【MCP实战】从0写一个本地工具服务器:文件搜索、SQLite查询与安全边界

🔥个人主页:爱和冰阔乐
📚专栏传送门:《数据结构与算法》 、C++
🐶学习方向:C++方向学习爱好者
⭐人生格言:得知坦然 ,失之淡然

🏠博主简介
文章目录
前言
前段用 Codex 干活的时候我一直在说一句话:
能调用工具,不代表工具就值得调用;能拿到结果,也不代表结果一定安全。
现在 AI 客户端基本都支持 MCP 了。刚上手最容易做的就是找个天气查询的 demo,注册个工具,看客户端能返回结果,就觉得学会了——但其实还差得远。
但真把它放进自己的开发环境,问题马上就变了:
- 能不能只搜索指定项目,而不是把整个硬盘暴露出去?
- 查询 SQLite 时,怎样保证模型不能执行
DELETE? - 文件很多时,怎样限制扫描时间和返回数量?
- 工具执行失败后,应该返回一大段堆栈,还是返回可判断的错误?
- 使用
stdio传输时,为什么随手写一行console.log就可能把连接弄断? - 客户端看到工具以后,怎样判断它到底调用了哪个参数?
这些问题比“注册一个函数”重要得多。
所以这篇文章不做天气接口,也不做只会返回一句 Hello 的演示,而是从零写一个真正能放在本机使用的小工具服务器。它提供两个工具:
search_files:在允许的项目目录中搜索文本;query_tasks:从本地 SQLite 数据库读取任务记录。
然后把路径白名单、参数校验、数量限制、超时、只读、错误返回这些边界逐一补上——这些才是 MCP 工具真正值得花时间的地方。

一、初始化 TypeScript MCP 项目
1.1 环境检查
先确认 Node.js 和 npm:
node --version
npm --version
本文环境示例:
v24.15.0
11.12.1
SDK v2 拆了包,只写服务端装这些就行:
npm init -y
npm install @modelcontextprotocol/server zod
npm install -D typescript @types/node
如果看到旧文章仍然从
@modelcontextprotocol/sdk/server/mcp.js导入,不要把两套示例混在一起。先看项目安装的是 SDK v1 还是 v2,再决定导入路径。
package.json 可以整理为:
{
"name": "mcp-local-lab",
"version": "1.0.0",
"type": "module",
"private": true,
"scripts": {
"build": "tsc -p tsconfig.json",
"dev": "npm run build && node build/index.js",
"init-db": "node scripts/init-db.mjs"
},
"dependencies": {
"@modelcontextprotocol/server": "^2.0.0",
"zod": "^4.0.0"
},
"devDependencies": {
"@types/node": "^24.0.0",
"typescript": "^5.9.0"
}
}
版本号不用抄到最后一位。关键是:
- SDK v2 使用拆分后的服务端包;
- 项目启用 ESM;
- Node.js 版本满足当前 SDK 要求;
zod的主版本与 SDK 示例一致。
1.2 TypeScript 配置
{
"compilerOptions": {
"target": "ES2023",
"module": "NodeNext",
"moduleResolution": "NodeNext",
"rootDir": "src",
"outDir": "build",
"strict": true,
"noUncheckedIndexedAccess": true,
"esModuleInterop": true,
"skipLibCheck": true
},
"include": ["src/**/*.ts"]
}
我比较建议打开 strict 和 noUncheckedIndexedAccess。
MCP 工具本质上在处理外部参数,类型检查越松,越容易在“理论上有值”的地方得到 undefined。编译器提前指出问题,总比客户端调用后返回内部错误更省时间。
二、实现安全的文件搜索工具
2.1 先定义结果结构
src/file-search.ts:
import { promises as fs } from "node:fs";
import path from "node:path";
export interface SearchMatch {
file: string;
line: number;
preview: string;
}
export interface SearchOptions {
keyword: string;
extensions: string[];
limit: number;
}
返回结果只保留:
- 相对路径;
- 行号;
- 截断后的当前行。
不返回绝对路径,是为了减少不必要的本机信息暴露;不返回整个文件,是为了控制结果大小。
2.2 路径校验不能只用 startsWith
下面这种写法看起来能判断子路径:
candidate.startsWith(root);
但如果根目录是:
D:\code\app
另一个目录是:
D:\code\app-backup
字符串同样以 D:\code\app 开头。
更稳妥的判断方式是使用 path.relative:
function isInside(root: string, candidate: string): boolean {
const relative = path.relative(root, candidate);
return (
relative === "" ||
(!relative.startsWith("..") && !path.isAbsolute(relative))
);
}
除此之外,还要注意符号链接。
目录表面上在项目中,但符号链接可能指向项目外。真正读取前,应尽量对根目录和目标文件执行 realpath,再做一次范围判断。
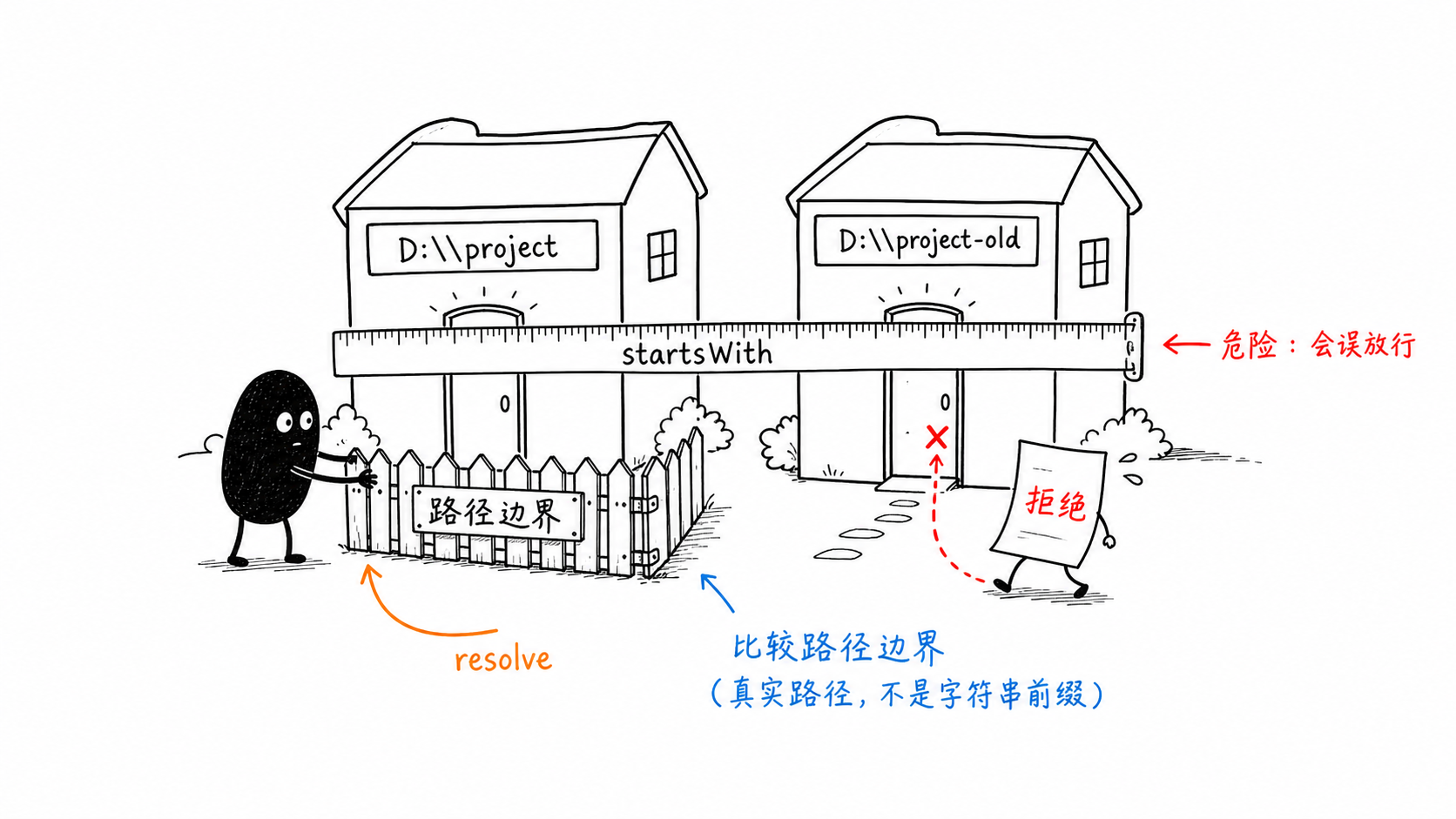
这里容易混淆的是“字符串前缀”和“目录边界”。app-backup 的文字前缀包含 app,但它不是 app 的子目录。先解析真实路径,再用 path.relative 判断是否出现 ..,才是在判断文件系统关系。
2.3 递归搜索实现
const ignoredDirectories = new Set([
".git",
"node_modules",
"build",
"dist",
"coverage"
]);
async function* walk(root: string): AsyncGenerator<string> {
const entries = await fs.readdir(root, { withFileTypes: true });
for (const entry of entries) {
if (entry.isSymbolicLink()) {
continue;
}
const fullPath = path.join(root, entry.name);
if (entry.isDirectory()) {
if (!ignoredDirectories.has(entry.name)) {
yield* walk(fullPath);
}
continue;
}
if (entry.isFile()) {
yield fullPath;
}
}
}
这里直接跳过符号链接。
这不是所有场景的唯一答案,但对本地只读搜索工具来说,它比“跟随链接后再判断”更简单,也更容易解释。
继续完成搜索函数:
export async function searchFiles(
projectRoot: string,
options: SearchOptions,
maxFileBytes: number
): Promise<SearchMatch[]> {
const rootRealPath = await fs.realpath(projectRoot);
const normalizedExtensions = new Set(
options.extensions.map((item) =>
item.startsWith(".") ? item.toLowerCase() : `.${item.toLowerCase()}`
)
);
const keyword = options.keyword.toLowerCase();
const matches: SearchMatch[] = [];
for await (const filePath of walk(rootRealPath)) {
if (matches.length >= options.limit) {
break;
}
const extension = path.extname(filePath).toLowerCase();
if (!normalizedExtensions.has(extension)) {
continue;
}
const stat = await fs.stat(filePath);
if (stat.size > maxFileBytes) {
continue;
}
const realFilePath = await fs.realpath(filePath);
if (!isInside(rootRealPath, realFilePath)) {
continue;
}
let content: string;
try {
content = await fs.readFile(realFilePath, "utf8");
} catch {
continue;
}
const lines = content.split(/\r?\n/);
for (let index = 0; index < lines.length; index += 1) {
const currentLine = lines[index] ?? "";
if (!currentLine.toLowerCase().includes(keyword)) {
continue;
}
matches.push({
file: path.relative(rootRealPath, realFilePath),
line: index + 1,
preview: currentLine.trim().slice(0, 240)
});
if (matches.length >= options.limit) {
break;
}
}
}
return matches;
}
这段代码没有调用 shell,也没有拼接命令。
性能肯定比专业搜索工具差,但边界比较清楚,适合作为第一版。项目很大时,可以在服务端内部调用 ripgrep,但必须使用参数数组,不要拼接命令字符串,同时仍然要保留根目录和数量限制。
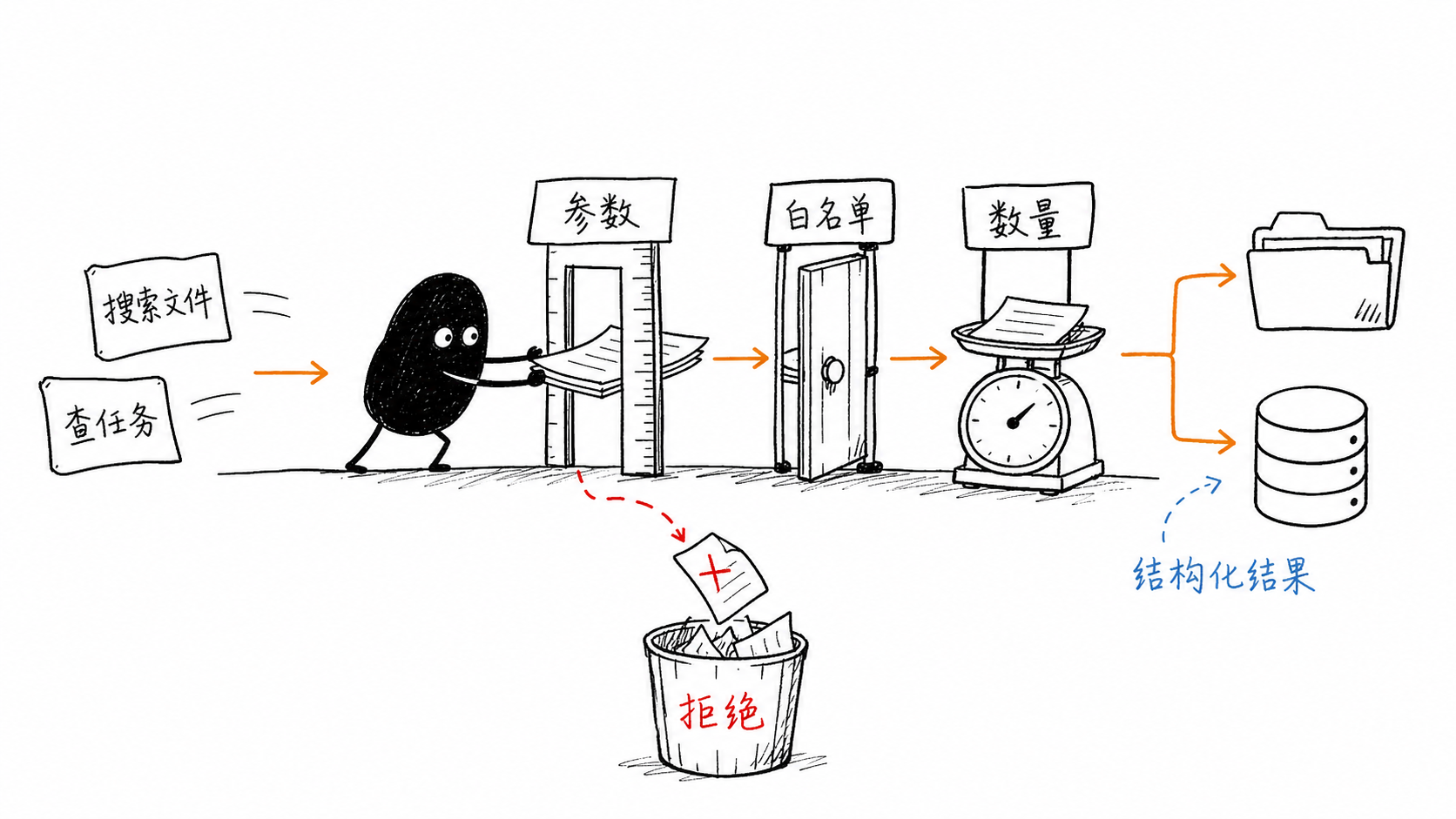
2.4 为什么不能只依赖输入 Schema?
zod 可以保证 limit 是数字,也可以限制它在 1 到 50 之间,但它不能自动判断:
- 当前文件是不是二进制;
- 符号链接是否越界;
- 文件读取是否超时;
- 返回结果是否过大。
Schema 是第一层,业务校验是第二层,操作系统权限是第三层。
安全不是某一个 z.object() 能解决的。
三、SQLite 查询:不要把“任意 SQL”包装成工具
3.1 先建立一个最小任务表
Node.js 24 可以使用 node:sqlite。初始化脚本 scripts/init-db.mjs:
import { mkdirSync } from "node:fs";
import { dirname, resolve } from "node:path";
import { DatabaseSync } from "node:sqlite";
const databasePath = resolve("data/tasks.db");
mkdirSync(dirname(databasePath), { recursive: true });
const db = new DatabaseSync(databasePath);
db.exec(`
CREATE TABLE IF NOT EXISTS tasks (
id INTEGER PRIMARY KEY,
title TEXT NOT NULL,
status TEXT NOT NULL CHECK(status IN ('open', 'doing', 'closed')),
priority TEXT NOT NULL CHECK(priority IN ('low', 'medium', 'high')),
created_at TEXT NOT NULL
);
`);
const count = db.prepare("SELECT COUNT(*) AS total FROM tasks").get();
if (count.total === 0) {
const insert = db.prepare(`
INSERT INTO tasks (title, status, priority, created_at)
VALUES (?, ?, ?, ?)
`);
insert.run("fix upload retry", "open", "high", "2026-06-01");
insert.run("add path allowlist", "open", "medium", "2026-06-03");
insert.run("remove debug output", "closed", "low", "2026-06-05");
}
db.close();
console.error(`database initialized: ${databasePath}`);
注意最后使用的是 console.error。
对 stdio MCP Server 来说,标准输出承载协议消息。调试信息写到 stdout,可能和 JSON-RPC 数据混在一起,客户端最后只会告诉你“连接断开”或“解析失败”。
本地
stdio服务端的普通日志写stderr,不要把console.log当成无害操作。
3.2 一个看似灵活、实际很危险的工具
不要设计成这样:
queryDatabase({
sql: "SELECT * FROM tasks"
});
然后在代码里判断:
if (!sql.startsWith("SELECT")) {
throw new Error("read only");
}
这种校验挡不住复杂注释、多个语句、不同大小写和数据库特性。即使能挡住写操作,模型也可能一次读取整个数据库。
更合理的接口是让工具表达业务意图:
按状态、优先级和数量查询任务
模型不需要知道表结构,更不需要自己拼 SQL。

图里的关键不是把 SQL 换个名字,而是收窄可执行能力。模型只提交状态、优先级和数量,服务端负责参数化查询,并用只读方式打开数据库。即使调用参数写错,也不会顺手变成任意 SQL 执行器。
3.3 任务仓库实现
src/task-repository.ts:
import { DatabaseSync } from "node:sqlite";
export type TaskStatus = "open" | "doing" | "closed";
export type TaskPriority = "low" | "medium" | "high";
export interface TaskRow {
id: number;
title: string;
status: TaskStatus;
priority: TaskPriority;
created_at: string;
}
export class TaskRepository {
private readonly database: DatabaseSync;
constructor(databasePath: string) {
this.database = new DatabaseSync(databasePath, {
readOnly: true
});
}
find(options: {
status?: TaskStatus;
priority?: TaskPriority;
limit: number;
}): TaskRow[] {
const conditions: string[] = [];
const values: Array<string | number> = [];
if (options.status) {
conditions.push("status = ?");
values.push(options.status);
}
if (options.priority) {
conditions.push("priority = ?");
values.push(options.priority);
}
const where =
conditions.length > 0 ? `WHERE ${conditions.join(" AND ")}` : "";
const statement = this.database.prepare(`
SELECT id, title, status, priority, created_at
FROM tasks
${where}
ORDER BY
CASE priority
WHEN 'high' THEN 1
WHEN 'medium' THEN 2
ELSE 3
END,
id ASC
LIMIT ?
`);
values.push(options.limit);
return statement.all(...values) as unknown as TaskRow[];
}
close(): void {
this.database.close();
}
}
这里用了三层限制:
- 数据库以只读模式打开;
- SQL 模板由服务端固定;
- 条件值使用参数绑定。
就算模型传入:
open' OR 1=1 --
zod 枚举也不会接受;即使绕过了上层,参数绑定也不会把它当作 SQL 结构执行。
四、注册两个 MCP 工具
4.1 创建服务器
src/index.ts:
import { McpServer } from "@modelcontextprotocol/server";
import { StdioServerTransport } from "@modelcontextprotocol/server/stdio";
import * as z from "zod/v4";
import { config } from "./config.js";
import { searchFiles } from "./file-search.js";
import { TaskRepository } from "./task-repository.js";
const server = new McpServer({
name: "mcp-local-lab",
version: "1.0.0"
});
const taskRepository = new TaskRepository(config.databasePath);
工具名称应该稳定、清晰。
像 do_it、run、execute 这种名字几乎不能帮助模型选择。描述中也不要写空话,要说明输入、结果和限制。
4.2 注册文件搜索工具
server.registerTool(
"search_files",
{
description:
"Search text files under the configured project root. " +
"Returns relative paths, line numbers and short previews. " +
"This tool is read-only and cannot search outside the allowed root.",
inputSchema: z.object({
keyword: z.string().trim().min(2).max(100),
extensions: z
.array(z.enum(["ts", "tsx", "js", "mjs", "json", "md", "yml", "yaml"]))
.min(1)
.max(8)
.default(["ts", "tsx", "js", "md"]),
limit: z.number().int().min(1).max(50).default(20)
})
},
async ({ keyword, extensions, limit }) => {
try {
const matches = await searchFiles(
config.projectRoot,
{ keyword, extensions, limit },
config.maxFileBytes
);
const text =
matches.length === 0
? "No matches found."
: matches
.map(
(item) =>
`${item.file}:${item.line}\n${item.preview}`
)
.join("\n\n")
.slice(0, config.maxReturnedCharacters);
return {
content: [{ type: "text", text }]
};
} catch (error) {
const message =
error instanceof Error ? error.message : "unknown search error";
console.error(`[search_files] ${message}`);
return {
isError: true,
content: [
{
type: "text",
text: "File search failed. Check the configured root and file permissions."
}
]
};
}
}
);
这里故意没有把完整堆栈返回给客户端。
堆栈可以写进本地日志,但工具结果只需要告诉模型:
- 什么操作失败了;
- 用户可以检查什么;
- 是否可以重试。
把本机绝对路径、依赖位置和内部堆栈全部返回,不但噪声大,还可能泄露不必要的信息。
4.3 注册任务查询工具
server.registerTool(
"query_tasks",
{
description:
"Read task records from the configured local SQLite database. " +
"Supports status and priority filters. This tool cannot modify data.",
inputSchema: z.object({
status: z.enum(["open", "doing", "closed"]).optional(),
priority: z.enum(["low", "medium", "high"]).optional(),
limit: z.number().int().min(1).max(30).default(10)
})
},
async ({ status, priority, limit }) => {
try {
const tasks = taskRepository.find({ status, priority, limit });
return {
content: [
{
type: "text",
text:
tasks.length === 0
? "No tasks matched the filters."
: tasks
.map(
(task) =>
`${task.id} | ${task.title} | ` +
`${task.status} | ${task.priority} | ${task.created_at}`
)
.join("\n")
}
]
};
} catch (error) {
const message =
error instanceof Error ? error.message : "unknown database error";
console.error(`[query_tasks] ${message}`);
return {
isError: true,
content: [
{
type: "text",
text: "Task query failed. Check database existence and read permission."
}
]
};
}
}
);
4.4 连接 stdio
async function main(): Promise<void> {
const transport = new StdioServerTransport();
await server.connect(transport);
console.error("[mcp-local-lab] connected through stdio");
}
async function shutdown(signal: string): Promise<void> {
console.error(`[mcp-local-lab] received ${signal}`);
taskRepository.close();
process.exit(0);
}
process.on("SIGINT", () => void shutdown("SIGINT"));
process.on("SIGTERM", () => void shutdown("SIGTERM"));
main().catch((error) => {
console.error("[mcp-local-lab] fatal error", error);
process.exit(1);
});
至此,两个工具已经注册完成。
这是本文自建案例的示例输出。真实项目中的文件数量和耗时会随目录规模变化,排查时更应该关注工具是否只返回允许范围内的路径和字段。
最后再提醒一个很隐蔽的坑:使用 stdio 时,标准输出本身就是协议通道。普通日志混进 stdout,客户端读到的就不再是完整协议消息。
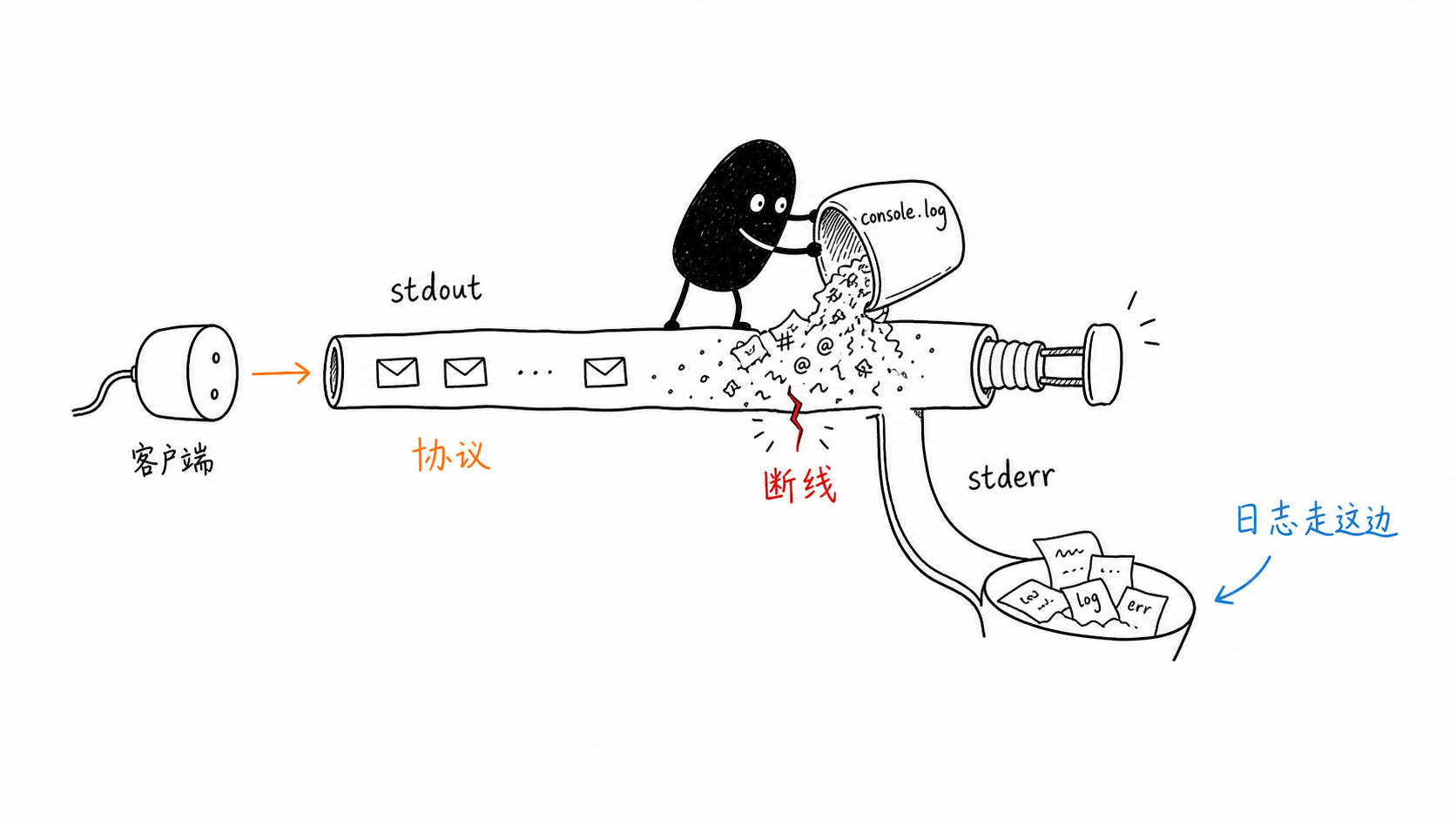
调试日志写到 stderr,协议消息留在 stdout。这个习惯看起来不起眼,实际能省掉不少“工具明明注册了,客户端却突然断开”的排查时间。
总结
写完了。两个工具——文件搜索和任务查询——代码本身不复杂,真正花时间的是边界。
- 根目录由服务端配置,不由模型决定;
- 文件搜索限制扩展名、大小和返回数量;
- 数据库只读打开,不接收任意 SQL;
- 所有参数经过 Schema 和业务逻辑双重校验;
stdio日志写入stderr;- 错误结果能判断,但不暴露内部细节;
- 测试不光跑正常路径,越界、失败和客户端行为都要过一遍。
MCP 最有价值的地方不是让 AI “什么都能调”,是能让我们把能力拆成一个个边界明确的工具。工具多了反而更要写清楚:允许范围、校验证据、失败方式。
后面如果继续扩展,可以增加:
- 项目构建结果读取;
- Git diff 摘要;
- 测试报告查询;
- 只读日志分析;
- 先生成补丁、确认后再写入的配置修改。
但不管加什么工具,先想清楚三件事:
它能读什么?
它能改什么?
它失败后会留下什么?
参考资料
-
MCP 官方:Build an MCP server
https://modelcontextprotocol.io/docs/develop/build-server -
MCP 官方 TypeScript SDK
https://github.com/modelcontextprotocol/typescript-sdk -
MCP TypeScript SDK Server Guide
https://github.com/modelcontextprotocol/typescript-sdk/blob/main/docs/server.md -
MCP TypeScript SDK v1 → v2 Migration Guide
https://github.com/modelcontextprotocol/typescript-sdk/blob/main/docs/migration.md -
Node.js SQLite 文档
https://nodejs.org/api/sqlite.html

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐

 3
3 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)