独立开发者别等用户来报错:一套轻量服务监控方案怎么搭
独立开发者别等用户来报错:一套轻量服务监控方案怎么搭
很多独立开发者和小团队,最开始都不会把“监控”放在很靠前的位置。
这很正常。产品还在验证,功能还在补,用户还不多,大家更愿意把时间花在页面、接口、支付、登录、增长这些更直接的事情上。可问题是,服务稳定性往往不会提前打招呼。
官网可能半夜访问不了,API 可能因为一次依赖抖动返回异常,服务器可能还能 ping 通但业务接口已经报错,SSL 证书可能在某个周末悄悄过期,支付回调可能失败了半天才被用户提醒。更麻烦的是,如果你同时维护官网、后台、App、小程序、开放接口和几个落地页,人工每天点一遍基本不现实。
我现在更倾向于一个朴素判断:只要一个项目开始有真实用户,就应该有一套最小可用的服务监控体系。它不一定复杂,也不一定要像大公司那样堆满 Prometheus、Grafana、日志平台和 on-call 流程,但至少要做到三件事:
- 出问题时比用户更早知道。
- 知道问题大概发生在哪一层。
- 事后能看历史数据,而不是靠感觉复盘。
这篇文章就从独立开发者和中小企业运维的角度,聊聊我会怎么搭一套轻量的监控方案。中间会提到一个我觉得比较适合小团队上手的工具:咕咕监控。但重点不是安利某个按钮,而是把“哪些东西应该被监控”这件事先讲清楚。

为什么小团队更需要轻量监控
大团队有专职运维,有值班,有内部群,有一堆基础设施。小团队通常没有。
独立开发者更典型:一个人写前端、写后端、处理支付、部署服务器、回复用户、做 SEO,还要抽空看数据。你不可能长期靠“我每天打开看看”来保证服务稳定。
我见过不少项目的故障发现路径是这样的:
- 用户在微信群里说“打不开了”。
- 客服反馈“有几个用户支付失败”。
- 运营发现今天注册突然少了。
- 搜索流量掉了几天后才想起来检查页面。
- 某个 API 调用方说接口返回格式不对。
这些都不是好的发现方式。因为当用户来提醒你的时候,说明故障已经影响到业务了。
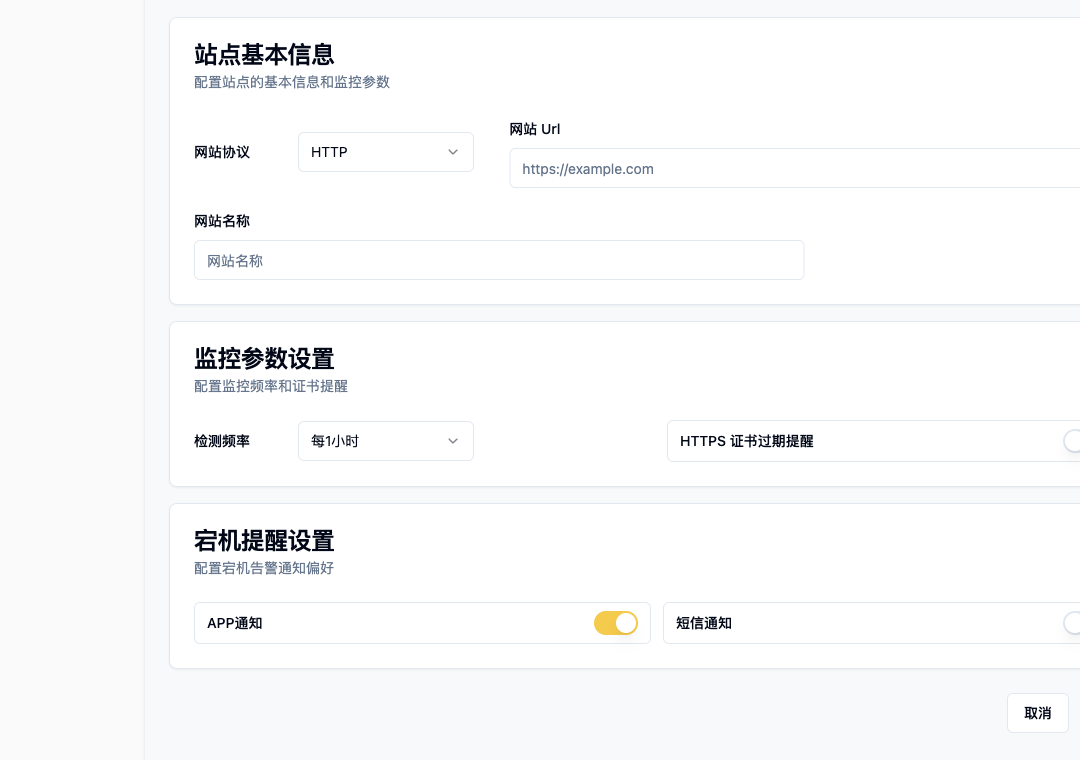
小团队做监控,核心不是把系统搞得多专业,而是用尽量低的维护成本,把最容易出问题、最影响业务的地方覆盖住。我的建议是先从五类对象开始:网站、API、设备或服务器、SSL 证书、SEO 和可访问性。
第一层:网站监控,先确认入口能不能打开
网站监控是最基础的一层。
如果你有官网、营销页、文档站、用户后台、公开状态页,这些入口都应该被监控。对用户来说,他并不会区分是 Nginx 问题、前端资源问题、证书问题,还是后端接口问题。打不开就是打不开。
一个合格的网站监控,至少要关注:
- HTTP 或 HTTPS 是否可访问。
- 状态码是否符合预期。
- 响应时间是否明显变慢。
- 最近一段时间的可用率是多少。
- 是否出现连续失败,而不是偶发网络抖动。
这里有一个容易忽略的点:不要只在服务器内部检查服务进程是否存在。进程还在,不代表外部用户能访问。DNS、证书、反向代理、CDN、出口网络都有可能成为故障点。
所以网站监控最好从外部视角发起。这样得到的结果更接近用户真实访问路径。
咕咕监控里的站点监控就是这种思路:添加一个网址后,它会持续检测连通性、状态和响应时间,并在异常时通过配置好的通知渠道提醒。对独立开发者来说,这比自己写一个定时脚本再维护告警要省心很多。
第二层:API 监控,不只看通不通,还要看对不对
网站能打开,不代表业务正常。
很多问题发生在 API 层。比如:
- 登录接口返回 500。
- 订单接口能访问,但返回状态不符合预期。
- 支付回调接口超时。
- 查询接口响应变慢。
- 第三方依赖异常导致部分字段为空。
如果只做网站监控,这类问题不一定能第一时间暴露。尤其是一些页面有缓存,首页看起来正常,但核心接口已经坏了。
API 监控应该比网站监控更进一步:不只检查接口是否连通,还要检查响应内容是否符合预期。
比如一个健康检查接口应该返回固定状态,一个订单查询接口应该包含明确字段,一个搜索接口应该在合理时间内返回结果。对小团队来说,不需要一开始覆盖所有接口,但可以先覆盖这些关键路径:
- 登录或鉴权接口。
- 下单、支付、回调、订单查询接口。
- 核心数据读取接口。
- 对外开放给客户或合作方的 API。
- 首页或控制台依赖的关键接口。
咕咕监控的 API 监控支持请求方式、参数和响应断言这一类能力,适合用来守住关键业务链路。它不是替代完整测试系统,而是补上“线上接口持续可用”这一层。
第三层:服务器和设备监控,别让基础链路变成盲区
有些项目不只是 Web 服务。
你可能还有服务器、路由器、数据库所在机器、边缘节点、内网设备、客户侧部署的硬件,或者某个必须长期在线的 IP 设备。这时候设备监控就很有用。
设备监控通常会用 ping 或类似方式判断目标是否在线。它不能证明业务一定正常,但能快速告诉你基础网络是否有问题。
这里要注意区分两件事:
- 设备在线,只说明基础链路有响应。
- 应用健康,仍然要看网站和 API 的业务响应。
换句话说,设备监控更适合作为前置链路信号。它能帮你判断“是机器都联系不上了”,还是“机器在线但应用层出问题了”。
如果一个中小企业有多个网站、接口、服务器和网络设备,把这些对象放在同一个监控面板里,会比散落在不同脚本和群消息里清晰很多。
第四层:SSL 证书监控,别让小失误变成大事故
SSL 证书过期是很典型的小团队事故。
它不复杂,甚至有点低级,但它真的会发生。特别是当你有多个域名、多个子域名、多个历史项目时,很容易漏掉某一个证书。
证书一过期,浏览器直接给用户红色警告。对官网、支付页、登录页来说,这种体验非常伤。
所以我会把 SSL 证书监控当成基础项,而不是可选项。最好做到提前提醒,而不是等过期当天再处理。
咕咕监控支持 HTTPS 站点的 SSL 证书到期提醒,这类能力对独立开发者尤其友好。因为你不需要单独维护证书扫描脚本,也不需要每个月人工翻一遍域名列表。
第五层:SEO 监控,把“能访问”扩展到“适合被访问”
如果你的项目依赖搜索流量,监控就不应该只停留在可用性。
一个页面能打开,不代表它适合被搜索引擎理解。常见问题包括:
- 页面性能变差,首屏加载时间明显上升。
- meta description 丢失。
- canonical 配置异常。
- robots 或可索引状态出问题。
- 移动端体验变差。
- 某次改版后 SEO 基础项被破坏。
这些问题通常不会像宕机一样马上炸群,但会慢慢影响搜索表现。等你从流量数据里发现下滑,可能已经过了几天甚至几周。
所以对内容站、工具站、SaaS 官网、API 产品文档站来说,SEO 监控很值得放进日常巡检。
咕咕监控现在也有 SEO 监控能力,可以查看站点性能、可访问性、最佳实践和 SEO 评分,并支持每日邮件报告。这个功能的价值不在于给你一个漂亮分数,而是把“上线后有没有破坏基础 SEO”变成一个可以持续观察的信号。
第六层:状态页,让用户看到你在处理问题
监控是给团队看的,状态页是给用户看的。
很多小团队会忽略这个环节。服务异常时,用户只能反复刷新或者找客服问。对于 B 端客户来说,这会放大不确定感。
公开状态页的作用不是证明你永远不出问题,而是在出问题时提供一个稳定的信息出口:
- 当前服务是否正常。
- 最近 30 天、90 天或 1 年可用率如何。
- 不同监控节点看到的状态是否一致。
- 最近是否发生过异常事件。
这对中小企业尤其重要。你不一定需要很重的工单系统,但至少可以给客户一个页面,让他们知道问题不是没人管。
咕咕监控的公开状态页可以展示站点当前状态、响应时间、历史可用率、节点检测结果和最近事件。对小团队来说,这是一种很轻的信任建设。
告警通知:别只建监控,不设计接收方式
很多人搭监控时会犯一个错误:监控项加了一堆,但通知没想清楚。
结果就是两个极端:
- 要么没人收到。
- 要么所有人都收到,最后大家都麻了。
我建议小团队至少按重要程度分层:
- 核心业务:App 推送、微信、短信或电话提醒,确保能及时看到。
- 普通页面:App 或微信提醒即可。
- SEO 日报和趋势类信息:用邮件更合适。
- 团队协作场景:通过 Webhook 接到自己的群、系统或自动化流程里。
告警通知不是越多越好,而是要让正确的人在正确时间收到正确的信息。
咕咕监控支持多种通知方式,包括 App 推送、微信、短信、电话等,也可以结合邮件报告和 Webhook 做团队化联动。对于没有专职运维的小团队来说,这比自己维护多套通知通道更实际。
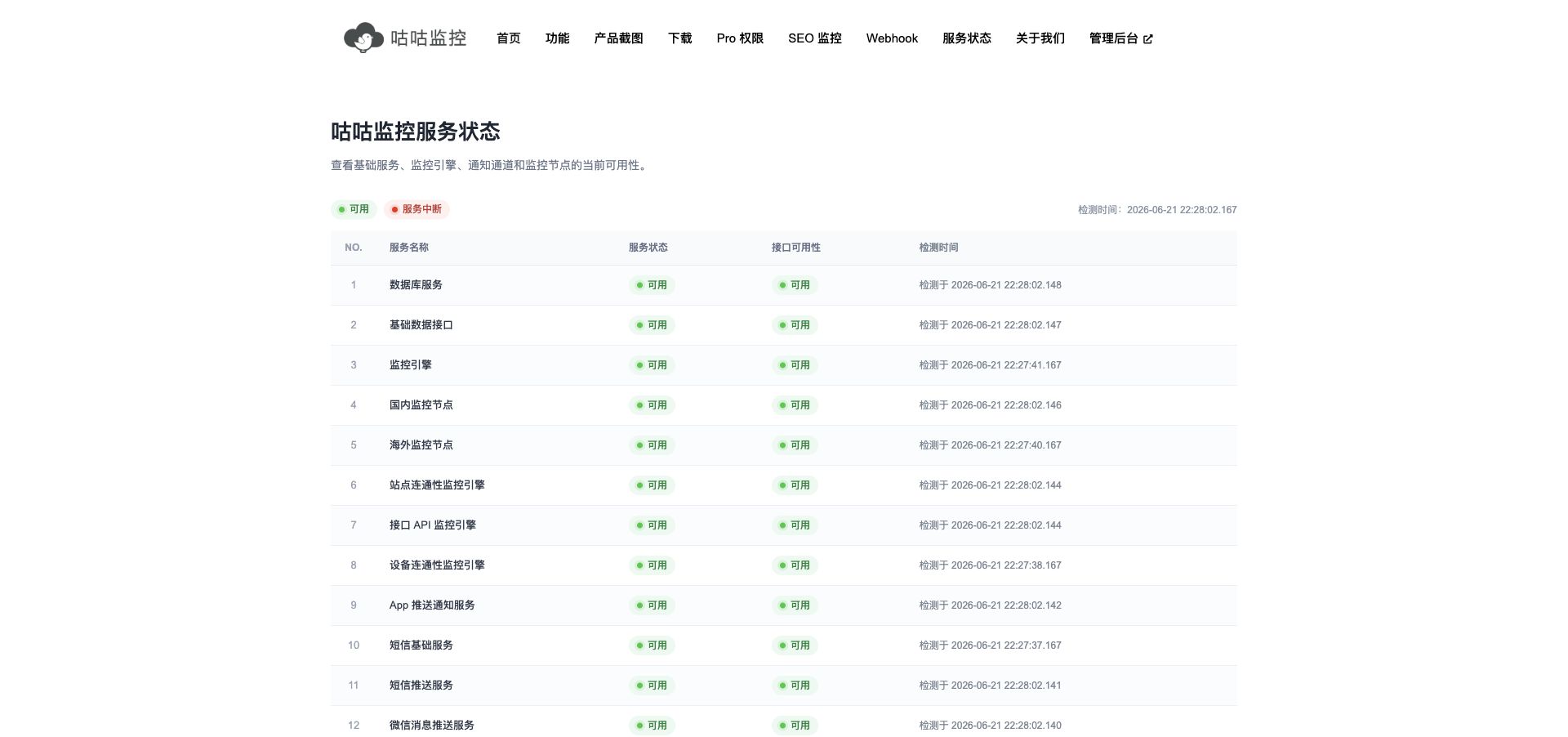
历史数据:没有记录,就没有复盘
监控还有一个经常被低估的作用:留下历史数据。
当用户说“最近感觉有点慢”,你需要看响应时间趋势;当客户问“上个月稳定性怎么样”,你需要可用率;当你怀疑某次发布引入问题,需要看故障发生时间和发布窗口是否重合。
没有历史数据,复盘就会变成聊天记录考古。
我会重点看这些指标:
- 最近 24 小时、7 天、30 天的可用率。
- 平均响应时间。
- 失败次数和失败时间段。
- 最近异常事件。
- 不同监控类型的健康状况。
这些数据不一定要一开始就做得很复杂,但必须能查到。咕咕监控的控制台里有网站、API、设备的监控概览、响应时间、可用率和历史记录,对日常排障已经够用。
独立开发者可以怎么开始
如果是一个人维护项目,我建议不要一上来追求完整体系。可以按这个顺序来:
第一步,先把最重要的用户入口加上网站监控,比如官网、登录页、控制台首页、文档首页。
第二步,把关键 API 加上接口监控,比如登录、下单、支付回调、订单查询、核心数据接口。
第三步,把 HTTPS 站点的 SSL 证书监控打开,避免证书过期这种低级事故。
第四步,如果项目依赖搜索流量,打开 SEO 监控和每日报告,至少能看到性能、可访问性和 SEO 基础项有没有突然变差。
第五步,如果你有对外客户或团队协作需求,把状态页公开出来,让用户能看到服务状态。
第六步,再根据重要程度配置告警方式。不要所有项目都电话提醒,也不要核心业务只靠后台红点。
这个顺序的好处是成本低,收益明显,而且不需要一开始就建立复杂流程。
写在最后
服务稳定性这件事,小团队很容易低估。
因为平时它不显眼,只有出问题时才突然变得很贵。一次官网无法访问,可能损失的是投放流量;一次 API 异常,可能影响的是订单和客户信任;一次证书过期,可能让用户觉得你的产品“不专业”;一次 SEO 基础项出错,可能让搜索流量慢慢下滑。
所以我更建议把监控当成产品上线后的基础设施,而不是等规模大了再补。
如果你是独立开发者,或者团队暂时没有专职运维,可以先用轻量工具把网站监控、API 监控、设备监控、SSL 证书监控、SEO 监控、状态页和告警通知这些基础能力搭起来。咕咕监控就是一个可以考虑的选择:它不需要你维护复杂系统,也能覆盖大部分小团队日常会遇到的服务稳定性问题。
官网可以看这里:https://www.gugujiankong.com/
如果你更习惯在手机上看状态,也可以在微信里搜索「咕咕监控」小程序。

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐
 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)