【Linux】线程概念与控制
线程是操作系统能够进行运算调度的最小单位,它被包含在进程之中,是进程中的实际运作单位。通俗定义:在一个程序里的一个执行路线就叫作线程。更准确地说,线程是"一个进程内部的执行序列"基本事实:一切进程至少都有一个执行线程(主线程)本质:线程在进程内部运行,即线程在进程的地址空间内运行CPU 视角:在 CPU 眼中,线程的 PCB 比传统进程更加轻量化内核是如何对进程资源进行划分的,尤其是代码和数据的划

🔥铅笔小新z:个人主页
🎬博客专栏:Linux学习
💫滴水不绝,可穿石;步履不休,能至渊。
一、Linux 线程概念
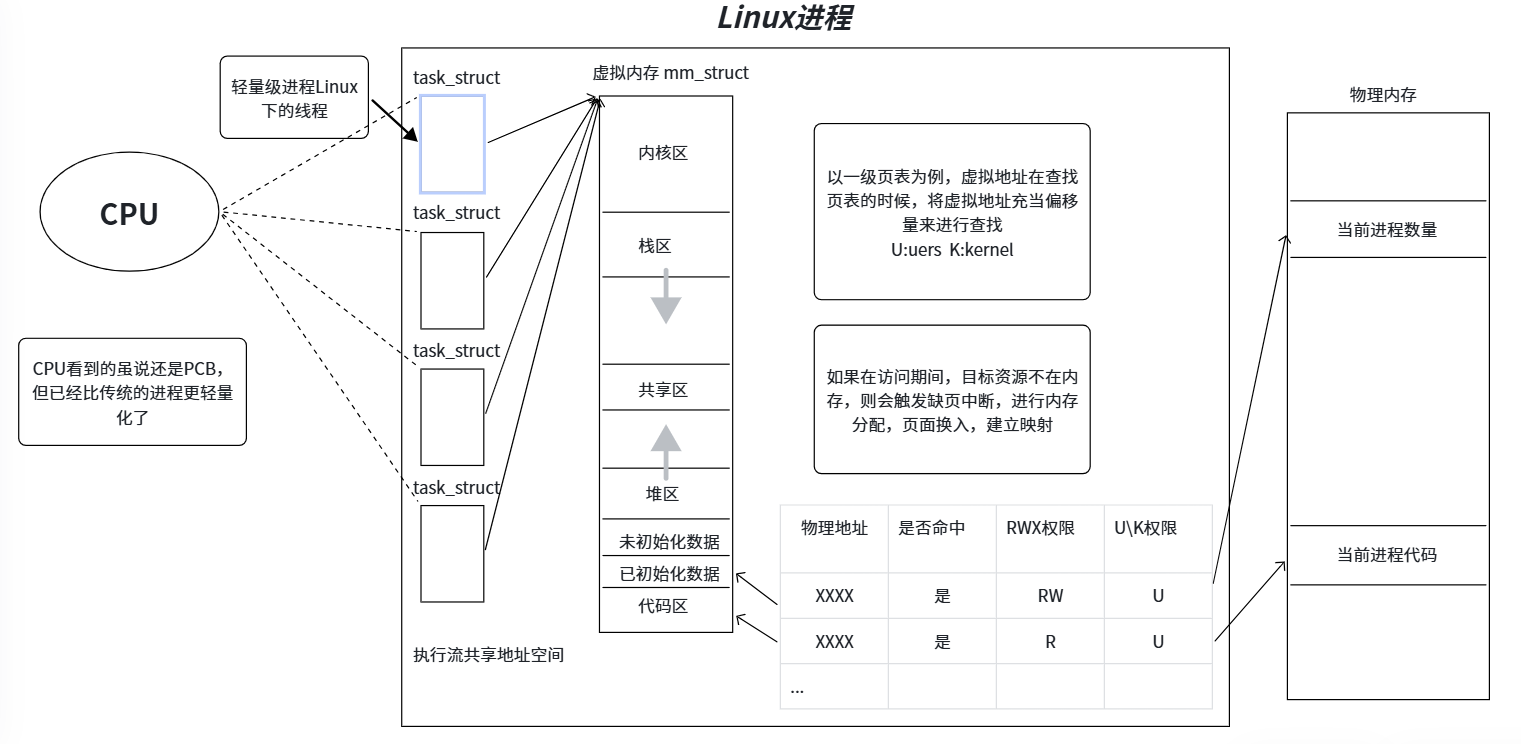
1. 什么是线程
线程是操作系统能够进行运算调度的最小单位,它被包含在进程之中,是进程中的实际运作单位。
- 通俗定义:在一个程序里的一个执行路线就叫作线程。更准确地说,线程是"一个进程内部的执行序列"
- 基本事实:一切进程至少都有一个执行线程(主线程)
- 本质:线程在进程内部运行,即线程在进程的地址空间内运行
- CPU 视角:在 CPU 眼中,线程的 PCB 比传统进程更加轻量化
想要真正理解线程,就必须搞明白:内核是如何对进程资源进行划分的,尤其是代码和数据的划分方式。
本质上,只要把进程的虚拟地址空间进行划分,进程资源就天然被划分好了。
下面先理解分页式存储管理,这是理解线程资源划分的基础。
2. 分页式存储管理
2.1 虚拟地址和页表的由来
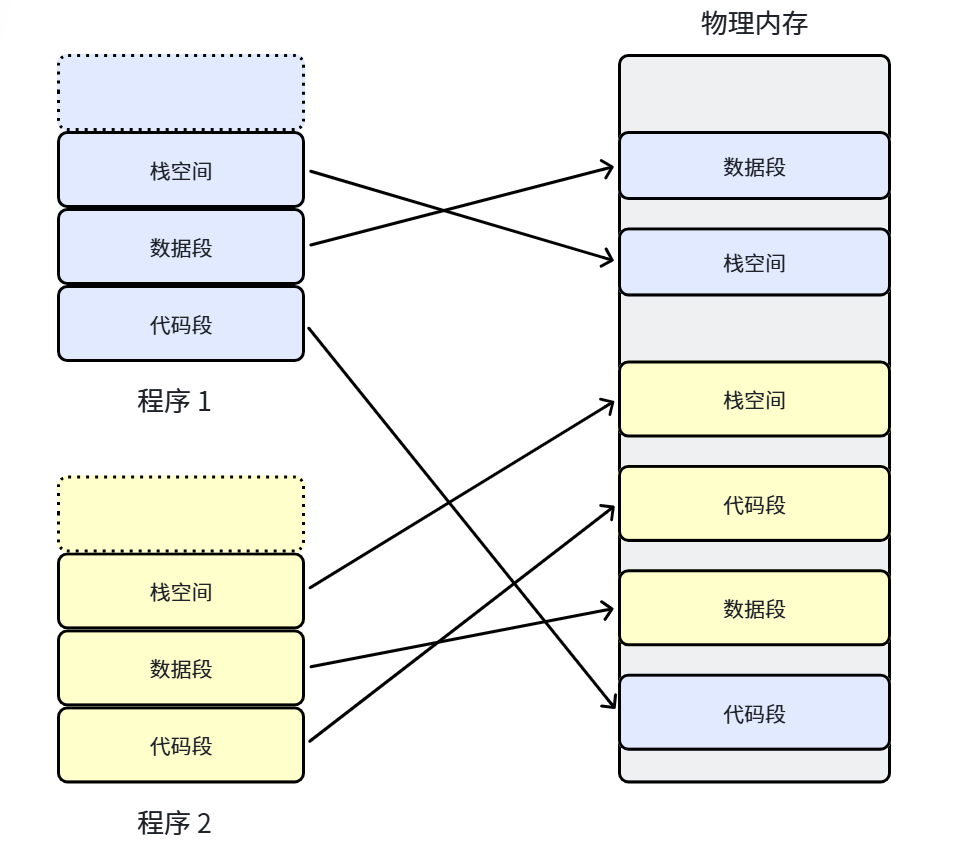
如果没有虚拟内存和分页机制,用户程序在物理内存中对应的空间必须是连续的。这会导致一个问题:随着程序的加载和退出,物理内存会被分割成许多离散的、大小不同的块——就像一块完整的蛋糕被切来切去,留下大量无法使用的蛋糕碎屑,这些就是内存碎片。
为了解决这个问题,操作系统引入了虚拟地址空间和分页机制:
- 虚拟地址空间:操作系统为每个正在执行的进程分配一个逻辑地址。在 32 位系统上,范围是
0 ~ 4G - 页框(物理页):把物理内存按固定长度分割,一般 32 位是 4KB,64 位是 8KB
- 页:进程虚拟内存中的数据块
- 页表:记录虚拟页和物理页框之间映射关系的表格
核心思想:把虚拟内存的逻辑地址空间分成若干页,把物理内存空间分成若干页框,通过页表把连续的虚拟内存映射到不连续的物理内存页上。这样既解决了碎片问题,又给用户程序呈现了连续的内存空间。
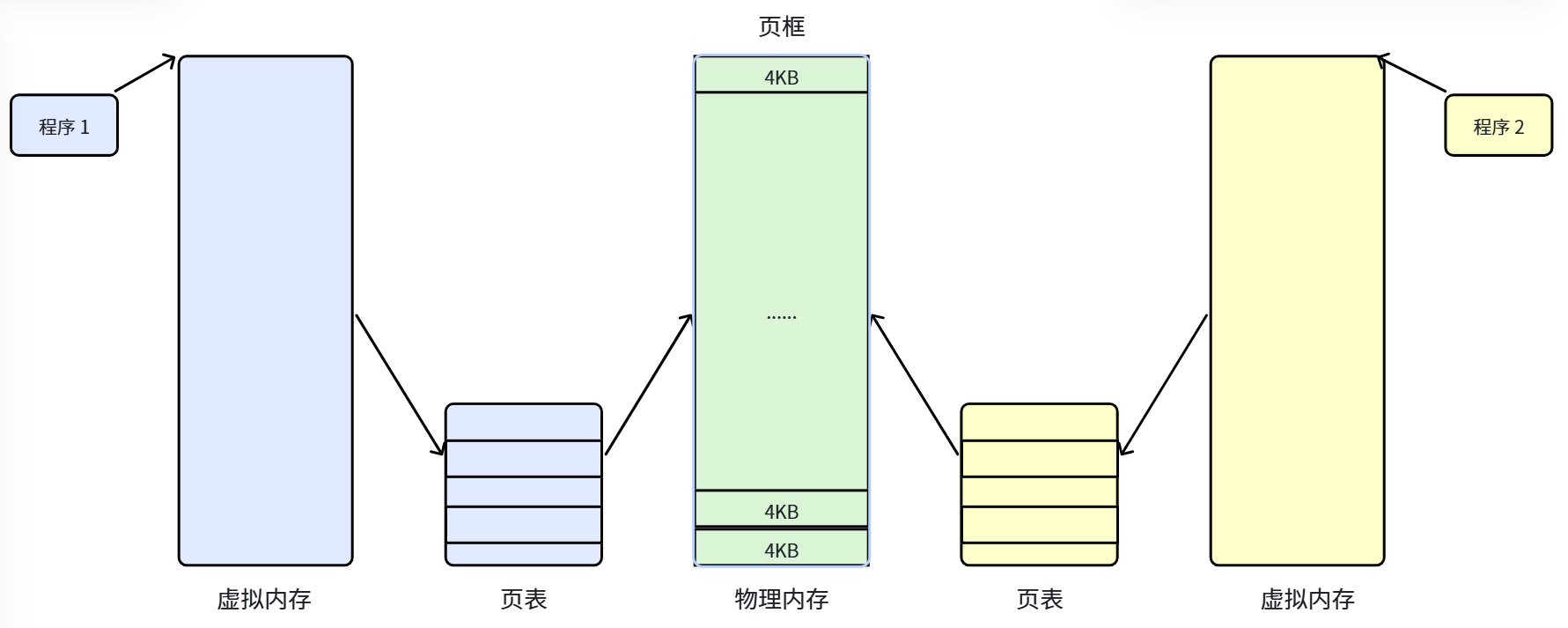
注意: 对用户程序来说,它以为自己的数据是连续存放的(页 0、页 1、页 2)。但通过页表这个“翻译官”,这些数据其实被零散地丢在了物理内存的各个角落。
【用户进程(虚拟内存)】 【页表(翻译官)】 【真实物理内存】
(程序以为自己拥有连续空间) (负责记录映射关系) (现实中零散的物理页框)
+-------------------+ +----+------+ +-------------------+
| 页 0 (Page 0) | ------------> | 页 | 页框 | ------------> | 页框 3 (空闲) |
+-------------------+ +----+------+ +-------------------+
| 页 1 (Page 1) | ----+ | 0 | 1 | | 页框 1 (存了页 0) |
+-------------------+ | | 1 | 4 | +-------------------+
| 页 2 (Page 2) | --+ | | 2 | 2 | | 页框 2 (存了页 2) |
+-------------------+ | | +----+------+ +-------------------+
| | | 页框 0 (空闲) |
| +-----------------------------------> +-------------------+
+-------------------------------------> | 页框 4 (存了页 1) |
+-------------------+
📌 知识点总结:为什么要有虚拟地址和页表?直接操作物理内存不行吗?
不行!如果没有虚拟地址和分页机制,所有用户程序必须连续地存放在物理内存中。随着程序频繁地加载和退出,物理内存会留下大量碎片,导致明明总内存还有剩余,却无法加载新的程序(因为没有足够大的连续空间)。虚拟地址空间给每个进程一个 0~4G 的"假地址",页表负责把连续的假地址映射到离散的真地址上。这样一来,用户程序以为自己在一片连续的大空间里运行,操作系统却在背后把数据散乱地存到物理内存的各处,充分利用了每一块可用空间,完美解决了碎片问题。简单说就是:用户要连续,物理不给连续,页表来做"翻译官",大家相安无事。
2.2 物理内存管理
假设物理内存有 4GB,按 4KB 一个页框划分,共 1048576 个页框。
内核用 struct page 结构体表示系统中的每个物理页:
/* include/linux/mm_types.h */
struct page {
unsigned long flags; // 原子标志,记录页的状态(是否脏、是否锁定等)
union {
struct {
struct list_head lru; // 换出页列表
struct address_space* mapping; // 映射的地址空间
pgoff_t index; // 在映射内的偏移量
unsigned long private; // 私有数据
};
struct { /* slab, slob, slub 分配器 */
union {
struct list_head slab_list;
struct {
struct page* next;
// ... 不同位数架构下的字段
};
};
struct kmem_cache* slab_cache;
void* freelist; // 第一个空闲对象
union {
void* s_mem;
unsigned long counters;
struct {
unsigned inuse : 16; // 对象数目
unsigned objects : 15;
unsigned frozen : 1;
};
};
};
};
union {
atomic_t _mapcount; // 页表中有多少项指向该页(引用计数)
unsigned int page_type;
unsigned int active;
int units;
};
void* virtual; // 内核虚拟地址(高端内存时为 NULL)
};
重要参数说明:
flags:存放页的状态(是否脏、是否锁定等),每一位表示一种状态_mapcount:页表中有多少项指向该页(引用计数),为 -1 时表示当前内核未引用该页virtual:页的虚拟地址。高端内存(不永久映射到内核地址空间的内存)下为 NULL
一个 struct page 约 40 字节。假设 4GB 物理内存、4KB 页框,共 1048576 个物理页,全部 page 结构体消耗约 40MB,相对 4GB 内存只是一小部分,这个代价是值得的。
📌 知识点总结:操作系统怎么管理物理内存的那么多页面?
操作系统为每个物理页框都创建了一个 struct page 结构体,这些结构体就像每页的"身份证",记录了该页的状态(是否被使用、是否脏数据、被几个页表指向等)。用一个简单的类比:就像图书馆管理员给每本书都建了一张索引卡,记录这本书在哪、被谁借了、状态如何。4GB 内存约 100 万个页框,管好这些"索引卡"大约只需要 40MB 的开销,完全在可接受范围内。
2.3 页表
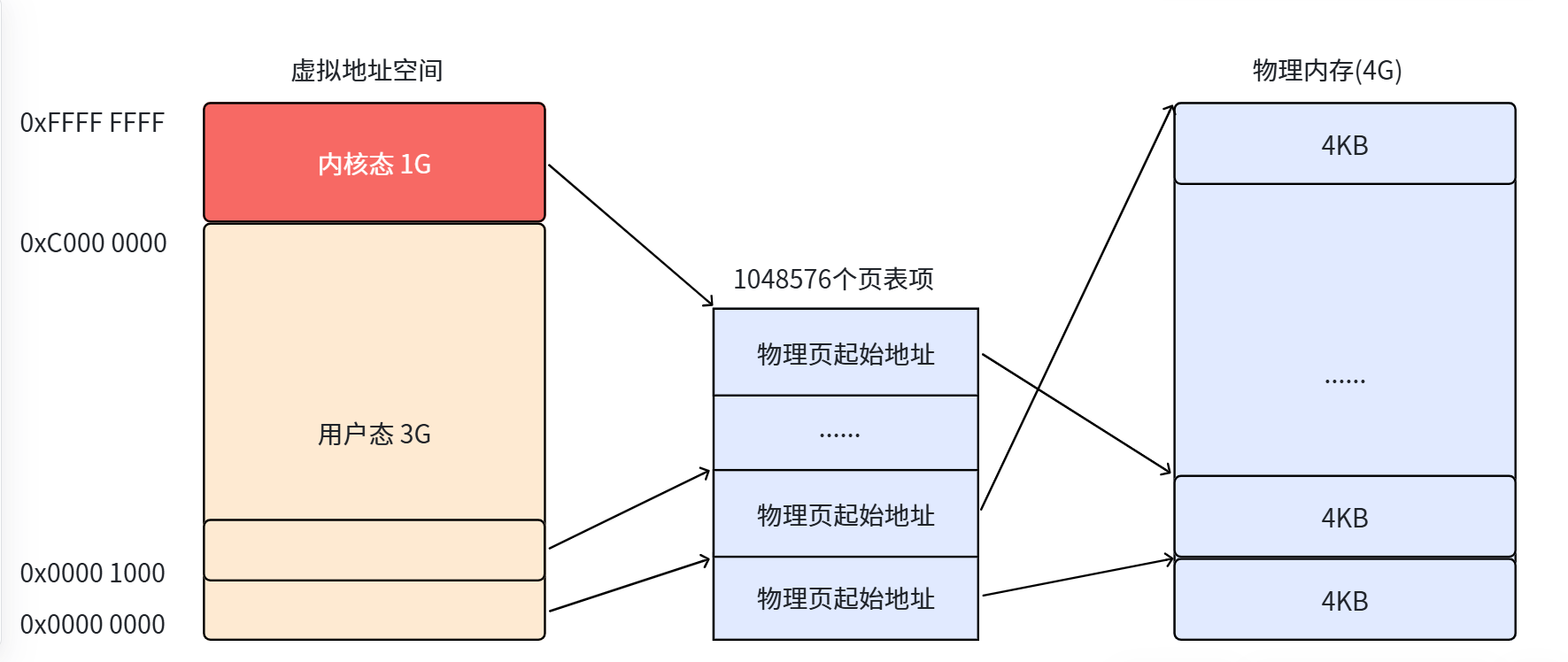
在 32 位系统中,虚拟地址空间最大 4GB,页大小 4KB,需要 4GB / 4KB = 1048576 个页表项。每个页表项占 4 字节,页表总大小为 1048576 * 4 = 4MB。
也就是说,页表自己就占用了 1024 个连续物理页。这存在两个问题:
- 连续性问题:页表本身需要连续存放 1024 个页框,这和使用页表的初衷(避免连续存储)相矛盾
- 局部性原理:进程在一段时间内通常只需要访问少数几个页,没必要让所有页表都常驻内存
解决方案:把页表再分页,形成多级页表。把 1048576 个表项拆成 1024 个页表,每个页表有 1024 个表项。这样,一个只需要 10MB 的程序只需 3 个页表就能覆盖(每个页表覆盖 4MB)。
📌 知识点总结:单级页表有什么问题?为什么要有多级页表?
单级页表需要连续存放 1024 个物理页来存储所有页表项,这违背了分页机制的初衷(避免连续存储)。而且根据局部性原理,程序往往只会用到一小部分空间。多级页表的思路是"用多少就建多少"——把一个大页表拆成 1024 个小页表,程序用到的空间只需对应少量小页表。10MB 的程序只需要 3 个小页表,既避免了连续存储的尴尬,又节省了内存空间。这就是空间换时间的反面——用多一次查表的"时间"换取节省内存的"空间"。
2.4 页目录结构
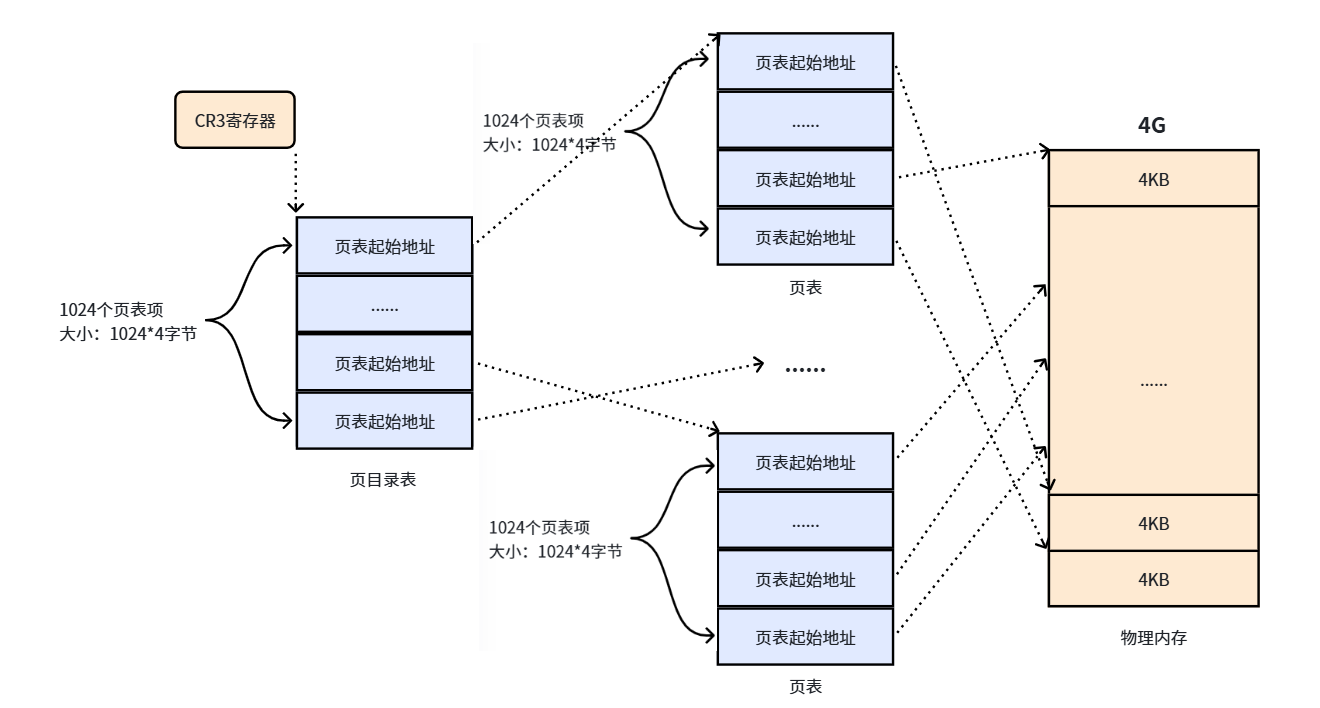
1024 个页表也需要被管理,管理它们的表叫页目录表,形成二级页表结构:
- 所有页表的物理地址被页目录表中的表项指向
- 页目录的物理地址被 CR3 寄存器指向(该寄存器保存了当前正在执行任务的页目录地址)
操作系统加载用户程序时,不仅需要为程序内容分配物理内存,还需要为页目录和页表分配物理内存。
📌 知识点总结:页目录是什么?
页目录就是"管页表的表"。有了 1024 个页表之后,需要有一个总表来记录这 1024 个页表各自在物理内存的什么位置,这个总表就叫页目录。CPU 通过 CR3 寄存器找到页目录,页目录找到页表,页表再找到物理页,形成二级查找机制。
2.5 两级页表的地址转换
以 32 位处理器、4KB 页大小为例,虚拟地址被分为三部分:
- 高 10 位:一级页号(页目录索引)
- 中间 10 位:二级页号(页表索引)
- 低 12 位:页内偏移量(4KB = 4096 字节)
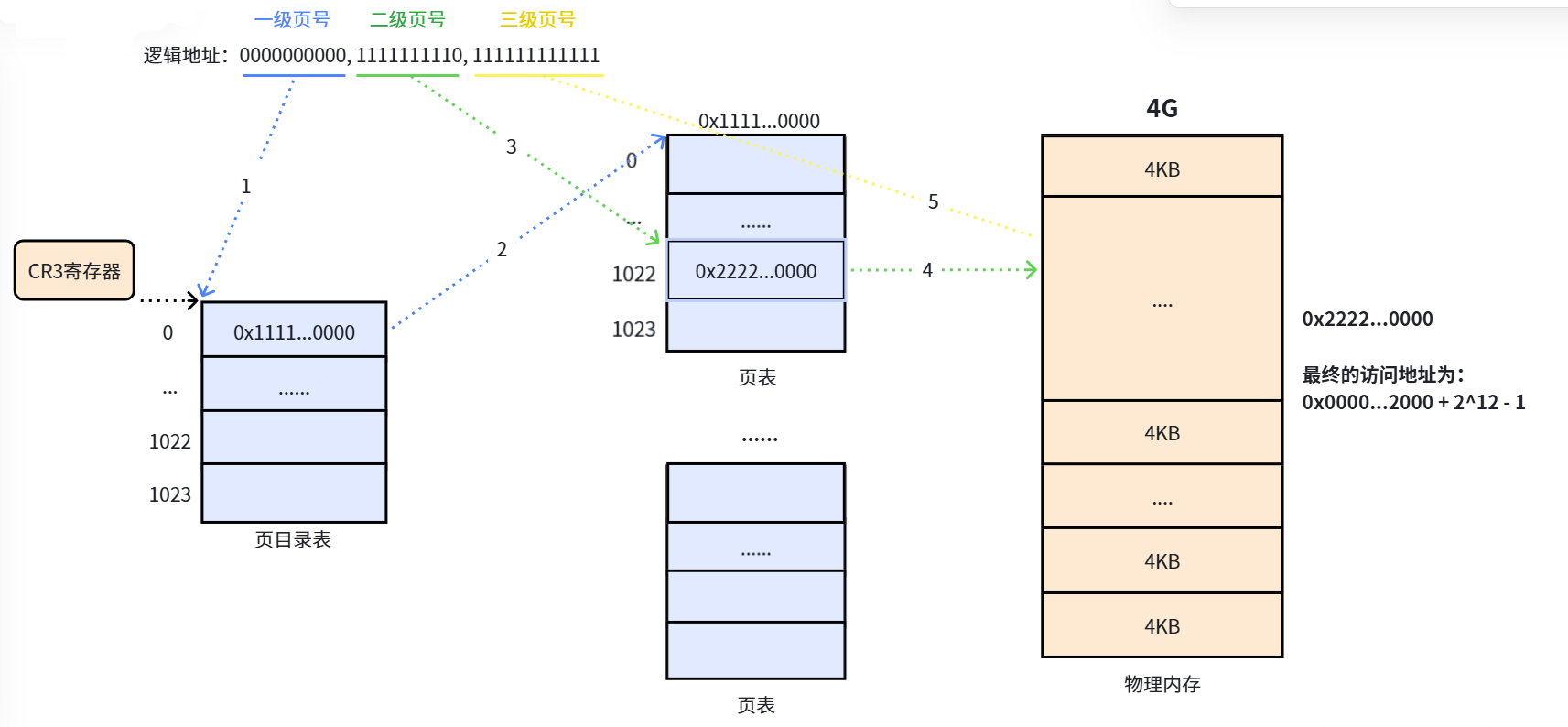
地址转换流程:
- CR3 寄存器读取页目录起始地址
- 根据一级页号查页目录表,找到下一级页表在物理内存中的位置
- 根据二级页号查页表,找到最终要访问的物理页框号
- 结合页内偏移量得到完整的物理地址
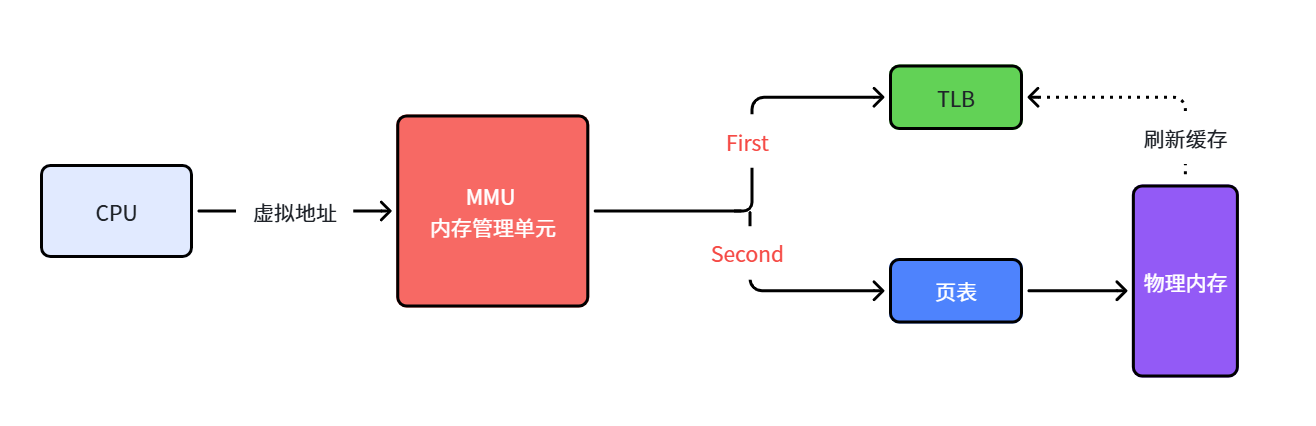
以上是 MMU(内存管理单元) 的工作流程。MMU 是一种硬件电路,速度很快,主要负责内存管理,地址转换只是它的业务之一。
效率问题:页表级数越多,查询步骤越多,CPU 等待时间越长。
TLB 快表引入:为了提升效率,MMU 引入了 TLB(转译后备缓冲器),即页表的硬件缓存。当 CPU 传新虚拟地址给 MMU 后,MMU 先在 TLB 中查找:
- TLB 命中:直接拿到物理地址,速度极快
- TLB 未命中:走页表查询,拿到物理地址后把映射关系更新到 TLB 中
📌 知识点总结:两级页表怎样把虚拟地址转换成物理地址?为什么有 TLB?
把 32 位的虚拟地址拆成三截:高 10 位找页目录、中间 10 位找页表、低 12 位在页内定位具体字节。整个过程就像去图书馆找书——先查区域索引(页目录)、再查书架索引(页表)、最后在书架上找第几本(页内偏移)。
但是多一级查表就多一次内存访问,为了加快速度,CPU 引入了 TLB,它就像一个"小本本"记住最近用过的地址映射关系。下次再访问同一个地址时,直接从小本本上抄答案,省掉两次查表的功夫。因为程序的访问通常具有局部性(反复访问同一片区域),TLB 的命中率非常高,可以大幅提升效率。
2.6 缺页异常
当 CPU 给 MMU 的虚拟地址在 TLB 和页表中都找不到对应的物理页时,就会触发缺页异常(Page Fault)。这是一个由硬件中断触发、可以由软件逻辑纠正的错误。
缺页异常分三种类型:
| 类型 | 说明 |
|---|---|
| 硬缺页(Major Page Fault) | 物理内存中没有对应页面,需要从磁盘读取到内存再建立映射 |
| 软缺页(Minor Page Fault) | 物理内存中有对应页面(被其他进程加载过),只需建立映射,无需磁盘 I/O |
| 无效缺页(Invalid Page Fault) | 访问非法地址(越界、空指针解引用),触发段错误,进程被终止 |
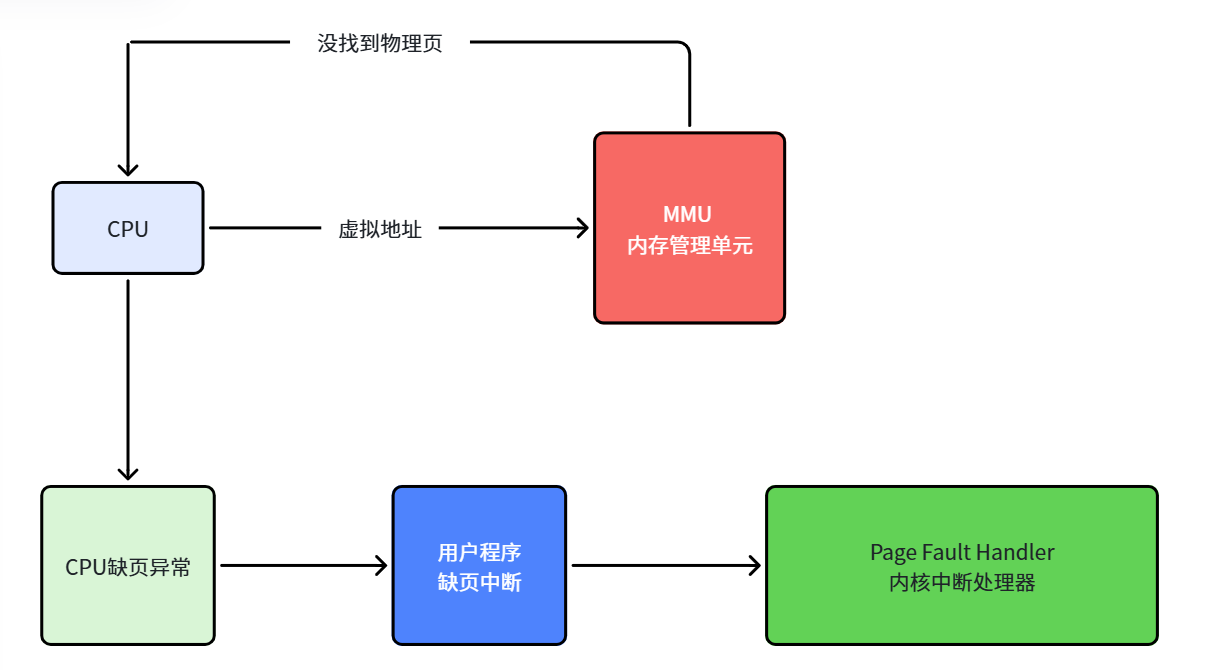
如何区分缺页和越界?
- 页号合法性检查:虚拟地址的页号是否合法?合法但不在内存 → 缺页;非法 → 越界
- 内存映射检查:地址是否在进程的内存映射范围内?是但不在内存 → 缺页;否 → 越界
理解
new和malloc:申请内存时,操作系统只是在虚拟地址空间里"记账"(分配虚拟地址),物理内存的分配往往是在真正访问时才通过缺页机制触发。这就是为什么new了很大的空间但没访问时,实际物理内存占用可能很小。
📌 知识点总结:什么是缺页异常?缺页和越界怎么区分?
缺页异常就像你去图书馆借书,查了索引发现这本书有记录但书架上找不到——书被放在仓库里了,需要管理员去仓库取出来。硬缺页类似于书在远程仓库,需要花时间搬运(磁盘 I/O);软缺页像是书已经被别人借出来放在桌上,你直接就能用,省了跑仓库的时间。
区分缺页还是越界,核心就是看这个地址"合不合法":地址合法但内容不在内存 → 缺页(操作系统会帮你去磁盘加载);地址非法(越界)→ 报段错误,进程直接被干掉。记住一句话:缺页是"有这个人但不在家",越界是"根本没这个人"。
3. 线程的优点
- 创建代价小:创建新线程比创建新进程快得多
- 切换开销小:线程切换比进程切换轻量
- 线程切换不需要改变虚拟内存空间(同进程内的线程共享地址空间)
- 进程切换会刷新 TLB 快表,导致一段时间内内存访问效率降低
- 线程切换不会刷新 TLB,也不会扰乱硬件缓存
- 占用资源少:线程占用的系统资源比进程少
- 充分利用多处理器:多个线程可以在多核 CPU 上并行执行
- 掩蔽 I/O 等待:一个线程等待慢速 I/O 时,其他线程可以继续执行计算任务
- 计算密集型应用:将计算分解到多个线程,在多处理器系统上运行
- I/O 密集型应用:线程可以同时等待不同的 I/O 操作,提高整体吞吐量
📌 知识点总结:为什么要用多线程?它比多进程好在哪里?
多进程就像开多家独立的公司,每家都有自己的办公室(地址空间)、文件柜(资源),开新公司要全套置办,公司间合并/拆分(通信/切换)成本极高。多线程就像在一家公司里设多个部门,大家共享同一间办公室、文件柜,开新部门只需要加一张桌子(创建线程快),部门之间切换(线程切换)也不需要换办公室。最核心的区别是:线程切换不改变虚拟地址空间,TLB 和 CPU 缓存不会被刷新,而进程切换会。这就好比你在同一个办公室里从工位 A 走到工位 B(线程切换),比从一座楼跑到另一座楼(进程切换)快得多,而且不用重新认路。
4. 线程的缺点
- 性能损失
- 计算密集型线程数量超过 CPU 核心数时,增加了额外的同步和调度开销,但可用资源不变
- 健壮性降低
- 多线程程序需要考虑更多并发问题,时间分配上的细微偏差或错误共享变量都可能导致问题
- 线程之间缺乏保护,一个线程出问题可能拖累整个进程
- 缺乏访问控制
- 进程是访问控制的基本粒度,线程中调用某些 OS 函数会影响整个进程
- 编程难度提高
- 编写和调试多线程程序比单线程程序困难得多
📌 知识点总结:多线程有哪些缺点?什么时候不适合用多线程?
多线程的主要问题是"人多手杂":线程过多时,CPU 在它们之间来回切换会浪费性能(上下文切换开销);共享资源不加保护会导致数据混乱(如两个线程同时修改一个变量);最要命的是,一个线程崩溃(除零、野指针)会导致整个进程挂掉,所有线程跟着殉葬。适合单线程的场景包括:任务本身是顺序执行的、对稳定性要求极高不能容忍任何线程崩溃的、编程能力有限写不好同步逻辑的。多线程是一把双刃剑,用好了效率翻倍,用不好是灾难。
5. 线程异常
- 单个线程出现除零、野指针等问题导致崩溃时,整个进程也会跟着崩溃
- 原因:线程是进程的执行分支,线程出异常就像进程出异常一样,会触发信号机制终止进程;进程终止后,该进程内的所有线程也随之退出
📌 知识点总结:一个线程崩溃会影响其他线程吗?
会!一个线程挂了,整个进程都得陪葬。因为线程是进程内部的执行流,它们共享同一个地址空间。当一个线程访问非法内存(野指针、数组越界)时,CPU 触发的段错误信号是发给整个进程的,而不是只发给那个线程。进程被终止,所有线程都活不了。这就是多线程健壮性差的原因——不像多进程,一个进程挂了不影响其他进程。
6. 线程用途
- 提高 CPU 密集型程序的执行效率:多线程让多个 CPU 核心同时干活,充分利用硬件资源
- 提高 I/O 密集型程序的用户体验:一边等待网络/磁盘 I/O,一边响应用户操作(比如一边写代码一边下载软件)
📌 知识点总结:多线程一般用在什么地方?
两种场景最常用:一是计算密集型应用,要把大任务拆成小块让多个 CPU 核心一起算(比如视频渲染、科学计算);二是I/O 密集型应用,要在等待磁盘/网络的时候不让程序卡死(比如下载工具同时下载多个文件、Web 服务器同时处理多个请求)。
二、Linux 进程 VS 线程
1. 进程和线程的核心区别
| 对比维度 | 进程 | 线程 |
|---|---|---|
| 基本角色 | 资源分配的基本单位 | 调度的基本单位 |
| 地址空间 | 每个进程有独立地址空间 | 同一进程的线程共享地址空间 |
| 独立性 | 进程间具有独立性(互不干扰) | 线程共享进程资源(紧密耦合) |
| 创建开销 | 大 | 小 |
| 切换开销 | 大(刷新 TLB) | 小 |
2. 线程独有的"私有"数据
每个线程虽然共享进程资源,但也拥有自己的一部分私有数据:
- 线程 ID:唯一标识线程
- 一组寄存器:线程的上下文数据
- 栈:线程自己的栈空间
- errno:错误码变量
- 信号屏蔽字:屏蔽哪些信号
- 调度优先级:线程的调度优先级
3. 线程共享的进程资源
同一进程的多个线程共享以下资源:
- 代码段(Text Segment):定义的函数可以在各线程中调用
- 数据段(Data Segment):全局变量在各线程中都可以访问
- 文件描述符表:打开的文件被所有线程共享
- 信号处理方式:SIG_IGN、SIG_DFL 或自定义处理函数
- 当前工作目录
- 用户 ID 和组 ID
4. 如何理解之前的单进程?
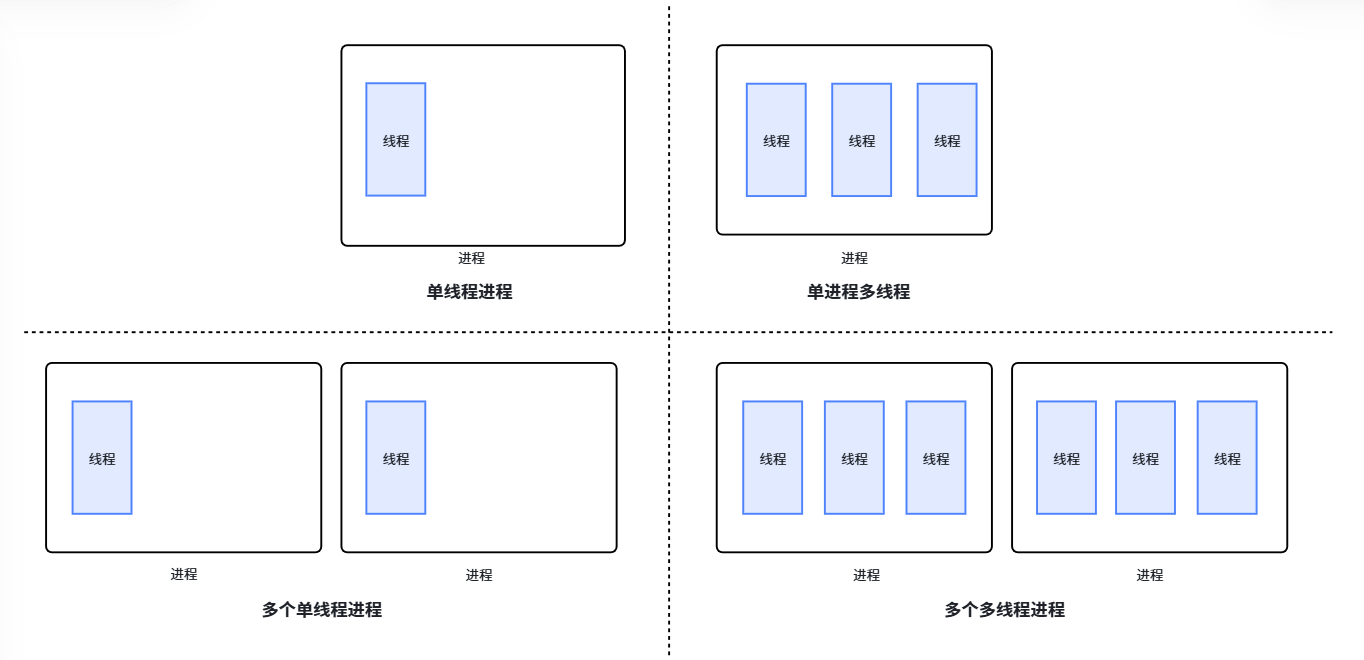
之前学的单进程,本质上是具有一个线程执行流的进程——即只有主线程的进程。
📌 知识点总结:进程和线程到底是什么关系?各自管什么?
用公司来类比:进程是公司,负责拥有资源(办公室、资产、营业执照);线程是员工,负责干活(执行代码)。一个公司(进程)可以有多个员工(线程),员工共享公司的办公室和资产(地址空间和资源),但每个员工有自己的工位(栈)、自己的记事本(寄存器)、自己的员工编号(线程 ID)。公司倒闭(进程终止),所有员工都得走人;一个员工闯大祸(线程异常),公司也可能被查封。
进程是资源分配的基本单位——操作系统给公司批办公室、批预算;线程是调度的基本单位——操作系统决定哪个员工先用电脑、干多久。
三、Linux 线程控制
1. POSIX 线程库
POSIX 线程库(pthread)是一套用于线程操作的标准化 C 语言接口:
- 函数名以
pthread_打头 - 头文件:
<pthread.h> - 编译链接选项:
-lpthread
错误检查注意事项:
与传统函数的区别:
- 传统函数:成功返回 0,失败返回 -1,通过全局变量
errno获取错误码 - pthread 函数:成功返回 0,失败直接返回错误码(不设置 errno)
- 建议通过返回值判断 pthread 函数是否成功,因为读取返回值比读取线程内 errno 开销更小
2. 创建线程
函数原型
#include <pthread.h>
// 功能:创建一个新的线程
// thread:输出参数,返回线程 ID(pthread 库中的 ID)
// attr:线程属性,传 NULL 表示使用默认属性
// start_routine:线程启动后要执行的函数(回调函数)
// arg:传给线程启动函数的参数
// 返回值:成功返回 0,失败返回错误码
int pthread_create(pthread_t *thread, const pthread_attr_t *attr,
void *(*start_routine)(void *), void *arg);
示例代码
#include <unistd.h> // sleep 函数
#include <stdlib.h> // exit 函数
#include <stdio.h> // printf 函数
#include <string.h> // strerror 函数
#include <pthread.h> // POSIX 线程库
// 子线程要执行的函数
void *rout(void *arg)
{
while (1)
{
printf("我是线程 1\n");
sleep(1); // 每秒打印一次
}
}
int main()
{
pthread_t tid; // 存放线程 ID
int ret;
// 创建线程,传入 NULL 表示默认属性,NULL 表示不给参数
if ((ret = pthread_create(&tid, NULL, rout, NULL)) != 0)
{
fprintf(stderr, "pthread_create: %s\n", strerror(ret));
exit(EXIT_FAILURE);
}
while (1)
{
printf("我是主线程\n");
sleep(1);
}
}
获取线程 ID
#include <pthread.h>
// 获取调用线程自身的 ID(pthread 库中的 ID)
// 返回值:当前线程的 ID,类型为 pthread_t
pthread_t pthread_self();
pthread 库的线程 ID 与内核线程 ID(LWP)的区别:
pthread_self()返回的是 pthread 库层面的线程 ID,本质上是一个虚拟地址(指向线程控制块 TCB 的指针,位于共享区内存中)- 内核为每个线程创建了一个全局唯一的 LWP(Light Weight Process,轻量级进程)ID
使用 ps -aL 命令查看两者区别:
$ ps -aL | head -1 && ps -aL | grep mythread
PID LWP TTY TIME CMD
2711838 2711838 pts/235 00:00:00 mythread ← 主线程,PID == LWP
2711838 2711839 pts/235 00:00:00 mythread ← 子线程,LWP 不同
-L选项:显示线程信息- PID:进程 ID
- LWP:线程在内核中的真实 ID
主线程的栈在进程地址空间的栈区;其他线程的栈在堆栈之间的共享区(因为 pthread 库在共享区)。LWP 更像是"系统全局唯一身份证号",而 pthread_self 得到的更像是"公司内部工号",系统不认识但同一个进程内可以用。
📌 知识点总结:pthread_create 怎么创建线程?pthread_self 返回的是什么?
pthread_create 做了三件事:① 在进程的共享区用 mmap 申请一块内存,作为新线程的栈和线程控制块(TCB);② 给 TCB 填入各种属性(要执行的函数、参数、栈地址等);③ 调用内核的 clone 系统调用,让内核创建一个轻量级进程(LWP)来执行线程函数。
pthread_self 返回的本质上是一个虚拟地址,指向内存中该线程的 TCB 结构体。而 ps -aL 看到的 LWP 才是内核真正用来调度的线程 ID。一个形象的比喻:LWP 是"身份证号"(系统全局唯一),pthread_t 是"工号"(公司内部用,本质是个地址值)。
3. 线程终止
如果需要只终止某个线程而不终止整个进程,有三种方法:
| 方法 | 说明 |
|---|---|
| 从线程函数 return | 对主线程不适用(main 函数 return 相当于 exit) |
pthread_exit |
线程主动终止自己 |
pthread_cancel |
一个线程终止同一进程中的另一个线程 |
pthread_exit
#include <pthread.h>
// 功能:终止当前线程
// value_ptr:线程返回值指针(不要指向局部变量!)
// 返回值:无返回值(线程调用后直接终止,不返回调用者)
void pthread_exit(void *value_ptr);
重要注意事项:pthread_exit 或 return 返回的指针所指向的内存单元必须是全局变量或用 malloc 分配的堆内存。不能是线程函数栈上的局部变量,因为其他线程拿到返回指针时,该线程函数已经退出了,局部变量已被销毁。
pthread_cancel
#include <pthread.h>
// 功能:取消同一进程中的另一个线程
// thread:要取消的目标线程 ID
// 返回值:成功返回 0,失败返回错误码
int pthread_cancel(pthread_t thread);
📌 知识点总结:线程怎么终止?和进程终止有什么区别?
线程终止有三种姿势:一是正常退出(函数 return 回家),二是自杀(调用 pthread_exit 自己了断),三是他杀(别人调用 pthread_cancel 把你干掉)。注意:主线程不能用 return 终止自己,因为 main 函数的 return 相当于调用 exit,整个进程都会退出。另外,pthread_exit 和 return 返回的数据不能是局部变量的地址——线程都退出了,栈上的局部变量也就被释放了,别人拿到的是一个悬空指针。
4. 线程等待
为什么需要线程等待?
- 已经退出的线程,其空间没有被释放,仍然在进程的地址空间内
- 如果不等待,已退出的线程资源会一直占用,产生类似"僵尸进程"的问题
- 不等待的话,创建新线程不会复用已退出线程的地址空间
pthread_join
#include <pthread.h>
// 功能:等待线程结束,回收线程资源
// thread:要等待的目标线程 ID
// value_ptr:二级指针,接收线程的返回值(传 NULL 表示不关心返回值)
// 返回值:成功返回 0,失败返回错误码
int pthread_join(pthread_t thread, void **value_ptr);
调用 pthread_join 的线程会挂起等待,直到目标线程终止。不同终止方式对应的返回值:
| 终止方式 | value_ptr 指向的内容 |
|---|---|
return 返回 |
线程函数的返回值 |
被 pthread_cancel 取消 |
常量 PTHREAD_CANCELED |
调用 pthread_exit |
传给 pthread_exit 的参数 |
| 不关心返回值 | 传 NULL 给 value_ptr |
示例代码
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <pthread.h>
// 线程1:通过 return 返回值
void *thread1(void *arg)
{
printf("线程1 正在 return...\n");
int *p = (int*)malloc(sizeof(int)); // 堆上分配内存,线程退出后数据还在
*p = 1;
return (void*)p; // 返回堆内存地址
}
// 线程2:通过 pthread_exit 返回值
void *thread2(void *arg)
{
printf("线程2 正在 exiting...\n");
int *p = (int*)malloc(sizeof(int));
*p = 2;
pthread_exit((void*)p); // 主动退出并返回值
}
// 线程3:无限循环,等待被取消
void *thread3(void *arg)
{
while (1)
{
printf("线程3 正在运行...\n");
sleep(1);
}
return NULL;
}
int main()
{
pthread_t tid;
void *ret;
// --- 测试 return ---
pthread_create(&tid, NULL, thread1, NULL); // 创建线程1
pthread_join(tid, &ret); // 等待线程1结束
printf("线程1 返回, thread id %X, return code:%d\n", tid, *(int*)ret);
free(ret); // 释放堆内存
// --- 测试 pthread_exit ---
pthread_create(&tid, NULL, thread2, NULL);
pthread_join(tid, &ret);
printf("线程2 返回, thread id %X, return code:%d\n", tid, *(int*)ret);
free(ret);
// --- 测试 pthread_cancel ---
pthread_create(&tid, NULL, thread3, NULL);
sleep(3); // 让线程3运行 3 秒
pthread_cancel(tid); // 主线程取消线程3
pthread_join(tid, &ret); // 等待线程3结束
if (ret == PTHREAD_CANCELED)
printf("线程3 返回, thread id %X, return code:PTHREAD_CANCELED\n", tid);
else
printf("线程3 返回, thread id %X, return code:NULL\n", tid);
}
运行结果:
线程1 正在 return...
线程1 返回, thread id 5AA79700, return code:1
线程2 正在 exiting...
线程2 返回, thread id 5AA79700, return code:2
线程3 正在运行...
线程3 正在运行...
线程3 正在运行...
线程3 返回, thread id 5AA79700, return code:PTHREAD_CANCELED
📌 知识点总结:为什么要调用 pthread_join 等待线程?
就像进程有"僵尸进程"一样,线程也有"僵尸线程"。线程虽然执行完了,但它的资源(TCB、栈空间)还在进程地址空间里没被释放。pthread_join 就是用来"收尸"的——它让调用者挂起等待目标线程结束,然后告诉内核可以释放资源了。更重要的是,通过 pthread_join 还能拿到线程的返回值。如果不 join,线程退出后的空间就无法被回收,也无法被新创建的线程复用,造成内存泄漏。
5. 分离线程
分离的原因
- 默认情况下,新创建的线程是 joinable(可连接) 的
- 线程退出后,必须调用
pthread_join回收资源,否则会造成资源泄漏 - 如果不关心线程返回值,每次都要 join 是一个负担
- 分离后,线程退出时系统自动释放资源,无需手动 join
pthread_detach
#include <pthread.h>
// 功能:将指定线程设置为分离状态
// thread:要分离的目标线程 ID
// 返回值:成功返回 0,失败返回错误码
int pthread_detach(pthread_t thread);
两种使用方式:
// 方式1:其他线程分离目标线程
pthread_detach(thread_id);
// 方式2:线程自己分离自己(常用方式)
pthread_detach(pthread_self());
重要规则:joinable 和分离是互斥的——一个线程不能既是 joinable 又是分离的。
示例代码
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <pthread.h>
void *thread_run(void *arg)
{
pthread_detach(pthread_self()); // 线程自己把自己设为分离状态
printf("%s\n", (char*)arg); // 打印传入的字符串
return NULL;
}
int main()
{
pthread_t tid;
// 创建线程,传入字符串 "thread1 run..."
if (pthread_create(&tid, NULL, thread_run, "thread1 run...") != 0)
{
printf("创建线程出错\n");
return 1;
}
int ret = 0;
sleep(1); // 很重要!让线程先完成分离,再尝试 join
if (pthread_join(tid, NULL) == 0)
{
printf("线程等待成功\n");
ret = 0;
}
else
{
printf("线程等待失败\n");
ret = 1;
}
return ret;
}
sleep(1)很重要:必须确保线程已经在自己内部调用pthread_detach完成了分离,否则主线程调用pthread_join仍然可能成功。
📌 知识点总结:分离线程是什么?什么场景下用?
分离线程就是告诉系统:"这个线程跑完就自动收拾干净,不用等我收尸。“默认创建的线程是 joinable 的,类似于"管杀管埋”——你创建了就得负责 join 回收。如果线程执行完就完事了,不关心返回值,每次还要 join 挺麻烦,就可以设置分离状态,让系统自动回收资源。
joinable vs 分离:就像借书——joinable 是"你借了就必须亲自还",分离是"放自助还书箱,图书馆自己处理"。两者只能选一个,不能既要自动回收又要手动 join。
四、线程 ID 及进程地址空间布局
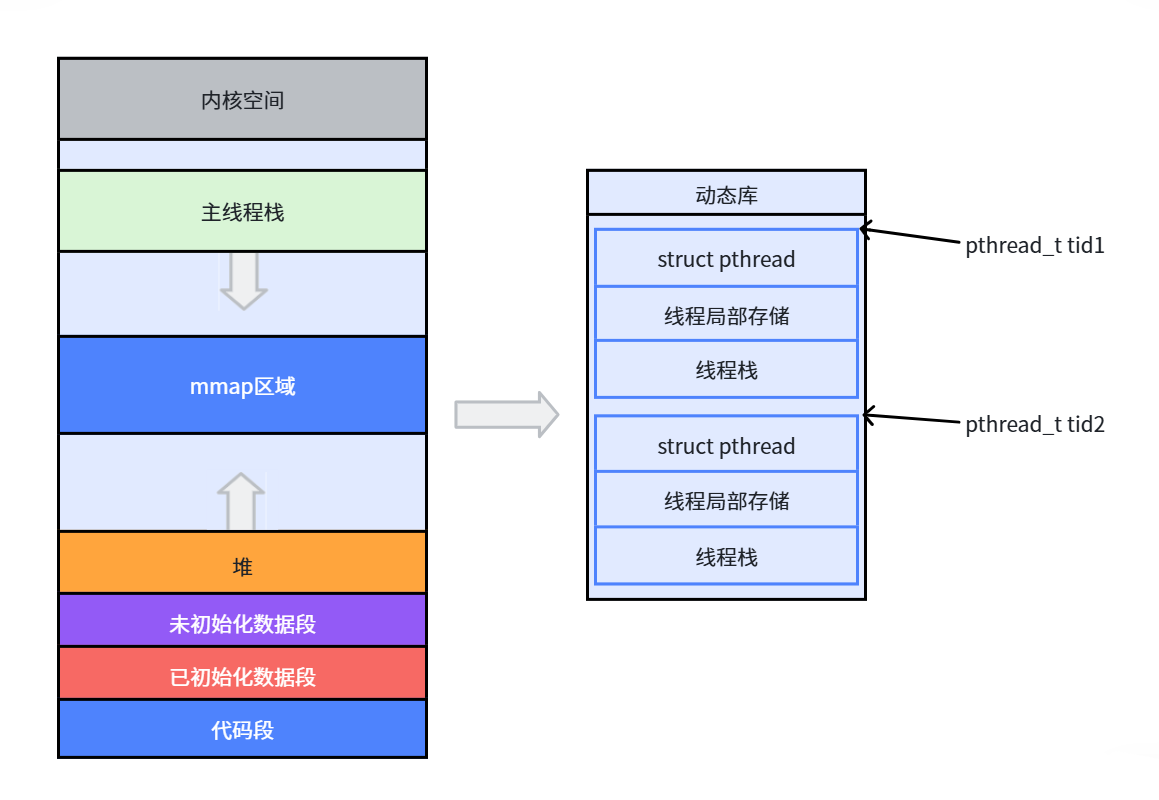
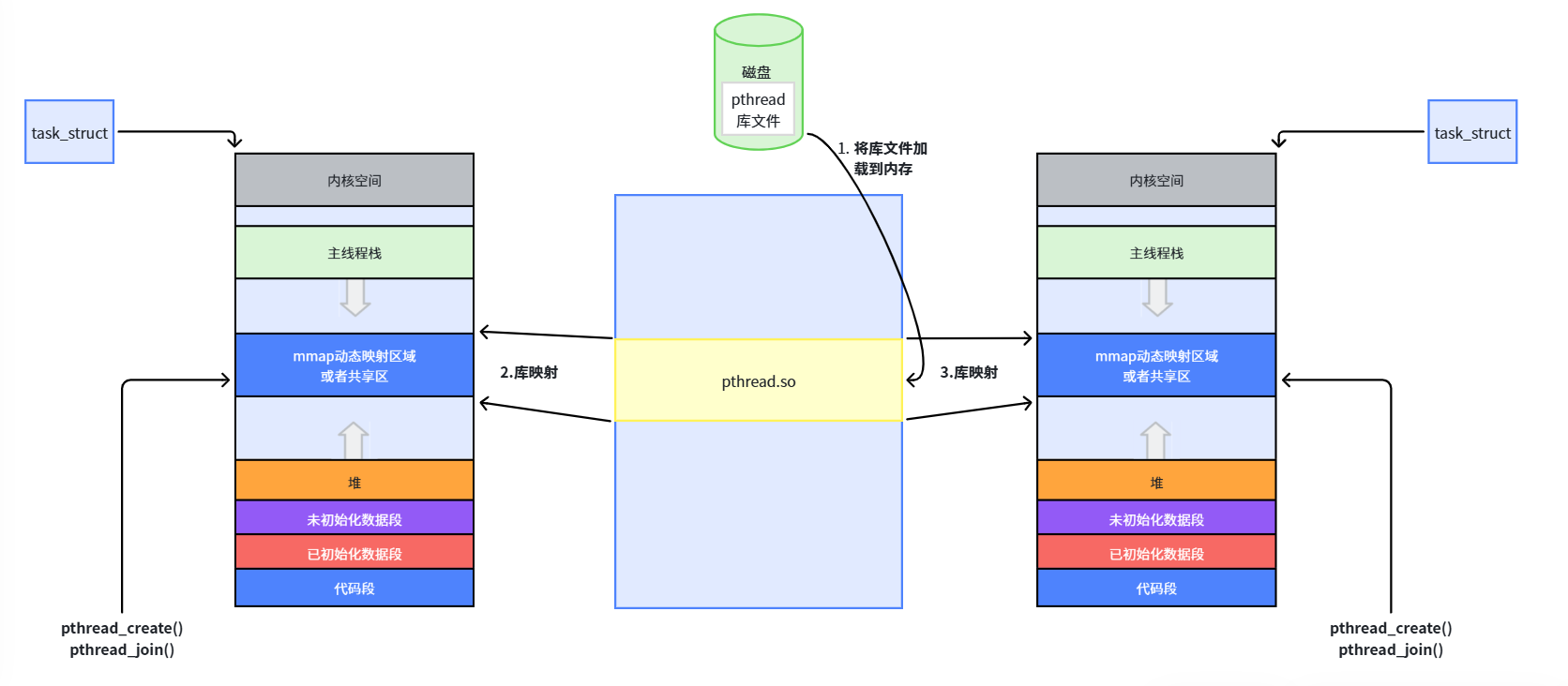
1. 两个"线程 ID"的区别
| 名称 | 来源 | 作用域 | 本质 |
|---|---|---|---|
| LWP(轻量级进程 ID) | 内核分配 | 系统全局 | 唯一标识线程,供内核调度 |
| pthread_t | pthread 库分配 | 进程内部 | 虚拟地址,指向 TCB 结构体 |
pthread_create 的第一个参数指向一个虚拟内存单元,该地址即为新创建线程的 pthread 线程 ID,属于 NPTL(Native POSIX Thread Library) 线程库的范畴。线程库后续的操作(如 pthread_join、pthread_cancel)都是根据这个 ID 来操作线程的。
2. pthread_t 的本质
对于 Linux 目前实现的 NPTL 实现而言,pthread_t 类型的线程 ID,本质就是一个进程地址空间上的一个地址。
#include <pthread.h>
// 获取当前线程自身的 ID
// 返回值:pthread_t 类型,本质是一个虚拟地址
pthread_t pthread_self();
3. 线程地址空间布局
- 主线程:栈在进程的栈区(向下生长)
- 子线程:栈在进程地址空间的共享区(堆和栈之间),使用
mmap系统调用分配,大小固定(默认 8MB),不能动态增长
📌 知识点总结:pthread_t 的线程 ID 到底是什么?
pthread_t 就是一个虚拟地址,指向进程共享区中该线程的 TCB(线程控制块)。这个 TCB 是 pthread 库用 mmap 在共享区申请的一块内存,放在这块内存开头的位置。因为它是进程中的一个地址,所以只能在同一个进程内用来标识线程。而 ps -aL 看到的 LWP 才是内核全局唯一的线程 ID,供内核调度使用。
五、线程封装(C++ 面向对象封装)
1. 基于 std::function 的封装
// Thread.hpp
#pragma once
#include <iostream> // 输入输出流
#include <string> // 字符串
#include <functional> // std::function 和 std::bind
#include <pthread.h> // POSIX 线程库
namespace ThreadModule
{
// 原子计数器,方便生成线程名称(如 Thread-0, Thread-1...)
std::uint32_t cnt = 0;
// 线程要执行的方法类型:void() 的可调用对象
using threadfunc_t = std::function<void()>;
// 线程状态枚举
enum class TSTATUS
{
THREAD_NEW, // 新建
THREAD_RUNNING, // 运行中
THREAD_STOP // 已停止
};
// 线程类封装
class Thread
{
private:
// 静态方法:作为 pthread_create 的回调函数
// 因为 pthread_create 的第三个参数必须是 void* (*)(void*) 类型
// 所以我们需要一个静态方法来接收 this 指针
static void *run(void *obj)
{
// 把参数转换回 Thread 对象指针
Thread *self = static_cast<Thread *>(obj);
// 设置线程名称(便于调试)
pthread_setname_np(pthread_self(), self->_name.c_str());
// 更新状态为运行中
self->_status = TSTATUS::THREAD_RUNNING;
// 如果设置了分离,则自动分离
if (!self->_joined)
{
pthread_detach(pthread_self());
}
// 执行线程函数
self->_func();
return nullptr;
}
// 生成线程名称
void SetName()
{
// 后期需要加锁保护 cnt(多线程并发时会有问题)
_name = "Thread-" + std::to_string(cnt++);
}
public:
// 构造函数:传入线程要执行的函数
Thread(threadfunc_t func)
: _status(TSTATUS::THREAD_NEW), _joined(true), _func(func)
{
SetName();
}
// 开启分离模式(必须在 Start 之前调用)
void EnableDetach()
{
if (_status == TSTATUS::THREAD_NEW)
_joined = false; // false 表示不需要 join,即分离
}
// 开启可连接模式(默认)
void EnableJoined()
{
if (_status == TSTATUS::THREAD_NEW)
_joined = true;
}
// 启动线程
bool Start()
{
if (_status == TSTATUS::THREAD_RUNNING)
return true;
// 调用 pthread_create,传入 this 指针作为参数
int n = ::pthread_create(&_id, nullptr, run, this);
if (n != 0)
return false;
return true;
}
// 等待线程结束
bool Join()
{
if (_joined)
{
int n = pthread_join(_id, nullptr);
if (n != 0)
return false;
return true;
}
return false; // 分离状态不能 join
}
~Thread() {}
private:
std::string _name; // 线程名称
pthread_t _id; // 线程 ID
TSTATUS _status; // 线程状态
bool _joined; // 是否需要 join(true=可连接,false=分离)
threadfunc_t _func; // 线程要执行的函数
};
}
2. 使用示例
// main.cc
#include <iostream>
#include <unistd.h>
#include "test.hpp"
// 线程函数1
void hello1()
{
char buffer[64];
// 获取当前线程名称
pthread_getname_np(pthread_self(), buffer, sizeof(buffer) - 1);
while (true)
{
std::cout << "hello world, " << buffer << std::endl;
sleep(1);
}
}
// 线程函数2
void hello2()
{
char buffer[64];
pthread_getname_np(pthread_self(), buffer, sizeof(buffer) - 1);
while (true)
{
std::cout << "hello world, " << buffer << std::endl;
sleep(1);
}
}
int main()
{
// 设置主线程名称
pthread_setname_np(pthread_self(), "main");
// 创建线程 t1,执行 hello1
ThreadModule::Thread t1(hello1);
t1.Start();
// 创建线程 t2,执行 hello2(使用 std::bind)
ThreadModule::Thread t2(std::bind(&hello2));
t2.Start();
// 等待线程结束
t1.Join();
t2.Join();
return 0;
}
查看运行结果:
$ ps -aL
PID LWP TTY TIME CMD
195828 195828 pts/1 00:00:00 main ← 主线程,名称为"main"
195828 195829 pts/1 00:00:00 Thread-0 ← 子线程1
195828 195830 pts/1 00:00:00 Thread-1 ← 子线程2
3. 模板版本的封装(支持任意参数)
// 模板形式的线程封装,支持传递任意类型数据
namespace ThreadModule
{
static int number = 1;
enum class TSTATUS
{
NEW,
RUNNING,
STOP
};
template <typename T>
class Thread
{
using func_t = std::function<void(T)>; // 带参数的函数类型
private:
// 静态方法:pthread_create 的回调
static void *Routine(void *args)
{
// 把参数转换为 Thread 对象指针
Thread<T> *t = static_cast<Thread<T> *>(args);
t->_status = TSTATUS::RUNNING;
t->_func(t->_data); // 执行线程函数,传入数据
return nullptr;
}
void EnableDetach() { _joinable = false; }
public:
// 构造函数:传入函数和数据
Thread(func_t func, T data)
: _func(func), _data(data), _status(TSTATUS::NEW), _joinable(true)
{
_name = "Thread-" + std::to_string(number++);
_pid = getpid();
}
// 启动线程
bool Start()
{
if (_status != TSTATUS::RUNNING)
{
int n = ::pthread_create(&_tid, nullptr, Routine, this);
if (n != 0)
return false;
return true;
}
return false;
}
// 取消线程
bool Stop()
{
if (_status == TSTATUS::RUNNING)
{
int n = ::pthread_cancel(_tid);
if (n != 0)
return false;
_status = TSTATUS::STOP;
return true;
}
return false;
}
// 等待线程结束
bool Join()
{
if (_joinable)
{
int n = ::pthread_join(_tid, nullptr);
if (n != 0)
return false;
_status = TSTATUS::STOP;
return true;
}
return false;
}
// 分离线程
void Detach()
{
EnableDetach();
pthread_detach(_tid);
}
bool IsJoinable() { return _joinable; }
std::string Name() { return _name; }
~Thread() {}
private:
std::string _name; // 线程名称
pthread_t _tid; // 线程 ID
pid_t _pid; // 进程 ID
bool _joinable; // 是否可连接(默认是)
func_t _func; // 线程函数
TSTATUS _status; // 线程状态
T _data; // 传递给线程的数据
};
}
4. 支持可变参数的线程封装(更现代的 C++ 方式)
#include <iostream>
#include <functional> // std::function 和 std::bind
#include <memory> // std::shared_ptr 和 std::unique_ptr
#include <pthread.h> // POSIX 线程库
#include <unistd.h>
class Thread
{
public:
Thread() : thread_id_(0), running_(false) {}
~Thread()
{
if (running_) {
pthread_detach(thread_id_); // 析构时分离,避免资源泄漏
}
}
// 模板方法:接受任意可调用对象和任意参数
template <typename Callable, typename... Args>
bool start(Callable&& func, Args&&... args)
{
if (running_)
{
std::cerr << "线程已在运行中!" << std::endl;
return false;
}
// 把函数和参数打包成一个 std::function<void()> 对象
// 使用 std::bind 绑定函数和参数,std::forward 完美转发
auto task = std::make_shared<std::function<void()>>(
std::bind(std::forward<Callable>(func), std::forward<Args>(args)...)
);
// 在堆上创建 shared_ptr,确保执行期间任务对象有效
// 创建线程,传入任务指针
if (pthread_create(&thread_id_, nullptr, &Thread::threadEntry,
new std::shared_ptr<std::function<void()>>(task)) != 0)
{
std::cerr << "创建线程失败!" << std::endl;
return false;
}
running_ = true;
return true;
}
// 等待线程结束
void join()
{
if (running_)
{
pthread_join(thread_id_, nullptr);
running_ = false;
}
}
private:
pthread_t thread_id_; // 线程 ID
bool running_; // 线程是否在运行
// 静态线程入口函数
static void* threadEntry(void* arg)
{
// 用 unique_ptr 管理 shared_ptr 的指针,确保资源释放
std::unique_ptr<std::shared_ptr<std::function<void()>>> task_ptr(
static_cast<std::shared_ptr<std::function<void()>>*>(arg)
);
auto task = *task_ptr; // 解引用获取任务对象
(*task)(); // 执行任务
return nullptr;
}
};
// 测试函数:带多个参数
void printMessage(const std::string& message, int value, int a, int b, int c)
{
std::cout << "消息: " << message << ", 数值: " << value << std::endl;
std::cout << "a:" << a << std::endl;
std::cout << "b:" << b << std::endl;
std::cout << "c:" << c << std::endl;
sleep(10);
}
int main()
{
Thread thread;
// 启动线程,可以传递任意函数和任意参数
thread.start(printMessage, "你好, 世界!", 42, 1, 2, 3);
thread.join();
return 0;
}
运行结果:
$ ./a.out
消息: 你好, 世界!, 数值: 42
a:1
b:2
c:3
$ ps -aL
PID LWP TTY TIME CMD
923509 923509 pts/1 00:00:00 a.out
923509 923510 pts/1 00:00:00 a.out
📌 知识点总结:为什么要把线程封装成 C++ 类?封装思路是什么?
把线程封装成类有三大好处:① 对象化管理——每个线程就是一个对象,创建、启动、停止、等待都通过方法调用,代码更清晰;② 自动资源管理——析构函数里自动处理分离/回收,不容易忘;③ 类型安全——可以用模板支持任意参数类型,避免裸的 void* 转换。
封装的核心理念是:pthread_create 需要一个 void* (*)(void*) 类型的函数,但我们想要的是面向对象的方法调用。所以技巧就是——把 this 指针作为参数传给 pthread_create 的静态包装函数,在包装函数里再把 this 转回来调用真正的成员函数。
六、附录:源码阅读(glibc pthread_create 源码分析)
1. pthread_create 主流程(glibc-2.4 / nptl/pthread_create.c)
// 版本:__pthread_create_2_1
// GLIBC_2.1 版本的 pthread_create 实现
int __pthread_create_2_1(newthread, attr, start_routine, arg)
pthread_t *newthread; // 输出:线程 ID
const pthread_attr_t *attr; // 线程属性
void *(*start_routine)(void *); // 线程函数
void *arg; // 参数
{
STACK_VARIABLES;
// 重点1:获取线程属性,如果用户没设置就用默认属性
const struct pthread_attr *iattr = (struct pthread_attr *)attr;
if (iattr == NULL)
iattr = &default_attr;
// 重点2:pd(thread descriptor)是线程控制块 TCB 的指针
struct pthread *pd = NULL;
// 重点3:ALLOCATE_STACK 申请栈空间和 TCB 内存
// 它会在进程的共享区申请一大块内存,struct pthread 在这块内存的开头
int err = ALLOCATE_STACK(iattr, &pd);
if (__builtin_expect(err != 0, 0))
return err;
// 初始化 TCB(线程控制块)
#ifdef TLS_TCB_AT_TP
pd->header.self = pd; // 自引用指针
pd->header.tcb = pd; // TLS 自引用
#endif
// 重点4:把要执行的方法和参数保存到 TCB 中
pd->start_routine = start_routine;
pd->arg = arg;
// 复制线程属性标志
struct pthread *self = THREAD_SELF;
pd->flags = ...;
// 初始化 joinid(用于判断是否分离)
pd->joinid = iattr->flags & ATTR_FLAG_DETACHSTATE ? pd : NULL;
// ... 各种调度参数、安全设置的复制 ...
// 重点5:把 pd(TCB 地址)作为线程 ID 返回给用户
// 所以用户在用户态拿到的 pthread_t 本质上就是一个虚拟地址!
*newthread = (pthread_t)pd;
// 重点6:检查线程是否是分离状态
bool is_detached = IS_DETACHED(pd);
// 重点7:调用 create_thread 真正创建线程
err = create_thread(pd, iattr, STACK_VARIABLES_ARGS);
if (err != 0)
{
if (!is_detached)
__deallocate_stack(pd); // 失败时回收栈
return err;
}
return 0;
}
// 版本信息:把 __pthread_create_2_1 导出为 pthread_create 符号
versioned_symbol(libpthread, __pthread_create_2_1, pthread_create, GLIBC_2_1);
2. 线程属性结构体
// 线程属性结构体
struct pthread_attr
{
struct sched_param schedparam; // 调度参数和优先级
int schedpolicy; // 调度策略
int flags; // 各种标志(分离状态、作用域等)
size_t guardsize; // 警戒区大小
void *stackaddr; // 栈地址(用户可自定义)
size_t stacksize; // 栈大小
cpu_set_t *cpuset; // CPU 亲和性掩码
size_t cpusetsize; // 亲和性掩码大小
};
3. struct pthread —— 线程控制块 TCB
// 线程描述符数据结构(核心)
struct pthread
{
union {
#if !TLS_DTV_AT_TP
tcbhead_t header; // TLS 线程本地存储相关的头部
#else
struct {
int multiple_threads; // 是否有多个线程
} header;
#endif
void *__padding[16]; // 填充字节
};
list_t list; // 在 stack_used 或 __stack_user 链表上的链接
pid_t tid; // 线程 ID(内核的 LWP ID)
pid_t pid; // 进程 ID
// ... 稳健互斥锁相关 ...
struct _pthread_cleanup_buffer *cleanup; // 清理函数缓冲区
struct pthread_unwind_buf *cleanup_jmp_buf; // 异常展开信息
int cancelhandling; // 取消处理的标志位
// 线程特有数据
struct pthread_key_data specific_1stblock[...];
struct pthread_key_data *specific[...];
bool specific_used;
bool report_events; // 是否报告事件
bool user_stack; // 是否使用用户提供的栈
bool stopped_start; // 启动时是否先暂停
lll_lock_t lock; // 同步锁
struct pthread *joinid; // 等待 join 的线程 ID
// 如果 joinid == pd 自己,表示是分离状态
// 实际判断宏:#define IS_DETACHED(pd) ((pd)->joinid == (pd))
int flags; // 标志位
void *result; // 线程函数的返回值(pthread_join 读取的就是它)
struct sched_param schedparam; // 调度参数
int schedpolicy; // 调度策略
void *(*start_routine)(void *); // 用户指定的线程函数
void *arg; // 用户指定的参数
// ... 调试状态 ...
void *stackblock; // 线程栈的起始地址
size_t stackblock_size; // 线程栈的大小
size_t guardsize; // 警戒区大小
// ...
};
4. allocate_stack —— 栈的分配
// 路径:nptl/allocatestack.c
// 实际调用的是 allocate_stack 函数
static int
allocate_stack(const struct pthread_attr *attr, struct pthread **pdp,
ALLOCATE_STACK_PARMS)
{
struct pthread *pd;
size_t size;
size_t pagesize_m1 = __getpagesize() - 1;
// 获取栈大小(用户设置或默认值,默认通常是 8MB)
size = attr->stacksize ?: __default_stacksize;
// 如果用户已经设置了栈地址,直接使用(但一般我们不设置,走默认流程)
if (__builtin_expect(attr->flags & ATTR_FLAG_STACKADDR, 0))
{
// ... 用户提供栈的处理逻辑 ...
}
else
{
// ---- 我们关心的默认流程 ----
// 优先尝试从 pthread 的缓存中获取栈
pd = get_cached_stack(&size, &mem);
if (pd == NULL)
{
// 缓存中没有,用 mmap 在共享区申请匿名内存
// MAP_PRIVATE | MAP_ANONYMOUS 表示私有匿名映射
mem = mmap(NULL, size, prot,
MAP_PRIVATE | MAP_ANONYMOUS | ARCH_MAP_FLAGS, -1, 0);
if (__builtin_expect(mem == MAP_FAILED, 0))
return errno;
}
// 重点:把 struct pthread(TCB)放在栈空间的末尾位置
// 这样栈向下生长,TCB 在栈的"天花板"处
// pd 就是 TCB 的地址
#if TLS_TCB_AT_TP
pd = (struct pthread *)((char *)mem + size - coloring) - 1;
#elif TLS_DTV_AT_TP
pd = (struct pthread *)((((uintptr_t)mem + size - coloring
- __static_tls_size) & ~__static_tls_align_m1) - TLS_PRE_TCB_SIZE);
#endif
// 记录栈块的信息
pd->stackblock = mem; // 栈起始地址
pd->stackblock_size = size; // 栈大小
// ... 其他初始化 ...
}
// 通过二级指针返回 TCB 地址
*pdp = pd;
return 0;
}
5. create_thread —— 调用 clone 系统调用
static int
create_thread(struct pthread *pd, const struct pthread_attr *attr,
STACK_VARIABLES_PARMS)
{
// 设置 clone 标志位 —— 这些标志决定了新创建的是"线程"而不是"进程"
int clone_flags = (
CLONE_VM // 共享地址空间(最重要!线程的关键标志)
| CLONE_FS // 共享文件系统信息
| CLONE_FILES // 共享文件描述符表
| CLONE_SIGNAL // 共享信号处理
| CLONE_SETTLS // 设置线程本地存储(TLS)
| CLONE_PARENT_SETTID // 父线程获取子线程 ID
| CLONE_CHILD_CLEARTID // 子线程退出时清除 ID
| CLONE_SYSVSEM // 共享 System V 信号量
// | CLONE_DETACHED // 早期版本的分离标志
| 0
);
// 调用 do_clone,最终调用 ARCH_CLONE(即 __clone)
int res = do_clone(pd, attr, clone_flags, start_thread,
STACK_VARIABLES_ARGS, stopped);
return res;
}
6. do_clone 和 ARCH_CLONE
static int
do_clone(struct pthread *pd, const struct pthread_attr *attr,
int clone_flags, int (*fct)(void *), STACK_VARIABLES_PARMS,
int stopped)
{
// 增加全局线程计数
atomic_increment(&__nptl_nthreads);
// 调用 ARCH_CLONE(即 __clone,用汇编封装 clone 系统调用)
if (ARCH_CLONE(fct, STACK_VARIABLES_ARGS, clone_flags,
pd, &pd->tid, TLS_VALUE, &pd->tid) == -1)
{
atomic_decrement(&__nptl_nthreads);
if (IS_DETACHED(pd))
__deallocate_stack(pd);
return errno;
}
return 0;
}
ARCH_CLONE 是 __clone,这是一个用汇编实现的函数(sysdeps/unix/sysv/linux/x86_64/__clone.S):
ENTRY (BP_SYM (__clone))
// 参数检查
movq $-EINVAL,%rax
testq %rdi,%rdi // 检查函数指针是否为 NULL
jz SYSCALL_ERROR_LABEL
testq %rsi,%rsi // 检查栈指针是否为 NULL
jz SYSCALL_ERROR_LABEL
// 把参数压入新栈
subq $16,%rsi
movq %rcx,8(%rsi)
movq %rdi,0(%rsi)
// 设置系统调用参数
movq %rdx, %rdi
movq %r8, %rdx
movq %r9, %r8
movq 8(%rsp), %r10
movl $SYS_ify(clone),%eax // 设置系统调用号为 clone
syscall // 陷入内核,创建轻量级进程
testq %rax,%rax
jl SYSCALL_ERROR_LABEL
jz L(thread_start) // 子线程从这里开始执行
📌 知识点总结:pthread_create 底层到底干了什么?glibc 源码能告诉我们什么?
读 glibc 源码让我们看到了线程创建的完整拼图:
- 分配 TCB 和栈:
allocate_stack用mmap在进程的共享区申请一块匿名内存(默认 8MB),struct pthread(TCB)放在这块内存的顶部,栈从 TCB 往下生长 - 填充 TCB:把线程函数、参数、各种属性填进 TCB
- 返回 TCB 地址作为 ID:
*newthread = (pthread_t)pd——所以用户拿到的pthread_t就是 TCB 的地址 - 调用 clone 系统调用:
ARCH_CLONE→syscall(SYS_ify(clone)),最关键的是传入了CLONE_VM标志——表示新创建的轻量级进程和父进程共享地址空间,这也就是"线程"的本质
整个过程就是:pthread 库在用户态搭好台子(申请内存、填好 TCB),然后一个 clone 系统调用让内核上场干活(创建共享地址空间的轻量级进程来执行线程函数)。
7. 线程栈的特殊性
进程/主线程的栈:
- 在进程地址空间的栈区,向下生长
- 可以动态增长(通过缺页异常自动扩充)
- 超出上限会报段错误
子线程的栈:
- 在进程地址空间的共享区(堆和栈之间的文件映射区)
- 通过
mmap系统调用分配,大小固定(默认 8MB) - 不能动态增长,一旦用完就没了
// glibc 中线程栈的申请
mem = mmap(NULL, size, prot,
MAP_PRIVATE | MAP_ANONYMOUS | MAP_STACK, -1, 0);
之后底层调用 sys_clone 系统调用,把 mmap 得到的栈指针传给内核:
int sys_clone(struct pt_regs *regs)
{
unsigned long clone_flags;
unsigned long newsp; // 线程的栈指针(来自 mmap)
clone_flags = regs->bx;
newsp = regs->cx; // 获取 mmap 得到的线程栈指针
if (!newsp)
newsp = regs->sp; // 如果没有指定,使用当前栈
return do_fork(clone_flags, newsp, regs, 0, parent_tidptr, child_tidptr);
}
8. 自己调用 clone 系统调用的示例
#define _GNU_SOURCE
#include <sched.h> // clone 函数
#include <stdio.h>
#include <stdlib.h>
#include <sys/wait.h> // waitpid
#include <unistd.h> // getpid
#define STACK_SIZE (1024 * 1024) // 1MB 的栈空间
// 子进程(轻量级进程)执行的函数
static int child_func(void *arg) {
printf("子进程: PID = %d\n", getpid());
return 0;
}
int main() {
// 为子进程分配栈空间
char *stack = (char*)malloc(STACK_SIZE);
if (stack == NULL) {
perror("malloc");
exit(EXIT_FAILURE);
}
// 使用 clone 创建子进程(子线程)
// CLONE_VM 标志表示共享地址空间——这就成了"线程"而不是"进程"
// 栈要指向栈顶(x86 栈向下生长,所以指向栈空间末尾)
pid_t pid = clone(child_func, stack + STACK_SIZE, CLONE_VM | SIGCHLD, NULL);
if (pid == -1) {
perror("clone");
free(stack);
exit(EXIT_FAILURE);
}
printf("父进程: PID = %d, 子进程 PID = %d\n", getpid(), pid);
waitpid(pid, NULL, 0); // 等待子进程结束
free(stack);
return 0;
}
📌 知识点总结:线程栈和主线程栈有什么不同?为什么子线程的栈不能动态增长?
主线程的栈在地址空间的栈区,由编译器自动管理,可以动态增长——缺页了内核就自动分配新页面。而子线程的栈是 mmap 在共享区申请的一块固定大小的内存(默认 8MB),它背后没有"随时可以扩充"的虚拟地址空间支持,用完了就是完了。这就像主线程的栈是"有无限扩张可能的自留地",而子线程的栈是"面积固定的租赁房"。
这也解释了为什么 pthread 创建时要指定栈大小(用户可以自定义),以及为什么递归层数太深或局部变量太大时子线程更容易栈溢出。
9. 页表与页表项
页表在 Linux 内核中的表示:
// 页表标志位
#define L_PTE_PRESENT (1 << 0) // 页是否在物理内存中
#define L_PTE_FILE (1 << 1) // 文件映射(仅当 !PRESENT 时)
#define L_PTE_YOUNG (1 << 1) // 最近是否被访问
#define L_PTE_BUFFERABLE (1 << 2) // 是否可缓冲
#define L_PTE_CACHEABLE (1 << 3) // 是否可缓存
#define L_PTE_USER (1 << 4) // 用户态可访问
#define L_PTE_WRITE (1 << 5) // 可写
#define L_PTE_EXEC (1 << 6) // 可执行
#define L_PTE_DIRTY (1 << 7) // 是否被修改过(脏页)
#define L_PTE_COHERENT (1 << 9) // I/O 一致性
#define L_PTE_SHARED (1 << 10) // CPU 间共享
#define L_PTE_ASID (1 << 11) // 非全局(使用 ASID)
// 页表项和页目录项的类型定义
typedef struct { unsigned long pte; } pte_t; // 页表项
typedef struct { unsigned long pgd; } pgd_t; // 页全局目录项
// 进程的内存描述符中包含页目录
struct mm_struct {
struct vm_area_struct *mmap; // 虚拟内存区域链表
// ...
pgd_t *pgd; // 页目录起始地址(指向第一级页表)
};
总结:线程概念与控制的完整图景
| 主题 | 一句话总结 |
|---|---|
| 线程是什么 | 进程内部的执行流,共享进程的地址空间和资源 |
| 分页管理 | 虚拟地址通过多级页表映射到离散的物理内存,TLB 加速转换 |
| 缺页异常 | 物理内存中没有对应页面时触发,操作系统负责从磁盘加载 |
| 线程优缺点 | 创建/切换快但健壮性差,一个线程崩溃拖垮整个进程 |
| 进程 vs 线程 | 进程管资源分配,线程管调度执行 |
| 线程控制 | create/exit/cancel/join/detach 五件套 |
| pthread_t 本质 | 一个指向 TCB 的虚拟地址 |
| 线程栈 | 子线程的栈在共享区通过 mmap 分配,固定大小不能增长 |
| 底层实现 | pthread 库填充 TCB → clone 系统调用(CLONE_VM 标志)→ 内核创建 LWP |

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐



 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)