欧拉回路与欧拉路径的代码执行演示
代码执行演示
读者可能很难相信,如此简单的代码就能完成从找环到判别到插入环的所有步骤。读者可能还会非常疑惑,为什么需要在 dfs 回溯的时候,才将边加入结果序列中?为什么 ans 中存储的是欧拉回路的倒序?让我们通过一个例子来理解这段代码实现的精妙之处。
考虑下面这张仅由一个环组成的图。
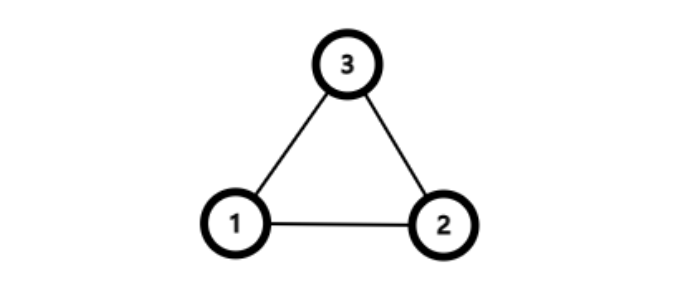
当我们调用 dfs(1) 时,上述实现会以 dfs(1) -> dfs(2) -> dfs(3) -> dfs(1) 的顺序逐层递归。由于节点 此时不存在未被遍历的边,我们找到了一个包含节点 的回路,dfs 也将开始回溯。这正是 Hierholzer 算法流程中的步骤 1(寻找子回路)。
其它节点此时也都不存在未被遍历的边,因此每一层 dfs 的 for 循环都不会被再次运行,而是继续回溯。这正是 Hierholzer 算法流程中的步骤 2(检查是否存在其它回路),只是我们没有找到其它回路。
由于 e[i] 在 dfs 回溯的过程中才被加入 ans,因此回溯结束后,ans 中保存的边为 [3 -> 1, 2 -> 3, 1 -> 2],正是包含节点 的回路的倒序。
让我们在图中增加两个节点,看看递归过程会发生什么变化。
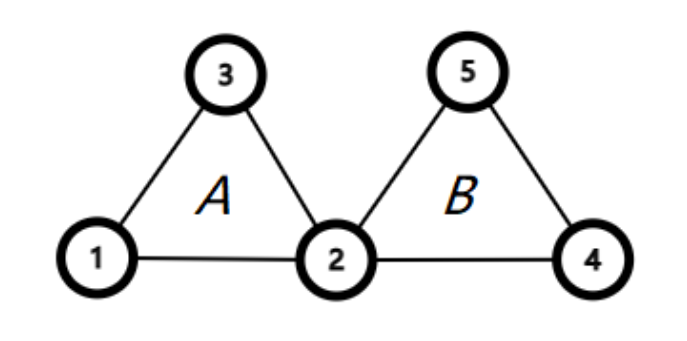
当我们调用 dfs(1) 时,假设上述实现仍然以 dfs(1) -> dfs(2) -> dfs(3) -> dfs(1) 的顺序逐层递归。由于节点 此时不存在未被遍历的边,我们找到了一个包含节点 的回路 ,dfs 也将开始回溯。这一步和前一张图没有什么差别。
当回溯到 dfs(2) 时,此时 ans 中保存的边为 [3 -> 1, 2 -> 3]。由于节点 存在未被遍历的边( 与 ),因此对回路 的记录将暂停。dfs(2) 重新进入 for 循环,开始寻找包含节点 ,且第一条边是 的回路。这正是 Hierholzer 算法流程中的步骤 2(检查是否存在其它回路),而且我们发现存在包含节点 的回路。
开始寻找包含节点 的回路后,上述实现将以 [dfs(1) -> dfs(2)] -> dfs(4) -> dfs(5) -> dfs(2) 的顺序逐层递归。由于节点 此时不存在未被遍历的边,我们找到了一个包含节点 的回路 ,dfs 也将开始回溯。这就重新执行了 Hierholzer 算法流程中的步骤 1(寻找子回路)。
其它节点此时也都不存在未被遍历的边,因此每一层 dfs 的 for 循环都不会被再次运行,而是继续回溯。当重新回溯到 dfs(2) 时,此时 ans 中保存的边为 [3 -> 1, 2 -> 3, 5 -> 2, 4 -> 5, 2 -> 4]。可以看到,我们将回路 的倒序插在了(未完成的)回路 的倒序里。回路 的回溯重新开始。
回溯结束后,ans 中保存的边为 [3 -> 1, 2 -> 3, 5 -> 2, 4 -> 5, 2 -> 4, 1 -> 2]。这正是我们要求的欧拉回路的倒序。

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐
 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)