全网最细梳理:Transformer原理解密,如何利用DeepSpeed训出百亿模型,以及vLLM如何实现极致推理加速
本文将带你进行一次硬核的技术溯源。我们将从Transformer的底层逻辑出发,揭示并行计算技术(数据并行、模型并行、ZeRO)是如何专门为Transformer设计的。接着,我们将深入vLLM的核心,独家解析PagedAttention如何借鉴操作系统的虚拟内存机制,彻底解决KV Cache的显存碎片化问题。文章不仅涵盖DeepSpeed的Stage 3优化策略,还包含vLLM Continuo
大家好,我是你们的技术伙伴。👋
在2026年的今天,我们每天都在和ChatGPT、Claude、以及国产大模型打交道。但作为一个开发者,我们不能只停留在“用”的层面,更要理解其背后的“肌肉”与“骨骼”。
目前的大模型几乎全部基于 Transformer 架构。这个架构虽然强大,但它有两个致命的痛点:吃显存(Memory Hungry) 和 计算量大(Computation Heavy)。
为了解决这两个问题,业界发展出了两大神器:
- 训练侧:DeepSpeed —— 微软推出的“显存粉碎机”。
- 推理侧:vLLM —— 加州大学伯克利分校推出的“推理加速器”。
今天,我将带你打通从 Transformer原理 到 并行训练,再到 高效推理 的任督二脉。
本文核心硬核点:
- 基石:一句话讲透Transformer(多头注意力与参数爆炸)。
- 训练:DeepSpeed如何通过ZeRO策略把显存占用降低90%。
- 推理:vLLM如何通过PagedAttention解决“显存碎片化”。
- 趋势:Continuous Batching如何实现GPU利用率100%。
🧬 第一部分:基石——为什么是Transformer?
在谈论并行之前,我们必须先理解为什么大模型需要并行?
Transformer的核心是 Self-Attention(自注意力)机制。
公式如下:
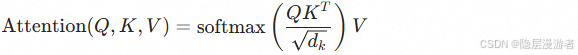
这意味着什么?
- 参数量巨大:Transformer的参数量通常在亿(B)到千亿(T)级别。例如,一个175B(GPT-3)的模型,仅参数本身就需要 350GB 的显存(FP16格式)。
- 中间状态更多:除了参数,训练过程中产生的梯度和优化器状态(如Adam)会占用更多的空间。
结论:单张GPU(哪怕是80GB的H100)根本放不下整个模型。我们必须把“蛋糕”切开。 这就是并行计算的由来。
🏗️ 第二部分:训练之道——DeepSpeed与ZeRO
DeepSpeed的核心目标只有一个:在有限的显存下,训练尽可能大的模型。
根据文档中的分析,大模型训练面临两大问题:效率和显存。DeepSpeed通过混合并行和ZeRO(Zero Redundancy Optimizer) 技术完美解决了这些问题。
1. 并行策略的演进
- 数据并行 (DP):最简单粗暴。把模型复制到多张卡上,各算各的梯度。缺点:每张卡都要存一份完整的模型,显存炸裂。
- 模型并行 (MP/TP):把模型切开。比如Layer 1在GPU0,Layer 2在GPU1。缺点:卡之间通讯太频繁,速度慢。
- DeepSpeed的杀手锏:ZeRO
2. DeepSpeed ZeRO 优化策略(显存优化的核心)
ZeRO的核心思想是:消除冗余。在传统数据并行中,每张卡都存了完整的优化器状态、梯度和参数,这是巨大的浪费。
DeepSpeed将显存优化分为了三个阶段(Stage):
| Stage | 优化对象 | 显存效率 | 原理简述 |
|---|---|---|---|
| Stage 1 | 优化器状态 | 中 | 将优化器状态(如Adam的动量)分片存储。 |
| Stage 2 | 梯度 + 优化器 | 高 | 在Stage 1基础上,梯度也分片存储。 |
| Stage 3 | 参数 + 梯度 + 优化器 | 极高 | 参数也分片存储。每张卡只存一部分参数,需要时才通信。 |
实战建议:
在2026年的今天,训练百亿/千亿模型,DeepSpeed Stage 3 是标配。它通过复杂的通信机制,换取了极致的显存节省,让我们能在有限的机器上跑起巨大的模型。
⚡ 第三部分:推理之术——vLLM与PagedAttention
如果说训练是“十月怀胎”,那么推理就是“一朝分娩”。推理面临的最大敌人是 KV Cache(键值缓存)。
1. 推理的瓶颈:显存碎片化
Transformer的自回归特性决定了它需要缓存历史的K和V向量。
- 问题1(容量):生成的文本越长,KV Cache越大。
- 问题2(碎片):传统推理框架需要预先分配连续的显存空间。就像停车场,如果车(请求)来来去去,会留下很多小缝隙,导致大车(长文本请求)进不来,造成显存浪费(内部碎片)和OOM(外部碎片)。
2. vLLM的革命:PagedAttention
vLLM的核心创新在于 PagedAttention,它借鉴了操作系统的虚拟内存管理机制。
- 传统方式:要求一块连续的大内存。
- PagedAttention:将KV Cache切分为固定大小的 Block(块)。
- 逻辑上:是一个连续的序列。
- 物理上:可以分散在显存的各个角落。
这带来了什么?
- 消除碎片:只要有零散的小空闲块,就能拼凑出大空间。
- 显存利用率提升:相比HuggingFace Transformers,vLLM的吞吐量(Throughput)可以提升 2-4倍。
3. Continuous Batching(连续批处理)
传统的批处理(Batching)像老式电梯:上来一批人,送到底,再回来接下一批。中间等待时间GPU是空闲的。
Continuous Batching 像流水线:
- GPU几乎不空闲。
- 一旦一个请求生成了结束符(EOS),立刻释放显存,马上塞入新请求。
- PagedAttention 为这种动态调度提供了底层显存支持。
🛠️ 第四驱:实战代码——从理论到代码
理论讲完,我们来看看在代码层面,这些技术是如何体现的。
1. DeepSpeed 配置文件 (JSON)
这是启用DeepSpeed Stage 3的关键配置。注意 zero_optimization 部分的设置。
{
"train_batch_size": 8,
"gradient_accumulation_steps": 1,
"optimizer": {
"type": "AdamW",
"params": {
"lr": 5e-5,
"weight_decay": 0.01
}
},
"fp16": {
"enabled": true
},
"zero_optimization": {
"stage": 3,
"overlap_comm": true, // 重叠通信
"contiguous_gradients": true,
"reduce_bucket_size": 5e8,
"stage3_prefetch_bucket_size": 5e8,
"stage3_param_persistence_threshold": 1e6,
"stage3_max_live_parameters": 1e9
},
"activation_checkpointing": {
"partition_activations": true,
"cpu_checkpointing": true,
"contiguous_memory_optimization": false,
"number_checkpoints": null,
"synchronize_checkpoint_boundary": false
}
}2. vLLM 推理服务代码 (Python)
vLLM的API设计非常简洁,几乎是对标HuggingFace的。你只需要替换几行代码,就能获得巨大的性能提升。
from vllm import LLM, SamplingParams
# 1. 初始化LLM
# tensor_parallel_size=4 表示使用4张卡进行张量并行
# dtype="half" 使用半精度
# max_model_len=4096 设置最大上下文长度
llm = LLM(model="meta-llama/Llama-3-8b",
tensor_parallel_size=4,
dtype="half",
max_model_len=4096)
# 2. 生成参数配置
sampling_params = SamplingParams(temperature=0.7,
top_p=0.95,
max_tokens=100)
# 3. 输入提示词
prompts = [
"请解释一下量子纠缠是什么?",
"写一首关于春天的诗。"
]
# 4. 生成输出 (vLLM自动处理PagedAttention和Continuous Batching)
outputs = llm.generate(prompts, sampling_params)
for output in outputs:
print(f"Prompt: {output.prompt}")
print(f"Generated text: {output.outputs[0].text}")
print("-" * 50)🏁 结语
回顾全文,我们可以看到一条清晰的技术脉络:
- Transformer 的结构决定了它必须面对巨大的显存压力。
- DeepSpeed 通过 ZeRO 技术,将显存分片,解决了训练时的“放不下”问题。
- vLLM 通过 PagedAttention(分页注意力),将显存分块,解决了推理时的“碎片化”问题。
在2026年,掌握这些底层优化技术,远比只会调用API更有价值。希望这篇博客能帮你建立起大模型底层架构的“上帝视角”。
如果你觉得有用,希望点赞、收藏、关注!

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐

 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)