MCP 本地工具服务器实战:文件搜索和 SQLite 查询做好安全边界,再用 cpolar 远程联调
MCP 本地工具服务器实战:文件搜索和 SQLite 查询做好安全边界,再用 cpolar 远程联调
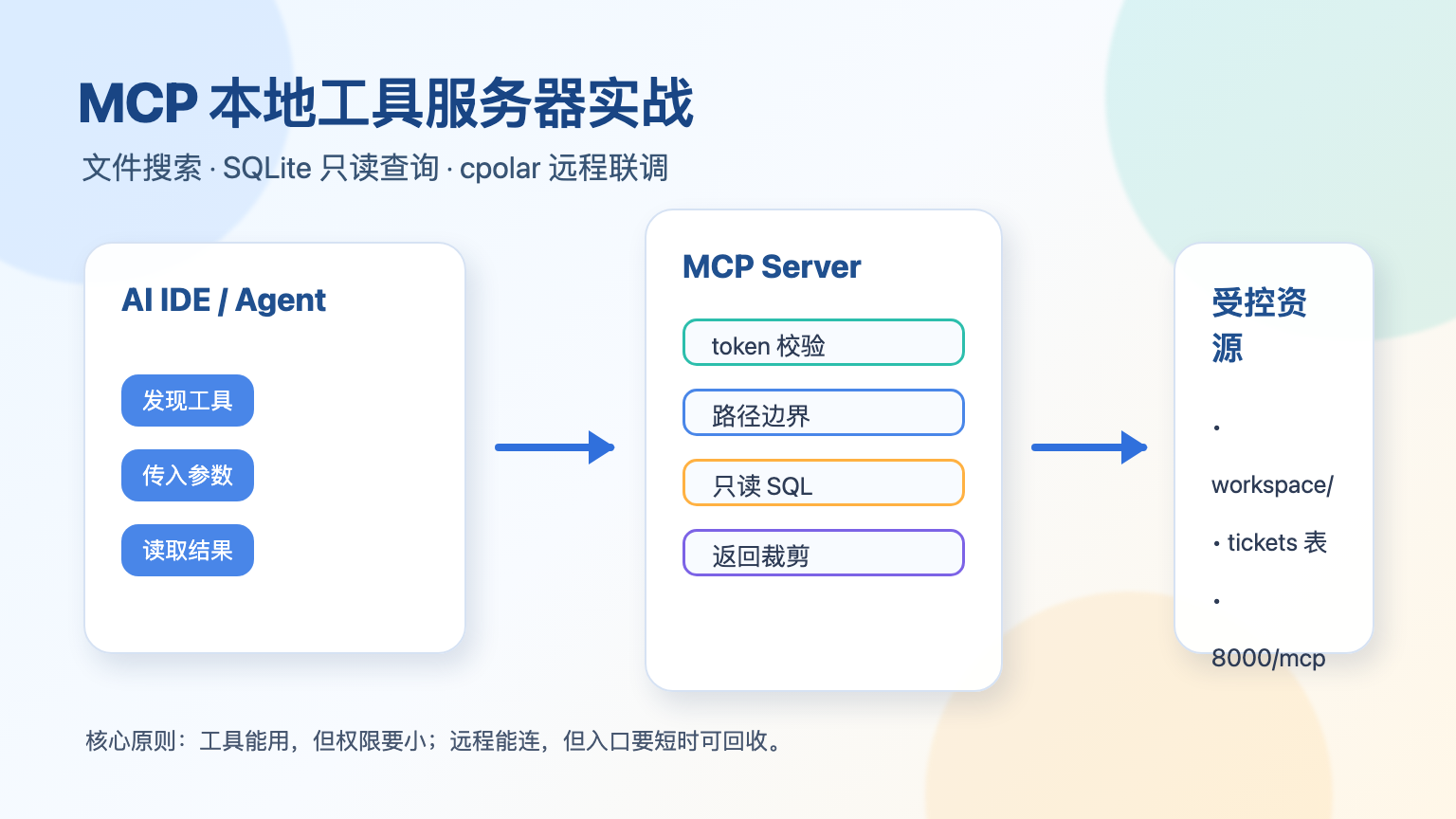
本地 MCP 工具最容易踩的坑,不是服务跑不起来,而是一上来就把“读文件、查数据库”开得太大。AI IDE 连上以后确实爽,但它能搜到什么目录、能查哪张表、能不能写库,这些边界如果没提前划好,后面排错会很难受。
这篇就做一个小而完整的本地 MCP 工具服务器:只允许搜索指定目录里的文件,只允许查询 SQLite 的白名单表,再用 token 做一层简单鉴权。最后用 cpolar 开一个临时 HTTPS 地址,方便远程同事或另一台机器联调。重点不是把服务暴露出去,而是把“能暴露什么、暴露多久、怎么收回来”讲清楚。
本文示例使用 Python MCP SDK。MCP 官方 Python SDK 支持
stdio、SSE、Streamable HTTP等传输方式,本文用Streamable HTTP做本地和远程联调演示。
1 什么是 MCP 本地工具服务器?
MCP,全称 Model Context Protocol,可以把本地能力包装成标准工具,让 AI IDE、Agent 客户端按统一协议调用。放到今天这个场景里,它负责三件事:
- 把文件搜索封装成一个工具
- 把 SQLite 查询封装成一个工具
- 给客户端提供统一的
/mcp接入入口
说白了,它不是让模型“随便操作你的电脑”,而是你把能力切成一个个受控工具,再交给客户端调用。
这里有个血泪教训:文件工具和数据库工具都不能图省事。文件搜索如果直接从用户输入拼路径,很容易搜到工作目录之外;SQL 查询如果直接执行完整 SQL,就会把删表、改表、导出敏感字段这些风险一起带进来。
所以本文的目标很明确:能用,但只给最小权限。
2 环境准备:创建项目和测试数据
先准备一个干净目录,后面的命令都在这个目录里执行。这里别直接拿真实项目根目录开搞,先用示例数据跑通链路,后面再替换成自己的只读目录。
mkdir -p ~/mcp-local-tools-demo/{workspace,data}
cd ~/mcp-local-tools-demo
python3 -m venv .venv
source .venv/bin/activate
pip install "mcp[cli]" aiosqlite
确认 Python 和依赖已经装好:
python --version
python -c "import mcp, aiosqlite; print('mcp demo ready')"
这一步不是走流程,而是提前确认环境没问题。如果这里报 ModuleNotFoundError,优先检查虚拟环境是否已经 source .venv/bin/activate。
2.1 准备允许搜索的文件目录
我们只让工具搜索 workspace 目录,别让它碰整个用户目录。先放几份测试文件:
cat > workspace/readme.md <<'EOF'
# Demo Project
This project contains API notes and deployment records.
EOF
cat > workspace/api-notes.txt <<'EOF'
The order API reads from SQLite and returns readonly reports.
EOF
cat > workspace/secret.env <<'EOF'
API_KEY=demo_key_should_not_be_returned
EOF
注意,secret.env 是故意放进去的。后面代码会跳过 .env 文件,这样能验证过滤规则真的生效。
2.2 准备 SQLite 只读示例库
再创建一个 SQLite 数据库,只放一张允许查询的表:
python - <<'PY'
import sqlite3
from pathlib import Path
Path('data').mkdir(exist_ok=True)
conn = sqlite3.connect('data/app.db')
conn.execute('DROP TABLE IF EXISTS tickets')
conn.execute('CREATE TABLE tickets (id INTEGER PRIMARY KEY, title TEXT, status TEXT)')
conn.executemany(
'INSERT INTO tickets (title, status) VALUES (?, ?)',
[
('MCP file search boundary', 'open'),
('SQLite readonly query', 'done'),
('cpolar remote debug session', 'open'),
],
)
conn.commit()
conn.close()
PY
查一下数据:
sqlite3 data/app.db "SELECT id, title, status FROM tickets;"
如果本机没有 sqlite3 命令行工具,也不影响后面的 Python 服务运行。这里主要是给自己看一眼数据是否写入成功。
3 编写 MCP 服务:只开放两个受控工具
现在开始写服务端。这个文件里有几个关键边界:文件目录白名单、后缀过滤、SQLite 表白名单、SQL 只读检查、token 校验。
新建 server.py:
cat > server.py <<'PY'
import os
import sqlite3
from pathlib import Path
from typing import Annotated
from mcp.server.fastmcp import FastMCP
BASE_DIR = Path(__file__).resolve().parent
WORKSPACE_DIR = (BASE_DIR / "workspace").resolve()
DB_PATH = (BASE_DIR / "data" / "app.db").resolve()
ACCESS_TOKEN = os.environ.get("MCP_DEMO_TOKEN", "change-me")
ALLOWED_SUFFIXES = {".md", ".txt", ".py", ".json"}
ALLOWED_TABLES = {"tickets"}
mcp = FastMCP("local-safe-tools", json_response=True)
def require_token(token: str) -> None:
if token != ACCESS_TOKEN:
raise ValueError("invalid token")
def ensure_inside_workspace(path: Path) -> Path:
resolved = path.resolve()
if not resolved.is_relative_to(WORKSPACE_DIR):
raise ValueError("path is outside workspace")
return resolved
@mcp.tool()
def search_files(
keyword: Annotated[str, "Keyword to search in allowed text files"],
token: Annotated[str, "Access token"],
) -> list[dict[str, str]]:
"""Search keyword in whitelisted files under the workspace directory."""
require_token(token)
keyword = keyword.strip()
if not keyword:
raise ValueError("keyword is required")
results: list[dict[str, str]] = []
for file_path in WORKSPACE_DIR.rglob("*"):
safe_path = ensure_inside_workspace(file_path)
if not safe_path.is_file() or safe_path.suffix not in ALLOWED_SUFFIXES:
continue
text = safe_path.read_text(encoding="utf-8", errors="ignore")
if keyword.lower() in text.lower():
results.append({"file": str(safe_path.relative_to(WORKSPACE_DIR)), "preview": text[:160]})
return results[:20]
@mcp.tool()
def query_tickets(
status: Annotated[str, "Ticket status filter, such as open or done"],
token: Annotated[str, "Access token"],
) -> list[dict[str, str | int]]:
"""Query tickets table with a readonly parameterized SQL statement."""
require_token(token)
if "tickets" not in ALLOWED_TABLES:
raise ValueError("tickets table is not allowed")
readonly_uri = f"file:{DB_PATH}?mode=ro"
with sqlite3.connect(readonly_uri, uri=True) as conn:
conn.row_factory = sqlite3.Row
rows = conn.execute(
"SELECT id, title, status FROM tickets WHERE status = ? ORDER BY id LIMIT 20",
(status,),
).fetchall()
return [dict(row) for row in rows]
if __name__ == "__main__":
mcp.run(transport="streamable-http")
PY
这里别把 ACCESS_TOKEN 写死到代码仓库里。示例里给了默认值,只是为了本地演示不至于卡住;正式用时用环境变量传入。
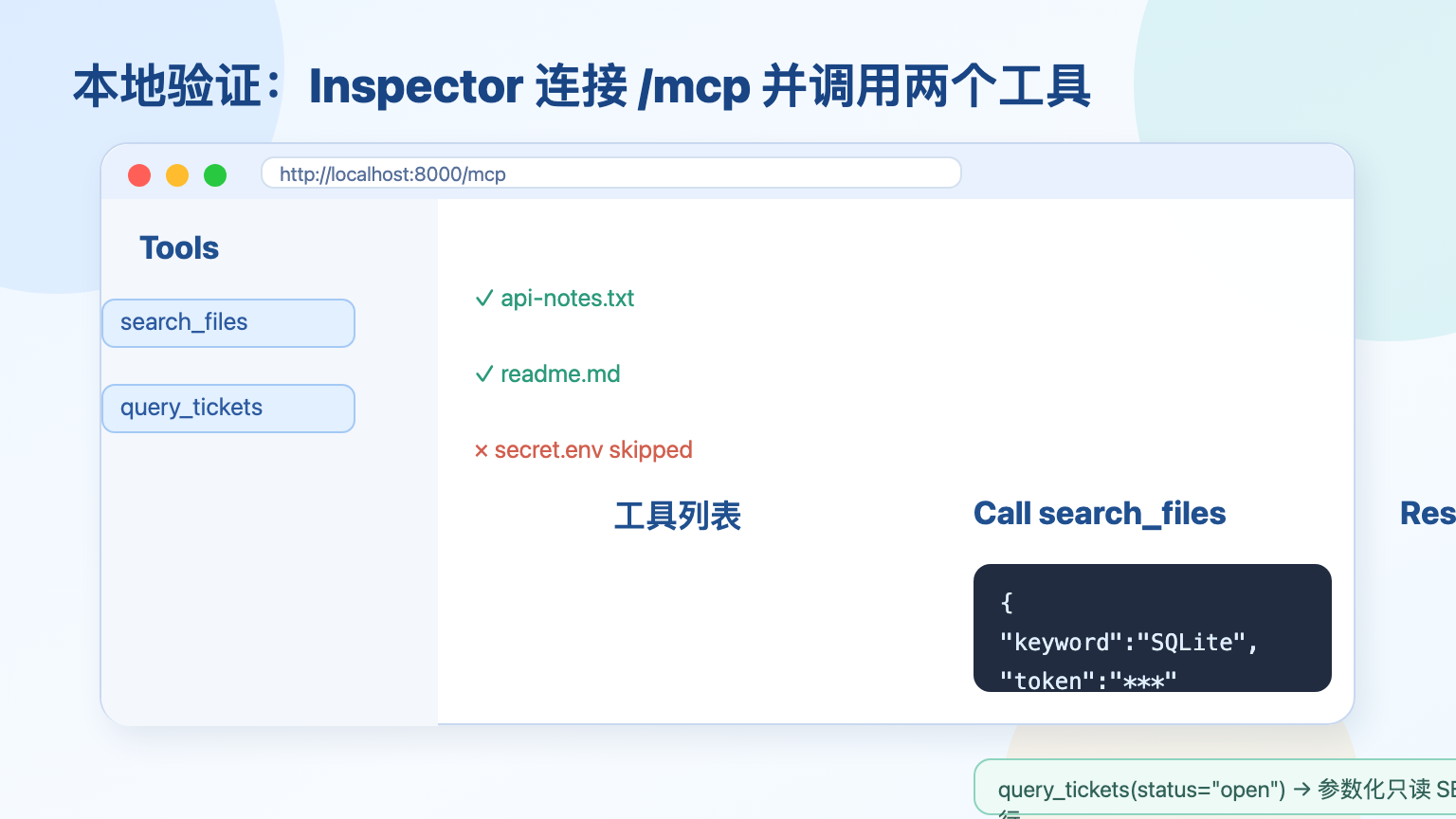
4 本地启动并用 Inspector 验证
启动服务前,先设置一个 token:
export MCP_DEMO_TOKEN="mcp-demo-20260615"
python server.py
FastMCP 使用 Streamable HTTP 运行时,默认会提供本地 MCP 入口。打开另一个终端,用官方 Inspector 连接:
npx -y @modelcontextprotocol/inspector
Inspector 启动后,在页面里连接:
http://localhost:8000/mcp
连接成功后能看到 search_files 和 query_tickets 两个工具。先调用 search_files,参数填:
{
"keyword": "SQLite",
"token": "mcp-demo-20260615"
}
预期会返回 api-notes.txt 或 readme.md 里的片段,但不会返回 secret.env。如果结果为空,先检查当前服务启动目录是否是 ~/mcp-local-tools-demo,再检查 workspace 里是否有刚才写入的文件。
再调用 query_tickets:
{
"status": "open",
"token": "mcp-demo-20260615"
}
这一步会返回状态为 open 的工单列表。注意这里没有让客户端提交任意 SQL,而是只提交 status 参数,服务端自己拼好参数化查询语句。
5 安全边界:文件、SQL、token 三层都要收紧
这类工具能不能放心给团队用,关键看边界有没有落实到代码里。
文件搜索这边,最重要的是 WORKSPACE_DIR 和 ensure_inside_workspace()。客户端不能传目录,服务端也不会从用户输入里拼根路径,所有搜索都固定在白名单目录下。后缀也做了限制,.env 不在 ALLOWED_SUFFIXES 里,密钥类文件不会进入返回结果。
SQLite 这边,示例用了 mode=ro 打开数据库,并且只写了固定查询:
readonly_uri = f"file:{DB_PATH}?mode=ro"
conn.execute(
"SELECT id, title, status FROM tickets WHERE status = ? ORDER BY id LIMIT 20",
(status,),
)
划重点:不要把“请输入 SQL”做成 MCP 工具参数。真要做通用查询,也要在服务端解析并限制只允许 SELECT,再叠加表白名单、字段白名单和行数上限。教程里我更推荐固定工具固定 SQL,排错轻松,权限也更清楚。
Token 这一层不复杂,但很有用。它不能替代完整的认证系统,不过足够挡住误连、乱连和临时地址被转发后的低级风险。生产环境要接入更严格的鉴权和审计,不要只靠一个演示 token。
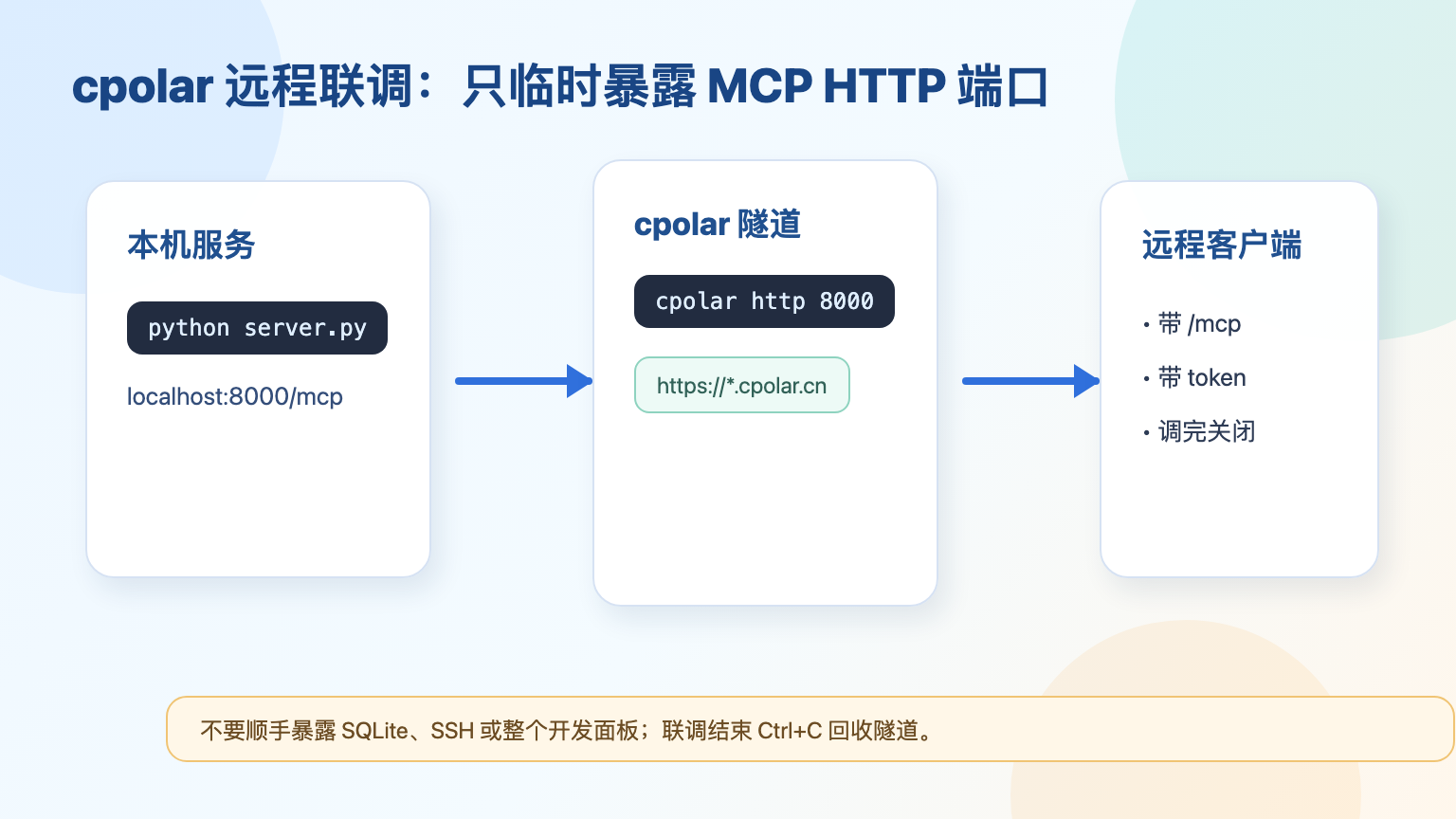
6 用 cpolar 做远程联调:只暴露 MCP 调试入口
本地验证完成后,再考虑远程联调。比如同事在另一台电脑上调 AI IDE,或者你想让一台测试机连到这台开发机的 MCP 服务,localhost:8000 对外不可见,这时可以用 cpolar 开一个临时 HTTPS 入口。
先安装并启动 cpolar。Linux 官方一键安装命令如下:
curl -L https://www.cpolar.com/static/downloads/install-release-cpolar.sh | sudo bash
cpolar version
macOS 可以通过 Homebrew 安装:
brew tap probezy/core && brew install cpolar
cpolar version
安装后打开本地 Web UI:
open http://127.0.0.1:9200
如果是纯命令行环境,也可以手动绑定账号 token:
cpolar authtoken YOUR_CPOLAR_AUTHTOKEN
这里别把 SQLite 端口、SSH 端口、整个开发面板一起暴露出去。本文只映射 MCP 服务端口 8000:
cpolar http 8000
命令启动后,终端会显示一个公网 HTTPS 地址。把远程客户端的 MCP 地址改成:
https://你的随机地址.cpolar.cn/mcp
免费随机公网地址会在 24 小时内变化,适合短时联调。需要固定二级子域名时,cpolar 需要基础服务版本或以上;需要自定义域名时,需要专业服务版本或以上。对这篇教程来说,随机地址已经够用,因为我们追求的是短时调试,调完就关。
7 远程联调后的回收和排错
远程联调时,建议只把地址发给可信同事,并同步 token。调试结束后,在运行 cpolar 的终端按 Ctrl+C 关闭隧道;如果是 Web UI 创建的隧道,就到 状态 -> 在线隧道列表 确认它已经下线。
如果远程访问失败,按这个顺序查:
- 本机
http://localhost:8000/mcp是否能被 Inspector 连接 cpolar http 8000是否还在运行- cpolar Web UI 的在线隧道列表里是否显示公网 HTTPS 地址
- 远程客户端填的路径是否带
/mcp - 工具参数里的 token 是否和环境变量
MCP_DEMO_TOKEN一致
别一上来就怀疑 MCP 或 cpolar。很多问题其实是服务没开、路径少了 /mcp,或者 token 复制时多了空格。
如果你只是自己在局域网里调试,这一节可以先跳过。cpolar 的价值在于“临时让外部机器接进来”,不是把本地工具长期裸挂在公网。
8 总结
到这里,我们已经做完了一个可联调的 MCP 本地工具服务器:文件搜索只能读白名单目录,SQLite 查询只能查固定表和固定条件,远程访问只临时暴露 8000 上的 MCP 入口。这个版本不花哨,但边界清楚,适合作为团队内部工具的起点。
- 本地工具先收权限:目录白名单、文件后缀过滤、SQLite 只读连接和参数化查询都要放在服务端。
- 联调入口短时开放:用 cpolar 暴露 MCP HTTP 端口即可,不要顺手暴露数据库、SSH 或整个开发机。
- 调试结束要回收:关闭 cpolar 隧道、轮换演示 token,必要时把测试库和测试目录删掉。
后面要扩展也很自然:可以继续加只读日志检索、只读接口状态查询、固定报表生成等工具。我的建议是每次只加一个工具,每个工具都写清楚输入、输出和权限边界;MCP 真正好用的地方,恰恰是把能力做小、做准、做安全。

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐
 3
3 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)