【Agent智能体22 | 构建AI工作流的技巧-延迟、成本优化】
本文总结了优化AI智能体工作流延迟和成本的实用技巧。针对延迟优化,建议通过基准测试识别瓶颈环节,采用并行处理或更换更快的小模型/服务商。成本优化则聚焦三类计费点:按Token计费的LLM调用(可精简提示词)、按次收费的API工具(寻找廉价替代方案)以及服务器计算资源。核心思路是通过测量各环节指标,优先优化高开销组件。文章源自吴恩达智能体教程的实践总结,为开发者提供了可落地的性能优化方法论。
声明:本篇博客是以吴恩达的【Agent智能体】教程为基础,并对其中的内容做了笔记整理以及个人收获的总结。
延迟、成本优化的优先级一般较低。下面展示一下相关的思路:
降低延迟
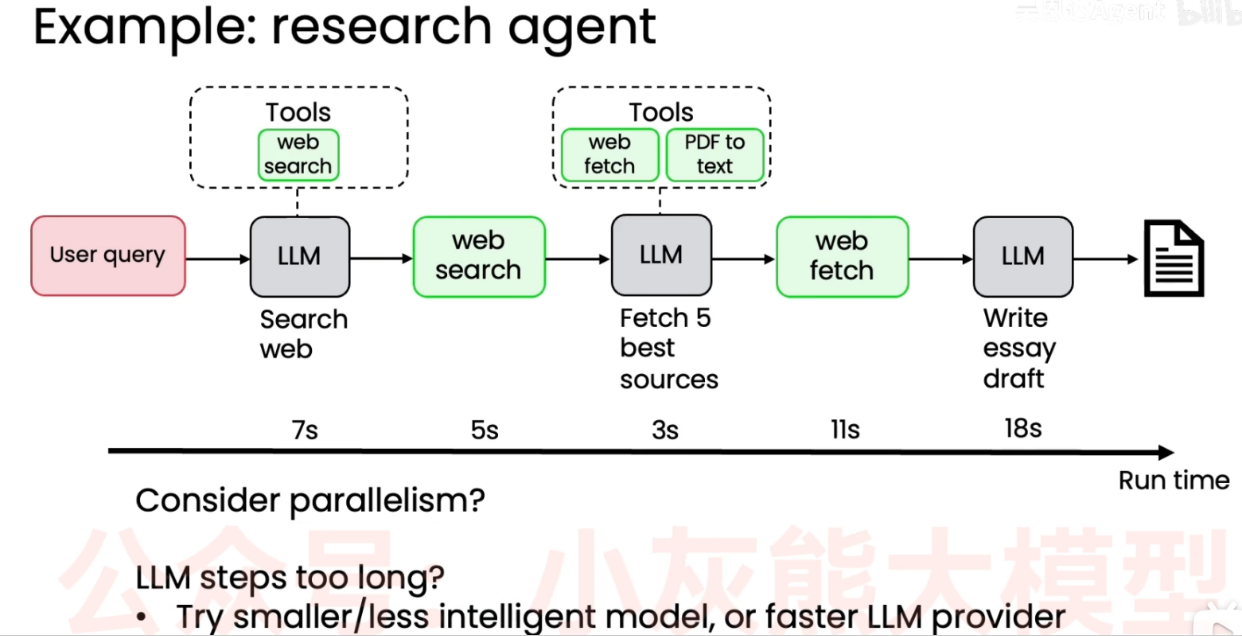
如果你想优化智能体工作流的延迟,常用的方法是对工作流进行基准测试或计时,通过查看整体时间线 我可以判断哪些环节有最大优化空间,可以加快速度,常用的方法如下:
- 考虑并行处理 (Consider parallelism?)
- 如果有些步骤还没并行处理,比如网页抓取,可以考虑将部分操作并行执行,而不是排队挨个抓取,从而大幅缩短总运行时间。
- LLM 步骤耗时过长? (LLM steps too long?)
- 或者发现某些大语言模型步骤耗时过长,尝试使用规模较小/稍弱但速度更快的模型 (smaller/less intelligent model),或者更换响应速度更快的 LLM 服务提供商 (faster LLM provider)。
通过这种计时分析 你能判断哪些环节最值得优化
减少成本

在构建和运行 AI 工作流时,通常需要为以下三类操作付费:
- LLM 步骤 (LLM steps - pay per token): 调用大语言模型(如 GPT-4、Gemini 等)的费用。这是基于输入(Prompt)和输出(生成的文本)的词块数量 (Token) 来计费的。处理的文本越长,费用越高。
- API 调用工具 (Any API-calling tools - pay per API call): 当代理使用外部工具(如谷歌搜索 API、天气 API、数据库查询等)时,通常是按调用次数 (per API call) 固定计费的。
- 计算步骤 (Compute steps - based on server capacity/cost): 在本地或云服务器上执行普通代码、数据处理或运行脚本的成本。这取决于所消耗的服务器计算资源和时长。
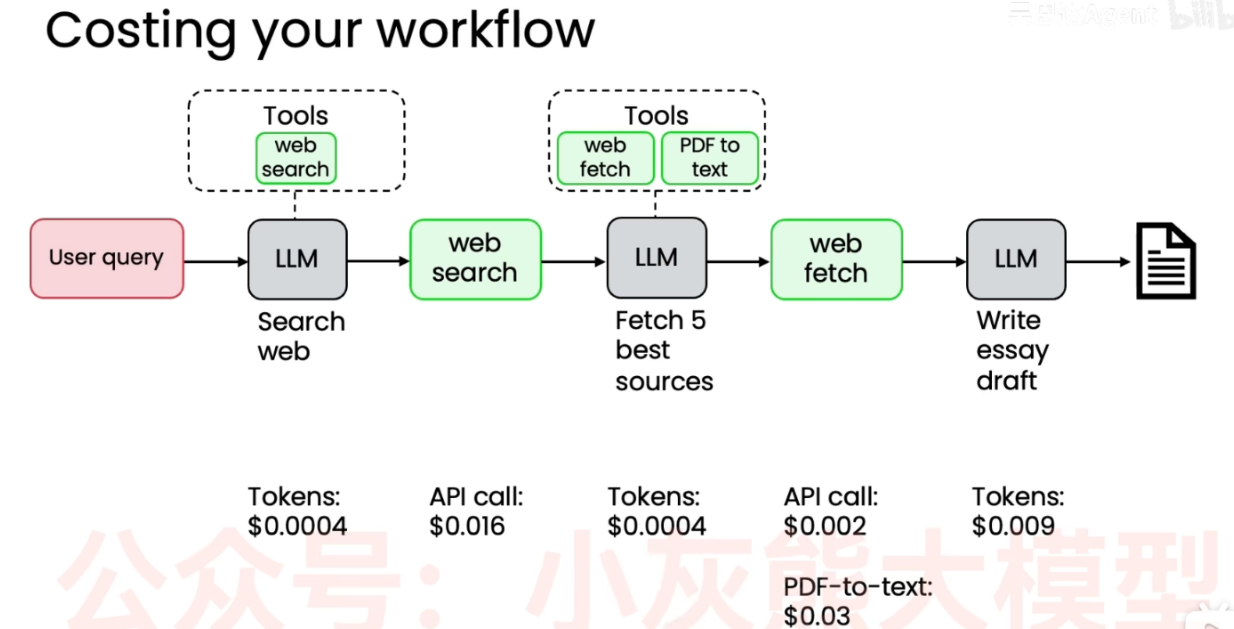
在优化成本方面,同样可以对每一步的成本进行计算 从而基准测试并决定哪些步骤需要优化,重点关注优化哪些环节。
有时候优化提示词减少无效长文本,或者寻找更便宜的替代 API 工具,能大幅降低整体工作流的运行费用。
总结:
所以发现当成本或延迟成为问题时,只需测量每一步的成本或延迟这通常能为你提供依据 判断该优先优化哪些组件
到此,构建AI工作流的技巧相关的知识就介绍完了,下面该介绍“规划”这个涉及模式了!
如果这篇文章对你有帮助,欢迎点赞、评论、关注、收藏。你们的支持是我前进的动力!

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐
 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)