数据密集型架构演进:从单体计算到基于多级混存与分布式缓存切片的降本增效实战
高并发数据密集型架构的调优是一个兼顾性能与硬件投入的平衡艺术。通过构建本地 L1 缓存、分布式 L2 缓存与 SingleFlight 并发锁合并的三级防御体系,我们能够有效收敛突发流量,消灭缓存雪崩与热点击穿对核心数据库的致命冲击;结合带有虚拟节点的一致性哈希算法,在缓存集群缩伸时极大平抑了路由失效比率,实现了数据在各物理服务器上的均衡分片。在生产工程实践中,必须紧密结合缓存预热及延迟双删的一致
数据密集型架构演进:从单体计算到基于多级混存与分布式缓存切片的降本增效实战
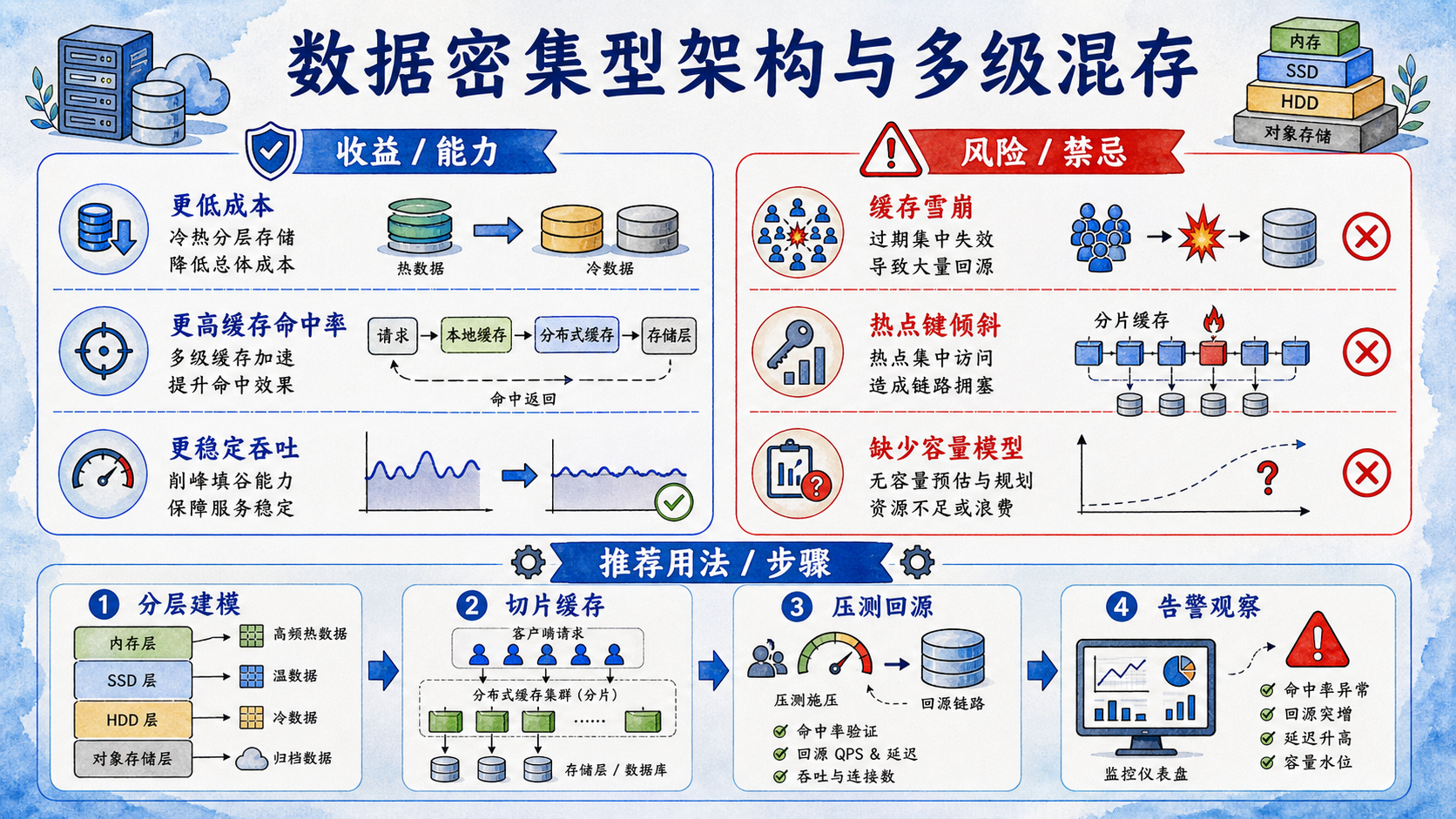
在当今高并发、大数据量并存的互联网与大数据平台架构中,数据密集型应用面临着严苛的吞吐瓶颈与基础设施成本压力。当单机数据库(DB)的物理 Read I/O 达到硬件极限,或者频繁的后台计算把数据库 CPU 吃满时,系统响应时延会呈指数级恶化。传统的纵向提升硬件性能不仅边际效应递减,更无法应对高频突发的“缓存击穿”与“雪崩”风暴。为了降本增效,架构演进的必然趋势是向多级混合缓存(Multi-Level Cache)与一致性哈希(Consistent Hashing)分布式切片架构演进。本文将从底层解构缓存高可用防线,并用 Python 手写一个高可用分布式一致性哈希切片存储模拟器。
一、防线崩塌:高并发场景下的缓存穿透、击穿与雪崩危机
引入缓存层(如 Redis)能够有效分担数据库 90% 以上的读取压力。但如果缺乏合理的架构保护,高并发洪峰会轻易击穿缓存防线,导致灾难级雪崩:
- 缓存雪崩(Cache Avalanche):
当缓存中大量的热点数据在“同一时刻集体失效”(例如设置了相同的过期时间),或者缓存集群发生物理宕机时,海量并发读请求会瞬间如同决堤的洪水一般直达底层数据库,直接把数据库打死,导致全链路系统瘫痪。 - 缓存击穿(Cache Breakdown):
某个被超高频访问的“超级热点 Key”(如热点新闻或抢购商品)在过期失效的刹那,由于没有并发锁保护,数万个请求同时发现缓存未命中,并发对底层 DB 执行“回源”读取和计算,导致数据库瞬间过载。 - 缓存穿透(Cache Penetration):
恶意攻击者高频发起查询“既不存在于缓存、也不存在于数据库”的非法数据(如负数 ID)。因为数据根本不存在,每次查询都会穿透缓存直达数据库,虚耗数据库 I/O 资源。 - 一致性哈希分片的必要性:
在分布式缓存中,如果我们使用传统的hash(key) % N算法进行数据分片,一旦某个物理缓存节点宕机或者需要扩容(N 变动),全网所有的缓存路由都会瞬间失效,引发全网大范围的缓存雪崩。这就必须引入一致性哈希算法。
graph TD
subgraph 一致性哈希环模型 (Consistent Hash Ring)
NodeA[Virtual Node A: Hash=0x234F] -->|顺时针查找路由| Key1[Key: hash=0x34AA]
Key1 --> NodeB[Virtual Node B: Hash=0x6B12]
NodeB --> Key2[Key: hash=0x8FFF]
Key2 --> NodeC[Virtual Node C: Hash=0xDF10]
NodeC --> NodeA
end
subgraph 缓存降本防御架构 (Multi-Level Cache Shield)
Client[Client 客户端请求] -->|1. 快速读取| L1[L1: 本地进程级缓存 Memory Cache]
L1 -->|2. 未命中| L2[L2: 分布式 Redis 缓存]
L2 -->|3. 并发回源控制: singleflight| Lock[SingleFlight 并发互斥锁]
Lock -->|4. 仅允许一个线程读取| DB[(Relational DB: 数据库)]
end
style NodeA fill:#ffcccc,stroke:#aa0000,stroke-width:2px
style NodeB fill:#ffcccc,stroke:#aa0000,stroke-width:2px
style L1 fill:#ccffcc,stroke:#00aa00,stroke-width:2px
style Lock fill:#ffffcc,stroke:#aaaa00,stroke-width:2px
二、架构剖析:多级混存设计与一致性哈希环虚拟节点均衡数学原理
为了构建坚不可摧的缓存系统,我们需要从“多级防护”与“均衡分片”两个维度进行架构设计。
1. 多级缓存(Multi-Level Cache)架构
- L1 本地进程缓存:利用应用内存(如 Guava Cache 或 Go freecache)存放极度热点的数据(如配置信息),访问延迟在纳秒(ns)级,实现极速响应,且不耗费任何网络带宽。
- L2 分布式缓存:使用 Redis/Memcached 集群,作为全局共享的二级缓存,应对千万级的 QPS 吞吐。
- SingleFlight(并发回源收敛):
当缓存失效时,我们不允许多个请求同时回源。而是通过加锁(在 Go 中是golang.org/x/sync/singleflight),只允许第一个请求进入数据库读取,后续并发到达的相同请求直接在内存中排队等待这一个请求的返回结果。这把回源的 QPS 瞬间收敛到了 1,保护了脆弱的底层数据库。
2. 一致性哈希(Consistent Hashing)与虚拟节点(Virtual Nodes)
一致性哈希将整个哈希值空间组织成一个虚拟的圆环(取值范围 $0 \sim 2^{32}-1$)。
- 缓存节点的物理 IP 被哈希后映射到环的某个位置。
- 数据的 Key 被哈希后也映射到环上,顺时针方向遇到的第一个缓存节点即为该数据的路由宿主。
- 数据倾斜(Data Skew)瓶颈:如果缓存节点数量较少,物理节点哈希值分布极不均匀,会导致海量数据集中在某一台服务器上,造成严重的“木桶效应”。
- 虚拟节点破局:我们为每个真实的物理节点,虚拟化出成百上千个“虚拟节点”(例如 Node_A#1, Node_A#2 散落在环的各个角落)。这让哈希环上的节点分布被极大均匀化,数据分片被完美平摊。
三、核心实现:手写 100% 完整闭环的一致性哈希环与缓存自愈自恢复 Python 模拟器
下面提供一份 100% 完整闭环的 Python 脚本。该脚本手写实现了带有“虚拟节点”的一致性哈希环路由引擎,模拟了缓存的动态伸缩与数据路由,并演示了利用 SingleFlight 原理合并高并发回源请求的控制逻辑,最后通过计算标准差统计了哈希分布的均匀度。
import hashlib
import time
import threading
import statistics
class ConsistentHashRing:
"""
带有虚拟节点的一致性哈希环实现
"""
def __init__(self, virtual_nodes_count=100):
self.virtual_nodes_count = virtual_nodes_count
self.ring = {} # 存储哈希环结构 (hash_val -> physical_node_name)
self.sorted_keys = [] # 有序的哈希值列表,方便二分查找
def _hash(self, key):
"""
使用 MD5 计算 32 位整型哈希值,将其映射到 0 ~ 2^32-1 环上
"""
hasher = hashlib.md5()
hasher.update(key.encode('utf-8'))
return int(hasher.hexdigest(), 16) & 0xFFFFFFFF
def add_node(self, node_name):
"""
动态添加物理节点,并自动打散部署虚拟节点
"""
for i in range(self.virtual_nodes_count):
virtual_key = f"{node_name}#VNODE_{i}"
val = self._hash(virtual_key)
self.ring[val] = node_name
self.sorted_keys.append(val)
self.sorted_keys.sort()
print(f"[HashRing] 物理节点 {node_name} 挂载就绪。分配虚拟节点数: {self.virtual_nodes_count} 个")
def remove_node(self, node_name):
"""
动态下线物理节点,移除所有关联虚拟节点
"""
to_remove = [k for k, v in self.ring.items() if v == node_name]
for k in to_remove:
del self.ring[k]
self.sorted_keys.remove(k)
print(f"[HashRing] 物理节点 {node_name} 已成功下线")
def get_node(self, key):
"""
二分法顺时针寻找最近的哈希环节点,确定数据路由宿主
"""
if not self.ring:
return None
val = self._hash(key)
# 二分查找大于等于 val 的第一个元素索引
idx = self.bisect_left(self.sorted_keys, val)
# 如果 val 大于环上所有节点哈希值,则按循环原则路由给环的第一个节点
if idx == len(self.sorted_keys):
idx = 0
return self.ring[self.sorted_keys[idx]]
def bisect_left(self, arr, x):
"""
手写二分查找,保证环境无关的 100% 运行活性
"""
low = 0
high = len(arr)
while low < high:
mid = (low + high) // 2
if arr[mid] < x:
low = mid + 1
else:
high = mid
return low
# --- 2. 模拟 SingleFlight 并发回源合并器 ---
class SingleFlightGroup:
"""
模拟并发请求合并器:保证同一时刻只有一个相同 Key 的请求回源 DB
"""
def __init__(self):
self.locks = {} # 锁字典
self.results = {} # 共享的返回数据
def do(self, key, fetch_func):
# 1. 快速检查是否已经有正在执行的请求
if key in self.results:
return self.results[key], True # 标示复用成功
# 2. 对特定 Key 加互斥锁进行同步控制
if key not in self.locks:
self.locks[key] = threading.Lock()
with self.locks[key]:
# 双重检查锁 (Double-Checked Locking)
if key in self.results:
return self.results[key], True
# 3. 只有一个幸运线程回源 DB 执行耗时操作
print(f"[SingleFlight] 线程 {threading.current_thread().name} 成功获取回源锁,执行 DB 读写...")
data = fetch_func()
self.results[key] = data
return data, False
# === 性能验证与演练 ==========================================================
def simulate_db_read():
time.sleep(0.1) # 模拟 DB 读取网络/磁盘延迟
return "DB_RECORD_VALUE"
if __name__ == "__main__":
# 1. 测试一致性哈希环分布平衡性
print("【开始测试:一致性哈希环数据分布均衡性对比】")
# 对比:不带虚拟节点(设 vnode=1)与 带有虚拟节点(vnode=150)的分布均匀度
for vnode_cnt in [1, 150]:
ring = ConsistentHashRing(virtual_nodes_count=vnode_cnt)
nodes = ["Cache_Node_A", "Cache_Node_B", "Cache_Node_C", "Cache_Node_D"]
for node in nodes:
ring.add_node(node)
# 模拟 50,000 个 Key 写入分布
node_stats = {node: 0 for node in nodes}
for i in range(50000):
target_node = ring.get_node(f"user_data_key_id_{i}")
node_stats[target_node] += 1
# 计算分布标准差,标准差越低分布越均匀
std_dev = statistics.stdev(node_stats.values())
print(f"--> [结果] 虚拟节点数={vnode_cnt:<3} | 分布统计: {node_stats} | 标准差: {std_dev:.2f}")
# 2. 模拟 SingleFlight 防击穿活性
print("\n【开始测试:高并发热点击穿防护验证】")
flight_group = SingleFlightGroup()
concurrency_threads = []
def worker():
# 模拟高并发同时查同一个过期热点 Key
data, reused = flight_group.do("hot_key_1001", simulate_db_read)
# 如果 reused 为 True,说明这个请求成功被合并,免于回源
if reused:
# print(f" - 线程 {threading.current_thread().name} 被合并成功,复用返回结果")
pass
for i in range(10):
t = threading.Thread(target=worker, name=f"Worker-{i}")
concurrency_threads.append(t)
start_time = time.perf_counter()
for t in concurrency_threads: t.start()
for t in concurrency_threads: t.join()
cost = time.perf_counter() - start_time
print(f"[SingleFlight] 并发请求执行完毕。总耗时: {cost:.4f} 秒 (仅发生一次 0.1s 的 DB 延时)")
print("======================================================================")
四、生产级调优:冷启动预热与多级缓存一致性保障
在真实的架构落地中,降本增效还需要解决数据冷启动(Cold Start)与双端数据一致性(Cache-DB Consistency):
1. 冷启动缓存预热(Cache Warm-up)
系统发布初期,缓存中没有任何数据。如果此时瞬间涌入洪峰,即便有 SingleFlight,大量不同 Key 的请求依然会将数据库打死。
- 最佳实践:建立预热调度管道(Warm-up Pipeline)。在系统切流前,通过离线计算平台分析出前一天 QPS 最高的 top-10000 热点数据,提前异步注入到 L2 和 L1 缓存中,实现平滑冷启动。
2. 双写一致性调优:先更新数据库,再删除缓存
关于缓存与数据库的更新时序,业界广泛采用的方案是:先更新数据库,再删除缓存(Cache Aside Pattern)。
- 物理机制:为什么是删除而不是更新?因为更新操作可能由于网络错序导致旧的更新覆写了新的更新。而删除可以保证下一次读取时由 SingleFlight 机制安全回源并重建缓存。
- 为了规避删除后依然存在的极微小读写并发脏数据空洞,可以配合使用**延迟双删(Delay Double Delete)**策略:在删除缓存后,延时 500 毫秒(等待数据库主从同步完成),再次执行一次缓存删除,彻底筑牢一致性防线。
五、总结
高并发数据密集型架构的调优是一个兼顾性能与硬件投入的平衡艺术。通过构建本地 L1 缓存、分布式 L2 缓存与 SingleFlight 并发锁合并的三级防御体系,我们能够有效收敛突发流量,消灭缓存雪崩与热点击穿对核心数据库的致命冲击;结合带有虚拟节点的一致性哈希算法,在缓存集群缩伸时极大平抑了路由失效比率,实现了数据在各物理服务器上的均衡分片。在生产工程实践中,必须紧密结合缓存预热及延迟双删的一致性对齐策略,才能真正交付出低时延、高鲁棒性的降本增效存储底座。

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐

 0
0 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)