为什么很多 DPDK 程序跑不满 CPU?——从 CPU Pipeline 视角重新理解数据面性能
很多 DPDK 开发者习惯使用 CPU 利用率来衡量系统性能,但在现代服务器中,CPU 跑满并不意味着流水线被充分利用。大量数据面程序虽然占用了 100% CPU,却仍然存在严重的 Pipeline Stall、Cache Miss 和 Branch Mispredict 问题。本文从现代 CPU 微架构出发,结合 DPDK、UPF 和高性能网络软件的实际场景,深入分析为什么数据面性能优化的本质不
一、一个令人困惑的现象
很多工程师在优化 DPDK 程序时都会观察 CPU 利用率。
例如:
top
htop
perf stat
当看到:
CPU Usage = 100%
时,往往会得出结论:
CPU已经跑满了
因此系统性能已经达到极限。
然而在实际项目中,经常会出现另一种情况:
CPU利用率:100%
吞吐量:15Mpps
经过优化后:
CPU利用率:100%
吞吐量:25Mpps
CPU利用率没有变化,吞吐量却提升了接近70%。
这说明:
CPU利用率 ≠ CPU真正利用率
问题的根源在于:
很多开发者看到的是:
CPU Busy
而不是:
CPU Productive
二、现代CPU到底在做什么?
很多人对CPU的理解仍然停留在:
取指令
↓
执行
↓
下一条
事实上现代Xeon已经完全不是这样工作。
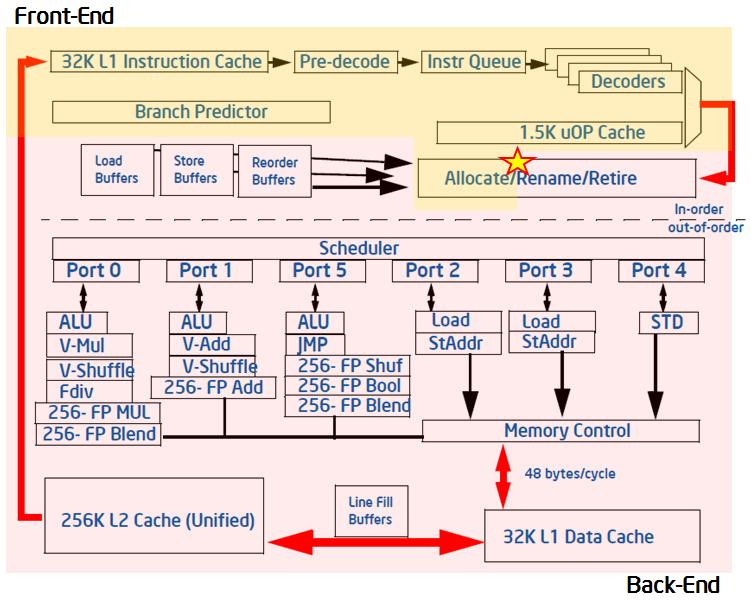
以Intel Xeon为例,CPU内部通常包含:
-
Frontend
-
Decode
-
Reorder Buffer
-
Execution Units
-
Load/Store Units
CPU会同时执行:
数十条甚至上百条指令
这种机制称为:
Out Of Order Execution
即:
乱序执行
CPU真正追求的是:
让执行单元永远不要闲着
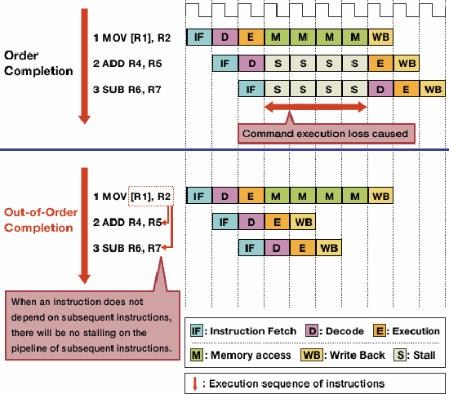
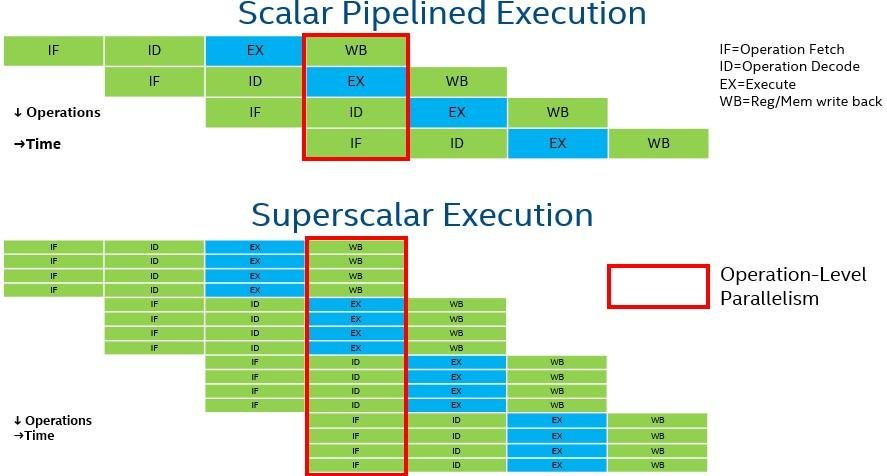
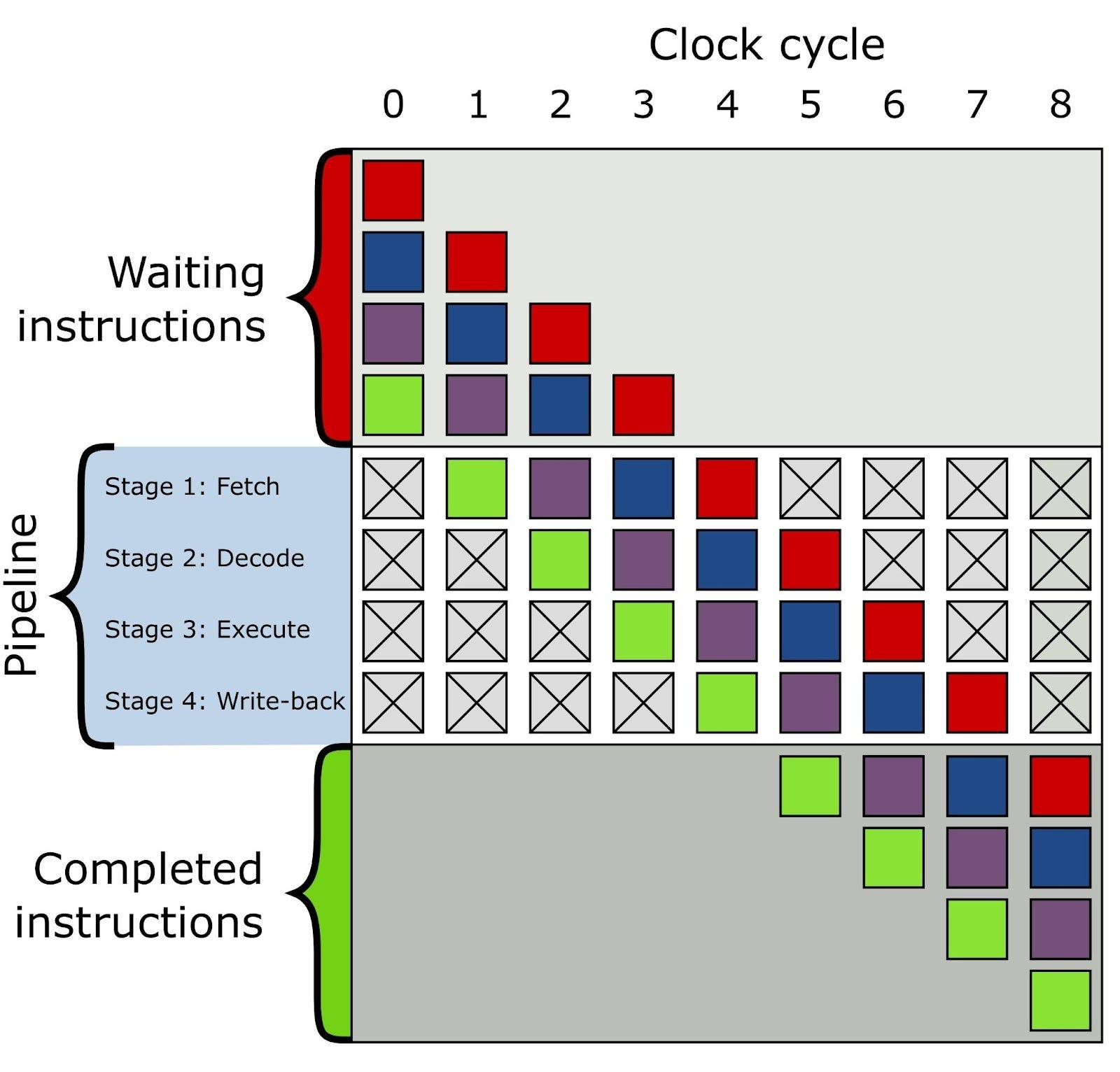
三、Pipeline才是CPU的核心
现代CPU本质上是一条超级流水线。
理想状态:
Cycle1
Inst1
Cycle2
Inst1 + Inst2
Cycle3
Inst1 + Inst2 + Inst3
最终形成:
满流水
执行单元始终工作,这才是CPU性能的来源。
四、为什么DPDK特别依赖Pipeline效率?
因为DPDK场景具有两个特点:
第一:
重复性极高
例如:
收包
解析
查表
转发
第二:
每包计算量很小
一个64B数据包。
真正逻辑可能只有:
几十条指令
因此:
如果Pipeline效率下降,吞吐量会立刻受到影响。
五、CPU最怕什么?
很多开发者认为:
CPU最怕:
复杂算法
实际上不是。
现代CPU最怕的是:
等待
例如:
等待内存
等待分支判断
等待依赖数据
这些都会导致:
Pipeline Stall
即:
流水线停顿
六、Cache Miss如何毁掉流水线?
假设:
session = hash_lookup(teid);
Session不在Cache。
CPU需要:
访问DRAM
此时:
延迟可能达到:
200~400 Cycle
在等待期间:
大量执行单元闲置。
表现为:
CPU Usage 100%
IPC 很低
其中:
IPC
=
Instructions Per Cycle
是衡量流水线效率的重要指标。
七、为什么IPC比CPU利用率更重要?
例如:
系统A:
CPU 100%
IPC = 0.6
系统B:
CPU 100%
IPC = 2.2
两者CPU占用一样。
但系统B实际完成的工作量远高于系统A。
因此:
优秀的数据面工程师关注:
IPC
而不是:
CPU Usage
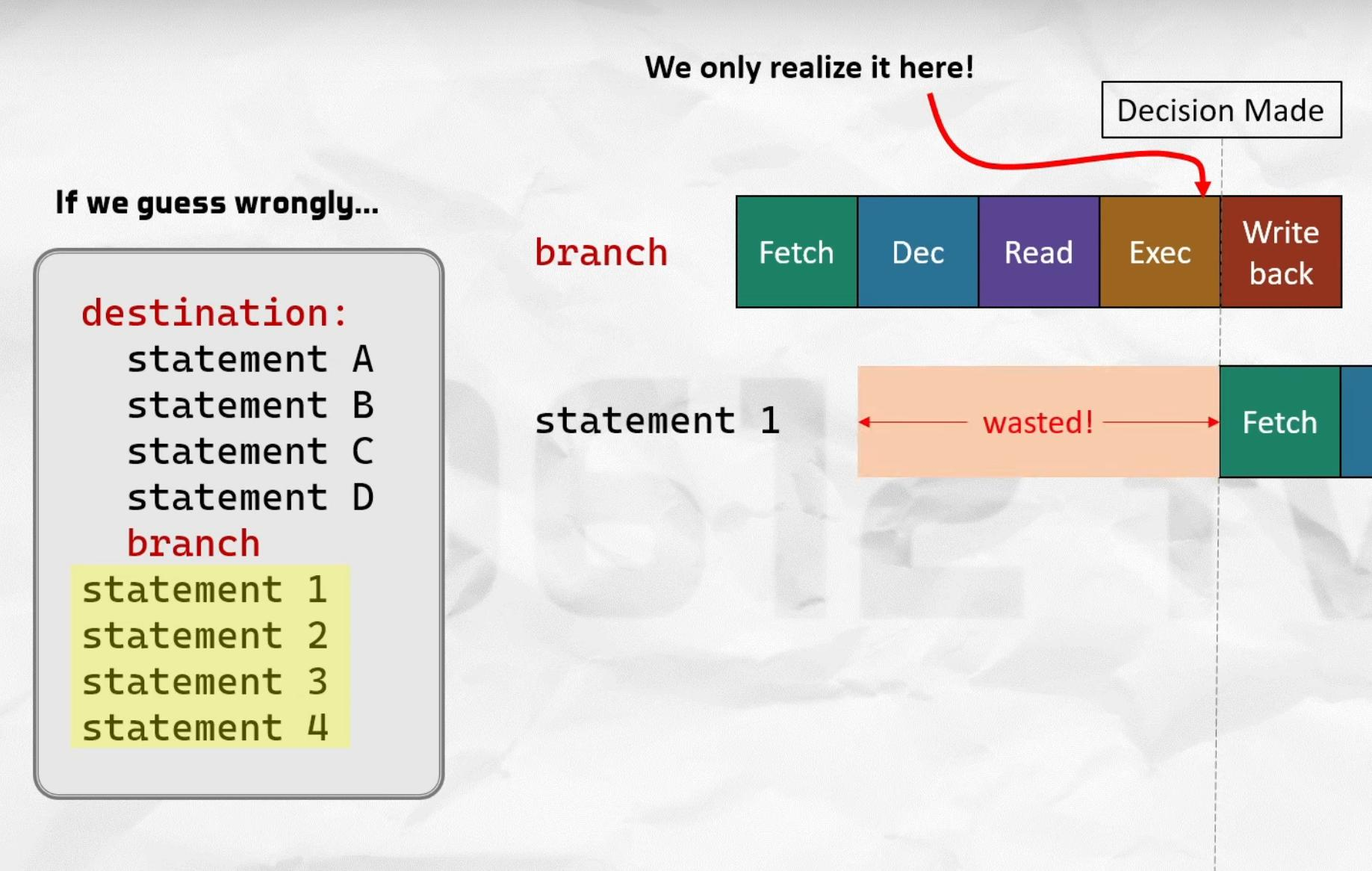
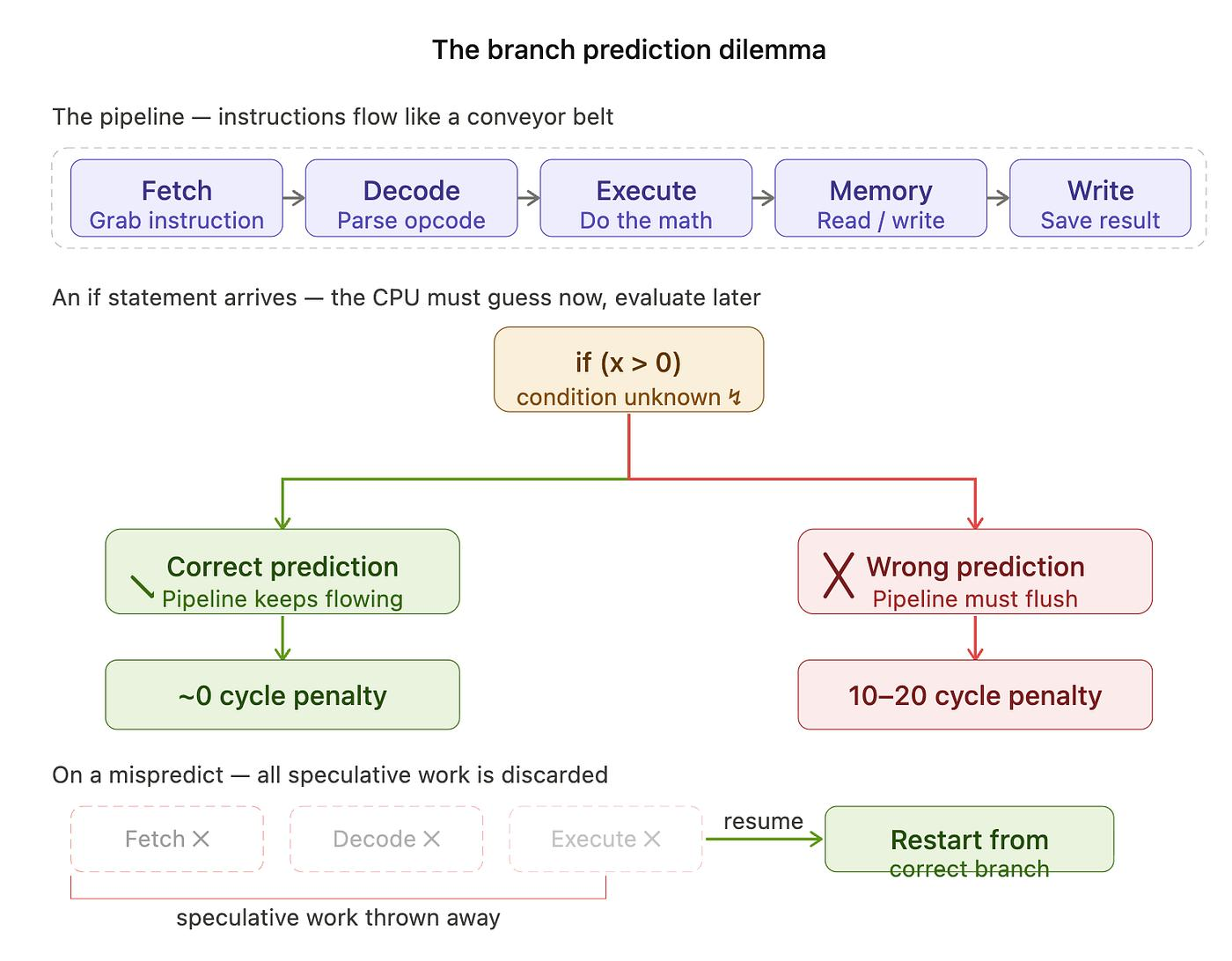
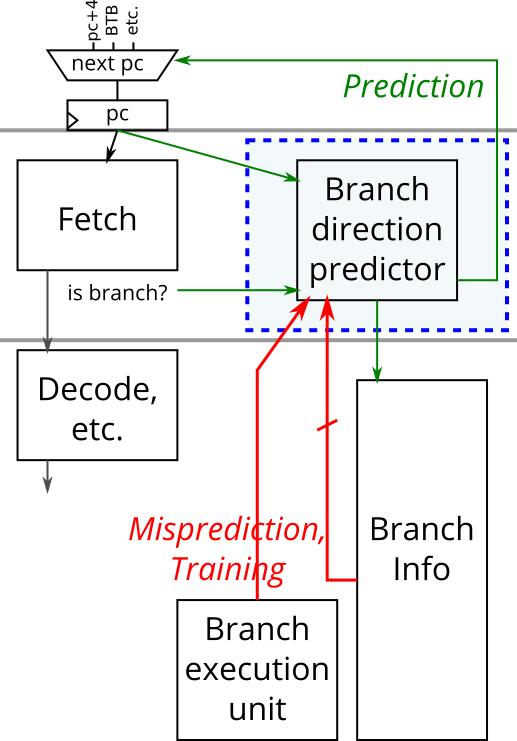
八、Branch Mispredict是隐藏杀手
看下面代码:
if (pkt_type == GTPU)
{
process_gtpu();
}
else
{
process_other();
}
CPU会尝试预测:
下一步走哪条路径
如果预测错误:
整个Pipeline需要:
Flush
即:
推倒重来
损失几十个Cycle。
九、为什么运营商流量更容易触发预测失败?
因为:
真实网络流量具有:
随机性
例如:
GTP-U
ARP
ICMP
BGP
OSPF
混合出现。
导致:
Branch Predictor
难以准确预测。
从而增加:
Pipeline Flush
频率。
十、DPDK为什么强调Burst?
很多人理解:
rte_eth_rx_burst()
是为了减少函数调用。
实际上更重要的是:
提高流水线利用率
例如:
一次处理:
32 Packet
CPU可以:
-
提前预取
-
重叠访问
-
并行执行
从而减少等待。
十一、Prefetch真正优化的是什么?
很多人认为:
Prefetch让访问更快
其实不是。
Prefetch无法降低内存延迟。
它只能:
隐藏延迟
例如:
处理:
Packet0
时。
提前加载:
Packet4
这样:
当执行到Packet4时。
数据已经进入Cache。
Pipeline不会停顿。
十二、为什么Pointer Chasing特别危险?
例如:
session
↓
pdr
↓
far
↓
qer
每一次:
->
都可能导致:
Cache Miss
于是:
等待
再等待
继续等待
Pipeline利用率持续下降。
十三、为什么VPP强调Vector?
VPP最核心思想之一:
Vector Processing
即:
一次处理64个Packet
这样做最大的收益是:
提高Pipeline填充率
CPU始终有足够工作量。
避免执行单元空闲。
十四、Run-To-Completion为什么有效?
很多人喜欢:
RX线程
↓
Parser线程
↓
Worker线程
↓
TX线程
看起来很专业。
实际上:
每次跨核都会导致:
Cache丢失
而:
Run-To-Completion
模式中:
一个Core完成整个流程。
Pipeline更加稳定。
十五、如何衡量流水线效率?
推荐关注:
perf stat
关键指标:
IPC
Instructions Per Cycle
Cache Miss
cache-misses
Branch Miss
branch-misses
Stall Cycle
stalled-cycles
这些指标远比CPU利用率更有价值。
十六、从DPDK到UPF
对于UPF而言。
真正消耗CPU的往往不是:
GTP-U解析
而是:
Session访问
PDR访问
FAR访问
QER访问
这些状态访问导致:
Cache Miss
Pipeline Stall
最终限制性能。
因此:
未来UPF优化方向越来越集中于:
状态布局优化
而不是:
协议解析优化
十七、总结
很多开发者认为:
DPDK性能优化就是:
-
SIMD
-
Prefetch
-
无锁队列
-
批处理
这些当然重要。
但从CPU视角来看。
真正决定性能的核心指标只有一个:
Pipeline利用率
现代CPU拥有惊人的计算能力,真正限制数据面性能的往往不是算力,而是等待。
等待内存。
等待分支结果。
等待数据依赖。
因此高性能网络软件设计的本质,不是减少几条指令,而是让CPU流水线始终保持忙碌。
谁能够让Pipeline持续运转,谁就能构建真正高性能的数据面系统。

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐


 14
14 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)