omlx实战:5分钟让Apple Silicon本地跑通Claude Code——分页SSD KV缓存把TTFT从90秒压到1秒(附安装踩坑+实测)
文章目录
🍃作者介绍:AI 应用负责人/AI产品架构师,阿里云专家博主。专注 LLM 应用开发、Agent 系统设计、具身智能与工业 AI 落地。日常在大模型训练、Coding Agent 工具链、AI 产品商业化等方向持续输出实战内容。
🦅个人主页:@逐梦苍穹
🐼GitHub主页:https://github.com/XZL-CODE
✈ 您的一键三连,是我创作的最大动力🌹

1、前言
「本地模型也能带得动 Claude Code 吗?」——这个问题我被问过很多次,过去我的答案一直是"能跑,但别抱太大期望"。
原因不在模型本身,而在推理服务。编码 Agent(Claude Code、Cursor、OpenCode 这类)和聊天机器人的请求模式完全不同:它一轮对话里会塞进系统提示、工具定义、一堆文件内容,而且每发一次请求,prompt 的前缀都在悄悄漂移。绝大多数本地 MLX 推理服务器一旦发现前缀变了,就把 KV 缓存整个作废、从头重算。结果就是——开局还行,聊几轮之后,每次响应都要干等 30~90 秒,本地 Agent 直接变成"电子木鱼"。
omlx(项目名 oMLX,作者 Jun Kim)就是冲着这个痛点来的。它是一个专为 Apple Silicon 打造的本地 LLM 推理服务器,核心杀手锏是分页 SSD KV 缓存(Paged SSD Cache):把算过的 KV 缓存分块落盘,下次遇到相同前缀直接从硬盘恢复,而不是重算。社区实测,长上下文场景下首字延迟(TTFT)从 30~90 秒压到了 1~3 秒。
它还顺手解决了一堆工程细节:连续批处理、多模型共存、原生 macOS 菜单栏 App、OpenAI 与 Anthropic 双协议兼容,甚至给 Claude Code 准备了一个一行命令的启动器。整个项目 Apache 2.0 开源。
这篇文章我会按"先用起来,再搞懂原理"的思路展开:
- 第 2 节:5 分钟从安装到把 Claude Code 接到本地模型(含我自己的真实安装记录);
- 第 3 节:讲清楚为什么编码 Agent 在本地一直跑不顺,omlx 到底解决了什么;
- 第 4~5 节:核心功能与分页 SSD 缓存的技术原理;
- 第 6 节:我安装时踩到的几个坑和排错方法(
brew services的几个陷阱); - 第 7 节:性能实测数据对比。
读完你应该能自己判断:这台 Mac 值不值得拿来当本地 AI 推理节点。
2、5 分钟快速上手(先把它跑起来)
我们先不谈原理,直接把它装上、接到 Claude Code 看效果。整个流程我跑下来就这几步: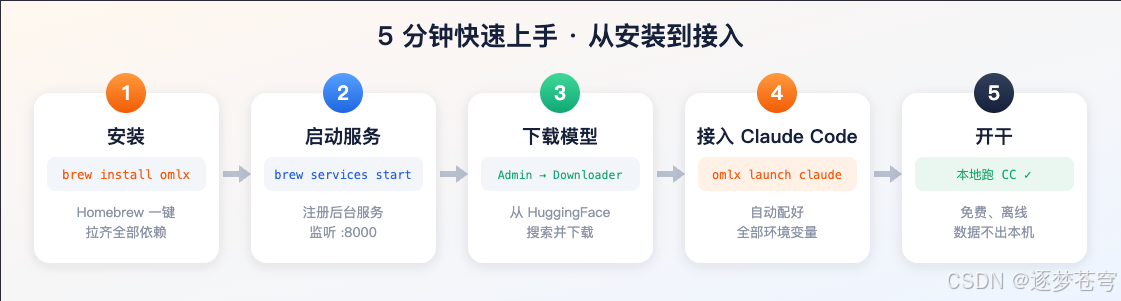
2.1 环境要求
omlx 是 Apple 专属,对环境有硬性要求:
| 项目 | 要求 |
|---|---|
| 芯片 | Apple Silicon(M1 / M2 / M3 / M4 系列),Intel Mac 不支持 |
| 系统 | macOS 15.0+(Sequoia) |
| Python | 3.11+(Homebrew 安装会自动拉取 python@3.11 / python@3.14) |
| 内存 | 建议 ≥ 16GB,跑 20B~35B 量化模型建议 ≥ 32GB |
| 命令行工具 | Xcode Command Line Tools(编译依赖用) |
为什么只支持 Apple Silicon?因为它的底座是 Apple 自家的 MLX 框架,专门为统一内存(Unified Memory)架构设计——这正是它比 Ollama 快的根本原因,第 3.3 节细讲。
2.2 Homebrew 一键安装
官方提供两种安装方式:下载 .dmg 菜单栏 App,或用 Homebrew 装命令行版。我选的是 Homebrew,因为我要的是后台服务 + CLI,不一定需要图形界面。
第一步,添加 tap(第三方仓库):
brew tap jundot/omlx https://github.com/jundot/omlx
第二步,安装:
brew install omlx
这一步会拉一大堆依赖,心里要有数——我装的时候它顺手装了 openssl@3、sqlite、python@3.11、python@3.14、z3、llvm、rust 等等,其中 llvm(约 1.9GB)和 rust(约 372MB)是大头,整体下载 + 编译花了我 6 分钟,装完占用约 1.4GB:
==> Installing jundot/omlx/omlx
==> python3.11 -m venv /opt/homebrew/Cellar/omlx/0.4.0/libexec
==> .../bin/pip install .[all]
🍺 /opt/homebrew/Cellar/omlx/0.4.0: 32,779 files, 1.4GB, built in 6 minutes 11 seconds
我装到的版本是 0.4.0。如果你的 Command Line Tools 太旧,安装日志里会提示去 System Settings 更新,一般不影响安装,但建议更到最新。
后续升级一条命令:
brew update && brew upgrade omlx
2.3 启动后台服务
omlx 装好后会注册成一个 Homebrew 服务。先把模型目录建出来(默认放 ~/.omlx/models):
mkdir -p ~/.omlx/models
然后用 brew services 把它拉起来,让它开机自启:
brew services start omlx
# ==> Successfully started `omlx` (label: homebrew.mxcl.omlx)
如果你不想要常驻后台服务(这玩意儿一跑就占内存),也可以直接前台运行,用完 Ctrl+C 关掉:
/opt/homebrew/opt/omlx/bin/omlx serve
服务默认监听 http://localhost:8000,API 路径是 http://localhost:8000/v1,同时兼容 OpenAI 和 Anthropic 协议。
⚠️ 这里有个反直觉的小坑:查服务状态不能用
brew services status omlx(status不是合法子命令,会直接报错),要用brew services info omlx或brew services list。
2.4 下载第一个模型
光有服务还不够,得喂模型。omlx 支持任意 MLX 格式的模型,下载有两种姿势。
方式一:Admin 控制台(推荐,最省事)
浏览器打开内置控制台:
http://localhost:8000/admin
进 Models → Downloader,直接搜 HuggingFace 上的 MLX 模型,能看到文件大小,点一下就下,模型自动落到 ~/.omlx/models/。
方式二:命令行 huggingface-cli
huggingface-cli download mlx-community/Qwen3.5-9B-MLX-4bit \
--local-dir ~/.omlx/models/Qwen3.5-9B-MLX-4bit
国内网络拉 HuggingFace 慢的话,omlx 的 serve 支持指定镜像:
omlx serve --model-dir ~/.omlx/models --hf-endpoint https://hf-mirror.com
模型选型我放在第 6.3 节专门讲,这里先说结论:优先选 MoE 架构的模型(如 gpt-oss-20b、Qwen3.x-A3B 系列),激活参数少、出字快。我自己用的是 Qwen3.6-35B-A3B-3bit-MLX(35B 总参数、约 3B 激活的 MoE,3bit 量化)。
2.5 一行命令接入 Claude Code:omlx launch
这是 omlx 最贴心的功能。它内置了一个 Claude Code 启动器,不用你手动配环境变量:
omlx launch claude
执行后它会弹一个极简 TUI,列出 omlx 知道的所有模型(已加载的排在最前面),你选一个,它就自动帮你设好 ANTHROPIC_BASE_URL、ANTHROPIC_AUTH_TOKEN、各档模型(Opus/Sonnet/Haiku 都指向本地模型)以及上下文窗口,然后直接 exec 进 Claude Code:
Launching Claude Code with model Qwen3.6-35B-A3B-3bit-MLX...
Auto-compact window: 262,144 tokens
注意那行 Auto-compact window: 262,144 tokens——这就是 omlx 的 Context Scaling 在起作用,它会缩放上报给 Claude Code 的 token 计数,让自动压缩(auto-compact)在合适的时机触发,避免小上下文模型被 Claude Code 的长上下文逻辑搞崩。这点第 4.4 节细说。
2.6 手动接入:环境变量方式(含局域网共享)
如果你想完全掌控配置,或者想从另一台机器连过来用,就走环境变量这条路。Claude Code 认 ANTHROPIC_BASE_URL 这套变量,把它指向 omlx 即可:
ANTHROPIC_BASE_URL='http://127.0.0.1:8000' \
ANTHROPIC_AUTH_TOKEN='XZL-AI' \
ANTHROPIC_DEFAULT_OPUS_MODEL='Qwen3.6-35B-A3B-3bit-MLX' \
ANTHROPIC_DEFAULT_SONNET_MODEL='Qwen3.6-35B-A3B-3bit-MLX' \
ANTHROPIC_DEFAULT_HAIKU_MODEL='Qwen3.6-35B-A3B-3bit-MLX' \
API_TIMEOUT_MS=3000000 \
CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC=1 \
claude
逐行拆解这几个变量:
| 变量 | 作用 |
|---|---|
ANTHROPIC_BASE_URL |
把 Claude Code 的请求指到本地 omlx,而不是 Anthropic 官方 |
ANTHROPIC_AUTH_TOKEN |
鉴权 token,与 omlx serve --api-key 设的值对应(本地随便填一个,但要一致) |
ANTHROPIC_DEFAULT_*_MODEL |
把 Opus / Sonnet / Haiku 三档都映射到你的本地模型 |
API_TIMEOUT_MS=3000000 |
关键:本地首次 prefill 慢,超时拉到 50 分钟,避免读超时直接断开 |
CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC=1 |
关掉非必要的遥测流量,纯本地更干净 |
局域网共享是个很实用的玩法:把 ANTHROPIC_BASE_URL 里的 127.0.0.1 换成这台 Mac 的局域网 IP(或 mDNS 主机名),同一个网里的其它设备就能共用这台机器的算力:
# 用局域网 IP
ANTHROPIC_BASE_URL='http://10.0.38.199:8000' ... claude
# 或用 .local 主机名(macOS 默认开了 mDNS)
ANTHROPIC_BASE_URL='http://xzls-MacBook-Pro.local:8000' ... claude
我实测三种地址(
127.0.0.1/ 局域网 IP /.local主机名)都能连上。想给团队搭一台"本地推理节点",这就是最简单的方案——一台 M 系列高配 Mac,全办公室蹭。当然,对外开放前记得用--api-key设个真正的密钥。
到这里,你已经在自己的 Mac 上跑起一个由本地模型驱动的 Claude Code 了。下面我们再回过头搞懂:它凭什么能跑得动?
3、为什么需要 omlx:本地编码 Agent 的真实痛点
要理解 omlx 的价值,得先理解编码 Agent 为什么是推理服务器的"压力测试机"。
3.1 编码 Agent 的请求模式:前缀在不停漂移
普通聊天是"一问一答",上下文线性增长。但编码 Agent(Claude Code)一个任务里会发几十上百次请求,每次请求都长这样:
[超长系统提示] + [一堆工具定义] + [项目文件内容] + [历史对话] + [本轮新增]
前面那一大段(系统提示 + 工具定义 + 文件内容)几乎不变,是典型的"长前缀"。理想情况下,这段的 KV 缓存应该被复用。
但问题在于:Agent 会编辑文件、读新文件、压缩历史,导致前缀中间某个位置发生变化。一旦中间变了,从变化点往后的 KV 缓存就全失效了。
3.2 KV 缓存一失效,就要重算整段上下文
这就是绝大多数本地 MLX 服务器的硬伤:它们的 KV 缓存是"全有或全无"的——前缀只要不完全匹配,就当作全新请求,把整个上下文重新做一遍 prefill。
编码场景的上下文动辄几万 token,重算一次 prefill 在本地就是几十秒。几轮下来,体验如下:
- 第 1 轮:还行,几秒响应;
- 第 5 轮:开始卡,每次 20~30 秒;
- 第 10 轮:每次 30~90 秒,人已经去泡咖啡了。
这就是为什么"本地跑 Claude Code"长期被认为是伪需求——不是模型不行,是缓存机制扛不住 Agent 的请求模式。
omlx 的解法是把 KV 缓存做成分块 + 分层 + 可持久化的:算过的块即使被挤出内存,也会落到 SSD;下次前缀命中,直接从盘里捞回来。社区实测缓存命中率能到 96%,TTFT 从 30~90 秒压到 1~3 秒。这是 omlx 区别于其它所有方案的根本点,第 4.1、5 节展开。
3.3 MLX vs Ollama(llama.cpp):Apple Silicon 上的性能差距
很多人 Mac 上跑本地模型第一反应是 Ollama。Ollama 好用,但它底层是 llama.cpp + Metal 后端,并不是为 Apple 统一内存深度优化的。
而 omlx 用的是 Apple 官方的 MLX 框架,它原生面向统一内存架构设计。同一台机器、同一个模型,差距相当明显:
- Token 生成:MLX 比 llama.cpp 快约 1.5~2 倍;
- Prompt 处理(prefill):MLX 快约 3~5 倍。
对编码 Agent 来说,prompt 处理速度才是决定体验的关键——因为每个请求都裹着臃肿的系统提示和工具定义,prefill 量极大。这也是为什么"MLX + SSD 缓存"这套组合拳特别适合编码 Agent。
具体的性能对比数字我放在第 7 节列表呈现。
4、核心功能详解
4.1 两级 KV 缓存(Hot RAM + Cold SSD)——omlx 的杀手锏
这是 omlx 的灵魂功能。它把 KV 缓存切成固定大小的块(block),放在两个层级里:
- 热层(Hot / RAM):高频访问的缓存块留在内存,访问最快;
- 冷层(Cold / SSD):当内存热层满了,把块以 safetensors 格式下放到 SSD。
关键在于:当一个新请求带着相同前缀进来,omlx 会去冷层把对应的块从硬盘读回来恢复,而不是重新计算。而且 safetensors 落盘的缓存重启服务后依然有效——你昨天跑的项目,今天重启电脑后第一次请求依然能命中缓存。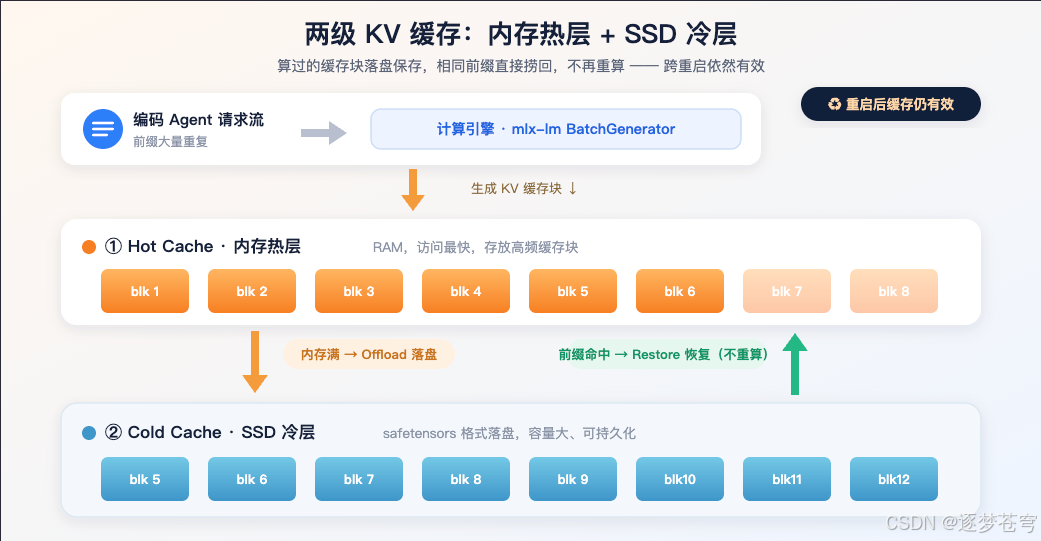
这套设计直接把"KV 缓存"从一个内存里的易失资源,变成了可持久化、可跨会话复用的资产——这正是它能扛住编码 Agent 的根本。
4.2 连续批处理 Continuous Batching
omlx 基于 mlx-lm 的 BatchGenerator 实现了连续批处理:多个并发请求可以动态地拼进同一个 batch 一起算,谁先生成完谁先返回,新请求随时插入,不用等整批结束。prefill 和 completion 的 batch 大小都可配。
并发可以通过参数调:
omlx serve --model-dir ~/.omlx/models --max-concurrent-requests 16
这意味着你可以一台 Mac 同时服务多个 Claude Code 会话(比如团队共享场景),而不是排队串行。
4.3 多模型服务与内存守护
omlx 能在同一个服务里同时管理多种模型:LLM、视觉语言模型(VLM)、embedding 模型、reranker——做 RAG 的同学会很喜欢,一个服务把"生成 + 向量化 + 重排"全包了。
内存管理上它做得很克制:
- LRU 自动驱逐:内存吃紧时,自动卸载最久没用的模型;
- 模型 Pin:把常用模型钉住,不让它被驱逐;
- 进程内存守护(Memory Guard):默认把上限设为"系统内存 − 8GB",防止把整机内存吃爆导致系统卡死。
内存守护可以手动调档:
# 保守模式
omlx serve --model-dir ~/.omlx/models --memory-guard safe
# 或直接指定上限 48GB
omlx serve --model-dir ~/.omlx/models --memory-guard-gb 48
实战提示:一次只跑一个大模型。多个模型同时加载会抢 GPU,即便是 48GB 的机器也可能出现随机超时。
4.4 Claude Code 专项优化
omlx 不只是"能连上 Claude Code",它针对 Claude Code 做了两个专项优化,这是它和通用推理服务器拉开差距的地方:
- Context Scaling(上下文缩放):Claude Code 是按官方大模型的超长上下文逻辑设计的,会根据 token 数决定何时触发 auto-compact(自动压缩历史)。本地小上下文模型如果如实上报 token 数,压缩时机会全乱。omlx 会缩放上报的 token 计数,让 auto-compact 在正确的时机触发——就是
omlx launch时打印的那行Auto-compact window: 262,144 tokens。 - SSE keep-alive:本地首次 prefill 很慢(长上下文要几秒),omlx 在流式响应里持续发 keep-alive 心跳,防止 Claude Code 因读超时直接断连。这和第 2.6 节那个
API_TIMEOUT_MS=3000000是一套组合拳。
这两点看着小,但正是"能用"和"难用"的分水岭。
4.5 菜单栏 App 与 Admin 控制台
如果你装的是 .dmg 版本,omlx 是一个原生 macOS 菜单栏 App(Swift/SwiftUI 写的,不是 Electron 套壳),可以在菜单栏里直接管理服务、监控模型状态、下载模型,不用开终端。
无论哪种安装方式,都有一个 Web 版 Admin 控制台(http://localhost:8000/admin),功能相当全:
- 实时监控性能(吞吐、内存占用);
- 模型管理(加载/卸载/Pin/设 TTL);
- 内置 Chat,直接和已加载的模型对话;
- 一键 Benchmark 跑性能测试;
- 从 HuggingFace 搜索下载模型;
- 一键接入 OpenClaw、OpenCode、Codex、Copilot、Pi 等多种编码 Agent。
4.6 API 兼容:OpenAI + Anthropic 双协议
omlx 是 OpenAI 和 Anthropic API 的双协议 drop-in 替换。这意味着几乎所有支持自定义 base_url 的工具都能直接接:
| 端点 | 用途 |
|---|---|
POST /v1/chat/completions |
OpenAI 风格对话(流式) |
POST /v1/completions |
文本补全 |
POST /v1/messages |
Anthropic Messages API(Claude Code 走这个) |
POST /v1/embeddings |
文本向量化 |
POST /v1/rerank |
文档重排 |
GET /v1/models |
列出可用模型 |
它还支持 Anthropic 的 adaptive thinking、流式 usage 统计、视觉输入,以及 Llama / Qwen / DeepSeek / Gemma / GLM / Kimi K2 等主流模型家族的工具调用(Function Calling)和结构化输出。想确认当前加载了哪些模型,curl 一下即可:
curl http://127.0.0.1:8000/v1/models -H "Authorization: Bearer XZL-AI"
5、技术原理:分页 SSD 缓存是怎么工作的
前面讲了"是什么",这一节讲"怎么实现的"。理解了架构,你才知道怎么调参、怎么排错。
5.1 整体架构一图看懂
omlx 的核心是一个 FastAPI 服务,请求进来后流经一条清晰的链路:
- FastAPI Server:对外暴露 OpenAI / Anthropic 兼容接口;
- EnginePool:多模型池,负责 LRU 驱逐与加载,下挂
BatchedEngine(LLM)、VLMEngine(视觉)、EmbeddingEngine、RerankerEngine; - Scheduler:FCFS 调度器,驱动 mlx-lm 的
BatchGenerator做连续批处理; - Cache Stack:缓存栈,包含
PagedCacheManager(管理 GPU 上的缓存块)、Hot Cache(内存热层)、PagedSSDCacheManager(SSD 冷层); - ProcessMemoryEnforcer:全局内存上限与 TTL 检查。
5.2 分页 KV 缓存 + 前缀共享 + COW
omlx 借鉴了 vLLM 的 PagedAttention 思路,把 KV 缓存切成固定大小的块来管理,带来三个好处:
- 分页(Paging):缓存不再是一整块连续内存,而是离散的块,内存碎片少、利用率高;
- 前缀共享(Prefix Sharing):多个请求如果共享同一段前缀(比如同一个系统提示),它们可以共用这部分缓存块,不重复存储;
- 写时复制(Copy-on-Write, COW):当某个请求要在共享块上做修改时,才复制出独立副本——这恰好对应第 3.1 节说的"前缀漂移",漂移点之前的块继续共享,只有漂移点之后才新建。
这套机制让"前缀大部分相同、只有局部变化"的编码 Agent 请求,能最大化复用已有缓存。
5.3 冷热分层与 safetensors 持久化
分页解决了"怎么高效管理块",冷热分层解决了"块放不下了怎么办":
- GPU 显存(统一内存)里放正在用的块;
- 内存热层放高频块;
- 内存满了,块以 safetensors 格式序列化到 SSD 冷层。
safetensors 是 HuggingFace 那套安全、快速的张量序列化格式,落盘和读回都很快。配合可指定的缓存目录:
omlx serve --model-dir ~/.omlx/models \
--paged-ssd-cache-dir ~/.omlx/cache \
--hot-cache-max-size 20%
--hot-cache-max-size 20% 控制热层占内存的比例;--paged-ssd-cache-dir 指定冷层落盘位置。整个缓存生命周期跨重启依然有效——这是 omlx 能让"今天接着昨天的活儿干"的关键。
6、实测踩坑与排错
这一节都是我自己装的时候真实遇到的,省得你再踩一遍。
6.1 brew services 没有 status 子命令
我习惯性地敲了:
brew services status omlx
# Error: Invalid usage: unknown subcommand: `status`
brew services 根本没有 status 这个子命令。查服务状态要用:
brew services info omlx # 看单个服务详情
brew services list # 列出所有服务及状态
记住合法子命令就这几个:start / stop / restart / run / kill / list / info / cleanup。
6.2 Bootstrap failed: 5: Input/output error
这个坑更隐蔽。我当时反复 stop / start 调试,敲快了几次,突然蹦出:
brew services start omlx
# Bootstrap failed: 5: Input/output error
# Error: Failure while executing; `/bin/launchctl bootstrap gui/501 .../homebrew.mxcl.omlx.plist` exited with 5.
原因:brew services 底层是 macOS 的 launchctl。短时间内频繁 start/stop,会让 launchd 的服务注册状态没来得及清理,下一次 bootstrap(注册服务)时就和残留状态冲突,报 I/O error。
解决办法(任选其一,从简到繁):
# 方法 1:直接 restart,让它先彻底 stop 再 start(我最后就是这么解决的)
brew services restart omlx
# 方法 2:手动把残留的服务注册踢掉,再重新 start
launchctl bootout gui/$(id -u)/homebrew.mxcl.omlx 2>/dev/null
brew services start omlx
# 方法 3:实在不行,stop 后等几秒再 start,别连续猛敲
brew services stop omlx && sleep 5 && brew services start omlx
经验:调试期别用后台服务反复折腾,直接
omlx serve前台跑、Ctrl+C退,调好了再交给brew services常驻。
6.3 模型选型与内存建议
模型选不对,体验直接劝退。结合社区实测和我自己的使用,给几条硬建议:
- 优先选 MoE 架构:像
gpt-oss-20b(20B 总参 / 仅 3.6B 激活)、Qwen3.x-A3B系列。激活参数少,出字快——社区在 M4 Pro(48GB) 上gpt-oss-20b-MXFP4-Q8实测 63 tok/s、亚秒级 TTFT。我用的Qwen3.6-35B-A3B-3bit也是同样的 MoE 思路(35B 总参、约 3B 激活)。 - 认准工具调用是否靠谱:编码 Agent 强依赖 Function Calling。社区实测里,
Qwen2.5-Coder-32B的工具调用会退化成纯文本(不可用),Qwen3-Coder-30B的 thinking token 会泄漏到可见输出(很吵)。选模型一定要实测工具调用,别只看跑分。 - 内存要留余量:
gpt-oss-20b带 128K 上下文大约吃 12GB;务必关掉 Chrome 这类吃内存大户(动辄 4~8GB)再加载大模型。 - 一次只加载一个大模型:多模型抢 GPU 会导致随机超时。
- 别在 Docker 里跑:macOS 上 Docker 拿不到 Metal GPU,速度断崖式下跌。
6.4 日志在哪看
排错离不开日志,omlx 的日志分两处:
# Homebrew 后台服务的日志
tail -f $(brew --prefix)/var/log/omlx.log
# omlx 服务器本身的日志
tail -f ~/.omlx/logs/server.log
7、性能实测对比
下面这组数据来自社区在 M4 Pro / 48GB 同一台机器、同模型下的对比测试(Ollama vs omlx),很有代表性:
| 指标 | Ollama(llama.cpp) | oMLX | 差距 |
|---|---|---|---|
| Token 生成 | 2030 tok/s | 36~63 tok/s | ~2x |
| Prompt 处理(prefill) | 5080 tok/s | ~349 tok/s | 47x |
| KV 缓存效率 | 无 | 96% | — |
| 内存占用(同模型) | ~16 GB | ~12 GB | 更省 |
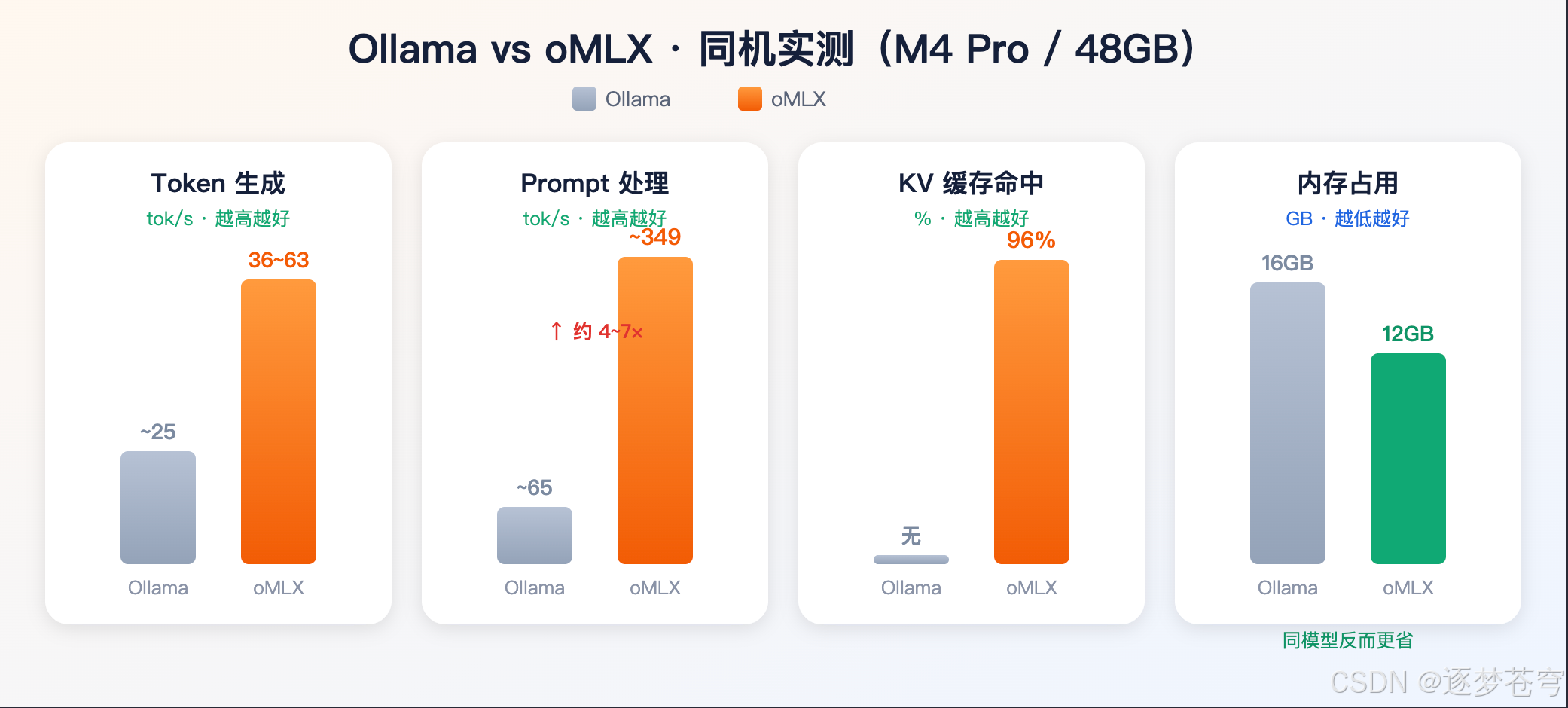
几个值得划重点的结论:
- Prompt 处理快 4~7 倍是对编码 Agent 影响最大的指标——因为每次请求都裹着臃肿的系统提示和工具定义;
- **缓存命中率 96%**意味着:大段不变的上下文,第二次起几乎"白嫖",TTFT 从几十秒降到 1~3 秒;
- MLX 的张量布局更高效,同一个模型反而更省内存(12GB vs 16GB)。
8、总结与适用边界
绕了一圈,回到开头那个问题:本地模型能不能带得动 Claude Code?
我的结论是:在 omlx 这套方案下,第一次变成了"真能用",而不是"勉强能跑"。 它的价值不在于"又一个本地推理服务器",而在于它精准命中了编码 Agent 的命门——用分页 SSD KV 缓存解决了前缀漂移导致的反复重算,再叠加 MLX 在 Apple Silicon 上的硬件红利和 Claude Code 专项优化(Context Scaling + SSE keep-alive),把体验从"等到泡完咖啡"拉回到"基本跟手"。
它适合什么场景:
- ✅ Apple Silicon Mac(尤其 32GB+ 的 M Pro/Max/Ultra),想白嫖本地算力跑编码 Agent;
- ✅ 注重隐私 / 离线 / 数据不出本机的开发;
- ✅ 想用一台高配 Mac 给小团队当共享本地推理节点(局域网接入 + API Key);
- ✅ 做 RAG,需要 LLM + Embedding + Reranker 一站式本地服务。
它的边界(要诚实):
- ⚠️ 本地小模型在复杂多文件推理、微妙 Bug 调试上仍远不如云端前沿模型,别指望它替代 Opus 干硬活儿;
- ⚠️ 适合的是:快速编辑、样板代码生成、写测试、代码解释、简单重构这类"速度比深度更重要"的任务;
- ⚠️ 仅限 Apple Silicon,Intel Mac 和其它平台无缘。
一句话收尾:如果你手里有一台闲置算力的 M 系列 Mac,omlx 值得装上试一次——它可能会改变你对"本地编码 Agent"的固有印象。
本文涉及的命令均基于 omlx 0.4.0 实测,新版本参数可能微调,以官方仓库 github.com/jundot/omlx 为准。
参考资料:
- omlx 官方仓库:github.com/jundot/omlx
- MLX 社区关于 oMLX 的讨论:ml-explore/mlx Discussion #3203
- 社区实测(opencode + omlx):agileguy.ca/opencode-fully-local
- MLX 模型库:huggingface.co/mlx-community
🚀 持续探索 AI 与前沿技术 分享大模型应用、软件开发实战与行业洞察。 欢迎关注 【龙哥AI】,加入 7000+ 技术同行的交流圈! 🌟 探索技术边界,让开发更有效率 |
 |

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐

 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)