我把 AI 画布项目“拆到螺丝级”:Infinite Canvas 如何把 Next.js、localForage、多模型生成与本地 Agent 组装成一条可用生产线
先抛个问题:
你现在做一张图,通常要在多少个窗口来回横跳?
提示词在记事本、参考图在网盘、生成历史在聊天记录、素材在某个“临时文件夹(永远找不到)”,最后把结果拖进 PPT 再手动对齐。这套流程最大的问题,不是“慢”,而是上下文断裂:你每次创作都像失忆重启。
这篇文章聊的项目是 infinite-canvas。它不只是一个“能生图的页面”,而是把创作过程拆成可编排节点,再把 AI 生成、素材沉淀、会话上下文、跨设备同步、Agent 自动化全部塞进同一张无限画布里。
说人话:它试图把“灵感流”变成“生产流”。
我会基于项目真实代码(web/ + canvas-agent/)做一次完整拆解,重点讲清楚三件事:
-
它的技术架构到底怎么分层,为什么这么分;
-
核心实现里有哪些值得借鉴的工程决策;
-
这套设计在实际业务里能落到哪些场景,以及下一步怎么演进。
全文较长,建议先收藏再看。看完你会发现:
“无限画布”真正难的不是画布,而是状态与上下文治理。
一、项目背景:为什么不是“再做一个生图页面”?
过去两年,AI 创作工具多到像手机里的拍照 App:
一个负责文生图,一个负责图生图,一个负责视频,一个负责 prompt 优化,再加一个素材站、一个剪贴板管理器,创作者在工具之间反复搬运数据。
infinite-canvas 的核心判断很直接:
-
创作是链路,不是单点请求
一次输出通常依赖前序文本、参考图、参数试验和多轮迭代。 -
上下文比模型更重要
模型会升级,但“这个结果从哪来、为何变成这样”必须可追溯。 -
本地优先仍然有价值
对个人创作者来说,先把体验跑通,未必要先上后端大系统。
所以它把“节点 + 连线”当成创作语言:
文本节点写意图,图片/视频/音频节点放素材,配置节点定义生成参数,连线表达依赖关系。
你不是“点按钮生成”,而是在“搭工作流”。
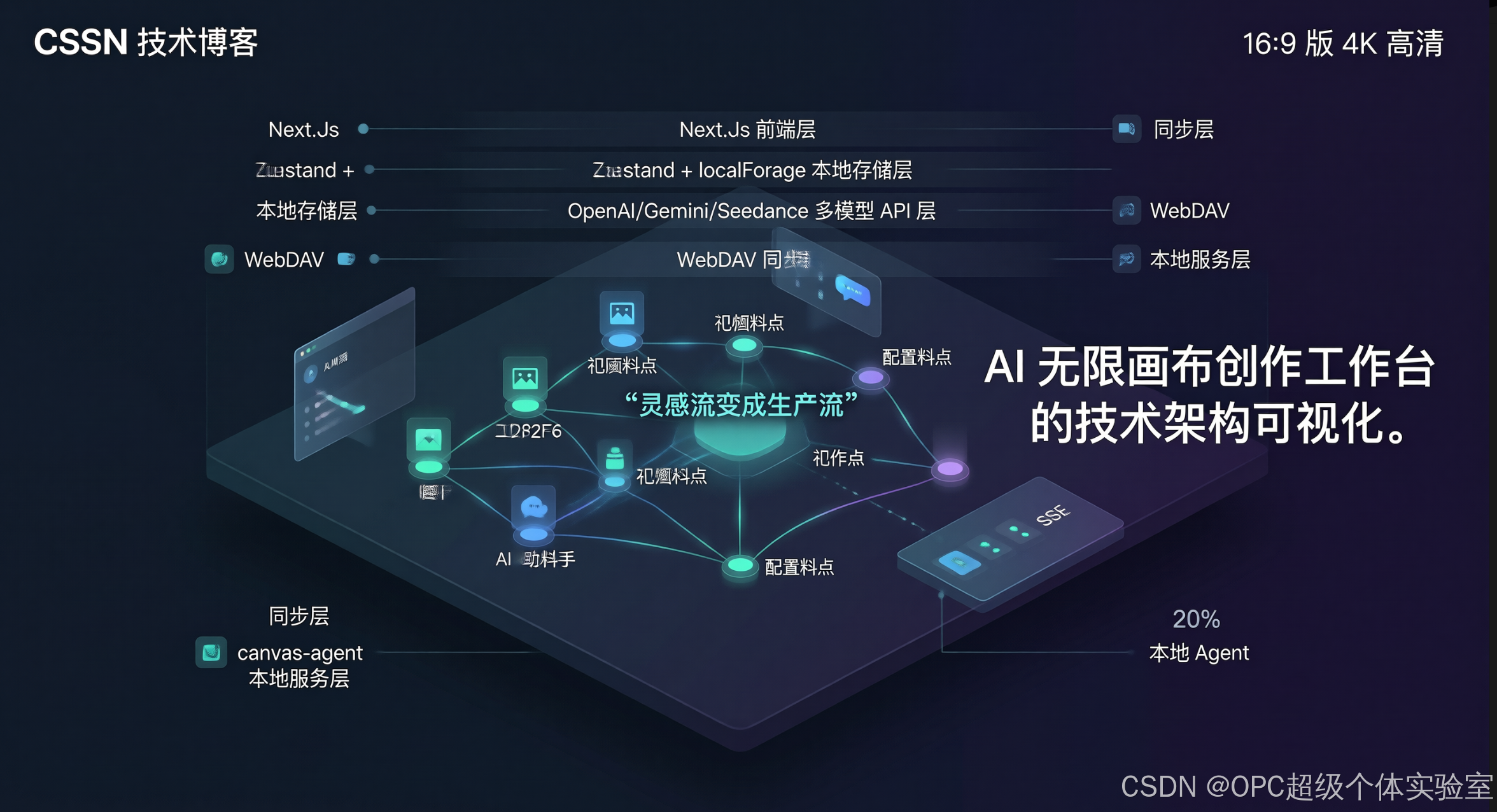
二、整体架构:这不是一个页面,而是五层协作
先给一张文字版架构图,帮助你快速定位模块:
┌────────────────────────────────────────────────────────────┐
│ 浏览器前端 (Next.js) │
│ 画布交互层: 节点/连线/缩放/历史/快捷键 │
│ 生成编排层: 文本/图像/视频/音频统一调度 │
│ 助手层: 在线 Agent + 本地 Agent 面板 │
├────────────────────────────────────────────────────────────┤
│ 本地数据层 (Zustand + localForage) │
│ 项目JSON、素材JSON、图片Blob、媒体Blob、生成日志 │
├────────────────────────────────────────────────────────────┤
│ AI 调用层 (OpenAI/Gemini/Seedance) │
│ 多渠道配置、模型能力分组、接口格式适配、流式响应处理 │
├────────────────────────────────────────────────────────────┤
│ 可选同步层 (WebDAV + Next.js Proxy) │
│ 清单合并、增量文件上传、缺失媒体补齐、跨设备迁移 │
├────────────────────────────────────────────────────────────┤
│ 本机 Agent 层 (canvas-agent + MCP + Codex) │
│ SSE事件、工具调用确认、线程管理、工作区隔离 │
└────────────────────────────────────────────────────────────┘
这套架构最妙的地方是:
在线能力和本地能力并行存在,互不强绑。
-
只想“开箱即用”:直接用网页在线 Agent(
canvas-assistant-panel.tsx) -
想让本机 Codex/Claude 深度参与:启本地
canvas-agent,走 MCP 工具链路
这比“全在线”或“全本地”的单一路径更贴近真实用户分层。
三、数据模型设计:把“创作过程”变成可序列化对象
1)项目模型:CanvasProject
项目状态由 useCanvasStore 管理,核心结构包括:
-
nodes:节点数组 -
connections:连线数组 -
chatSessions/activeChatId:助手对话上下文 -
backgroundMode/showImageInfo/viewport:界面和视图状态
也就是说,项目不是只存“画面”,而是把“聊天过程”和“工作区观感”都保存下来,回到项目时能接续上下文。
2)节点模型:CanvasNodeData
项目支持五类节点(代码真实定义):
-
text -
image -
config -
video -
audio
metadata 承担业务语义,例如:
-
生成状态:
idle/loading/success/error -
生成参数:
model/size/quality/count/... -
媒体元信息:
storageKey/mimeType/bytes/naturalWidth/... -
批量关系:
isBatchRoot/batchRootId/batchChildIds/primaryImageId
这套模型的意义在于:
节点既是 UI 元素,也是业务单元。
你可以把它当“可视化工作流 DSL”。
四、交互内核:无限画布为什么“丝滑”?
不少画布类应用失败,不是因为功能少,而是拖起来卡、撤销不准、误操作多。
这个项目在交互层做了几件很实在的事。
1)视口变换统一处理
InfiniteCanvas 组件维护 viewport = { x, y, k },所有坐标换算都通过 screenToCanvas 统一转换。
滚轮缩放采用“鼠标锚点缩放”,而不是固定中心缩放,用户体感会自然很多。
2)拖拽期间暂停历史提交
节点拖动时,代码将 historyPausedRef.current = true,结束拖拽再恢复。
这样不会在拖动过程写进几十条“半成品快照”。
3)历史系统做了“延迟合并提交”
历史不是每次 setState 都立刻压栈,而是 180ms 合并提交,最多保留 50 步(slice(-49) + 当前)。
// 精简自 canvas-client-page.tsx
if (historyCommitTimerRef.current) clearTimeout(historyCommitTimerRef.current);
historyCommitTimerRef.current = setTimeout(() => {
historyRef.current.past = [...historyRef.current.past.slice(-49), last];
historyRef.current.future = [];
lastHistoryRef.current = current;
}, 180);
这种“短窗口聚合”对交互系统很关键:
既保留撤销可用性,又避免历史膨胀。
4)复制粘贴不仅复制节点,还复制内部连线
copySelectedNodes 会把“选中集合内部的连接关系”一并写入剪贴板,pasteCopiedNodes 再通过 idMap 重建连线。
你复制的是“局部子图”,不是“孤立节点”。
5)连接拖到空白区,弹出“创建并连接”菜单
这是一个很容易被忽略但体验很强的设计。
当用户从节点拖一条连接到空白处,不是报错,而是弹菜单让你“新建文本/图片/视频/配置节点并自动连线”。
工作流搭建速度会明显提升。
五、生成引擎:统一入口,分模式执行
核心生成入口在 canvas-client-page.tsx 的 handleGenerateNode。
它不是“一个按钮调一个 API”,而是一个完整状态机:
-
读取来源节点与配置
-
构造上下文(文本、参考图、参考视频、参考音频)
-
根据模式分支:
image/video/audio/text -
按节点更新状态(loading/success/error)
-
生成成功后落地为新节点并建立连线
-
记录并管理
AbortController,支持中断
1)上下文构造:从“连接图”里抽资源
buildNodeGenerationContext + buildNodeGenerationInputs 会沿连线找上游资源。
如果是配置节点并启用了 composer,还会解析 @[node:xxx] 引用语法,把节点内容替换为标签文本,并注入对应媒体引用。
// 精简自 canvas-node-generation.ts
for (const match of prompt.matchAll(/@\[node:([^\]]+)\]/g)) {
const input = inputByNodeId.get(match[1]);
// 文本引用替换为“【文本1】”,图片/视频/音频替换为标签并进入 references
}
这一点非常像“可视化 prompt 模板引擎”,而且是和画布图结构绑定的。
2)图片批量生成:根节点 + 子节点组
当 count > 1 时,不是简单塞一个数组,而是创建:
-
一个根节点(
isBatchRoot) -
多个子节点(
batchRootId) -
根子连线
并支持:
-
折叠/展开批量结果
-
切换主图(
primaryImageId) -
失败重试保留上下文
这就是“把 AI 结果结构化”而不是“吐一堆图”。
3)文本生成也走同一逻辑
文本模式同样可以从配置节点批量生成多个文本子节点。
并且支持流式回写(requestImageQuestion 回调里持续更新节点内容),用户能看到“边生成边长字”。
4)中断机制
项目用 generationRequestsRef: Map<targetNodeId, request> 跟踪请求,stopGenerationByRunningId 会批量 abort() 同一批运行。
这比“全局一个 loading 标志位”靠谱得多,适合并发节点生成场景。
六、媒体存储策略:JSON 轻量,Blob 独立
很多类似项目把 base64 直接塞进项目 JSON,前期方便,后期灾难。
这个项目走了更稳妥的路:
-
结构化状态(项目、素材)走
localForage app_state -
图片 Blob 单独进
image_files -
视频/音频 Blob 单独进
media_files -
业务里通过
storageKey关联
uploadImage 的处理非常典型:
const storageKey = `image:${nanoid()}`;
await store.setItem(storageKey, blob);
const url = URL.createObjectURL(blob);
objectUrls.set(storageKey, url);
这个设计的好处
-
项目 JSON 更小、更容易序列化导入导出
-
大文件不反复 JSON 编码解码
-
支持按引用清理,避免误删共享媒体
-
旧数据可迁移:发现
data:image/...时自动转存 Blob 并补storageKey
清理策略也很工程化
cleanupUnusedImages/cleanupUnusedMedia 会递归扫描“项目 + 素材 + 额外上下文”里所有 storageKey,再删除未被引用的 Blob。
这是一种“引用可达性清理”,而不是“谁删节点谁删文件”的脆弱策略。
七、多模型接入:不是多写几个下拉框那么简单
配置中心 use-config-store.ts 做了一套我很认可的建模方式:
-
模型值编码为
channelId::modelName -
统一函数
resolveModelRequestConfig在请求前解析为真实baseUrl/apiKey/apiFormat/model -
能力维度分组:
imageModels/videoModels/textModels/audioModels
// 精简自 use-config-store.ts
export function resolveModelRequestConfig(config, value) {
const channel = resolveModelChannel(config, value);
return {
...config,
model: modelOptionName(value || config.model),
baseUrl: channel.baseUrl,
apiKey: channel.apiKey,
apiFormat: channel.apiFormat,
};
}
这让“同一个页面调用不同供应商”变得很顺:
-
图片:OpenAI
images/generations+ GeminigenerateContent -
文本/工具:OpenAI
responsesSSE + GeministreamGenerateContent -
视频:OpenAI 风格
videos或 Seedance 任务接口 -
音频:OpenAI
audio/speech(Gemini 通道会明确提示不支持)
另外,项目还处理了不少边角:
-
火山 Agent Plan Base URL 自动规范化(避免重复拼
/v1) -
图像尺寸支持比例转实际像素并做边界校验(长边、像素总量、16 倍数)
-
错误提示按状态码细分(401/403、429 等)
这类“脏活”才是多模型接入真正的工程成本。
八、提示词库:不是静态文档,而是可检索内容池
/api/prompts route 做了三件事:
-
抓取多个 GitHub 仓库原始内容(README、JSON、案例文件)
-
解析为统一 Prompt 结构(标题、标签、预览、来源)
-
用内存缓存 + TTL(1 小时)减少重复拉取
它还用了 loadingPrompts Promise 做并发去重:
同一时刻多个请求进来,只触发一次真实拉取。
这让“提示词库”从静态页面变成了可维护的外部知识源。
九、WebDAV 同步:可选云,不强依赖后端
本项目强调本地优先,但提供了跨设备同步能力。
关键思路是“按领域分清单”而不是搞一锅大 JSON。
同步域分成四块:
-
canvas -
assets -
image-workbench -
video-workbench
每个域各有一个 manifest.json,包含:
-
data(结构化业务数据) -
files(Blob 索引:storageKey/path/mimeType/bytes)
同步流程大致是:
-
拉远端清单
-
合并本地与远端(按
id + 时间戳) -
下载本地缺失媒体
-
上传本地新增或变更媒体
-
回写新清单
媒体传输用并发池(默认 3)控制吞吐:
// 精简自 app-sync.ts
await runWithConcurrency(tasks, 3, async ({ item, blob }) => {
await uploadWebdavFile(config, item.path, blob, item.mimeType);
});
如果 WebDAV 服务 CORS 不友好,还能切 nextjs 代理模式,走 webdav-proxy route 转发。
这个设计对 NAS 用户和自建 WebDAV 用户非常实用。
十、最有辨识度的链路:在线 Agent + 本地 Agent 双系统
这是我认为这个项目最“有产品想法”的地方。
它没有把 Agent 强行做成单一路径,而是拆成两个互补模式。
10.1 在线 Agent(网页内置)
核心在 canvas-assistant-panel.tsx:
-
预定义大量工具 schema(
canvas_create_node、canvas_generate_image、canvas_apply_ops等) -
每轮请求都把当前画布快照(精简版)和选中引用发给模型
- 工具循环分两阶段:
-
第一步
tool_choice: required,强制模型先用工具 -
后续
tool_choice: auto,自动续跑,最多 4 步(ONLINE_AGENT_MAX_STEPS)
-
如果开启“工具确认”,写操作会先进入待审批消息,再由用户批准执行。
这让在线 Agent 既有自动化能力,又能控制风险。
10.2 本地 Agent(canvas-agent)
前端面板 canvas-local-agent-panel.tsx 通过 EventSource 连接本机服务:
-
hello:连接建立 -
tool_call:请求网页执行画布工具 -
agent_event:Codex 结构化事件流 -
agent_done:一轮完成
本地模式的关键特性:
-
上传图片可作为附件传给本地 Codex(限制 6 张,约 28MB)
-
canvas_apply_ops默认二次确认,防止误改 -
可查看本地线程历史、恢复会话、删除会话
从体验上看,它把“浏览器画布”和“本机编码 Agent”连成了一个工作台。
10.3 canvas-agent 服务端:SSE + MCP + 线程工作区
canvas-agent 本身是一个 Node 服务,入口在 http-server.ts / agents.ts。
几个关键点非常值得看:
-
仅监听 127.0.0.1
默认本机可见,不做公网暴露。 -
token 鉴权 + origin 记忆
首次带 token 的 origin 会被记录,后续只允许已登记来源访问。 -
画布工具请求-回执闭环
服务端发tool_call,网页执行后POST /canvas/result回传,服务端 resolve pending promise。 -
每个画布独立 Codex 工作区
目录在~/.infinite-canvas/codex-workspaces/<canvasId>,减少线程串场。 -
Codex app-server 直连
通过@openai/codex的app-server --stdio走结构化事件流。
路由骨架如下(精简):
app.get("/events", ...); // SSE 事件通道
app.post("/canvas/state", ...); // 前端上传当前快照
app.post("/canvas/result", ...); // 前端回传工具执行结果
app.post("/api/tools", ...); // MCP/HTTP 工具调用入口
app.post("/agent/codex/turn", ...);// 发起本地 Codex 一轮
它还提供 mcp 模式:canvas-agent mcp 启动后,把同一套工具注册到 MCP,命令行 Codex/Claude 可以直接调画布工具。
这就形成了“网页助手”和“终端助手”共享工具协议的统一面。
十一、从 0 到 1 怎么用:一条最顺手的实践路径
下面这套流程,基本是我自己验证后认为最顺手的:
步骤 1:先把画布跑起来
cd web
bun install
bun run dev
打开 http://localhost:3000,右上角配置里填:
-
渠道 Base URL
-
API Key
-
文本/图片/视频/音频模型
步骤 2:搭一个“可复用生成流”
-
新建文本节点,写核心需求
-
新建配置节点,选择
generationMode -
连线文本 -> 配置
-
补充参考图节点,再连到配置节点
-
触发生成并保留结果节点与连线
这样下次改文案时,不需要重造结构,只改局部节点即可。
步骤 3:把结果沉淀进素材
把图片/视频/文本节点直接“加入我的素材”,后续在画布、工作台、提示词库联动时复用。
这个动作看似小,长期会变成你的私有内容资产库。
步骤 4(可选):接本地 Agent 提升生产效率
npx -y @basketikun/canvas-agent
复制终端输出的 Local URL 和 token,填到 Agent 面板连接。
之后你可以直接说:“把左侧三张图做成 9:16 视频流并给我三版文案”。
十二、真实应用场景:它不是只能“玩图”
场景 1:品牌海报快速迭代
-
文本节点放品牌调性和卖点
-
图片节点放产品图和风格参考
-
配置节点控制模型和比例
-
批量生成后根节点收敛主图
优点:版本关系清楚,甲方让“改回第三版字体风格”时不崩溃。
场景 2:短视频分镜草案
-
文本节点写分镜描述
-
图片节点做视觉参考
-
视频节点串联结果
-
音频节点尝试口播或背景音
优点:同一画布里把文案、画面、声音关联起来,不再跨工具拼接。
场景 3:教育内容工业化
-
一套课程模板画布复用多次
-
每个知识点替换文本节点,自动生成图文素材
-
结果批量沉淀素材库,供下一轮课程复用
优点:降低制作波动,团队协作更可复制。
场景 4:电商上新素材流水线
-
商品图做参考节点
-
文案节点输出卖点变化
-
批量生图得到主图、详情图、活动图
-
通过 WebDAV 同步给多设备或多成员查看
优点:效率提升来自流程稳定,而不仅仅是模型速度。
场景 5:一人 AI 工作室
如果你是“写文案 + 做图 + 剪视频 + 发内容”全包选手,这类项目最大的价值是把脑内切换成本降下来。
你终于可以把注意力放在“审美与表达”,不是“文件去哪了”。
十三、工程层面的几个高价值细节
这里总结几个我认为非常“可抄作业”的点:
-
状态与二进制分层存储:JSON 和 Blob 分仓,避免状态肥大。
-
历史提交合并窗口:拖拽和频繁编辑时不污染撤销栈。
-
图结构驱动上下文:生成输入来自连线关系,不靠临时参数。
-
统一工具协议:在线 Agent、本地 Agent、MCP 共享同一语义。
-
可控自动化:写操作可二次确认,防止 Agent 误伤。
-
多模型适配前置:请求前解析渠道、格式、模型能力,避免页面散落判断。
-
同步域拆分:WebDAV 清单按业务域分治,迁移和排障都轻松。
-
工作区隔离:本地 Agent 线程按画布隔离 cwd,降低跨项目污染。
-
事件流透明化:日志和诊断面板让“Agent 到底干了啥”可见可追。
-
失败可恢复:重试、取消、错误细分信息贯穿生成链路。
一句话总结:它不是“功能堆叠”,而是“边界清晰的系统拼装”。
十四、当前限制与务实建议
先说限制,这很重要:
-
项目和素材默认保存在浏览器本地,不是天然云端协作产品;
-
API Key 在浏览器本地保存,适合个人可信环境;
-
部分上游接口对本地参考媒体支持程度不一;
-
移动端触控体验还不是这个项目当前主战场。
如果你打算用于团队生产,建议优先做三件事:
-
固化“模型渠道规范”和默认参数模板;
-
打通 WebDAV 或对象存储,至少先做可追溯备份;
-
对关键画布建立命名规范(节点命名、版本命名、导出命名)。
别小看这三件基础治理,能省下大量返工。
十五、未来趋势:下一代创作工作台会长什么样?
结合这个项目的现状,我认为它最值得继续演进的方向有六个:
1)多用户实时协作(CRDT / OT)
从“个人画布”进化到“多人同步编辑”,需要真正的冲突解决与权限模型。
这一步难,但一旦做成,产品形态会从工具跃迁成平台。
2)远端媒体分层存储
本地优先可以保留,但应提供“冷热分层”:
热数据本地、冷数据对象存储,避免长期本地空间膨胀。
3)工作流模板化
把“高复用节点子图”沉淀为模板(例如广告图模板、分镜模板),让新任务一键套用,不必从空白画布开始。
4)语义检索素材库
现在素材检索主要是关键词,后续可加入向量检索,支持“找一张类似这个情绪但更明亮的图”。
5)模型能力自动协商
根据任务类型、预算、时延目标自动选择渠道与模型,不再靠人工切换。
6)Agent 编排与审计
把 Agent 工具调用转成“可回放任务清单”,并支持策略审计(哪些操作必须人工确认,哪些可自动执行)。
十六、源码级链路复盘:一次“从需求到结果”到底经历了什么?
前面讲了架构,现在我们按真实调用顺序,复盘一次常见链路。
假设用户在画布里做了这件事:
“我给你一段产品文案 + 两张参考图,帮我出 4 张风格统一的海报初稿。”
第 0 步:用户动作进入画布状态
用户把文案贴到文本节点,把两张图拖入画布变成图片节点,再新建一个配置节点并连接。
这一刻,useCanvasStore 和画布页面内部状态里已经形成了“可计算图结构”。
这很关键:
如果你只在按钮点击时临时拼参数,就无法稳定复用。
而图结构一旦形成,每次生成都是“同一流程不同输入”。
第 1 步:生成入口拿到稳定快照
handleGenerateNode 被触发时,会先基于当前节点集合和连线集合构建上下文。
这一步不是直接调接口,而是先判断:
-
目标节点是什么类型;
-
上游是否存在可用文本输入;
-
是否有图片/视频/音频参考;
-
当前模型配置是否完整;
-
是否存在进行中的同批次请求。
如果配置不齐,流程会在这里短路,并写入可读错误信息。
这比“后端 400 再兜底弹框”用户体验要好太多。
第 2 步:上下文提取与 prompt 组装
buildNodeGenerationContext 会把连线图中的输入抽成可消费结构。
如果你在配置节点里使用 @[node:xxx],则 hydrateNodeGenerationContext 会做两件事:
-
把引用替换成可读标签(方便模型理解角色);
-
把媒体引用转为实际可上传资源列表。
你可以把这层理解成“面向模型的中间表示(IR)”。
第 3 步:模式分发与供应商适配
到了 API 层,代码会根据 generationMode 进入不同 service:
-
图片走
image.ts -
视频走
video.ts -
音频走
audio.ts -
文本走问答/工具调用逻辑
同一模式内部还要根据渠道格式分支:
-
OpenAI 兼容风格;
-
Gemini 风格;
-
Seedance 任务式风格(视频)。
这里最容易写崩的是“参数矩阵爆炸”。
项目的做法是尽量把“通用参数”前置归一化,再在最后一跳做供应商映射,降低分支复杂度。
第 4 步:流式过程可视化
无论是文本流、工具流,还是任务轮询,UI 都在节点上显示过程状态。
用户看到的是“节点正在生长”,不是“按钮转圈等奇迹”。
以文本为例,流式响应会持续回调更新节点内容;
以视频为例,任务创建后轮询状态,成功后再下载并存储本地 Blob。
第 5 步:结果落地与关系维护
生成成功并不是结束。
项目会继续完成以下动作:
-
创建新节点或更新目标节点;
-
建立来源与结果的连线关系;
-
写入媒体
storageKey; -
更新批量根节点元数据(主图、子图列表);
-
清理进行中请求引用。
这一步确保“结果不是孤儿”,而是回到可追踪图结构里。
第 6 步:历史与持久化收敛
节点变更最终进入历史系统并延迟提交,随后触发 store 持久化。
持久化采用 zustand persist + localForage,项目结构和媒体索引写入状态仓,媒体实体写入 Blob 仓。
用户刷新页面,几乎总能回到之前那一刻。
十七、落地时最容易踩的 10 个坑(附规避建议)
如果你也在做类似系统,下面这些坑大概率会遇到。
我把“症状 -> 原因 -> 建议”写在一起,方便直接对照。
1)症状:撤销一团乱麻
原因:把拖拽过程中每一帧都入历史。
建议:拖拽期间暂停 history,结束后一次性提交;并加时间窗口合并。
2)症状:项目文件越来越大,导出越来越慢
原因:把 base64 媒体塞进 JSON。
建议:结构化状态与媒体实体分离存储,状态只保存 storageKey 引用。
3)症状:用户说“我改了参数,但生成结果像没变”
原因:上下文来源混乱,输入不是从图结构统一提取。
建议:统一从连线图推导输入,不允许页面局部拼参数覆盖图语义。
4)症状:支持第三家模型后,代码分支爆炸
原因:页面层直接写供应商判断。
建议:建立配置归一化层,把供应商差异压到 service 末端映射。
5)症状:Agent 偶尔“误删半个画布”
原因:写工具无确认机制,且缺乏可回滚快照。
建议:写操作默认确认;批量操作前保存 agentUndoSnapshot,可一键回退。
6)症状:本地 Agent 偶尔请求失败,浏览器报跨域
原因:本机服务没有正确处理 origin 或私网访问头。
建议:本地服务固定 127.0.0.1,同时维护 token + 允许来源白名单。
7)症状:跨设备同步后,媒体“节点在,图不在”
原因:只同步了 JSON,没同步 Blob 文件。
建议:清单里必须包含文件索引,按索引补齐缺失媒体后再渲染。
8)症状:并发生成时偶发状态串台
原因:全局单 loading 状态、无请求实例隔离。
建议:按 runningId 或 targetNodeId 建立请求 Map,取消时精准中断。
9)症状:Prompt 系统卡顿,打开页面就慢
原因:每次都实时抓取第三方仓库。
建议:加 TTL 缓存 + Promise 去重,首个请求加载后复用结果。
10)症状:用户不信任 Agent 自动化
原因:过程不可见,只给最终结果。
建议:提供事件流日志、工具调用摘要、逐步确认和失败可诊断信息。
结语:真正的门槛,不是模型,而是“可持续创作系统”
infinite-canvas 给我的最大启发是:
当大家都在卷“再快一点出图”时,它在卷另一件更难但更值钱的事——
如何把创作过程沉淀成可复用、可追踪、可协作的系统。
如果你只把它当“生图工具”,会觉得它功能挺多。
如果你把它当“创作操作系统”的雏形,你会发现它很多看似琐碎的设计(节点 metadata、历史快照、工具协议、同步清单、线程工作区)其实都在为同一件事服务:
让创作从“灵光一闪”变成“稳定交付”。
说得直白一点:
今天你能做出一张好图,很厉害;
明天你还能稳定做出第 100 张,而且知道每一张怎么来的,这才是工程价值。
附:关键代码入口索引(建议二刷时对照)
-
画布主逻辑:
web/src/app/(user)/canvas/[id]/canvas-client-page.tsx -
生成上下文:
web/src/app/(user)/canvas/components/canvas-node-generation.ts -
资源引用推导:
web/src/app/(user)/canvas/utils/canvas-resource-references.ts -
在线 Agent:
web/src/app/(user)/canvas/components/canvas-assistant-panel.tsx -
本地 Agent 面板:
web/src/app/(user)/canvas/components/canvas-local-agent-panel.tsx -
画布状态存储:
web/src/app/(user)/canvas/stores/use-canvas-store.ts -
素材状态存储:
web/src/stores/use-asset-store.ts -
配置中心:
web/src/stores/use-config-store.ts -
图片 API 适配:
web/src/services/api/image.ts -
视频 API 适配:
web/src/services/api/video.ts -
音频 API 适配:
web/src/services/api/audio.ts -
WebDAV 同步:
web/src/services/app-sync.ts、web/src/services/webdav-sync.ts -
提示词聚合 route:
web/src/app/api/prompts/route.ts -
本地 Agent 服务:
canvas-agent/src/http-server.ts -
本地 Agent 会话桥:
canvas-agent/src/canvas-session.ts -
Codex 集成:
canvas-agent/src/agents.ts -
MCP 服务:
canvas-agent/src/mcp-server.ts
如果你准备把这套思路用在自己的项目里,建议先从两件事开始:
-
把“生成请求”升级成“节点化工作流”;
-
把“结果落地”升级成“可追溯状态 + 独立媒体存储”。
先把这两步走稳,你的 AI 创作系统就已经超过大多数“只会调接口”的项目了。

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐
 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)