Linux系统编程:(十二)孤儿进程&&进程优先级&&切换调度
1. 孤儿进程
系统初始运行 0 号进程,设备开机后,系统管理工作交由 1 号进程负责。当父子进程运行时,倘若父进程率先退出,残留的子进程会被 1 号进程接管,该类子进程即为孤儿进程。现阶段只需将 1 号进程简单理解为操作系统即可。
核心规则:父进程终止而子进程持续运行时,子进程会被 1 号进程收养。
为了模拟出孤儿进程,创建一个.c文件,然后使用vim编辑器编辑如下内容:
1 #include<stdio.h>
2 #include<unistd.h>
3 #include<sys/types.h>
4 int main()
5 {
6 pid_t id = fork();
7 if(id == 0)
8 {
9 //child
10 while(1)
11 {
12 printf("我是一个子进程,我的pid为:%d,ppid为 %d\n",getpid(),getppid());
13 sleep(1);
14 }
15 }
16 else
17 {
18 //father
19 int cnt = 5;
20 while(cnt)
21 {
22 printf("我是父进程,我的pid为:%d,ppid为: %d\n",getpid(),getppid());
23 cnt--;
24 sleep(1);
25 }
26 }
27 return 0;
28 }
然后对该文件进行编译运行,会发现父进程运行了5次之后便会退出,而子进程则是无限运行。当父进程退出后,子进程便成为了孤儿进程。
重新打开一个命令行窗口对这两个进程的运行进行监视,可以发现,当父子进程同时运行时,输出的进程信息如下:

当父进程运行结束而子进程仍然在运行时,输出的进程信息如下:

可以观察到此时的父进程为1号进程,说明原来的子进程被1号进程领养了!
为什么会被领养???
子进程终止后会转为僵尸进程,需要由父进程负责回收其进程信息与占用资源。若父进程提前退出,子进程将失去管理者,资源无法正常释放,进而引发内存泄漏。因此系统会将该子进程交由 1 号进程接管,完成资源回收。
补充知识点 1:
为何父进程不会成为孤儿进程??
每个终端下的普通父进程,其父进程默认是bash终端进程。当该父进程正常退出后,会由上级bash进程完成资源回收,因此它不会转变为孤儿进程。
补充知识点 2:
孤儿进程无法通过 Ctrl+C 终止的原因 在命令行中产生的孤儿进程,会被系统1 号进程接管,转为后台运行状态。此时按下Ctrl+C无法终止它,想要结束进程,只能使用 kill 命令手动关闭。
kill -9 [pid]2. 进程优先级
2.1 基础概念
进程优先级就是进程得到cpu资源的先后顺序。
为什么存在进程优先级??
因为目标资源稀缺,导致要通过优先级确认谁先谁后的问题!
优先级 VS 权限
优先级:能得到资源,考虑先后的问题;
权限:是否能够得到资源的问题。
优先级也是一个整数,属于task_struct中的一个变量。对应的值越低,优先级越高;反之,优先级越低。
基于时间片的分时操作系统,考虑公平性。优先级可能会发生变化,但是变化幅度不能太大。
2.2 查看系统进程
通过以下指令可以访问Linux系统的进程:
ps -al输出结果一般是如下结果:

查看用户的UID指令如下:
ls -ln系统怎么知道我访问文件的时候,是拥有者、所属者还是other?---通过对比进程的UID和创建文件的UID来进行判断。所以在Linux系统中,访问任何资源,都是进程访问,进程就代表用户。
从上面的输出结果中还可以看到有PRI和NI:
PRI:进程的优先级。默认值:80
NI:进程优先级的修正数据,又称nice值。
进程真实的优先级:PRI(使用默认值80进行运算)+NI
2.3 更改进程优先级
如果想要更改一个进程的优先级:
方法1
第一步输入top指令:
top便会输出如下结果:
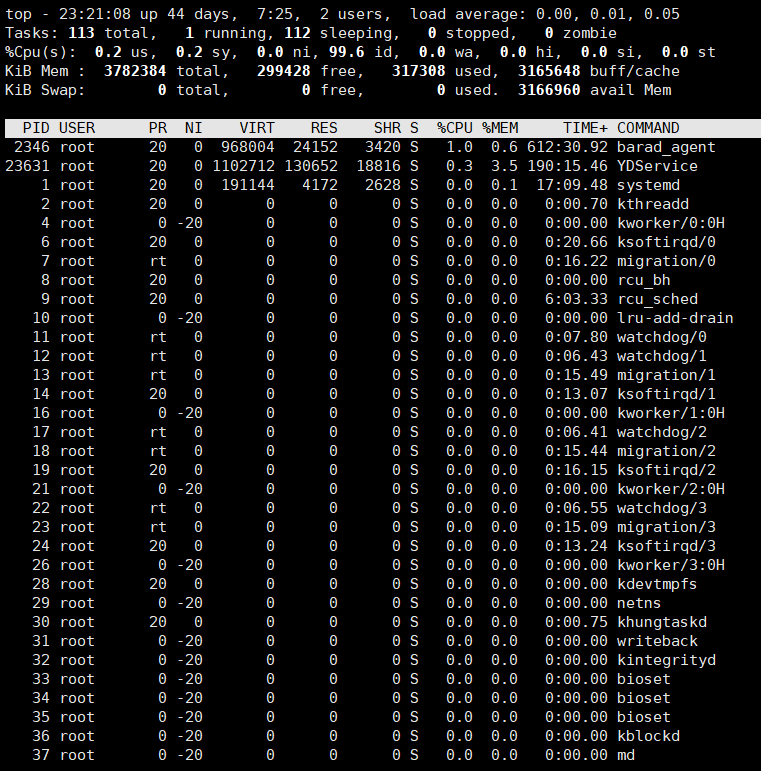
然后输入:
r命令行便会自动跳出如下结果,提示你输入想要修改的进程对应的pid:
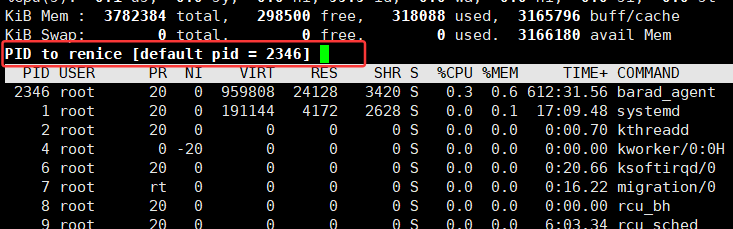
接下来输入想要更改的进程的对应pid,再按下enter,随后该行会提示你输入想要的nice值,这里我输入10:

这样就将nice值(NI)设置成了10,再查看此进程对应的PRI,可以观察到已经从默认的80变为了90:

方法2
在 Linux 中,nice 和 renice 用来调整进程的调度优先级(niceness):
1、nice —— 启动程序时设置优先级
nice [选项] 命令 [参数...]常用:
nice -n 5 ./myapp # 以 nice=5 启动(较低优先级)
nice -n -10 sudo ./myapp # 以 nice=-10 启动(需 root)若不指定 -n,默认 nice=10。
2、renice —— 修改已运行进程的优先级
renice -n <优先级> -p <PID>示例:
renice -n 10 -p 1234 # 将 PID 1234 的 nice 改为 10
renice -n -5 -p 5678 # 提高优先级(需 root)也可按用户或组:
renice -n 15 -u username # 调整某用户所有进程从上面演示的示例可以发现,只有root用户可以执行增大优先级操作,而普通用户只能执行减小优先级操作。
2.4 Linux系统调整优先级的系统调用
Linux 中进程“优先级”对用户态暴露为 nice 值(-20 ~ 19),底层由 CFS / 实时调度器处理,用户态通过两个主要系统调用来调整:
|
系统调用 |
作用 |
|---|---|
|
|
设置一个或多个进程的 nice 值(对应 |
|
|
获取进程的 nice 值 |
|
|
已废弃/简化接口,内部通常转为 |
⚠️ 真正“调整优先级”的标准接口是
setpriority(),不是直接用sched_setscheduler(那是改调度策略/RT 优先级)。
函数getpriority / setpriority原型
#include <sys/time.h>
#include <sys/resource.h>
int getpriority(int which, id_t who);
int setpriority(int which, id_t who, int prio);参数说明
which 指定作用对象:
-
PRIO_PROCESS→ 按 PID -
PRIO_PGRP→ 按进程组 -
PRIO_USER→ 按 UID
who:
-
0表示当前进程 / 当前进程组 / 当前用户
prio:
-
nice 值,-20(最高)~ 19(最低)
-
非 root 只能 调低优先级(增大 nice)
使用示例:renice 效果
#include <sys/resource.h>
#include <unistd.h>
int main(void) {
/* 将当前进程 nice 设为 10 */
setpriority(PRIO_PROCESS, 0, 10);
return 0;
}等价 shell 行为:
renice -n 10 -p [PID]获取 nice 值
int nice_val = getpriority(PRIO_PROCESS, 0);
/* 注意:成功时返回 nice 值,失败返回 -1(需区分 errno)*/⚠️ getpriority()合法返回值可以是 -1,因此判断错误必须用 errno:
errno = 0;
nice_val = getpriority(PRIO_PROCESS, 0);
if (nice_val == -1 && errno != 0) {
perror("getpriority");
}2.5 优先级的极值问题
在 Linux 中,nice 和 renice 调整进程的调度优先级范围通常是 -20 ~ 19:
-
-20:最高优先级(需 root)
-
19:最低优先级
-
默认启动进程一般为 0
所以进程的优先级范围,即PRI范围为:[60,99]----总共40个优先级!
如果优先级设立不合理,会导致优先级低的进程长时间得不到CPU资源,进而导致:进程饥饿
3.前提知识补充
3.1 补充概念:竞争、独立、并行、并发
- 竞争性:系统进程数目众多,而CPU资源只有少量,甚至1个,所以进程之间是具有竞争属性的。为了高效完成任务,更合理竞争相关资源,便具有了优先级
- 独立性:多进程运行,需要独享各种资源,多进程运行期间互不干扰
- 并行:多个进程在多个CPU下分别,同时进行运行,这称之为并行
- 并发:多个进程在一个CPU下采用进程切换的方式,在一段时间之内,让多个进程都得以推进,称之为并发
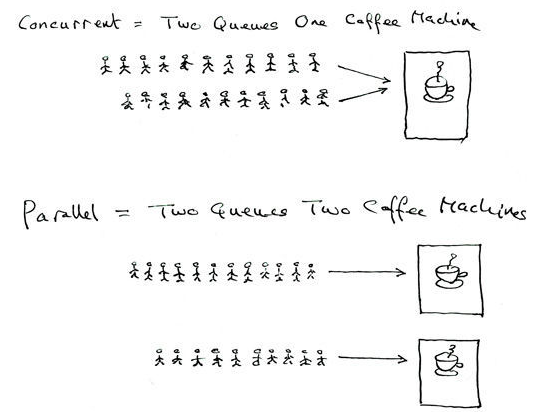
3.2 死循环进程如何运行?
回答这个问题之前,先思考这个问题:
一旦一个进程占有了CPU,会把自己的代码跑完吗???
答案:不会。现代操作系统中,进程被调度上 CPU 后并不是一直跑到自己的代码结束,而是按时间片(time slice)分配 CPU 使用权;通常一个进程只运行极短时间(毫秒级)就会被时钟中断打断,保存上下文并让出 CPU 给下一个就绪进程,即便它的代码还没执行完。只有当进程阻塞(如等待 I/O)或时间片用完发生调度切换时才会让出 CPU,后续再通过调度恢复继续执行,直到最终跑完整段代码。
基于上面这个问题的答案,我们可以回答标题中的问题了:
死循环进程不会卡死系统,也不会一直占用 CPU,因为操作系统通过时间片轮转机制强制每个进程只能运行一小段时间(通常几毫秒到几十毫秒),时间一到就会触发时钟中断,暂停当前进程,保存其上下文,然后切换到下一个就绪进程。即使某个进程是死循环,它也会在每次获得时间片后短暂运行,随后被调度器换出,让其他进程轮流获得 CPU 执行机会。正是这种基于时间片的抢占式调度,保证了即使存在死循环进程,整个系统依然能够正常响应、多任务并发推进,而不会被单个进程独占 CPU 导致"卡死"。
3.3 聊聊CPU、寄存器
CPU 内部包含一组容量极小但速度极快的存储单元,称为寄存器。它们是 CPU 直接读写数据的唯一场所,也是程序运行时最底层的“工作台”。不同类型的寄存器承担着截然不同的职责,共同支撑起指令的执行、数据的暂存、内存的访问以及进程的切换。
|
寄存器类别 |
代表寄存器(x86-64) |
核心职责 |
|---|---|---|
|
通用寄存器 |
RAX、RBX、RCX、RDX、RSI、RDI、R8~R15 |
存放临时数据、计算结果、地址 |
|
指令指针寄存器 |
RIP |
指向下一条要执行的指令地址 |
|
栈指针寄存器 |
RSP |
指向当前栈的栈顶 |
|
基址指针寄存器 |
RBP |
标识当前函数栈帧的基地址 |
|
标志寄存器 |
RFLAGS / EFLAGS |
记录运算结果的状态(零、进位、溢出等) |
|
段寄存器 |
CS、DS、SS、ES、FS、GS |
分段内存模型的段选择子(现代OS中主要用于TLS) |
|
控制寄存器 |
CR0、CR2、CR3、CR4 |
控制CPU工作模式、分页、缺页异常地址、页表基址 |
4. 进程切换
CPU 上下文切换,本质上就是任务之间的切换,也就是 CPU 寄存器状态的切换。当多任务内核决定将当前任务切换出去时,它会先把当前任务在 CPU 寄存器中的所有现场信息保存到该任务自己的栈中;接着,再将下一个要运行的任务之前保存的现场信息从它的栈中恢复到 CPU 寄存器中。这样一来,新任务就能从上一次被中断的地方继续执行。整个过程就是先保存旧任务的现场,再恢复新任务的现场,这就是所谓的上下文切换(context switch)。
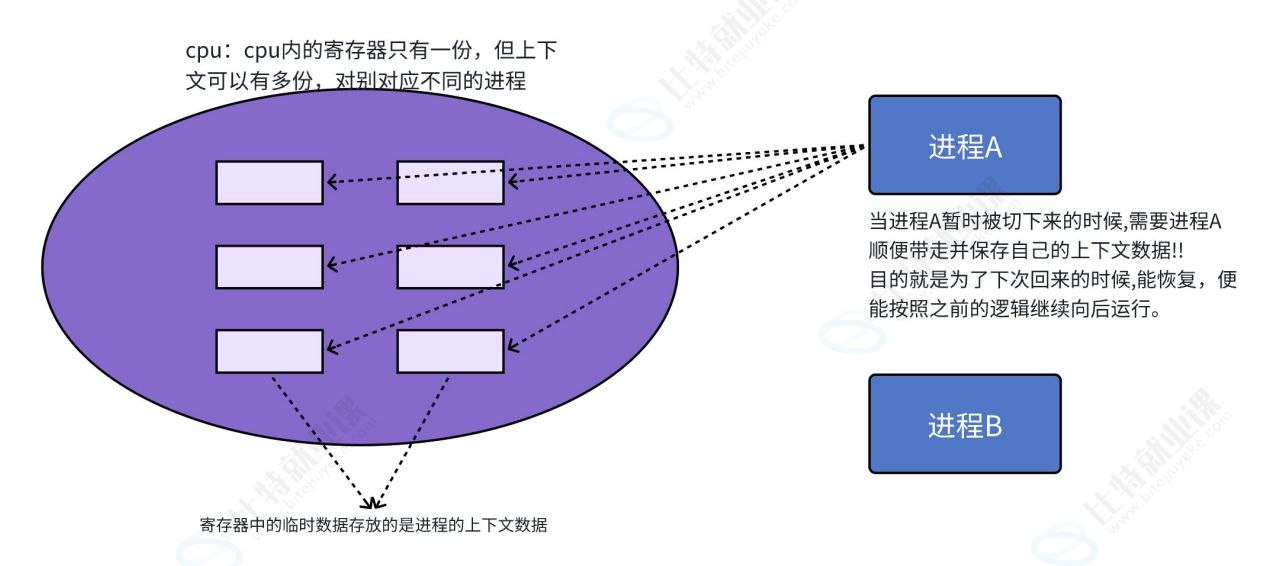
问题1
所以当前进程要把自己的进程硬件上下文数据保存起来,是保存到哪里了呢??
答案:当前进程需要保存的硬件上下文数据,最终就存放在该进程的 task_struct中。在 task_struct内部专门嵌套了一个名为 TSS (任务状态段)的结构体,用来承载并保存这些关键的上下文数据,为后续的进程恢复与调度提供支持。
参考一下Linux内核0.11代码:

问题2
如何区分全新的进程和已经调度过的进程??
答案:在 tss_struct中有一个变量 isrunning(或其他类似名称的标志位):如果该值为 0,表示该进程从未被调度过,是一个全新的进程,调度器会将其当作首次运行来处理;如果该值为 1,则表示该进程已经被调度过,之前保存过完整的硬件上下文,调度器可以直接恢复其寄存器现场继续执行。

5. Linux真实调度算法
下面这张图片展示的是一个运行队列:(一个CPU有一个运行队列)
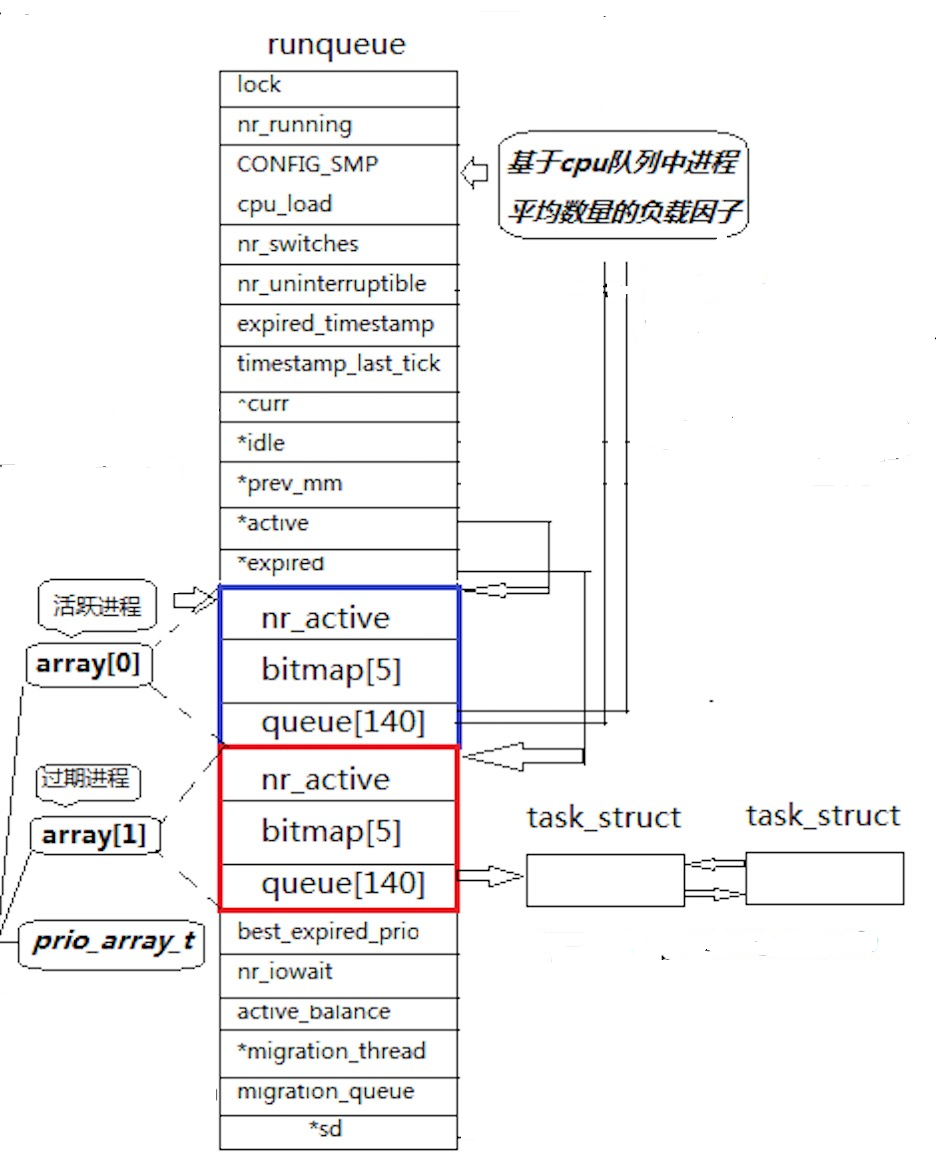
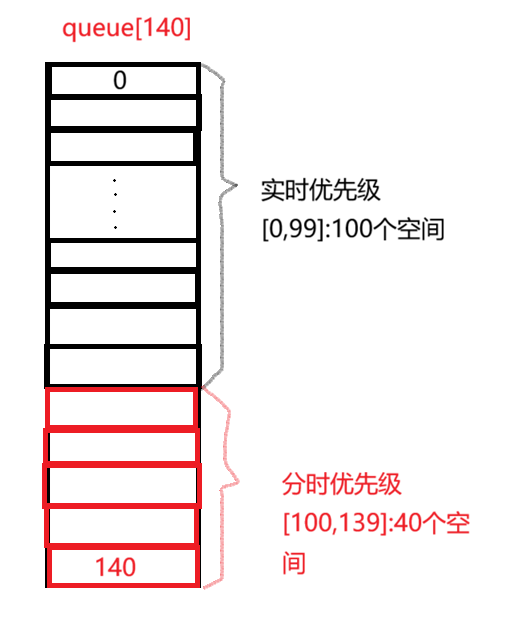
5.1 queue[140]数组
从图中可以看出,runqueue(即 rq结构体)内部包含一个名为 queue[140]的成员。这是一个指针数组,其完整定义为 struct task_struct *queue[140],数组中的每一个元素都是一个指向 task_struct的指针,分别对应 140 个不同优先级(从 0 到 139)的运行队列,用于按优先级链接和管理等待调度的进程。
在这个包含 140 个物理存储空间的数组中,下标 [0, 99] 共 100 个位置用于存放实时优先级,下标 [100, 139] 共 40 个位置用于存放分时(普通)优先级。这也就验证了为什么分时优先级的数字范围是 [60, 99],总共 40 个优先级。如果需要将一个分时优先级对应的数字映射到数组中的下标位置,可以使用公式:下标 = (x - 60) + 100,其中 x的取值范围为 [60, 99]。
为什么会有实时优先级??
普通的 Linux 进程(SCHED_OTHER / SCHED_NORMAL)采用完全公平调度算法(CFS),每个进程按照 nice 值分配 CPU 时间比例,但无法保证在指定的时间内必须得到 CPU。然而在某些场景下,比如工业控制、自动驾驶、音频处理、无人机飞控,系统必须在严格的时间限制内完成某项任务——例如传感器数据采集必须在 1 毫秒内得到响应,否则会导致控制失效或数据丢失。普通调度策略无法满足这种“截止时间”要求,因为一个高 nice 值的后台进程可能暂时抢占了 CPU,导致关键任务被延迟。为此,Linux 引入了实时优先级机制,通过 SCHED_FIFO和 SCHED_RR两种实时调度策略,让实时进程拥有比任何普通进程都更高的调度优先级:只要一个实时进程处于就绪状态,它就会立即抢占所有普通进程的 CPU,直到它主动让出或时间片用完。实时优先级的取值范围是 0~99,数值越大优先级越高,并且实时进程之间也遵循严格的优先级抢占规则。简单来说,实时优先级的存在,是为了解决“普通调度只关心公平,不关心时效”这一根本矛盾,确保对时间敏感的关键任务能够在规定时间内得到 CPU 资源。
总结
所以在真正的进程调度中(只考虑分时优先级),调度器会先在
queue数组中根据进程的优先级找到对应的链表,如果链表中有多个相同优先级的进程,则按照 FIFO(先进先出)的规则依次取出执行。但每个进程并不能一次性运行完所有代码,而是只能运行一个固定长度的时间片,时间片用完后,该进程被放回链表尾部,调度器再从链表头部取出下一个进程继续执行。如此循环往复,直到所有进程执行完毕。简单理解:
- queue[140]: 一个元素就是一个进程队列,相同优先级的进程按照FIFO规则进行排队调度,所以,数组下标就是优先级!
- 从该结构中,选择一个最合适的进程,过程是怎么的呢?
从0下表开始遍历queue[140]
找到第一个非空队列,该队列必定为优先级最高的队列
拿到选中队列的第一个进程,开始运行,调度完成!
遍历queue[140]时间复杂度是常数!但还是太低效了!--bitmap解决(下一节讲解)
补充知识点:
当我们要添加一个新进程时,首先通过公式
下标 = (x - 60) + 100计算出该进程优先级对应的数组下标位置,然后将其放入queue数组中对应的链表里。因此,queue数组本质上是一个哈希表,其中优先级数字充当键(key),通过哈希函数(即上述公式)映射到对应的存储位置(桶),而冲突(多个进程优先级相同)则通过链表来解决。
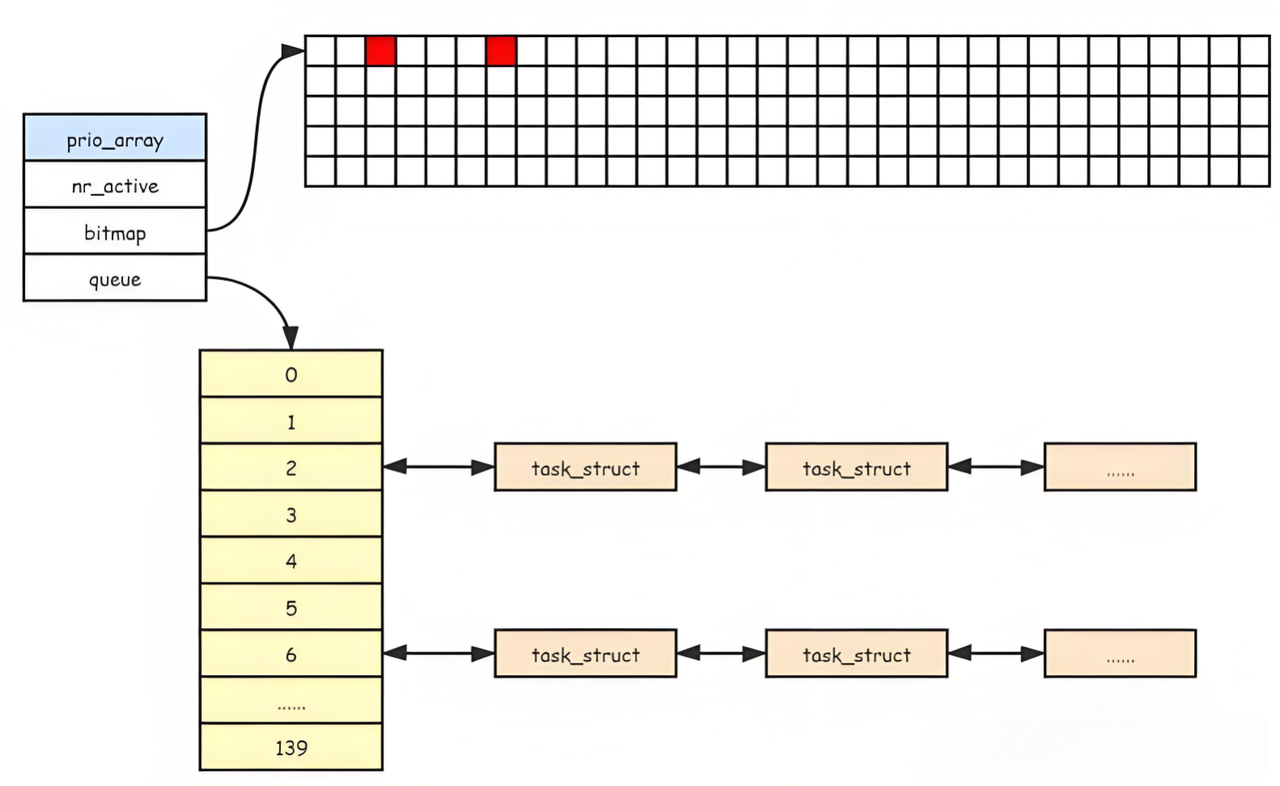
5.2 bitmap[5]数组
如果调度器挑选的进程对应的优先级数字较大,那么它在 queue数组中的位置就会比较靠后(接近数组底部)。这意味着,如果调度器每次都要从数组头部开始逐个遍历来寻找待调度的进程,那么优先级越低的进程,查找所需的耗时就越长,效率显然无法接受。为了解决这个问题,调度器引入了一种更高效的优化手段——位图(bitmap)。
bitmap[5]:一共140个优先级,一共140个进程队列,为了提高查找非空队列的效率,就可以用5*32个比特位表示队列是否为空,这样便可以大大提高查找效率!
为什么是bitmap[5],而不是bitmap[4]或者bitmap[6]???
140 个优先级需要至少 140 个比特位来表示。如果用 4 个 32 位整数(共 128 位)不够,用 6 个(共 192 位)又浪费,所以选择 5 个 32 位整数(共 160 位),刚好覆盖 140 位,剩余的 20 位闲置不用。这是一种权衡存储与效率的设计。
5.2.1 调度器如何使用位图挑选进程
位图的数据结构
调度器维护一个长度为 140 的位图,每一位对应一个优先级队列:
-
位 0 对应优先级 0(最高实时优先级)
-
位 1 对应优先级 1
-
……
-
位 139 对应优先级 139(最低分时优先级)
当一个队列中有进程等待时,该位被置为 1;队列为空时,该位被清为 0。
由于 140 个比特位需要存储空间,调度器通常使用 5 个 32 位整数(共 160 位)来承载这个位图,多余的 20 位闲置不用。
挑选进程的完整流程
当一个调度事件发生时,调度器执行以下步骤:
第一步:定位最高优先级的非空队列
调度器扫描位图,找到第一个(最低位)被置为 1 的位。这一步通过 CPU 提供的专用指令完成,例如 x86 的 BSF(Bit Scan Forward)指令或 __builtin_ctz(Count Trailing Zeros)编译器内置函数。这些指令可以在一个时钟周期内返回最低位 1 的位置。
例如,位图值为 0b00100100时,最低位的 1 位于第 2 位,说明优先级 2 的队列非空且为当前最高优先级。
第二步:从对应队列中取出进程
得到优先级编号后,调度器直接访问 queue[优先级],从该链表的头部取出第一个进程投入运行。
第三步:更新位图
如果取出进程后该队列变为空,调度器将位图中对应的位清为 0,避免下次调度时再次访问空队列。
为什么高效??
整个挑选过程只需要两条关键操作:一条位运算指令找到最低位的 1,一次数组访问取出进程。无论系统中有多少个优先级(140 个还是更多),时间复杂度始终是 O(1),与优先级数量无关。相比遍历数组的最坏情况需要扫描 140 次,位图方案将性能提升了一个数量级以上。
5.2.2 示例
假设当前系统中优先级 2和优先级 6 的队列中有进程等待。位图的值如下(仅展示低 10 位):
位序号: 9 8 7 6 5 4 3 2 1 0
二进制: 0 0 0 1 0 0 0 1 0 0
注意:这是从右往左看的!调度器执行 __builtin_ctz(0b0100100100),立即得到结果 2,于是直接跳转到 queue[2]取出进程运行。整个过程不需要知道优先级 6 的存在,也不需要扫描任何空队列。
小结
位图将调度器从线性遍历中解放出来,使进程选择的效率达到了硬件指令级别。这正是操作系统设计中经典的“用空间换时间”思想——用不到 20 字节的额外存储,换取了每次调度时稳定且极致的性能表现。
5.3 nr_active指针:调度器中的活跃进程计数器
在 Linux 调度器的设计与实现中,除了我们之前讨论的优先级队列和位图之外,还有一个看似简单却至关重要的统计字段——nr_active。
nr_active是运行队列(rq结构体)中的一个计数器,用于记录当前运行队列中所有处于可运行状态(TASK_RUNNING) 的进程总数。简单来说,它就是“当前有多少个进程正在排队等待 CPU”。
nr_active 的作用
1. 快速判断是否需要调度
当调度器被触发时(例如时钟中断、进程唤醒、进程阻塞等事件),它需要知道当前是否真的有进程需要调度。通过检查 nr_active是否为 0,调度器可以快速做出判断:
-
nr_active == 0:没有任何进程需要运行,CPU 可以进入空闲状态(执行 idle 进程) -
nr_active > 0:有进程在等待,需要进行调度决策
这个判断比遍历整个 queue数组要快得多,因为它只是一个整数的读取与比较。
2. 负载均衡的依据
在多核系统中,每个 CPU 都有自己的运行队列,每个队列都有一个 nr_active计数器。当负载均衡模块工作时,它会比较各个 CPU 的 nr_active值,判断哪些 CPU 过载、哪些 CPU 空闲,从而决定是否需要将进程迁移到其他 CPU 上。
例如,如果 CPU0 的 nr_active为 50,而 CPU1 的 nr_active为 5,负载均衡器就会尝试将 CPU0 的部分进程迁移到 CPU1,以达到整体负载的均衡。
5.4 Linux2.6内核进程O(1)调度队列
在早期的 Linux 内核(2.4 及以前)中,进程调度器在选择下一个要运行的进程时需要遍历整个任务列表,时间复杂度为 O(n)——系统中的进程越多,调度一次的开销就越大。这在服务器和高负载场景下成为明显的性能瓶颈。为了解决这个问题,Linux 2.6 引入了著名的 O(1) 调度算法(Completely Fair Scheduler 的前身,也称 O(1) Scheduler),其核心目标是:无论系统中有多少进程,选择下一个进程的时间都是常数级。
O(1) 调度算法:双队列机制
O(1) 调度算法的核心设计非常简单:设置一个活跃队列(active queue)和一个过期队列(expired queue),并维护两个指针——active和 expired,初始时 active指向活跃队列,expired指向过期队列。
调度过程如下:
当 CPU 需要执行进程时,从 active指针指向的活跃队列中取出进程,按照固定时间片运行。如果一个进程在时间片用完后仍未执行完毕,调度器不会让它继续占用 CPU,而是将它放入 expired指针指向的过期队列中,等待下一轮调度。
随着时间推移,活跃队列中的进程逐渐被转移到过期队列。当活跃队列中的所有进程都执行完毕(即队列为空)时,调度器执行一次关键操作:交换 active和 expired两个指针。这一操作的时间复杂度为 O(1),仅仅是一次指针赋值。
交换完成后,原来的过期队列变成了新的活跃队列,原来的活跃队列变成了新的过期队列。CPU 继续从新的活跃队列中取出进程执行,而那些被移入新过期队列的进程将在下一轮再次获得执行机会。如此循环往复,实现了所有进程的公平调度。
这就是 O(1) 调度算法的核心思想:通过双队列和指针交换,避免了遍历和排序带来的性能损耗,使得进程选择的复杂度始终保持为常数级别。
注意点
过期队列
过期队列和活动队列结构一模一样
过期队列上放置的进程,都是时间片耗尽的进程
当活动队列上的进程都被处理完毕之后,对过期队列的进程进行时间片重新计算
active指针和expired指针
active指针永远指向活动队列
expired指针永远指向过期队列
可是活动队列上的进程会越来越少,过期队列上的进程会越来越多,因为进程时间片到期时一直都存在的。
没关系,在合适的时候,只要能够交换active指针和expired指针的内容,就相当于又具有了一批新的活动进程!
这段话有以下几处错误需要更正:
结构体名称:在 Linux O(1) 调度器中,正确的结构体名称是
prio_array_t或struct prio_array,而不是rqueue_elem。数组名称:数组名称为
array[2],而不是prio_arrry[2]。下标对应关系:
array[0]存放的是过期队列,array[1]存放的是活跃队列,与你描述的正好相反。当然,这一点在不同内核版本中可能有差异,但标准的 O(1) 调度器实现中是array[1]为活跃队列。
在 runqueue中,活跃队列和过期队列被封装在一个结构体数组 struct prio_array array[2]中,数组元素的类型为 struct prio_array。这个数组包含两个物理存储空间:array[0]对应的是过期队列,array[1]对应的是活跃队列。两个指针 active和 expired分别指向这两个队列,初始时 active指向 array[1](活跃队列),expired指向 array[0](过期队列)。
结构体struct prio_array的构成如下:
struct prio_array { int nr_active; bitmap[5]; queue[140]; }
5.5 为什么不直接修改PRI值来更改进程优先级?
不直接修改 PRI 的原因很简单:PRI 是进程当前的实际优先级,由内核根据进程的运行行为(是否交互型、是否刚被唤醒、时间片剩余量等)动态计算得出,用户无权直接干涉。如果允许用户直接修改 PRI,就等于允许用户绕过内核的调度策略,可能导致高优先级被恶意压低、低优先级被抬高,破坏公平性。而 NI(Nice 值) 则是用户提供给内核的一个建议值,范围限定在 -20 到 19 之间,普通用户也只能调高(降低优先级),不能随意调低。内核在计算 PRI 时会参考 NI,但最终决定权仍在内核手中。更重要的是,这种设计是为了配套调度算法:调度器需要根据进程的行为动态调整 PRI(例如给交互型进程奖励、给 CPU 密集型进程惩罚),如果 PRI 可以被用户随意修改,调度算法的动态调整机制就会失效。而 NI 作为一个静态参考值,与调度器的动态计算互不冲突,既给了用户一定的干预能力,又保证了调度算法的正常运行。一句话总结:PRI 是内核的最终裁决结果,NI 是用户输入的参考因子,二者分工明确,共同服务于调度算法的公平性与灵活性。
总结
本文深入探讨了Linux进程管理的核心概念与调度机制。首先介绍孤儿进程的形成原理及处理方法,解释子进程被1号进程接管的原因。其次详细讲解进程优先级体系,包括PRI和NI值的关系、调整方法及系统调用接口。重点剖析了Linux O(1)调度算法,通过双队列结构(活跃队列和过期队列)和位图优化实现高效调度,分析queue[140]数组和bitmap[5]的协同工作原理。最后阐明PRI值动态调整机制与NI值的区别,揭示调度器保持公平性的设计理念。全文贯穿Linux进程调度从用户态到内核态的实现细节,展现了操作系统资源管理的精妙设计。

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐
 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)