Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
学习低成本硬件的细粒度双手操作
这也是是具身领域的经典硬件aloha和经典算法act的提出论文。也是遥操在具身里应用的开山之作(据我所知)。
“我们展示了一种低成本系统,直接通过定制远程操作界面收集的真实演示进行端到端的模仿学习。”即ACT
“为应对这些挑战,我们开发了一种简单但新颖的算法——动作分块变换器(Action Chunking with Transformers,ACT)算法,它通过对动作序列学习生成模型。”
“因此,我们构建了一个低成本但灵活的远程操作系统用于数据收集,以及一种能够有效从演示中学习的新型模仿学习算法。我们将在接下来的两段中概述每个组成部分。远程操作系统。我们设计了一套远程操作装置,配备两套低成本、现成的机器人手臂。它们是彼此的近似缩放版本,我们使用关节空间映射实现遥控操作。我们通过3D打印组件补充这一配置,方便回驱,打造出一个功能强大的远程操作系统,预算仅为2万美元。”
“模仿学习算法。需要精确和视觉反馈的任务,即使有高质量的演示,也对模仿学习构成了重大挑战。预测动作中的小误差可能导致状态差异巨大,加剧模仿学习中的“复合误差”问题[47, 64, 29]。为此,我们从心理学中的“行动分块”(action chunking)中汲取灵感,该概念描述了一系列动作如何被分组为一个整体,并作为一个整体执行[35]。在我们的案例中,策略预测的是接下来k个时间步的目标联合位置,而不仅仅是一步步。这通过k折减少任务的有效视野,减少了复合误差。预测动作序列还有助于解决时间相关的混杂因素[61],例如演示中的暂停,这些情况难以用马尔可夫单步策略来建模。为了进一步提升策略的平滑性,我们提出了时间汇合,即更频繁地查询策略并在重叠动作块间进行平均值。我们采用Transformers[65]实现动作分块策略,这是一种为序列建模设计的架构,并将其训练为条件VAE(CVAE)[55, 33],以捕捉人类数据的变异性。我们将该方法命名为“带变换器的动作分块(ACT),发现其在一系列模拟和现实精细操作任务中显著优于以往的模仿学习算法。”
解读:在算法层面,有两个操作,即动作分块和时间汇合
“纠正复合错误。BC(行为克隆)的一个主要缺点是叠加错误,即前一时间步的误差累积,导致机器人偏离训练分布,导致难以恢复的状态[47, 64]。这个问题在细微操作设置中尤为明显[29]。减少复利错误的一种方法是允许额外的策略内交互和专家纠正,如DAgger [47](这有空可以去读读,据说这是pi的RECAP的灵感来源)及其变体[30, 40, 24]。”
“我们使用同一公司制造的小型机器人WidowX的直接关节空间映射,成本为3300美元[2]。用户通过反向驱动较小的WidowX(“领导者”)进行远程操作,其关节与较大的ViperX(“跟随者”)同步。”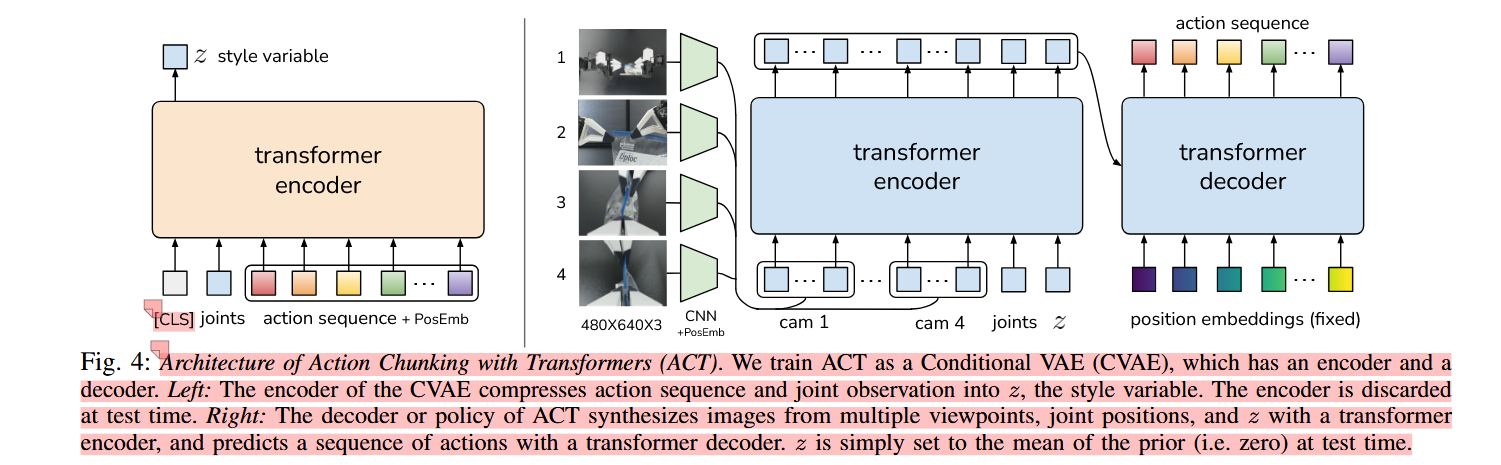
解读:
-
首先,这里先弄懂:VAE 是什么?
再首先,得要弄懂普通 autoencoder 是:
输入 x -> encoder -> 压缩表示 z -> decoder -> 重建 x
比如输入一张人脸,encoder 压成一个向量 z,decoder 再从 z 还原人脸。
VAE 也是 autoencoder,但它不把 z 当成一个确定向量,而是当成一个概率分布:
encoder: x -> z 的均值 μ 和方差 σ
从这个分布里采样 z
decoder: z -> 重建 x
训练时有两个目标:
-
重建得像:decoder(z) 要接近原始 x
-
z 的分布不要乱跑:希望 z 接近标准正态分布 N(0, I)
第二项通常是 KL loss。直觉上就是:不要让 encoder 随便发明一套混乱的暗号,要让 latent space 规整一点。
-
-
CVAE 是什么?
CVAE = Conditional VAE,条件 VAE。
普通 VAE 学的是:
生成 x
CVAE 学的是:
在条件 c 下,生成 x
比如:
条件 c = “当前机器人看到的图像和关节位置”
要生成的 x = “未来 k 步动作”
所以 ACT 里的 CVAE 是:
encoder: 未来真实动作片段 + 当前关节观测 -> z
decoder/policy: 当前图像 + 当前关节位置 + z -> 预测未来 k 步动作
这里 z 被叫做 style variable,意思是“同一个当前状态下,人可能用不同方式完成任务”。例如同样是把电池插进去,有人路径偏左一点,有人偏右一点,有人先停一下再
插。z 用来表示这些动作风格/模式差异。
-
所以,“z is set to the mean of the prior, i.e. zero” 是什么意思?
ACT 里假设 latent prior 是标准正态分布:
p(z) = N(0, I)
标准正态分布的均值就是全零向量:
mean(p(z)) = 0
所以测试时他们直接设置:
z = 0
这不是说模型“算出来 z 就是 0”,而是说:测试时没有未来真实动作,不能跑 encoder,所以手动选择 prior 里最典型、最中心的那个 latent 值,也就是 0。
为什么不随机采样一个 z ~ N(0, I)?
可以,但机器人控制通常希望稳定、可复现。如果每次随机采样,动作风格会变,可能更不稳定。所以论文选择确定性解码:固定 z=0。论文算法 2 里也写了 inference 时用 z=0。
-
所以,有一个非常自然的问题:训练时 action sequence 输入 encoder,这不会泄露答案吗?
这是你问到的关键点。短答案:训练时 encoder 看见真实动作,不算测试泄露,因为 encoder 只在训练时用,测试时被丢掉。 但你的担心是对的:如果处理不好,确实可能
出现 train-test mismatch。
训练时流程是:
真实动作片段 a_{t:t+k} -> encoder -> z
当前观测 o_t + z -> decoder -> 预测动作片段
预测动作片段 和 真实动作片段 做 MSE loss
看起来像 encoder 把答案偷偷告诉 decoder。VAE/CVAE 里这是允许的,因为 encoder 的角色不是最终 policy,而是训练 decoder 的辅助工具:它帮助 decoder 学到“在当
前观测下,可能有哪些动作模式”。
但是为了防止 z 变成“答案压缩包”,VAE 加了 KL 正则:
D_KL(q(z | action, obs) || N(0, I))
也就是强迫 encoder 输出的 z 分布接近标准正态。论文还用了一个系数 β 控制这个约束,β 越大,z 能携带的信息越少。论文也明确说:更高的 β 会让更少信息通过 z
传递。
所以:
不是:训练时拿未来动作作弊,测试时也拿未来动作。
而是:训练时用未来动作学习一个规整的潜变量空间,测试时用默认 z=0 走一个典型动作模式。
可以把 ACT 里的 CVAE 理解成:
> 训练时:用“当前看到的东西 + 未来真实动作片段”学习一个隐变量 z,让模型知道这段动作属于哪种“风格/模式”。
> 测试时:未来动作不知道,所以不能再用 encoder,只给 decoder 一个默认的 z=0,让它输出一个稳定的、典型的动作片段。
论文里也明确说了:ACT 训练时预测未来动作序列;encoder 输入动作序列和当前观测,decoder/policy 输入当前观测和 z 来预测动作序列;测试时 encoder 被丢弃,并令 z=0。
图5:我们在应用动作时同时使用动作分块和时间集合,而不是交错观察和执行。
具身领域遥操的开山之出(据我所知):
“我们记录领导机器人的关节位置(即来自人类操作员的输入),并将其作为动作即action使用。使用引头接头位置而非跟随接头位置非常重要,因为施加的力的大小隐含由它们之间的差值决定,通过低级别PID控制器实现。观测数据包括跟随机器人当前关节位置(也就是state,joint)和4台相机的图像流。接下来,我们训练ACT根据当前观测预测未来行动的顺序。这里的动作对应于下一个时间步中两臂的目标关节位置(同上面的action)。”
下面解说了图4中的position embeddings (fixed)(位置嵌入(混合))是什么
“该政策首先使用ResNet18骨干处理图像[22],该骨干链将480×640×3张RGB图像转换为15×20×512张特征图。然后沿空间维度展开,得到300×512的序列。为了保持空间信息,我们在特征序列中添加了二维正弦波位置嵌入[8]。对所有4张图像重复此操作,特征序列尺寸为1200×512维(位置嵌入,加上2就是混合了)。”
解读:position embeddings是Transformer 用的“位置标签”,告诉模型每个 token 对应图像里的哪个空间位置,或者动作序列里的第几个时间步。
下述讲解了系统框图里的CLS是什么和CLS与其他部件的组合。 ”编码器的输入包括:1)[CLS]令牌,由随机初始化的学习权重组成,2)嵌入的关节位置,即通过线性层投影到嵌入维度的关节位置,3)嵌入动作序列,即通过另一线性层投影到嵌入维度的动作序列。这些输入形成一个序列 (k + 2) × embedding_dimension,并由变压器编码器处理。我们只取第一个输出,对应于[CLS]符号,并使用另一个线性网络预测z分布的均值和方差,并将其参数化为对角高斯分布。通过重参数化获得 z 的样本,这是一种允许在采样过程中反向传播的标准方法,从而实现编码器和解码器的联合优化[33]。“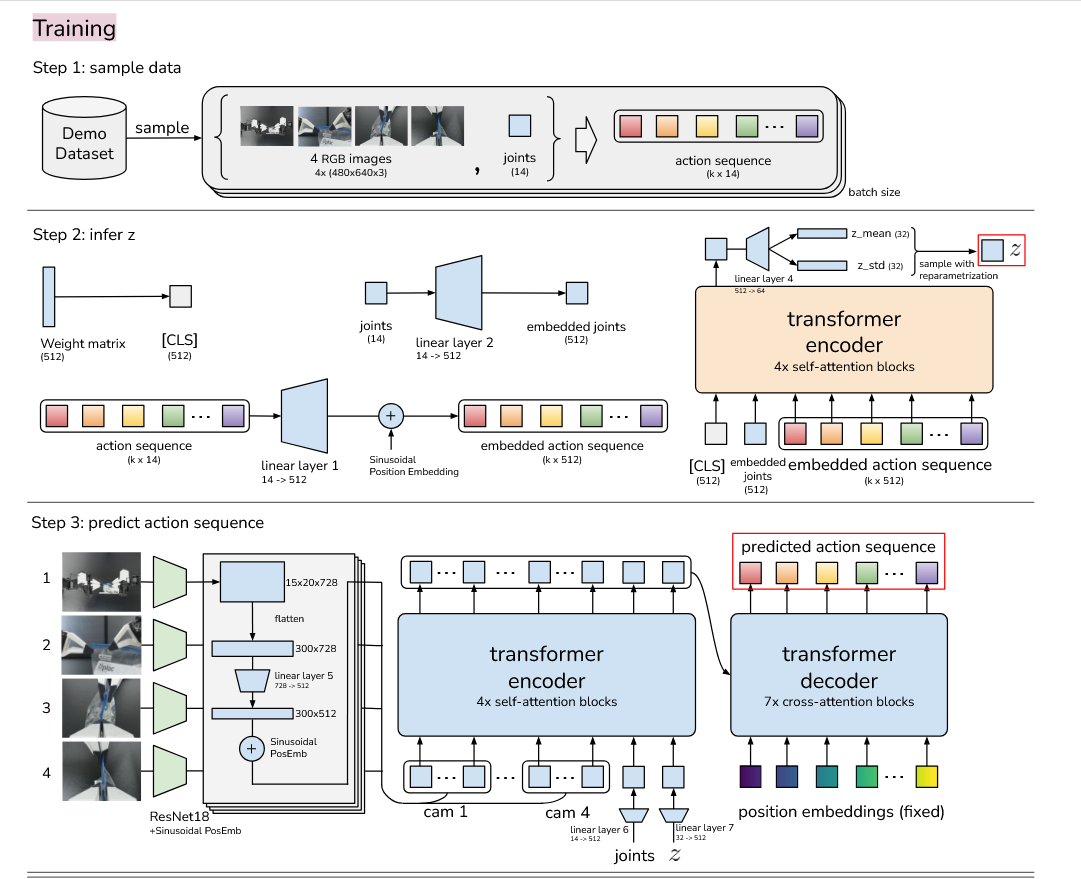

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐



 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)