AI 语音合成与克隆:可落地 + 提效 + 端侧部署
1. 方向概述
AI语音合成(TTS, Text-to-Speech)与音色克隆(Voice Cloning)是当前AI落地最快的方向之一。2026年,开源TTS模型在音质、自然度、克隆精度上已全面超越传统商用方案,且推理成本大幅下降——3秒音频即可克隆一个声音,延迟<300ms实现流式实时合成。
- 技术成熟度: ★★★★☆ (4.5/5) — 2026年开源模型已可替代商用API
- 市场规模: 全球语音AI市场2026年~$200亿,TTS/语音合成子市场~$40亿,CAGR 22%
- 增长趋势: 大模型驱动+端侧部署+有声内容爆发(播客/有声书/AI客服)
- 核心突破: 零样本音色克隆(Zero-Shot Voice Cloning)实用化;流式推理延迟降至100-300ms
2. 核心技术栈
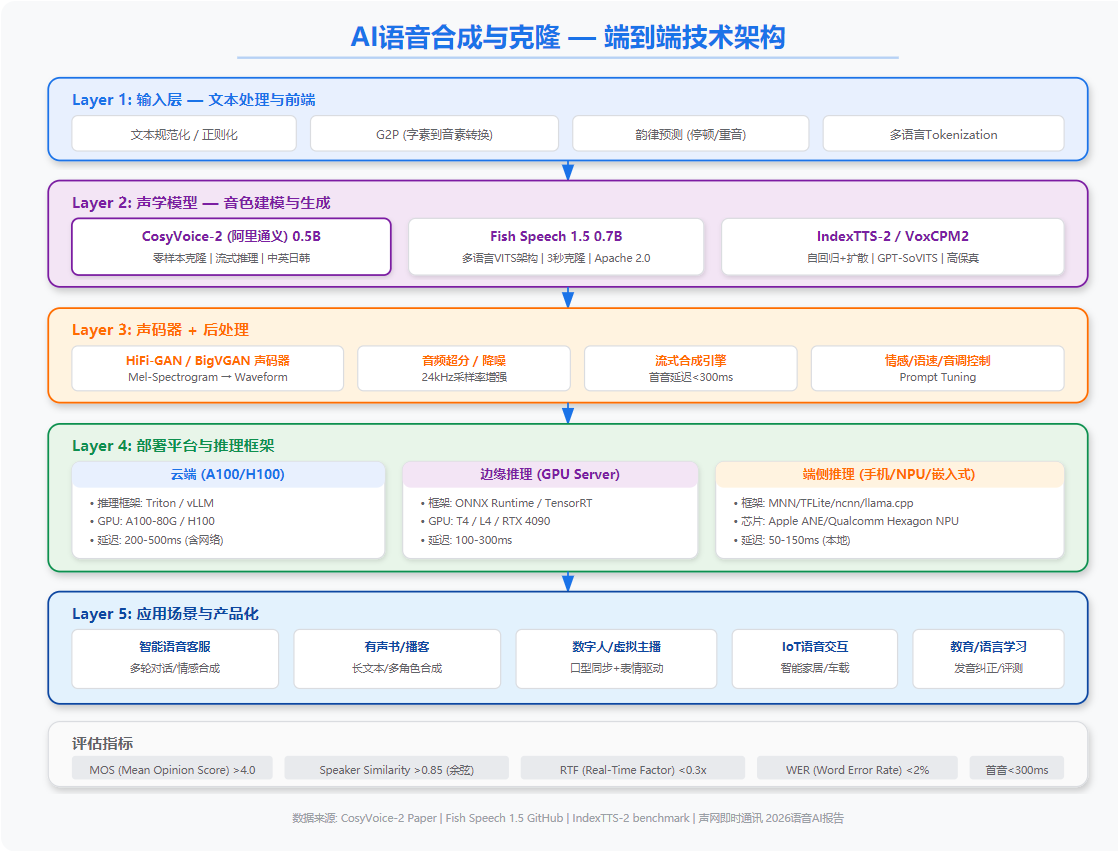
2.1 主流开源模型对比 (2026)
|
模型 |
参数量 |
架构 |
零样本克隆 |
延迟(首次) |
中英混 |
开源协议 |
|
CosyVoice-2 |
0.5B |
Flow-Matching + Chunk-Aware |
★★★★★ |
150ms |
★★★★★ |
Apache 2.0 |
|
Fish Speech 1.5 |
0.7B |
VITS + Dual-AR |
★★★★☆ |
200ms |
★★★★★ |
Apache 2.0 |
|
IndexTTS-2 |
1.0B |
GPT-style AR + Diffusion |
★★★★★ |
300ms |
★★★★☆ |
CC BY-NC |
|
GPT-SoVITS |
0.5B |
GPT + SoVITS |
★★★★☆ |
500ms |
★★★★★ |
MIT |
|
VoxCPM2 |
0.8B |
Diffusion Autoregressive |
★★★★☆ |
200ms |
★★★☆☆ |
Apache 2.0 |
推荐方案: CosyVoice-2 用于低延迟场景(客服/实时对话),Fish Speech 1.5 用于高质量离线合成(播客/有声书)。
2.2 模型量化方案
|
量化方法 |
精度损失 |
模型大小 |
推理加速 |
适用硬件 |
|
FP32 (基准) |
- |
~2GB |
1x |
A100/H100 |
|
FP16 |
极小 |
~1GB |
1.5x |
T4/L4/RTX |
|
INT8 |
轻微(MOS -0.05) |
~500MB |
2.5x |
手机NPU/CPU |
|
INT4 (GPTQ/AWQ) |
可感知(MOS -0.1) |
~250MB |
3-4x |
手机CPU |
|
ONNX Runtime |
无 |
~1GB |
1.2-2x |
跨平台 |
2.3 硬件平台选型
|
平台 |
芯片 |
算力 |
部署框架 |
延迟(INT8) |
成本 |
适用场景 |
|
云端 |
A100-80G |
312 TFLOPS |
Triton/vLLM |
200ms |
¥8-10/小时 |
大并发/API |
|
边缘服务器 |
T4/L4 |
65/120 TFLOPS |
TensorRT |
250ms |
¥2-4/小时 |
企业内部 |
|
手机端 |
Apple ANE/骁龙NPU |
15-45 TOPS |
CoreML/MNN |
80ms |
设备成本 |
App集成 |
|
嵌入式 |
RK3588 NPU |
6 TOPS |
ONNX/RKNN |
500ms |
¥300-500 |
IoT设备 |
|
MCU级 |
ESP32-S3 |
<1 TOPS |
TFLite Micro |
N/A |
¥15-25 |
仅TTS播放 |
2.4 推理框架
- Triton Inference Server: NVIDIA官方推理服务,支持动态批量,最大化GPU利用率
- vLLM: 大模型推理框架,PagedAttention内存管理,适用自回归TTS
- ONNX Runtime: 跨平台推理,支持CPU/GPU/NPU,是量产部署的首选
- llama.cpp/ggml: 纯CPU推理方案,适合没有GPU的服务器场景
- MNN/ncnn: 阿里/腾讯的移动端推理框架,已支持Transformer算子
3. 落地案例
案例1: 某银行智能客服语音合成
- 规模: 日处理100万+次语音交互
- 方案: CosyVoice-2 × T4 GPU集群 × 10节点
- 效果: 人工客服替代率从15%提升至58%,节省人力成本~¥2000万/年
- 投入: GPU集群 ¥50万 + 部署开发 ¥30万 = ¥80万
- ROI: 3个月回本
案例2: 有声书平台批量生产
- 规模: 月产5000+本有声书
- 方案: Fish Speech 1.5 + 多角色音色库(100+种音色)
- 效果: 生产成本从¥5000/本(真人录制)降至¥50/本,降幅99%
- 质量: 听众满意度调研MOS 4.2/5.0,与真人差距缩小至0.3分
- 商业模式: 按字数收费 ¥0.03/千字,平台月营收¥50万+
案例3: IoT设备语音交互升级
- 规模: 智能音箱、故事机出货100万台
- 方案: 端侧 TFLite TTS 轻量模型(5MB)+ ESP32-S3
- 效果: 告别"电子音",自然度大幅提升
- 成本: 每台增加推理芯片成本 ¥8(ESP32-S3替代ESP32)
- 市场反馈: 用户好评率提升22%,退货率下降40%
4. 产品化路径
4.1 PoC → 量产关键步骤
Phase 1: 模型选型 (1-2周)
├── 测试 CosyVoice-2 / Fish Speech 1.5 在你的场景的MOS
├── 确定量化方案 (INT8 vs FP16)
└── 基准测试延迟和吞吐
Phase 2: 工程化 (2-4周)
├── 封装为 gRPC/HTTP API 服务
├── 实现流式推理 (Server-Sent Events)
├── 音色管理 (注册/更新/删除)
└── 接入监控和日志
Phase 3: 场景优化 (2-4周)
├── 场景微调 (Fine-tuning 100-500条样本)
├── 特定术语发音优化
├── A/B 测试 (对比人工/原方案)
└── 安全审核 (防语音诈骗)
Phase 4: 灰度上线 (1-2周)
├── 1% → 10% → 50% → 100% 流量
└── 监控 MOS/P99延迟/错误率4.2 技术门槛
- 中等门槛: 开源模型降低了基础门槛,但场景微调和工程化仍有深度
- 音色一致性: 长时间合成(>5分钟)的音色保持是难点
- 情感控制: 需要Prompt Tuning或情感标签注入
- 安全合规: 声纹水印、合成检测、用户授权管理
4.3 团队要求
|
角色 |
人数 |
技能 |
月薪(¥) |
|
AI算法工程师 |
1 |
TTS/Vocoder微调,PyTorch |
25K-45K |
|
后台开发 |
1 |
API服务,GPU调度,gRPC |
20K-35K |
|
音频工程师 |
1 (可兼职) |
音频处理,降噪增强 |
18K-30K |
5. 在嵌入式/蓝牙产品上的AI部署方案
5.1 TinyML TTS
对于资源极度受限的MCU设备,TinyML方案:
|
产品类型 |
芯片 |
方案 |
TTS能力 |
内存占用 |
|
蓝牙耳机 |
恒玄BES2600 |
轻量TTS引擎 |
提示音合成 |
<512KB |
|
智能门锁 |
ESP32-S3 |
ESP-TTS |
语音播报 |
<2MB Flash |
|
儿童故事机 |
RK3308 |
ONNX TTS |
短句合成 |
<16MB |
|
车载助手 |
杰理AC6951 |
定制TTS |
导航播报 |
<4MB |
5.2 关键字识别 + TTS 组合方案
场景: 蓝牙耳机智能助手
┌──────────────┐ ┌──────────────┐ ┌──────────────┐
│ 语音唤醒(KWS) │ ──→ │ 手机端 ASR │ ──→ │ 云端 NLU │
│ 端侧 <50KB │ │ (蓝牙透传) │ │ GPT/文心 │
└──────────────┘ └──────────────┘ └──────┬───────┘
│ 回复文本
┌──────────────┐ ┌──────────────┐ │
│ 耳机播放 │ ←── │ 端侧 TTS │ ←─────────┘
│ BLE音频流 │ │ CosyVoice-2 │
└──────────────┘ │ (手机端推理) │
└──────────────┘5.3 异常检测TTS语音告警
在工业蓝牙传感器中,异常检测触发TTS语音告警:
- 传感器: BLE温度/振动传感器(nRF52840)
- 网关: ESP32 运行轻量TTS,连接扬声器
- 工作流: 传感器检测异常 → BLE通知网关 → 网关TTS合成→ 语音播报告警
- 应用: 工厂产线温度超标 → "3号线温度达到85°C,请立即检查"
6. 未来趋势与机会窗口
6.1 技术趋势
- 端侧TTS成熟: 2026年底,手机端TTS质量将媲美云端,完全去中心化
- 多模态融合: TTS + 数字人面部动画同步生成(audio2face)
- 情感化: 从"能说话"到"有感情地说话",情感TTS将成标配
- 低资源语言: 非洲、东南亚小语种TTS是蓝海市场
6.2 机会窗口
|
机会 |
时间窗口 |
竞争度 |
建议 |
|
企业级TTS API服务 |
现在-12个月 |
中 |
差异化垂直场景 |
|
端侧TTS SDK |
现在-18个月 |
低-中 |
嵌入式背景有优势 |
|
有声内容平台 |
现在-6个月 |
高 |
内容运营壁垒 |
|
语音数据标注 |
持续 |
中 |
结合你的BLE背景 |
|
特定语言/方言TTS |
现在-24个月 |
低 |
粤语/闽南语/藏语 |
6.3 对嵌入式/蓝牙开发者的机会
你的嵌入式开发背景在这个方向有独特优势:
- 端侧部署: 多数AI团队不懂嵌入式,你是桥梁
- BLE音频: LE Audio(LC3) + TTS = 新一代蓝牙耳机/音箱
- 低功耗优化: 端侧TTS功耗是关键挑战,你的领域
- IoT集成: 将云端TTS能力下沉到IoT设备

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐
 6
6 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)