LLM应用落地必读(五): 智能体的记忆——MemGPT如何实现无限上下文
在上一篇文章中(LLM应用落地必读(四):上下文管理与Claude Code的分级压缩),我们介绍了上下文管理。由于上下文窗口长度的限制,以及信息密度、冗余和干扰等因素对LLM推理性能的影响,上下文管理成为智能体开发的核心问题之一。
当智能体处理长时(Long Horizon)任务时,LLM往往会因为输入内容的膨胀而遗忘早期的重要信息。而当上下文窗口接近限制时,简单截断或丢弃早期对话,只可能让早期的关键信息更快丢失。
上一篇文章中我们介绍了Claude Code的五级压缩机制。无论是哪一级,本质上都涉及同一个核心问题:如何对上下文进行组织、存储、检索和读取。这些操作都是由智能体的Memory模块来完成的。上下文管理是目标,而Memory是其实现手段。
学术界和产业界对Memory的研究仍在快速发展。如果你希望获得一个全面的概览,推荐阅读综述论文:Memory in the Age of AI Agents: A Survey。
本文的目标是帮助大家理解Memory的功能是什么以及如何实现。为此,我们将聚焦于该领域的一项基础性工作——MemGPT,来自论文 MemGPT: Towards LLMs as Operating Systems。
之所以选择MemGPT,是因为它提出了一个至今仍被广泛引用的核心洞察:将LLM视为操作系统,将Memory划分为主上下文(Main Context) 和外部上下文(External Context)。主上下文直接输入LLM,其长度受限于上下文窗口容量,就像计算机的内存(RAM)。外部上下文可以无限扩展,其存储类比于计算机的磁盘(Disk)。主上下文和外部上下文之间,可以通过“存储”(从主上下文移出到外部上下文)和“读取”(从外部上下文加载到主上下文)进行双向移动。这一思想奠定了后续许多记忆系统的基础。
一、MemGPT介绍
1.1架构设计
MemGPT的设计灵感来自于传统的操作系统(Operating System)。在MemGPT的架构中,Memory分为
- 主上下文:主上下文的存储类似于RAM,其中包含了我在上一篇博客中提到的内容,即系统提示词(System Prompt)、工具定义(Tool Definition)、对话历史(Conversation History)、当前轨迹的工具执行结果(Tool Call Results from Current Trajectory)以及检索到的文档(Retrieved Doc)。它是LLM在推理过程中需要处理的输入,受到上下文窗口长度的限制。
- 外部上下文:外部上下文指的是存储在上下文窗口之外的任何信息。外部上下文中的内容只有被移入主上下文中才能参与LLM的推理。外部上下文的存储类似于磁盘。
- 数据移动:通过队列管理器(Queue Manager)和函数执行器(Function Executor)将主上下文和外部上下文,通过“存储”(从主上下文移出到外部上下文)和“读取”(从外部上下文加载到主上下文)进行双向移动。
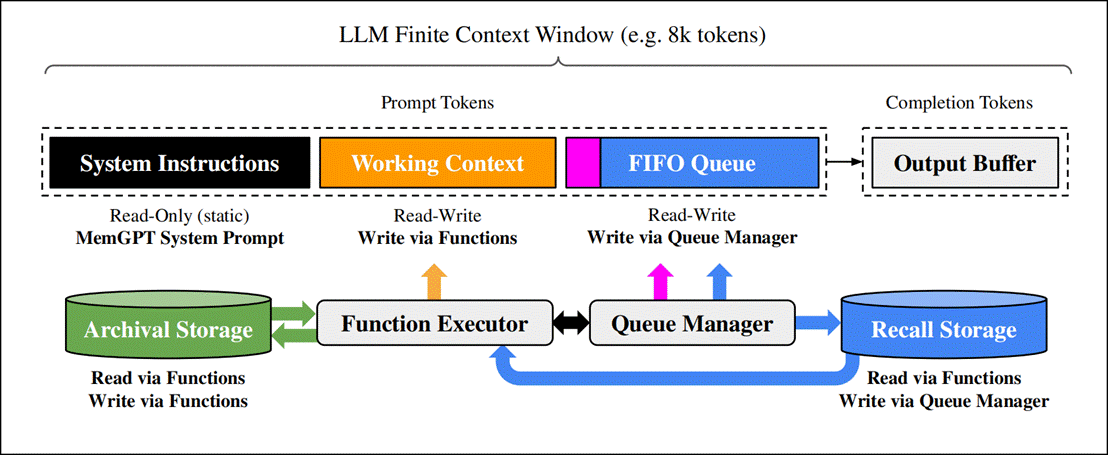
图1:MemGPT架构
1.1.1 主上下文
在memGPT中,主上下文又被分为三个连续的部分:
- 系统指令(System Instructions):系统指令是只读的,它在memGPT的运行周期内是不变的。它就是静态的系统提示词,如LLM所扮演的角色,在什么情况下需要检索外部上下文等。
- 工作上下文(Working Context):工作上下文是一个固定大小的非结构化文本块,也是系统提示词,但它是可读可写的、动态的、不断演进的。在对话场景中,它存储了关键事实,用户偏好等重要信息。随着用户和智能体之间对话的深入,工作上下文可以不断地被更新,从而让智能体加深对用户的了解。
- FIFO队列(FIFO Queue):FIFO队列用于存储滚动的对话历史递归摘要、对话历史(用户输入的问题和智能体对应的回复)、Memory警报(临时插入的系统提示词)、从外部上下文检索到的内容等。
1.1.2 外部上下文
外部上下文存储在召回数据库(Recall Storage)和归档数据库(Archival Storage)中。MemGPT将用户的输入和LLM的输出都完整地记录在召回数据库中,而将对话历史中的重要信息存储到归档数据库中。从存储的内容来看,显然召回数据库中存储的内容更适用于当前会话(Session),而归档数据库中存储的数据更适用于跨会话。
1.1.3 队列管理器
队列管理器负责FIFO队列和召回数据库中的消息管理。当智能体收到来自用户的问题时,队列管理器会将用户问题追加到FIFO队列,和系统指令、工作上下文一起输入LLM进行推理。同时,队列管理器会将用户的问题和LLM的对应输出写入召回数据库。召回数据库动态地记录了LLM输入(包括用户的问题,工具的执行结果,但不包括系统提示词,即系统指令和工作上下文)和输出,所以它完整地记录了对话历史,如果LLM需要回忆对话历史,则可以通过函数调用(Function Call)的方式从召回数据库中进行检索,并追加到FIFO队列中。
队列管理器通过队列淘汰策略控制上下文窗口的过载问题。在MemGPT中,设置了两个警告阈值,一个是Memory Pressure,另一个是Memory Flush。当上下文窗口的使用量达到Memory Pressure的阈值时,队列管理器在FIFO队列中插入Memory Pressure警报,这是一条临时的系统提示词,用于告知LLM上下文窗口即将过载,需要通过函数调用的方式将FIFO队列中的重要信息存入工作上下文或者归档数据库。当上下文窗口使用量达到Memory Flush的阈值时,队列管理器将淘汰FIFO队列中的早期对话历史,以释放部分上下文窗口空间。淘汰掉的对话历史将通过函数执行器生成递归摘要,递归摘要取代了FIFO队列中被替换掉的对话历史,继续参与LLM的推理。淘汰掉的对话历史依然保留在召回中,可以通过函数调用的方式来读取使用。
1.1.4 函数执行器
当主上下文和外部上下文之间需要进行数据传输时,LLM先生成函数调用指令,然后函数执行器执行相应的函数,即写入函数或者读取函数。通过函数执行器写入和读取的Memory包括:
- 工作上下文(函数执行器只写入):在对话场景中,它存储了关键事实,用户偏好等重要信息。如果这些信息需要被更新,LLM将做出推理,生成调用函数的指令(此函数为写入工作上下文)。函数执行器总结用户的输入,提取重要事实和用户偏好,并且和已有的事实和用户偏好进行合并,然后将结果更新到工作上下文中。
- 召回数据库(函数执行器只读):队列管理器将用户输入、工具执行结果、LLM的输出都写入了召回数据库,由此完整地记录了对话历史。如果需要回忆对话历史,LLM将做出推理,生成调用函数的指令(此函数为读取召回数据库)。函数执行器从召回数据库中检索相关信息,并将结果追加到FIFO队列中。
- 归档数据库(函数执行器可读可写):当上下文窗口的使用量达到Memory Pressure的阈值时,会触发LLM推理,生成调用函数的指令(此时函数为写入归档数据库)。函数执行器将FIFO队列中的一些重要信息写入归档数据库中。归档数据库中持久保存了一些重要信息,这些信息是可以跨会话,跨任务使用的,当需要利用这类信息时,LLM将做出推理,生成调用函数的指令(此时函数为读取归档数据库)。函数执行器从归档数据库中检索相关信息,并将结果追加到FIFO队列中。
函数执行器执行哪个函数是由LLM推理决定的。当LLM生成调用函数的指令后,MemGPT会解析这些指令,并由函数执行器执行相应的函数。当函数执行器执行了读取召回数据库和归档数据库中的数据后,执行结果会被反馈给FIFO队列,用于LLM的下一步推理和行动。在前文中我们提到当上下文窗口使用量超过一定的阈值的时候会插入Memory Pressure或者Memory Flush警报,这些警报会被用作依据提供给LLM,LLM据此决定生成函数调用指令,将重要信息写入工作上下文或者归档数据库中。
读过我的博客(LLM应用落地必读(三):从代码到原理,深入理解智能体的“工具”)应该对Function Call不会陌生,Function Call本质上就是工具调用。工具调用需要将工具定义告知LLM,MemGPT中有四个函数,即写入工作上下文函数、读取召回数据库函数,写入归档数据函数和读取召回数据库函数。这些函数的名称,使用场景和参数都写在了系统提示词里。
二、MemGPT设计思想的应用
我将MemGPT Memory的设计思想应用到了智能体天气助手中,我将之称为MemGPT天气助手。
2.1 工具设计
在MemGPT天气助手中,除了weather_report工具外还有另外1个工具,即archival_storage.retrieve,用于读取归档数据库中存储的城市天气数据。archival_storage.retrieve适用于过往会话中已被归档的城市天气,LLM生成工具调用指令时需要提供的参数为城市名称和日期。
在MemGPT天气助手中,我并没有设计用于写入工作上下文和写入归档数据库的工具,写入这两者Memory的操作不是通过函数调用,而是通过条件判断,即当检测到系统提示词中有Memory Pressure的警告时,在当前的ReAct循环结束后,就立即开始执行写入工作上下文和写入归档数据库的操作。
MemGPT天气助手中也没有读取召回数据库的操作,因为在这个简单的智能体中,当上下文窗口使用量达到Memory Flush阈值时,递归总结对话历史时并不会丢失查询过的城市天气数据,这使得从召回数据库中查找并读取城市天气数据显得没有必要。
2.2 写入召回数据库
写入召回数据库的操作由队列执行器来实施。如下内容会被写入召回数据库:
- 用户输入
- LLM在ReAct循环中的中间输出,包括调用工具的指令
- 工具的执行结果
- LLM依据工具执行结果生成的输出
- 智能体的输出(在简单的用户问题中,该输出和LLM依据工具执行结果生成的输出一样)
召回数据库的生命周期和会话一致,当会话结束,召回数据库中的内容就会被释放。召回数据库解决的是“会话内跨轮次检索”,归档数据库解决的才是“跨会话持久化”。
2.3 写入工作上下文
当上下文窗口使用量达到Memory Pressure阈值时,Memory Pressure警告被插入系统提示词中。在当前的ReAct循环结束后,智能体将调用LLM(提炼用户画像LLM),从召回数据库中的用户输入中提炼出用户的个人信息(如居住城市、职业、家庭情况、兴趣爱好等)和偏好(如喜欢的天气类型、对温度的敏感度等),结合工作上下文中的已有内容,生成新的用户画像。新的用户画像会被更新到一个User Profile的数据库中。User Profile数据库中的用户画像会作为工作上下文输入到LLM进行推理。
用这种方式刻画用户画像会使得智能体越来越了解用户。
2.4 写入归档数据库
当上下文窗口使用量达到Memory Pressure阈值时,Memory Pressure警告被插入系统提示词中。在当前的ReAct循环结束后,智能体将读取召回数据中的工具执行结果并写入归档数据库。
2.5 读取归档数据库
当用户的输入表明需要获取城市的历史天气数据时,在ReAct循环中,LLM将生成调用archival_storage.retrieve的指令。archival_storage.retrieve会从归档数据库中检索指定城市的历史天气数据,并将执行结果将反馈给LLM做下一步的推理和行动。
2.6 递归摘要
当上下文窗口使用量达到Memory Flush阈值时,Memory Flush警告被插入系统提示词中。在当前的ReAct循环结束后,智能体将调用LLM(总结对话历史LLM),将FIFO队列中的对话历史进行总结,然后用总结后的内容替换掉对话历史,以此节省上下文窗口的使用量。
三、小结
本文从智能体的“记忆”问题出发,引入MemGPT的设计思想——将LLM视为操作系统,将上下文窗口视为有限的内存,将窗口之外的信息视为无限的磁盘存储。
我们详细拆解了MemGPT的三层架构:
主上下文:系统指令、工作上下文和FIFO队列,构成LLM直接处理的输入。
外部上下文:召回数据库(会话内对话历史)和归档数据库(跨会话信息)。
数据移动:通过队列管理器和函数执行器实现主上下文与外部上下文之间的双向移动。
在此基础上,我们将MemGPT的设计思想应用到了天气助手中,通过召回数据库、工作上下文(用户画像)、归档数据库和递归摘要四个模块,验证了分层记忆架构在实践中的可行性。
MemGPT的核心启示在于:智能体的记忆不在于“记住更多”,而在于“知道什么时候记住什么、忘掉什么”。这种分级的、动态的记忆管理思路,至今仍是构建长时记忆智能体的重要范式。
四、参考文献
1. Charles Packer, Sarah Wooders, Kevin Lin. MemGPT: Towards LLMs as Operating Systems, 2023.
作者:徐宏勤
版权声明:本文为原创内容。如需转载,请务必在文章开头标注作者和来源,并保持文章完整,否则视为侵权。

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐

 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)