1 小时极速体验 AMD 云环境模型微调 #Datawhale #AMDev
#Datawhale、#AMDev
在 本节学习内容 中,你将晋升为“AI 训练师”!
你将把一个只会 通用聊天 的模型,通过特定领域的数据训练成能够精准识别 6 种人类情绪 的“情感分析专家” 。这个把通用模型改造成特定领域专家的过程,就叫 模型微调(Fine-Tuning) 。
真实的 AI 微调涉及复杂的代码、环境配置和硬件调优,即便是计算机专业的同学也可能被各种报错劝退。
为了让你专注于 理解微调核心逻辑 ,我们已经将所有复杂操作打包优化,准备了“一键顺滑运行”的实验报告(Notebook)。
虽然是“一键运行”,但它绝非花哨玩具,它对你未来独立做 AI 项目非常有价值:
它是标准的工业级微调模板 :从 下载模型 → 清洗数据 → 显卡配置 → LoRA 轻量化训练 → 训练效果对比 ,完整呈现 AI 工业标准流程。未来你换数据集或大模型,都可复用这一核心框架。
跑通即赚到(极速避坑指南) :脚本已兼容 AMD GPU 环境。今天顺利跑通,意味着你掌握了在AMD 算力平台上部署和训练大模型的第一手实战经验,这在当前算力多元化的时代是非常吃香的技术背景!
接下来,请跟随指南,开启你的第一次大模型微调之旅吧!👇
我们使用的云环境就像"酒店的房间"。一旦你 关闭并重启了云环境 ,系统就会像保洁阿姨一样,把房间的桌椅摆设(运行环境)默默"复原"成最初的状态。
🎁 你的"财产"很安全 :之前辛苦下载的 Gemma 4 模型文件原封不动还在,无需重新下载 !
🔧 但"工具"需要重装 :任务二里安装的那些环境依赖(如 vLLM 等"工具插件")会被清空,需要重新快速配置一下。
首先,把云环境里自带的、不兼容的旧版组件卸载掉(别担心,后面的自动化脚本会帮你把配套的最新版自动装回来)
uv pip uninstall torchvision torchaudio
💡 避坑指南:释放显存(非常重要!)
在点击运行之前,请务必检查: 如果你刚才在“任务二”中启动了 vLLM 对话服务 ,请先回到那个终端窗口,停止它( Mac电脑: 按 Control+C ;Windows电脑: 按 Ctrl +C ) 。
为什么要这么做? 显卡的 显存(VRAM) 就像厨房的灶台空间。刚才的对话服务已经占满了整个灶台,如果不把它关掉,“微调”这个新任务就没有地方起锅烧油了,会导致“显存不足”而报错。
⚠️ 特别注意:千万不要直接点“叉”关掉终端! 在 Jupyter Lab 里面,点右上角的 X 关掉终端,只是把这个窗口隐藏到了后台,里面的程序依然在疯狂运行、死死霸占着显存! 这就好比你把厨房门关上了,但里面火还没灭呢。所以一定要用 Ctrl + C 亲手把程序结束掉。
(如果你不小心已经把终端叉掉了,别慌,赶紧往后翻到【常见问题排查】部分,有救砖教程!)
- 确认模型微调成功
执行云服务器上的 gemma4_emotion_lora_modelscope_single_gpu.ipynb文件。

运行成功后,你会看到类似这样的对比表,代表模型微调成功
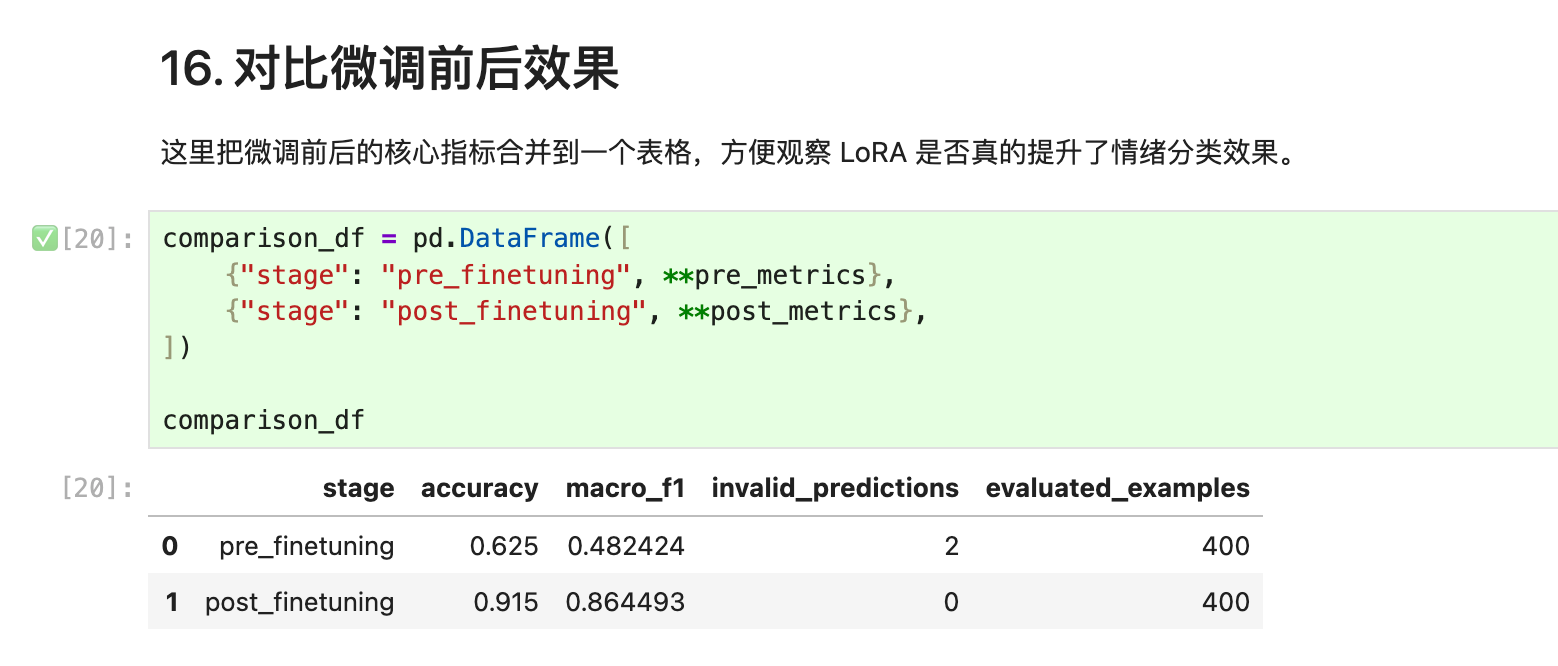
Gemma4 进行情绪分类任务的准确率(accuracy)从0.625升到0.915,无效预测结果从2个降低为0。
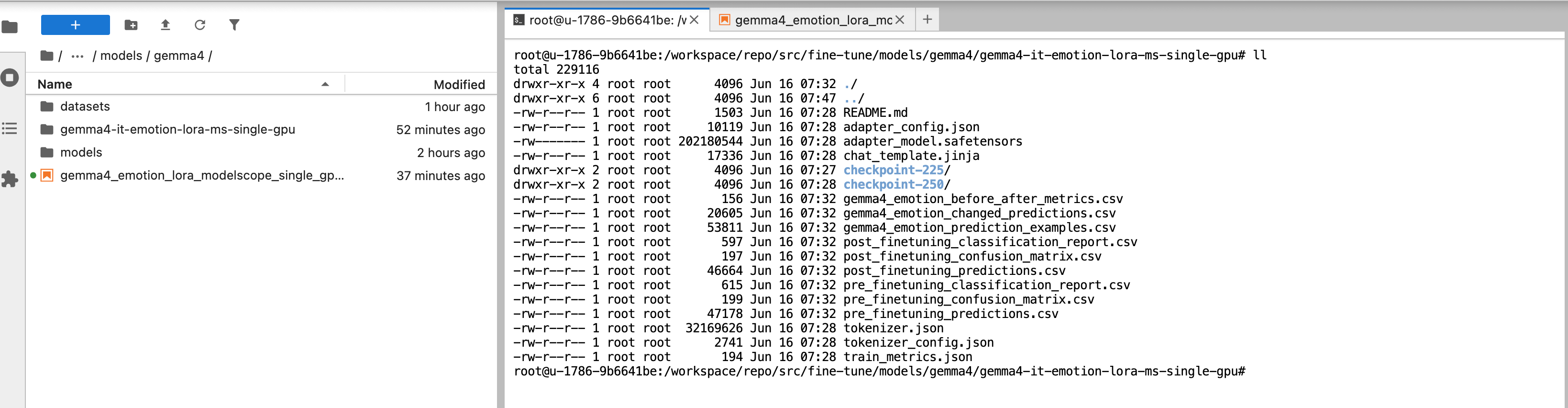
上面这些常用的结果文件,都存放在同一个目录里:
./gemma4-it-emotion-lora-ms-single-gpu
- 跑完后你应该得到什么
跑完整个 Notebook,相当于你已经独立完成了一次完整的模型微调。具体来说,你手上会多出这样几样成果:
一个保存好的 LoRA adapter 目录 ——这就是你这次训练的核心产物,模型新学到的"情绪识别本领"都浓缩在这里。
一张微调前后的指标对比表 ——把训练前、训练后的成绩并排放在一起,让你一眼看出微调到底有没有效果。
几个 CSV 结果文件 ——保存了详细的评估数据,方便你之后写实验报告时引用。
一个微调后的模型 ——它现在能读懂一句英文,并给出对应的情绪标签,从"通用聊天模型"变成了"情绪分类专家"。
- 🚨 运行环境与安装的库
建议: 用 requirements.txt 或 Dockerfile 保存环境配置,随时可以重建。 - 🛠️ 关机前的“安全撤退”两步走
把核心成果下载到本地(最重要!) — 代码、训练过程和结果
【科普卡片】一文读懂"微调"
- 微调是什么?
模型的本事,藏在它内部那几十亿个参数(数字)里;而所谓"训练",就是反复调整这些数字,让它表现越来越好。
微调(Fine-tuning),就是在别人已经训练好的模型基础上,用你自己的一小批专门数据,再训练一轮,把它往你要的方向调。
它和模型最初的训练,其实是同一件事(都是"猜答案 → 对照正确答案 → 调参数"),区别只有两点:
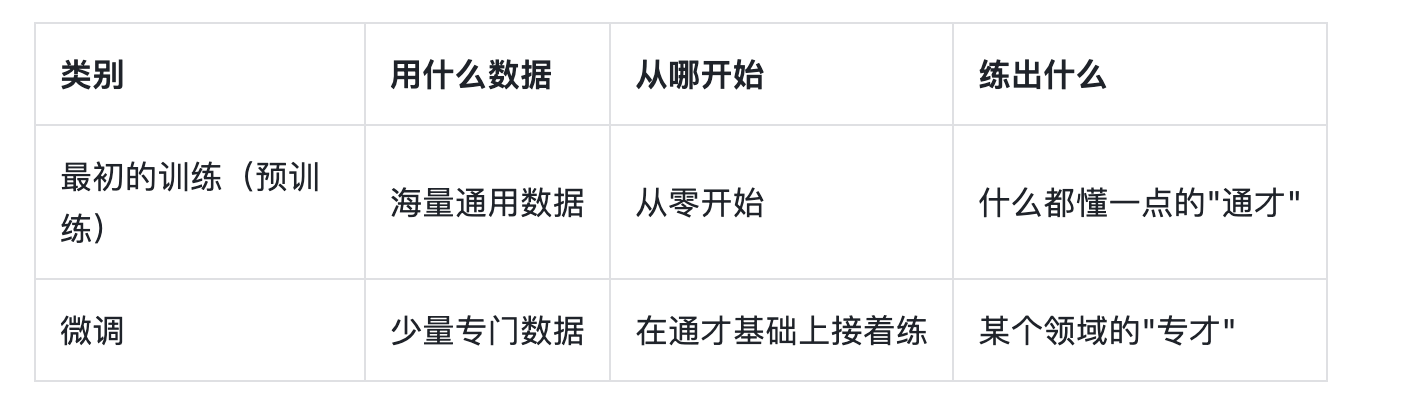
本节学习内容做的就是微调:把通用的 Gemma 4,喂给它一批"一句话 → 对应情绪"的数据,调成一个专门判断情绪的模型。你看到准确率从 0.625 升到 0.915,就是这堆参数真的被调对了的证据。
💡 一句话理解:微调 = 用你的数据,把一个"通才"模型调成你需要的"专才",改的是模型参数本身。
- 为什么要用微调?它能解决什么
通用大模型什么都会一点,但放到你的具体场景里, 常常"不够专、不够稳"。 微调就是来补这个的,它最擅长解决三类问题:
让输出格式固定 :比如本教程,要它读完一句话只回一个情绪词,不啰嗦、不跑题。
让风格 / 语气统一 :比如始终用客服的口吻、按公司模板来回答。
让某个垂直领域更准 :在医疗、法律、某种小语种等专门领域,比通用模型表现更好。
有人会问:那我直接用提示词(prompt)告诉它"请只回情绪词"不行吗?——临时用可以,但遇到 大量、重复、要求稳定 的任务,微调比每次写提示词更可靠、更省事,效果也更好。
微调的真实威力,看下例子就懂:耶鲁大学用微调后的 Gemma 4 探索癌症治疗的新方向;保加利亚的团队把它微调成了"保加利亚语优先"的大模型 BgGPT。 同一个通用模型,喂不同的专门数据,就能变成不同领域的专家 ——这就是微调的价值所在。
- 顺便搞懂几个关键词!
1️⃣ 数据集(模型的"教材") 微调效果好不好,数据是头号关键。数据集就是你喂给模型的"教材"。本教程的教材,是一条条"英文句子 + 它对应的情绪标签",情绪一共 6 类:悲伤 / 喜悦 / 爱 / 愤怒 / 恐惧 / 惊讶。教材越贴合任务、质量越高,微调出来越好(质量往往比数量更重要)。
2️⃣ LoRA(省显存的微调办法)
全量微调要把大模型的几十亿参数全部重调,单张显卡根本扛不住。LoRA 换了个聪明办法:把原来的大模型参数全"冻住"不动,只额外加一小撮新参数来训练,所以单卡一小时就能跑完。
它的产物不是一个完整的新模型,而是那一小撮参数,专业上叫 adapter(适配器) 。
敲黑板 :平时使用时,我们可以把“原模型 + adapter”一起加载; 但实际上,这个 adapter 是可以直接“融合(Merge)”到原模型里的! 融合之后就变成了一个纯净、完整的新模型,以后直接加载这一个就行,不需要每次都费事带上这个“补丁包”一起加载了。
3️⃣ epoch(训练轮数)
把整套教材完整学一遍,叫一个 epoch(一轮)。
本教程为了让你快速跑通,只训练了 1 轮,所以提升有限是正常的——这一阶段的目标是先把流程走通,而不是冲最高分。
危险警告 :想要更好的效果,之后可以加大数据、多训几轮。 但 epoch 绝不是设置得越高越好!如果轮数太高,模型就会变成“死记硬背”的呆子(专业叫“过拟合 / Overfitting”) ——它把教材里的每一句话都背得滚瓜烂熟,但在现实中遇到没见过的新句子时,反而考试交白卷。
4️⃣ 评估指标(怎么判断有没有效果) 怎么知道微调到底有没有用?靠"微调前 vs 微调后"的成绩对比。主要看三个:
准确率(accuracy) :答对的比例,越高越好。
F1 :综合各类情绪表现的得分,越高越好。
无效预测(invalid predictions) :模型答非所问、没给出 6 个标签之一的次数,越低越好。
- 读懂本节任务:Notebook 一键跑,背后到底做了什么
💡
本节任务你只点了一下"运行全部",但背后 Notebook 替你自动跑了一整套标准流程。跑完回头看一遍,能真正搞懂"微调"长什么样。整套流程其实就 8 步: 安装依赖、检查 GPU、下载模型和数据集、改造数据格式、微调前评估、LoRA 微调、保存结果、微调后评估 。
(1)装工具:先把训练要用的工具库装好(下载模型、读数据、跑 LoRA 都靠它们)
Notebook 会先安装一批训练用得到的工具库,比如 transformers 、 datasets 、 trl 、 peft 、 modelscope 。
你不用记住每个库具体是做什么的,只要知道:它们分别负责 下载模型、读取数据、加载大模型、执行 LoRA 微调 这几件事,相当于开工前先把工具都备齐。
(2)查显卡:确认 GPU 能用——和任务三第一步一个道理,地基先确认
训练大模型需要显卡(GPU)来出力,所以代码会先确认显卡是否就位:
torch.cuda.is_available()
这里有个容易误会的点:在 AMD 显卡的 ROCm 环境里,这行代码依然写着 cuda 。 cuda 本来是 NVIDIA 的叫法,PyTorch 沿用了这个老名字,所以 看到 cuda 不代表你在用 NVIDIA 显卡 ,不用担心。
只要这行返回 True ,并且后面打印出来的设备信息里能看到 AMD GPU 的名字,就说明显卡已经准备好了,可以继续。
(3)下模型和数据:把要微调的 Gemma 4(学生)和情绪数据集(教材)都拿到本地
这一步会下载两样东西:要微调的 Gemma 4 模型 (相当于待培训的"学生"),以及一份 情绪分类数据集 (相当于"教材")。
数据集里每一条样本,大致是"一句话配一个情绪答案"的形式:
一句英文句子 -> 一个情绪标签
情绪标签一共有 6 类:
sadness / joy / love / anger / fear / surprise
(悲伤 / 喜悦 / 爱 / 愤怒 / 恐惧 / 惊讶)
也就是说,我们要教会模型:读完一句话,从这 6 类里挑出正确的情绪。
(4)改数据格式:把"句子 → 情绪"的原始数据,改写成 Gemma 4 习惯的"一问一答"聊天格式,让它学会"看到一句话,就直接回一个情绪词"
Gemma 4 是一个"聊天型"模型,它习惯的是"一问一答"的对话格式。所以 Notebook 会把原始的分类数据,改写成这样一问一答的形式:
用户:判断这句话的情绪
助手:joy
经过这样改造,模型学到的就是一个明确的习惯: 看到一句话,就直接回一个情绪标签 ,不多说别的。
(5)微调前先考一次:用还没训练的模型先测一遍,记下"原始成绩"留作对照——否则训练完你说不清到底有没有进步
正式训练之前,代码会先用没训练过的模型测一遍,记下一个"原始成绩"。这是为了留个对照——否则训练完之后,你根本说不清模型到底有没有进步。
主要看三个指标:
(6)LoRA 微调:核心步骤——冻住原参数,只训练那一小撮新参数
这是整个流程的核心。LoRA 的思路是: 不去动整个庞大的模型,只额外训练一小部分新增的参数 。
打个比方,与其把整本书重写一遍,不如只在关键处贴上批注。这样做的好处是 省显存、训练快 ,特别适合教程里这种只有单张显卡的云环境。
(7)保存成果:把训练出来的 adapter 存下来
训练完成后,Notebook 会把成果保存到这个目录:
./gemma4-it-emotion-lora-ms-single-gpu
需要注意:这里保存的 不是完整的 Gemma 4 模型,而是那一小部分训练出来的 LoRA adapter (可以理解为"外挂的批注")。所以以后想再用它,需要把 原始的基础模型 也带上 。
(8)微调后再考一次:用训练好的模型再测一遍,和第 5 步的成绩并排对比
最后,代码会用训练好的模型再测一遍,并把它和第 5 步的原始成绩放在一起对比。
你只需要关注一件事: post_finetuning (微调后)的成绩,是不是比 pre_finetuning (微调前)更好 。
如果提升不太明显,也不一定是代码出了问题。本教程为了让大家先快速跑通,默认只用了少量数据、只训练了 1 轮(1 个 epoch)。 这一阶段的目标是把整个流程走通,而不是追求最高的分数。
你最终看到的那张对比表(0.625 → 0.915),就是第 5 步和第 8 步两次"考试成绩"放在一起的结果。
5. 你可以用AMD 云服务器微调什么?
AMD 云服务器吗不是只能跑完这一遍情绪分类就闲置了。你这次走通的流程是 通用的 ——同一台机器、同一套流程, 换上你自己的数据集 ,就能微调出各种不一样的模型。
这台机器(单张显卡 + LoRA)最适合下面这类 轻量、专门、目标明确 的场景,给你找找灵感:
1️⃣ 换个"分类"任务(最容易上手) 和本教程几乎一模一样,只要把数据换成别的"一句话 → 一个标签":评论好评/差评、垃圾信息识别、新闻分类、用户意图识别……改数据集就行,最稳的练手选择。
数据长这样: “这家店服务太差了” → 差评
2️⃣ 教它固定的"输出格式" 喂"输入 → 想要的格式",让它稳定地按格式产出:把杂乱的话抽成结构化信息(姓名、时间、地点)、把口语句子改写成正式的邮件/工单。
数据长这样: “老王明天下午三点来开会” → {姓名:老王, 时间:明天15:00}
3️⃣ 调出特定的"语气/人设" 喂一批某种风格的对话,让它说话带上你要的味道:某品牌口吻的客服助手、某种文风的文案/标题生成器。
4️⃣ 让它更懂某个"垂直领域" 喂某领域的问答数据,把通才调成小专家:某门课、某款产品、某个游戏的答疑助手,或某行业的术语、黑话理解。
怎么用? 步骤和任务四一样,就三步:① 准备好你自己的数据集(整理成"一问一答"的格式)→ ② 在这台云服务器上,把 notebook 里加载数据的那部分换成你的数据 → ③ 点运行,等它跑完。
提个醒:这台机器配单卡小模型(像 E4B),强项是把通才"在某件事上调得更专、更稳",不适合从头造一个无所不能的大助手。先从"换个分类数据集"起步,跑顺了再挑战更花的玩法。
四、常见问题排查:Jupyter提示显存不足(OutOfMemoryError)怎么办?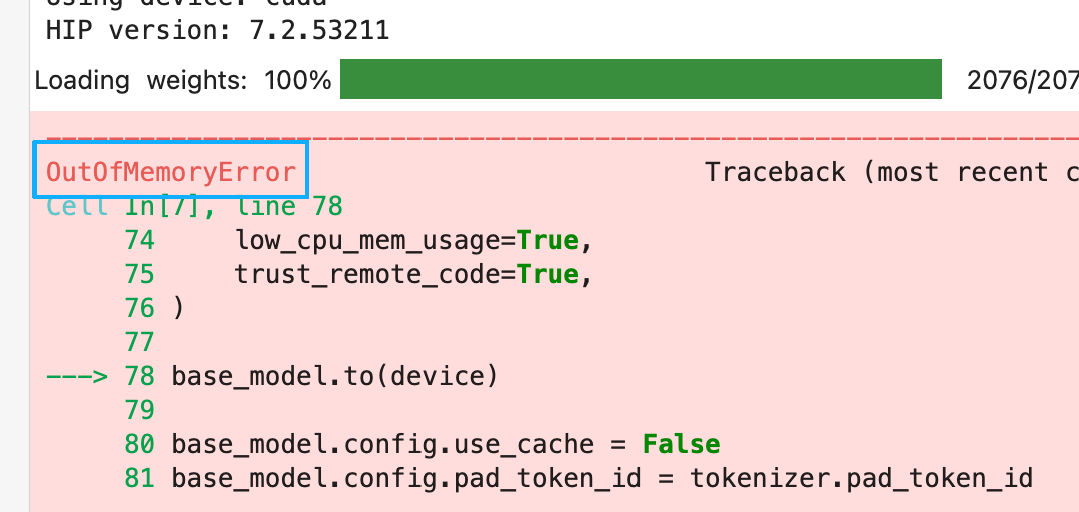
遇到这个请检查,前面步骤中vLLM是否正确关闭
请注意,在网页中叉掉终端页面只是隐藏这个终端,终端中的vLLM还会继续运行占用显存
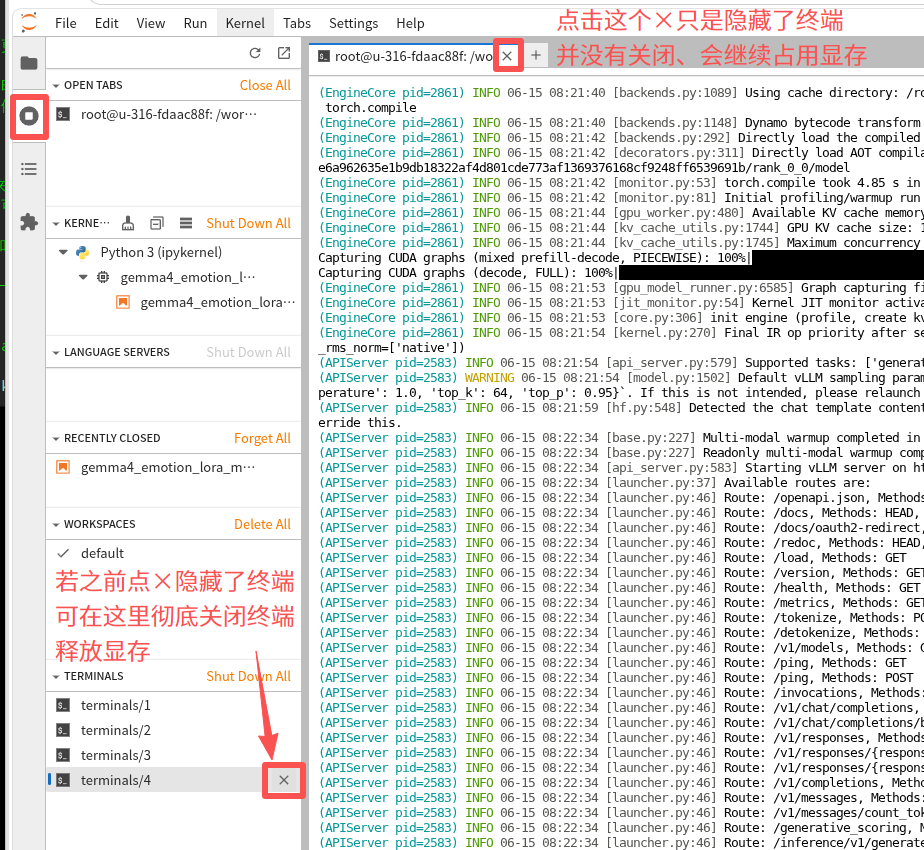
可以按下图指示,找到被隐藏的vLLM终端并关闭,如不确定具体是哪个终端可都关掉。

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐

 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)