Nginx 15分钟入门
零、前言
Nginx 有如下几个重要功能:
- 反向代理与负载均衡
- 正向代理
- 存放静态资源。如果客户端请求的是静态资源,可以直接返结果,不往后走了。
- 等等
这里暂且只讲反向代理功能,与反向代理下的负载均衡。
1、反向代理
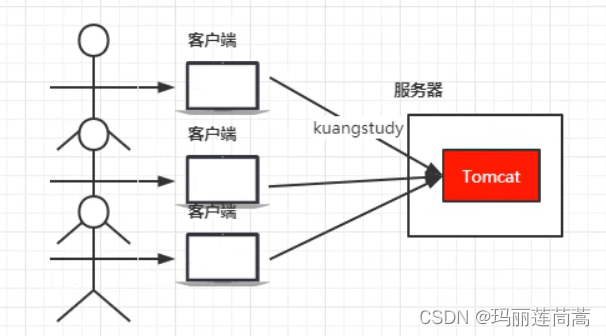
如上图,网站初期用户量较少的时候,一台服务器就够用,但是当大量用户注册,那么显然一台机器就不够了,我们把同一个项目部署在3台服务器上(这里以实体物理服务器举例,虚拟pod同理哈),如下图所示。那么问题又来了,用户A的请求应该打到哪台服务器上呢?用户B呢?那就需要加一个代理服务器来分配连接请求,这就是反向代理(PS:没有什么是加一层不能解决的!)
为什么叫反向代理?那正向代理呢?正向代理代理的是客户端。我们用代理访问外网就是正向代理,反向代理代理的是服务器,反向代理是替服务端干活的,比如我们把同一个服务部署在127.xxx.xxx.2,127.xxx.xxx.3和127.xxx.xxx.4上,但是对外提供的url都是baidu.com,那么这个baidu.com就代理了127.xxx.xxx.2,127.xxx.xxx.3和127.xxx.xxx.4的请求。
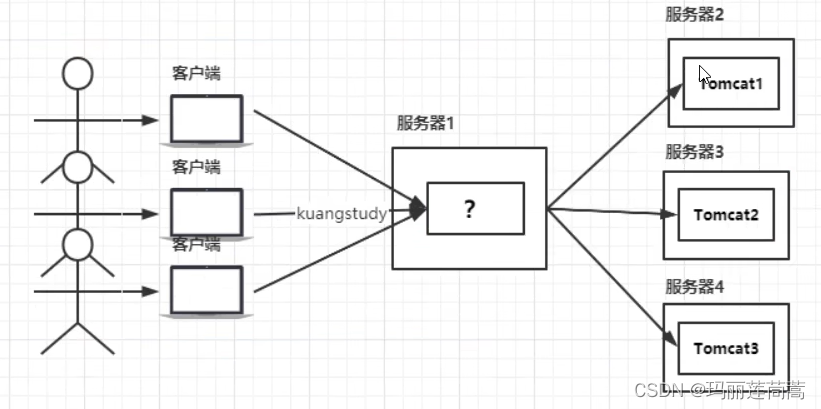
反向代理的实现过程中,有以下需求:
- 会话保持。服务器之间的session是不共享的,要保证用户A上次访问的是第一台服务器,下一次连接也要访问第一台服务器,如果下一次连接的是第二台服务器可能就不认识这个用户了(nginx貌似没解决这个问题哈!)
- 负载均衡。比如上图中服务器的内存依次是64G,16G和8G,那我就希望让64G的服务器承担更多的连接请求,也就是Nginx负责让更多的连接打到64G的服务器上,我们需要在Nginx的配置文件里给服务器配置权重。
- 等等。
2、Nginx性能
tomcat只能支持五六百个并发连接数的响应,但Nginx能支持5万个并发连接(tomcat的100倍)!
除了响应之外,其他性能也很好

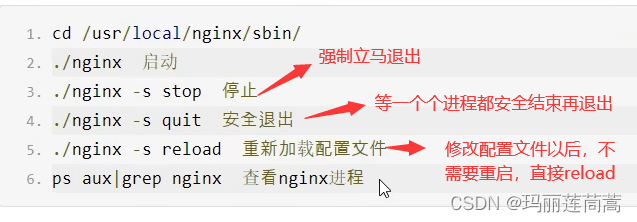
3、Nginx常用命令
4、如何使用Nginx
配置文件:Nginx.conf文件
4.1 反向代理配置
配置反向代理
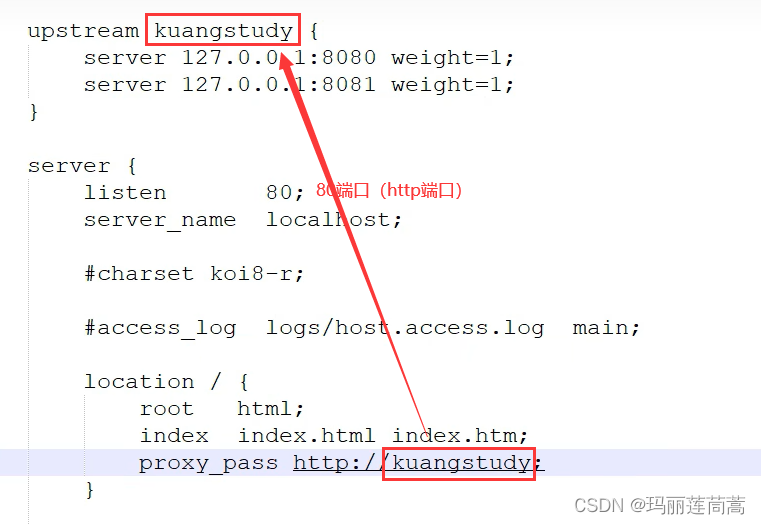
有了上面的配置,访问根目录“/”的请求就会打到127.0.0.1:8080和127.0.0.1:8081这两个端口上。
4.2 负载均衡配置
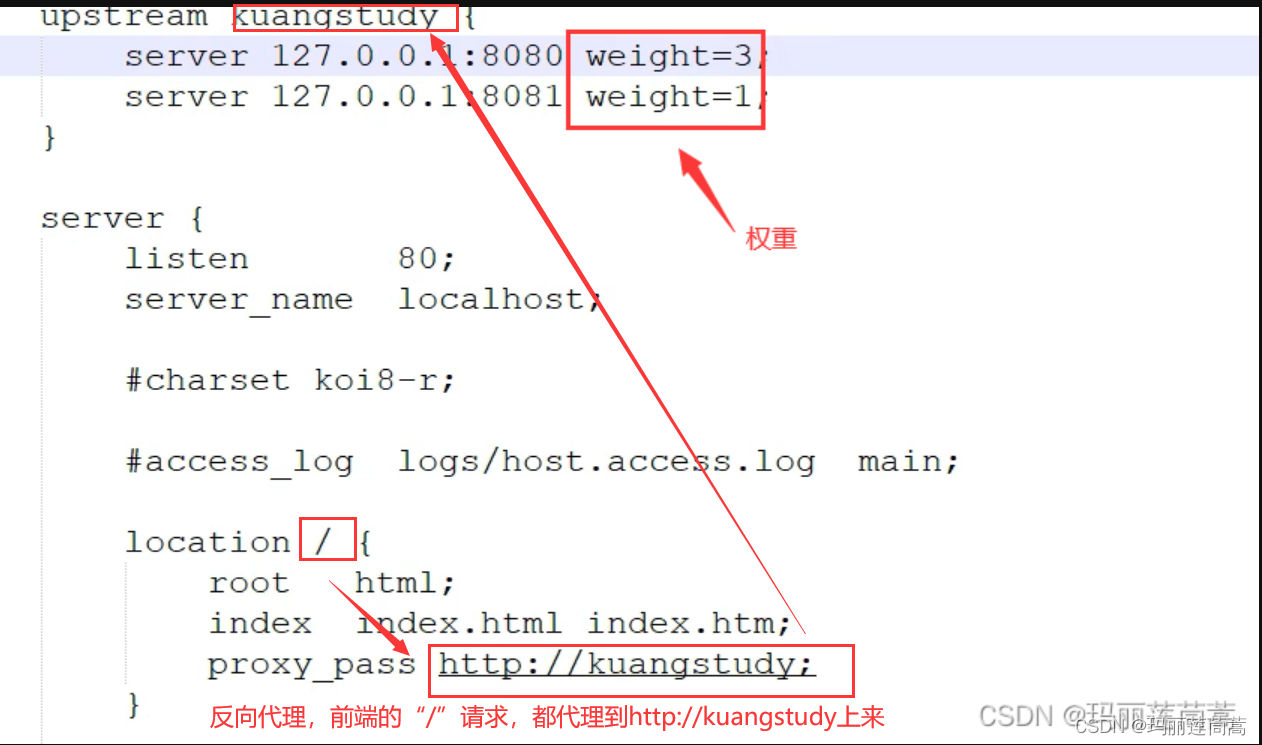
通过权重进行负载均衡的配置。有4个请求,其中3个会打到127.0.0.1:8080上,一个会打到127.0.0.1:8081上
负载均衡的策略
- 轮询(√)
- 这个轮询不是一人一次哦,是根据配置的weight,权重越大的轮询的次数越多(概率越大)
- 实际开发都用这个,其他的策略根本不用的!
- least_conn最小连接(×)
- nginx负责记录各个服务器都有几个连接,每次给最少连接数的服务器分配一个连接。这样保证了一个“绝对公平”,就是大家各台服务器上的连接数是一样的,细想一下就知道不对。因为每一台服务器的配置是不一样的啊,64G内存的就应该比8G内存的机器多连一些
- ip_hash(×)
- 提供一个映射,用户IP地址到服务器编号的映射,思路是同一个用户每次连接,都找第一次连接的那一台服务器,不会出现第一次请求服务连接的是第一台,第二次请求又变成第二台了,因为第二台没存放这个用户的cookie,所以用户还要重新登陆一遍。但是有个问题,用户的IP是一成不变的吗?换个WiFi,相当于换了一个局域网,那么分配给用户的IP就会变呀!
5、Nginx+gateway
真实开发中,二者可以配合使用,nginx后面先分发给gateway集群。
6、递归捋顺知识
Nginx也是一个软件,只不过不同于应用的是,Nginx是一个跑在服务器上,用来做分发的软件。
那既然是软件,也就是程序,也就是一行行代码写出来的。怎么Nginx就能实现5W并发呢?
我们先去想,如果要我们写一个跑在服务器上的、接受前端无数请求的程序,你会怎么写?作为一个服务就得开放一个端口对吧,创建一个专门用来监听这个端口的socket,监听到一个请求就给这个请求创建一个线程去处理,然后我们就不一点点从手工new线程演变到线程池了,直接用成熟的线程池。伪代码如下。
//服务器
public class Server {
public static void main(String[] args) {
//创建专门用来接受客户端请求的线程池
SimpleThreadPool pool = new SimpleThreadPool(10, 100);
//创建一个监听的socket的,指定端口号
ServerSocket serverSocket = new ServerSocket(8080);
//死循环,也就是服务端监听一直跑着,和Nginx一样,实现7×24小时的监听
while (true) {
//监听到客户端连接
Socket clientSocket = serverSocket.accept();
//提交一个任务到线程池
pool.execute(() -> handleClient(clientSocket));
}
}
//提交到线程池的任务
static void handleClient(Socket socket) {
// 读取请求、处理业务、返回响应
}
}好了应用层就写好了,这个任务也完成了,放到Nginx里开始跑吧。
我们写应用层代码的时候,什么5W个并发请求的IO啊全没考虑,为什么应用层变得这么简单呢?因为底层——操作系统层给我们解决好了,并且提供了系统调用select()、poll、epoll,JDK直接调用select()、poll、epoll(对应的系统调用是epoll_create1()、epoll_ctl()和epoll_wait()),我们的线程池直接调用JDK。。。所以我们谈java BIO还是java NIO,其实就是让你理解原理,真实开发中根本不需要你去写java NIO啊,而且JDK给你选好了,你也无法选择。
所以接下来我们只需要理解原理,理解前人的智慧就好啦。你就要去学什么是select、poll、epoll呢?又是如何解决C10K问题的呢?
PS:讲这部分的时候,概念在计算机组成原理、计算机网络、操作系统的层面一直跳来跳去,对着这张学习路径图看就不会迷糊了。
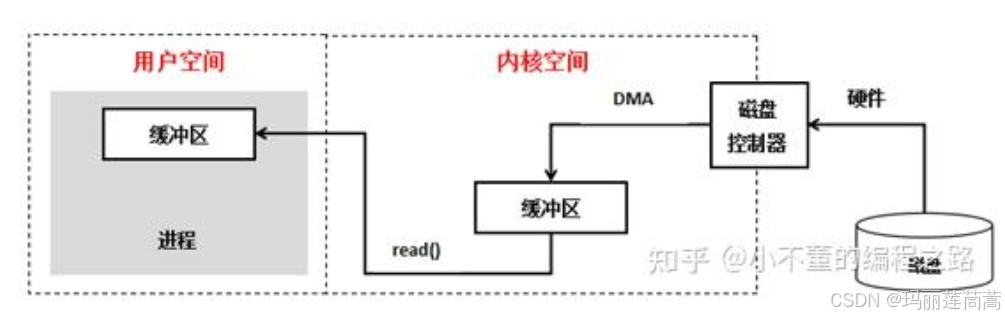
C10K问题本质是什么问题?换句话说,1万个客户端请求一起来了,哪里会暴雷呢?万变不离其祖师爷哈,就算是AI时代、互联网时代,不也是从一台台主机发展出去的吗,也就是离不开我们的计算机,computer 抗木皮优特儿,本身。又回来了,又回到大学计算机组成原理第一课了,冯诺依曼体系结构,分成5大组成部分——运算器、控制器、存储器、输入设备、输出设备。那客户端给服务器发请求的本质上是什么?“客户端给服务器发请求”这句话描述的是应用层,从应用层往下拆拆拆拆到物理层/数据链路层,不就是通过我们看得见摸得着的网卡传“0”和“1”的数据吗,网卡是啥,不就是输入输出设备吗,所以“客户端给服务器发请求”本质上是在进行网络IO(PS:最常发生的IO就两种,磁盘IO和网络IO)。网卡的数据通过DMA(direct memory access)直接进入内存,而DMA是硬件实现的,所以别管怎么进内存的了,直接默认网络I/O来的数据直接进到内存,并且具体是内核态的缓冲区。
接下来我们来到操作系统层面,并且以Linux系统为背景,Linux系统又分为了内核态和用户态。应用和shell一样,都运行在用户态,直观点,就是上面伪代码写的线程池,就是运行在用户态的。客户端的请求数据通过网卡来了并且进入到了内核态的缓冲区里,应用处理业务需要这部分数据呀,所以应用就要通过read()之类的系统调用陷入内核态把数据从内核态拷贝到用户态。拷贝方式有5种,分别对应5个I/O模型。
- blockingIO - 阻塞IO——BIO(✅️,简单的系统也可以用这个模型呀)
- nonblockingIO - 非阻塞IO —— NIO(✅️,好像也有用的吧)
- signaldrivenIO - 信号驱动IO
- asynchronousIO - 异步IO —— AIO
- IOmultiplexing - IO多路复用 (✅️,目前主流操作系统普遍采用这个)
PS:这些IO模型是解决网络大量IO的。磁盘大量IO用缓存去解决。
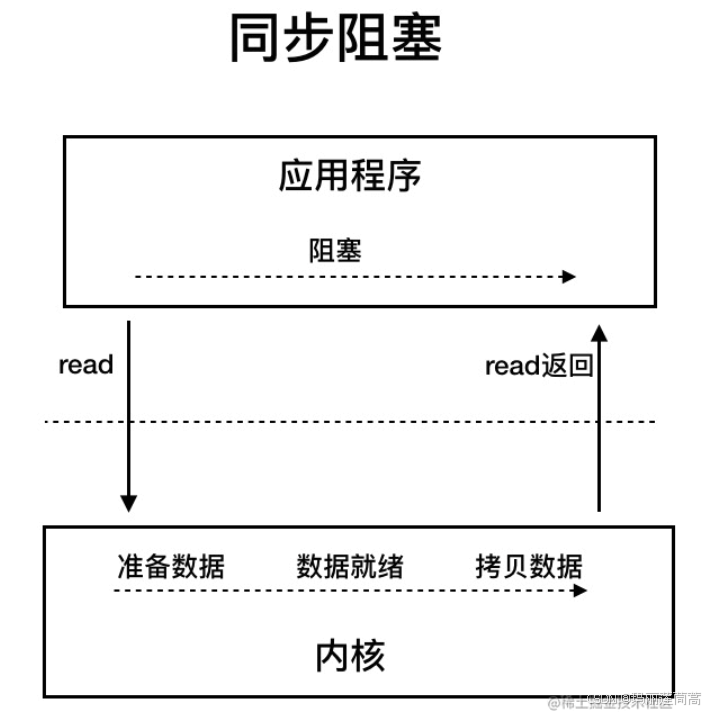
阻塞式IO(BIO),read()方法主要做两件事:
- 整个线程阻塞等待内核态准备好数据
- 拷贝数据
如果同时来了1万个客户端请求,那就在用户态开了1万个线程(忽略应用层线程池做的优化哈,因为应用层的线程池还有一层优化——通过设置线程池的核心参数,可能先开2000个线程先执行着,后面8000个去任务队列排队,我们不管这些,不然说起来没完了),一万个线程同时调用系统调用read(),但是内核态不一定把数据准备了呀,读不到数据没法走下面的代码,read就只能等着数据来。一万个线程同时这么搞,这不就炸了吗?
- read()是阻塞调用,把线程的时间浪费在等待内核态准备数据上了。
- 一边阻塞一边进行1万个线程所属于的进程的上下文切换
总的来说,就是1万个线程又切换又阻塞,CPU一直在转,内存也一直满着,但几乎啥事也没干成,相当于一直在进行很多无意义的系统调用开销。
还有NIO,非阻塞式IO。read()的时候,不让线程空等着,而是让线程可以去处理其他事情,再分出一部分时间来轮询是否准备好数据,准备好了再读。
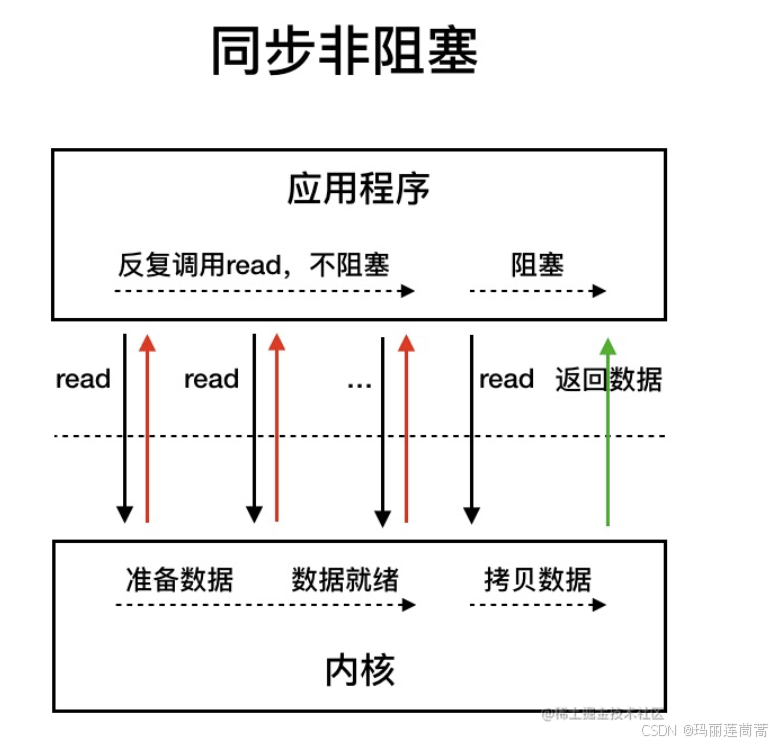
但面对1万个线程来说,稍微解决了BIO的阻塞等待问题,但线程切换的问题还没解决。。所以面对高并发来说依然治标不治本。治“本”的方法是减少陷入内核态的线程数。
其实相信你看完以后,一定有一些自己的优化想法了对不?
- 优化想法1:如果不需要每个线程都单打独斗,要是能组织起来,批量处理就好了
- 优化想法2:如果直接休眠并且不会一遍遍醒过来去等、去查数据是否准备好。而是让他一直睡,当数据准备好,有人去喊醒他就好了。
这就是我们的IO多路复用模型。既然是操作系统层面的问题,所以应该操作系统出面去处理,像Linux 系统就针对IO多路复用模型,先后实现了 select()、poll,并最终提供了高性能的 epoll(对应的系统调用是epoll_create1()、epoll_ctl()和epoll_wait())。
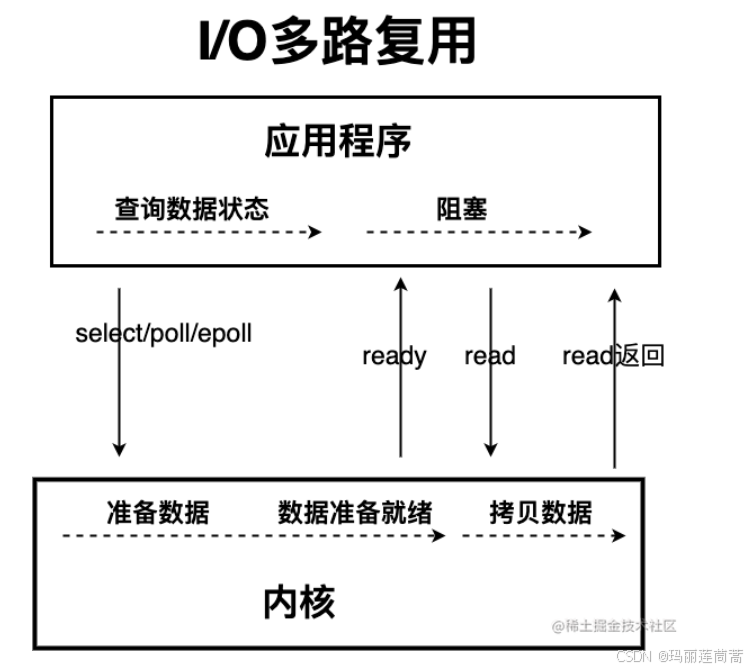
所以其实跟消息队列的思想是一模一样的?加一层,然后谁需要谁就来我这里注册,由事件驱动。。。
协程把切换逻辑完全放在用户态完成,全程不需要陷入内核,彻底绕开了内核上下文切换的开销,让单机并发能力再次突破上限。

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐


 2
2 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)