端侧 AI 推理部署:操作系统层级的优化策略
·
端侧 AI 推理部署:操作系统层级的优化策略
一、引言痛点:端侧 AI 的现实约束
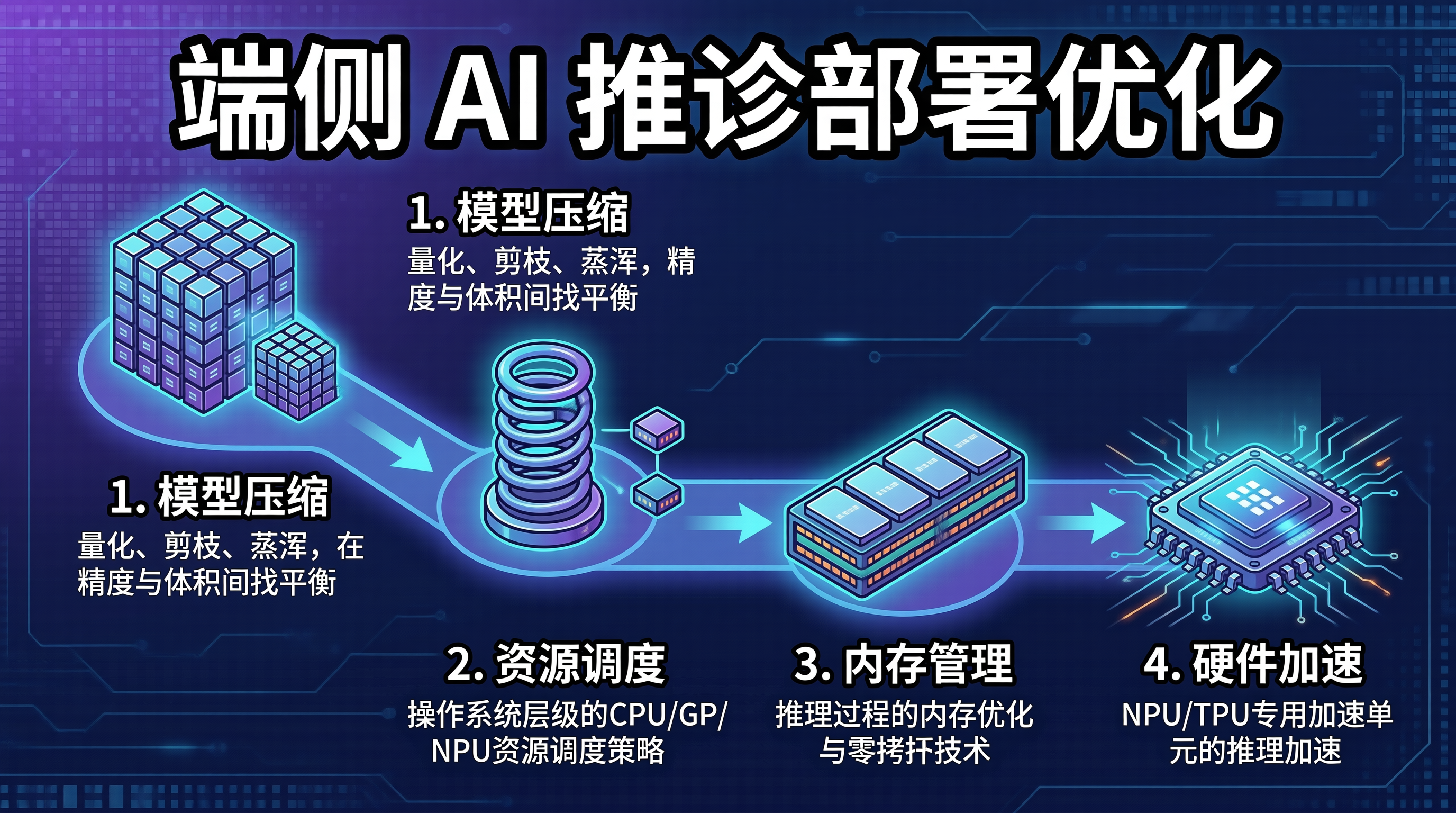
随着 AI 模型的规模化和应用场景的多元化,端侧 AI 部署(Edge AI)成为越来越重要的技术方向。相比云端 AI,端侧部署具有隐私性好、延迟低、无需网络连接等优势,但也面临严峻的资源约束:计算能力有限、内存受限、功耗敏感。
在移动端或嵌入式设备上部署一个大模型,需要在模型精度、推理速度和资源消耗之间找到精妙的平衡点。这不仅是模型压缩的技术问题,更涉及操作系统层级的资源调度、内存管理和硬件加速。
本文将系统讲解端侧 AI 推理部署的优化策略,从模型压缩、操作系统资源管理到硬件加速,为读者提供完整的工程化视角。
二、端侧 AI 的资源约束分析
2.1 资源瓶颈矩阵
端侧 AI 部署面临多重资源瓶颈:
flowchart TD
A[端侧 AI 资源瓶颈] --> B[计算资源]
A --> C[内存资源]
A --> D[存储资源]
A --> E[功耗/散热]
B --> B1[CPU算力有限]
B1 --> B2[不支持 BF16/FP16]
B --> B3[缺少 GPU/NPU]
C --> C1[物理内存有限]
C1 --> C2[模型参数无法全部加载]
C --> C3[带宽限制]
D --> D1[模型文件体积大]
D1 --> D2[APP 体积膨胀]
D --> D3[闪存读写速度]
E --> E1[发热降频]
E1 --> E2[续航影响]
E --> E3[用户体验下降]
style A fill:#fff3e0
2.2 推理延迟的分解
端到端推理延迟可以分解为多个阶段:
flowchart LR
A[输入预处理] --> B[模型推理]
B --> C[输出后处理]
A --> A1[数据清洗]
A1 --> A2[格式转换]
A2 --> A3[内存分配]
B --> B1[算子调度]
B1 --> B2[计算执行]
B2 --> B3[内存读写]
C --> C1[结果解析]
C1 --> C2[格式转换]
C2 --> C3[资源释放]
style B fill:#e3f2fd
三、模型压缩技术
3.1 量化(Quantization)
"""
模型量化:将 FP32 参数转换为低比特表示
量化方法:
1. INT8 量化:4x 模型体积压缩,2x 推理加速
2. INT4 量化:8x 模型体积压缩,但精度损失明显
3. 混合量化:部分层量化,部分层保留 FP16/BF16
"""
# PyTorch 动态量化示例
import torch
import torch.nn as nn
class QuantizedModel(nn.Module):
def __init__(self, original_model):
super().__init__()
self.quant = torch.quantization.QuantStub()
self.model = original_model
self.dequant = torch.quantization.DeQuantStub()
def forward(self, x):
x = self.quant(x)
x = self.model(x)
x = self.dequant(x)
return x
def apply_dynamic_quantization(model):
"""动态量化(权重 INT8, activations FP32)"""
quantized_model = torch.quantization.quantize_dynamic(
model, # 原始模型
{nn.Linear, nn.LSTM, nn.GRU}, # 要量化的层类型
dtype=torch.qint8
)
return quantized_model
# 静态量化示例(更激进的量化)
def apply_static_quantization(model, calibration_data):
"""静态量化(权重和 activations 都是 INT8)"""
# 1. Fuse layers
model_fused = torch.quantization.fuse_modules(
model,
[['conv1', 'bn1', 'relu']]
)
# 2. 指定量化配置
model_fused.qconfig = torch.quantization.get_default_qconfig('fbgemm')
torch.quantization.prepare(model_fused, inplace=True)
# 3. Calibration(使用代表性数据校准)
model_fused.eval()
with torch.no_grad():
for batch in calibration_data:
model_fused(batch)
# 4. 转换
quantized_model = torch.quantization.convert(model_fused, inplace=True)
return quantized_model
3.2 剪枝(Pruning)
"""
模型剪枝:移除不重要的神经元或连接
剪枝类型:
1. 非结构化剪枝:移除单个参数(细粒度)
2. 结构化剪枝:移除整个神经元/通道(粗粒度,更适合硬件加速)
剪枝流程:
1. 训练模型
2. 计算参数重要性(权重绝对值、梯度等)
3. 移除不重要参数
4. 微调恢复精度
"""
import torch
import torch.nn.utils.prune as prune
def magnitude_pruning(model, amount=0.3):
"""
幅值剪枝:移除权重绝对值最小的参数
Args:
model: 要剪枝的模型
amount: 剪枝比例(0-1)
"""
parameters_to_prune = []
for module in model.modules():
if isinstance(module, nn.Linear):
parameters_to_prune.append((module, 'weight'))
# L1 范数剪枝
prune.global_unstructured(
parameters_to_prune,
pruning_method=prune.L1Unstructured,
amount=amount,
)
return model
def structured_channel_pruning(model, channels_to_remove):
"""
结构化通道剪枝:移除整个卷积通道
更适合硬件加速,因为保持了规则的计算模式
"""
for name, module in model.named_modules():
if isinstance(module, nn.Conv2d):
# 计算通道重要性(BN 层的 gamma 参数)
if hasattr(module, 'bn') and module.bn is not None:
gamma = module.bn.weight.data.abs()
_, sorted_idx = torch.sort(gamma)
# 移除不重要的通道
num_to_remove = channels_to_remove
channels_to_keep = sorted_idx[num_to_remove:]
# 重新构建卷积层(简化示例)
new_conv = nn.Conv2d(
module.in_channels,
len(channels_to_keep),
module.kernel_size,
module.stride,
module.padding,
bias=module.bias is not None
)
3.3 知识蒸馏(Knowledge Distillation)
"""
知识蒸馏:用大模型(Teacher)指导小模型(Student)训练
核心思想:
- Student 学习 Teacher 的"软标签"(概率分布)
- 软标签包含类别间关系信息,比硬标签更有信息量
"""
import torch.nn.functional as F
class DistillationLoss(nn.Module):
def __init__(self, temperature=4.0, alpha=0.7):
super().__init__()
self.temperature = temperature
self.alpha = alpha
def forward(self, student_logits, teacher_logits, labels):
# 硬标签的交叉熵损失
hard_loss = F.cross_entropy(student_logits, labels)
# 软标签的 KL 散度损失
soft_teacher = F.softmax(teacher_logits / self.temperature, dim=1)
soft_student = F.log_softmax(student_logits / self.temperature, dim=1)
soft_loss = F.kl_div(soft_student, soft_teacher, reduction='batchmean') * (self.temperature ** 2)
# 组合损失
return self.alpha * hard_loss + (1 - self.alpha) * soft_loss
def distill(teacher_model, student_model, train_loader, epochs=10):
"""知识蒸馏训练流程"""
optimizer = torch.optim.Adam(student_model.parameters(), lr=0.001)
for epoch in range(epochs):
for batch, (inputs, labels) in enumerate(train_loader):
optimizer.zero_grad()
# Teacher 前向传播(不更新参数)
with torch.no_grad():
teacher_logits = teacher_model(inputs)
# Student 前向传播
student_logits = student_model(inputs)
# 计算蒸馏损失
loss = DistillationLoss()(student_logits, teacher_logits, labels)
loss.backward()
optimizer.step()
四、操作系统层级优化
4.1 内存管理优化
// Android/iOS 端的内存管理策略
/*
* 端侧 AI 推理的内存管理关键点:
* 1. 模型分片加载:避免一次性加载全部参数
* 2. 内存池复用:减少碎片化
* 3. 低内存时降级:降低精度换内存
*/
// 模型分片加载示例
void *load_model_partition(const char *model_path, int partition_idx) {
size_t partition_size = get_partition_size(model_path, partition_idx);
void *partition = mmap(NULL, partition_size, PROT_READ | PROT_WRITE,
MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);
// 从存储读取到内存
int fd = open(model_path, O_RDONLY);
lseek(fd, partition_idx * partition_size, SEEK_SET);
read(fd, partition, partition_size);
close(fd);
return partition;
}
// 内存复用策略
void inference_with_memory_reuse(Model *model, Tensor *input, Tensor *output) {
// 尝试复用上一个推理的中间缓冲区
if (model->intermediate_buffer &&
model->intermediate_buffer_size >= model->required_buffer_size) {
// 复用已有缓冲区
void *buffer = model->intermediate_buffer;
run_inference(model, input, output, buffer);
} else {
// 分配新缓冲区
void *buffer = malloc(model->required_buffer_size);
run_inference(model, input, output, buffer);
// 缓存缓冲区供下次使用
if (model->intermediate_buffer) free(model->intermediate_buffer);
model->intermediate_buffer = buffer;
model->intermediate_buffer_size = model->required_buffer_size;
}
}
4.2 CPU 调度优化
# Android 上的 CPU 调度策略
"""
关键优化点:
1. big.LITTLE 调度:大核处理推理计算,小核处理预处理
2. CPU 频率调度:推理期间锁定高频
3. 亲和性设置:将推理线程绑定到大核
"""
import os
def set_inference_cpu_affinity(cpu_mask=0b0010): # CPU 1 (大核)
"""
设置推理线程的 CPU 亲和性
"""
tid = os.gettid()
os.sched_setaffinity(tid, {1}) # 绑定到大核
def lock_cpu_frequency(min_freq=1800000):
"""
锁定 CPU 频率(需要 root 权限)
"""
# 写入 CPU 频率设置
with open('/sys/devices/system/cpu/cpu0/cpufreq/scaling_min_freq', 'w') as f:
f.write(str(min_freq))
def configure_inference_thread():
"""
配置推理线程的调度策略
使用 SCHED_FIFO 保证优先级
"""
import ctypes
SCHED_FIFO = 1
SCHED_PRIORITY = 50
class sched_param(ctypes.Structure):
_fields_ = [('sched_priority', ctypes.c_int)]
param = sched_param(SCHED_PRIORITY)
ctypes.CDLL('libc.so.6').sched_setscheduler(0, SCHED_FIFO, ctypes.byref(param))
五、硬件加速集成
5.1 NPU/GPU 加速
# 使用 Android NNAPI 进行硬件加速
"""
Android Neural Networks API (NNAPI)
- 安卓设备上的通用 AI 加速接口
- 自动调度到 GPU/NPU/DSP
"""
import androidnn
def run_with_nnapi(model_path, input_data):
# 加载模型
model = androidnn.load_model(model_path)
# 配置执行选项
options = androidnn.ExecutionOptions()
options.set_priority(androidnn.Priority.HIGH)
options.set_timeout(5000) # 5 秒超时
# 执行推理
result = androidnn.run(model, [input_data], options)
return result[0]
# iOS CoreML 加速
"""
CoreML 是 iOS 上的 AI 加速框架
自动使用 Neural Engine (ANE)
"""
import coremltools as ct
def convert_to_coreml(pytorch_model, input_shape):
# 转换为 CoreML 格式
traced_model = torch.jit.trace(pytorch_model, torch.zeros(input_shape))
coreml_model = ct.convert(
traced_model,
compute_units=ct.ComputeUnit.ALL # 使用 ANE/GPU/CPU
)
coreml_model.save('model.mlpackage')
return coreml_model
六、总结
端侧 AI 推理部署是一项系统性工程,需要从模型层到系统层的多维度优化。核心策略可以归纳为三点:
第一,模型压缩是基础。量化、剪枝、知识蒸馏是减少模型体积和计算量的核心技术,需要根据目标设备的特性选择合适的压缩策略。
第二,操作系统层级优化不可忽视。内存管理、CPU 调度、线程亲和性等系统层面的配置直接影响推理性能和功耗表现。
第三,硬件加速是性能倍增器。NPU、GPU、Neural Engine 等专用硬件可以显著提升推理性能,但需要适配相应的 SDK(NNAPI、CoreML、TensorRT)。
端侧 AI 的终极目标是在有限的资源约束下,提供接近云端体验的智能服务。

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐
 5
5 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)