【云计算与云原生实战】08:分布式系统基石——并发与并行计算核心原理深度解析
🌟 【云计算与云原生实战】08:分布式系统基石——并发与并行计算核心原理深度解析
专栏前言
本专栏旨在通过深度剖析云计算底层的工具链与架构设计,帮助读者构建完整的云原生知识体系。上一章我们讲解了Docker Compose多容器编排技术,实现了单机应用栈的一键部署。而分布式系统与云计算能够支撑大规模算力的核心底层能力,正是并发与并行计算。本章将系统拆解并发与并行的核心概念,讲解并行计算的经典模型、分布式通信机制、逻辑时钟与消息序,深入剖析并发控制与死锁的底层原理,理解分布式系统协同工作的底层逻辑。
(注:本系列的动手实验 Lab 将在独立的实战篇专栏中连载,敬请期待。)
一、并发与并行基础:核心概念辨析
1.1 并发与并行的本质差异
很多人会混淆并发与并行,二者是相关但完全不同的两个概念:
- 并发:指多个活动在宏观上同时发生的特性,强调多个任务交替推进、互相协作的过程,核心关注任务的协调与相互影响。
- 并行:是实现并发的一种技术手段,指多个任务在物理上同时执行,核心目标是缩短整体任务的完成时间。
从耦合度的视角,二者又可进一步区分:
- 并行通常对应紧耦合:任务之间交互频繁、联系紧密,通常运行在共享内存的多核或紧耦合集群上。
- 并发通常对应松耦合:任务之间相对独立,通过消息传递协作,通常分布在不同节点上。
通俗理解:并发是一个人同时吃三个包子,咬完这个咬那个,宏观上都在吃;并行是三个人同时各吃一个包子,物理上真的同时在吃。云计算的大规模算力,本质上是通过并行物理资源实现并发业务处理。
1.2 云计算中的并发价值
并发是云计算的核心底层逻辑:海量用户的业务请求需要并发处理,大规模计算任务需要拆分为并行任务分发到多台机器执行,从而突破单台计算机的物理算力上限。
最典型的场景是易并行(Embarrassingly Parallel)任务,比如500万张图片的格式转换:
- 串行执行:单核心逐个处理,总耗时极长。
- 并行执行:5个核心并行处理,每个核心负责100万张图片,任务之间几乎不需要通信,加速比接近5倍。
并行执行的收益可以用加速比直观衡量:
加速比=串行执行总时间/并行执行总时间 加速比 = 串行执行总时间 / 并行执行总时间 加速比=串行执行总时间/并行执行总时间
并行任务分为初始化、核心计算、收尾三个阶段,其中只有核心计算阶段能被并行加速,初始化和收尾阶段无法通过并行缩短时间,这也和我们之前讲的阿姆达尔定律逻辑一致。
1.3 协调与通信:并发的核心前提
并发任务不可能完全独立运行,必须通过协调与通信保证逻辑正确,缺乏协调的并发会带来严重问题,比如死锁、数据错乱。
- 通信:决定了并发系统的整体效率。通信速度远慢于计算速度,传输几个字节的时间里,处理器可以执行数十亿条指令。频繁通信会严重拖慢并行任务的速度。
- 同步:是协调的核心形式。比如分阶段的计算任务,必须等所有并行线程都完成当前阶段,才能进入下一阶段,这就是屏障同步(Barrier Synchronization)。同步会带来等待开销,是并行效率损耗的重要来源。
生活类比:就像团队合作做项目,如果沟通成本太高、同步等待太多,人多反而效率更低。并发系统的设计,本质上就是在平衡并行收益与通信、同步的开销。
二、并行计算的分类与经典模型
2.1 并行粒度:粗粒度与细粒度
根据计算与通信的比例,并行可分为两类:
- 粗粒度并行:并行线程每次执行一大段代码,才进行一次通信。通信频率低,并行效率高,适合松耦合的分布式任务。
- 细粒度并行:并行线程每次执行很短的计算,就需要等待消息或数据,通信频率高,并行效率低,但能处理更复杂的紧耦合任务。
从程序结构上看:
- 串行程序:单进程顺序执行,无并行。
- 粗粒度并行:多进程并行,进程间交互少。
- 细粒度并行:多线程并行,线程间交互频繁。
2.2 BSP整体同步并行模型
BSP(Bulk Synchronous Parallel,整体同步并行)是由Leslie Valiant提出的软硬件桥接模型,是并行计算的经典理论模型。它的核心思想是将并行计算划分为一个个超步(Superstep),每个超步都遵循「计算→通信→同步」的固定流程。
(1)BSP模型三大组成
- 处理单元:一组带内存的处理器,各自执行本地计算。
- 路由器:负责处理器之间的消息传递与通信。
- 同步机制:每隔固定的时间周期L,执行一次全局屏障同步。
(2)超步的三个阶段
每个超步的执行流程完全一致:
- 本地计算阶段:每个处理器独立执行本地计算任务,只访问本地内存。
- 通信阶段:处理器之间互相发送消息,交换数据。
- 全局同步阶段:等待所有消息传递完成,确认所有处理器都完成当前超步,再进入下一个超步。
并行松弛度:通过给每个处理器分配足够多的待执行任务,可以在通信等待时切换到其他任务执行,从而隐藏通信延迟,提升整体效率。
(3)BSP模型的成本计算
BSP模型的核心优势之一是可量化评估并行效率,通过四个核心参数可以精确计算每个超步的执行成本,从而估算并行任务的总耗时,评估方案的性价比。
核心参数定义
| 参数符号 | 参数含义 | 单位说明 |
|---|---|---|
p |
并行处理器的总数量 | 个 |
r |
单个处理器的计算速率 | 操作数/秒(op/s) |
g |
单位数据通信成本:传输1个字的数据,等价于多少次计算操作的耗时 | 操作数/字 |
l |
单次全局屏障同步的成本,等价的计算操作数 | 操作数 |
(3)单超步成本计算公式
由于计算、通信阶段都是所有处理器并行执行,因此单个超步的总等价操作成本取各阶段的最大耗时,再加上固定的全局同步开销:
单超步总成本=单处理器最大计算量+(单处理器最大通信字数×g)+l 单超步总成本 = 单处理器最大计算量 + (单处理器最大通信字数 \times g) + l 单超步总成本=单处理器最大计算量+(单处理器最大通信字数×g)+l
- 计算阶段:所有处理器并行执行,阶段总耗时由计算量最大的处理器决定。
- 通信阶段:所有处理器并行传输数据,阶段总耗时由通信量最大的处理器决定,乘以单位通信成本g转换为等价操作数。
- 同步阶段:全局统一屏障等待,为固定开销l。
经典例题
题目:某并行任务采用BSP模型执行,共5个处理器,已知单位通信成本g=2.5 操作/字,单次全局同步成本l=20 操作。单个超步内,计算量最大的处理器需要执行80次操作,通信量最大的处理器需要传输12个字的数据。请问该超步的总执行成本为多少?
详细计算步骤:
- 计算阶段开销:取最大计算量,即 80 操作
- 通信阶段开销:最大通信字数 × 单位通信成本 = 12 × 2.5 = 30 操作
- 同步阶段开销:固定值 l = 20 操作
- 单超步总成本 = 80 + 30 + 20 = 130 操作
随堂练习
题目:某BSP并行任务包含2个完整超步。已知参数:处理器数量p=4,单位通信成本g=3 操作/字,单次同步成本l=24 操作。
- 第1个超步:单处理器最大计算量100操作,单处理器最大通信量8字
- 第2个超步:单处理器最大计算量90操作,单处理器最大通信量6字
请问整个任务的总等价操作成本是多少?
参考答案:
- 第1个超步成本 = 100 + (8×3) + 24 = 100 + 24 + 24 = 148 操作
- 第2个超步成本 = 90 + (6×3) + 24 = 90 + 18 + 24 = 132 操作
- 任务总成本 = 148 + 132 = 280 操作
2.3 两类并行模式:数据并行 vs 任务并行
根据并行对象的不同,并行计算分为两大范式:
| 并行模式 | 核心逻辑 | 典型场景 |
|---|---|---|
| 数据并行 | 将输入数据拆分,分发到多个处理器上,每个处理器执行相同的计算逻辑 | 批量图片处理、大数据MapReduce计算 |
| 任务并行 | 将不同的计算任务分发到多个处理器上,每个处理器执行不同的计算逻辑 | 多传感器数据处理,不同传感器的数据分别用不同程序处理 |
数据并行是云计算中最常见的并行模式,大数据处理、AI模型训练都基于数据并行的思路实现。
2.4 两种计算模型:控制流 vs 数据流
根据执行驱动方式的不同,计算模型分为两类:
- 控制流模型:就是我们熟悉的冯·诺依曼模型,程序按指令顺序执行,每一步明确指定下一条要执行的指令,通过分支、循环控制流程。并行需要开发者手动拆分任务、编写并行算法。
- 数据流模型:没有固定的执行顺序,只要一个计算节点的所有输入数据都就绪了,就可以自动开始执行。这种模型能天然挖掘出程序中的最大并行度,无需手动设计并行逻辑。
数据流模型天然适配大规模并行场景,但编程范式差异大,目前更多作为底层理论模型存在。
三、并发实体与通信机制
3.1 进程与线程:并发的调度单元
操作系统中,并发的基本执行单元是进程和线程:
- 进程:正在执行的程序,拥有独立的内存空间、文件句柄等资源,是资源分配的最小单位。
- 线程:轻量级进程,是CPU调度的最小单位。同一个进程内的多个线程共享进程的内存、文件等资源,切换开销远小于进程。
一个进程可以包含多个线程,所有线程共享代码、数据、文件资源,但每个线程有独立的寄存器、程序计数器、栈空间,保证各自的执行上下文。
相关基础概念
- 进程状态:进程所有状态信息的集合,包含代码、数据、寄存器、栈等,有了完整状态就可以暂停、恢复进程的执行。
- 事件:进程状态的变化,分为本地事件和通信事件。
- 进程组:一组相互协作的进程,共同完成同一个目标,通过通信互相协调,比如MPI并行计算中的所有进程就属于同一个进程组。
3.2 消息与通信通道
分布式并发系统中,进程之间通过消息传递进行通信,核心抽象是通信通道。
- 消息:结构化的信息单元,是进程间传递数据的载体。
- 通信通道:两个进程之间的消息传输通路,通道的状态就是「已发送但还未被接收的所有消息」。
- 通信只有两个基础操作:
send(m)发送消息、receive(m)接收消息。
注意:消息接收和消息交付是两个不同的操作。消息到达目标节点后,不会直接交给进程,而是先由通道接口缓存,按规则交付给进程,这就为消息顺序控制提供了空间。
3.3 通信协议
通信协议是进程间协调的规则约定,一套可靠的通信协议需要实现三大能力:
- 差错控制:通过检错码、纠错码,在有噪声的网络中保证消息传输正确。通过增加冗余位,让接收方可以发现甚至纠正传输错误。
- 流量控制:接收方向发送方反馈处理能力,强制发送方只发送接收方能处理的数据量,避免接收方被消息淹没。
- 拥塞控制:保证网络的总负载不超过网络的承载能力,避免网络拥堵瘫痪。
四、分布式时钟与消息顺序
4.1 全局时间的困境
并发协调需要明确事件的先后顺序,但分布式系统中不存在全局统一的时钟:
- 每个节点只有本地时钟,走时速度存在偏差,无法得到精确的全局时间。
- 两个没有因果关系的事件,本质上没有绝对的先后顺序,我们称之为并发事件。
但很多场景下我们又需要对事件排序,因此需要一种不依赖物理时钟的排序方法——逻辑时钟。
4.2 Lamport 逻辑时钟
逻辑时钟(Logical Clock)是Lamport提出的抽象时钟,通过事件的因果关系来定义顺序,保证「如果事件a发生在事件b之前,那么a的逻辑时钟一定小于b」。
逻辑时钟的两条更新规则
- 本地事件:进程内发生一个本地事件时,本地逻辑时钟加1。
LC(e)=LC+1 LC(e) = LC + 1 LC(e)=LC+1 - 接收事件:当进程收到一条消息时,将自己的逻辑时钟更新为「本地时钟值」和「消息携带的时间戳+1」二者的最大值。
LC(e)=max(LC, TS(m)+1) LC(e) = max(LC,\ TS(m) + 1) LC(e)=max(LC, TS(m)+1)
每条消息发送时,都会带上发送方当时的逻辑时钟值作为时间戳TS(m)。
逻辑时钟只能保证因果顺序:有因果关系的事件,逻辑时钟一定满足先后;但逻辑时钟小,不代表事件一定发生在前面。
4.3 消息交付规则
在正式讲解交付规则前,首先明确两个核心概念的区别:
- 消息接收:消息通过网络到达目标节点,存入节点的网络缓冲区,属于底层网络行为。
- 消息交付:将缓冲区中的消息正式递交给上层业务进程,属于业务层的行为。
网络本身只能保证消息“送达节点”,但不能保证交付给业务进程的顺序。我们讨论的FIFO交付、因果交付,都是通过协议控制消息交付给进程的顺序,而非消息到达节点的顺序。
(1)FIFO交付:单发送方顺序保障
FIFO(先入先出)交付是最基础的交付保证,规则非常简单:
同一个发送方发给同一个接收方的多条消息,会按照发送方的发送顺序,依次交付给接收方进程。
比如进程A先后给进程B发了m1、m2两条消息,无论网络中是否出现乱序,进程B都会先交付m1,再交付m2。
- 实现方式:发送方给每条消息附加递增的序列号,接收方按序列号从小到大依次交付。如果后发的消息先到,就先暂存到缓冲区,等前面的消息到达并交付后,再交付后续消息。
FIFO的局限:只能保障单发送方→单接收方的顺序,无法处理多发送方场景下的因果关系。当一个接收方从多个发送方收消息时,FIFO无法保证跨发送方的消息先后逻辑。
(2)因果交付:全局因果顺序保障
因果交付是比FIFO更强的交付保证,它基于分布式系统的happens-before(发生在前)因果关系,保障所有符合因果关系的消息,在所有接收方都按因果顺序交付。
核心基础:happens-before 因果关系
happens-before是分布式系统中定义事件先后逻辑的核心规则,满足三条规则:
- 本地先后:同一个进程内,事件A发生在事件B之前,则A happens-before B。
- 消息因果:发送消息m的事件,happens-before 接收消息m的事件。
- 传递性:如果A happens-before B,B happens-before C,那么A happens-before C。
对应到消息场景:如果消息m1的发送事件,happens-before 消息m2的发送事件,那么我们就说m1是m2的因果前置,m2依赖m1的因果关系。
因果交付的正式定义
对于任意两条消息m1和m2,如果 m1 的发送事件 happens-before m2 的发送事件,那么所有同时收到m1和m2的进程,都必须先交付m1,再交付m2。
简单来说:有因果先后的消息,所有接收方看到的顺序都必须和因果顺序一致,不能出现“结果先到、原因后到”的逻辑颠倒。
底层实现原理
因果交付的核心实现思路是依赖检查 + 缓存等待,本质是用延迟换取顺序正确性,步骤如下:
- 携带依赖信息:每条消息发送时,都会附带自己的因果依赖信息(通常是逻辑时钟/向量时钟值),标识这条消息是在哪些事件之后产生的。
- 接收端检查:接收方收到消息后,不会立刻交付给上层进程,而是先检查:这条消息的所有因果前置消息,是否都已经交付给本进程了。
- 交付或缓存:
- 如果所有前置依赖都已交付,就立刻将这条消息交付给上层业务进程。
- 如果还有前置消息没到达,就把这条消息暂存在缓冲区,不交付。
- 延迟交付:等缺失的前置消息到达并完成交付后,再从缓冲区取出等待的消息,按因果顺序依次交付。
经典反例拆解
我们用三进程场景详细拆解因果交付的作用:
场景:p3先给p1发了消息m1;p1收到m1之后,基于m1的内容处理,再给p2发了消息m3。
从因果关系看:m1的发送 happens-before m3的发送,m1是m3的因果前置。
如果没有因果交付保障,可能出现的异常情况:
- 由于网络延迟,m3先到达p2,m1后到达p2。
- 没有因果控制的话,p2会先交付m3,后交付m1。
- 业务层就会出现逻辑混乱:先看到了p1的回复,之后才看到触发回复的原始消息,因果颠倒。
在因果交付机制下的处理:
- p2先收到m3,检查依赖发现:m3的因果前置m1还没有交付给本进程。
- p2将m3暂存到缓冲区,不交付给上层业务。
- 稍后m1到达p2,检查无前置依赖,先交付m1给业务进程。
- m1交付完成后,系统检查缓冲区,发现m3的所有依赖都已满足,再将m3交付给业务进程。
- 最终p2的业务层看到的顺序是m1 → m3,符合因果逻辑。
因果交付是分布式系统一致性的重要基础,在协同编辑、分布式聊天、分布式数据库同步等场景中,都是保障业务逻辑正确的核心前提。
五、并发控制:临界区与锁机制
5.1 临界区问题
并发系统中,多个线程同时修改共享数据时,会出现数据错误。最经典的例子就是计数器同时加减:
- 两个线程分别执行
count+1和count-1,理论上最终count值不变。 - 但
count+1本质是「读取→加1→写回」三步操作,如果两个操作交叉执行,就会出现结果错误。
因此,访问共享数据的代码段必须被保护,这段代码就叫做临界区。同一时间只能有一个线程进入临界区执行,这种机制叫做序列化,保证操作的原子性。
5.2 互斥锁:基础并发控制
实现临界区保护最基础的方式是互斥锁(Lock):
- 进入临界区前,必须先获取锁。
- 离开临界区后,必须释放锁。
- 同一时间只有一个线程能成功获取锁,其他线程必须等待锁释放。
线程进入临界区前:ACQUIRE 锁L
执行临界区的原子操作
线程离开临界区后:RELEASE 锁L
锁机制保证了结果的正确性,但也降低了并发度,和并行的目标天然矛盾。但没有并发控制,就无法保证计算结果的正确性,这是并发系统必须做的权衡。
5.3 读写锁:多读单写优化
普通互斥锁连并发读都会禁止,但读操作不会修改数据,并发读是安全的。因此衍生出读写锁,也叫「多读单写锁」:
- 读锁:共享锁,多个线程可以同时持有读锁,用于读取数据。
- 写锁:排他锁,同一时间只能有一个线程持有写锁,写的时候不能有任何读。
锁的兼容性矩阵如下:
| 当前持有锁\请求锁 | 请求读锁 | 请求写锁 |
|---|---|---|
| 无锁 | 允许 | 允许 |
| 读锁 | 允许 | 等待 |
| 写锁 | 等待 | 等待 |
读写锁在读多写少的场景下,能大幅提升并发性能,是数据库、缓存系统中常用的并发控制机制。
六、死锁:并发系统的经典难题
6.1 什么是死锁
死锁是并发系统中最经典的故障之一:多个进程互相持有对方需要的资源,同时等待对方释放资源,导致所有进程都无法继续执行,永远卡住。
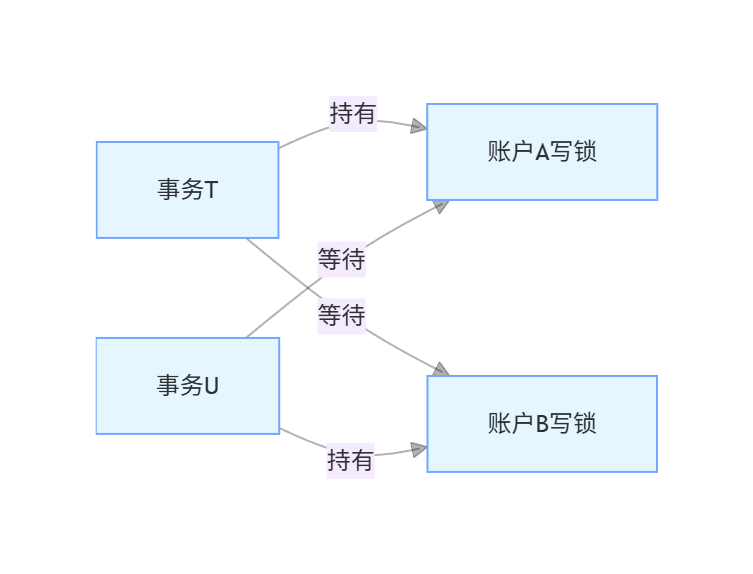
最经典的转账场景:
- 事务T持有账户A的写锁,想要获取账户B的写锁。
- 事务U持有账户B的写锁,想要获取账户A的写锁。
- 双方都持有对方需要的资源,又都在等待对方释放,永远无法继续,这就是死锁。
6.2 死锁产生的四个必要条件
死锁必须同时满足以下四个条件,缺一不可:
- 互斥条件:资源是互斥访问的,同一时间只能给一个进程使用。
- 持有并等待:进程已经持有了一部分资源,同时在等待其他进程持有的资源。
- 不可剥夺:资源一旦分配给进程,就不能被强行收回,只能进程主动释放。
- 循环等待:进程之间形成了环形的等待链,每个进程都在等下一个进程持有的资源。
6.3 死锁预防:打破必要条件
预防死锁的核心思路,就是打破四个必要条件中的任意一个:
| 要打破的条件 | 对应方案 | 存在的问题 |
|---|---|---|
| 互斥条件 | 资源足够多,不需要共享 | 成本极高,绝大多数场景不现实 |
| 持有并等待 | 进程一次性申请所有需要的资源 | 资源利用率极低,很多资源提前占用却长期不用 |
| 不可剥夺 | 高优先级进程可以抢占低优先级的资源 | 需要事务回滚,实现复杂,开销大 |
| 循环等待 | 给所有资源编号,必须按编号从小到大申请 | 资源编号不灵活,可能导致部分进程饥饿 |
死锁预防方案简单可靠,但都会牺牲一定的效率或灵活性。
6.4 死锁检测与解除
另一种思路是不主动预防,而是允许死锁发生,定期检测死锁,发现后再解除。
- 检测方法:构建等待图,节点代表事务,边代表「等待资源」的关系。如果图中出现了环,就说明发生了死锁。
- 解除方法:选择一个事务中止,释放它持有的资源,打破循环,让其他事务可以继续执行。
6.5 超时机制与副作用
更简单常用的方案是超时机制:给每个锁设置超时时间,超时后锁自动释放,事务中止。
- 优点:实现简单,不需要复杂的检测算法。
- 缺点:可能误杀没有死锁的长事务;超时时间难以设定,太短频繁中断,太长死锁持续时间久。
事务中止还会带来两类副作用:
- 脏读:一个事务读取了另一个未提交事务修改的数据,如果后者中止回滚,前者读到的就是错误的脏数据。
- 提前写:事务修改的数据在提交前就被其他事务看到,事务中止后数据回滚,导致数据不一致。
因此,死锁处理没有完美方案,需要在可靠性、性能、实现复杂度之间做权衡。
七、本章总结与课后思考
7.1 核心内容总结
本章系统讲解了并发与并行计算的核心理论,要点如下:
- 并发是多任务协同的特性,并行是实现并发的手段;云计算通过并行算力实现大规模并发业务处理。
- 并行分为粗粒度与细粒度,BSP整体同步模型是经典的并行计算理论,通过超步机制简化并行编程。
- 数据并行与任务并行是两类核心并行模式,控制流与数据流是两类底层计算范式。
- 分布式并发通过消息传递通信,通信协议负责保障传输的可靠、有序与稳定。
- 分布式系统没有全局时钟,逻辑时钟通过因果关系定义事件顺序,因果交付是分布式一致性的基础。
- 临界区需要锁机制保护,互斥锁保证正确性,读写锁优化读多写少场景的并发性能。
- 死锁是并发系统的经典故障,满足四个必要条件,可通过预防、检测、超时三类方案应对。
7.2 课后思考题与参考答案
思考题1
有人说「并发就是并行,并行就是并发」,请结合定义分析这句话是否正确,并举例说明二者的区别。
参考答案:
这句话是错误的,二者概念不同:
- 定义不同:并发强调多个任务宏观上同时推进,关注任务的协调;并行强调多个任务物理上同时执行,关注速度提升。
- 举例:单核心CPU上,多个进程通过时间片轮转交替执行,这是并发但不是并行;多核心CPU上多个进程同时在不同核心运行,这既是并发也是并行。
- 关系:并行是实现并发的一种手段,并发还可以通过分时轮转等方式实现;并行一定属于并发,但并发不一定是并行。
思考题2
某分布式任务采用BSP模型,共4个处理器,每个处理器本地计算需要100个操作单位,通信成本每个字2个操作单位,每个处理器需要传输20个字的数据,全局同步成本为20个操作单位。请问一个超步的总操作成本是多少?
参考答案:
BSP一个超步的成本 = 本地计算成本 + 通信成本 + 同步成本
- 本地计算成本:每个处理器独立计算,取最大值,为100
- 通信成本:每个处理器传输20字,每字成本2,即 20 × 2 = 40
- 同步成本:全局统一同步,成本为20
- 总操作成本 = 100 + 40 + 20 = 160 个操作单位
思考题3
某数据库系统中,多个事务同时读写同一张表。请分析使用普通互斥锁和读写锁分别有什么优缺点,分别适合什么场景。
参考答案:
- 普通互斥锁
- 优点:实现简单,逻辑清晰,不会出现复杂的锁冲突问题。
- 缺点:并发度低,连读操作也会互斥,读多写少场景下性能差。
- 适用场景:写操作非常频繁,读写比例接近的场景;或者逻辑简单、对性能要求不高的场景。
- 读写锁
- 优点:读操作可以并发执行,读多写少场景下能大幅提升并发性能。
- 缺点:实现更复杂,存在写饥饿问题(一直有读的话写锁永远拿不到)。
- 适用场景:读多写少的业务场景,比如商品信息查询、配置读取等。
🚀 下期预告
掌握并发与并行的核心原理后,我们将进入云计算的核心存储与计算技术——分布式存储与大数据计算基础。我们将拆解CAP定理、SQL与NoSQL的技术差异、分布式文件系统架构,深入讲解Google GFS设计原理与MapReduce计算模型,理解大数据时代的存储与计算范式。

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐

 11
11 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)