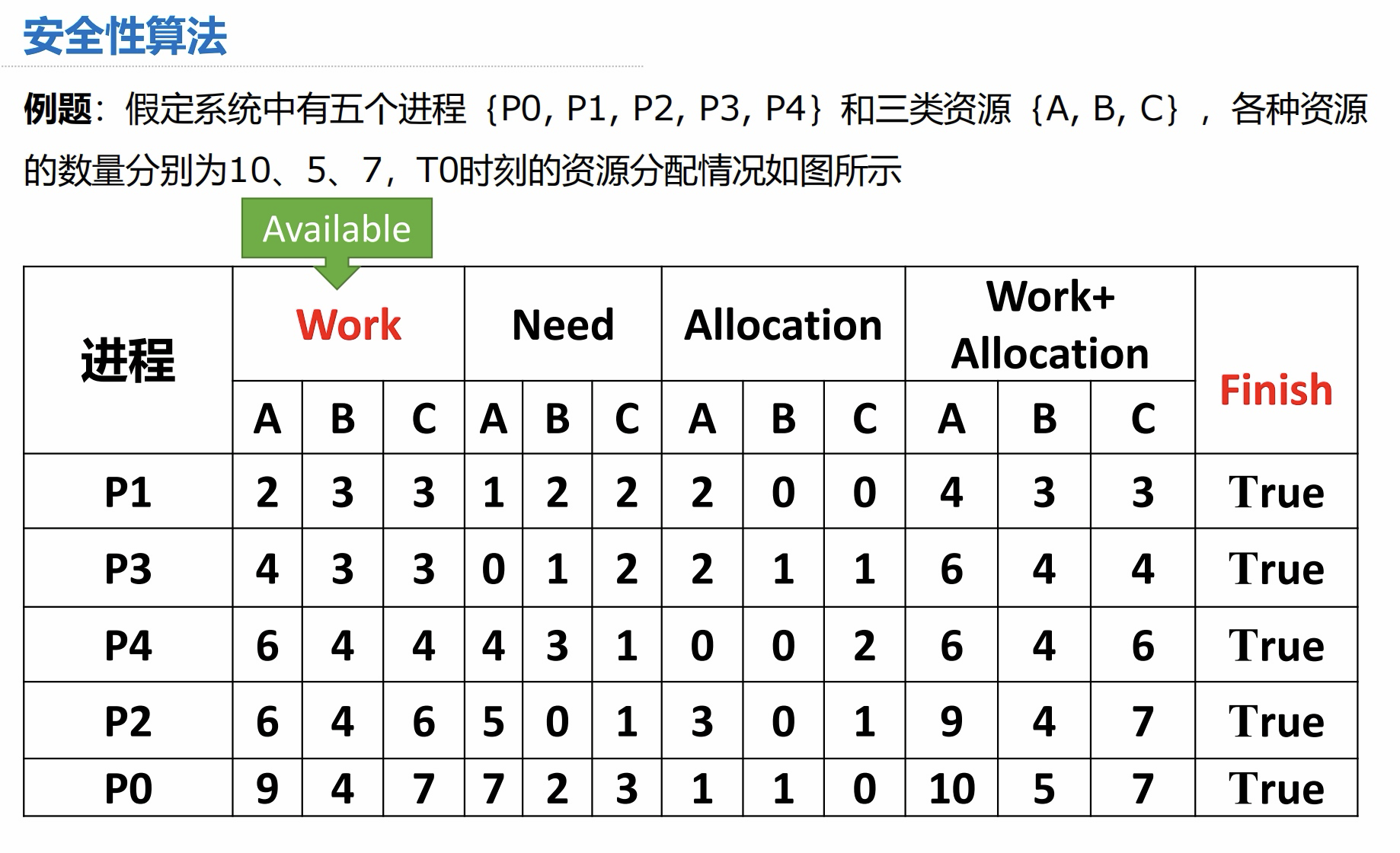
3.2 安全性算法


例题:
3.3 资源分配图
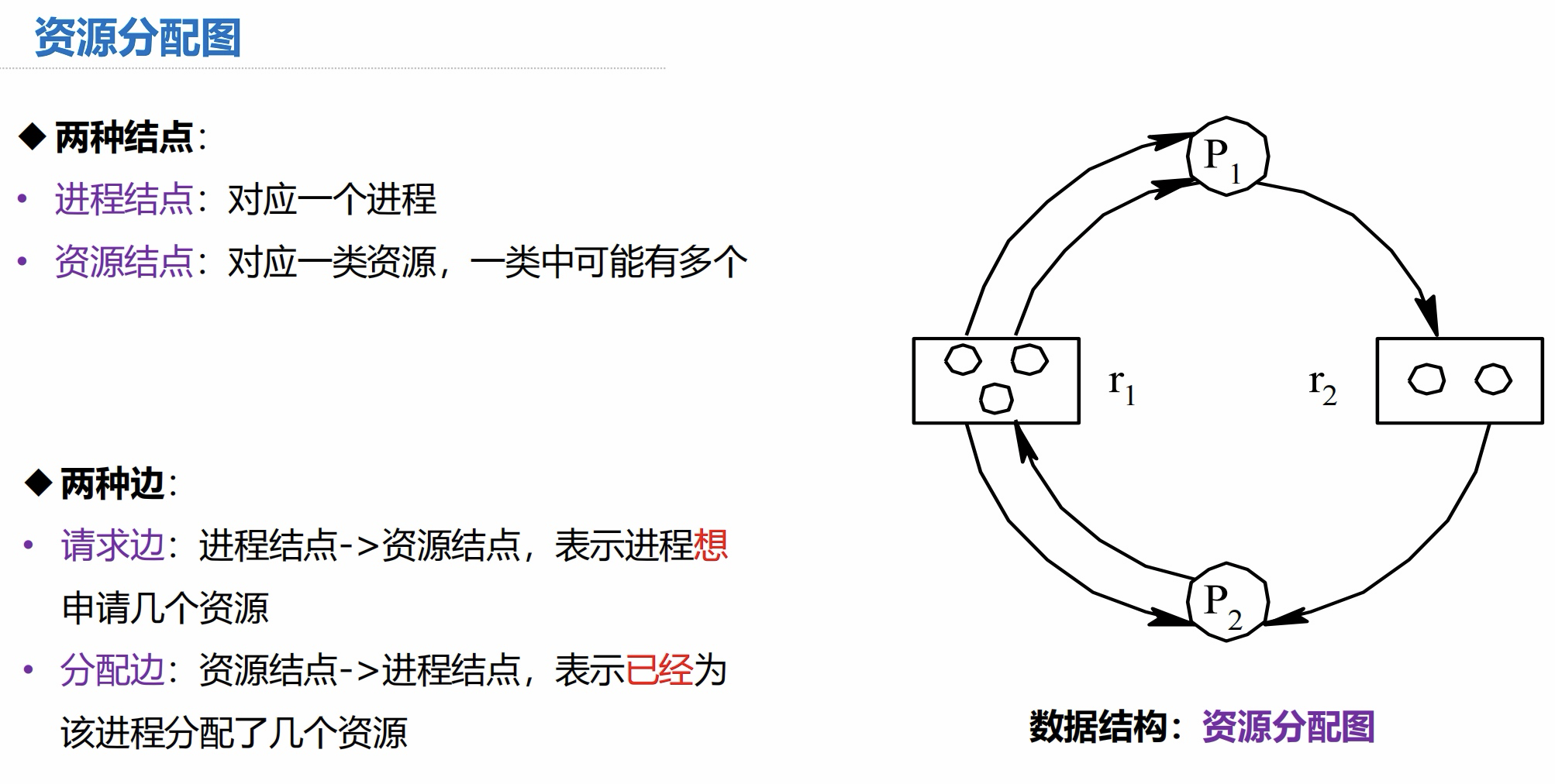
在图中矩形节点为资源节点,其中有几个圈,代表资源有几个实例(有几份)。
P1、P2 为进程节点
资源分配图的化简
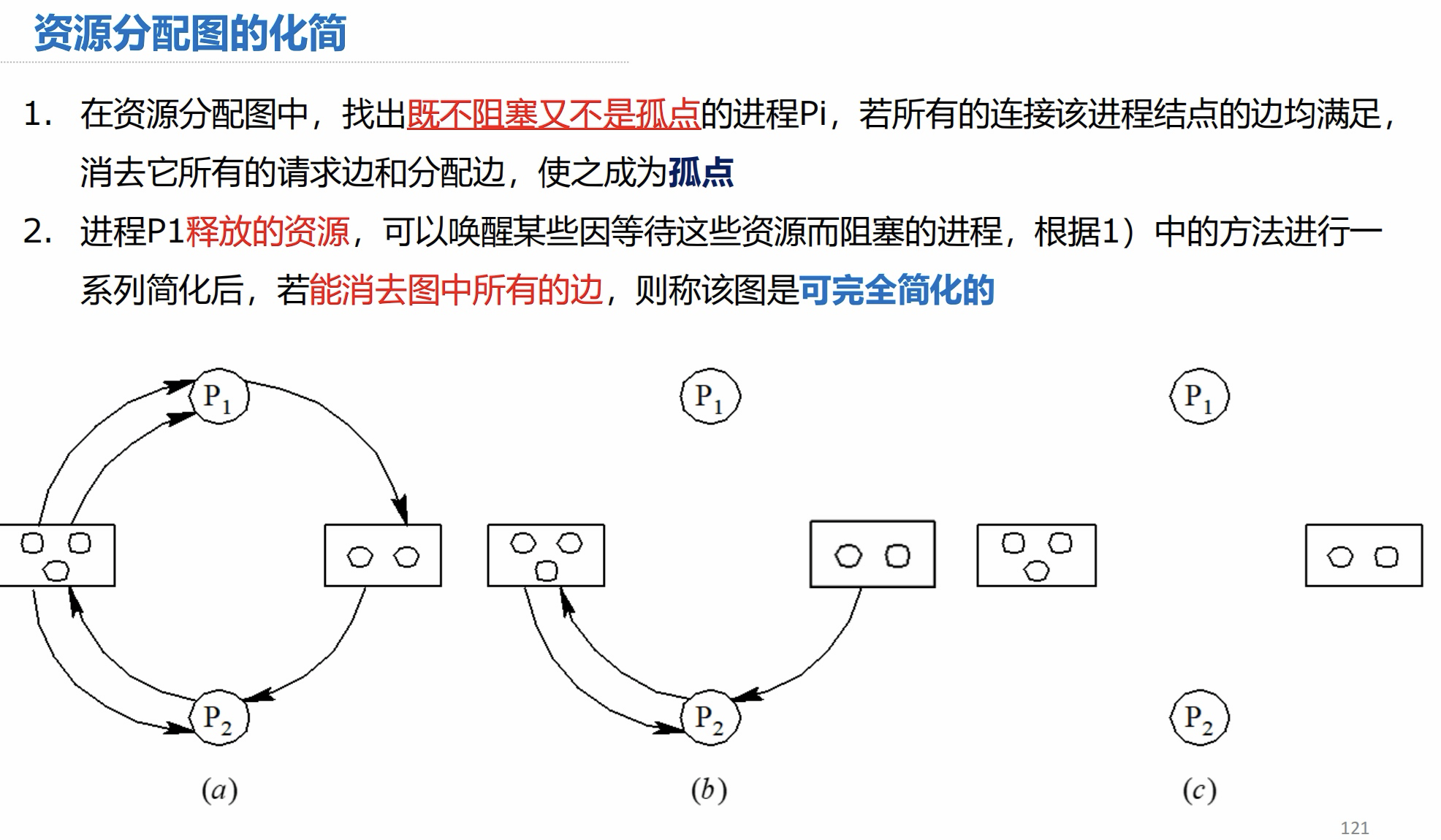
将左边的资源节点命名成 r1,右边的资源节点命名成 r2。
先对图进行分析:
P1 节点被分配两个 r1 实例,此时它向 r2 请求一个示例
P2 节点被分配一个 r1 实例,一个 r2 实例,此时它向 r1 请求一个示例
现在显然 P2 的请求是无法被满足的,因为 r1 的实例已经被分配完了,没有空闲实例,所以它被阻塞在 r1 节点处。
P1 的请求是显然可以满足的,r2 此时空闲的实例为 1,可以分配给 P1进程,在 P1 进程运行完后,会返还它所占用的资源,返还 r1 的两个示例后,便可以唤醒 P2 进程,分配资源。
这样便消去图中所有的边,此图便是可完全化简的,系统是安全的。
4. 分区分配算法
4.1 前置知识
可变分区分配:

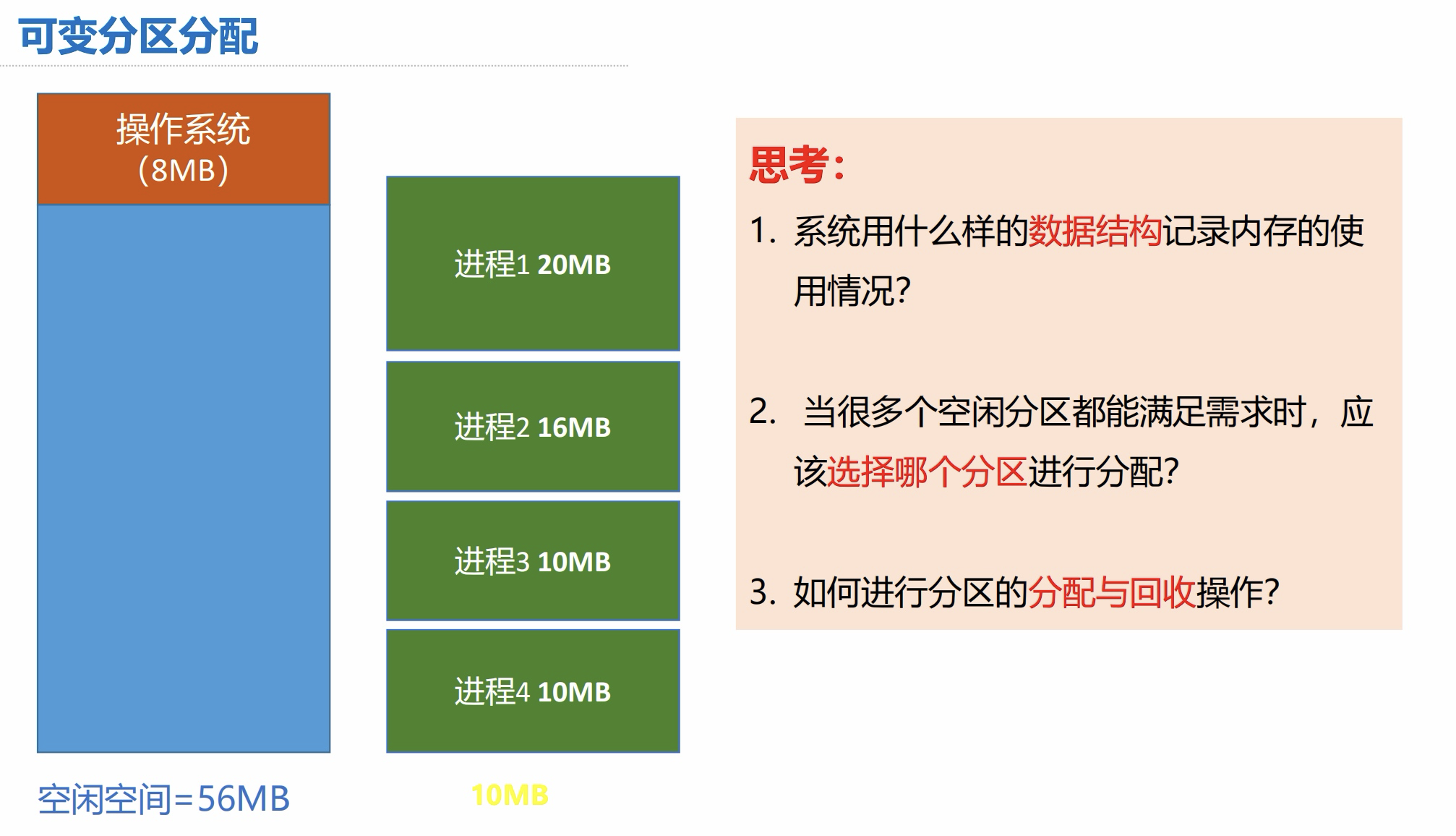
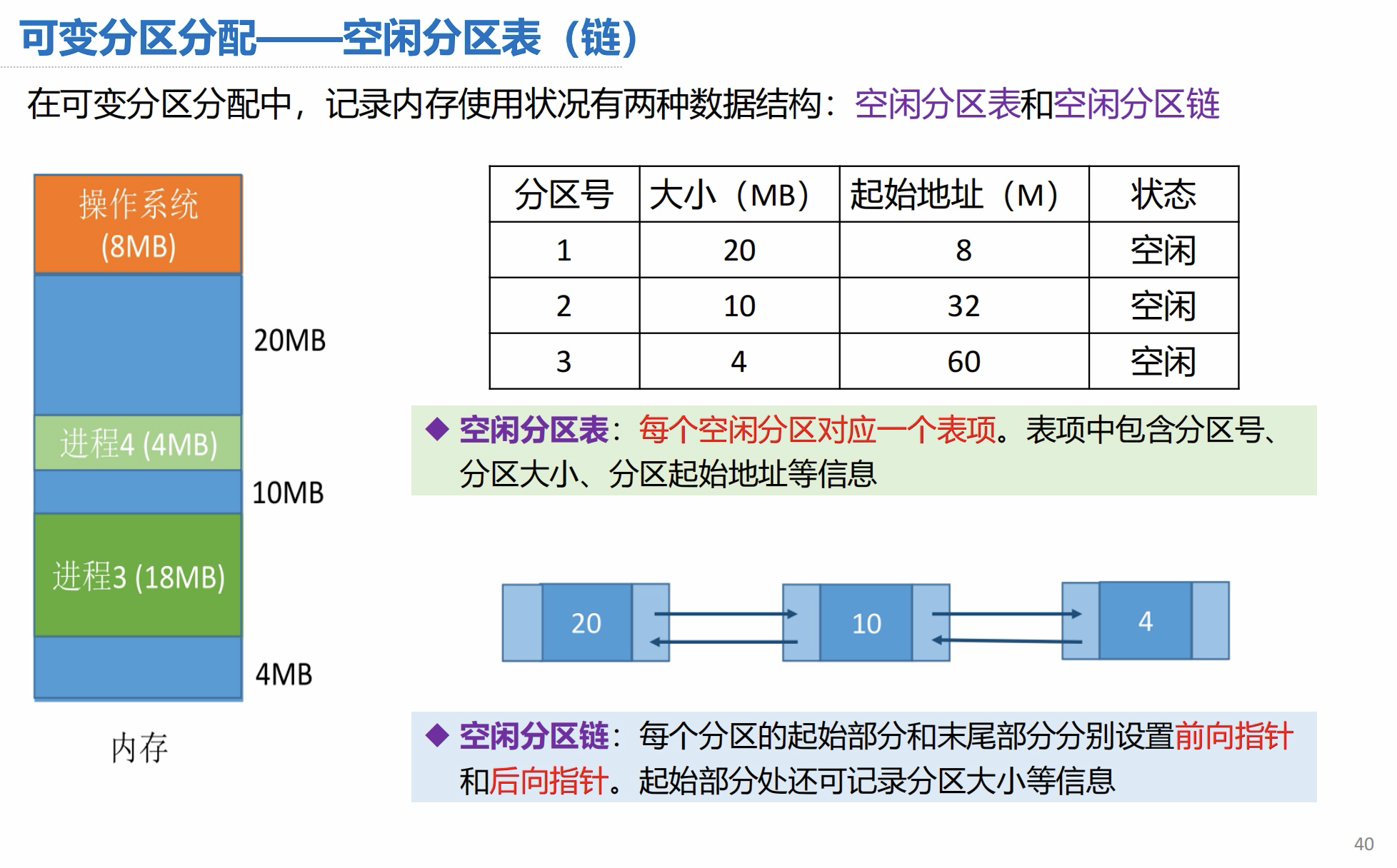
可变分区分配 - 空闲分区链
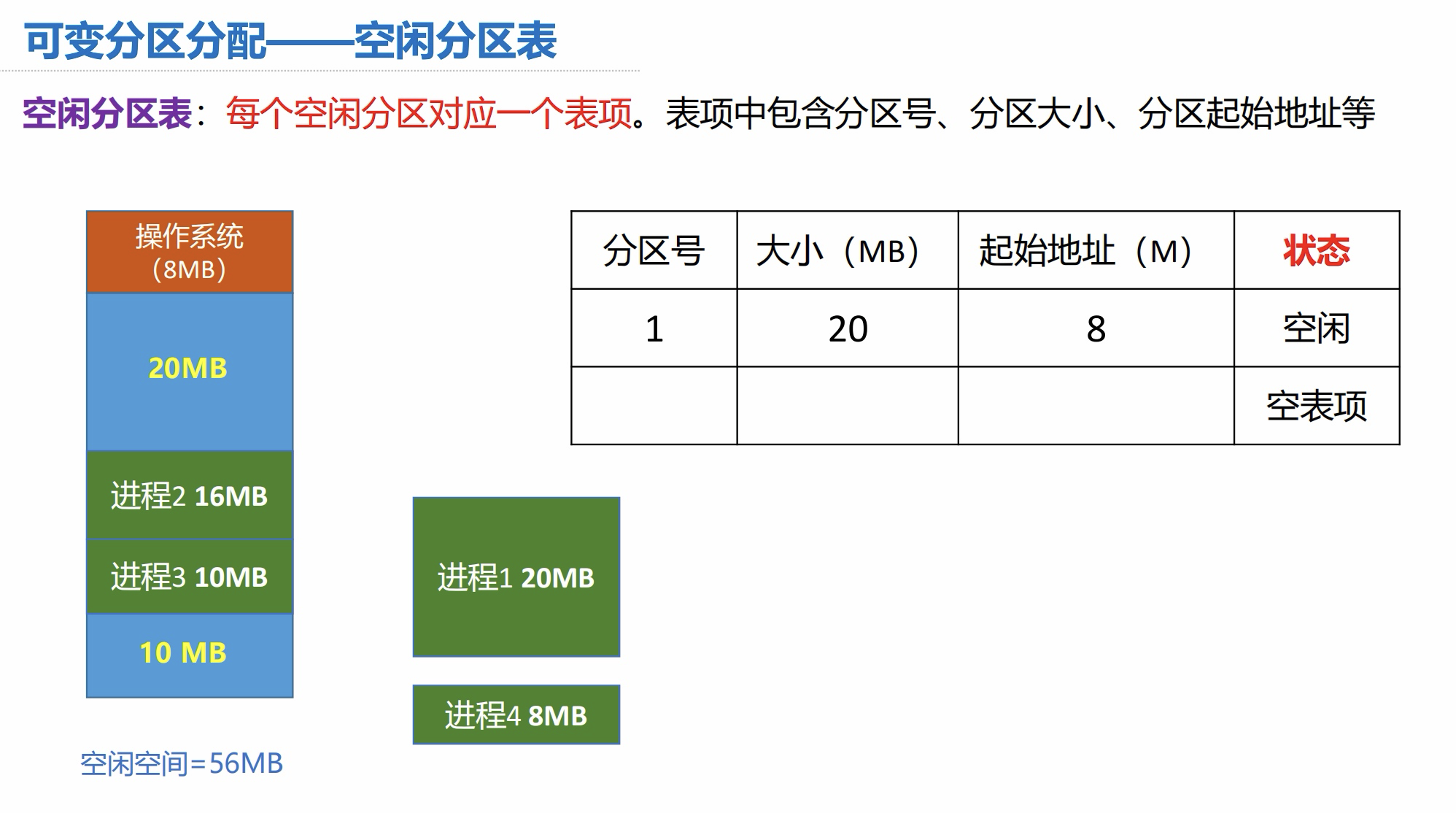
可变分区分配:空闲分区表
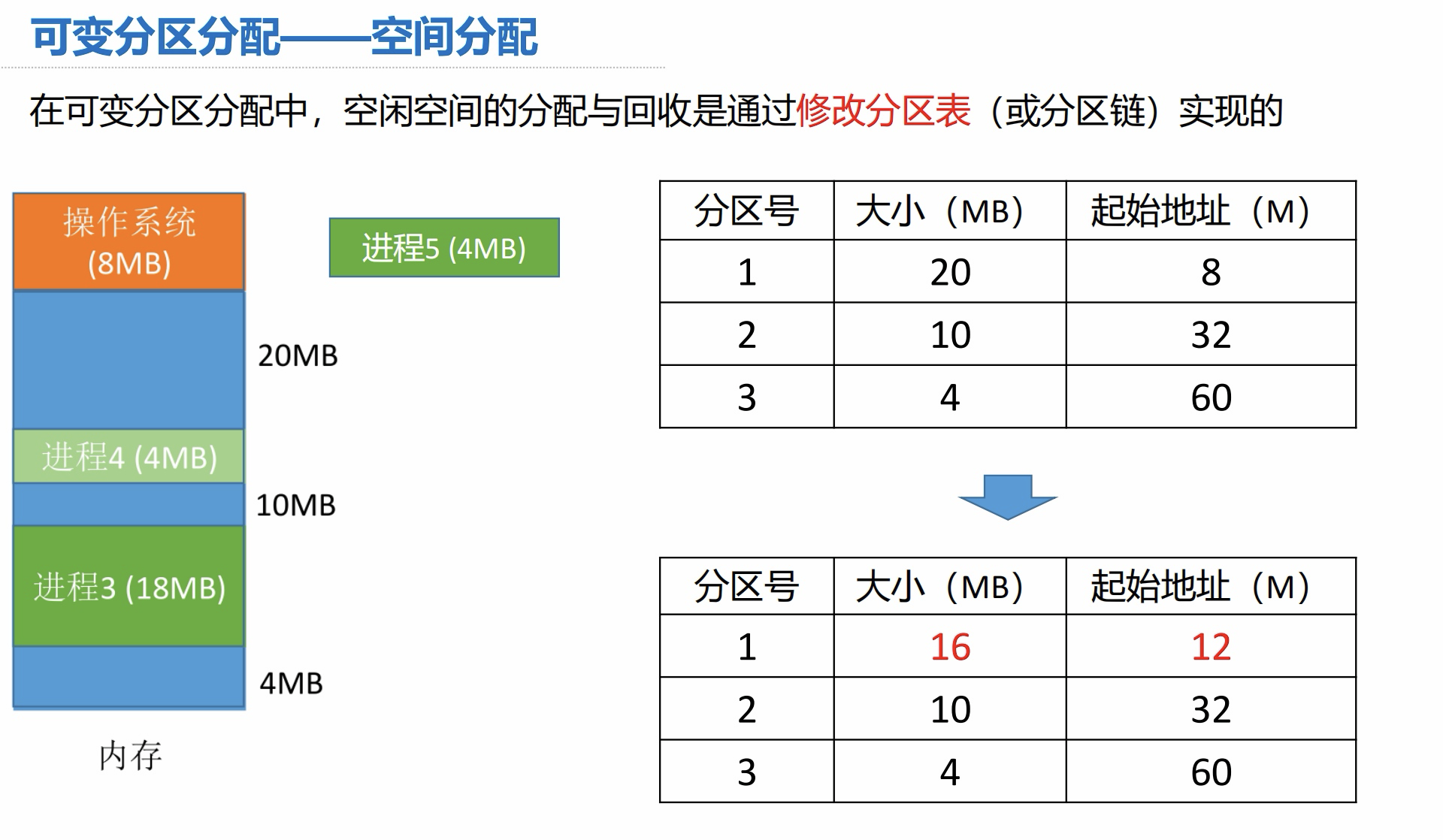
可变分区分配 - 空间分配
可变分区分类 - 空间回收

关于空间回收,PPT 还有很多页内容举出了示例方便理解。具体翻看老师的课件,我不再呈现
4.2 首次适应算法
算法思想:
- 从低地址开始查找,找到第一个能满足大小的空闲分区
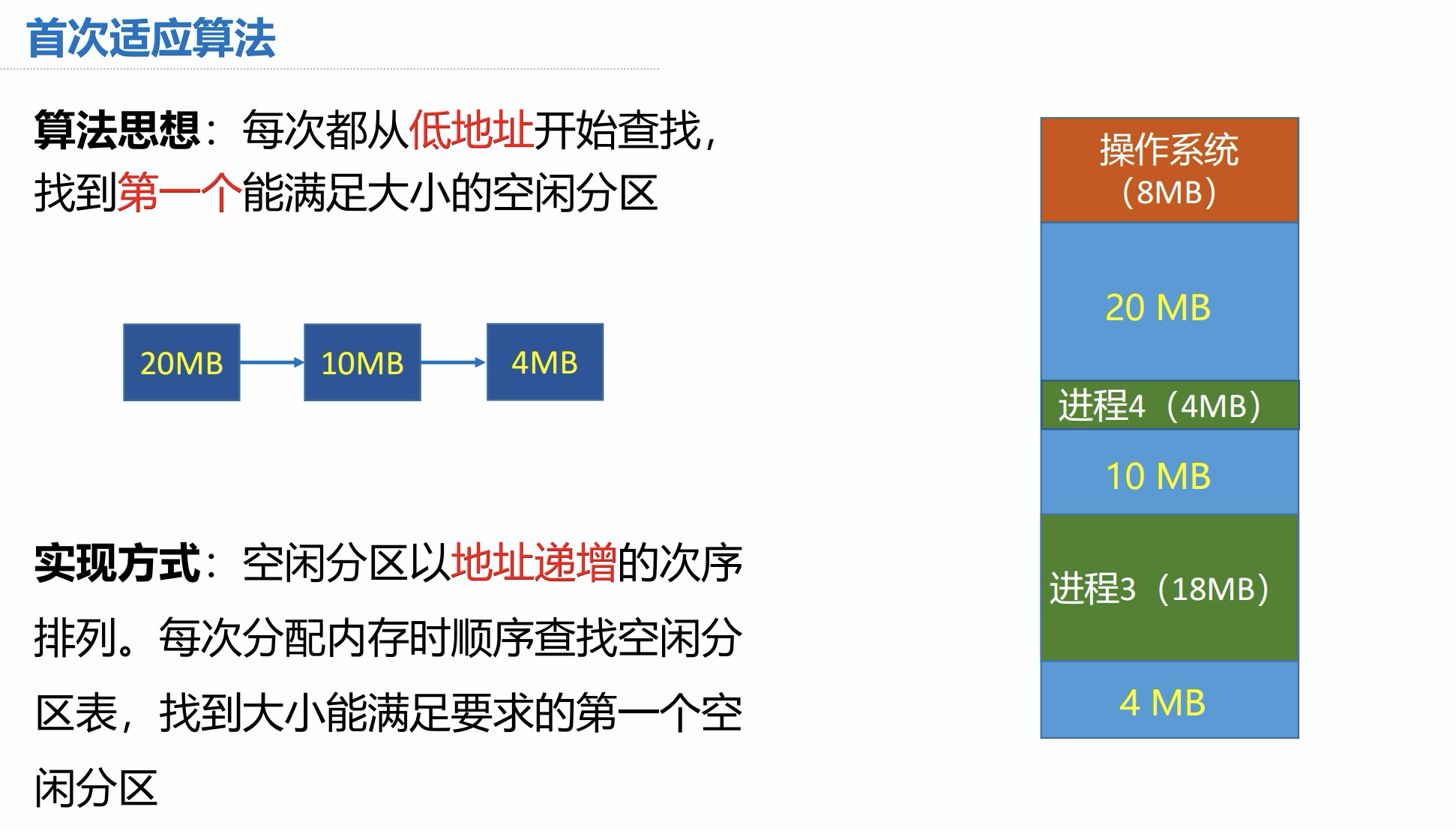
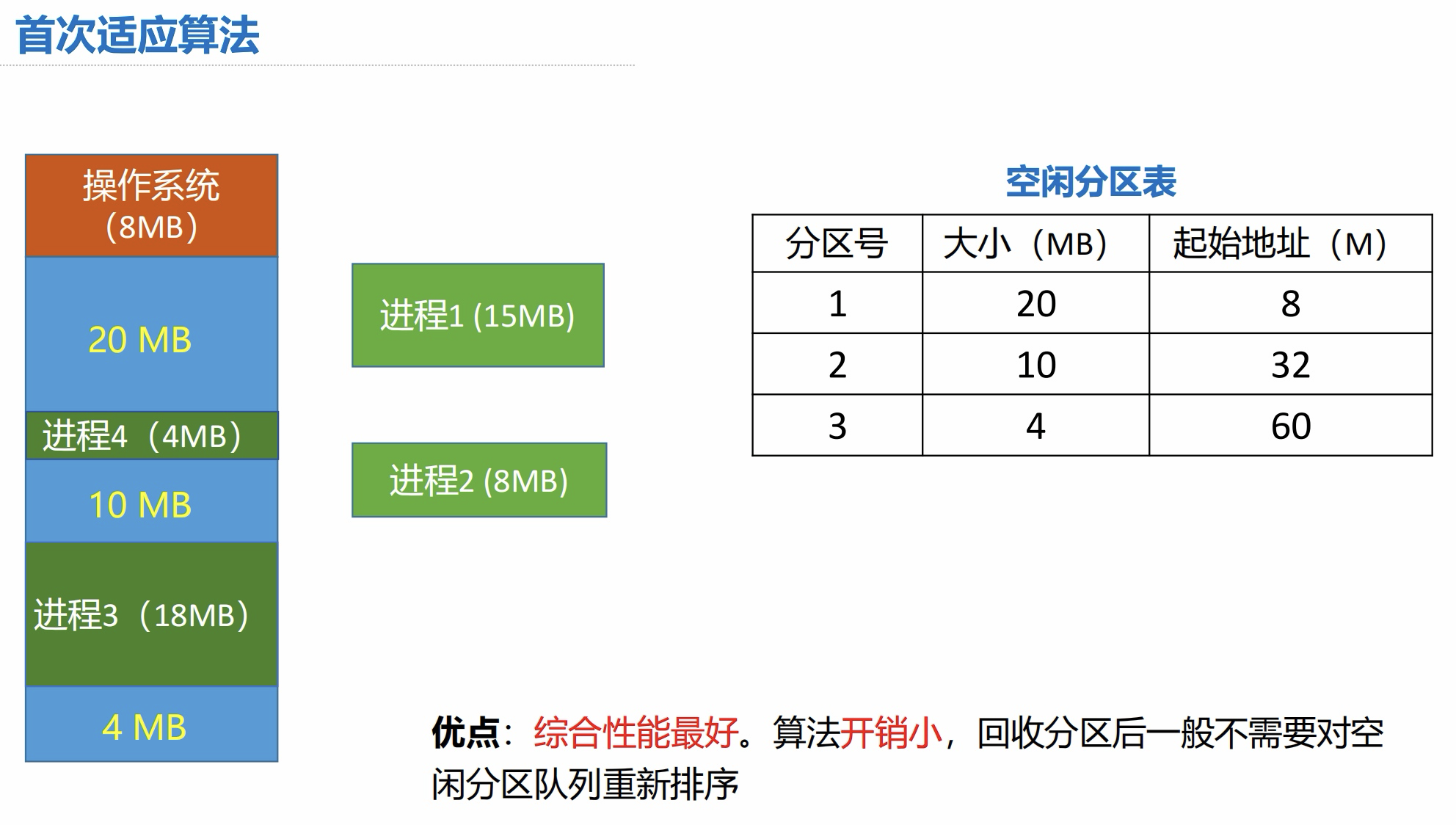
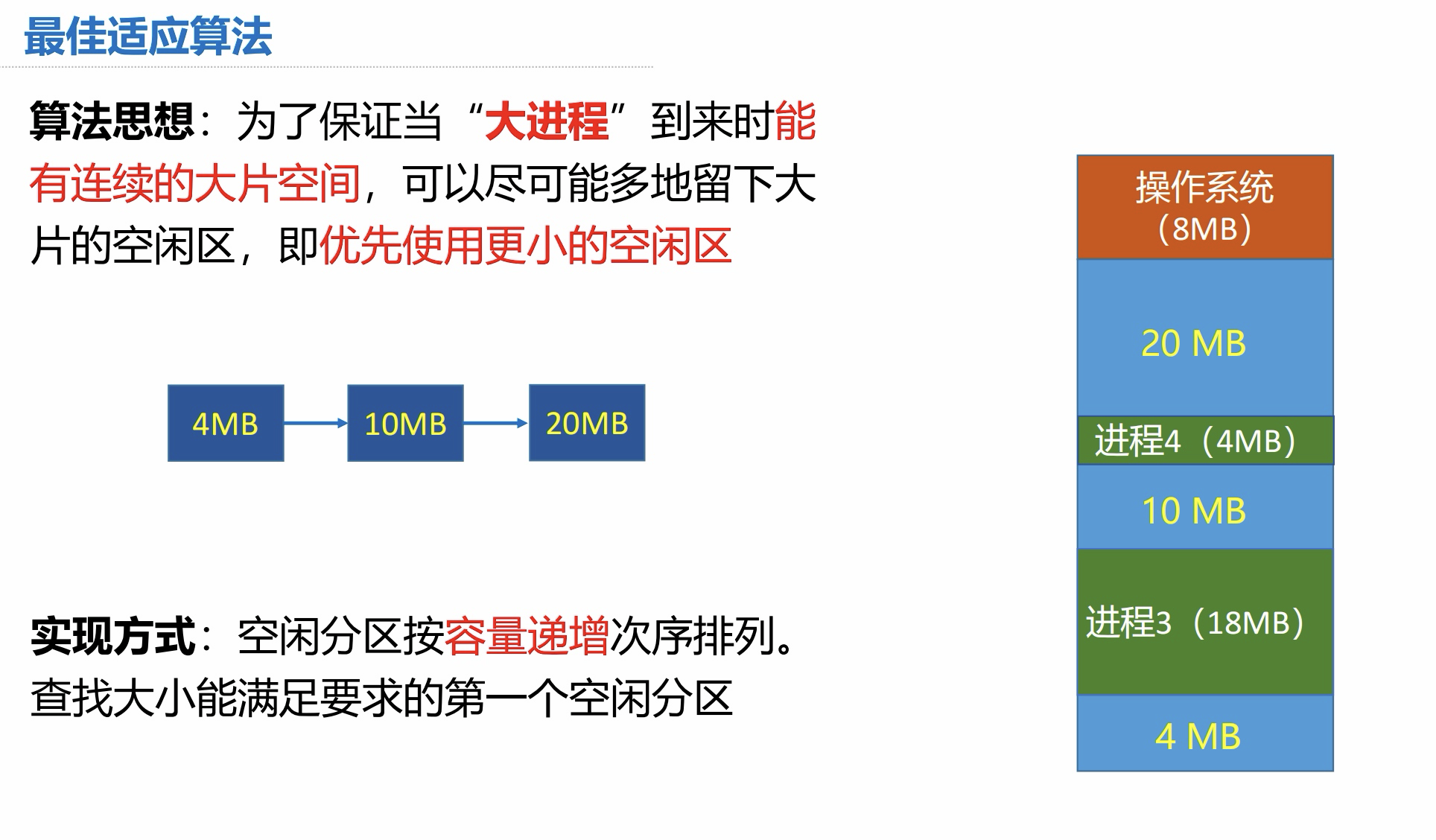
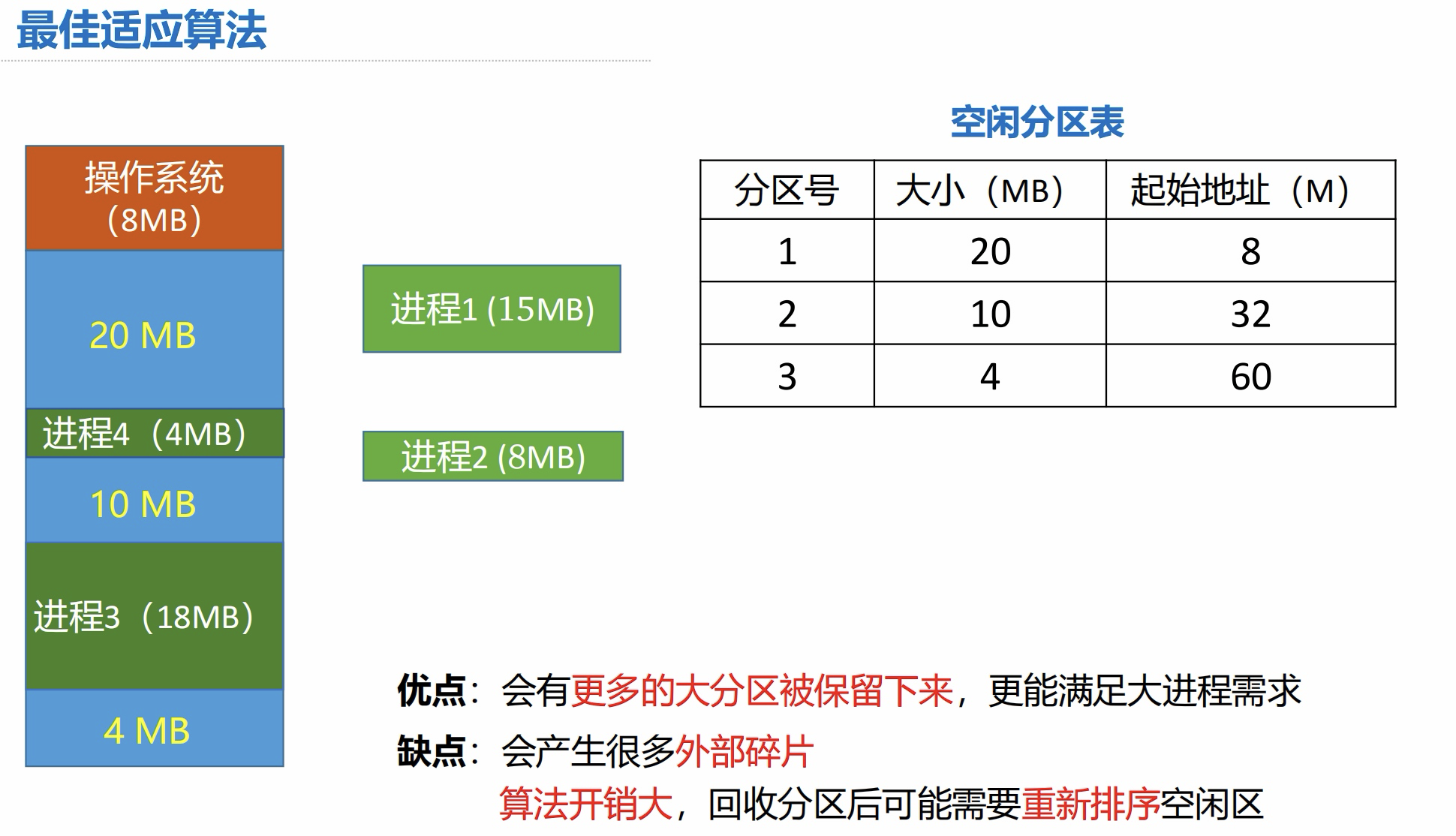
4.3 最佳适应算法
算法思想:
-
优先使用更小的空闲区
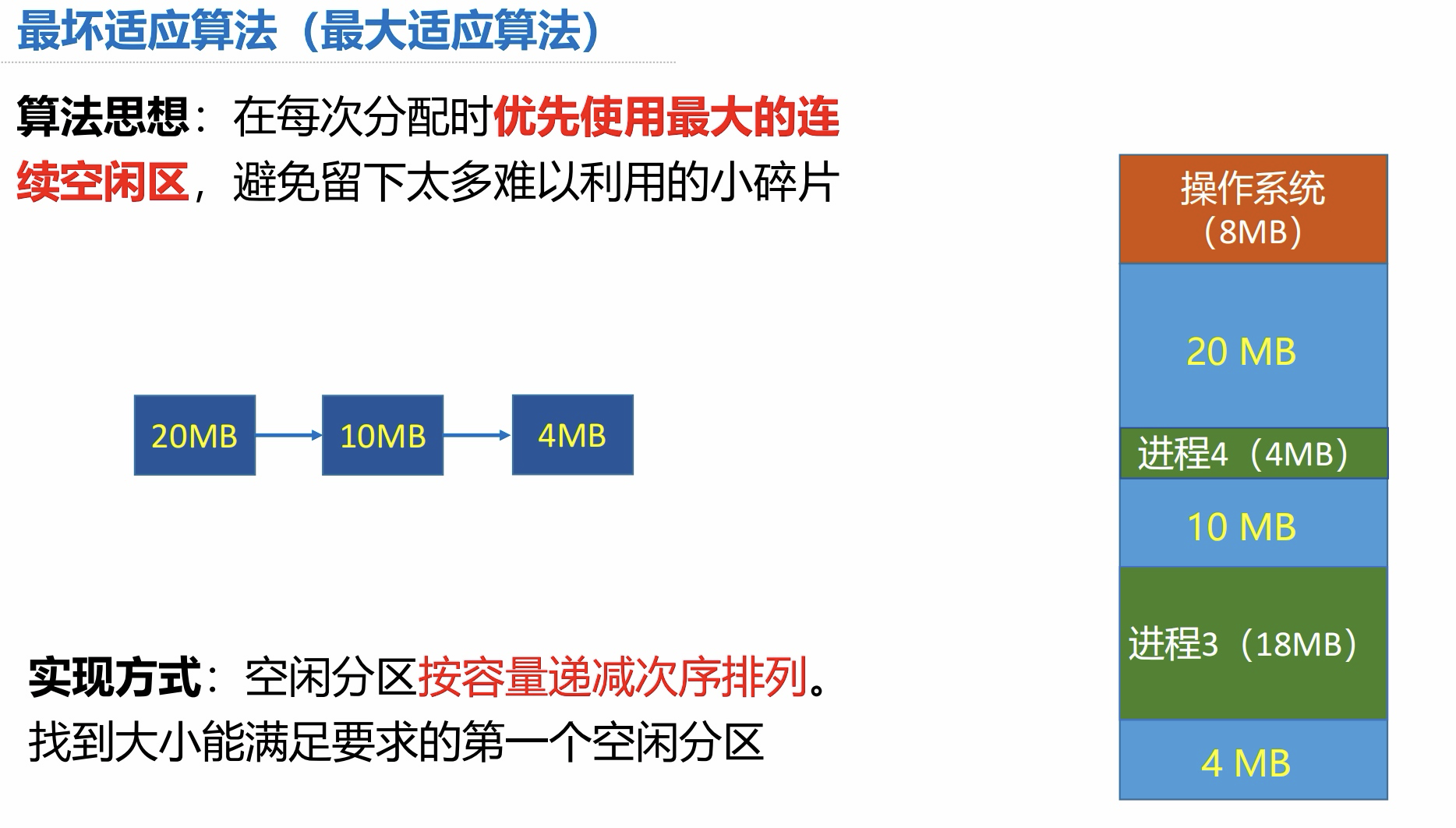
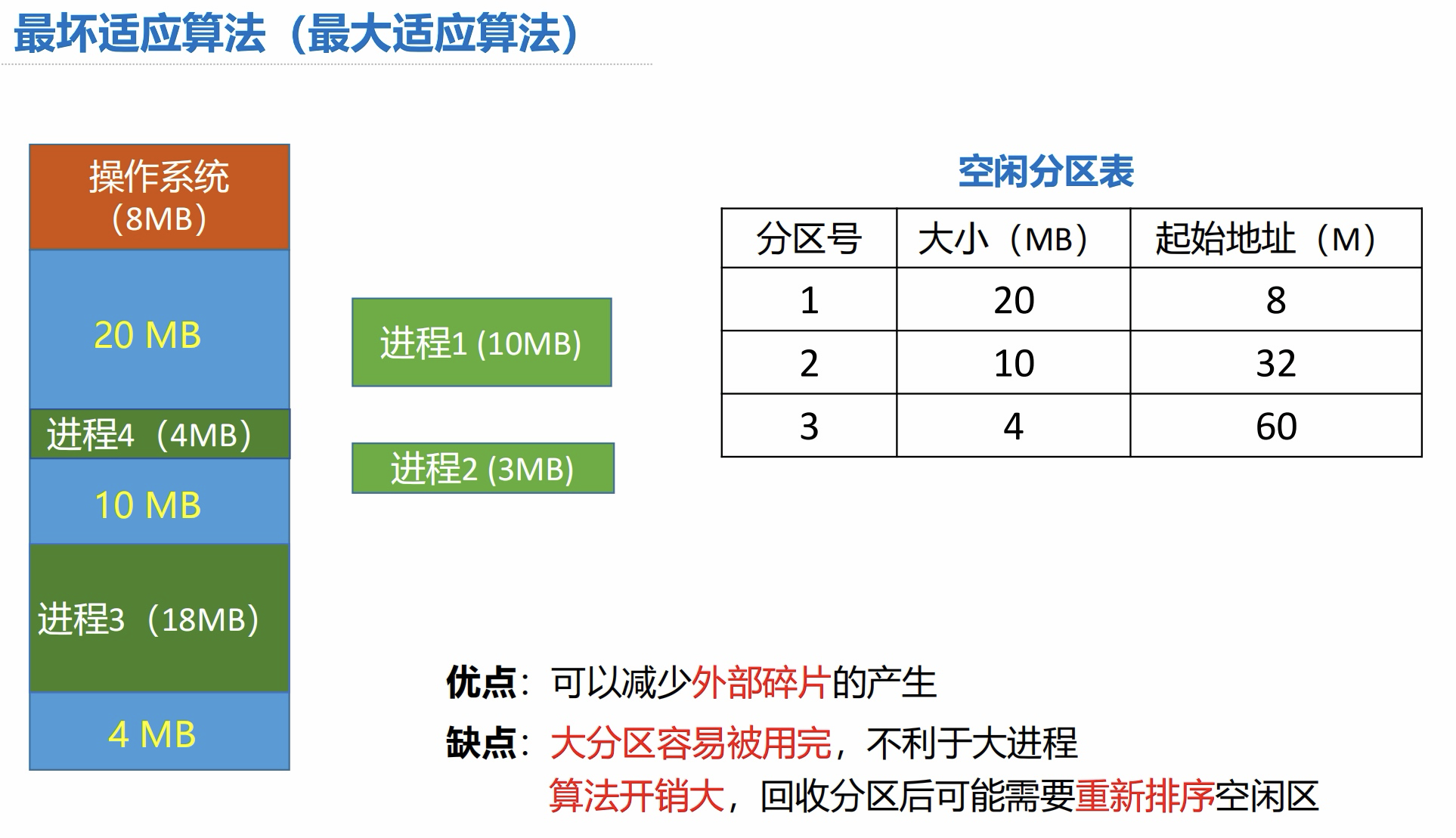
4.4 最坏适应算法
算法思想:
- 优先使用最大的连续空闲区
4.4 循环首次算法
此算法有争议,故不在考点中,不作讲解
5. 分页、分段、段页地址转换
5.1 分页地址转换
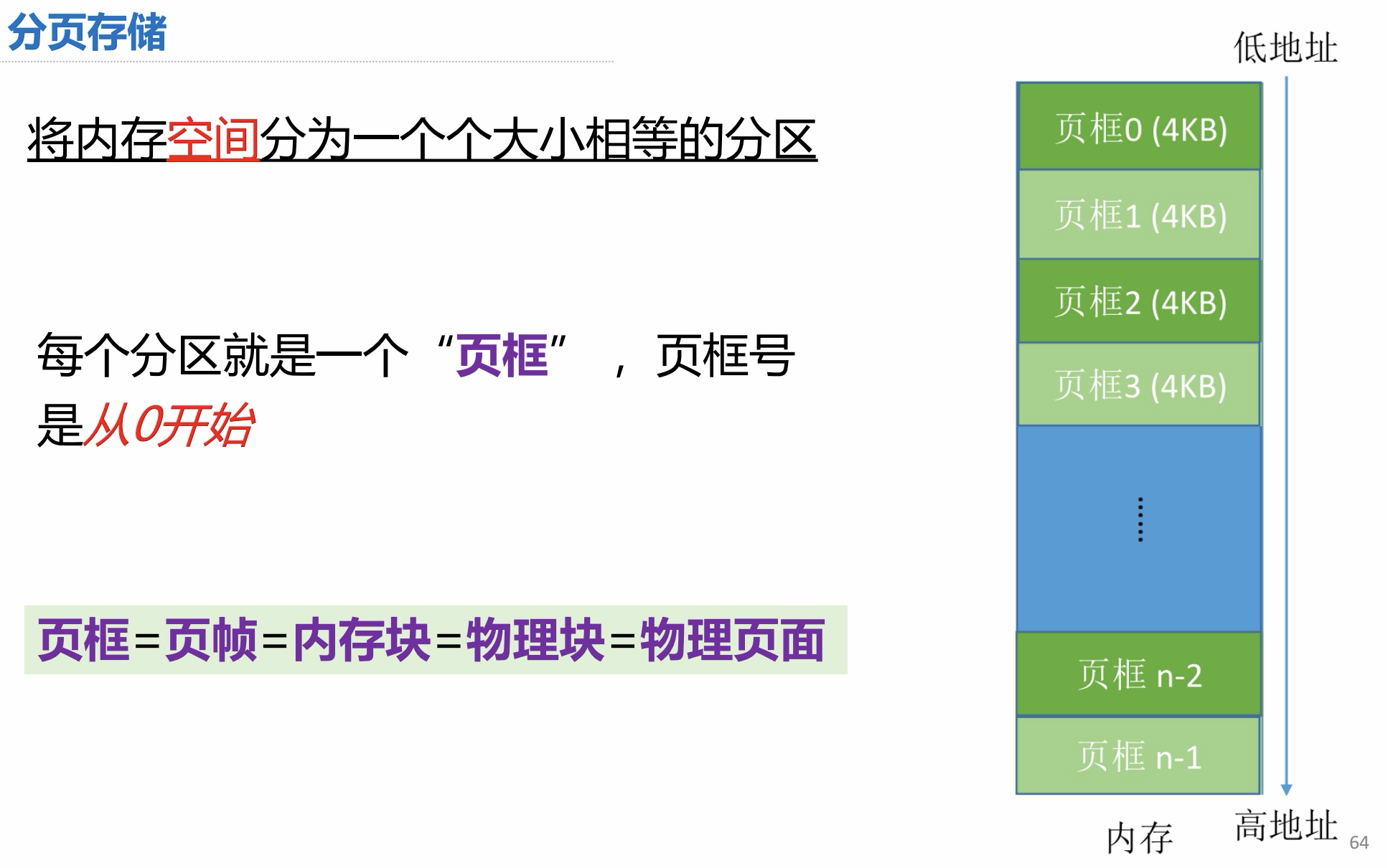
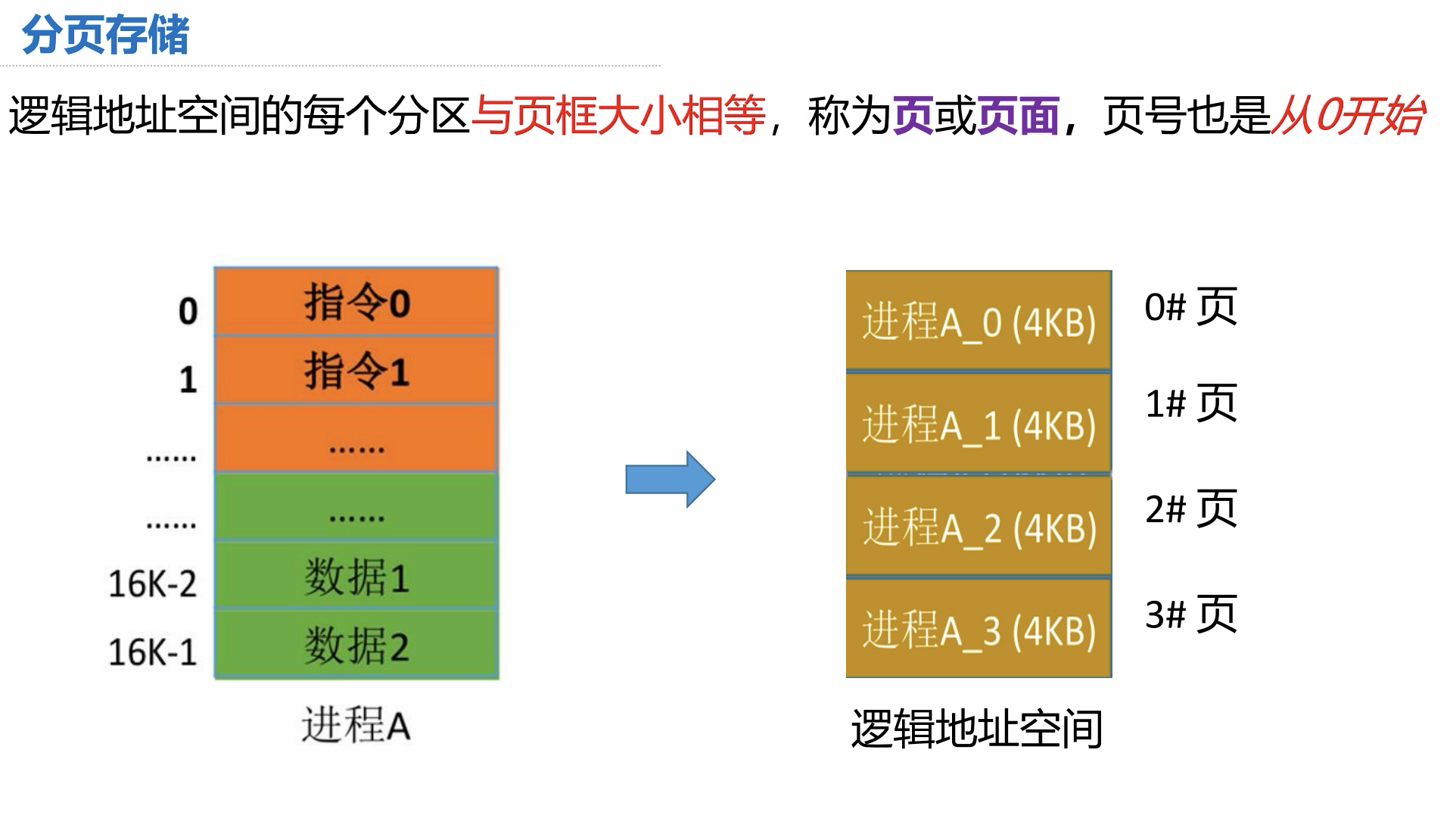
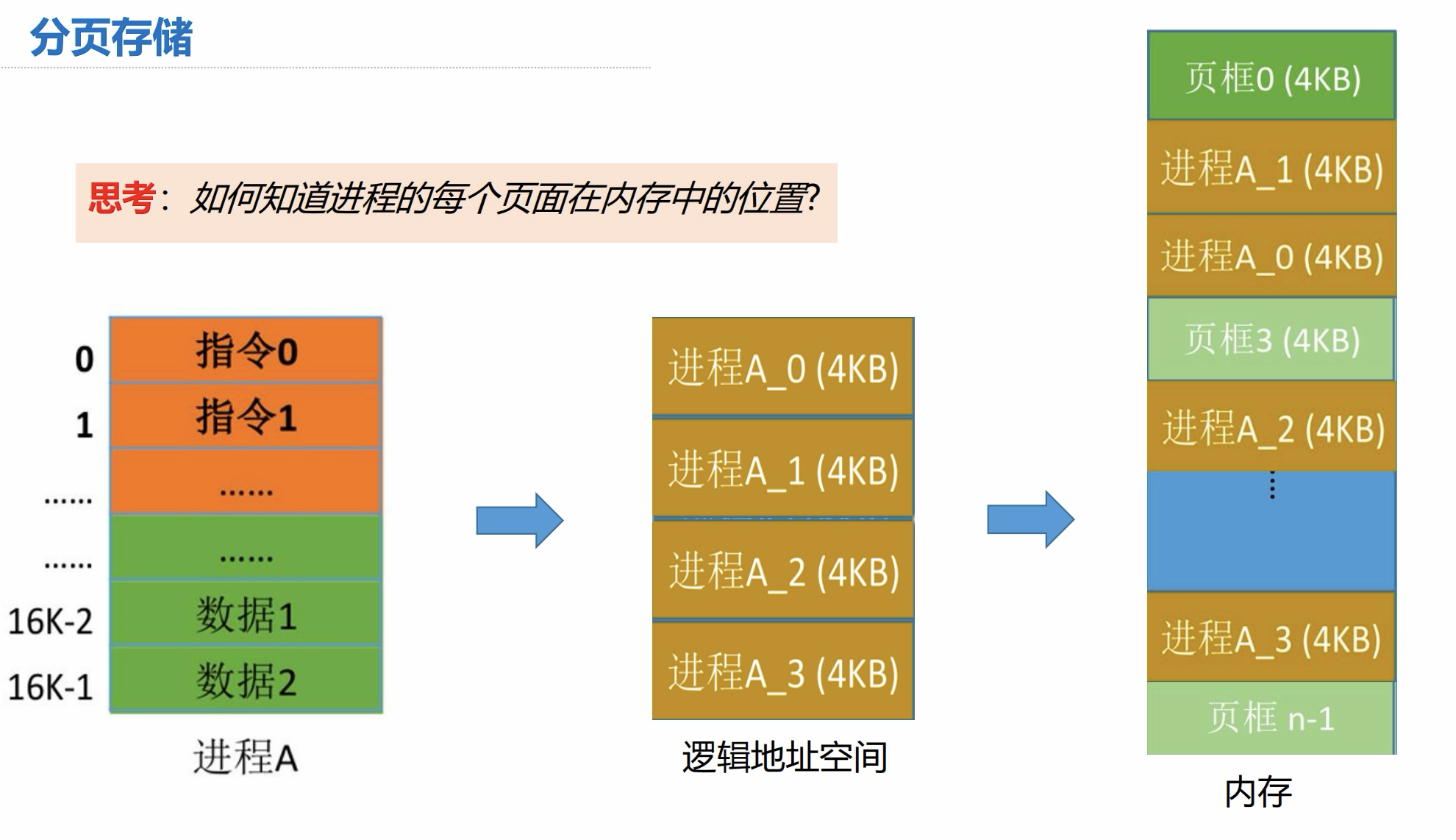
分页存储
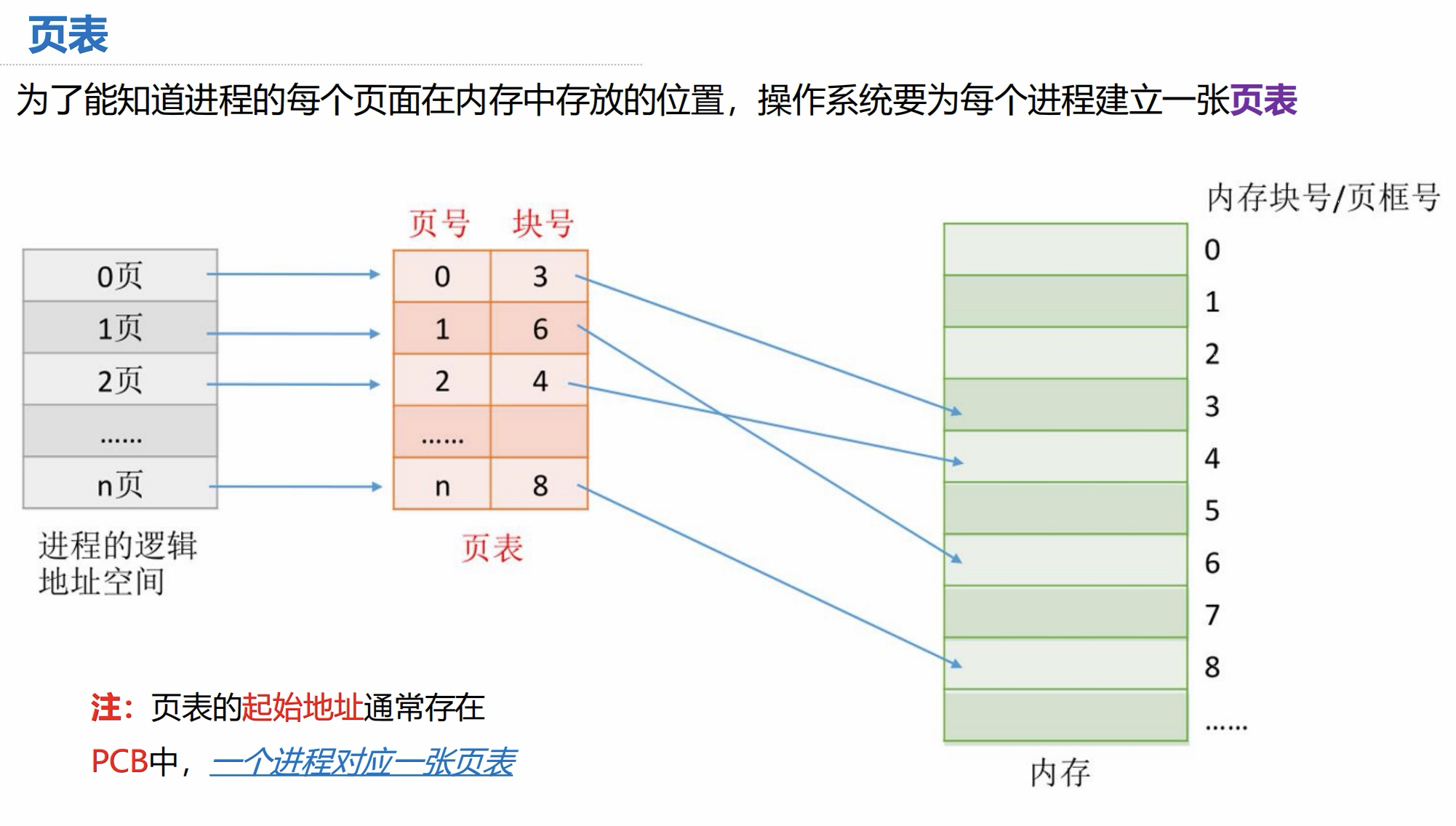
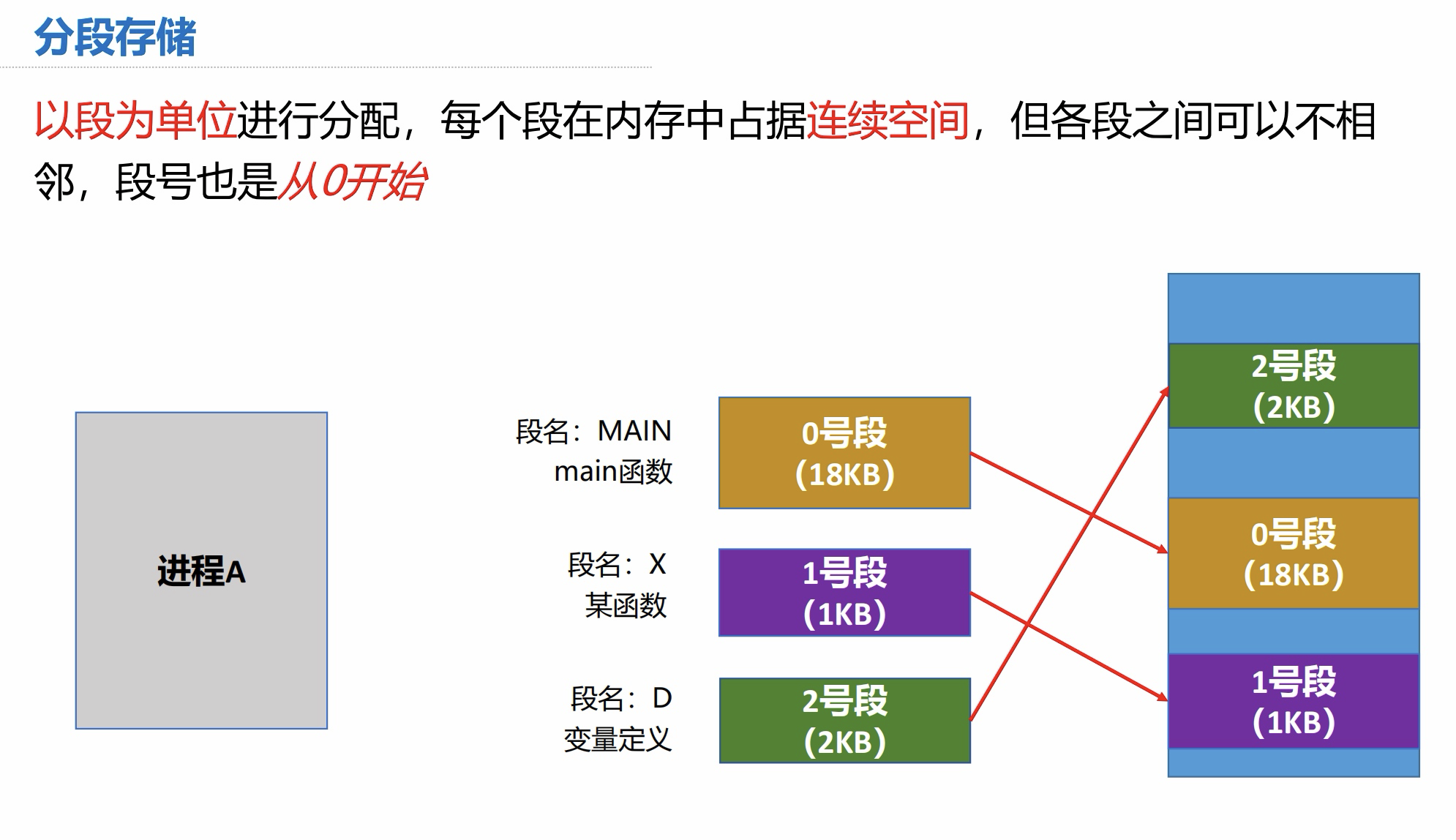
页表

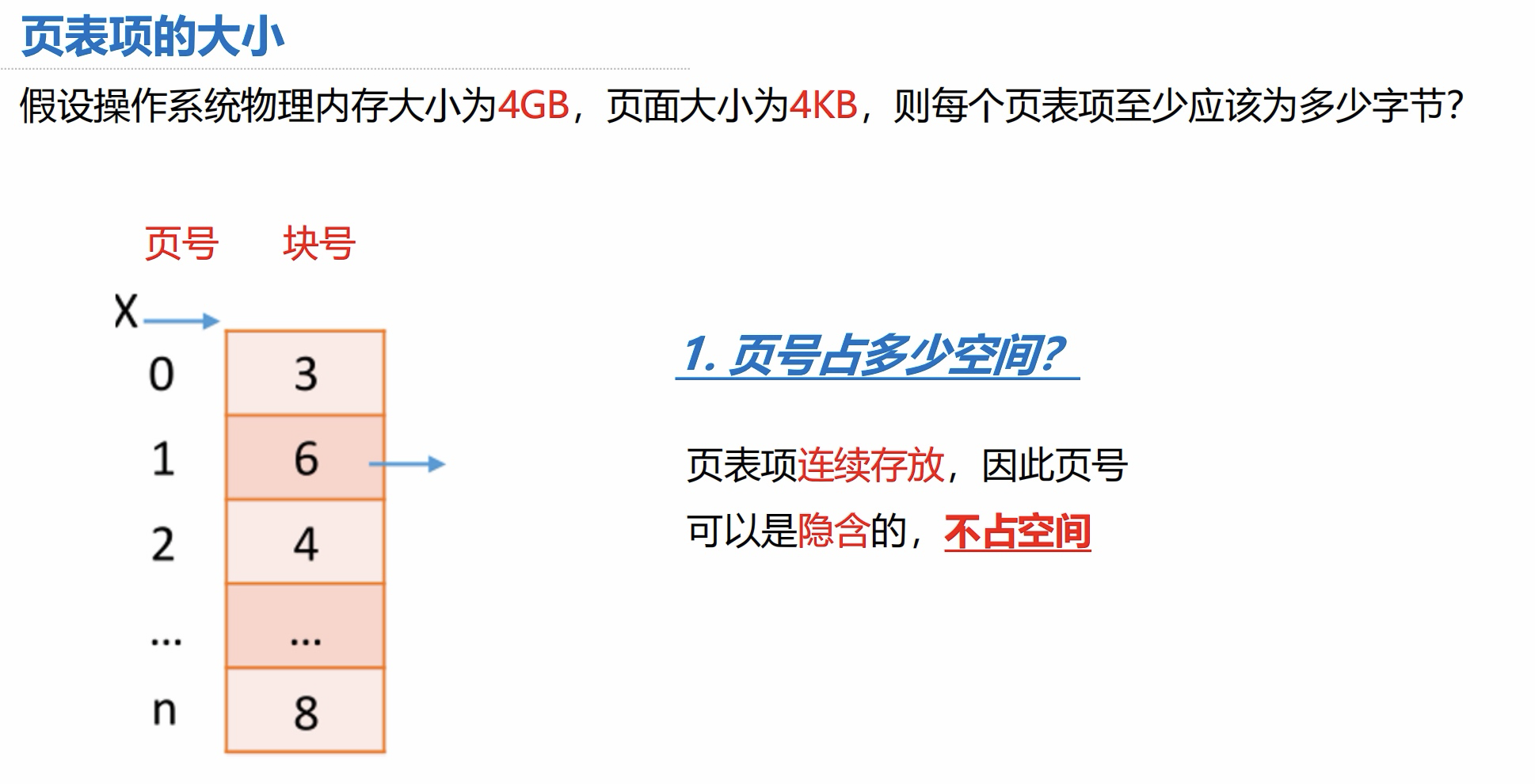
页表项的大小



地址转换的实现(重要)
这部分与后面做题息息相关,必须理解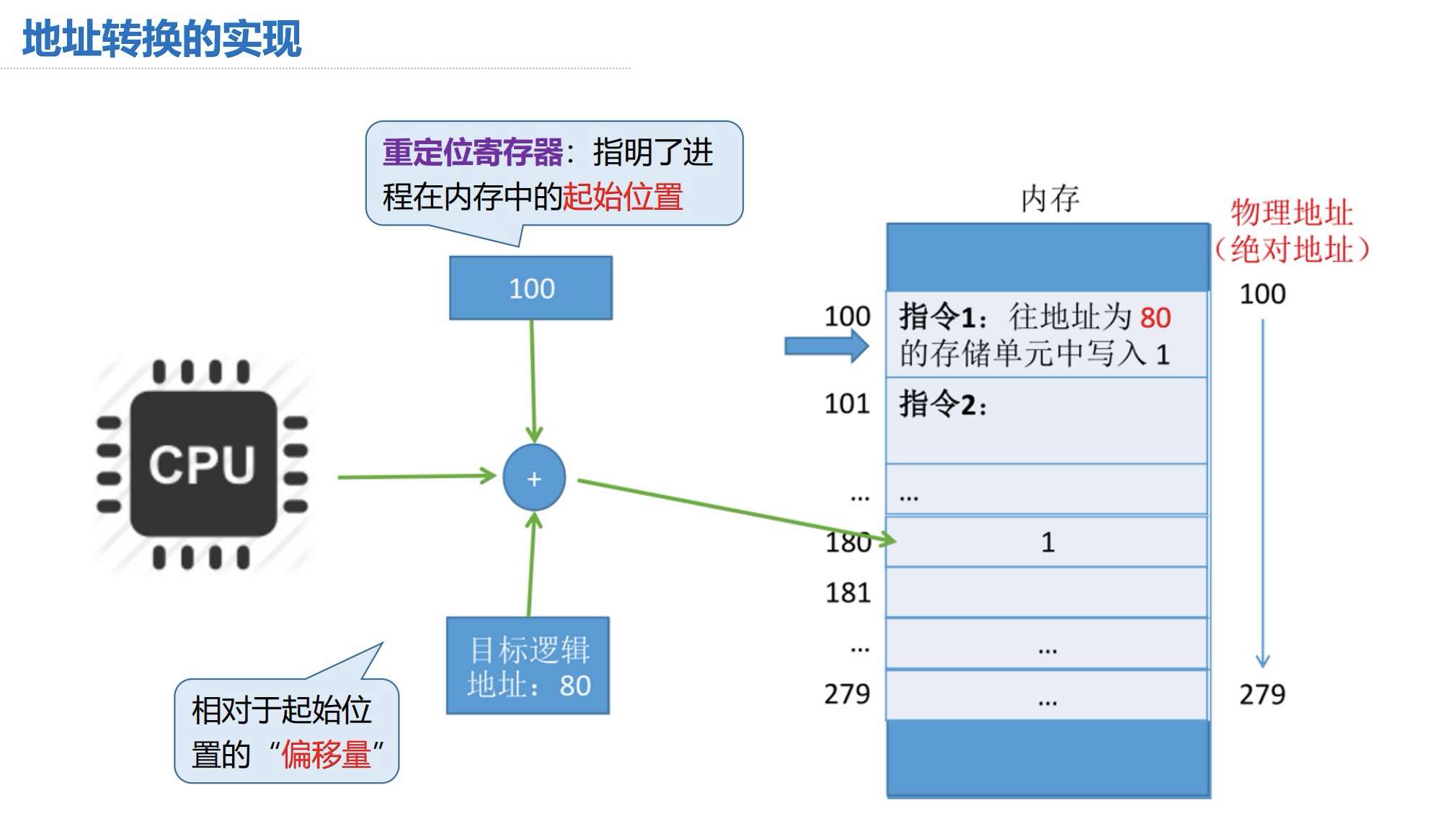
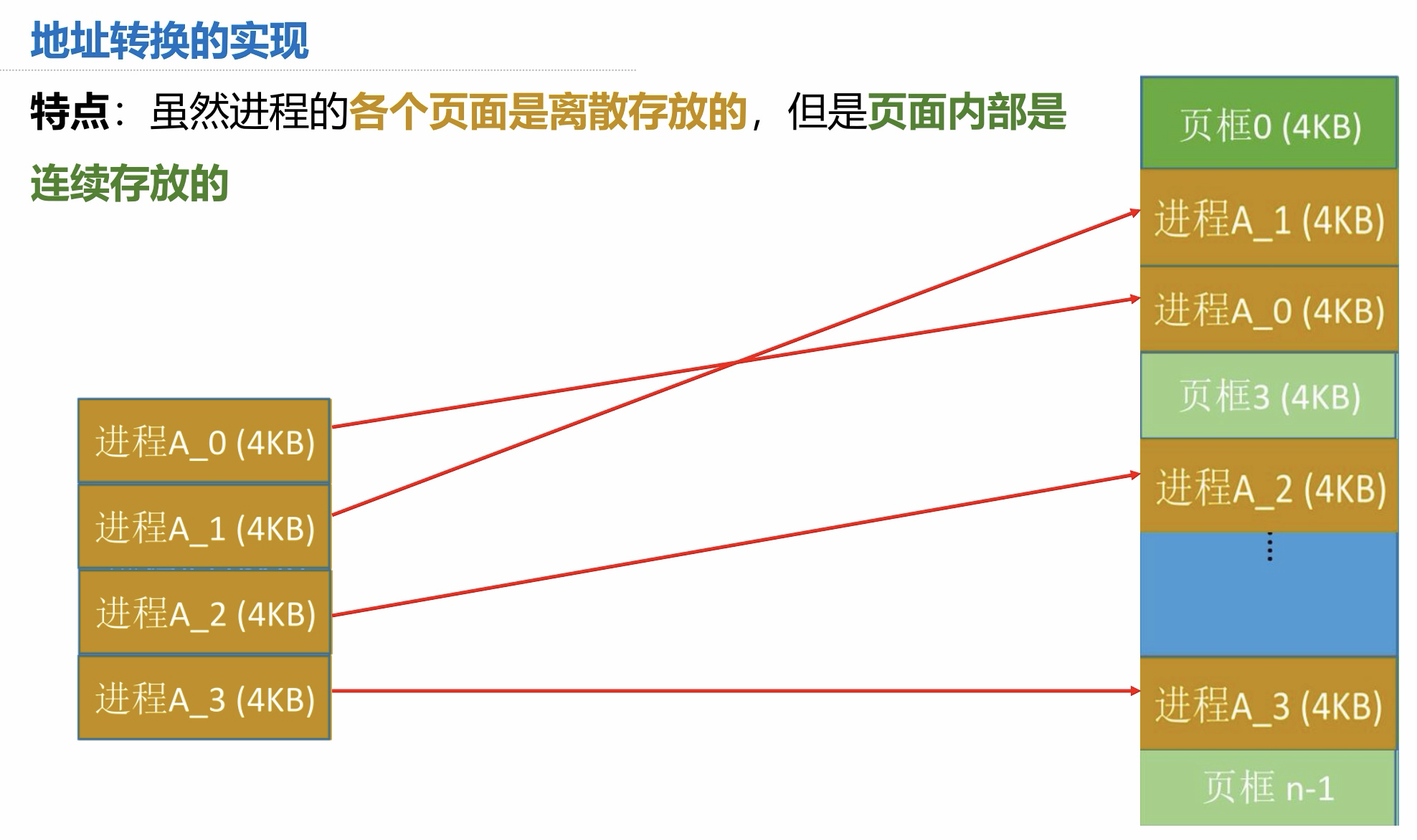
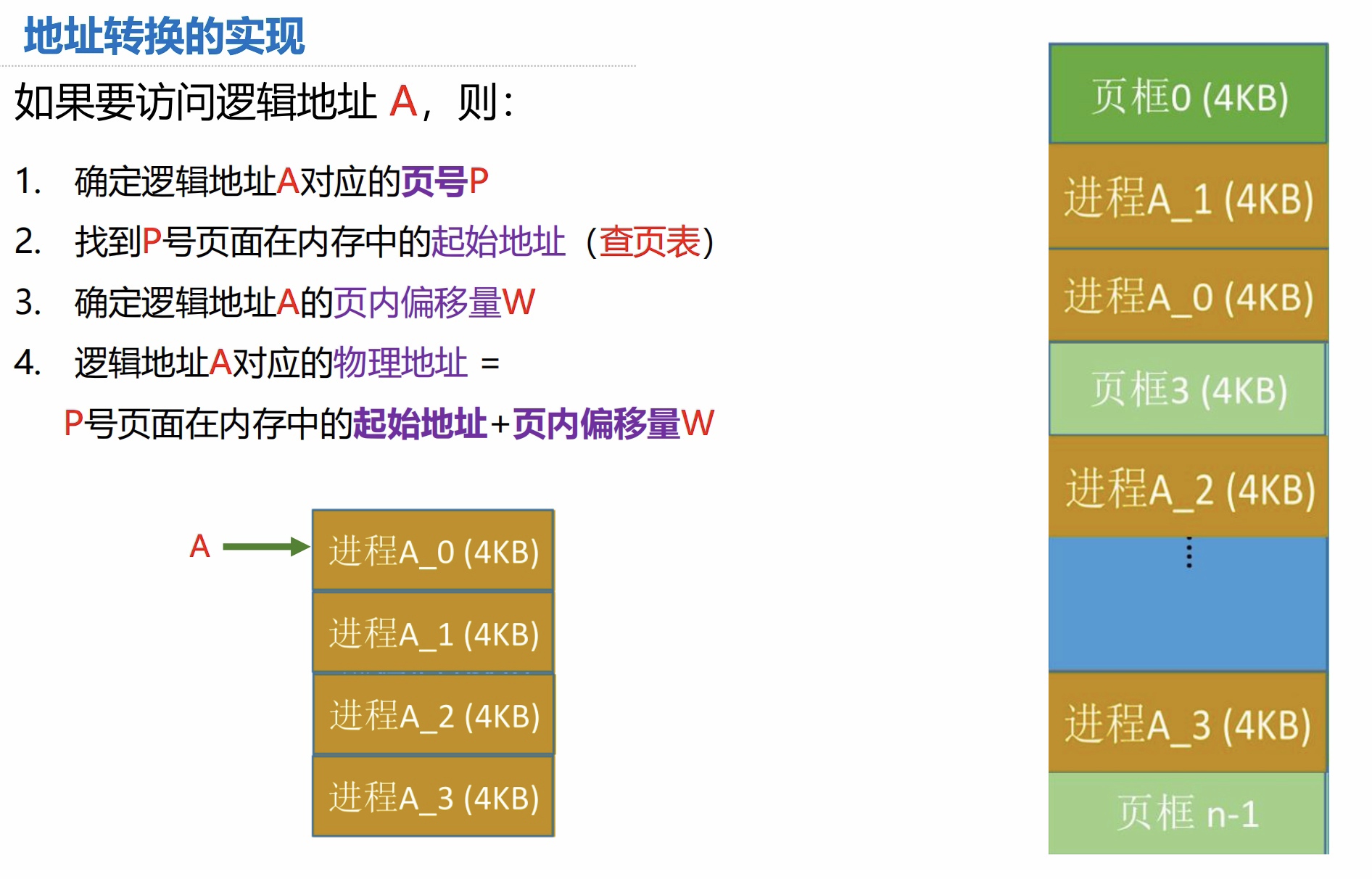


总结一下以上内容:
如果要访问逻辑地址 A:
- 确定逻辑地址 A 对应的页号 P
- 找到 P 页面在内存中的起始地址(查页表)
- 确定逻辑地址 A 的页内偏移量 W
- 逻辑地址 A 对应的物理地址 = P 号在页面中的起始地址 + 页内偏移量 W
通过页号查找的实际为块号,块号 * 页面大小 = 物理起始地址。
所以求得物理地址只需得知:
- 页号、页面大小、页内偏移量
例题:
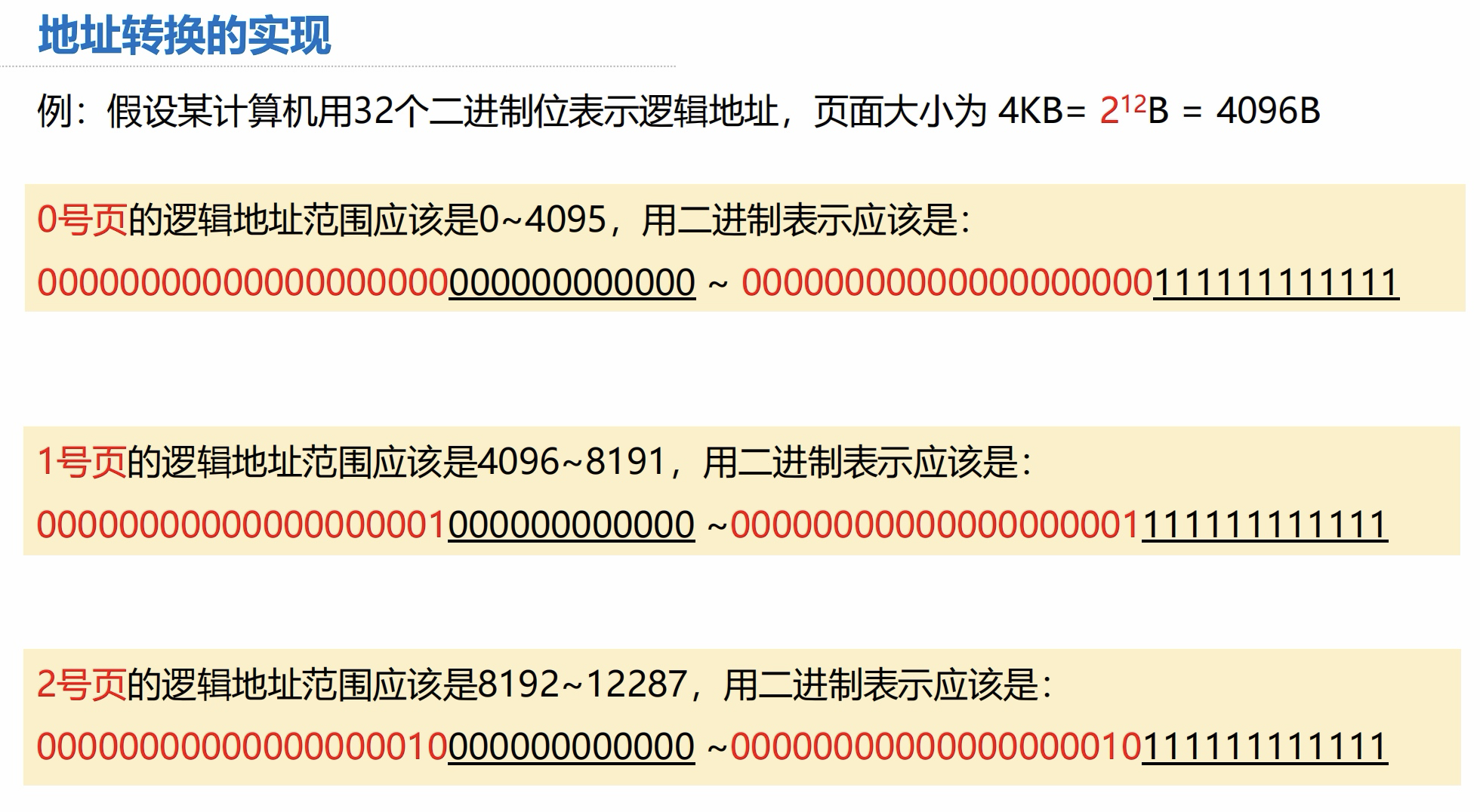



这里的两个结论比较重要,重点理解一下。
-
如果每个页面大小为
2^KB,用二进制数表示逻辑地址,则末尾 K 位即为页内偏移量,其余部分就是页号。 -
如果页面大小刚好是 2 的整数幂,则只需把页表中记录的物理块号拼接上页内偏移量就能得到对应的物理地址。
逻辑地址结构

分页地址转换机构


此模块中,最后一页 PPT 内容非常重要,这就是在答题时的整体思路,一定要完全理解。
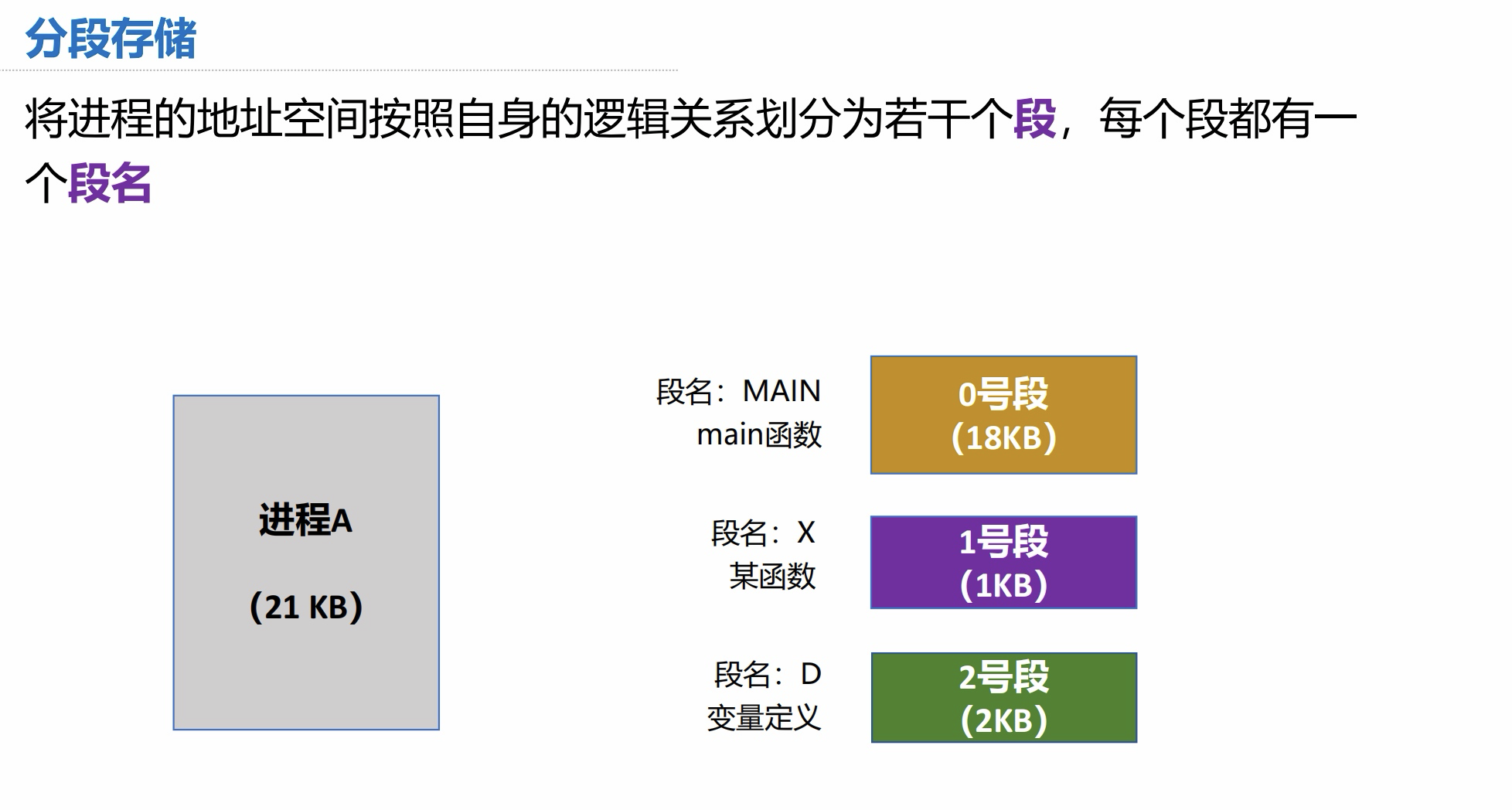
5.2分段式存储管理
分段存储
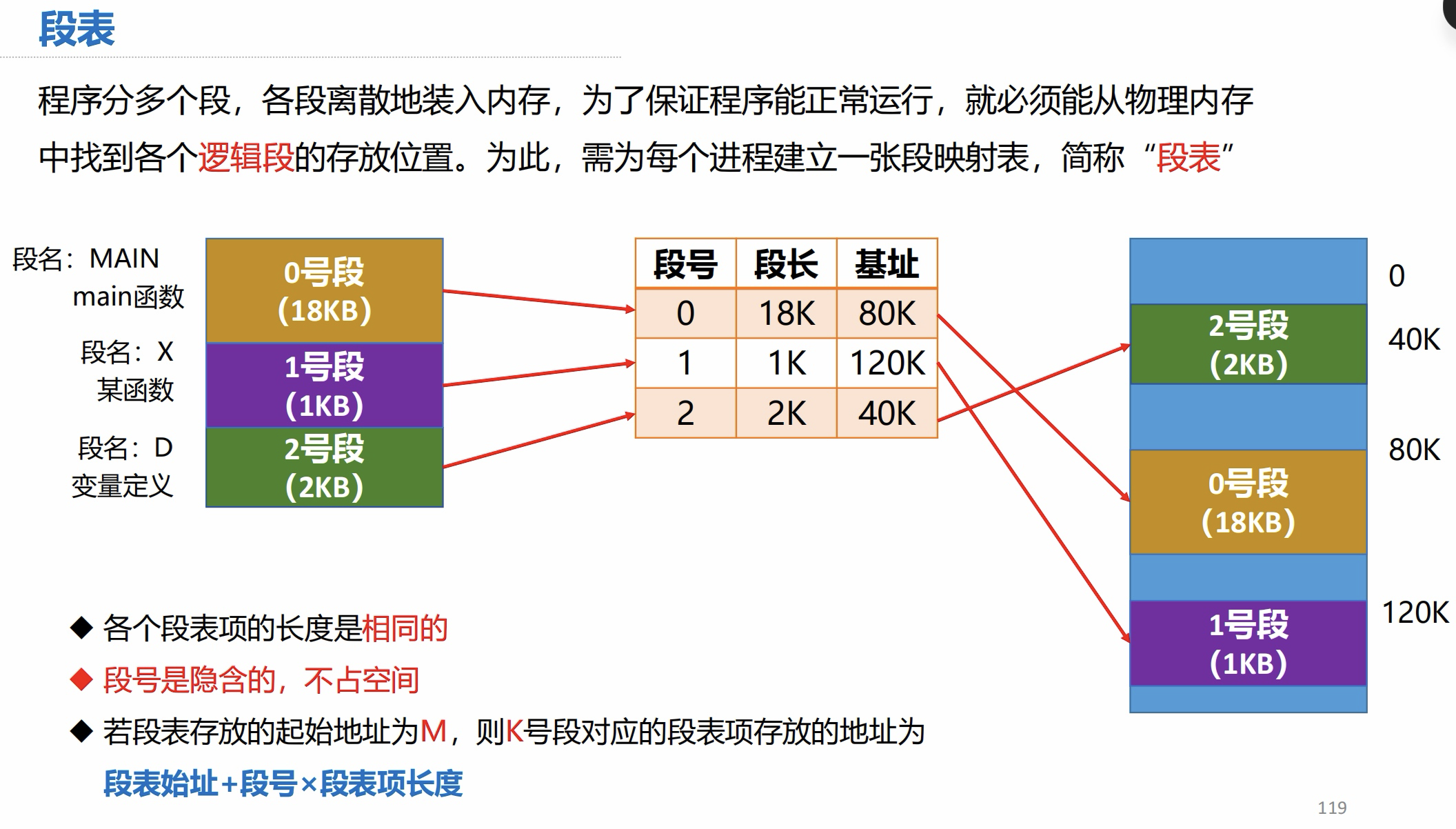
段表
逻辑地址结构

分段地址转化机构

此页 PPT 的内容比较重要,陈列出了分段式管理从逻辑地址到物理地址,需要知道的信息,重点理解,答题时要能分析出变量属于哪个信息。
地址变换(重要)

此页 PPT 内容极为重要,这就是答题思路和模板,只有理解它,才可以开始做题。在开始做例题之前,一定要充分理解。
例题:
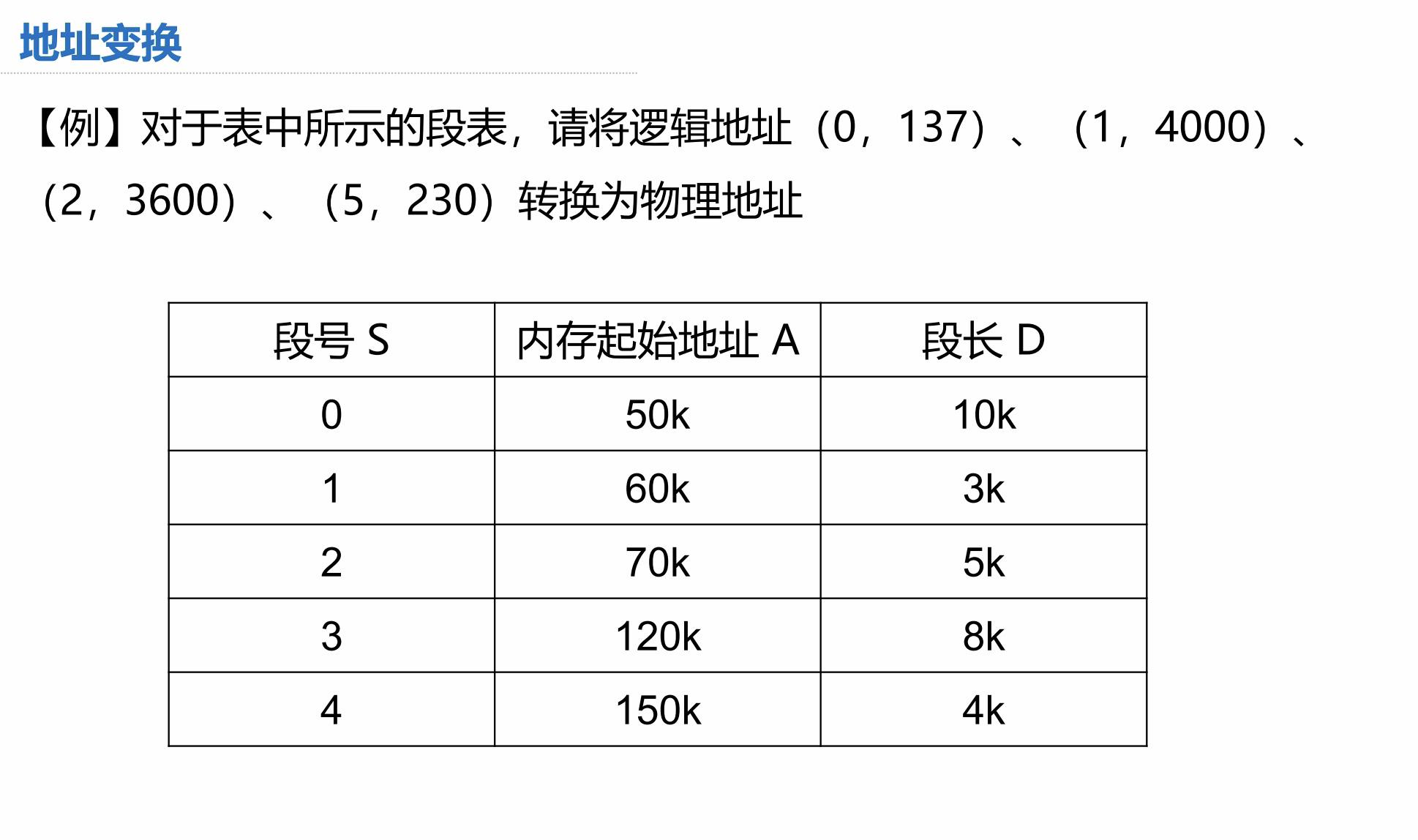

5.3 段页式内存管理
段页式存储管理
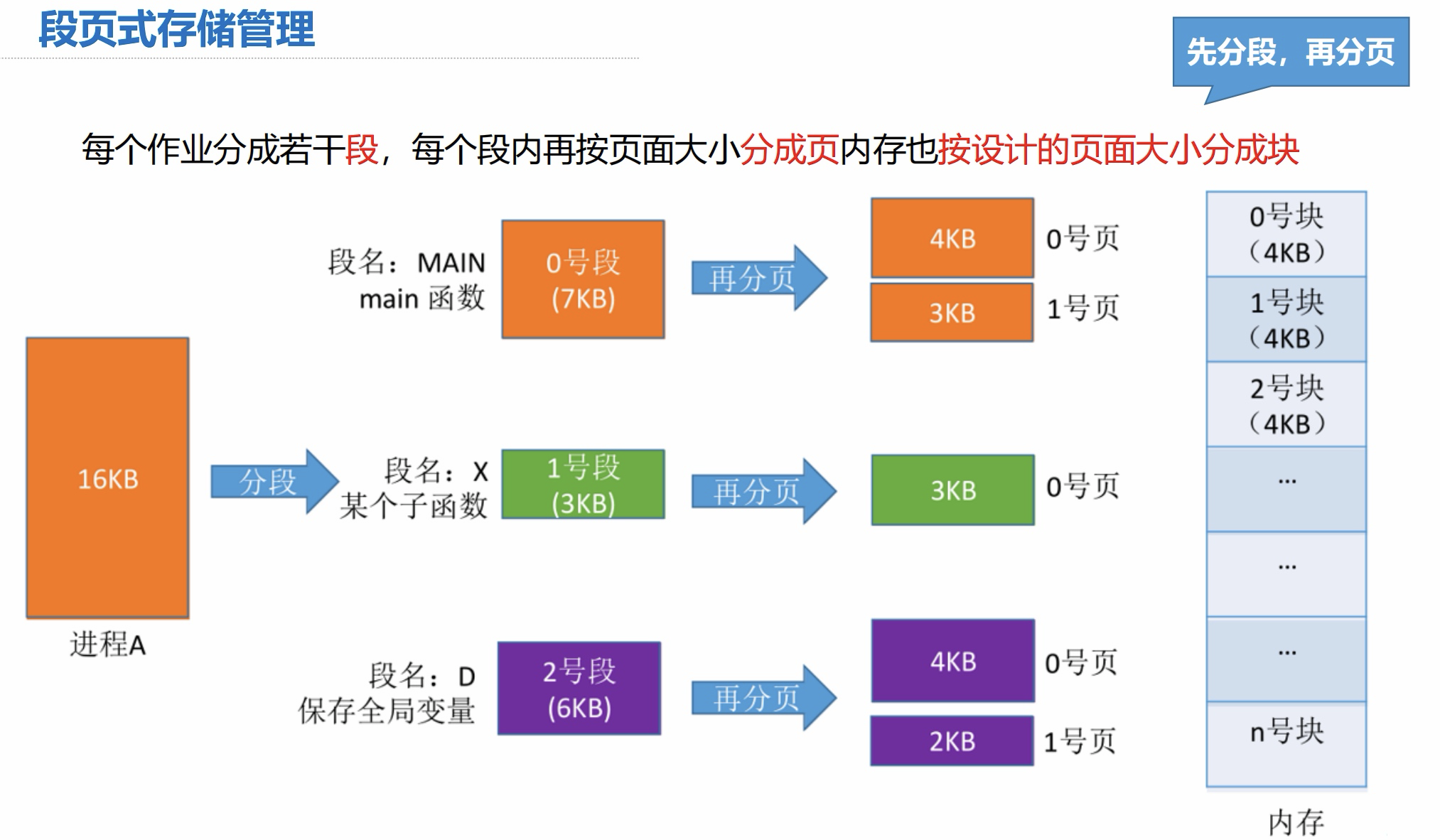
强调一点:
- 每个段都有自己的独立页表
逻辑结构地址

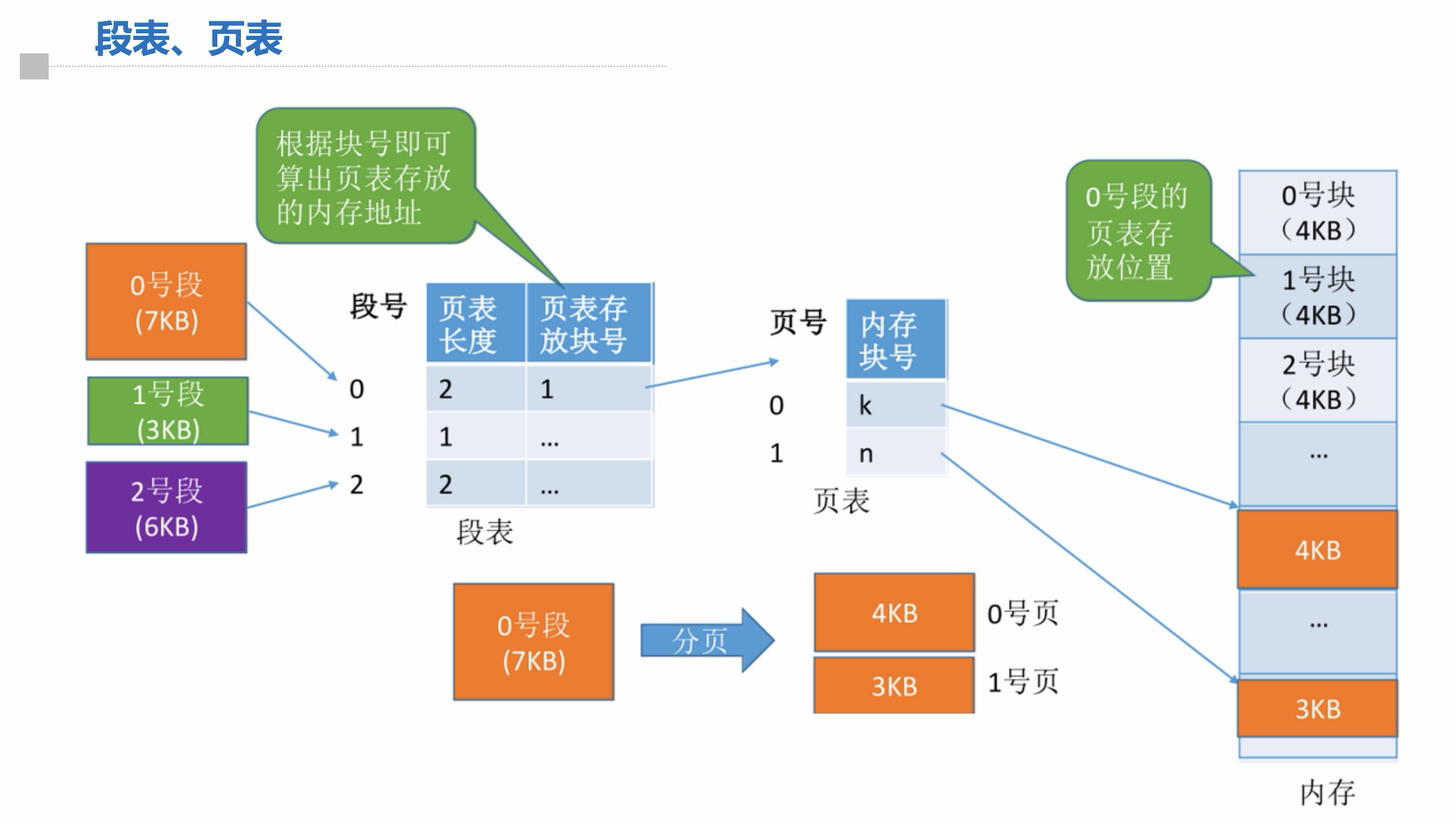
段表、页表(重要)
这页 PPT 将地址转换的具体过程完全展现,解题思路就是按照此流程逐步进行,此页内容是解题的关键,一定要完全理解。
地址转换
例题:
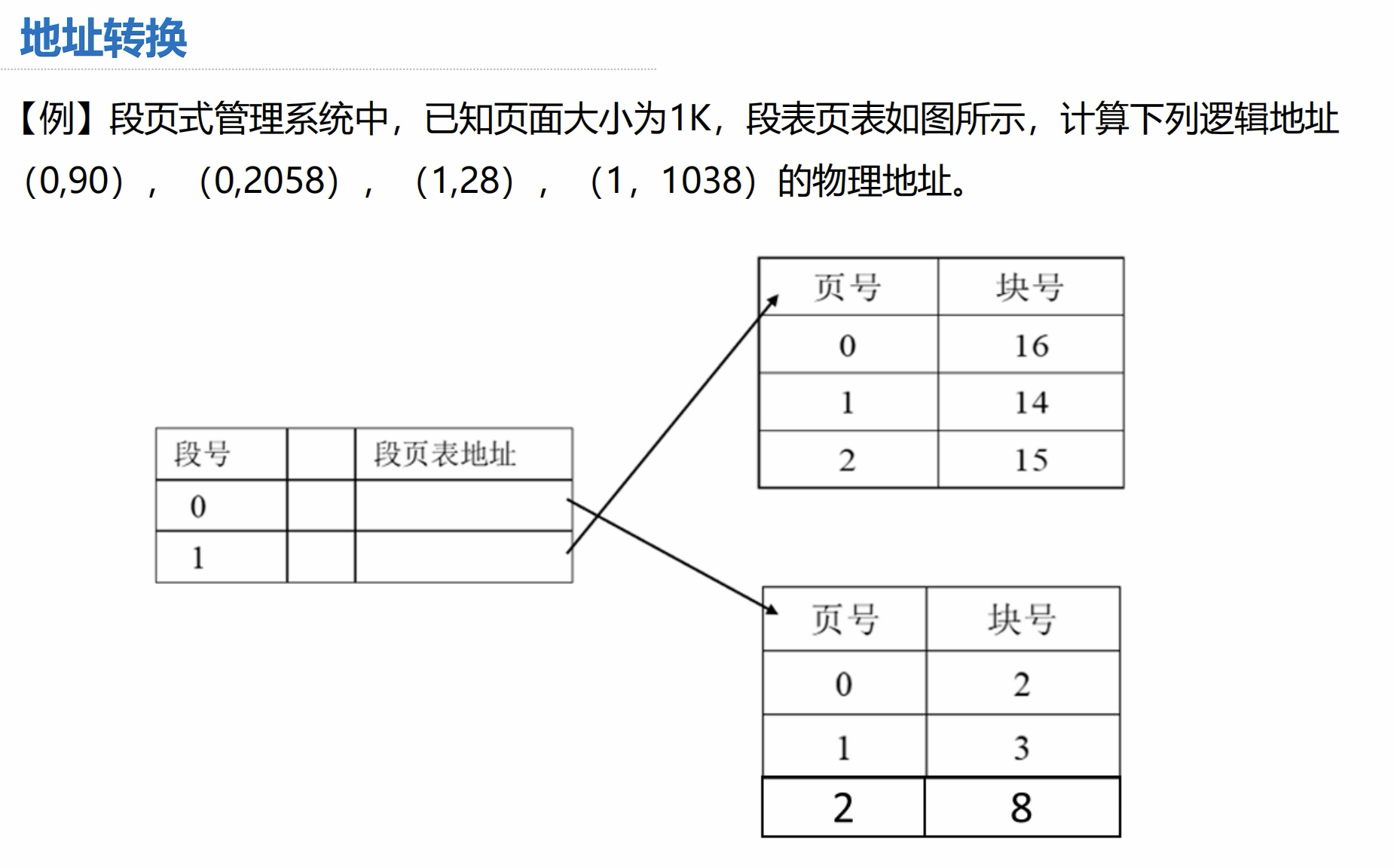



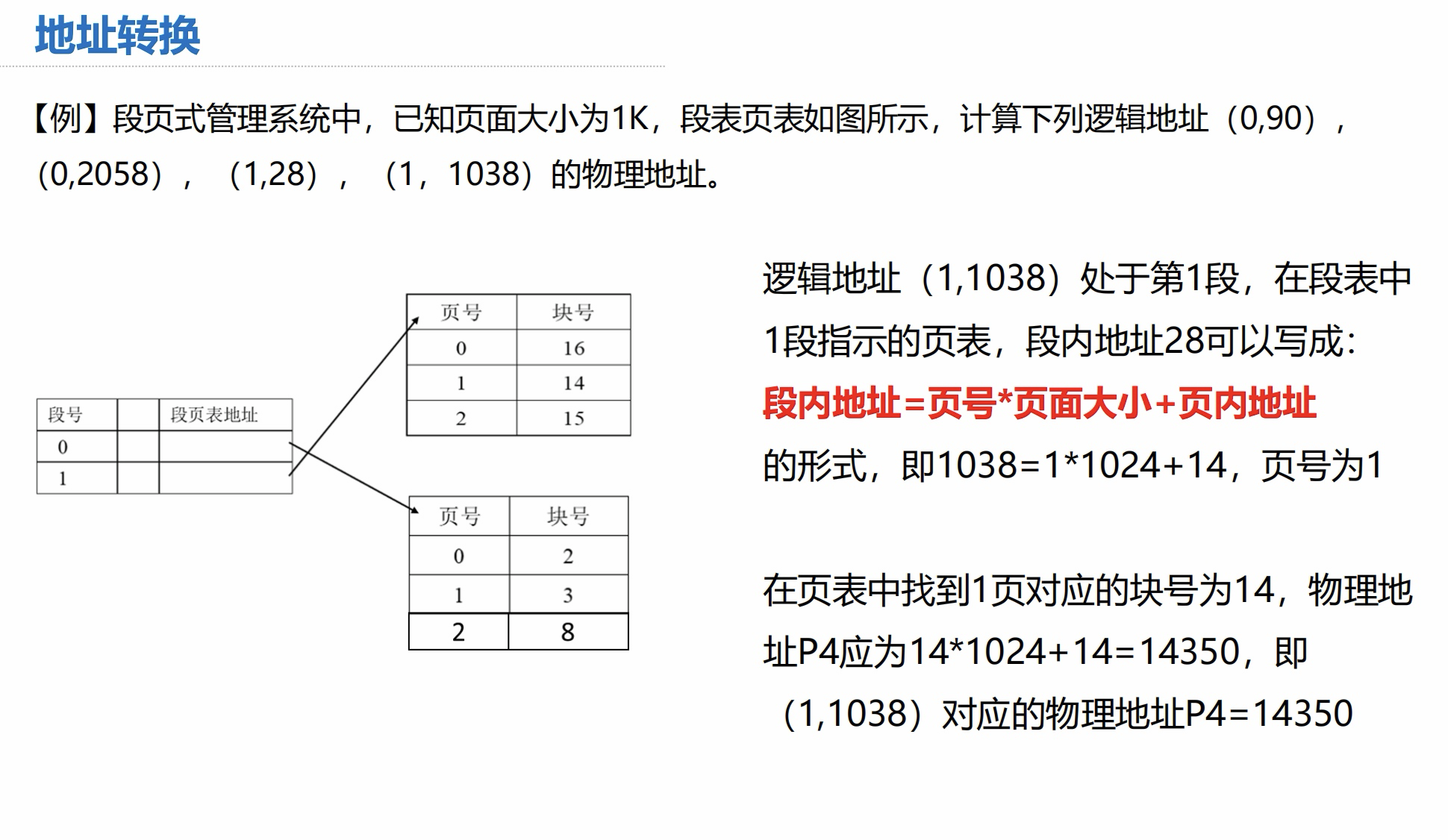
1K 为 1024 这一点不要忘记,容易踩坑。

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐

 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)