vllm部署大模型全整合(多种部署)

物理机信息
| 机器名称 | 机器IP | 操作系统 | 角色 | 显卡 |
|---|---|---|---|---|
| k8s-master | 10.132.47.90 | ubuntu 22.04 | master | Tesla T4 16G |
| k8s-node1 | 10.132.47.91 | ubuntu 22.04 | Worker | Tesla T4 16G |
| k8s-node2 | 10.132.47.92 | ubuntu 22.04 | Worker | Tesla T4 16G |
| k8s-node3 | 10.132.47.95 | ubuntu 22.04 | Worker | NVIDIA A40 48G |
| k8s-node4 | 10.132.47.96 | ubuntu 22.04 | Worker | NVIDIA A40 48G |
GPU驱动相关安装
一、基础环境配置
# 检查操作系统版本(推荐Ubuntu 20.04/22.04或CentOS 7/8)
cat /etc/os-release
# 检查内核版本(需要4.15+)
uname -r
cat /etc/os-release
cat /etc/os-release
# 检查GPU硬件
lspci | grep -i nvidia
# 如果看不到GPU,检查BIOS设置和PCIe插槽
# 检查系统资源
free -h
df -h
lscpu
二、安装NVIDIA驱动
# Ubuntu系统安装驱动
# 添加NVIDIA官方仓库
sudo apt update
sudo apt install -y software-properties-common
sudo add-apt-repository ppa:graphics-drivers/ppa
sudo apt install -y alsa-utils
sudo apt update
sudo apt install ubuntu-drivers-common
# 查看推荐的驱动版本
ubuntu-drivers devices
# 安装推荐的驱动
sudo apt install -y nvidia-driver-580
# 重启系统使驱动生效
sudo reboot
# 重启后验证驱动安装
nvidia-smi
# 预期输出:显示GPU信息、驱动版本、CUDA版本
Thu Jan 22 14:19:34 2026
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 580.126.09 Driver Version: 580.126.09 CUDA Version: 13.0 |
+-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 Tesla T4 Off | 00000000:00:0A.0 Off | 0 |
| N/A 42C P8 9W / 70W | 0MiB / 15360MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+
三、安装 CUDA
# 卸载旧的CUDA工具包
sudo apt-get purge nvidia-cuda-toolkit
sudo apt-get autoremove
sudo apt-get clean
添加 NVIDIA 官方源
# 添加GPG密钥
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-keyring_1.1-1_all.deb
sudo dpkg -i cuda-keyring_1.1-1_all.deb
# 更新源列表
sudo apt-get update
安装 CUDA Toolkit
# 安装CUDA 13.0(和你的驱动版本匹配)
sudo apt-get install -y cuda-13-0
配置环境变量
# 编辑~/.bashrc文件
vim ~/.bashrc
# 在文件末尾添加以下内容
export PATH=/usr/local/cuda-13.0/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-13.0/lib64:$LD_LIBRARY_PATH
# 保存并退出后,生效配置
source ~/.bashrc
验证安装
# 检查CUDA版本
nvcc -V
# 预期输出应该包含:
# nvcc: NVIDIA (R) Cuda compiler driver
# Copyright (c) 2005-2024 NVIDIA Corporation
# Built on ...
# Cuda compilation tools, release 13.0, V13.0.xxx
四、安装 NVIDIA Container Toolkit
安装 NVIDIA Container Toolkit,参考[Installing the NVIDIA Container Toolkit](
#中科大源安装
#拉取中科大 GPG 密钥并写入
curl -fsSL https://mirrors.ustc.edu.cn/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg
#配置适配 Ubuntu 22.04 的 nvidia 源列表
# 生成源列表并添加签名验证(适配 jammy 版本)
curl -s -L https://mirrors.ustc.edu.cn/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
# 关键:替换源中的系统版本为 jammy(Ubuntu 22.04),避免源适配错误
sudo sed -i 's/focal/jammy/g' /etc/apt/sources.list.d/nvidia-container-toolkit.list
# 把源列表里的 nvidia.github.io 替换为 mirrors.ustc.edu.cn
sudo sed -i 's#nvidia.github.io/libnvidia-container#mirrors.ustc.edu.cn/libnvidia-container#g' /etc/apt/sources.list.d/nvidia-container-toolkit.list
#更新 apt 缓存
sudo apt update -y
#安装 nvidia-container-toolkit
sudo apt install -y nvidia-container-toolkit
四、安装docker
# 1. 安装依赖
sudo apt install -y apt-transport-https ca-certificates curl gnupg lsb-release
# 2. 配置阿里云yum源
curl -fsSL http://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg
# 3. 修改 Docker 软件源为阿里云
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] http://mirrors.aliyun.com/docker-ce/linux/ubuntu \
$(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
# 4. 更新
sudo apt update
# 5. 安装 Docker 最新版本
sudo apt install -y docker-ce docker-ce-cli containerd.io
#验证 Docker 是否安装成功
docker --version
# 3. 配置Docker镜像加速和cgroup驱动、GPU使用
mkdir -p /etc/docker && cat > /etc/docker/daemon.json << 'EOF'
{
"exec-opts": ["native.cgroupdriver=systemd"],
"registry-mirrors": [
"https://mirror.aliyuncs.com",
"https://hub-mirror.c.163.com",
"https://docker.m.daocloud.io"
],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"default-runtime": "nvidia",
"runtimes": {
"nvidia": {
"path": "nvidia-container-runtime",
"runtimeArgs": []
}
},
"storage-driver": "overlay2"
}
EOF
# 4. 启动Docker
systemctl daemon-reload && systemctl start docker && systemctl enable docker
# 5. 配置Docker运行时(如果使用Docker)
sudo nvidia-ctk runtime configure --runtime=docker
sudo systemctl restart docker
# 安装指定版本 如20.10.24
sudo apt install -y docker-ce=5:20.10.24~3-0~ubuntu-jammy docker-ce-cli=5:20.10.24~3-0~ubuntu-jammy containerd.io
五、验证docker可以使用GPU
#拉取镜像
docker pull nvidia/cuda:11.8.0-base-ubuntu22.04
#运行
docker run --rm --gpus all nvidia/cuda:11.8.0-base-ubuntu22.04 nvidia-smi
docker pull swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/nvidia/cuda:11.8.0-base-ubuntu22.04
#运行
docker run --rm --gpus all swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/nvidia/cuda:11.8.0-base-ubuntu22.04 nvidia-smi
#一键验证
for host in master node1 node2; do echo -e "\n==================== $host Docker GPU 测试 ===================="; ssh $host "docker run --rm --gpus all swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/nvidia/cuda:11.8.0-base-ubuntu22.04 nvidia-smi"; done
# 预期输出:容器内能看到GPU信息
root@k8s-master:~# docker run --rm --gpus all swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/nvidia/cuda:11.8.0-base-ubuntu22.04 nvidia-smi
Thu Jan 22 06:33:02 2026
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 580.126.09 Driver Version: 580.126.09 CUDA Version: 13.0 |
+-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 Tesla T4 Off | 00000000:00:0A.0 Off | 0 |
| N/A 42C P8 9W / 70W | 0MiB / 15360MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| No running processes found |
+---------------------------------------------------------------------------------------+
linux部署(单机单卡)
一、前置条件与准备
# 验证驱动安装
nvidia-smi # 应显示GPU信息及CUDA版本兼容性
# 验证CUDA安装
nvcc -V # 应显示CUDA 12.1版本信息
# 安装基础依赖
sudo apt install -y build-essential gcc g++ cmake git wget curl python3 python3-pip python3-venv
# 配置pip国内镜像(加速安装)
pip3 config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
pip3 config set global.trusted-host pypi.tuna.tsinghua.edu.cn
二、创建 Python 虚拟环境
# 创建虚拟环境
python3 -m venv vllm-env
# 激活环境
source vllm-env/bin/activate
# 升级pip
pip install --upgrade pip
#注意:机器重启后需要重新激活虚拟环境
source vllm-env/bin/activate
三、安装 vLLM
# 安装vLLM(自动包含PyTorch 2.1+依赖)
pip install vllm # 最新稳定版,支持Qwen3.5{insert\_element\_0\_}
# 验证安装
python -c "from vllm import LLM; print('vLLM安装成功')"
# 查看vLLM库文件路径
python -c "import vllm; print(vllm.__file__)"
# (vllm-env) root@ubuntu:~# python -c "import vllm; print(vllm.__file__)"
# /root/vllm-env/lib/python3.10/site-packages/vllm/__init__.py
可选:从源码编译(支持最新功能)
git clone https://github.com/vllm-project/vllm.git
cd vllm
pip install -e .
四、下载千问 3.5-7B 模型
使用 ModelScope(国内推荐)
# 安装modelscope
pip install modelscope
# 创建 /opt/models/ 目录(-p 表示自动递归创建,不存在就新建)
sudo mkdir -p /opt/models/
# 将文件夹权限赋予当前用户
sudo chown -R $USER:$USER /opt/models/
# 下载模型到文件夹内
modelscope download --model Qwen/Qwen3.5-9B --local_dir /opt/models/Qwen3.5-9B
五、启动
后续启动 vLLM 时,模型路径必须填这个路径:
# 需要注意这是前台启动的
vllm serve /opt/models/Qwen3.5-9B \
--served-model-name qwen35 \
--speculative-config '{"method":"mtp","num_speculative_tokens":4}' \
--tensor-parallel-size 1 \
--gpu-memory-utilization 0.95 \
--max-model-len 262144 \
--max-num-seqs 8 \
--enable-prefix-caching \
--trust-remote-code \
--enable-auto-tool-choice \
--tool-call-parser qwen3_coder \
--host 0.0.0.0 \
--port 8000
--speculative-config '{"method":"mtp","num_speculative_tokens":4}' #投机解码
--max-model-len 262144 #最大上下文256k
--enable-prefix-caching \
--trust-remote-code \
--enable-auto-tool-choice \
--tool-call-parser qwen3_coder \
#上面三个是为了可以接入open code等工具
这个命令是前台启动,测试需要重开两个窗口
窗口1:测试
curl http://127.0.0.1:8000/v1/chat/completions -H "Content-Type: application/json" -d '{
"model": "qwen35",
"messages": [{"role": "user", "content": "你好,请介绍一下你自己"}],
"temperature": 0.7
}'
"model": "/opt/models/Qwen3.5-9B" :这是模型的路径
窗口2:查看显卡状态
watch nvidia-smi
linux部署(单机多卡)
本章节使用的为机器master、node1、node2(ip可能不太对,无需在意)组建的1 Head 2 Worker 三节点,但是我配置建议1 Head 1 Worke
一、 配置虚拟环境和模型文件
(所有节点执行:master、node1、node2)
# 安装基础依赖
sudo apt install -y build-essential gcc g++ cmake git wget curl python3 python3-pip python3-venv
# 配置pip国内镜像(加速安装)
pip3 config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
pip3 config set global.trusted-host pypi.tuna.tsinghua.edu.cn
1. 创建 Python 虚拟环境
(所有节点执行:master、node1、node2)
# 创建虚拟环境
python3 -m venv vllm-env
# 激活环境,(注意:后续所有操作都需在此环境中执行)
source vllm-env/bin/activate
# 升级pip
pip install --upgrade pip
#注意:机器重启后需要重新激活虚拟环境
source vllm-env/bin/activate
2. 下载模型
(仅在master执行)
# 安装modelscope
pip install modelscope
# 创建 /models/ 目录(-p 表示自动递归创建,不存在就新建)
sudo mkdir -p /models/
# 将文件夹权限赋予当前用户
sudo chown -R $USER:$USER /models
# 只在10.132.47.60下载模型到文件夹内
modelscope download --model Qwen/Qwen3.5-9B --local_dir /models/Qwen3.5-9B
3. 创建NFS服务共享模型
安装 NFS 服务(仅在master执行)
sudo apt update
sudo apt install -y nfs-kernel-server
配置 NFS 共享目录,编辑 /etc/exports 文件,添加共享规则:
sudo vim /etc/exports
#在文件末尾添加以下内容(根据需求调整):
/models *(rw,sync,no_root_squash,no_subtree_check)
使配置生效
sudo exportfs -arv
动 NFS 服务并设置开机自启
sudo systemctl start nfs-kernel-server
sudo systemctl enable nfs-kernel-server
客户端挂载(仅在node1、node2执行)
sudo apt install -y nfs-common
创建本地挂载目录
sudo mkdir -p /models
临时挂载 NFS 到 /models
sudo mount -t nfs 10.132.47.90:/models /models
永久挂载,编辑 /etc/fstab 文件:
sudo vim /etc/fstab
#添加以下内容(或修改之前的挂载配置):
10.132.47.90:/models /models nfs defaults 0 0
执行挂载验证
sudo mount -a
#验证挂载
df -h | grep /models
#进入 /models 目录,应该能看到和服务端一样的内容(如 Qwen3.5-4B 文件夹)。
四、安装核心依赖
(所有节点执行:master、node1、node2)
在虚拟环境中安装 vLLM 和 Ray:
# 安装 vLLM (会自动安装匹配的 PyTorch 和 CUDA 依赖)
pip install vllm
# 安装 Ray (包含 Dashboard 和必要的集群组件)
pip install "ray[default]"
验证安装
# 检查 vLLM 版本
python3 -c "import vllm; print(f'vLLM version: {vllm.__version__}')"
# 检查 Ray 版本
ray --version
五、启动Ray 集群
在 Head 节点(10.132.32.90)启动 Ray Head
# 确保在虚拟环境中
source ~/vllm-env/bin/activate
# 启动 Ray Head
# --dashboard-host=0.0.0.0 允许外部访问 Dashboard (端口 8265)
ray start --head --port=6379 --dashboard-host=0.0.0.0 --node-ip-address=10.132.47.90 --disable-usage-stats
在 Worker 节点启动并加入集群
Next steps
To add another node to this Ray cluster, run
ray start --address='10.132.47.90:6379'
#请记录下这个地址。
# 确保在虚拟环境中
# 加入集群 (请替换为 Head 节点的实际 IP)
ray start --address='10.132.47.90:6379'
# 输出提示:Local node IP: xxx.xxx.xxx.xxx 表示成功加入。
验证集群状态
# 在 Head 节点 运行:
ray status
#显示集群的信息
(vllm-env) root@ubuntu:~# ray status
======== Autoscaler status: 2026-04-13 05:59:47.050278 ========
Node status
---------------------------------------------------------------
Active:
1 node_e9634775437fe647a43ba0f13a5afeaeb5e0369c906c11832c7f5bd9
1 node_88efd0d4ed2a70bada2f267b2695f67c43c909767a866cbdca7d1c9f
1 node_3812bbc61a51d34f71968dcc8f4722bbaf1649eb48fd8a29d10a8af3
Pending:
(no pending nodes)
Recent failures:
(no failures)
Resources
---------------------------------------------------------------
Total Usage:
0.0/96.0 CPU
0.0/3.0 GPU
0B/259.87GiB memory
0B/111.37GiB object_store_memory
From request_resources:
(none)
Pending Demands:
(no resource demands)
六、测试启动vLLM服务
在 Head 节点 的终端执行(如果是以太网而非 InfiniBand,建议设置):
# 强制使用以太网 (如果没有 IB 设备)
export NCCL_IB_DISABLE=1
# 设置 NCCL 日志级别 (方便排错,测试完可设为 INFO)
export NCCL_DEBUG=INFO
export NCCL_SOCKET_IFNAME=ens3 # 如果网卡名不是 ens3 请用 ip a 查看并替换
启动 vLLM API 服务 (前台测试)
在 Head 节点 的虚拟环境中执行:
注意:
- 这里以
Qwen/Qwen-9B为例(Qwen 3.5 发布后请替换名称)。--pipeline-parallel-size=3对应 3 台机器。- 需从 ModelScope 下载,需提前配置
export VLLM_USE_MODELSCOPE=True。
# 需要注意这是前台启动的
vllm serve /models/Qwen3.5-9B \
--served-model-name qwen35-9b \
--speculative-config '{"method":"mtp","num_speculative_tokens":4}' \
--tensor-parallel-size 3 \
--distributed-executor-backend ray \
--gpu-memory-utilization 0.95 \
--max-model-len auto \
--max-num-seqs 16 \
--enable-prefix-caching \
--trust-remote-code \
--enable-auto-tool-choice \
--tool-call-parser qwen3_coder \
--host 0.0.0.0 \
--port 8000
部署完成之后测试(前台部署,需要新开一个终端或者在其他机器上测试)
curl http://10.132.47.90:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "qwen35-9b",
"messages": [
{"role": "user", "content": "你好,介绍一下你自己"}
],
"temperature": 0.7,
"max_tokens": 2048
}'
集群监控入口
-
Ray 集群资源监控面板:
http://10.132.47.90:8265,可实时查看 3 台机器的 GPU/CPU 负载、任务调度状态 -
vLLM 健康检查:
curl http://10.132.47.90:8000/health,返回 200 即服务正常 -
Prometheus 性能指标:
http://10.132.47.90:8000/metrics,可接入监控系统做长期告警和趋势分析
k8s集群使用单卡
一、提前准备
已完成了:安装NVIDIA驱动、CUDA Toolkit、NVIDIA Container Toolkit、k8s集群
也可以自己准备高可用集群,本文只做了单master
| 机器名称 | 机器IP | 操作系统 | 角色 | 显卡 |
|---|---|---|---|---|
| k8s-master | 10.132.47.90 | ubuntu 22.04 | master | Tesla T4 16G |
| k8s-node1 | 10.132.47.91 | ubuntu 22.04 | Worker | Tesla T4 16G |
| k8s-node2 | 10.132.47.92 | ubuntu 22.04 | Worker | Tesla T4 16G |
| k8s-node3 | 10.132.47.95 | ubuntu 22.04 | Worker | NVIDIA A40 48G |
| k8s-node4 | 10.132.47.96 | ubuntu 22.04 | Worker | NVIDIA A40 48G |
二、NVIDIA Device Plugin部署
1. 环境监测
在安装 NVIDIA Device Plugin 之前,请确保你的集群满足以下条件:
- 所有节点已安装 NVIDIA 显卡驱动(驱动版本需与 GPU 型号匹配)
- 节点已安装
nvidia-container-toolkit(容器运行时需支持 GPU 调用) - k8s 集群已正常运行(版本建议 1.24+)
- 已配置 kubectl 并能正常访问集群
检查驱动:
# 检查 NVIDIA 驱动是否安装并输出 GPU 信息
nvidia-smi
检查工具包安装状态
# 检查 nvidia-container-toolkit 是否安装
dpkg -l | grep nvidia-container-toolkit
# 检查工具包版本(确保版本适配驱动)
nvidia-container-toolkit --version
验证容器运行时是否配置了 NVIDIA 运行时
# 检查 Docker 运行时列表,确认包含 nvidia
docker info | grep -i runtime
验证 k8s 集群已正常运行
# 检查 k8s 版本(确认 ≥1.24)
kubectl version
# 检查所有节点状态(需为 Ready)
kubectl get nodes
# 检查核心组件 Pod 状态(需为 Running)
kubectl get pods -n kube-system
2. 通过官方 YAML 安装
#下载文件
curl -O https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v0.18.0/deployments/static/nvidia-device-plugin.yml
#替换镜像
sed -i 's/nvcr.io\/nvidia\/k8s-device-plugin:v0.18.0/crpi-vdf183p7g8m4zpud.cn-hangzhou.personal.cr.aliyuncs.com\/shy_my\/k8s-device-plugin:v0.18.0/g' nvidia-device-plugin.yml
# 验证替换结果(查看文件中是否包含新镜像地址)
grep -n "image:" nvidia-device-plugin.yml
#部署
kubectl apply -f nvidia-device-plugin.yml
#检查
kubectl get pod -n kube-system | grep "nvidia-device-plugin"
文件内容
vim nvidia-device-plugin.yml
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: nvidia-device-plugin-daemonset
namespace: kube-system
spec:
selector:
matchLabels:
name: nvidia-device-plugin-ds
updateStrategy:
type: RollingUpdate
template:
metadata:
labels:
name: nvidia-device-plugin-ds
spec:
tolerations:
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
# Mark this pod as a critical add-on; when enabled, the critical add-on
# scheduler reserves resources for critical add-on pods so that they can
# be rescheduled after a failure.
# See https://kubernetes.io/docs/tasks/administer-cluster/guaranteed-scheduling-critical-addon-pods/
priorityClassName: "system-node-critical"
containers:
- image: crpi-vdf183p7g8m4zpud.cn-hangzhou.personal.cr.aliyuncs.com/shy_my/k8s-device-plugin:v0.18.0
name: nvidia-device-plugin-ctr
env: []
securityContext:
allowPrivilegeEscalation: false
capabilities:
drop: ["ALL"]
volumeMounts:
- name: kubelet-device-plugins-dir
mountPath: /var/lib/kubelet/device-plugins
volumes:
- name: kubelet-device-plugins-dir
hostPath:
path: /var/lib/kubelet/device-plugins
type: Directory
3. 测试 GPU 调度
# 创建 gpu-demo-v0.18.0.yaml
cat > gpu-demo-v0.18.0.yaml << EOF
apiVersion: v1
kind: Pod
metadata:
name: nvidia-gpu-demo-v0-18-0
spec:
restartPolicy: OnFailure
containers:
- name: gpu-test
image: swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/nvidia/cuda:12.2.0-base-ubuntu22.04
command: ["bash", "-c", "nvidia-smi && sleep 600"] # 执行 nvidia-smi 后休眠 10 分钟
resources:
limits:
nvidia.com/gpu: 1
requests:
nvidia.com/gpu: 1
EOF
# 部署测试 Pod
kubectl apply -f gpu-demo-v0.18.0.yaml
# 查看 Pod 日志(验证 GPU 调用)
kubectl logs -n default nvidia-gpu-demo-v0-18-0
root@ubuntu:~/device-plugin-yaml# kubectl logs -n default nvidia-gpu-demo-v0-18-0
Tue Jan 27 06:52:40 2026
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.288.01 Driver Version: 535.288.01 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 Tesla T4 Off | 00000000:00:0A.0 Off | 0 |
| N/A 40C P8 9W / 70W | 2MiB / 15360MiB | 0% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| No running processes found |
+---------------------------------------------------------------------------------------+
三、 模型文件预下载
部署NFS作为存储
master节点用来作为NFS服务
1. 安装 NFS 服务(已配置可跳过)
sudo apt update
apt update && apt install -y nfs-kernel-server nfs-common
2. 配置 NFS 共享目录,编辑 /etc/exports 文件,添加共享规则:
mkdir -p /data
chmod 777 /data
chown nobody:nogroup /data
sudo vim /etc/exports
#在文件末尾添加以下内容(根据需求调整):
/date *(rw,sync,no_root_squash,no_subtree_check)
使配置生效
sudo exportfs -arv
3. NFS 服务并设置开机自启
sudo systemctl start nfs-kernel-server
sudo systemctl enable nfs-kernel-server
客户端部署挂载
sudo apt install -y nfs-common
4. 验证:
showmount -e 10.132.47.90
5. NFS 动态供应器部署
vim nfs-provisioner-complete.yaml
# ========================== 1. 服务账户:授权供应器访问 K8s API ==========================
# 声明Kubernetes API版本,ServiceAccount属于核心API组v1版本,用于提供Pod访问K8s API的身份凭证
apiVersion: v1
# 定义资源类型为ServiceAccount,为NFS动态供应器Pod分配独立身份,实现API访问授权
kind: ServiceAccount
metadata:
name: nfs-provisioner # ServiceAccount名称,后续部署和角色绑定将引用该名称
namespace: kube-system # 部署在kube-system命名空间(系统级组件常用命名空间,便于统一管理)
---
# ========================== 2. 集群角色:包含 leader 选举+存储操作完整权限 ==========================
# 声明RBAC相关API版本,ClusterRole属于rbac.authorization.k8s.io/v1组,用于定义集群级权限集合
apiVersion: rbac.authorization.k8s.io/v1
# 定义资源类型为ClusterRole,权限范围覆盖整个集群,包含NFS供应器所需的所有操作权限
kind: ClusterRole
metadata:
name: nfs-provisioner-runner # ClusterRole名称,标识该权限集合的用途
rules:
# 权限1:操作PersistentVolume(PV)资源,动态供应器需创建/删除PV以响应PVC请求
- apiGroups: [""] # 核心API组(空字符串表示核心组,包含PV、PVC等基础资源)
resources: ["persistentvolumes"] # 目标资源:持久化卷(PV)
verbs: ["get", "list", "watch", "create", "delete"] # 允许操作:查询、监听、创建、删除
# 权限2:操作PersistentVolumeClaim(PVC)资源,需监听PVC状态变化并完成绑定
- apiGroups: [""]
resources: ["persistentvolumeclaims"] # 目标资源:持久化卷声明(PVC)
verbs: ["get", "list", "watch", "update"] # 允许操作:查询、监听、更新(更新PVC绑定状态)
# 权限3:操作StorageClass资源,需读取存储类配置以匹配PVC的存储需求
- apiGroups: ["storage.k8s.io"] # 存储相关API组,包含StorageClass等存储资源
resources: ["storageclasses"] # 目标资源:存储类(StorageClass)
verbs: ["get", "list", "watch"] # 允许操作:仅查询、监听(无需修改存储类配置)
# 权限4:操作Events资源,用于记录供应器运行状态(如PV创建成功/失败、绑定结果等事件)
- apiGroups: [""]
resources: ["events"] # 目标资源:事件(Events)
verbs: ["create", "update", "patch"] # 允许操作:创建、更新、修补事件
# 权限5:操作Services和Endpoints资源,用于多实例部署时的leader选举(避免多个供应器冲突)
- apiGroups: [""]
resources: ["services", "endpoints"] # 目标资源:服务(Service)、端点(Endpoints)
verbs: ["get", "create", "update", "patch"] # 允许操作:查询、创建、更新、修补(选举相关操作)
# 权限6:操作Deployments资源(扩展权限),用于管理供应器自身的部署实例(可选)
- apiGroups: ["extensions"] # 扩展API组(兼容旧版K8s的Deployments资源)
resources: ["deployments"] # 目标资源:部署(Deployment)
verbs: ["get", "list", "watch", "create", "delete", "update"] # 允许全量操作
# 权限7:操作Leases资源,兼容K8s 1.14+版本的新版leader选举机制,确保选举安全性
- apiGroups: ["coordination.k8s.io"] # 协调相关API组,提供租约(Leases)资源
resources: ["leases"] # 目标资源:租约(Leases)
verbs: ["get", "create", "update"] # 允许操作:查询、创建、更新租约
---
# ========================== 3. 集群角色绑定:关联服务账户与权限 ==========================
# 声明RBAC相关API版本,ClusterRoleBinding用于将集群角色权限绑定到服务账户
apiVersion: rbac.authorization.k8s.io/v1
# 定义资源类型为ClusterRoleBinding,实现"权限(ClusterRole)-身份(ServiceAccount)"的关联
kind: ClusterRoleBinding
metadata:
name: run-nfs-provisioner # 角色绑定名称,标识该关联关系
subjects:
# 权限授予对象:1中创建的nfs-provisioner服务账户
- kind: ServiceAccount
name: nfs-provisioner # 服务账户名称(必须与1中一致)
namespace: kube-system # 服务账户所属命名空间(必须与1中一致)
roleRef:
# 绑定的权限:2中创建的集群角色
kind: ClusterRole # 角色类型为ClusterRole(集群级权限)
name: nfs-provisioner-runner # 集群角色名称(必须与2中一致)
apiGroup: rbac.authorization.k8s.io # 角色所属API组(固定值)
---
# ========================== 4. 动态供应器部署:关联 NFS 服务器配置 ==========================
# 声明Kubernetes API版本,Deployment属于apps/v1版本(稳定版),用于管理Pod的创建和生命周期
apiVersion: apps/v1
# 定义资源类型为Deployment,部署NFS动态供应器的Pod实例
kind: Deployment
metadata:
name: nfs-client-provisioner # Deployment名称,标识该供应器部署
namespace: kube-system # 所属命名空间,与服务账户、角色绑定保持一致
spec:
replicas: 1 # 部署副本数为1(单实例部署,生产环境可根据高可用需求调整为2+)
selector:
matchLabels:
app: nfs-client-provisioner # 标签选择器,匹配Pod标签,确保Deployment管理目标Pod
strategy:
type: Recreate # 部署策略:重建式更新(删除旧Pod后创建新Pod,避免多个供应器实例冲突)
template:
metadata:
labels:
app: nfs-client-provisioner # Pod标签,与Deployment的selector一致,用于资源关联
spec:
serviceAccountName: nfs-provisioner # 关联1中创建的服务账户,获取API访问权限
containers:
- name: nfs-client-provisioner # 容器名称,在Pod内唯一
# NFS动态供应器镜像:国内阿里云镜像仓库(避免国外仓库拉取失败),版本v4.0.2(稳定版)
image: registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images/nfs-subdir-external-provisioner:v4.0.2
# 资源限制配置:限制容器的CPU和内存使用,避免资源过度占用
resources:
requests: # 容器启动时的最小资源请求(调度器依据此分配节点资源)
cpu: 100m # 最小CPU请求:100毫核(0.1核)
memory: 128Mi # 最小内存请求:128兆字节
limits: # 容器能使用的最大资源量(超出后会被K8s限制)
cpu: 500m # 最大CPU限制:500毫核(0.5核)
memory: 512Mi # 最大内存限制:512兆字节
# 存储卷挂载:将NFS共享目录挂载到容器内指定路径
volumeMounts:
- name: nfs-client-root # 卷名称,与下方volumes中定义的名称一致
mountPath: /persistentvolumes # 容器内挂载路径,供应器会在此目录下创建PVC对应的子目录
# 环境变量配置:传递NFS服务器信息和供应器标识
env:
- name: PROVISIONER_NAME # 供应器名称,必须与后续StorageClass的provisioner字段一致
value: k8s-sigs.io/nfs-subdir-external-provisioner # 标准供应器名称(社区规范,确保兼容性)
- name: NFS_SERVER # NFS服务器IP地址,供应器通过该IP访问NFS共享目录
value: 10.132.47.90 # 替换为你的实际NFS服务器IP(需确保K8s集群所有节点能访问)
- name: NFS_PATH # NFS服务器的共享目录路径
value: /data # 替换为你的实际NFS共享目录(需提前在NFS服务器创建并配置权限)
# 卷配置:定义容器挂载的NFS卷
volumes:
- name: nfs-client-root # 卷名称,与volumeMounts中定义的名称一致
nfs: # 卷类型为NFS,挂载外部NFS服务器的共享目录
server: 10.132.47.90 # NFS服务器IP(与上方env中的NFS_SERVER一致)
path: /data # NFS共享目录路径(与上方env中的NFS_PATH一致)
---
# ========================== 5. 存储类:动态供给核心配置 ==========================
# 声明存储相关API版本,StorageClass属于storage.k8s.io/v1组,用于定义动态存储供应规则
apiVersion: storage.k8s.io/v1
# 定义资源类型为StorageClass,K8s通过该资源触发动态存储供应
kind: StorageClass
metadata:
name: nfs-client # StorageClass名称,PVC创建时通过该名称关联此存储类
annotations:
# 标识该存储类是否为默认存储类("false"表示非默认,需在PVC中显式指定存储类名称)
storageclass.kubernetes.io/is-default-class: "false"
provisioner: k8s-sigs.io/nfs-subdir-external-provisioner # 关联的供应器名称,必须与Deployment的PROVISIONER_NAME一致
parameters:
archiveOnDelete: "true" # 删除PVC时是否归档数据:"true"表示归档(保留NFS目录下的数据,仅解除绑定),"false"表示删除数据
# NFS子目录命名规则:使用PVC所属命名空间和PVC名称拼接,便于区分不同PVC的数据目录(如elfk-es-data-es-0)
pathPattern: "${.PVC.namespace}-${.PVC.name}"
reclaimPolicy: Delete # PV回收策略:"Delete"表示PVC删除后自动删除对应的PV和NFS数据目录;"Retain"表示保留PV和数据(需手动清理)
allowVolumeExpansion: true # 是否允许PVC扩容:"true"表示支持(K8s 1.11+版本支持,需NFS服务器目录支持扩容)
kubectl apply -f nfs-provisioner-complete.yaml
6.验证
kubectl get sc
模型预下载
1. 确认/创建存储卷 (PVC)
确保 kube-ai 命名空间下已经存在 50Gi 的 卷。
kubectl create namespace kube-ai
# model-storage-pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: llm-model-pvc
namespace: kube-ai
spec:
accessModes:
- ReadWriteMany
storageClassName: nfs-client
resources:
requests:
storage: 100Gi #可以视模型大小决定,因为我下了三个模型,所以配置有点大
执行命令:kubectl apply -f model-storage-pvc.yaml
2.部署中转下载 Pod (model-downloader.yaml)
# model-downloader.yaml
apiVersion: v1
kind: Pod
metadata:
name: model-downloader
namespace: kube-ai
spec:
containers:
- name: loader
image: swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/library/python:3.10-slim
command:
- /bin/sh
- -c
- sleep 36000
volumeMounts:
- name: model-storage
mountPath: /mnt/models
volumes:
- name: model-storage
persistentVolumeClaim:
claimName: llm-model-pvc
执行kubectl apply -f model-downloader.yaml
3. 进入容器并执行下载
利用 modelscope 工具进行断点续传下载,确保模型完整性。
# 1. 进入下载 Pod
kubectl exec -it model-downloader -n kube-ai -- bash
# 2. 安装/更新下载工具 (容器内执行)
pip install modelscope -U
# 3. 开始下载模型至 PVC 路径(我下了三个)
modelscope download \
--model 'Qwen/Qwen3.5-9B' \
--local_dir /mnt/models/Qwen3.5-9B
modelscope download --model Qwen/Qwen3.6-27B-FP8 --local_dir /mnt/models/Qwen3.6-27B
modelscope download --model Qwen/Qwen3.5-27B-FP8 --local_dir /mnt/models/Qwen3.5-27B-FP8
4. 运维校验
下载完成后,不要急着关掉 Pod,先确认文件是否齐全且路径正确,这对 vLLM 启动至关重要。
ls -lh /mnt/models/Qwen3.6-27B
ls -lh /mnt/models/Qwen3.5-9B
ls -lh /mnt/models/Qwen3.5-27B-FP8
四、 部署vllm服务
先给节点打 label
kubectl label node k8s-master hardware-type=gpu
kubectl label node k8s-node1 hardware-type=gpu
kubectl label node k8s-node2 hardware-type=gpu
kubectl label node k8s-node3 hardware-type=gpu
kubectl label node k8s-node4 hardware-type=gpu
kubectl label node k8s-master gpu-type=t4
kubectl label node k8s-node1 gpu-type=t4
kubectl label node k8s-node2 gpu-type=t4
kubectl label node k8s-node3 gpu-type=a40
kubectl label node k8s-node4 gpu-type=a40
单节点启动千问3.6(不使用ray集群)
# k8s-vllm-qwen36.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: qwen36-vllm
namespace: kube-ai
spec:
replicas: 1
selector:
matchLabels:
app: qwen36-vllm
template:
metadata:
labels:
app: qwen36-vllm
spec: # 匹配的标签
nodeSelector:
hardware-type: gpu
gpu-type: a40
terminationGracePeriodSeconds: 60
containers:
- name: vllm
image: crpi-vdf183p7g8m4zpud.cn-hangzhou.personal.cr.aliyuncs.com/shy_my/vllm-openai:v0.22.0
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8000
name: serve
command:
- /bin/bash
- -c
args:
- |
vllm serve /mnt/models/Qwen3.6-27B \
--served-model-name qwen36 \
--speculative-config '{"method":"mtp","num_speculative_tokens":4}' \
--tensor-parallel-size 1 \
--gpu-memory-utilization 0.95 \
--max-model-len 131072 \
--max-num-seqs 8 \
--enable-prefix-caching \
--trust-remote-code \
--enable-auto-tool-choice \
--tool-call-parser qwen3_coder \
--host 0.0.0.0 \
--port 8000
readinessProbe:
httpGet:
path: /health
port: 8000
initialDelaySeconds: 240
periodSeconds: 240
failureThreshold: 3
livenessProbe:
httpGet:
path: /health
port: 8000
initialDelaySeconds: 300
periodSeconds: 240
failureThreshold: 3
resources:
requests:
cpu: "16"
memory: "58Gi"
nvidia.com/gpu: 1
limits:
cpu: "16"
memory: "58Gi"
nvidia.com/gpu: 1
volumeMounts:
- name: model-storage
mountPath: /mnt/models
- name: shm
mountPath: /dev/shm
volumes:
- name: model-storage
persistentVolumeClaim:
claimName: llm-model-pvc
- name: shm
emptyDir:
medium: Memory
sizeLimit: 16Gi
---
# Service
apiVersion: v1
kind: Service
metadata:
name: vllm-service
namespace: kube-ai
labels:
app: vllm
spec:
type: NodePort
selector:
app: qwen36-vllm # 匹配Deployment的labels
ports:
- name: http
protocol: TCP
port: 8000
targetPort: 8000
nodePort: 30080
启动之后测试
VLLM36_POD=$(kubectl get pods -n kube-ai -l app=qwen36-vllm -o jsonpath='{.items[0].metadata.name}')
kubectl exec -it -n kube-ai $VLLM36_POD -- curl http://127.0.0.1:8000/v1/models
kubectl exec -it -n kube-ai $VLLM36_POD -- \
curl http://127.0.0.1:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model":"qwen35",
"messages":[
{
"role":"user",
"content":"请你用中文做一个自我介绍"
}
],
"temperature":0.7
}'
日志查看
VLLM36_POD=$(kubectl get pods -n kube-ai -l app=qwen36-vllm -o jsonpath='{.items[0].metadata.name}')
kubectl logs -f -n kube-ai $VLLM36_POD
单节点启动千问3.5(不使用ray集群)
# vllm-qwen35.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: qwen35-vllm
namespace: kube-ai
spec:
replicas: 1
selector:
matchLabels:
app: qwen35-vllm
template:
metadata:
labels:
app: qwen35-vllm
spec:
nodeSelector:
hardware-type: gpu
gpu-type: a40
terminationGracePeriodSeconds: 60
containers:
- name: vllm
image: crpi-vdf183p7g8m4zpud.cn-hangzhou.personal.cr.aliyuncs.com/shy_my/vllm-openai:v0.22.0
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8000
name: serve
command:
- /bin/bash
- -c
args:
- |
vllm serve /mnt/models/Qwen3.5-9B \
--served-model-name qwen35 \
--speculative-config '{"method":"mtp","num_speculative_tokens":4}' \
--tensor-parallel-size 1 \
--gpu-memory-utilization 0.95 \
--max-model-len 262144 \
--max-num-seqs 16 \
--enable-prefix-caching \
--trust-remote-code \
--enable-auto-tool-choice \
--tool-call-parser qwen3_coder \
--host 0.0.0.0 \
--port 8000
readinessProbe:
httpGet:
path: /health
port: 8000
initialDelaySeconds: 200
periodSeconds: 300
failureThreshold: 3
livenessProbe:
httpGet:
path: /health
port: 8000
initialDelaySeconds: 300
periodSeconds: 300
failureThreshold: 3
resources:
requests:
cpu: "16"
memory: "58Gi"
nvidia.com/gpu: 1
limits:
cpu: "16"
memory: "58Gi"
nvidia.com/gpu: 1
volumeMounts:
- name: model-storage
mountPath: /mnt/models
- name: shm
mountPath: /dev/shm
volumes:
- name: model-storage
persistentVolumeClaim:
claimName: llm-model-pvc
- name: shm
emptyDir:
medium: Memory
sizeLimit: 16Gi
---
# Service
apiVersion: v1
kind: Service
metadata:
name: vllm-service-qwen35
namespace: kube-ai
labels:
app: vllm
spec:
type: NodePort
selector:
app: qwen35-vllm # 匹配Deployment的labels
ports:
- name: http
protocol: TCP
port: 8000
targetPort: 8000
nodePort: 30081
启动之后测试
VLLM35_POD=$(kubectl get pods -n kube-ai -l app=qwen35-vllm -o jsonpath='{.items[0].metadata.name}')
kubectl exec -it -n kube-ai $VLLM35_POD -- curl http://127.0.0.1:8000/v1/models
kubectl exec -it -n kube-ai $VLLM35_POD -- \
curl http://127.0.0.1:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model":"qwen35",
"messages":[
{
"role":"user",
"content":"请你用中文做一个自我介绍"
}
],
"temperature":0.7
}'
日志查看
VLLM35_POD=$(kubectl get pods -n kube-ai -l app=qwen35-vllm -o jsonpath='{.items[0].metadata.name}')
kubectl logs -f -n kube-ai $VLLM35_POD
vllm启动调用模型命令参数
| 参数 | 类型 | 作用 | 常用值 | 说明 |
|---|---|---|---|---|
model |
string | 指定模型名称 | "qwen36" |
对应 /v1/models 里的模型 ID |
messages |
array | 对话内容 | [{"role":"user","content":"你好"}] |
ChatGPT 标准格式 |
max_tokens |
int | 最大生成 token 数 | 256~4096 |
控制输出长度 |
temperature |
float | 随机性/创造性 | 0~1.2 |
越高越发散 |
top_p |
float | nucleus sampling | 0.7~1.0 |
控制候选词概率范围 |
top_k |
int | 候选 token 数量 | 20~100 |
越小越保守 |
stream |
bool | 是否流式输出 | true/false |
类似 ChatGPT 打字机效果 |
repetition_penalty |
float | 防止重复 | 1.0~1.2 |
Qwen 推荐 1.05 |
frequency_penalty |
float | 降低重复频率 | 0~2 |
OpenAI 风格参数 |
presence_penalty |
float | 鼓励新话题 | 0~2 |
提高内容多样性 |
stop |
array/string | 停止词 | ["</s>"] |
遇到后停止生成 |
seed |
int | 固定随机种子 | 1234 |
结果可复现 |
n |
int | 一次生成多个结果 | 1~n |
类似多候选答案 |
logprobs |
bool/int | 返回 token 概率 | true |
调试用 |
max_completion_tokens |
int | completion token 上限 | 1024 |
新版 OpenAI 参数 |
response_format |
object | JSON 输出格式 | {"type":"json_object"} |
强制 JSON 输出 |
tools |
array | Tool Calling | function schema | Agent 场景 |
tool_choice |
string/object | 工具选择策略 | "auto" |
自动调用工具 |
chat_template_kwargs.enable_thinking |
bool | 是否开启思维链 | true/false |
Qwen3 专用参数 |
chat_template_kwargs.enable_thinking=false |
bool | 关闭 thinking | false |
推荐生产环境使用 |
chat_template_kwargs.enable_thinking=true |
bool | 开启 reasoning | true |
数学/代码更强 |
truncate_prompt_tokens |
int | 截断超长输入 | 4096 |
避免 context 爆掉 |
skip_special_tokens |
bool | 跳过特殊 token | true |
通常默认开启 |
ignore_eos |
bool | 忽略结束 token | false |
很少用 |
min_tokens |
int | 最少生成 token | 0~100 |
强制最小输出长度 |
KubeRay 分布式推理环境部署
1. 核心思路
在 Kubernetes 上运行分布式 LLM(如 Qwen3.5-9B),底层的稳定性取决于三点:
1控制面:Kuberay Operator 的正确安装。
2网络面:消除容器网卡命名差异,打通 NCCL/Gloo 通信隧道。
3资源面:解决模型加载瞬时内存(RAM)激增导致的 137 错误。
2. 基础环境配置 (YAML 准备)
统一环境变量配置 (ray-common-config.yaml)
注意: 此配置通过 ConfigMap 强制所有节点使用 eth0 网卡,并针对 T4 显卡禁用了不支持的硬件特性,防止通信死锁。
# ray-common-config.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: ray-common-config
namespace: kube-ai
data:
NCCL_DEBUG: "INFO"
NCCL_SOCKET_IFNAME: "eth0" # 网卡名 ip a 查看
GLOO_SOCKET_IFNAME: "eth0"
TP_SOCKET_IFNAME: "eth0"
# --- 分布式调优 ---
NCCL_IB_DISABLE: "1" # 无 IB 架构,必须禁用
NCCL_NET_GDR_LEVEL: "0" # 不支持 GPU Direct RDMA
# NCCL_P2P_DISABLE: "1" # 跨节点通信建议禁用 P2P 以防卡死,但是:现在每节点1GPU,实际上P2P 根本不存在
# --- 显存与内存优化 ---
VLLM_SOURCE_THREADS_PER_WORKER: "1" # 限制加载线程,防止加载时内存爆表
PYTORCH_CUDA_ALLOC_CONF: "expandable_segments:True" # 解决显存碎片,vLLM 场景尤其严重,因为continuous batching、KV cache、动态token会频繁分配显存,这个参数允许动态扩展 memory segment,减少CUDA out of memory
CUDA_DEVICE_ORDER: "PCI_BUS_ID" # 异构 GPU 场景下,固定 GPU 编号顺序
NCCL_ASYNC_ERROR_HANDLING: "1" # NCCL 异步错误检测,避免通信假死
NCCL_TIMEOUT: "1800" #vLLM 第一次加载大模型慢,尤其:大模型、多机、NFS、shard很多,默认 NCCL timeout大约600秒,容易某个 rank 加载慢,然后NCCL误判超时
TORCH_NCCL_BLOCKING_WAIT: "1" # 让NCCL 错误同步抛出,否则错误可能延迟几十秒才出现。
3. 下载helm
1:下载适配版本的 Helm 二进制包
# 下载 Helm 3.8.2 二进制包(amd64 架构,适配大多数服务器)
wget https://get.helm.sh/helm-v3.18.0-linux-amd64.tar.gz
# 解压包(解压后会得到 linux-amd64 目录)
tar -zxvf helm-v3.18.0-linux-amd64.tar.gz
# 将 helm 二进制文件移动到系统 PATH 目录(全局可用)
mv linux-amd64/helm /usr/local/bin/helm
# 验证二进制文件可执行
chmod +x /usr/local/bin/helm
2:验证 Helm 安装及版本
# 查看 Helm 版本,确认是 3.8.2
helm version
# 正常输出示例:
# version.BuildInfo{Version:"v3.8.2", GitCommit:"6e3701edea09e5d55a8ca2aae03a68917630e91b", GitTreeState:"clean", GoVersion:"go1.17.5"}
3:配置 Helm 仓库
# 添加官方稳定仓库(阿里云镜像,访问更快)
helm repo add stable https://kubernetes.oss-cn-hangzhou.aliyuncs.com/charts
helm repo add kuberay https://ray-project.github.io/kuberay-helm/
# 更新仓库索引
helm repo update
# 验证仓库配置
helm repo list
4. 安装 KubeRay Operator
# 添加仓库
helm repo add kuberay https://ray-project.github.io/kuberay-helm/
helm repo update
# 安装控制器
helm install kuberay-operator kuberay/kuberay-operator \
--version 1.6.1 \
--namespace kube-ai
无法添加这个仓库的话:
# 下载源码包
wget https://ghfast.top/https://github.com/ray-project/kuberay/archive/refs/tags/v1.6.1.tar.gz
# 解压
tar -zxvf v1.6.1.tar.gz
# 进入 chart 目录
cd kuberay-1.6.1/helm-chart/kuberay-operator
# 安装
helm install kuberay-operator . \
--namespace kube-ai
验证:
kubectl get pod -n kube-ai
kubectl get crd | grep ray
#应该看到
rayclusters.ray.io
rayjobs.ray.io
rayservices.ray.io
应用基础配置
将刚才准备好的 ConfigMap 应用到集群中:
kubectl apply -f ray-common-config.yaml
5. 创建ray-cluster集群并且启动大模型
定义资源文件raycluster-a40.yaml
# A40*2配置
apiVersion: ray.io/v1
kind: RayCluster
metadata:
name: qwen36-fp8-cluster
namespace: kube-ai
spec:
rayVersion: "2.50.0"
########################################################
# Head
########################################################
headGroupSpec:
serviceType: ClusterIP
rayStartParams:
dashboard-host: "0.0.0.0"
num-gpus: "1"
template:
metadata:
labels:
ray.io/node-type: head
app: qwen36-vllm
spec:
hostNetwork: true
dnsPolicy: ClusterFirstWithHostNet
nodeSelector:
kubernetes.io/hostname: k8s-node3
terminationGracePeriodSeconds: 60
containers:
- name: ray-head
image: crpi-vdf183p7g8m4zpud.cn-hangzhou.personal.cr.aliyuncs.com/shy_my/vllm-openai:v0.19.0-ray
imagePullPolicy: IfNotPresent
ports:
- containerPort: 6379
name: gcs
- containerPort: 8265
name: dashboard
- containerPort: 8000
name: serve
- containerPort: 10001
name: client
env:
- name: VLLM_HOST_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
- name: NCCL_SOCKET_IFNAME
value: eth0
- name: NCCL_DEBUG
value: WARN
- name: CUDA_DEVICE_ORDER
value: PCI_BUS_ID
- name: VLLM_USE_V1
value: "1"
- name: VLLM_WORKER_MULTIPROC_METHOD
value: spawn
- name: PYTORCH_CUDA_ALLOC_CONF
value: expandable_segments:True
- name: VLLM_LOGGING_LEVEL
value: INFO
envFrom:
- configMapRef:
name: ray-common-config
command:
- /bin/bash
- -c
args:
- |
set -ex
ray stop --force || true
export MY_POD_IP=$(hostname -i)
echo "Starting Ray Head..."
ray start \
--head \
--port=6379 \
--dashboard-host=0.0.0.0 \
--node-ip-address=$MY_POD_IP \
--num-gpus=1 \
--block &
echo "Waiting worker join..."
until ray status 2>/dev/null | grep "0.0/2.0 GPU"; do
echo "Current cluster:"
ray status || true
sleep 5
done
echo "Ray cluster ready."
echo "Starting vLLM..."
vllm serve /mnt/models/Qwen3.6-27B \
--served-model-name qwen36 \
--speculative-config '{"method":"mtp","num_speculative_tokens":4}' \
--tensor-parallel-size 2 \
--distributed-executor-backend ray \
--gpu-memory-utilization 0.95 \
--max-model-len auto \
--max-num-seqs 16 \
--enable-prefix-caching \
--trust-remote-code \
--enable-auto-tool-choice \
--tool-call-parser qwen3_coder \
--host 0.0.0.0 \
--port 8000
readinessProbe:
tcpSocket:
port: 6379
initialDelaySeconds: 15
periodSeconds: 10
failureThreshold: 10
livenessProbe:
tcpSocket:
port: 6379
initialDelaySeconds: 30
periodSeconds: 15
failureThreshold: 10
startupProbe:
tcpSocket:
port: 6379
failureThreshold: 60
periodSeconds: 10
resources:
requests:
cpu: "16"
memory: "58Gi"
nvidia.com/gpu: 1
limits:
cpu: "16"
memory: "58Gi"
nvidia.com/gpu: 1
volumeMounts:
- name: model-storage
mountPath: /mnt/models
- name: shm
mountPath: /dev/shm
volumes:
- name: model-storage
persistentVolumeClaim:
claimName: llm-model-pvc
- name: shm
emptyDir:
medium: Memory
sizeLimit: 16Gi
########################################################
# Worker
########################################################
workerGroupSpecs:
- groupName: a40-workers
replicas: 1
minReplicas: 1
maxReplicas: 1
rayStartParams:
num-gpus: "1"
template:
metadata:
labels:
ray.io/node-type: worker
app: qwen36-vllm
spec:
hostNetwork: true
dnsPolicy: ClusterFirstWithHostNet
nodeSelector:
kubernetes.io/hostname: k8s-node4
terminationGracePeriodSeconds: 60
containers:
- name: ray-worker
image: crpi-vdf183p7g8m4zpud.cn-hangzhou.personal.cr.aliyuncs.com/shy_my/vllm-openai:v0.19.0-ray
imagePullPolicy: IfNotPresent
env:
- name: VLLM_HOST_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
- name: NCCL_SOCKET_IFNAME
value: eth0
- name: NCCL_DEBUG
value: WARN
- name: CUDA_DEVICE_ORDER
value: PCI_BUS_ID
- name: VLLM_WORKER_MULTIPROC_METHOD
value: spawn
envFrom:
- configMapRef:
name: ray-common-config
command:
- /bin/bash
- -c
args:
- |
set -ex
ray stop --force || true
export MY_POD_IP=$(hostname -i)
echo "Starting Ray Worker..."
ray start \
--address=$RAY_IP:6379 \
--node-ip-address=$MY_POD_IP \
--num-gpus=1 \
--block
readinessProbe:
exec:
command:
- /bin/bash
- -c
- ps aux | grep raylet | grep -v grep
initialDelaySeconds: 15
periodSeconds: 10
failureThreshold: 10
livenessProbe:
exec:
command:
- /bin/bash
- -c
- ps aux | grep raylet | grep -v grep
initialDelaySeconds: 30
periodSeconds: 15
failureThreshold: 10
startupProbe:
exec:
command:
- /bin/bash
- -c
- ps aux | grep raylet | grep -v grep
failureThreshold: 60
periodSeconds: 10
resources:
requests:
cpu: "16"
memory: "58Gi"
nvidia.com/gpu: 1
limits:
cpu: "16"
memory: "58Gi"
nvidia.com/gpu: 1
volumeMounts:
- name: model-storage
mountPath: /mnt/models
- name: shm
mountPath: /dev/shm
volumes:
- name: model-storage
persistentVolumeClaim:
claimName: llm-model-pvc
- name: shm
emptyDir:
medium: Memory
sizeLimit: 16Gi
---
apiVersion: v1
kind: Service
metadata:
name: vllm-service
namespace: kube-ai
labels:
app: vllm
spec:
type: NodePort
selector:
ray.io/node-type: head
ports:
- name: http
protocol: TCP
port: 8000
targetPort: 8000
nodePort: 30080
# 查看 Head 日志
HEAD_POD=$(kubectl get pods -n kube-ai -l ray.io/node-type=head -o jsonpath='{.items[0].metadata.name}')
kubectl logs -f -n kube-ai $HEAD_POD
kubectl get svc -n kube-ai
curl http://10.132.47.90:30080/v1/models
接入聊天界面(open webUI)
mkdir -p /opt/openwebui/OllamaWeb
chmod -R 777 /opt/openwebui/OllamaWeb # 赋予权限
docker run -d \
-p 3000:8080 \
--add-host=host.docker.internal:host-gateway \
-v /opt/openwebui/OllamaWeb:/app/backend/data \
--name open-webui \
--restart always \
crpi-vdf183p7g8m4zpud.cn-hangzhou.personal.cr.aliyuncs.com/shy_my/open-webui:main
浏览器访问http://IP:3000
第一次进入会让你注册账号(本地随便注册即可,自己记住就行)
进入之后—点击左下角的头像—管理员面板—设置—外部链接—管理 OpenAI 接口连接
这个管理 OpenAI 接口连接右边有个+,点击之后根据要求进行配置(外部链接、URL:http://10.132.47.90:30080/v1、密钥、模型等等)
配置好了之后再去新对话就有你的模型了
对接: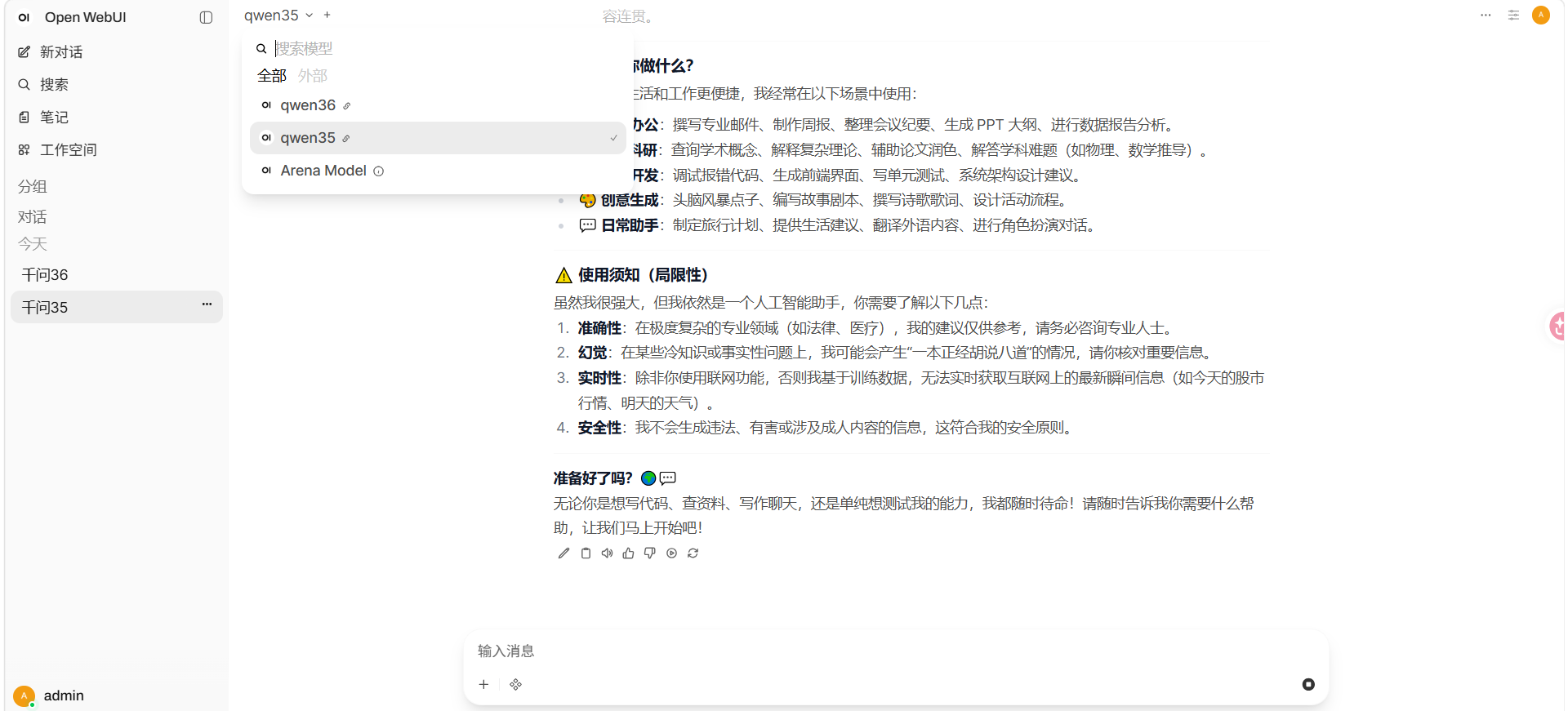

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐



 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)